
Abstract
This paper studies the Job Shop Scheduling Problem (JSSP) with Unit Processing Times evolving in an uncertain environment. Our aim is to determine a set of solutions instead of a unique solution in order to manage unanticipated events. To achieve this, an approach integrating two techniques is presented to achieve sequential flexibility. In the first time, the decomposition of the initial problem into sub-problems is exploited for producing a dominant schedule. Then, based on the Group Sequence (GS) method, a set of schedules is constructed, allowing for sequential flexibility with an evaluation of performance. The present work also develops a new lower bound for the GS and compares it with an existing lower bound from the literature. Using benchmark data sets, computational studies demonstrate that the suggested lower bound significantly outperforms the established lower bound found in the literature. In addition, our approach succeeded in finding a set of solutions for all tested benchmarks within a reasonable amount of CPU time. Moreover, two interesting flexibility indicators are presented to evaluate the efficacy of our approach.
Keywords
Introduction
In the current era of digital manufacturing technologies, combined with uncertain manufacturing environments, production scheduling represents a strategic problem for companies. Scheduling involves allocating a restricted number of machines to a set of jobs within a specific time horizon while satisfying a set of constraints and optimizing one or more objective functions. 1 To solve this problem, many research work has focused mainly on proposing exact and approximate methods to find optimal or near-optimal solutions. These methods adopted deterministic assumptions and considered static environments, where all parameters were known in advance and remained constant over time. However, not all information is known with certainty in real-world production systems, and the environment is naturally dynamic where many disruptions might arise, such as the arrival of new jobs, 2 machine breakdowns,3–5 processing time variations, 6 etc. In recent years, scheduling under uncertainty has received a lot of interest within the research community. Different methods have been proposed in the literature to deal with such uncertainty, often referred to as robust approaches, with the aim of generating schedules that remain valid and effective even when disruptions occur. These methods seek to respond to practical challenges where flexibility and reactivity are essential to managing uncertainties.7,8 In this context, there are generally three categories of approaches: proactive (offline scheduling), reactive (real-time scheduling), and proactive-reactive.
Scheduling problem with unit processing times is a special case of the general scheduling problem. When assuming that all jobs have the same processing time, it is to simplify the problem and provide a way of managing mass production. 9
JSSP with unit processing times is the most common configuration in industries where operations are standardized and have similar durations. Typical examples include electronic component testing, printed circuit board assembly, and surface treatment workshops, where each job goes through a series of short and similar operations on different machines. In such environments, uncertainty can arise from unexpected machine stoppages, material delays, or priority changes. Therefore, the main challenge is to organize and assign tasks efficiently under uncertainty rather than to handle variations in processing times. Despite its simplified processing assumptions, the JSSP with unit processing times remains an NP-hard combinatorial optimization problem, making its resolution computationally challenging even for medium-sized instances. 10 Introducing uncertainty into this already complex problem further increases its difficulty, as it requires developing more robust and adaptive scheduling strategies.
The primary aim of our research is to address the JSSP with equal processing times, by drawing inspiration from the most effective proactive–reactive strategies highlighted in the literature. To the best of our knowledge, no prior study has tackled the JSSP with equal processing times under uncertainty, despite its clear practical relevance. In contrast, this work introduces a novel robust approach that takes into account the uncertain environment of real life. It aims to deliver robust solutions that, although sometimes of lower quality, are often preferred by decision-makers for their greater resilience compared to vulnerable optimal ones. The main contributions of this work are:
The generation of a set of feasible schedules instead of a single one, enabling both proactive and reactive decision-making.
A solution set defined via the GS method, characterized by best and worst-case execution times for each operation.
The identification of a new lower bound, based on the best-case performance, which outperforms several benchmarks from existing studies.
The introduction of two flexibility indicators to evaluate the robustness and adaptability of the proposed solutions.
The remainder of this paper is structured as follows: the next section presents the literature review on scheduling under uncertainty and scheduling problems with unit processing times. The description of the issue and its representation as a disjunctive graph are given in Section “Problem statement.” In Section “Problem decomposition and dominant sequences,” a decomposition of the global problem into several local scheduling that provide sequential flexibility is detailed. In Section “Group sequence based approach,” the construction of a solution set and the determination of a lower bound are presented using the GS method. Section “Computational experiments” presents and discusses the computational results. Finally, Section “Conclusion” summarizes the contribution with future research directions.
Literature review
This section reviews related research. The first subsection presents main approaches for scheduling under uncertainty, while the second examines studies addressing scheduling problems with unit processing times.
Scheduling under uncertainty
Scheduling under uncertainty has been widely studied to address the variability that affects real production systems. Depending on the timing and availability of information, three main approaches are generally distinguished: offline (proactive), online (reactive), and hybrid (proactive–reactive) methods.
Reactive scheduling occurs at the time of executing a predictive schedule by adjusting it so as to take into account the current state of the system. In this context, Ghaleb et al. 11 have developed real-time scheduling models to resolve a flexible job shop scheduling problem (FJSSP) subjected to two types of disruptions: machine breakdowns and the arrival of new jobs. In line with this, Zhou et al. 12 studied a scheduling problem in cloud manufacturing services and proposed a purely reactive approach based on an event-triggered strategy that took into account the arrival of new jobs. Considering both the setup time and the random arrival of jobs in the dynamic job shop scheduling problem (DJSSP), the authors in Zhang et al. 13 have proposed an improved gene programming algorithm to construct scheduling rules. Later, an effective decision-making algorithm is proposed in Zhang and Buchmeister 14 to solve the DJSSP optimization problem. The authors proposed an improved multiphase particle swarm optimization and showed the high level of robustness of their approach.
In contrast to the reactive approach, the proactive approach takes into account the uncertainty when establishing the predictive schedule. The schedule is then more robust as it remains valid even when disturbances occur. Often flexibility is used and is defined as the property of having the potential to satisfy performance requirements. 15 These techniques have also attracted the attention of many researchers. Wang et al. 16 proposed two robust scheduling formulations for JSSP in a realistic production system with uncertainty of processing time, based on a set of bad scenarios. Another study was conducted by Wang et al. 17 to resolve a proactive scheduling problem in a steel production system, considering both stochastic machine breakdown and processing time to achieve a robust predictive schedule. Parallely, Xiao et al. 18 have discussed robust JSSP under processing time variations. Robustness was measured by the deviation between the realized makespan and the predictive makespan. A surrogate model was offered to optimize both scheduling performance and robustness. In Grumbach et al., 19 the authors have considered a dynamic production system and integrated regression models into a metaheuristic model to predict makespan robustness and to deal with uncertain processing times.
In reality, proactive scheduling and reactive scheduling are closely intertwined. In fact, it is unlikely that all unforeseen events will be predicted in advance. It is worth mentioning the work of Davari and Demeulemeester 20 where they have considered the project scheduling problem with stochastic processing time and formulated the problem as an integrated proactive and reactive scheduling problem. They showed that their model outperformed the traditional models. In addition, within the framework of these types of approach, one of the most successful methods used in the literature is the Groups of Permutable Operations method (GoPO),21,22 commonly called the “Group Sequence” (GS) method. It assigns an ordered partition of operations to each machine, that is, a group sequence.23–26 The principle of this approach consists of building, in a predictive manner, a set of flexible solutions without enumerating them. This representation allows us to choose the most adapted solution to react to unexpected events during the reactive phase. An important characteristic of this approach is that it can ensure, admittedly, the existence of a solution computable in polynomial time 24 with a quality, in the worst case, lower than the non-robust optimal solution, and can thus be used during the reactive phase of the GS schedule. Still in the same context, other approaches that exhibit sequential flexibility were proposed, which is less restrictive than the GS method. These approaches are based on a dominance theorem that generates a dominant partial order between tasks. 27 In Briand et al., 28 the authors proposed a robust approach for the single machine scheduling problem that characterizes a large set of optimal schedules regarding the lateness criterion.
A review of the literature reveals that robust approaches are becoming more and more popular because in real-world environments, unexpected events and data uncertainty are challenging the planned plans, making them ineffective. Reactive approaches do not create a plan in advance but react to events when they arise. They calculate in real-time the best possible scheduling, taking into account the type of uncertainties. The disadvantage is that the solution is often unstable, and frequent changes may disrupt the remaining steps of the process. Proactive approaches aim to anticipate problems before they occur. They create a schedule in advance and at the beginning, taking into account prior knowledge of probable uncertainties to absorb potential disruptions. The schedule in this case does not require frequent adjustments, but its efficiency may be reduced since it is unrealistic to proactively take into account all the unexpected events that may arise. The proactive-reactive approach is a combination of two previous ones, and it is the most common approach used in complex and uncertain production environments. They are not only interested in providing a unique schedule accounting for the most common and probable disruptions, but also in determining a flexible set of baseline schedules, thereby offering more choices during the reactive phase.
A key strength of our approach lies in the sequential flexibility it offers. Rather than producing a single static schedule, it generates a set of feasible alternatives offline, allowing real-time adaptation to disruptions by switching between solutions without significant performance loss. This approach combines two complementary techniques. First, the problem is decomposed into several single-machine sub-problems (as in Erschler and Roubellat 29 ) to establish a partial order between operations and handle sequential flexibility. Then, drawing from the GS method, 22 groups of fully permutable operations are constructed to generate a set of robust schedules with measurable performance. This framework ensures proactive flexibility during the planning phase while enabling reactive adaptation during execution.
Scheduling problem with unit processing times
The scheduling problem with unit processing times has attracted the interest of many researchers in the literature. In the field of single-machine scheduling with unit processing times, many recent studies have made important contributions, considering total completion times and the number of late jobs as criteria to minimize.30,31 Chen et al. 32 have applied the concept of two agents to a one-machine scheduling problem where the jobs of each agent have their own equal processing times. Their analysis reveals the binary NP-hardness of the problem depending on the criterion chosen for each agent. The research in Shen et al. 33 investigated the problem of scheduling jobs with equal processing times on uniform machines to optimize the total weighted completion time and the total tardiness simultaneously. Considering a parallel problem with identical execution times of jobs, the authors of Kravchenko and Werner 34 addressed a survey. By assigning jobs to machines sequentially, the open-shop scheduling problem with unit processing times was studied by van Bevern and Pyatkin. 35 They showed that the problem can be solved effectively in polynomial time. In the context of parallel machine scheduling with unit processing times, only a few studies have addressed this problem. One study considers a parallel machine scheduling problem and proposes both an optimal offline algorithm and an online algorithm with a competitive ratio matching the lower bound. 36 In the same line of research, another study develops an online algorithm for identical parallel machines with the makespan criterion, where jobs arrive sequentially and must be assigned immediately without knowledge knowing the release times of future tasks. 37 In Sotskov and Mihova, 38 the authors addressed multiprocessor unit scheduling tasks and solved them as an optimal mixed graph coloring problem with makespan and Lateness criteria.
Despite its practical importance, the JSSP with unit processing times has received limited attention in the literature, primarily due to its high computational complexity, even though it remains theoretically challenging and industrially relevant. In this context, the problem of minimizing the completion time has been shown to be equivalent to an optimal mixed graph coloring, 39 for which branch-and-bound algorithms have been developed to obtain optimal solutions. In another study, for solving large problem instances, a metaheuristic was developed in Kouider et al. 10 A review of recent research on mixed graph coloring is provided in Sotskov. 40 However, the JSSP with unit processing and two objective functions, the makespan and the total completion time, was studied in Kouider and Haddadene. 41 The authors modeled the problem as a bi-objective mixed graph coloring and proposed a resolution approach based on the branch-and-bound method. Beyond parallel machine environments, another line of research has examined multiprocessor scheduling problems.
The main studies addressing scheduling problems with unit processing times are summarized in Table 1.
Summary of studies on scheduling problems with unit processing times.

Most of the previous works, summarized in Table 1, assume deterministic environments where all information is known in advance. Among them, only two works consider uncertainty: the first proposes both an offline exact algorithm and an online competitive algorithm for parallel machines, 36 while the second develops optimal online algorithms for the same context. 37 However, for scheduling problems with unit processing times, no study has simultaneously integrated a proactive–reactive method. Moreover, within the JSSP with unit processing times framework, no work has been conducted under uncertainty, nor has any approach aimed to generate a flexible set of solutions capable of adapting to unexpected disturbances, which remains an open and unexplored area.
Problem statement
The job shop scheduling problem with unit processing times
In this work, the scheduling problem with equal processing time (where
It is important to note that this problem is classified as NP-hardfor n > 2.10,42
To simplify our notation, we use an equivalent representation of the problem throughout the rest of this paper. Given a job J
j
, the index jk of operation O
jk
is replaced by a single index O
i
with
The most popular model in the literature to represent a scheduling problem is the disjunctive graph
In more detail, each arc has a length, with an initial extremity representing the release date r i and a final extremity representing the due date d i . 43 Notice that r i and d i values are calculated using the Ford-Bellman algorithm 44 according to the following formulas:


where
To illustrate this problem, an example of JSSP involving three jobs and three machines with unit processing times

The disjunctive graph of an example problem with three jobs and three machines
In the initial structure of the JSSP
The data of the initial structure of the example given in Figure 1.

Problem decomposition and dominant sequences
In this section, considering the JSSP with equal processing times, we propose a new scheduling approach with uncertainties. It is part of a robust approach and allows one to anticipate and react in real time to disturbances. The approach is based on the decomposition of the global problem into several local schedulings that provide sequential flexibility by exploiting a known dominance condition.
Local scheduling
Since the problem
In this paper, the basic idea of the proposed robust approach is to define for each machine a set of dominant solutions instead of one optimal solution that can be used in real time during execution. Sequential flexibility is then used, and it is based on partial orders between tasks belonging to the same machine. The partial order is associated with the interval structure defined by the relative order of the release r i and due dates d i of tasks. 27
Interval structure and dominance principle
An interval structure is a model for representing temporal information. It describes a hierarchical representation of relationships between temporal intervals using constraints. An interval structure can be defined by a set of intervals I and a set of constraints C over I × I. Each interval x is defined by a lower bound (release date r x ) and an upper bound (deadline d x ). Any constraint between two intervals can be expressed using the relations of the algebra proposed in Allen. 46 Table 3 depicts the basic relations that can be defined between two intervals A and B using Allen’s algebra.
Allen’s algebra.


By considering Allen’s algebra, two particular types of intervals can be distinguished: top and base. 44
The notion of top has allowed to define the notion of s-pyramid that contains the top s and possibly other intervals.
These concepts were used by Erschler et al. 27 for the one-machine scheduling problem with execution windows. They highlight a new dominance condition, relative either to the admissibility or to minimizing the maximum lateness. The dominance condition, known as the pyramidal theorem, takes into account only the relative order of the release dates r i and due dates d i of the tasks without using their explicit values or either of the processing times of the tasks. The dominance condition defines a partial order between tasks. On the one hand, it imposes the tops to be ordered according to the increasing order of their release date, and in the case of ties, according to the increasing order of their due date. If two tops have the same values of r i and d i , they are sequenced in arbitrary order. On the other hand, the non-tops of a s-pyramid are ordered before or after the top s.
Let us consider the example

The initial interval structures for the three machines.
The relative order of the release dates r
i
and due dates d
i
of the tasks for each machine are given as following:
An interesting characteristic of the dominance condition is its ability to measure the number of dominant sequences defined by
Propriety of the JSSP with equal processing times
In this section, we have shown that the JSSP with equal processing times has a particular property where all machines have tasks with an interval structure defined only by tops.
Global scheduling
Once the interval structure for each resource has been established, it becomes relevant to go back to solving the multi-resource problem. Note that each local schedule established by a given resource depends on the decisions made by preceding (upstream) and following (downstream) resources. This can lead to inconsistencies that need to be eliminated to achieve a feasible schedule. To maintain the coherence between local decisions, we have adopted the heuristic proposed in Ourari et al.
47
The mechanism will use primitives to establish, for each pair of tasks

For the initial interval structure, the starting time (S i ) of each operation i represents the maximum between its release date r i and the completion time C j of the previous operation j on the same machine. This ensures that operation i only starts when the machine is available and the execution of the previous operation j on the machine is complete. This is given by:

It is obvious that for the first operation to be processed on a machine, the starting time S i is equal to its release date r i , since there are no operations that precede it.
For illustration, let us again consider the example given in Figure 2. Table 4 shows the starting and completion times for each operation i in the initial interval structure and in the final interval structure after the incoherence has been eliminated. The result has enabled us to deduce an incoherence between tasks 8 and 9 of machine M3 with
The starting and completion times for the example given in Figure 1.

By applying Algorithm 1, first we decrease C8. To achieve this, we need to decrease the deadline of task 8 (d8). Since it is impossible since
The interval structures IntS k associated with each machine are illustrated in Figure 3.

The final interval structures for the three machines.
Once the final interval structure IntS
k
has been determined for each machine, it is crucial to evaluate the sequential flexibility of each of them. Let us consider the previous example and the case of M3 with three operations {3; 6; 7}. There are three tops {3; 6; 7} and then three pyramids, without any base-type operation. The application of the formula
Nevertheless, an interesting characteristic of our particular interval structure is that it allows the application of an approach known as the group sequence method, offering hence flexibility.
In the next section, we investigate the GS method. The aim is to assess the sequential flexibility induced by the application of this method to our problem and to determine a set of solutions with their corresponding worst performance.
Group sequence based approach
The group sequence (GS) method was initially introduced by Erschler and Roubellat in 1989. It is one of the most extensively studied proactive-reactive approaches that provide, without enumeration, several baseline solutions with sequential flexibility and a quality that corresponds to the worst-case scenario. A group sequence is an ordered sequence of groups of permutable operations, specifying for each resource a sequence of task groups where all permutations within the group are free. The performance of the schedule corresponds to the quality of the worst solution it characterizes with regard to a regular criterion, and its flexibility is valuable when measuring the number of groups. The notion of a GS has aroused the interest of several research works in the field of shop scheduling. The basic idea is to identify a set of solutions that are applicable throughout the real-time execution of the schedule.24,25,48–50
The generation of the GS schedule is the vital aspect of the method. In this work, for generating flexible schedules, we have adopted the Ensemble-Based Job Grouping algorithm (EBJG), originally defined by Esswein, 22 that has polynomial complexity and stands out as the best performer in terms of quality and flexibility.23,51 Thus, we have modified and adapted the EBJG algorithm in order to generate flexible solutions for our scheduling problem with equal processing times.
Generation of group sequence schedules: An adapted EBJG
A group sequence schedule
The main modification, introduced in our adapted EBJG, lies in the way the groups are selected at each iteration. In fact, the proposed version of the algorithm incorporates an additional condition: only groups whose successive operations have identical release dates r i and due dates d i are assigned to the same group. This condition reduces the number of possible groups at each iteration, keeping only those that lead to feasible scheduling. As a result, it reduces the number of group evaluations and speeds up the execution time without significantly affecting the final solution. This rule ensures the grouping of tops that can be sequenced in an arbitrary order according to the dominance condition established by the pyramid theorem (see Section “Problem decomposition and dominant sequences”).
Example illustration
To illustrate the GS schedule, let us consider the example described in Section “Problem statement” and the corresponding groups of operation assignments given in Table 5. The disjunctive graph associated with the GS schedules is shown in Figure 4. This graph is an induced subgraph of the disjunctive graph given in Figure 1.
Group sequence assignment.


GS disjunctive graph highlighting two-operation permutable groups.
Table 5 shows the sequence of groups for each machine. For M1, we have three single-operation groups (i.e. v
1
= 3) in this order:

Feasible schedules: (a) C max = 4, (b) C max = 4, (c) C max = 4, and (d) C max = 5.
As we can see, all operations within the group
It is important to note that each solution has its own makespan value, which allows us to evaluate the performance of the set of feasible schedules in the worst case by
Decision support indicators
To fully benefit from the GS technique, it is imperative to evaluate the GS schedule once it has been generated by measuring its quality. Quality can be provided by a performance measure based on job completion times. Hence, the worst performance of a group is represented by its worst completion time. On the other hand, the best-case quality is also interesting to evaluate, and we will determine it by evaluating the best completion time of any job. At least, an indicator of flexibility allows us to measure the quality of the set of possible solutions that the GS technique characterizes.
Worst performance
The worst-case scenario evaluates the quality of GS by representing the worst-case scenario. To calculate it in a disjunctive graph, it is necessary to compute the maximum starting/completion times of the operations present in the set of feasible schedules described by a GS using the dynamic program given in Artigues et al.
24
The first step consists of determining the earliest worst-case starting time

The second step aims to calculate the worst-completion time

Finally, the worst performance of the GS is given by:
As an application of equation (5) on the example Figure 2, we obtain
Best performance
In this section, we propose to evaluate the quality of a group in the best-case scenario or the most favorable scenario. In other words, we seek to determine for each group its best starting time, that is, the best starting time of each task belonging to the group.
We notice that, for determining the best performance and for purposes of simplification, we have maintained the same notation
If we consider again our reference example, the best finishing time of each operation is:
Sequential flexibility
As previously stated, GS characterizes a set of feasible schedules without listing them, ensuring sequential flexibility. An evaluation of this set is required and is considered a measure of flexibility. In this context, there are two measures for GS schedules presented in Esswein.
22
This concerns the total number of groups contained in a solution and designated by

As we can see from the formula, when the number of groups is equal to the number of operations, the flexibility is minimal (
Lower bound computations for the example given in Figure 1.

Among these indicators,
For our example in Figure 3,
To illustrate the principle of the proposed approach in handling unanticipated events during the reactive phase. Let us consider the example given in Table 5 with an unexpected event (e.g. arrival of an urgent task or a maintenance activity). We suppose that the unexpected task u occurs at time t= 2 with a processing time p
u
= 1 and needs to be performed on machine M3. The set of tasks {1, 4, 5, 7, 8} has been completed. We know a priori that set {3, 6} is a group of permutable operations and

Illustration of the generality of the proposed approach through urgent task scenario on M3.
This scenario demonstrates that the proposed method can effectively handle real-time disruptions without violating precedence constraints or increasing the worst-case makespan. The flexibility that fully permutable groups bring allows preserving schedule feasibility and makes the approach both robust and applicable to dynamic environments.
Computational experiments
All the numerical experiments were conducted on a personal computer equipped with an Intel Core i5-4210U CPU @ 1.70 GHz, 4 GB RAM, and Windows 10 (64-bit). All algorithms were implemented in C++ and compiled with g++ (TDM-GCC 9.2.0) in single-thread mode using the -O3 optimization flag. To evaluate our approach, we have conducted extensive computational tests on a set of instances obtained from the job-shop OR-library (https://people.brunel.ac.uk/∼mastjjb/jeb/orlib/files/jobshop1.txt). This library offers sets of square instances: La01-La40 (Lawrence), orb01-orb10 (Applegate and Cook), and ft06, ft10, ft20 (Fisher and Thompson), as well as the modified sets abz05m-abz09m (Adams, Balas, and Zawack) and yn01m-yn04m (Yamada and Nakano), covering various workshop planning scenarios. In order to adapt these benchmarks to our problem, we fixed the processing time for each task i to one unit p i = 1.
For each benchmark instance, a feasible solution is first generated using Algorithm 1. Its runtime is not included in reported computational times. The CPU time refers exclusively to the adapted EBJG grouping procedure and to the computation of the lower bound. We specify that the original EBJG runs in polynomial time, 22 and the additional condition introduced to the adapted version of our approach does not change the overall complexity of the algorithm, as it only adds, at each iteration, a constant-time for checking. Moreover, the algorithm stops when no more operations satisfy the grouping condition or when the worst-case schedule reaches the maximum deviation (D = 20%) allowed from the makespan of the initial solution. The purpose is to preserve sequential flexibility while controlling the performance degradation.
The experimental results are summarized in Tables 7 to 11. We assigned the notation
Test results for La01m-La40m instances.

Test results for abz05m-abz09m instances.

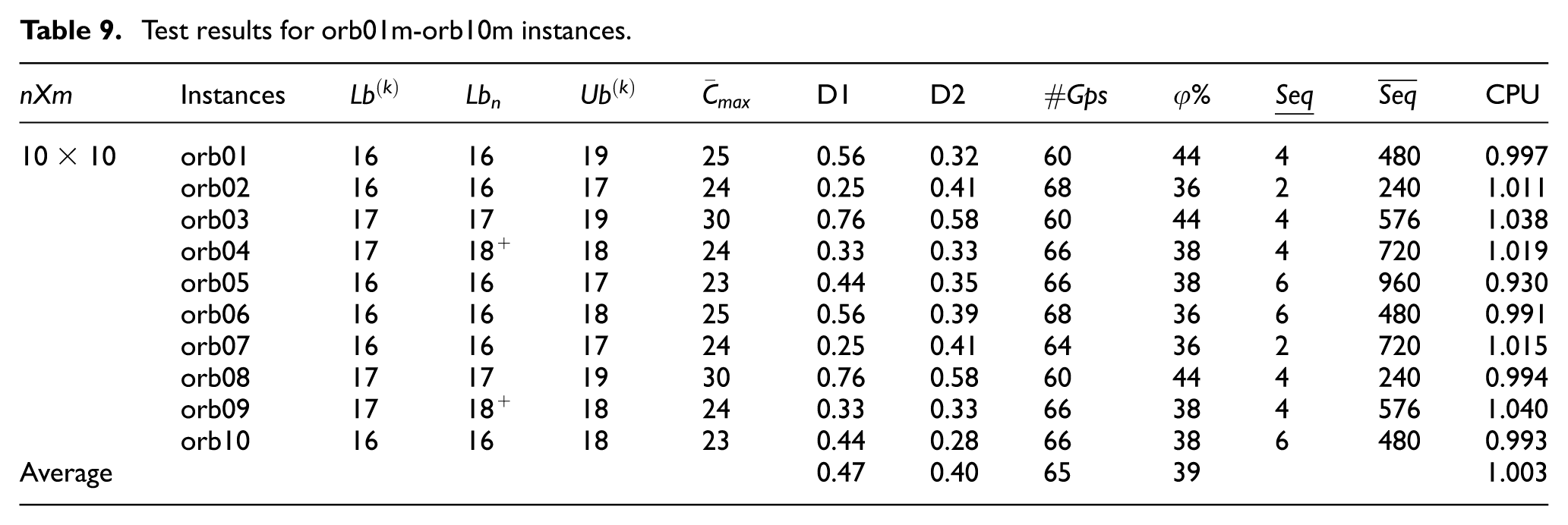
Test results for orb01m-orb10m instances.
Test results for yn01m-yn04m instances.

Test results for ft06m, ft10m, and ft20m instances.

In the following, we compare our lower bounds Lb
n
with the best results
Based on the results presented in the five tables, we compare our lower bound that represents the best completion of any job when it is performed earlier (in the best case defined by the partial order given by our adapted EBJG approach) to the Lb
n
value proposed in the literature. For all instances, our bounds are either equal to
It should be mentioned that the presence of a gap between the upper and lower bounds motivates new research efforts so that instances that have not yet been resolved converge toward optimal solutions. As part of our work, our contribution goes in this direction. Indeed, some of our lower bounds Lb
n
, when they are not equal to those given in the literature, are much tighter and thus improve the quality of the solutions. For example, for instance Y04, our lower bound Lb
n
, equal to 28, corresponds to the literature value
The performance of our approach is evaluated using the two measures (D1) and (D2), which allow us to compare our worst performance (
Conclusion
This paper considered robust JSSP with unit processing times. Our goal was to design a set of solutions rather than a single solution capable of adapting to unforeseen events that could disrupt the production system, leveraging the flexibility provided. To achieve this, we applied two complementary methods, which we adapted to our specific problem: a heuristic approach to generate a schedule having a specific interval structure and allowing to apply a GS method and hence create groups of fully interchangeable operations, with a performance evaluated in the best and worst scenarios. The computational results using benchmarks from OR-Library and adapted to our studied problem have shown, on one hand, the good quality of the proposed lower bound, which is equivalent to sequencing a job in the best case. On the other hand, the results obtained on worst-case performance compared to the generated flexibility validate the relevance of our approach, which aims to anticipate environmental disturbances.
Scheduling problems with unit processing times are widely studied in the literature because they offer both theoretical and practical contributions. The JSSP remains NP-hard in this case and demonstrates its inherent computational difficulty. When the application environment is uncertain, models developed serve as standard references for evaluating the performance of planning algorithms, particularly approximation or heuristic methods. The proposed approach is a contribution to this field because it offers multiple schedules instead of a single solution, allowing a group of operations to be completely permutable, thus ensuring sequential flexibility. The current method is particularly well tailored for instances with equal processing times where operations share identical release and due dates on the same machine. Our lower bound surpasses some results in the literature; moreover, it can be generalized for the case where the processing times are arbitrary in future research.
For future research, it would also be interesting to integrate the proposed approach into a real-life decision support system, taking into account the influence of the human factor. An application of this kind would verify and enhance the theoretical results by testing the robustness of the approach in contexts where human decisions play a central role.
Footnotes
Handling Editor: Chenhui Liang
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.