
Abstract
Gearboxes are critical in industrial machinery, and leveraging multi-sensor data is crucial for effective fault diagnosis. However, robust diagnosis is particularly challenging under varying operational conditions, especially with unlabeled data. This paper introduces an adaptive multi-sensor data level fusion and fine-grained domain adaptation approach (AMDFFDA) to improve gearbox fault diagnosis. The method enhances performance across different operational conditions by combining multi-sensor data fusion at the data level with domain adversarial techniques. Firstly, each single sensor data undergoes preprocessing using the eccentricity technique, followed by the determination of their optimal weighting factors for the effective convergence of data from multiple sensors, with the aim of minimizing the mean square error. Subsequently, an adversarial domain adaptation module is employed to extract features that remain invariant across domains through continuous adversarial training. Ultimately, a teacher model generates reliable pseudo-labels for the target domain, thereby reducing class-conditional shifts between the source and target domains. The findings on the MCC5 dataset demonstrate that AMDFFDA surpasses its competitors in the realm of unsupervised cross-domain fault diagnosis, achieving an average accuracy of 75%. Furthermore, ablation studies validated the contribution of each module within our method, and parameter sensitivity analyses highlighted their impact on the model’s effectiveness.
Keywords
Introduction
In the contemporary industrial field, the efficient and stable operation of mechanical equipment is the cornerstone to ensure production efficiency and operational safety. As a key power transmission component, the gearbox’s operational condition is pivotal to the overall system’s dependability and longevity. However, the gearbox is subjected to complex loads and harsh working environments during the transmission process, so it is very easy to have various faults such as gear wear, tooth surface fatigue, missing teeth, and broken teeth. 1 In order to prevent mechanical failures from causing further economic losses and casualties, the reliable and automated diagnosis of fault within rotational machinery is essential for effective equipment maintenance and management. In sophisticated mechanical systems, overreliance on signals from a single sensor can omit vital data, compromising the diagnostic process.
As sensor technology, artificial intelligence, and big data analytics continue to evolve, data collection during the operation of the gearbox has become more convenient and reliable, which provides a solid foundation for fault diagnosis technology with data analysis as the core. At present, the collection and analysis method based on vibration signals has a dominant position due to its mature technical system and high accuracy. 2 Nonetheless, there are inherent limitations to the fault message about gearboxes that can be captured by monitoring data from a single sensor, and the influence of external noise and environmental fluctuations has weakened the monitoring ability of the overall operation status of the gearbox to a certain extent. To surpass these constraints and enhance the precision and dependability of gearbox fault diagnosis, researchers have increasingly adopted multi-sensor data collected from multiple critical positions and directions, leveraging advanced information fusion techniques to improve diagnostic accuracy. Yang et al. 3 crafted an algorithm for data fusion that integrates signals from various sensors at the data tier. This algorithm is underpinned by an improved fuzzy support system and employs an adaptive noise technique to deconstruct and rebuild the sensor signals. Feature-level fusion involves employing sophisticated algorithms for feature selection and extraction while extracting features. These algorithms deeply integrate information from various sensors’ data. Guo et al. 4 adopted a multi-scale cyclic frequency demodulation framework to achieve high-precision diagnosis of gearbox faults by calculating the covariance matrix of multi-sensor information. Li et al. 5 introduced a deep fusion network that spans multiple layers and incorporates an attention mechanism. This setup enables the integration of deep features from both the branch and central networks, thereby accomplishing adaptive, hierarchical information fusion. Shi et al. 6 fused decision information based on DS evidence theory and convolutional network architecture to identify fault within the hydraulic reversing valve. Fu et al. 7 employed the diagnostic outcomes from the GA-BP algorithm as the foundational probabilities for the task of diagnosing gearbox faults, and integrated DS evidence theory with GA to fuse decisions, thereby arriving at the conclusive identification of faults. Although the above methods have improved diagnostic performance to some extent, they often face difficulties in mitigating the effects of redundancy and localized anomalies within multi-sensor data. In addition, uneven error distributions among different sensors can lead to biased fusion outcomes, thereby impairing the overall reliability of fault diagnosis.
While multi-sensor data fusion has been successful in fault diagnosis, its effectiveness in predictive maintenance tasks across various operating conditions is fundamentally constrained by the assumption of distribution consistency. 8 However, real-world industrial data often falls short of this assumption. With shifts in the distribution of data from multiple sensors, the efficacy of fault diagnosis consistently deteriorates. With the advent of transfer learning, researchers have started to integrate this approach to address the issue of diagnosis faults in mechanical equipment across varying operational conditions. Liu et al. 9 accomplished the adaptive weighting of multi-sensor data fusion by employing a shared feature extraction module. This module specializes in domain-specific feature extraction, using the local maximum mean discrepancy (LMMD) to harmonize disparate subdomains. The output decision module then integrates the classification results from each source domain based on a weighted score calculated using the maximum mean difference, thereby facilitating the diagnosis of faults across different domains for axial piston pumps. Jiang et al. 10 studied a multi-sensor data adaptive weighting strategy (MSAWS) combined with a semi-supervised OTPCL framework. This method dynamically determines the significance of various sensor datasets and assigns them appropriate weights. It improves the extraction of distinctive, domain-agnostic features by fine-tuning the temperature coefficient, which in turn enables cross-domain fault diagnosis even with a scarcity of tagged data. Zhang et al. 11 introduced a framework for extracting and merging features from multiple sensors, integrating both convolutional neural networks and Transformer models. They enabled learning that is invariant to domains by employing a weighted adversarial approach and threshold-based supervised loss functions, and incorporated entropy maximization and minimum loss to classify samples from unknown categories, thereby elevating the effectiveness of cross-domain fault diagnosis for rotary equipment under changeable operating conditions. Warke et al. 12 introduced a TrAdaBoost regressor-based approach for instance domain adaptation, and optimized the precision of tool wear estimation and generalizability of the model across various machining environments by introducing Squeeze-and-Excitation module to assign different weights to multi-sensor pixel matrices. Lin et al. 13 introduced a diagnosis method for few-shot meta-transfer utilizing information fusion-based model-agnostic meta-learning (IFMAML). By enhancing and fusing the RGB channel information of multi-sensor data, this method aims to enhance diagnostic accuracy and computational efficiency across diverse working scenarios. Nevertheless, current approaches typically concentrate on global domain alignment and often overlook the distributional shifts among individual classes. Additionally, due to the absence of annotated data in the target domain, these methods generally lack mechanisms to provide class-specific guidance, thereby restricting their capacity to achieve substantial performance gains in target-domain classification tasks.
Despite recent advancements, fault diagnosis methods that integrate multi-sensor data fusion and transfer learning still face several challenges. Most existing approaches overlook the non-uniformity of sensor noise characteristics and are unable to effectively handle redundant or anomalous inputs, thereby compromising the robustness and representativeness of the fused features. These methods typically compress all sensor inputs into a unified representation, discarding potentially critical differences embedded in the raw signals, which further limits the diversity of feature representations across source and target domains. Moreover, conventional transfer learning frameworks primarily focus on aligning global distributions, lacking fine-grained mechanisms to guide class-level discrimination in unlabeled target domains. This shortfall undermines the model’s ability to adapt to nuanced class structures and ultimately constrains its transfer performance under complex operating conditions.
To address the aforementioned challenges, this study proposes a gearbox fault diagnosis method based on adaptive multi-sensor data-level fusion and fine-grained domain adaptation (AMDFFDA). The method comprises three core modules: a multi-sensor data-level fusion module, an adversarial domain adaptation module, and a category-conditional alignment module. Specifically, the multi-sensor data-level fusion module employs an eccentric distance–based technique to uniformly preprocess individual sensor signals. It then performs adaptive fusion through an optimal weighting strategy, and combines the fused output with original sensor data to construct multi-sensor, multi-level datasets, thereby enhancing the completeness of fault information. The adversarial domain adaptation module introduces class-discriminative information into the domain discriminator. By minimizing inter-domain discrepancies through adversarial training, it enhances the model’s global generalization ability under varying operating conditions. The category-conditional alignment module is designed to generate reliable pseudo-labels for the unlabeled target domain, thereby mitigating conditional shift between source and target domain categories and improving class-level alignment accuracy. A series of ablation experiments and comparative evaluations with existing diagnostic methods have been conducted, demonstrating the feasibility and effectiveness of the proposed method in gearbox fault diagnosis tasks. The main contributions of this work can be summarized as follows:
(1) Considering that sensor data in real-world monitoring environments often suffer from varying levels of noise and redundancy, which can undermine both diagnostic accuracy and robustness, this study introduces an adaptive multi-sensor data-level fusion approach. Specifically, a preprocessing technique based on eccentric distance is applied to individual sensor signals to eliminate outliers, followed by a fusion strategy that minimizes the total mean square error (MSE), thereby achieving optimized and denoised data integration.
(2) To prevent the loss of initial fault information during the fusion of multi-sensor data, this study proposes a method for constructing a multi-sensor, multi-level dataset. By integrating preprocessed single-sensor data with fused multi-sensor data, the approach not only reduces redundancy in the original signals but also preserves the integrity of fault-relevant information, thereby significantly improving the classification accuracy of the diagnostic model.
(3) To achieve precise alignment of multi-sensor data distributions under varying working conditions, this study employs a teacher model to generate reliable pseudo-labels for unlabeled data originating from novel operating scenarios. This strategy effectively alleviates feature discrepancies among corresponding categories across domains and enhances the fine-grained accuracy of cross-domain feature alignment within the adversarial domain adaptation process.
The remainder of this paper is structured as follows: Section “Preliminaries” introduces a method for gearbox fault diagnosis method based on adaptive multi-sensor data level fusion and fine-grained domain adaptation. Section “Results and discussion” presents a series of comparative experiments conducted on public datasets, including analyses that incorporate parameter sensitivity evaluations. Finally, Section “Conclusions” provides a conclusive summary of the principal findings and contributions of this work.
Preliminaries
Problem formulation
This paper examines the issue of cross-domain fault diagnosis for gearboxes, leveraging multi-sensor data across various operating conditions. In general, the approach outlined in this paper is predicated on the following presuppositions:
(1) For the source domain task, labeled multi-sensor data is acquired under specific operating states of the machine. These sensors are of the same type but are placed in dissimilar locations.
(2) For the target domain task, the absence of labels in multi-sensor data precludes its direct application in training fault diagnosis models.
(3) The diagnostic tasks across domains are identical in that they share a common label space.
Assume that
The proposed method
Addressing the issues of robustness deficiency, loss of raw information, and fine-grained category ambiguity in current multi-sensor data fusion methods for cross-domain gearbox fault diagnosis, this article introduces a novel diagnostic approach that leverages adaptive multi-sensor data-level fusion along with fine-grained domain adaptation. Figure 1 shows the framework of the suggested approach, comprising three principal components:
(1) Multi-sensor data-level fusion module: This module employs an eccentricity-based preprocessing technique to detect and eliminate outliers within each sensor’s data. Subsequently, an adaptive weighting strategy guided by the principle of minimizing the total mean squared error is adopted to fuse the denoised signals at the data level. In addition, by integrating the robust preprocessed single-sensor data with the fused multi-sensor data, a multi-sensor, multi-level dataset is constructed, thereby enhancing the completeness of fault-related information. This design effectively reduces the risk of overfitting caused by noise or redundant inputs, thus addressing the challenge of insufficient robustness.
(2) Adversarial domain adaptation module: This module constructs an adversarial training framework comprising a domain discriminator and a target feature extractor to learn domain-invariant representations. During training, the feature extractor is optimized to generate features that confuse the domain discriminator, thereby aligning the marginal feature distributions between the source and target domains. By jointly minimizing the classification loss and the domain discrimination loss, the model ultimately learns domain-agnostic features, achieving an initial alignment of feature distributions across domains.
(3) Category-conditional alignment module: In this module, a teacher network constructed based on the Exponential Moving Average (EMA) of the target model’s parameters is employed to generate pseudo-labels for unlabeled samples in the target domain. Only class predictions with probabilities exceeding a predefined threshold are retained as pseudo-labels to ensure their reliability. The target model is subsequently trained by minimizing the cross-entropy loss between its predictions and the generated pseudo-labels, thereby aligning the class-conditional feature distributions between the source and target domains. Finally, the target model is optimized using a joint loss composed of the adversarial domain discrimination loss and a weighted class-conditional alignment loss. Building upon the marginal feature alignment achieved in the previous stage, this design enables fine-grained, category-level alignment across domains and enhances the model’s ability to adapt to subtle inter-class distributional discrepancies.

Architecture of the suggested approach.
Multi-sensor data level fusion module
The multi-sensor data-level fusion module presented in this study consists of two parts: single sensor data preprocessing and multi-sensor data fusion, as illustrated in Figure 2. It intends to reduce the redundancy and noise interference of measurement data thereby enhancing the precision and dependability of signal sequences.
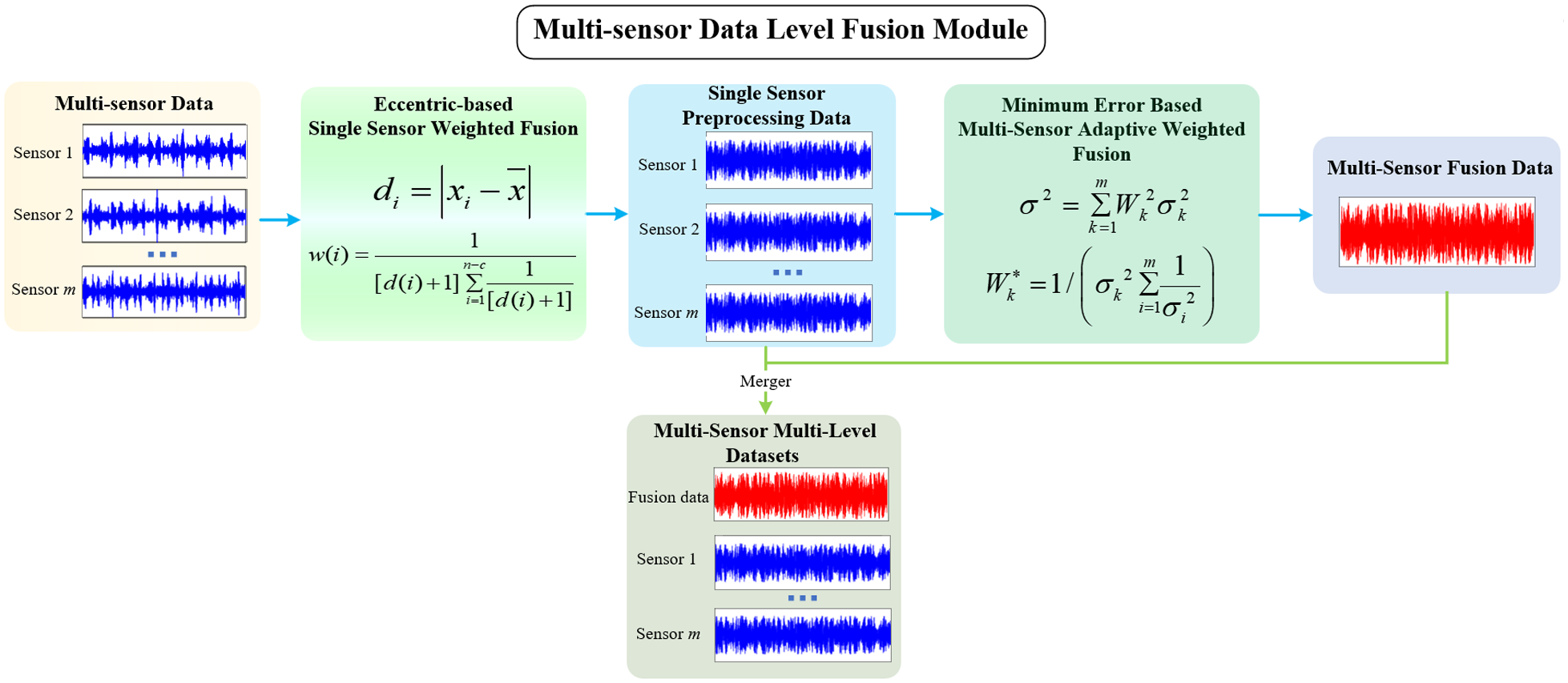
Multi-sensor data level fusion module.
Single sensor data preprocessing
In the process of using multiple sensors to monitor vibration information on key components of a gearbox, sensor failure or environmental interference can cause significant deviations in the data. If abnormal data is not identified and eliminated in advance, noise will be amplified during the data fusion process, the data’s signal-to-noise ratio and amplifying the fused data’s error. To this end, this study uses the center deviation analysis method to conduct data preprocessing for the measurement data of each sensor. In this method, if a certain observation value’s deviation distance surpasses the predefined threshold, it is considered that it may have an adverse impact on the accuracy of data fusion and should be excluded. Assume that m sensors are deployed to simultaneously track the gearbox’s operational status, and the observation sequence collected by each sensor contains n data points. Then the eccentricity distance for a single sensor’s observation is specified as follows:

where,
The eccentricity is calculated for the observation value of each sensor. After removing the first c outliers in descending order according to the set threshold, the reliable data points are obtained as follows:

where,
For the other n−c data points from the p-th sensor, single sensor weighted preprocessing is performed. The closer the observation is to the center, the stronger its coordination with other data points is, and the corresponding weight coefficient ought also to be increased. Based on this rule, the weight coefficient

where,

where,
Multi-sensor data fusion module
On the basis of single sensor data preprocessing, multi-sensor data fusion aims to harness the complementary nature of information from various sources and enhance data stability. To this end, this study adopts an adaptive weighted data fusion strategy with minimizing the MSE as the optimization goal. Based on the signal series from various sensors following single sensor preprocessing, the optimal weight coefficients of multiple sensors are automatically searched, and finally integrated with the single sensor fusion data to form a multi-sensor multi-scale data set.
Assume that m independent sensor observation sequences are

where,

where,

Adversarial domain adaptation module
The adversarial domain adaptation module
15
employs a domain adversarial training mechanism to learn domain-independent feature representations. This module comprises three components: the domain discriminator D, the feature extractor E, and the classifier C. E is tasked with extracting common features from the input data

where,
In order to guarantee the feature extractor and classifier of the source domain also maintain excellent performance on the target domain data, a domain distinguisher is introduced to identify the source of data features and optimized through adversarial training strategy, which can be calculated as follows:

where,

Category conditional alignment module
Although the adversarial domain adaptation module can facilitate the alignment of feature edge distributions between the source and target domains, the method still cannot accurately match the inter-category distributions due to the offset in category conditions. To address this issue, a teacher model-based credible pseudo-labeling method is proposed to better accommodate fine-grained distributional discrepancies between source and target domains across different categories. This method constructs a stable teacher model via an EMA mechanism and employs a high-confidence thresholding strategy to filter out unreliable predictions, retaining only trustworthy pseudo-labels for guiding the training of the target model.
(1) Teacher model: Throughout the training and model refinement of the target domain’s feature extractor and classifier, the teacher model

where,
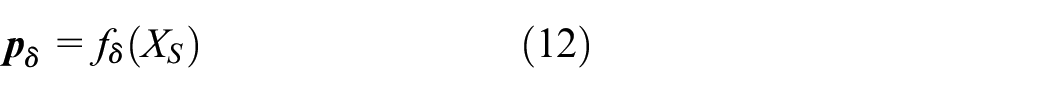
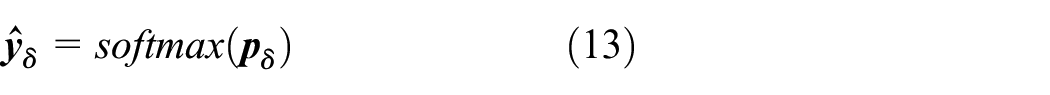
where,
(2) Confident pseudo labels: To enhance the precision of pseudo-labels, this study only considers those labels whose probability values exceed a certain threshold in the prediction results of the teacher model, 17 as shown in Figure 3. Specifically, labels with predicted probabilities higher than a predefined confidence threshold are retained as pseudo-labels and incorporated into the subsequent training process. In contrast, predictions that fall below this threshold are discarded to ensure the reliability of the pseudo-label supervision, thereby improving training efficiency.
This method screens out labels which predicted probabilities are higher than the preset threshold and includes them as pseudo-labels in the subsequent analysis and learning process. For those labels whose predicted probabilities do not reach the threshold, this study chooses not to consider them, to guarantee the dependability of the pseudo-labels used, thereby enhancing the learning efficiency of the model. It is given by the equation:

where,
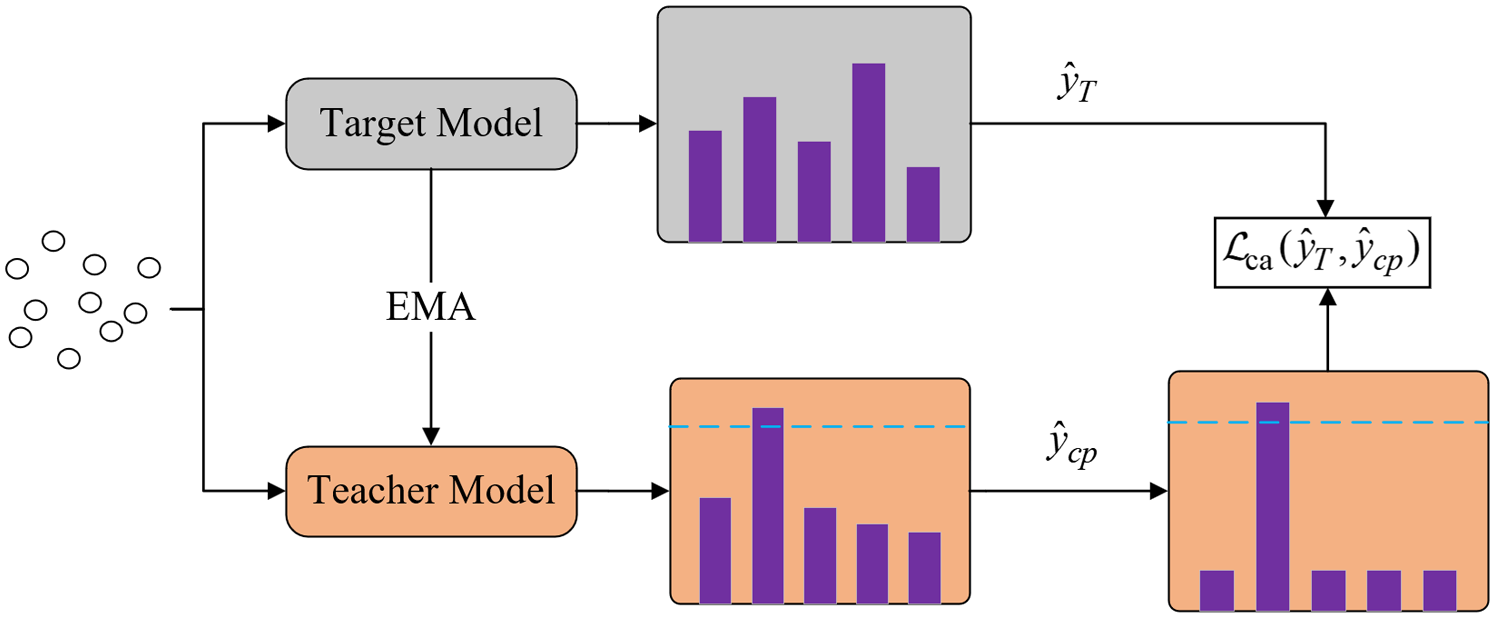
Alignment of class-conditional distributions guided by a teacher model.
Notably, pseudo-labels are neither retained nor reused across training steps or epochs. Instead, at each training step, the latest teacher model regenerates pseudo-labels for all target-domain samples, thereby ensuring real-time updates. Pseudo-labels generated in preceding steps are immediately discarded. This mechanism guarantees that each iteration utilizes pseudo-labels derived from the most up-to-date teacher model, dynamically reflecting the ongoing refinement of the model’s representational capacity.
This paper uses the confidently assigned pseudo-labels to refine the target model and coordinates the distribution of specific categories by calculating the cross-entropy loss between the pseudo-labels and the predicted labels of the target domain model. The cross-entropy loss between the two can be defined as:
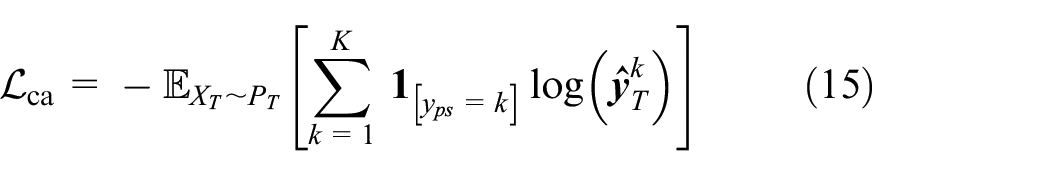
where,
Overall objective function
For AMDFFDA, the optimization process of the target model is achieved by combining two key loss functions: domain discrimination loss and the weighted class-conditional alignment loss. The overall objective function is delineated by:
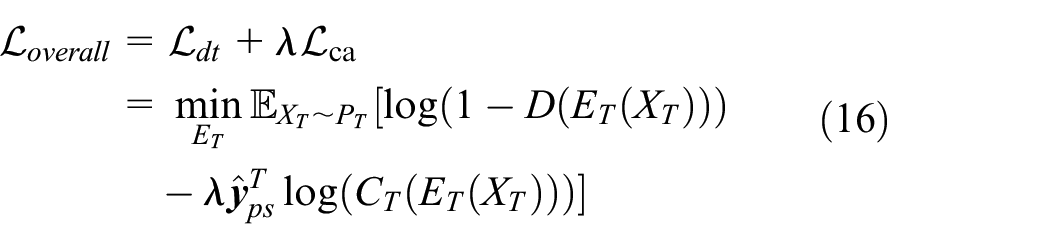
where,
Diagnostic procedure
The diagnostic procedure of the AMDFFDA method offered in this article is depicted in Figure 4. It encompasses four primary stages:
(1) Gearbox multi-sensor data acquisition: By pre-arranging multiple acceleration sensors at key positions of the gearbox, the gearbox operation data under different working conditions can be collected within a certain period of time. Typically, multi-sensor data for the source domain are collected under specific operating conditions are labeled, while multi-sensor data for different operating conditions, known as the target domain, are unmarked.
(2) Multi-sensor data level fusion: The eccentricity of all observations of a single sensor is calculated, and abnormal data with large eccentricity are eliminated in proportion. Then, according to the consistency test principle, the weighting factors of the remaining observations are obtained and the weighted fusion of the single sensor is realized. On this basis, this paper employed an adaptive weighting fusion estimation approach aimed at reducing the overall MSE of the fused data, dynamically and adaptively find the optimal weighting factors corresponding to multiple sensors, thereby realize efficient fusion of data from various sensors. Integrate the above single sensor pre-processed data after consistency processing with the multi-sensor fusion data to form a multi-sensor multi-level dataset.
(3) Model training: The proposed AMDFFDA model is first subjected to supervised pretraining using the processed labeled source domain data, where the classification loss is calculated according to equation (8) to update the model parameters. Subsequently, both source and target domain data are fed into the model for adversarial training. A teacher–student framework is adopted, in which the target domain model is initialized with the pretrained source model parameters and updated independently, while the teacher model is dynamically updated via the EMA mechanism and is used to generate pseudo-labels for the target domain at each training step. The training process consists of two stages: in the first stage, the domain discrimination loss is computed using equation (9) to update the domain discriminator; in the second stage, high-confidence pseudo-labels generated by the teacher model are selected, and the total loss defined by equation (16) is calculated to optimize the target model. This process is iteratively performed over the joint training set of the source and target domains.
(4) Fault diagnosis: By inputting the test data from the unlabeled target domain into the trained model, the encoder model
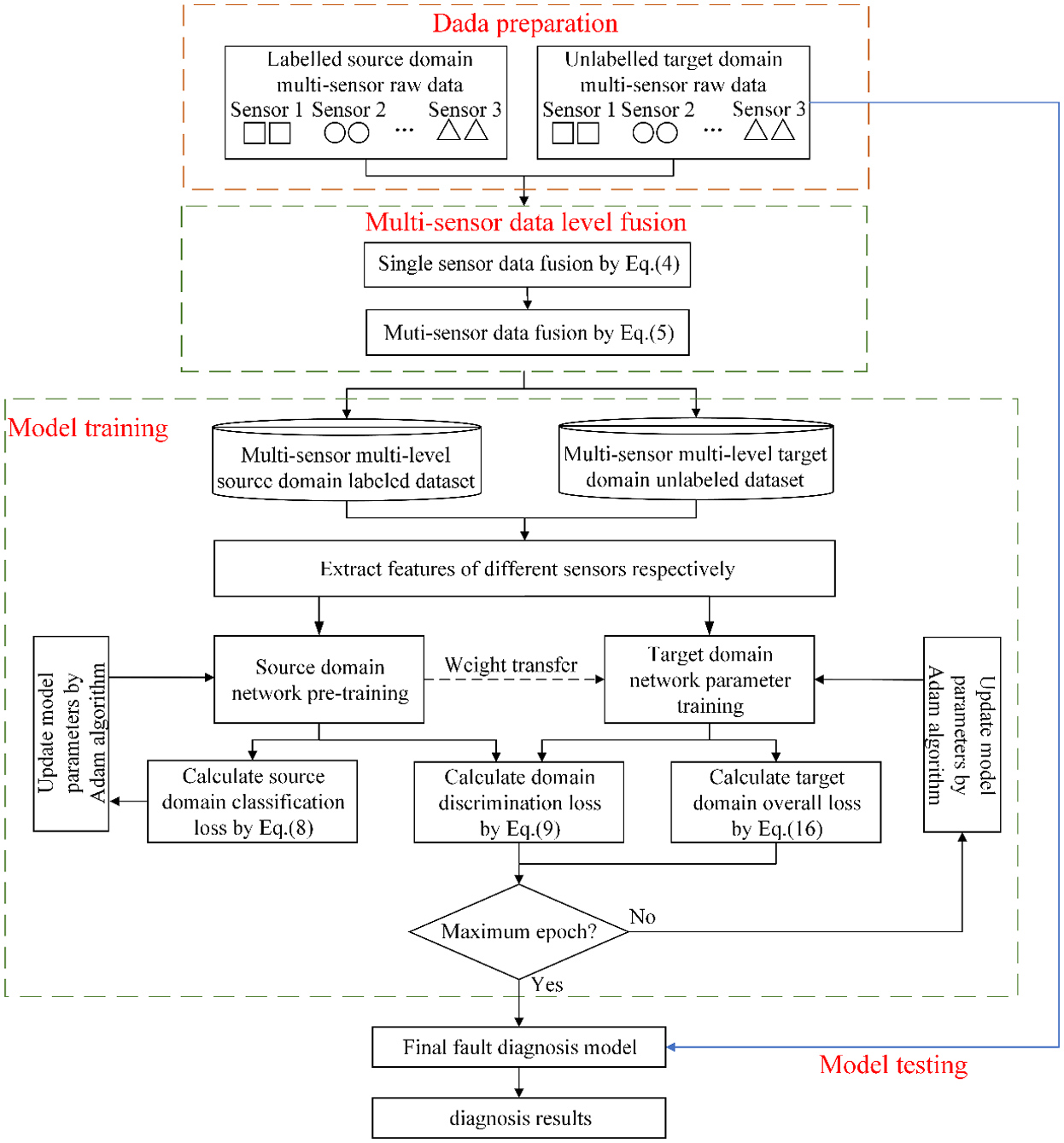
Diagnostic flowchart.
Results and discussion
Experimental dataset description
This paper employs the Tsinghua University gearbox multi-mode fault diagnosis dataset (MCC5) to confirm the efficacy of the suggested approach. The experimental platform used to collect this dataset is depicted in Figure 5. It comprises a 2.2 kW three-phase asynchronous motor, a two-stage parallel gearbox, a torque sensor, a magnetic powder brake serving as a torque generator, and a measurement and control system. 18 Fault gears were introduced into the intermediate shaft of the gearbox using laser etching technology. Two triaxial vibration accelerometers (model TES001V, with a sensitivity of 100 mV/g) were positioned at the motor drive end and the bearing seat of the gearbox’s intermediate shaft. These sensors monitor the triaxial vibration signals of the associated components under various operating conditions with a sampling rate of 12.8 kHz.

Data acquisition test bench.
With the aim of deeply investigate the fault properties of a specific type of gearbox under constant working conditions, this paper covers six health states of the gearbox: gear pitting, wear, missing teeth, broken teeth, cracks, and health states. These states are represented by codes from 0 to 5, and the concrete classification is presented in Table 1. In the experiment, 20 s of vibration data were collected under different health states and working conditions through six synchronously installed accelerometers, totaling 256,000 sampling points. In order to effectively extract features from these vibration signals, this paper uses a sliding window technique, setting the time window length to 1024 sampling points and the sliding step to 512 sampling points to extract samples from the original data. According to this method, 500 samples can be obtained for each health state. Furthermore, to confirm the efficacy and generalization of the model, the collected data were split into a training set and a test set with a proportion of 4:1 to guarantee the rationality of data use and the reliability of experimental outcomes.
Gearbox fault type information.

Comparison methods and implementation details
Task definition
For each health state, three different operating conditions are designed for the experiment (denoted as A, B, and C), namely, operating at a speed of 3000 rpm under a constant load of 10 N m, and running at speeds of 2000 and 3000 rpm under a constant load of 20 N m, as shown in Table 2. This paper mainly focuses on the following six tasks, namely A→B, A→C, B→A, B→C, C→A, and C→B, which are defined as tasks T0 to T5 respectively.
Gearbox operating information.

Parameter settings
In all experiments of this study, the standard back-propagation algorithm based on the Adam optimizer was employed to optimize the network, and the risk of model overfitting was reduced by setting the learning rate weight decay coefficient to 0.0001. All models were trained with a consistent number of iterations, 120. The domain discriminator and feature extractor were both assigned a learning rate of 0.001, while the batch size was configured to 32. The domain discriminator adopted in this study is composed of three fully connected layers with intermediate batch normalization and ReLU activations, specifically configured as a sequence of fully connected layers with output dimensions of 256, 128, 64, and 1, respectively. In order to guarantee impartiality and repeatability of the experimental outcomes, every model was trained and tested five times independently under different random seed conditions to attain a more reliable assessment of the model performance. Importantly, all comparative methods adopted the convolutional neural network architecture defined in Table 3 as a unified backbone for fair comparison. The number of input channels was adjusted depending on whether the method incorporated the multi-sensor data level fusion module, with seven channels used when fusion is applied and six otherwise. For the class alignment module, the trade-off parameter was set to 0.0005, the confidence threshold for pseudo-label screening was 0.85, and the teacher model’s momentum parameter was configured to 0.9.
CNN backbone architecture.

Note: Output dimensions are formatted as (Channels, Sequence length). Batch size is omitted for clarity.
Comparison method description
To demonstrate the benefits of our approach, four other approaches are used to conduct comparative analysis on the same dataset with the proposed method. These methods include:
(1) Convolutional Neural Network (CNN): This baseline model is trained using the labeled source domain data and directly evaluated on the unlabeled target domain data, without incorporating the domain adversarial training or the category conditional alignment modules.
(2) Deep Adaptation Network (DAN) 19 : Being a classic approach in the field of cross-domain unsupervised learning, DAN improves the domain-agnostic feature transferability within deep neural networks’ task-specific layers by minimizing disparities between domains, and uses MK-MMD to match the average embeddings of different domain distributions.
(3) Domain Adversarial Neural Network (DANN) 15 : As a typical cross-domain transfer strategy that integrates the concept of Generative Adversarial Networks (GANs), the core of this network architecture is to embed a special domain discriminator to realize the adversarial training process, and ultimately promote the feature extractor to learn domain-independent feature representation. It also successfully mitigates the problem of gradients that vanish or blow up, which can occur within adversarial training, by incorporating a gradient reversal layer. In this study, the adversarial learning structure employed in DANN is kept consistent with that used in the proposed method.
(4) MFET 20 : This method proposes a lightweight fault diagnosis framework that integrates multi-sensor data fusion with a modified EfficientNetV2 backbone and transfer learning. The fused signals are input into the improved EfficientNetV2 for feature extraction, followed by domain adaptation to handle unseen target domains. In this study, to ensure a fair comparison, we replace its original backbone with the same CNN architecture defined in Table 3 and adopt the same dataset configuration.
Experimental results analysis and discussion
Analysis of multi-sensor data-level fusion results
According to the approach described in Section “Multi-sensor data level fusion module,” the outliers with eccentricity in the top 10% are excluded. Figure 6 shows the raw vibration signal’s waveforms in the time domain, single sensor fusion signal and multi-sensor fusion signal of the gearbox synchronously monitored by six groups of vibration sensors during the gear pitting state at a load of 10 N m, a speed of 1000 rpm.

Time-domain graphs of multi-sensor data: (a) original data, (b) preprocessing data, and (c) multi-sensor fusion data.
As observed in the figure, after weighted fusion processing of single sensor data by applying a consistency check algorithm based on eccentricity, compared with the original data signal, the fused signal shows higher uniformity in amplitude distribution. This shows that through consistency preprocessing, random fluctuations in the signal are effectively removed, the impact of redundancy and outliers on the signal is significantly decreased, and the consistency of the data is markedly enhanced. Furthermore, through the multi-sensor data fusion technology rooted in minimum error, the monitoring results of multiple sensors are integrated, while effectively isolating non-fault related information such as noise, while successfully retaining the signal components closely related to the fault characteristics. This method not only enhances the reliability of the signal, but also more comprehensively captures the variations in the gear’s operational condition through multi-sensor data-level adaptive weighted fusion strategy, thereby providing more comprehensive data support for the health status assessment and fault diagnosis of the gearbox.
Diagnosis results analysis and discussion
The average accuracy and variance of five different random seeds for the approach introduced in this paper and the comparison method are shown in Table 4. The best-performing accuracy for each cross-domain scenario is highlighted in bold, with the second-best underscored. Overall, AMDFFDA achieves the highest average accuracy of 0.75, significantly outperforming CNN (0.37), DAN (0.45), DANN (0.44), and MFET (0.58), demonstrating its superior cross-domain diagnostic capability. As a baseline, CNN lacks both data preprocessing and domain adaptation mechanisms, resulting in consistently low performance. Although DAN introduces MK-MMD to reduce domain discrepancies, it struggles to capture discriminative features when multi-sensor data contains redundancy and noise. Similarly, DANN employs adversarial training to encourage domain-invariant features, but its simple global alignment mechanism is insufficient to handle the complex noise patterns in multi-sensor environments. MFET shows better performance with an average accuracy of 0.58, owing to its use of sensor fusion and transfer learning within a lightweight framework. However, it still falls short of AMDFFDA, indicating that while basic integration strategies offer generalization benefits, they are inadequate for addressing fine-grained category shifts and heterogeneous distribution noise. These comparisons underscore the necessity of more sophisticated fusion and alignment strategies in cross-domain fault diagnosis using multi-sensor data.
Performance statistics of different cross-domain fault diagnosis methods.

To facilitate a clearer comparison across different methods, Figure 7 presents the confusion matrices of all approaches on the B→C task. CNN, DAN, and DANN exhibit relatively high accuracy in identifying Gear pitting and Teeth crack, but their performance on other categories often below 50%. This reflects their limited ability to distinguish subtle fault patterns in the presence of redundant or noisy sensor signals, resulting in blurred class boundaries and poor generalization. The MFET method benefits from sensor fusion and lightweight transfer learning, showing improved results in classes like Miss teeth and Gear pitting. However, it still suffers from noticeable misclassification in Health and Gear wear, indicating its lack of fine-grained domain alignment and adaptive feature filtering. In contrast, the proposed AMDFFDA method achieves consistently high accuracy across all six classes, with each category exceeding 96%. This highlights its robustness in suppressing noise, preserving complementary fault information, and aligning domain features at both global and class levels—offering superior generalization in complex transfer scenarios.

Confusion matrix of the results of each model in task B→C.
Aiming to more clearly evaluate the performance of different approaches in terms of feature extraction capabilities, all test samples from the target domain are introduced to the feature extraction network, which then captures the output features from the final pooling layer. Subsequently, these high-dimensional features are mapped into a reduced-dimensional space via t-distributed stochastic neighbor embedding (t-SNE) technique. 21 for visualization analysis. Figure 8 presents the t-SNE visualizations of the target domain features for task B→C. As shown, CNN lacks domain adaptation and exhibits loose clusters with considerable overlap, especially between T-0 and T-4, indicating poor feature discriminability. DAN improves aggregation for some classes such as T-0 and T-4 due to MK-MMD-based global alignment, but still suffers from blurred class boundaries as it neglects category-conditional alignment. DANN achieves slightly better clustering, particularly for T-4 and T-5, yet overlaps remain in T-0 and T-3 due to its limited fine-grained alignment. MFET achieves improved clustering over earlier baselines, with clearer separation between T-4 and T-5, but T-0 and T-2 still exhibit noticeable overlap, suggesting that its sensor fusion and transfer learning integration is insufficient for fine-grained alignment. In contrast, AMDFFDA shows a high degree of intra-class aggregation even for T-0, T-3, and T-4 categories that are misclassified by other methods. The boundaries of each category are clear, there is no obvious overlapping area, and it presents the optimal feature distribution structure. The distribution of each category shows a clear hierarchical relationship, indicating that the model can better extract target domain features.

Feature visualization of the MCC5 dataset on the B→C task.
Ablation study
To demonstrate the impact of each part within our offered approach, this paper presents an ablation study conducted on the MCC5 dataset, defining the model variants as detailed below.
(1) AMDFFDA (w/o AMD): It eliminated the multi-sensor data fusion module and only used the original source and target domain data as the input of the model.
(2) AMDFFDA (w/o DAT): This method removed the domain adversarial module, inputs the data processed by multi-sensor fusion into the model, leveraged the teacher model to generate pseudo-labels for the target domain’s unmarked data.
(3) AMDFFDA (w/o Teacher): This method bypasses the class alignment module, instead utilizing the multi-sensor data fusion module to treat the data, and subsequently extracts domain-invariant features with the domain adversarial module.
Figure 9 presents the average classification accuracy across six cross-domain settings for each ablated variant. Notably, removing the AMD module causes the most severe degradation, with accuracy plunging to 19.38%—a drop of over 50%—which clearly underscores its foundational role. The AMD module not only suppresses noise and outliers via eccentricity-based preprocessing but also integrates complementary fault information to enhance feature completeness. By suppressing redundancy and preserving fault-relevant information, it improves the robustness of feature representations and strengthens the model’s adaptability to varying operating conditions, thereby indirectly supporting the effectiveness of the remaining modules. In contrast, removing the domain adversarial training (DAT) module leads to a moderate performance decline, revealing its significance in aligning global feature distributions between domains. Although adversarial learning helps enforce domain invariance, the relatively smaller impact of its removal suggests that the fused features and high-confidence pseudo-labels already retain substantial discriminative power for the target domain. Similarly, the exclusion of the category alignment module also degrades model performance. This is because DAT primarily reduces global domain shifts but does not guarantee intra-class alignment. The teacher model, through dynamic pseudo-labeling, provides soft supervision that refines category boundaries and avoids semantic overlaps in the feature space. The comparatively smaller performance drop implies that while fine-grained guidance enhances precision, its effectiveness depends on the representational quality established by AMD and DAT.

Comparison of ablation experiment accuracy.
Hyperparameter analysis
The proposed method encompasses several pivotal parameters that could substantially influence the model’s performance. These include the momentum parameter

Hyperparameter variation accuracy heatmap.
One of the key parameters is

Pseudo-label confidence sensitivity analysis.
Conclusions
This study presents a cross-domain gearbox fault diagnosis framework that integrates adaptive multi-sensor data-level fusion, domain adversarial training, and category-conditional alignment based on dynamic pseudo-labeling. Experimental results on the MCC5 dataset validate the framework’s effectiveness in mitigating noise sensitivity, preserving complementary fault information, and addressing fine-grained category shifts under unlabeled conditions. Despite its demonstrated performance, the approach remains limited by the assumption of fully labeled source domain data. Future work will explore semi-supervised strategies to extend its applicability to label-scarce industrial scenarios.
Footnotes
Handling Editor: Divyam Semwal
Author contributions
Yabin Shi: Resources, Validation, Investigation, Funding acquisition, Jian Zheng: Writing—original draft, Software, Validation. Gaige Chen: Conceptualization, Writing—original draft, Software, Methodology. Lin Li: Supervision, Project administration, Funding acquisition. Xiaozheng Jin: Supervision, Data curation. Zhongquan Li: Data analysis, Visualization, Writing—review & editing.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the Project of Key Industrial Chain Technical Research of Xi’an (23ZDCYJSG G0025-2023).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.