
Abstract
In practical industrial applications, the operating conditions of bearings frequently change, posing significant challenges for reliable fault diagnosis. Traditional machine learning methods, which rely on the assumption of independent and identically distributed samples, often experience a significant decline in diagnostic accuracy under such variable conditions. To address this issue, this paper proposes a bearing fault transfer diagnosis method that combines the Balanced Distribution Adaptation (BDA) algorithm with a Back Propagation neural network (BPNN) classification algorithm. Firstly, time-domain features of the bearing signals are extracted to comprehensively reflect the operational state of the bearings. Principal Component Analysis (PCA) is then utilized to reduce the dimensionality of the high-dimensional features, preserving the main information while reducing computational complexity. Subsequently, the BDA algorithm is employed to align the features of the source and target domains, balancing distribution differences and achieving effective feature space transfer. Finally, the BP neural network classification algorithm is used to classify the transferred features, thereby diagnosing bearing faults. Experimental results demonstrate that, compared to traditional fault diagnosis methods, the proposed approach achieves higher diagnostic accuracy and robustness under different working conditions. This method not only addresses the challenges posed by changing operating conditions but also holds significant practical value, providing a robust and efficient solution for real-world industrial applications such as predictive maintenance and condition monitoring in critical engineering systems.
Keywords
Introduction
Bearings, as critical components in mechanical equipment, directly influence the overall system’s operational state and lifespan. 1 Therefore, timely and effective bearing fault diagnosis is essential for preventing equipment failures, reducing downtime, and lowering maintenance costs. Traditional bearing fault diagnosis methods primarily rely on expert knowledge and experience. However, these methods often struggle to adapt to complex and variable working conditions. 2 With advancements in computational technology and data acquisition techniques, data-driven machine learning methods have been widely applied in bearing fault diagnosis, demonstrating excellent diagnostic performance.
Nevertheless, most traditional machine learning methods assume that the training and testing data are independently and identically distributed, which is often not the case in practical applications. 3 In real industrial environments, bearing operating conditions, such as load, speed, and ambient temperature, frequently change, leading to significant differences between the training and testing data distributions. This distribution discrepancy significantly degrades the diagnostic performance of traditional machine learning methods under varying conditions. 4 Thus, maintaining high diagnostic accuracy and efficiency under variable conditions has become a current research hotspot and challenge.
Additionally, a number of researchers have explored the combination of statistical signal processing with intelligent algorithms to mitigate the effects of non-stationary operating conditions. 5 Techniques such as wavelet transforms, 6 empirical mode decomposition, 7 and time-frequency analysis have been applied to extract robust features from vibration signals under diverse conditions. 8 These feature extraction methods, when paired with classifiers like support vector machines and neural networks, have demonstrated improved fault diagnosis performance. However, challenges related to data scarcity and model generalization under changing conditions still persist, indicating a clear research gap.
More recent research has focused on transfer learning 9 and domain adaptation as promising approaches to address the discrepancy between training and testing data distributions in variable industrial settings, including adaptive algorithms and shared feature space construction, have been developed to minimize the differences between source, and target domains. These innovative strategies enhance the robustness and accuracy of fault diagnosis systems, providing a comprehensive framework that addresses both the theoretical and practical challenges of bearing fault diagnosis in real-world applications.
Recent advancements in transfer learning have significantly impacted the field of bearing fault diagnosis. Traditional machine learning methods often struggle under varying industrial conditions due to the assumption of identical data distributions between training and testing datasets. In contrast, transfer learning techniques leverage labeled data from a source domain to enhance the performance of models in a target domain where data distributions may differ markedly. Researchers have explored various strategies such as Maximum Mean Discrepancy (MMD) 10 and adversarial domain adaptation networks (AAN) to align the feature spaces of disparate domains, thereby mitigating the adverse effects of domain shifts. Additionally, novel approaches incorporating adaptive weighting and balanced distribution adaptation have been developed to handle the imbalance between intra-class and inter-class distributions, further refining the discriminative power of the extracted features.
However, earlier methods like Transfer Component Analysis (TCA) 11 and Joint Distribution Adaptation (JDA) 12 exhibit certain limitations. TCA primarily focuses on aligning the marginal distributions of source and target data, often neglecting the conditional distributions, which can be critical for accurate fault diagnosis. JDA attempts to address this by aligning both marginal and conditional distributions, but it may struggle with balancing the trade-off between these two aspects, potentially compromising the diagnostic performance under highly variable conditions. However, the Balanced Distribution Adaptation (BDA) algorithm, which offers a more nuanced approach by adaptively weighting and balancing the distribution discrepancies, thereby achieving superior alignment and improved fault diagnosis outcomes.
This paper proposes a bearing fault transfer diagnosis method that combines the Balanced Distribution Adaptation (BDA) algorithm with the Backpropagation Neural Network (BPNN) classification algorithm. This method achieves bearing fault diagnosis through the following main steps: (1) Extracting rich time-domain features from bearing vibration signals to comprehensively reflect the bearing’s operational state. Time-domain features include metrics that describe the statistical properties of the signals, such as mean, variance, skewness, and kurtosis. (2) Using Principal Component Analysis (PCA) to reduce the dimensionality of the high-dimensional features. PCA linearly transforms the original high-dimensional features into a low-dimensional space, retaining the primary feature information while reducing data redundancy and computational complexity, thus enhancing feature processing efficiency. (3) Applying the Balanced Distribution Adaptation algorithm to align the features of the source and target domains. The BDA algorithm introduces an adaptive weighting strategy in the feature space to adjust the distribution of the source and target domain data, making them more consistent in the new feature space, thereby effectively reducing the discrepancy between the feature distributions of the source, and target domains. (4) Combining the Backpropagation Neural Network classification algorithm to classify the transferred features. The BP neural network adjusts weights through the backpropagation algorithm to minimize prediction errors, thereby improving classification accuracy and robustness. BP neural networks excel at handling complex nonlinear problems, making them suitable for bearing fault diagnosis tasks.
Materials and methods
Feature extraction
In vibration signal analysis, time-domain feature extraction is crucial. 13 The vibration signals generated during the operation of rotor systems contain rich fault information. By performing statistical analysis on the time-domain signals, various feature parameters can be extracted that reflect the overall trend, fluctuation level, and subtle changes of the signals, aiding in the diagnosis of different types of faults.14,15 Below are the commonly used time-domain features and their physical meanings, as shown in Table 1.
Expressions of different time-domain features.

In this study, MATLAB was employed to implement the feature extraction process. This section focuses on several selected time-domain indicators due to their effectiveness and low computational complexity. MATLAB enabled efficient processing of vibration data to compute features such as mean, RMS, standard deviation, skewness, kurtosis, and others, forming an initial high-dimensional feature set that captures the system’s fault characteristics.
The time-domain features of bearing vibration signals reveal key physical characteristics. The mean indicates the average level and DC component, while the RMS value quantifies signal energy, with higher values suggesting greater energy. Variance reflects the signal’s dispersion, and the peak value identifies maximum amplitudes, highlighting impact events. The crest factor (peak-to-RMS ratio) is particularly sensitive to impact faults. Skewness and kurtosis provide insights into the distribution’s symmetry and sharpness, respectively, with high kurtosis often indicating strong impacts. Additionally, the clearance, shape, and impulse factors describe the waveform’s morphology and the intensity of impact components. 16 Collectively, these features offer a comprehensive view of the vibration signal’s statistical properties, which is essential for effective rotor fault diagnosis.
Principal component analysis (PCA) dimensionality reduction algorithm
Principal Component Analysis (PCA) is a widely used unsupervised learning algorithm for dimensionality reduction and feature extraction. Its goal is to project high-dimensional data onto a lower-dimensional space through linear transformation while preserving as much of the data’s variance as possible. Specifically, PCA aims to identify the principal components of the data, which are the directions that explain the most variance in the data.17–19 These principal components are linear combinations of the original features, capturing the maximum variance information in the new coordinate system. The main steps of PCA are as follows:
(1) The original data is centered by subtracting the mean to eliminate the effect of data translation.
(2) Covariance matrix calculation: The covariance matrix of the data is computed. Suppose there is an N×D data matrix X, where N is the number of samples and D is the feature dimension. The formula for the covariance matrix is as follows:
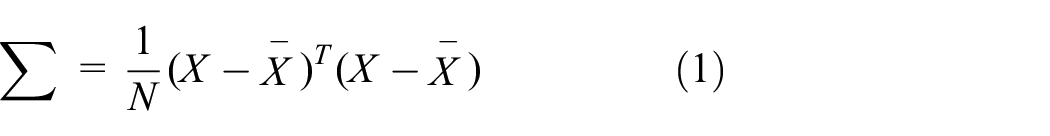
Where,
(3) Perform eigenvalue decomposition on the covariance matrix to obtain eigenvalues
(4) Based on the magnitude of the eigenvalues, select the top K eigenvectors to form the projection matrix W. Typically, the top K eigenvectors with the largest variances are chosen as principal components.
(5) Multiply the original data matrix X by the projection matrix W to obtain the reduced-dimensional data matrix Z. The projection is formulated as follows:

Given a dataset X, where each sample

Where,
Following the steps of PCA as described above effectively reduces feature dimensions, eliminates redundant information, and enhances the accuracy and reliability of fault feature extraction. This provides superior input features for subsequent machine learning models, thereby improving the performance of fault diagnosis.
Balanced distribution adaptation (BDA) algorithm
The Balanced Distribution Adaptation (BDA) algorithm is a transfer learning method designed to address the issue of disparate data distributions between source and target domains. 20 Its core idea involves introducing adaptive weighting strategies in the feature space to adjust the distributions of source and target domain data, thereby aligning them in the new feature space. 21
Algorithm steps
(1) Constructing Initial Classifier: Train an initial classifier on the source domain data. Typically, a linear classifier such as Support Vector Machine (SVM) or Logistic Regression is used. The classifier can be represented as
(2) Computing Weighting Matrix: Based on the distribution differences between the source and target domain data, compute a weighting matrix W to adjust the weights of the source and target domain data. The computation of the weighting matrix can utilize methods such as kernel density estimation to quantify the distribution disparities between the two domains. Assuming the source and target domain data are denoted as Xs and Xt, respectively, the computation of the weighting matrix can be expressed as:

Where,
(3) Optimization Objective Function: By minimizing the objective function, adjust the parameters of the classifier to minimize classification errors on the target domain. Typically, optimization algorithms such as gradient descent are used to optimize the objective function. The objective function for optimization can be represented as:
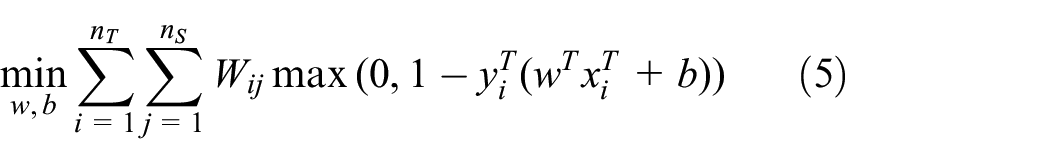
Where,
(4) Iterative Updating: Iteratively update the weighting matrix and classifier parameters until convergence criteria are met. During each iteration, based on the current weighting matrix and classifier parameters, recalculate the objective function and update the parameters accordingly.
Mathematical expression of the algorithm
Given the source domain dataset

Where L is the loss function, and
Back propagation neural network (BPNN)
The Back Propagation Neural Network (BPNN) is a commonly used artificial neural network model widely applied in fields such as pattern recognition, classification, and regression. BPNN adjusts the network weights and biases through the backpropagation algorithm to achieve effective mapping of input data.23,24 It typically consists of the following components:
(1) Input Layer: Receives the input data, with each node corresponding to an input feature.
(2) Hidden Layer: Positioned between the input and output layers, it can contain one or more hidden layers, each comprising several neurons. The number of hidden layers and neurons per layer are hyperparameters of the network that need to be adjusted based on the specific problem.
(3) Output Layer: Produces the output results, with the number of nodes corresponding to the output dimensions.
The network structure is illustrated in Figure 1.

Network architecture diagram of the BP neural network.
During the forward propagation process, input data sequentially passes through the input layer, hidden layers, and output layer. The weighted sum and bias for each neuron in every layer are calculated, and the output is obtained through an activation function.
The input and output calculations for the j-th neuron in the hidden layer are as follows:

Where,

The input and output calculations for the output layer are as follows:

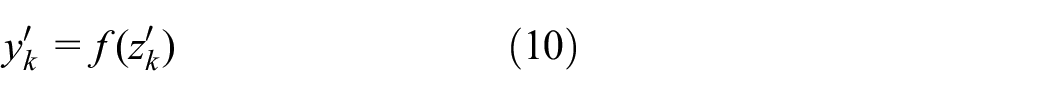
The BP neural network is a neural network model that adjusts network weights and biases using the backpropagation algorithm to minimize the error function E. During the forward propagation process, input data sequentially passes through the input layer, hidden layers, and output layer, computing the weighted sum and bias of each layer’s neurons, and obtaining outputs through activation functions. The BP neural network utilizes the Mean Squared Error (MSE) as the error function:

Where,
During the backpropagation process, the first step is to compute the error at the output layer.

Where,
Then compute the error at the hidden layer.

Finally, update the weights and biases using gradient descent.

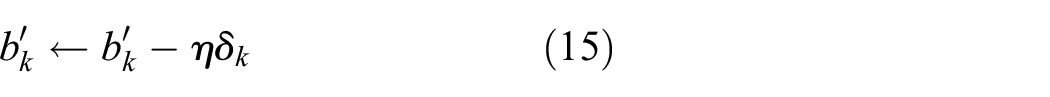
Where, η represents the learning rate. The commonly used activation functions include the Sigmoid function, Tanh function, and ReLU function, which introduce nonlinearity to enable the network to handle complex nonlinear problems.
BDA-BPNN for bearing fault feature transfer diagnosis
In order to validate the effectiveness of the BDA algorithm in bearing fault transfer diagnosis under variable operating conditions, this study designed cross-platform validation experiments. These experiments encompass two types, each representing different data sources and working environments, thus comprehensively assessing the applicability, and robustness of the BDA algorithm. Two distinct datasets were selected for experimentation: one sourced from publicly available bearing datasets abroad, and another collected from laboratory test rig bearing datasets. These datasets represent bearing operational data from diverse sources and characteristics, covering a range of operating conditions. Through these experiments, the diagnostic performance of the BDA algorithm across different operating conditions will be thoroughly evaluated, providing reliable reference for practical applications. Figure 2 The specific flowchart is as follows:

Process diagram for bearing fault feature transfer diagnosis using BDA-BPNN.
Experimental validation and analysis
Experimental design
To validate the effectiveness of the BDA algorithm in bearing fault transfer diagnosis under varying operating conditions, this study conducted experiments across different platforms and operating conditions to comprehensively assess the algorithm’s applicability and robustness. Two distinct datasets were utilized to ensure the algorithm’s effectiveness and robustness under various operational conditions. One dataset was sourced from the publicly available bearing data repository of Case Western Reserve University (CWRU), USA. This database includes bearing data collected under diverse operating conditions, meticulously designed and curated to cover various typical bearing fault types such as inner race faults, outer race faults, and rolling element faults. Each operational condition’s dataset comprises rich vibration signals, ensuring high representativeness and reliability. The experimental setup for this dataset is illustrated in Figure 3.

Case western reserve university bearing fault test rig.
The other dataset was obtained from a laboratory-built test rig designed to simulate real-world bearing operating environments. Data from the laboratory test rig encompass vibration signals collected under different loads, speeds, and environmental conditions. By precisely controlling experimental parameters, the laboratory test rig simulates multiple real-world conditions to capture bearing data under different states. The dataset includes vibration signals not only from normal operating conditions but also from fault conditions such as wear or damage to the inner race, outer race, and rolling elements. The experimental device of the laboratory test bench and the simulated fault signal diagram are shown in Figures 4 and 5 respectively.

Laboratory WS-ZHT1-2 type bearing fault test rig.

The simulated fault signal diagram. (a) Rotor vertical fault diagram. (b) Rotor misalignment fault diagram. (c) Rotor unbalance fault diagram. (d) Rotor horizontal deviation fault diagram.
Besides the operating conditions described in Table 2, the CWRU dataset also includes conditions with rotational speeds of 1797 and 1750 r/min, facilitating subsequent experimental research.
Parameter data of different bearing sample sets.

Dimensionality reduction of signal features
The collected vibration signal data were processed using MATLAB to extract corresponding time-domain features, as detailed in Table 1. These features include mean, root mean square (RMS), kurtosis, skewness, peak value, variance, peak-to-peak value, impulse factor, margin factor, and waveform factor, comprehensively reflecting the statistical properties and trends of the signals. Subsequently, Principal Component Analysis (PCA) was employed to perform dimensionality reduction on all extracted time-domain features.
First, the features were standardized to eliminate the influence of different dimensions and scales among them. The covariance matrix of the feature matrix was then calculated, and eigenvalue decomposition was performed to obtain eigenvalues and eigenvectors. The principal components with the highest cumulative explained variance were selected based on the magnitude of the eigenvalues. In this study, the top five principal components were chosen, and the original features were projected into this principal component space to obtain the reduced-dimensionality features. These features retained most of the information and trends from the original data, making them more effective for subsequent fault diagnosis analysis, thereby improving diagnostic accuracy, and reliability. The explained variance plot of the PCA-reduced features is shown in Figure 6.

Variance explained of principal components after PCA dimensionality reduction.
Figure 6 shows that after PCA dimensionality reduction, the cumulative contribution rate of the first five principal components exceeds 90%, adequately representing the primary trends, and information content of the original data. These reduced features retain the original information, significantly reduce data redundancy, and effectively distinguish between different fault states. PCA dimensionality reduction greatly reduces the data dimensions and computational complexity, improving model training and prediction efficiency, while enhancing the model’s stability, and generalization capability.
Cross-platform diagnostic verification and analysis
To validate the effectiveness of the proposed balanced domain adaptation (BDA) algorithm, a visual analysis of feature transfer was conducted, comparing the feature distribution before transfer and after transfer using TCA (Transfer Component Analysis), JDA (Joint Distribution Adaptation), and BDA algorithms. The visualization of feature transfer before and after is shown in Figure 6.
As seen in Figure 7(a), before feature transfer, the features of different states are mostly clustered together in the feature space, making it difficult to distinguish between different fault states, and affecting the accuracy of fault diagnosis. Figure 7(b) shows that after processing with the JDA algorithm, the feature distribution improves, but the features of the normal state and rolling element fault state are still mixed. The TCA algorithm further improves feature distribution by aligning the marginal and conditional distributions of the source and target domains, but the issue of confusion between the normal state and the rolling element fault state persists.

Visualization after different feature transfer algorithm. (a) Visualization before feature transfer. (b) Visualization after JDA feature transfer. (c) Visualization after TCA feature transfer. (d) Visualization after BDA feature transfer.
From Figure 7(d), it is evident that the feature distribution significantly improves after applying the proposed Balanced Distribution Adaptation (BDA) algorithm for feature transfer. By balancing the distribution between the source domain and the target domain, the BDA algorithm effectively optimizes the feature space, resulting in better separation of features under different conditions. After BDA processing, the features of normal and faulty states are clearly separated, without clustering together. This indicates that the BDA algorithm effectively adjusts the data distribution between the source and target domains during feature transfer, enhancing the accuracy and reliability of fault diagnosis. Compared to TCA and JDA algorithms, the BDA algorithm demonstrates stronger generalization ability and robustness in fault diagnosis tasks under complex conditions.
The diagnostic accuracy of various models at different rotational speeds is shown in Table 3. The results indicate that BDA outperforms other transfer learning algorithms in optimizing distribution adaptation, achieving an average diagnostic accuracy of 96%. In contrast, the diagnostic accuracy using the TCA method is about 78%, showing some improvement but still not ideal. The diagnostic accuracy of the JDA method ranges from 82% to 86%. Although it shows significant improvement over TCA, it still falls short of the performance achieved by the BDA algorithm.
Diagnostic accuracy of different models under varying rotational speeds (%).

In Table 3, the bolded numbers represent the highest accuracy values for each method under the corresponding conditions.
In order to verify the validity of the proposed model, several common diagnostic models such as support vector machine (SVM), K-nearest neighbor algorithm (KNN), decision tree (DT) and radial basis neural network (RBF) are compared, and the results are as follows: The result is shown in Figure 8.

Diagnostic accuracy of different models under feature transfer.
Under the three different working conditions (1750, 1772, and 1797 r/min transferred to 800 r/min), the BDA-BPNN demonstrated exceptional performance. Its accuracy remained above 90% across all conditions, showing strong generalization capabilities, particularly excelling under Working Condition 2 (1772 r/min→800 r/min) where the accuracy reached nearly 100%. This result indicates that BDA-BPNN adapts well to transitions between different high-speed conditions and the low-speed laboratory condition, exhibiting excellent stability and robustness in handling varying working speeds.
Compared to other algorithms like BDA-SVM and BDA-KNN, BDA-BPNN performed significantly better, especially under Working Condition 2, where the performance of other algorithms noticeably declined, while BDA-BPNN maintained nearly perfect accuracy. Its performance was also stable in Working Conditions 1 and 3, effectively handling challenges across different conditions. This demonstrates that BDA-BPNN not only has strong learning abilities in cross-condition transfer learning but also excellent adaptability, making it a highly effective model choice for application under multiple working conditions.
Results
This paper proposes a bearing fault diagnosis method based on the BDA-WKNN approach, and the effectiveness of the proposed method is verified through experiments. The main conclusions are as follows:
(1) To tackle the challenge of uneven sample distribution and varying feature differences caused by different operating conditions and rotational speeds, the Balanced Distribution Adaptation (BDA) algorithm is employed. BDA adaptively aligns the feature distributions between the training and testing data, ensuring that fault-relevant information is consistently captured despite domain discrepancies. Experimental results indicate that this adaptive adjustment effectively reduces misclassification arising from distribution shifts.
(2) To further improve diagnostic accuracy, the method integrates the Weighted K-Nearest Neighbors (WKNN) classifier, which assigns higher weights to samples closer to the query point. This weighted approach enhances the influence of more relevant neighboring samples, thereby boosting the overall decision-making process and classification performance, especially under noisy, or variable conditions. Comparative experiments show that WKNN outperforms traditional KNN, particularly in scenarios with imbalanced or challenging data distributions.
(3) By combining the strengths of BDA and WKNN, the proposed method effectively overcomes the challenges associated with uneven sample distribution and feature variations across different operating conditions. The integrated approach significantly enhances the accuracy and reliability of fault diagnosis, with experimental results demonstrating excellent diagnostic performance under various rotational speeds and operational environments.
This method not only proves its superior performance over other techniques but also exhibits high practical value, indicating its potential for widespread application in real-world industrial settings.
The results of this study clearly demonstrate the effectiveness of the proposed BDA-WKNN method in bearing fault diagnosis, showcasing significant improvements in diagnostic accuracy across varying rotational speeds and operating conditions. While the results are promising, they also highlight areas for future research. One direction could involve optimizing the computational efficiency of the BDA-WKNN method to ensure its applicability in real-time fault diagnosis systems. Additionally, expanding the validation of the BDA-WKNN method to other types of machinery and fault conditions would pro-vide a broader understanding of its generalizability. Future studies could explore its performance across different industries and investigate how it performs when inte-grated with other diagnostic technologies, such as IoT-based monitoring systems. An-other potential research avenue could involve exploring the integration of BDA-WKNN with other advanced machine learning techniques, such as deep learning models, to further enhance its diagnostic capabilities.
Footnotes
Handling Editor: Divyam Semwal
Ethical considerations
The studies not involving humans or animals.
Author contributions
Conceptualization, Lulu Wang and Chunyi Zhang; methodology, Lulu Wang; software, Lulu Wang; validation, Lulu Wang, Chunyi Zhang, Yongqi Li; formal analysis, Lulu Wang, Yongqi Li; resources, Chunyi Zhang; data curation, Lulu Wang; writing—original draft preparation, Lulu Wang; writing—review and editing, Chunyi Zhang, Yongqi Li; supervision, Chunyi Zhang; project administration, Chunyi Zhang. All authors have read and agreed to the published version of the manuscript.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by Guangdong province key construction discipline scientific research ability promotion project, grant number 2022ZDJS149.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The data that support the findings of this study are available from the author, [Lulu Wang], upon reasonable request.