
Abstract
This paper proposes a novel approach for identifying defective casting products using a custom convolutional neural network architecture named Hierarchical Defect Recognition Architecture (HiDraNet). The HiDraNet model is designed to classify submersible pump impeller casting products into Normal and Defective categories by learning and extracting hierarchical features from a comprehensive dataset of 7348 casting product images, which includes various defect types such as fins, porosity, surface imperfections, and multiple defects. Experimental results demonstrate the superior performance of the HiDraNet model compared to several well-known deep learning models, such as AlexNet, MobileNetv2, ResNet18, GoogLeNet, ShuffleNet, and SqueezeNet, achieving the highest classification accuracy of 99.8% while exhibiting faster computation times. The proposed approach has significant implications for the manufacturing industry, as it can reduce the reliance on manual inspection methods, improve overall product quality, and minimize production costs, contributing to the broader adoption of Industry 4.0 technologies in the manufacturing sector.
Introduction
In modern manufacturing industries, ensuring high product quality while minimizing production costs is a critical challenge. 1 Casting, a vital process in shaping various products, plays a significant role in determining the quality and performance of the final product. However, casting defects such as cracks, pores, and rough surfaces can occur during the manufacturing process, leading to suboptimal product quality, increased production costs, and potential damage to the manufacturer’s reputation.2–4
Correctively detecting and rejecting defective castings are essential to ensure product quality and minimize waste. Traditional manual inspection methods are time-consuming, prone to human error, and often fail to detect subtle defects. As a result, there is a growing interest in applying machine learning techniques, particularly convolutional neural networks (CNNs), to automate the quality inspection process for casting products.5,6
Recent advancements in machine learning, particularly in the field of deep learning and CNNs, have shown great potential for automating visual inspection tasks.7,8 CNNs have demonstrated remarkable performance in image classification, object detection, and defect-recognition across various domains, including manufacturing. 9 By leveraging the power of CNNs, manufacturers can develop efficient and accurate systems for detecting and classifying defects in casting products, thereby improving quality control and reducing costs. 10
This paper proposes a novel approach for identifying defective casting products using a custom CNN architecture named Hierarchical Defect Recognition Architecture (HiDraNet). This research focuses on developing an efficient and accurate HiDraNet model that can classify casting products (submersible pump impeller) into Normal and Defective categories. Automating the quality inspection process aims to reduce manual inspection methods’ time, cost, and errors.
The proposed HiDraNet architecture is designed to effectively learn and extract hierarchical features from casting product images, enabling accurate defect detection and classification. The model is trained and evaluated using a comprehensive dataset of casting product images, including various types of defects such as cracks, pores, and rough surfaces. The performance of the HiDraNet model is compared with several well-known CNN architectures to demonstrate its effectiveness and superiority.
The main contributions of this research are as follows:
• Develop a novel HiDraNet architecture designed explicitly for defect detection in casting products;
• Comprehensively evaluate the HiDraNet model using a large dataset of casting product images, comparing its performance with well-known CNN architectures;
• Demonstrate the effectiveness of the proposed approach in automating quality inspection and reducing the reliance on manual inspection methods.
Critical analysis of relevant research
The casting process, a fundamental pillar of the manufacturing industry, involves pouring molten metal into molds to create desired shapes. However, casting defects can arise during this process, leading to subpar product quality and increased production costs. Traditional methods for detecting these defects, such as manual inspection, are often time-consuming, prone to human error, and inefficient. In recent years, computer vision techniques, particularly CNN models, have emerged as promising solutions for automating defect detection in various industrial settings. This section reviews relevant research that explores the use of CNNs for casting defect detection, highlighting key approaches, advancements, and existing limitations.
The article 11 investigated the use of CNNs for intelligent surface defect detection in submersible pump impellers, aiming to automate the quality inspection process and overcome the limitations of manual inspection. The study utilized the real dataset of 7348 grayscale images, categorized into four defect types: ideal, extra projection, shrinkage, and multiple defects. Data augmentation techniques were employed to expand the dataset to 12,000 images, mitigating potential overfitting. Three CNN architectures were evaluated: MobileNetv2, ResNet18, and a general model. The architectures were assessed using metrics such as precision, recall, and F1-Score.
The study found that the MobileNetv2 architecture achieved the highest test accuracy of 98.17%, outperforming ResNet18 (97.58%) and the general model (93.58%). This superior performance was attributed to MobileNetv2’s better learning capability. Additionally, the authors developed a graphical user interface (GUI) to assist workers in identifying defects and proposed remedial measures for the identified defects.
However, the study acknowledged several limitations. The misclassification of “extra projection” defects was attributed to the limited number of corresponding images in the original dataset, highlighting the importance of balanced and diverse datasets for training CNN models. The general model’s lower performance was attributed to its fewer layers, suggesting that more complex architectures might be necessary for achieving higher accuracy in defect detection. Furthermore, the study did not delve into real-time implementation, leaving a gap for future research to explore the integration of the system into a live production environment. Additionally, the study only considered four defect types, limiting its applicability to a wider range of industrial scenarios.
The article 12 investigated the use of deep learning for casting defect analysis in the manufacturing industry, aiming to improve product quality, reduce costs, and enhance customer satisfaction. The authors proposed an ensemble model combining a transfer learning ResNet50 model and a custom CNN model. They utilized the Kaggle dataset, consisting of 7348 images of casting products categorized as defective or non-defective. The ensemble model was trained and evaluated using various hyperparameters, including optimizers, batch sizes, and epochs.
The proposed ensemble model outperformed the individual models, achieving a precision of 99.89% and an accuracy of 98.18% with the optimal hyperparameters. This demonstrated the effectiveness of the ensemble approach in improving defect detection accuracy.
The study admitted several shortcomings. The model focused on classifying casting products as either defective or non-defective, without differentiating between specific types of defects. The study relied on simulations and analysis of the dataset, but it did not include real-world validation of the model in an actual manufacturing environment. Additionally, the article did not discuss the computational cost of the model, which is a crucial factor in real-world applications.
The article 13 focused on optimizing Deep Neural Network (DNN) execution in edge-AI enabled smart manufacturing environments. Their study addressed the challenge of performing compute-intensive DNN tasks with minimal latency. The researchers developed a novel Task Aware DNN Splitting (TADS) scheme, which aimed to reduce average task execution time by leveraging collaborative computing between Edge Computing Nodes (ECNs) and Edge Servers (ESs).
The DNN splitting policy was determined using the suggested TADS technique by considering multiple aspects such as communication bandwidth, available computational resources, and task characteristics. Three iterative stages comprised the algorithm’s operation: updating the policy pool, selecting candidate policies, and selecting the best policies. The authors used hardware-based tests, three separate DNN models, and a realistic use case for product quality inspection to validate their methodology.
The study’s findings showed that, regarding average task implementation time, TADS performed better than several other DNN splitting techniques, including Greedy-based, DNN-off, ES-only, and ECN-only schemes. The researchers demonstrated that TADS’s effectiveness stemmed from its ability to adaptively select DNN splitting policies based on dynamic factors like task volume, inter-arrival time (IAT), and network conditions. For instance, TADS scheme achieved an average task execution time reduction of 21%–70% compared to ECN-only, 58%–95% compared to ES-only, and 13%–32% compared to Greedy-based schemes under various bandwidth scenarios. Similarly, under various task IATs, the TADS scheme achieved an average task execution time reduction of 22%–73% compared to ECN-only, 65%–95% compared to ES-only, and 16%–40% compared to Greedy-based schemes.
The study carried some restrictions. The research focused on a single application (product quality inspection) and a single ECN-ES collaborative scenario. Further research is needed to explore the TADS scheme’s effectiveness in multi-application and multi-ECN/multi-ES scenarios. Additionally, the TADS scheme primarily focused on minimizing task execution time, neglecting energy consumption as a decision factor. Future research could incorporate energy consumption into the scheme in order to strike a balance between energy efficiency and delay. The study did not extensively address the challenges of mobility in smart manufacturing environments, where ECNs (such as mobile robots) might experience intermittent network connections. Further research is needed to integrate mobility prediction schemes into the TADS scheme to mitigate these challenges.
The article 14 aimed to develop a neural network model capable of recognizing and classifying casting defects in submersible pump impellers. The aim of the authors’ use of CNNs was to enhance the labor-intensive and prone to human-error traditional manual inspection methods. A set of 7348 photos of pump impellers that were divided into two groups, defective and non-defective, were used in the study. A two-layered CNN model was employed, incorporating Conv2d and Maxpooling2d layers with a ReLU activation function. The model was trained on the dataset and then used to classify new images.
The model achieved a 94% accuracy rate in identifying the presence of defects and a 68% accuracy rate in classifying the defect type (fins or heat cracks). This demonstrated the potential of CNNs for automating casting defect detection and classification, potentially improving efficiency and reducing errors in manufacturing processes. However, the study noted some limitations. The study only focused on recognizing two types of defects (fins and heat cracks). Expanding the model to recognize a wider range of casting defects would be necessary for more comprehensive industrial applications. While the study used a sizable dataset (7348 images), it is unclear if the dataset was sufficiently diverse and representative of the full range of casting defects encountered in real-world industrial settings. The computing cost of the model, an important consideration in practical implementations, was not included in the paper. The study also depended on dataset analysis and simulations, but it omitted real-world validation of the model in a manufacturing setting. This makes it harder to comprehend how well the model works in actual situations and what obstacles it might face.
The article 15 aimed to develop a system for automating visual inspection of mechanical components using visual imaging and machine learning. The authors specifically focused on identifying surface defects in submersible pump impellers, aiming to improve product quality, reduce production costs, and increase efficiency by minimizing human intervention. The study utilized a dataset of images of both defective and non-defective pump impellers. The model was trained using a CNN architecture, which is commonly used for image recognition tasks. The Grad-CAM algorithm was employed to identify the regions of error in the images, providing a visual explanation of the model’s predictions.
The model achieved a high accuracy rate in identifying defective parts and highlighting the location of defects. This demonstrated the potential of using machine learning for automated visual inspection in manufacturing settings, potentially leading to faster and more accurate quality control. Some shortcomings were mentioned in the study. The study only focused on identifying defects in submersible pump impellers, limiting its applicability to other types of mechanical components. The study did not provide details about the size and diversity of the dataset used for training. A larger and more diverse dataset would likely improve the model’s accuracy and generalizability. A critical component in practical implementations, the model’s computational cost was not addressed in the paper. Apart from relying on simulations and dataset analysis, the study omitted real-world validation of the model in a manufacturing setting. This reduces our comprehension of the model’s functionality and any drawbacks in real-world scenarios.
The article 16 aimed to develop a machine vision model for inspecting problematic products during manufacture. Their goal was to combine defect identification with process improvement by predicting optimal production parameters to minimize defects. The study focused on integrating various Industry 4.0 technologies, including IoT, cloud computing, edge computing, big data analytics, and machine learning. The proposed model employed a combination of technologies: IoT sensors and cameras for data collection, cloud computing for model training and data storage, edge computing for real-time image processing and defect classification, and machine learning algorithms (CNNs and decision trees) for image classification and process prediction, respectively. The study evaluated different pre-trained CNN models (VGG16, Inception v3, EfficientNetB0) and a simple CNN for image classification. Inception v3 achieved the highest accuracy (95%) within a reasonable training time. The authors also compared various regression algorithms (Lasso Regression, Linear Regression, K-NN, Decision Trees) for predicting process variables. Decision trees outperformed other models with a high R2 score (0.99).
The article 17 proposed a novel adversarial training strategy that employed historical gradients and domain adaptation to enhance the robustness of deep learning-based soft sensors, but it exhibited several limitations that needed to be addressed. The evaluation was confined to a single industrial case study involving silicon single-crystal growth, which limited the generalizability of the approach to other processes and larger datasets. The experimental validation did not include comparisons with more advanced adversarial defense strategies, such as Transformer-based models, and the sensitivity of key hyperparameters was not thoroughly analyzed, leaving questions about the computational overhead and scalability of the method. Moreover, the article relied on fixed parameter settings and did not provide a comprehensive discussion on the potential overfitting issues that might arise under different conditions, thereby raising concerns about the reproducibility, practicality, and overall robustness of the proposed approach in real-world applications.
The article 18 addressed an important research problem and proposed an innovative solution; however, it exhibited several notable limitations that needed to be resolved. The experimental evaluation was conducted on a limited dataset and within a narrowly defined scenario, which raised concerns about the generalizability and scalability of the proposed approach to broader applications.
The article 19 proposed an innovative approach to address weld defect detection, and although it demonstrated promising results under controlled experimental conditions, it exhibited several significant limitations that needed to be resolved.
While the study highlighted the potential of the proposed system, it also acknowledged several limitations. CNN models require significant computational resources and large training datasets, which can be a barrier to implementation in resource-constrained environments. The study relied on publicly available datasets, which may not fully represent the complexity and variability of real-world industrial data. The model was tested on specific datasets related to casting defects and mining processes, requiring further research to assess its generalizability to other manufacturing processes and product types. The paper did not provide a detailed analysis of the system’s latency and response time in a real-world production setting, nor did it explicitly address the cost implications of implementing the proposed system.
While previous studies have demonstrated the potential of CNNs for casting defect detection, they often face limitations in terms of accuracy, computational efficiency, and model complexity. Many studies focused on identifying the presence of defects rather than classifying specific defect types, and they often relied on simulations without real-world validation. To address these limitations, this research proposes a novel CNN architecture designed to achieve higher accuracy, faster computation speed, and a smaller number of trainable parameters, ultimately leading to reduced training time. The proposed methodology and its implementation are detailed in the following section.
The proposed methodology
Images of cast products
In this study, we utilize a diverse dataset consisting of 7348 images of submersible pump impeller castings to develop a deep learning model for automatically classifying products into two categories: Defective and Normal. 20 All images have a resolution of 300×300 pixels.
Casting is a crucial manufacturing method in various industries, but the process often encounters defects such as fins, porosity, shrinkage, and imperfections related to mold materials, pouring, and metallurgy. These defects can lead to substandard products and cause significant losses for manufacturers.
Quality inspection of cast products primarily relies on manual methods, which are time-consuming, labor-intensive, and prone to human error. Developing an automated inspection system based on deep learning will improve efficiency and accuracy, thereby minimizing defective product rates and limiting potential business losses.
The dataset is divided into two subsets to train and evaluate the model: a training set with 3758 Defective images and 2875 Normal images and a test set with 453 Defective images and 262 Normal images. The dataset 20 is released under the CC BY-NC-ND 4.0 license, allowing non-commercial use without permission.
Figure 1 illustrates five types of casting products, including a normal product and four types of defective products, as listed below.
• Fin defect: Excess material protruding from the product edge. This is a common defect in the casting process, which can be caused by improper mold design, high casting temperature, or excessive casting pressure.
• Porosity defect: Small holes on the product surface. The causes may include gas absorption during the casting process, evaporation of grease or gas-forming substances, or uneven shrinkage during cooling.
• Surface defect: Various surface imperfections like ridges and scratches. These defects can be due to poor mold quality, inappropriate casting temperature, or incorrect post-casting surface treatment.
• Multiple defect: A combination of two or more defect types. This indicates that the casting process is experiencing multiple issues and needs to be controlled and optimized.
• Normal product: This casting product meets the standards and has no apparent defects.

Illustration of casting product types: Normal product, fin defect, porosity defect, surface defect, and multiple defects.
Our research aims to develop a CNN model that can automatically classify casting products into two groups: Normal (non-defective) and Defective, based on the input images. The accurate classification of specific defect types (fin, porosity, surface, multiple defects) will be a future development direction to provide more detailed information about product quality and support the quality control process.
Hierarchical defect recognition architecture: HiDraNet
Figure 2 illustrates the architecture of the proposed CNN model, named HiDraNet, for classifying casting products into two categories: Normal (non-defective) and Defective. The architecture consists of two main branches: a multi-scale feature extraction branch and a classification branch.
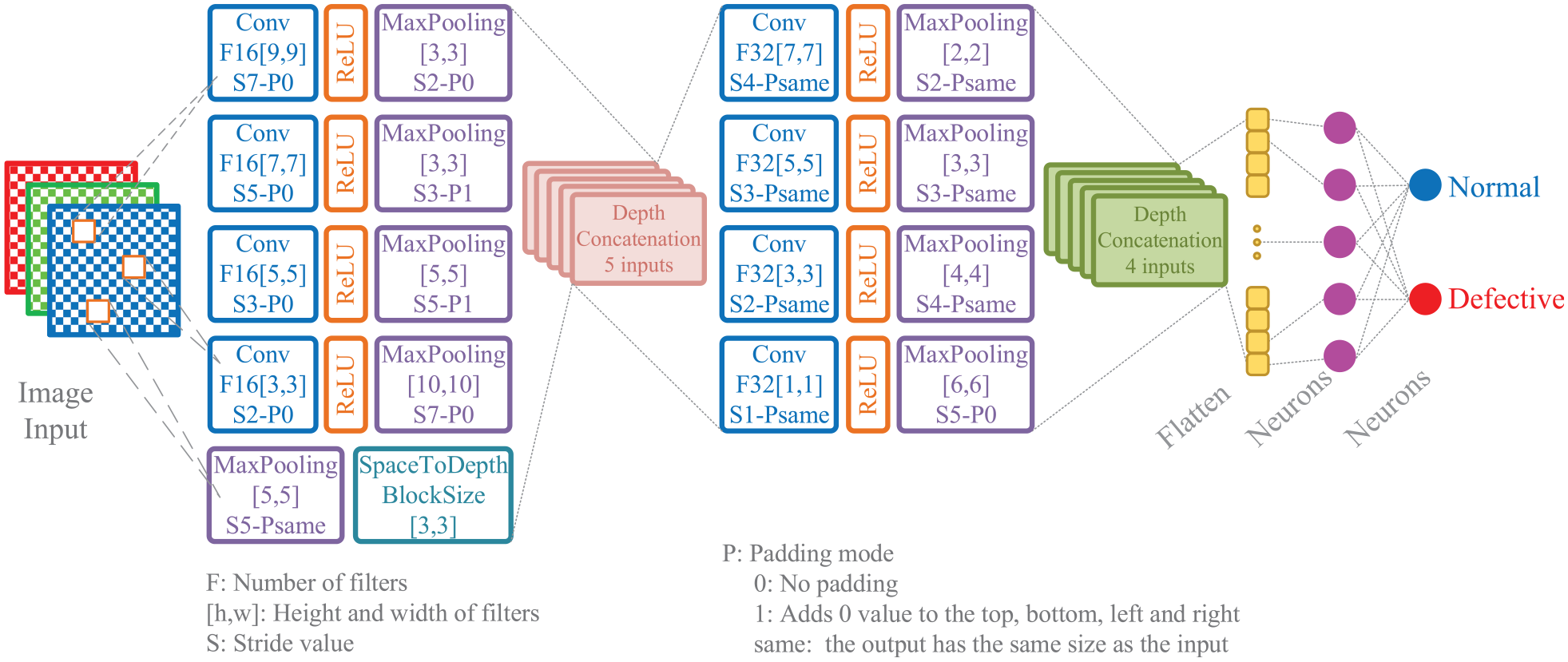
HiDraNet: Hierarchical defect recognition architecture for cast product classification.
The multi-scale feature extraction branch comprises four blocks sequentially using filters of sizes 9×9, 7×7, 5×5, and 3×3, with 16 filters each. Each convolutional layer (Conv) is followed by a ReLU layer and a Max Pooling layer with decreasing window sizes and increasing stride values. This helps to extract features at different spatial scales. The outputs from these four blocks, along with the input image, are concatenated along the depth dimension using a Depth Concatenation layer.
Besides, a SpaceToDepth layer with a block size of 3×3 is used to reduce the spatial dimensions and increase the number of channels. The result is passed through the classification branch, consisting of four convolutional blocks with increasing filters (32) and decreasing filter sizes (7×7, 5×5, 3×3, 1×1). Each convolutional layer is followed by a ReLU layer and a Max Pooling layer with increasing stride values. Finally, the outputs from these four blocks are concatenated along the depth dimension and used to classify the product into two classes: Normal and Defective.
This architecture combines the following key ideas:
• Multi-scale feature extraction: Using filters of different sizes and Max Pooling layers with different strides helps to extract features at multiple scales, from local details to global contextual information.
• Contextual information integration: Concatenating the outputs from the feature extraction branches and the input image helps to integrate contextual information from different scales, improving the feature representation.
• Spatial dimension reduction and depth increase: The SpaceToDepth layer reduces the spatial dimensions and increases the number of channels, helping to reduce the number of parameters and enhance the model’s representational capacity.
• Efficient classification: The classification branch with an increasing number of filters and decreasing filter sizes helps to extract discriminative features and perform efficient classification.
The HiDraNet architecture is designed to effectively leverage multi-scale and contextual information to improve the accuracy of detecting defects in casting products while ensuring computational efficiency for real-world applications.
The model evaluation metrics
Comparative analysis of deep learning models
In this study, we evaluate the performance of several well-known CNN architectures, including AlexNet, GoogLeNet, MobileNetv2, ResNet18, ShuffleNet, and SqueezeNet, alongside our proposed HiDraNet model. Each of these architectures has its unique characteristics and has been widely used in various computer vision tasks.
• AlexNet 21 : a groundbreaking convolutional neural network that revolutionized the field of computer vision. AlexNet achieved remarkable results in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2012, demonstrating the potential of deep learning for image classification. Its architecture, featuring multiple convolutional layers, pooling layers, and fully connected layers, paved the way for the development of more sophisticated deep learning models. AlexNet’s success marked a significant milestone in the history of computer vision and sparked a wave of research in deep learning for image recognition.
• GoogLeNet 22 : a deep and wide convolutional neural network architecture that introduced the concept of Inception modules. GoogLeNet won the ILSVRC 2014 competition, showcasing its ability to learn complex features and achieve high accuracy in image classification tasks. The Inception modules allow for parallel processing of different feature scales, resulting in a more efficient and effective network. GoogLeNet’s architecture has significantly influenced the design of subsequent deep learning models, paving the way for more powerful and efficient image classification systems.
• MobileNetv2 23 : a highly efficient convolutional neural network architecture designed specifically for mobile and resource-constrained environments. MobileNetv2 builds upon the success of its predecessor, MobileNetv1, introducing key improvements such as inverted residual blocks, linear bottlenecks, and the removal of ReLU activations at the beginning of inverted residual blocks. These innovations significantly enhance its performance, achieving state-of-the-art accuracy while requiring minimal computational resources. MobileNetv2 has proven to be a powerful tool for various mobile applications, including image recognition, object detection, and machine translation.
• ResNet18 24 : a deep convolutional neural network architecture that utilizes residual connections to improve training efficiency and accuracy. ResNet18 is a relatively compact version of the ResNet family, achieving impressive performance in image classification tasks while maintaining computational efficiency. This makes it suitable for various applications where resource constraints are a concern.
• ShuffleNet 25 : a lightweight and efficient convolutional neural network architecture designed for mobile devices with limited computational resources. ShuffleNet introduces a novel group convolution operation and channel shuffling mechanism to reduce computational complexity and improve efficiency. It achieves comparable accuracy to other state-of-the-art models while requiring significantly fewer parameters and operations. This makes ShuffleNet particularly suitable for resource-constrained environments, such as mobile applications and embedded systems.
• SqueezeNet 26 : a compact and efficient neural network architecture designed for image classification tasks. SqueezeNet achieves comparable accuracy to AlexNet while requiring significantly fewer parameters, making it suitable for resource-constrained environments. It employs a unique “squeeze-and-excitation” strategy, which reduces the number of feature maps in the network while preserving essential information. This approach allows SqueezeNet to maintain high accuracy with a significantly smaller model size, making it ideal for deployment on devices with limited memory and processing power.
Evaluation metrics for defective submersible pump impeller castings classification
To assess the performance of the proposed HiDraNet model and compare it with other well-known CNN architectures, we employ several standard evaluation metrics commonly used in binary classification problems. These metrics include accuracy, precision, recall, and F1-Score.
Accuracy is the ratio of correctly predicted instances to the total number of instances, as described in equation (1). It provides an overall measure of how well the model performs in classifying both Defective and Normal products. However, more than an accuracy metric is required when dealing with imbalanced datasets, 27 as it can be biased toward the majority class.

where:
•
•
•
•
In our context, precision measures the proportion of products correctly identified as Defective among all the products predicted as Defective by the model. A high precision indicates that the model has a low false positive rate, as described in equation (2).

In our study, recall represents the proportion of Defective products that are correctly identified by the model among all the actual Defective products. A high recall suggests that the model has a low false negative rate, as described in equation (3).

F1-Score is the harmonic mean of precision and recall, providing a balanced measure of the model’s performance, as described in equation (4). It is particularly useful when dealing with imbalanced datasets, as it considers both false positives and false negatives. A high F1-score indicates that the model achieves a good balance between precision and recall.
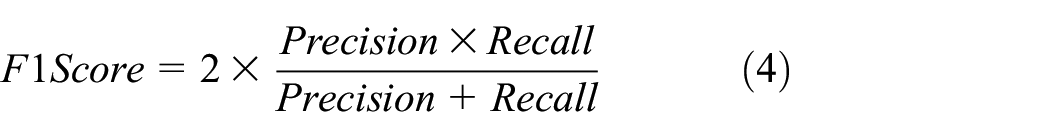
These evaluation metrics are crucial in assessing the effectiveness of the proposed HiDraNet model and comparing it with other CNN architectures. By considering these metrics together, we can gain a comprehensive understanding of the model’s performance in accurately identifying Defective and Normal casting products. This is particularly important in the context of quality control in manufacturing, where minimizing both false positives (which can lead to unnecessary product rejections) and false negatives (which can result in defective products being accepted) is essential to maintain high product quality and reduce production costs.
Other parameters and setting
We used a consistent set of hyperparameters and training options to train all the models (AlexNet, GoogLeNet, MobileNetv2, ResNet18, ShuffleNet, and SqueezeNet) for the comparative analysis. The models were trained using the Adam optimizer, 28 which is an adaptive learning rate optimization algorithm designed to handle sparse gradients and noisy problems effectively. We set the initial learning rate to 0.0005, allowing the models to learn at a relatively low pace and gradually converge to optimal solutions, as described in Table 1.
Training hyperparameters and system specifications.

The maximum number of training epochs was set to 10, providing sufficient iterations for the models to learn meaningful features from the dataset. We utilized the GPU execution environment to accelerate the training process and leverage the parallel processing capabilities of graphics processing units. The mini-batch size was set to 50, enabling the models to process a subset of the training data in each iteration, which helps in efficient memory utilization and faster convergence.
Furthermore, we implemented the “Shuffle” option set to “every-epoch,” which randomly shuffles the training data at the beginning of each epoch. This technique helps prevent the models from learning the order of the samples and generalizes better to new data.
We specified the “OutputNetwork” option as “best-validation-loss,” which saves the model with the lowest validation loss during training. This ensures that we obtain the best-performing model based on its ability to minimize the loss function on the validation dataset. By using consistent training options and hyperparameters across all models, we ensure a fair comparison of their performance and maintain the integrity of our comparative analysis.
It is important to note that while all models in our comparative analysis (AlexNet, GoogLeNet, MobileNetv2, ResNet18, ShuffleNet, and SqueezeNet) were trained using transfer learning, our proposed HiDraNet model was trained from scratch. Transfer learning allows us to leverage pre-trained weights from models that have been trained on large-scale datasets, such as ImageNet, and fine-tune them for our specific task. This approach enables faster convergence and better generalization, especially when working with limited training data.
However, since HiDraNet is a novel architecture designed specifically for defect detection in casting products, we trained it from scratch to ensure that it learns features tailored to our dataset. As a result, HiDraNet required a higher number of training epochs to converge and achieve optimal performance. While the other models were trained for 10 epochs, HiDraNet was trained for 30 epochs to compensate for the lack of pre-trained weights and allow sufficient time for the model to learn discriminative features from the dataset.
Our experiments were conducted using MATLAB 2024a to evaluate the performance of the proposed model. The experiments were repeated 10 times independently to ensure statistical significance, and the Wilcoxon rank sum test was employed to compare the performance of the proposed model with that of other selected methods. 29
In the following section, we present the results of our comparative analysis, discussing the performance of each CNN architecture in terms of the evaluation metrics and their implications for the task of automated defect detection in casting products.
Results and discussion
Table 2 compares the accuracy of the proposed HiDraNet model with various CNN architectures. HiDraNet achieves the highest performance with an average accuracy of 99.818%, significantly outperforming other models. Statistical testing reveals that the differences in accuracy between HiDraNet and most other models are statistically significant, with
Model accuracy comparison and statistical analysis.

Table 3 presents more detailed performance metrics for the models, including precision, recall, and F1-Score. HiDraNet attains the highest values in all three metrics with low standard deviations, demonstrating the model’s stability and consistency in performance.
Model performance metrics comparison: precision, recall, and F1-Score.

To gain a deeper understanding of HiDraNet’s performance and visually compare it with other models, the following figures present detailed analyses.
Figure 3 compares the performance of investigated deep learning architectures in the casting product classification task, including HiDraNet (the proposed model), AlexNet, GoogLeNet, MobileNetv2, ResNet18, ShuffleNet, and SqueezeNet. The performance is evaluated based on two criteria: mean accuracy and calculation time.

Comparison of deep learning architectures: accuracy versus computation time.
In terms of accuracy, all models achieve good results, ranging from 96.252% (AlexNet) to 99.818% (HiDraNet). The proposed HiDraNet model achieves the highest accuracy, outperforming other architectures. The GoogLeNet, MobileNetv2, ResNet18, ShuffleNet, and SqueezeNet models also yield nearly equivalent results, all above 99%.
On the other hand, when considering the calculation time, there are significant differences among the architectures. HiDraNet not only achieves the highest accuracy but also has the second shortest calculation time (102 s), only after AlexNet (122 s). In contrast, architectures such as MobileNetv2, ResNet18, and ShuffleNet have calculation times of several hundred seconds, which is multiple times longer than HiDraNet.
These results demonstrate that the HiDraNet architecture is not only effective in classifying casting products with high accuracy but also very fast, making it suitable for deployment in real-world applications that require fast processing speed, such as quality inspection systems on production lines.
Figure 4 presents more detailed performance evaluation metrics of deep learning models in the casting product classification task, including precision, recall, and F1-Score.
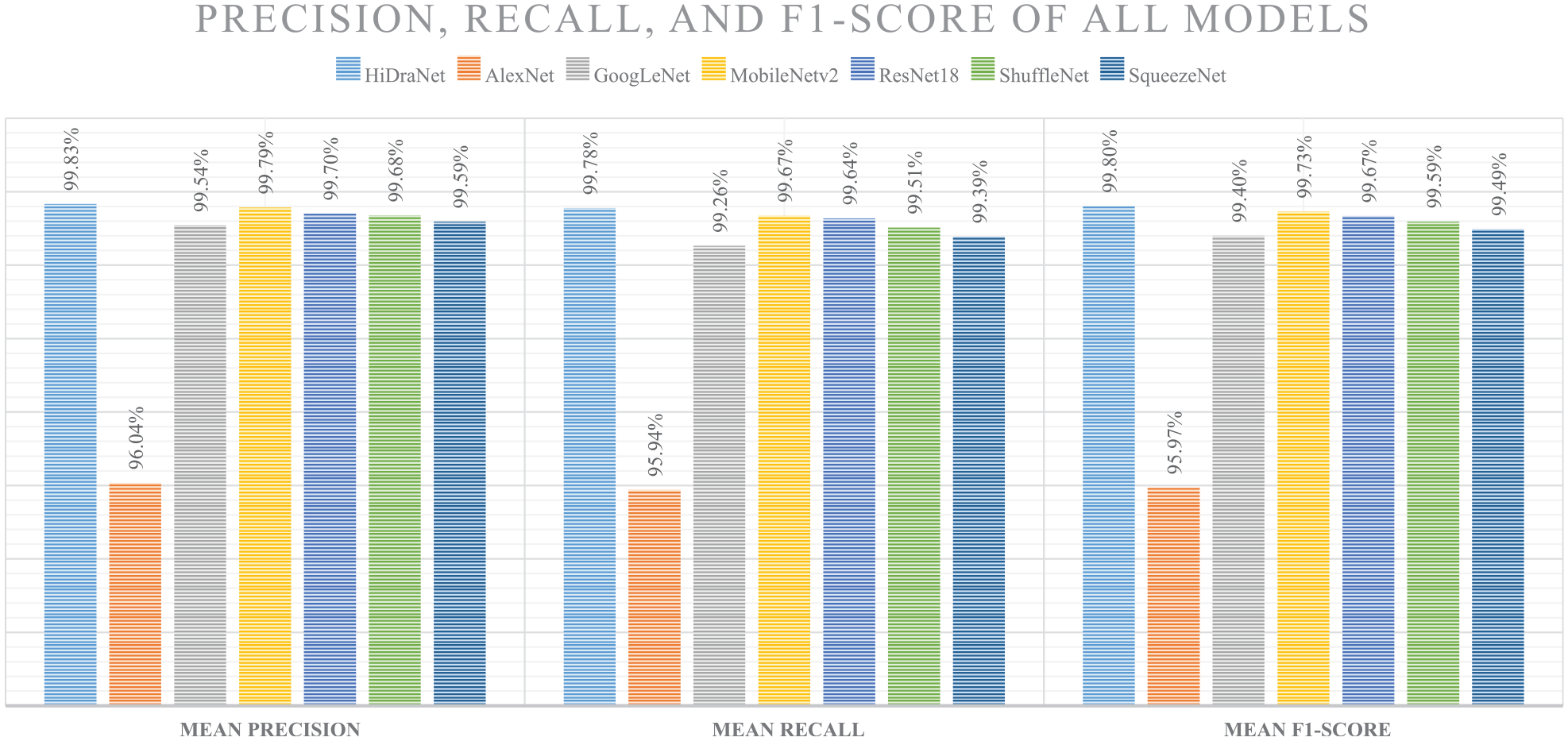
Comparison of precision, recall, and F1-Score of deep learning models in the casting product classification task.
Precision represents the proportion of correctly predicted samples among all samples predicted as positive. HiDraNet achieves the highest average precision (99.83%), followed by MobileNetv2 (99.79%) and ResNet18 (99.70%). AlexNet has the lowest precision (96.04%), while the remaining models all achieve above 99.5%.
Recall represents the proportion of correctly predicted positive samples among all actual positive samples. HiDraNet continues to lead with an average recall of 99.78%, and MobileNetv2 comes second with 99.67%. AlexNet has the lowest recall (95.94%), while the other models all achieve above 99.2%.
F1-Score is the harmonic mean of precision and recall, providing an overall assessment of the model’s performance. HiDraNet has the highest average F1-Score (99.80%), demonstrating a good balance between precision and recall. MobileNetv2 and ResNet18 also achieve high F1-Scores of 99.73% and 99.67%, respectively. AlexNet has the lowest F1-Score (95.97%) due to its low precision and recall.
Overall, HiDraNet performs superior in all three metrics: precision, recall, and F1-Score. This confirms the accurate and stable classification ability of the proposed model on the casting product dataset, outperforming other popular architectures.
Figure 5 illustrates the accuracy convergence during the training process of HiDraNet, AlexNet, GoogLeNet, MobileNetv2, ResNet18, ShuffleNet, and SqueezeNet models for the casting product classification task.
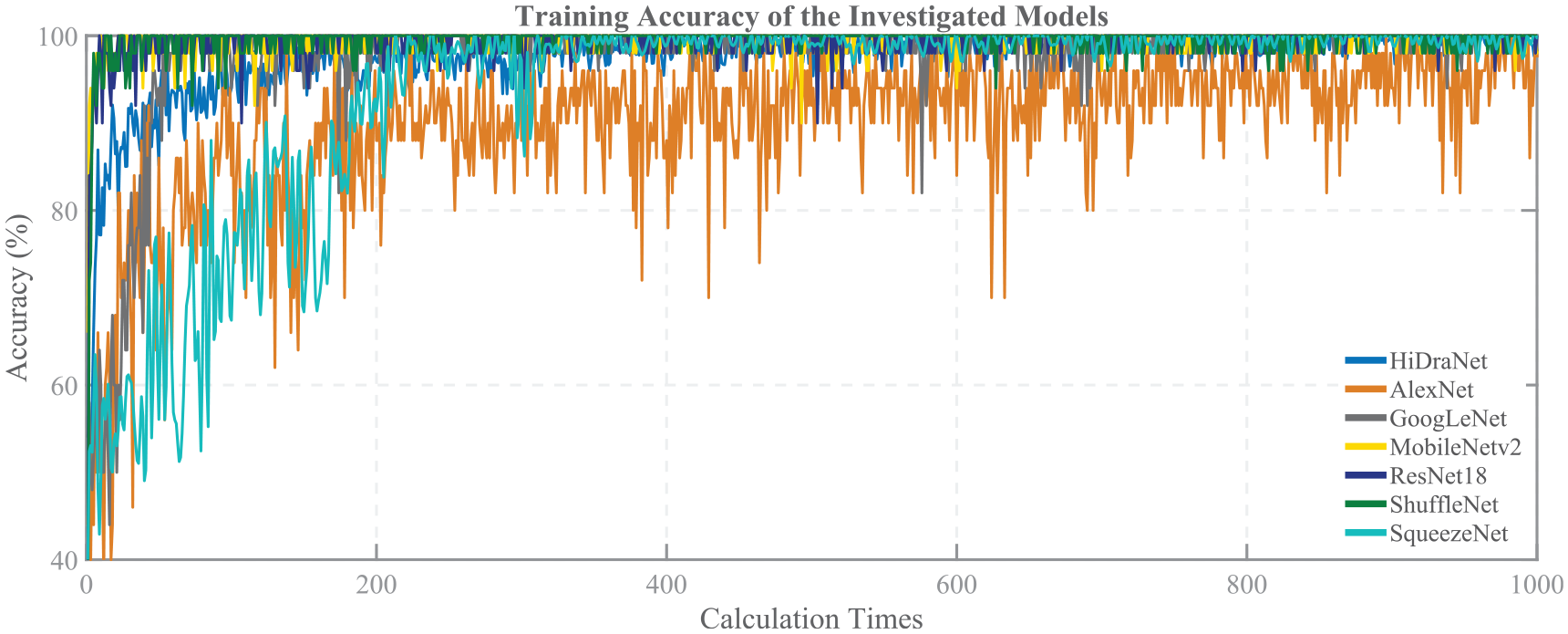
Training accuracy of the investigated models in the casting product classification problem.
The horizontal axis represents the number of calculation times, while the vertical axis represents the accuracy in percentage. Each curve corresponds to a specific model, showing the change in accuracy on the training set over the number of calculations.
Overall, all models improve their accuracy over time and achieve convergence after around 1000 calculation times. However, the convergence speed and final accuracy differ among the models.
HiDraNet exhibits the fastest convergence speed and reaches the highest accuracy, outperforming other models from the early stages of the training process. This indicates that the proposed architecture has better learning and generalization capabilities on the casting product dataset.
The MobileNetv2, ResNet18, GoogLeNet, ShuffleNet, and SqueezeNet models have relatively similar convergence speeds and achieve fairly high accuracy after training. However, AlexNet converges significantly slower and has the lowest accuracy among the investigated models.
Figure 6 illustrates the loss function’s convergence during the seven models’ training process.
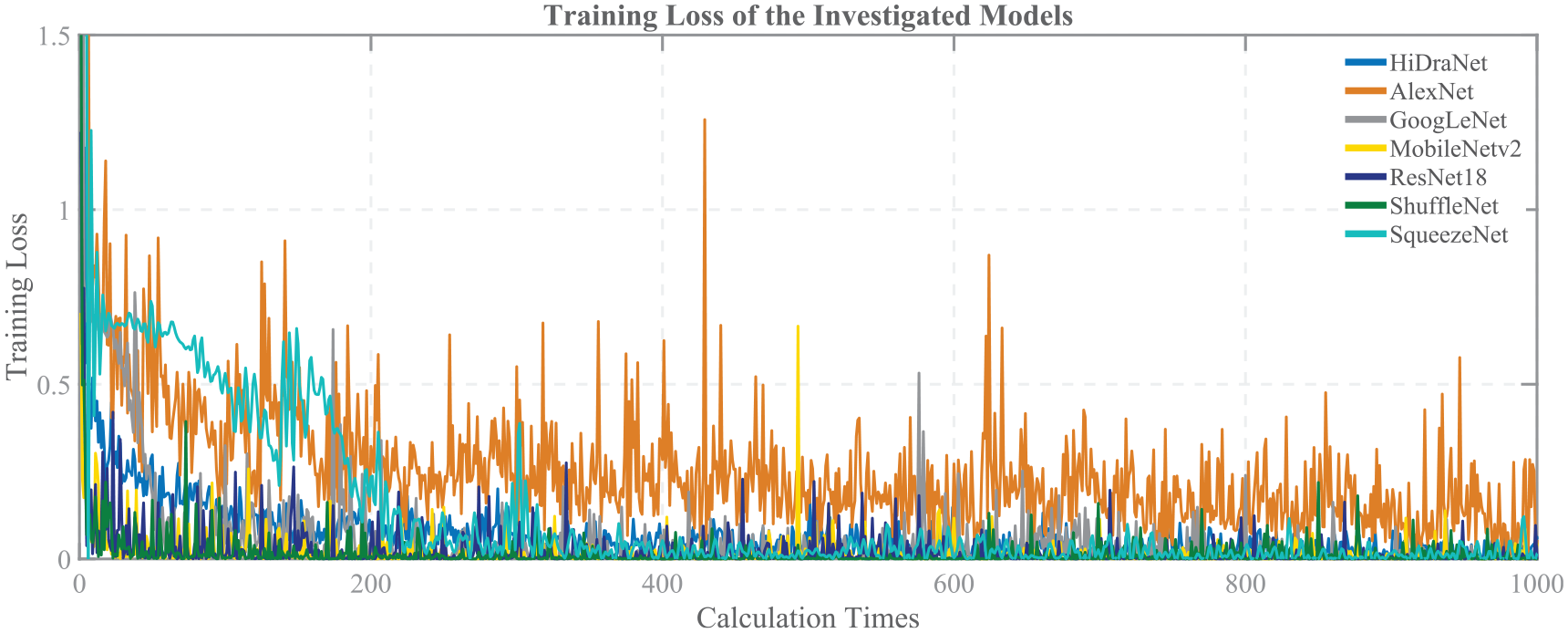
Training loss of the investigated models in the casting product classification problem.
The vertical axis represents the value of the training loss. Each curve corresponds to a specific model, showing the change in the loss function value on the training set over the number of calculations. Overall, the loss function values of all models decrease gradually and converge after around 1000 calculation times, corresponding to the increase in accuracy as shown in the previous figure. However, the convergence speed and final loss function values differ among the models.
HiDraNet has the fastest convergence speed and reaches the lowest loss function value, demonstrating that this model learns and optimizes better than the other models on the casting product dataset. This is consistent with the results of the high accuracy and fast convergence speed of HiDraNet in the previous figure.
The MobileNetv2, ResNet18, GoogLeNet, ShuffleNet, and SqueezeNet models also achieve relatively fast convergence speeds and low-loss function values after training. However, AlexNet converges significantly slower and has the highest loss function value among the investigated models, corresponding to the lowest accuracy in the previous figure.
Figure 7 presents the confusion matrices of all investigated deep learning models on the test set for the casting product classification task.

Confusion matrices of the deep learning models on the test set for the casting product classification task averaged over 10 runs.
The initial test set contains only 715 images, with 453 images for the “Normal” class (normal products) and 262 images for the “Defective” class (defective products). However, to thoroughly evaluate the performance and stability of the models, the testing process is repeated 10 times. As a result, the total number of test samples reported in the confusion matrices is 7150, with 4530 samples for the “Normal” class and 2620 samples for the “Defective” class.
For each model, the confusion matrix is illustrated as a 2×2 table, where the columns correspond to the true classes and the rows correspond to the predicted classes. The values in the matrix represent the number of samples classified correctly or misclassified between the “Defective” and “Normal” classes over 10 runs.
From the confusion matrix, we can calculate various performance metrics such as accuracy, class-specific accuracy, true positive rate, false positive rate, and others. The percentage values are shown alongside the absolute values in each matrix cell.
Overall, after 10 runs, all models achieve a high accuracy of over 95% on the test set. However, there are significant differences in performance among the models:
• HiDraNet has the best performance with nearly perfect accuracy (99.8% and 99.9% for the two classes), with only a few samples misclassified in 10 runs;
• AlexNet has the worst performance, with significantly higher misclassification rates compared to other models (3.2% and 4.8% for the two classes);
• The remaining models (GoogLeNet, MobileNetv2, ResNet18, ShuffleNet, SqueezeNet) have relatively similar performance, with an accuracy of over 99% and only a few samples misclassified after 10 runs.
Repeating the testing process 10 times helps increase the results’ reliability and assess the models’ stability. The results show that the performance of the models is quite consistent across runs, especially the HiDraNet model, which has nearly perfect accuracy and low fluctuations.
Conclusions
In this paper, we proposed a novel approach for identifying defective casting products using a custom CNN architecture called Hierarchical Defect Recognition Architecture (HiDraNet). The proposed model aimed to automate the quality inspection process, reduce reliance on manual methods, and improve overall product quality while minimizing production costs.
The HiDraNet architecture was designed to effectively learn and extract hierarchical features from casting product images, enabling accurate defect detection and classification. The model was trained and evaluated using a comprehensive dataset of 7348 casting product images, including various types of defects such as fins, porosity, surface imperfections, and multiple defects.
Experimental results demonstrated the superior performance of the HiDraNet model compared to several well-known CNN architectures. HiDraNet achieved the highest classification accuracy of 99.8%, outperforming models like AlexNet, MobileNetv2, ResNet18, GoogLeNet, ShuffleNet, and SqueezeNet. Moreover, HiDraNet exhibited faster computation times, making it suitable for real-time applications in industrial settings.
The proposed approach has significant implications for the manufacturing industry. By automating the quality inspection process and accurately identifying defective products, manufacturers can reduce the time and costs associated with manual inspection, minimize human error, and enhance overall product quality. This can lead to increased customer satisfaction, improved brand reputation, and a competitive edge in the market.
Despite the promising results, this study has some limitations that provide opportunities for future research. First, while the model can classify products as defective or non-defective, it does not currently identify specific types of defects. Extending the model to classify individual defect categories could provide more detailed insights for quality control. Second, the model’s performance should be validated in real-world manufacturing environments to assess its robustness and identify potential challenges in practical implementation.
Future research directions include expanding the dataset to incorporate a wider range of casting products and defect types, optimizing the model architecture for improved efficiency and accuracy, and integrating the system with existing manufacturing processes for seamless deployment. Additionally, exploring the use of unsupervised learning techniques, such as anomaly detection, could enable the identification of previously unknown defect patterns and further enhance the model’s adaptability.
In conclusion, this research demonstrates the potential of deep learning, specifically convolutional neural networks, in revolutionizing quality inspection processes in the manufacturing industry. The proposed HiDraNet model offers a powerful tool for automating defect detection in casting products, leading to significant improvements in efficiency, accuracy, and cost-effectiveness. As industries continue to embrace digital transformation and Industry 4.0 technologies, such intelligent systems will play an increasingly crucial role in driving innovation and competitiveness in the global market.