
Abstract
To detect possible failures of the pressure sensor in the fuel cell engine air supply subsystem, this study proposes a fault identification method based on Random forest. To simulate faults in the sensor, we injected deliberate faults and constructed a fault dataset based on it. This dataset includes gradual fixed deviation and gradual complete deviation. The peRandom forestormance of training accuracy is observed on different fault datasets, aiming to identify fault types based on the deviation in accuracy caused by the presence of polluted or corrupted samples in the dataset. The results indicate that machine learning can effectively distinguish the data collected within 9 min. The validity of the residual law established by the root mean square error (RMSE) can be demonstrated through an example, wherein successful identification of intermittent faults 1.2/1.5 can be achieved a difference of 33%, which can effectively distinguish fault categories. In addition, this method does not rely on high-precision models and effectively utilizes abundant sensor data and the uneven distribution of data sets under faults, including sensors other than the target fault sensor, for machine learning to identify different types of sensor faults.
Introduction
Currently, with the rapid global development of hydrogen production, hydrogen storage, and hydrogen refueling technology, there has been a significant increase in investments by stack-related enterprises and the establishment of industry standards.1–5 The manufacturing technology for membrane electrode components has become more mature. 6 The research conducted by manufacturers on the main components of fuel cells is increasingly becoming more comprehensive and refined. So a mature research and development system has been formed. 7 In the coming decades, hydrogen fuel cell vehicles will undoubtedly emerge as a strategic choice for countries and enterprises. However, due to the characteristics of hydrogen, there are potential safety hazards in the hydrogen-related operation link. 8 Fuel cell contain multiple subsystems, and it is important to note that most sensors can be influenced by the surrounding environment.9–11 For instance, the pressure sensor in the air supply subsystem may experience failure due to the condensation of liquid water.
The stable operation of fuel cell vehicles relies heavily on the information provided by a multitude of sensors as a reference. 12 Once the running data is available, the next step of status detection and fault identification can be peRandom forestormed. Common ones are active fault tolerance and passive fault tolerance. 13 All of them have achieved good results in various fields.14,15 To ensure the proper functioning of the equipment, Fault Detection and Isolation (FDI) systems are often designed. 16
Jouin et al. proposed a Prediction and Health Management (PHM) framework, with the first layer focused on data acquisition through sensors. 17 It can be seen that if the data acquisition of the first layer fails, subsequent processes such as data processing, scenario assessment, and diagnosis in the following layers will not accurately reflect the real state.18,19 Therefore, it is of utmost importance to effectively identify sensor failures, as timely diagnosis of sensor faults plays a vital role in ensuring the safety of fuel cell vehicles. 20 Yan et al. constructed a thermal model comprising 42 equations and introduced an Active Fault Tolerant Control (AFTC) strategy that substantially enhanced the control peRandom forestormance of the stack. The simulation utilized the Offset Fault and Multiplicative Fault, followed by the successful diagnosis of sensor faults using the residual model. 21 In practical applications, as the usage of fuel cell increases and working conditions change, it is necessary to further validate the migration and stability of the residual model. Elkhatib Kamal proposed a Takagi-Sugeno (TS) fuzzy model affected by the sensor, defined the state space equation of Proton Exchange Membrane Fuel Cell (PEMFC) using matrices and functions, and utilized the Fuzzy Unknow Input Observer (FUIO) algorithm to effectively reduce the error between sensor prediction estimates and sensor normal values, 22 Fuzzy logic control is an intelligent control system that mimics the way of human thinking.23,24 All of these approaches mentioned above are model-based.
Mao et al. introduced the concept of sensor reliability in their research. They suggested using voltage-sensitive sensors for diagnostics to enhance the accuracy of the diagnosis. It was discovered that removing abnormal sensors led to improved diagnostic results. 25 Another study by Zhang et al. proposed an online diagnostic approach specifically for intermittent sensor faults. 26 These works illustrate that sensor failure is a critical issue in fuel cell. The accuracy of data acquisition from various sensors is influenced by the operating state of the fuel cell, resulting in different types of sensor failures.
Wang and Li addressed the issues of complex modeling and poor portability by proposing the use of Spiking Neural Networks (SNN) for sensor fault diagnosis. They also highlighted the limitations of deep learning, such as low robustness, data dependence, and high resource consumption. 27 Many challenges in the field of deep learning remain unsolved. Firstly, there is still a considerable gap between academic theory and practical application in online vehicle diagnosis. Secondly, some problems arise when combining algorithm usage with fault diagnosis, including the pursuit of high accuracy at the algorithm level and the integration of new algorithms with traditional fault detection methods. The true power of machine learning algorithms lies in their ability to uncover intrinsic relationships among large amounts of data, which often involves using a black-box model. This intrinsic relationship encompasses multiple metrics beyond the prediction accuracy on a single test set.
Quan et al. utilized the Levenberg-Marquardt (LM) algorithm for constructing an Artificial Neural Network (ANN) model, which was deployed to detect faults in the current sensors of the air supply subsystem. 28 Oh et al. used representative residual and machine-learning-based methods to diagnose faults in the air mass flow sensor and thermocouples.29–31 Gong et al. utilized a sensor pre-selection method to enhance the accuracy of the diagnosis. 32 Therefore, the identification of sensor faults not only enhances the stability of closed-loop control of fuel cell but also accelerates the process of sensor pre-selection in fault diagnosis. This, in turn, increases the accuracy of fault diagnosis by eliminating faulty sensors.
There exists a significant correlation between sensor failures and the failures of the corresponding systems.33,34 Furthermore, there may be interdependencies among different sensor failures, such as step faults, pulse faults, noise faults, stuck faults, drift faults, and periodic faults.9,35
The fuel cell bench sensor can present the measured data in the form of a data set, which serves as the most direct representation of the sensor’s working results. It is crucial to discover effective troubleshooting methods for sensors designed for in-vehicle applications. 36 Data-driven fault diagnosis has been equally successful in other areas, such as the good performance of unsupervised learning methods for Main Steam Line Break (MSLB) faults in nuclear power plants, Collecting failure data in industry can be difficult, expensive, or even impossible, and unsupervised learning offers an effective alternative. 37 Ball bearings are sorted according to Fisher features with good accuracy, 38 and bearing fault classification based on fault image datasets. 39 At the same time, the Random forest adopted in this paper has also achieved certain results in fault classification learning. 40 This paper primarily utilizes a residual-based Random forest to identify fault datasets by intentionally injecting faults into the sensor. Although there are many types of sensor faults, this paper examines typical fixed, complete, and intermittent deviations
Then, by calculating the RMSE of the subsequent forest training results, we generate the residual between the measured value and the normal value when a specific fault occurs in the sensor. This residual-based approach allows for distinguishing various common types of sensor faults, thereby achieving accurate diagnostic outcomes.
Random forest-based approach
Random forest is a classic machine learning method that uses random sampling with a return on the dataset, as shown in Figure 1. Even though the training set and test set are separated, the division is purely based on the number of datasets. The data allocated to the test set can still be randomly sampled and included in the training set during the machine learning process, and vice versa. Therefore, modifying the output data of the test set will effectively modify the overall dataset. This interference can disrupt the training process by introducing artificially created data that does not align with real operating conditions. Consequently, the final training outcome will reflect the extent to which the dataset has been contaminated by inaccurate samples. This paper is also the first to propose sensor fault identification based on the severity of dataset pollution. By the RMSE of the results to reflect the difference between the predicted and actual values. Different RMSE manifestations for different types of faults can create residuals for identifying sensor faults and distinguishing between different sensor faults. In the past, excessive attention was given to the test set, but this article primarily focuses on analyzing the deviation between the faulty state and the normal state.

Random forest algorithm construction flowchart.
The Random forest algorithm has a good performance effect on high-dimensional large-sample datasets. A variety of sensor data can theoretically train a black-box model similar to a fuel cell engine. However, the training process can be affected by data pollution caused by sensor failure, leading to deviations in the final trained model from the actual working state of the fuel cell engine. In this paper, the main focus is on evaluating the degree of bias in the training model, rather than solely relying on traditional research criteria such as test set accuracy.
The Random forest uses the autonomous sampling method to train a base learner for each sampled training subset. The regression task uses the averaging method to combine these base learners. In a given dataset D containing m samples, a random sample is selected from it and put into another sampling set D’ hen the sample is put back into the original dataset D, so that the sample may still be selected in the next sampling. Therefore, after m random sampling operations, we obtain the sampling set D’ containing m samples. The probability of not being picked at once in a sample is about 36.8% as in equation (1). So the sample that is not selected at all can be used as the test set (36.8%) and the selected sample as the training set (63.2%). However, since the goal of this paper is to reflect the degree of contamination of the entire dataset by using the RMSE results of the training set, the sample size of the training set is expanded to 70% (4140). The test set consisting of fault data injections makes up 30% of the dataset (1774). Due to the randomness of Random forest sampling, the data in the test set will also be extracted into the training set. Because the Out-of-Bag Estimate (OOB) method can only quantitatively divide the train set and the test set without training on the specific specified samples, it provides the possibility for the successful identification of the more hidden intermittent sensor faults in this method.

To eliminate the dimensional influence between the sensor data, the dataset set is normalized to the data in the range of (0,1).

y is the normalized value, x is the initial value, x max is the maximum value in the initial value, x min is the minimum of the initial value, y min = 0, y max = 1. Therefore, the formula can be reduced to equation (3)

Set trees = 100 and leaf = 1. The corresponding error curve is shown in Figure 2, which proves that the adjusted parameters are relatively stable.
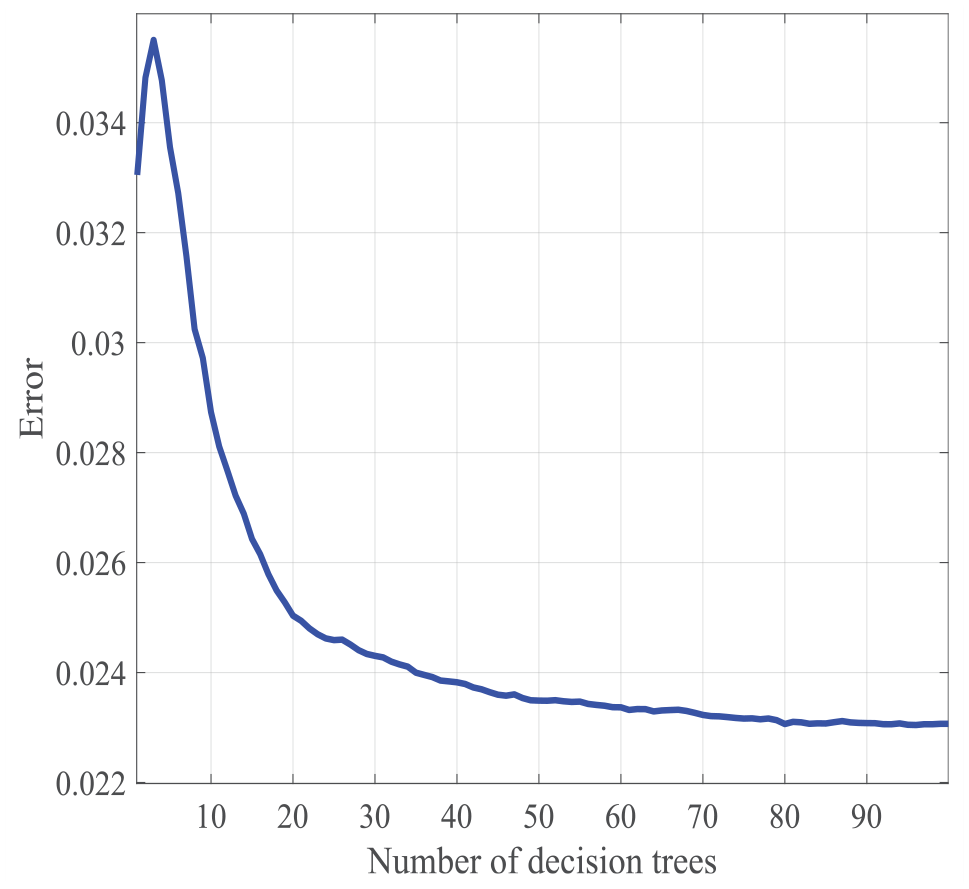
Random forest error curves.
It is assumed that the algorithm contains T basis learners.

The output of each base learner on sample x is hi(x). The combination strategy of the average method is used for the numerical output to combine the learning results of each base learner.
In addition, due to the different degrees of influence of the fuel cell subsystem on the air supply subsystem, it is necessary to carry out closed-loop control according to the hydrogen/air supply subsystem sensor data to control the hydrogen-air pressure difference for example. However, the influence of the electrical system on the air supply subsystem is relatively small. The above phenomenon will lead to a large difference in the performance of individual learners. So weighted averaging was used to combine the base learner as follows

H
(x) is the output prediction value, T is the number of learners, and the weight of the individual learner is h(i), Usually required wi ≥ 0,

Random forestfeature weight maps.
The data is then denormalized to output values that match the dimensions of the target fault sensor. The RMSE of the training set is then calculated as shown in equation (6). RMSE is the square root of the square of the deviation from the predicted value to the true value and the ratio of the number of training set M. It measures the deviation between the predicted value and the true value and is sensitive to outliers in the data. The characteristics of RMSE include being intuitive, interpretable, and insensitive to outliers.

M is the total number of samples in the train set (4140), H(xk) is the output prediction of the kth sample, and F(xk) is the true value of the output of the k sample.
The identification of sensor faults needs to ensure that there is no voltage drop, which is to ensure the various components of the stack are in normal operation. Since the threshold for normal operation of the sensor is difficult to define, if the voltage sensor has intermittent slow deviation fault while the stack is operating normally. It will hinder the troubleshooting of normal systems.
The basic judgment logic of the sensor is to first look for whether the first feature appears, and continue to use the method of polluting the dataset based on the bad samples of Random forest to diagnose when it does not appear. It is worth noting that the fault of the first feature is the strongly coupled state of the sensor fault and the stack fault, and it is impossible to determine what the cause of the fault is. However, from the perspective of subsequent normal engine monitoring or from the perspective of sensor failure, both faults are fatal: the former loses detection ability, and the latter false fault false alarm. Therefore, the dataset used in this paper is to monitor the normal operation of the fuel cell in the absence of the first feature of voltage drop.
Machine learning process and result analysis
Fault injection to construct a failure data set
The sensor data was obtained from a real uh fuel cell engine, and the experimental setup is shown in Figure 4. The flow chart of the proposed method is shown in Figure 5.

Detail photograph of the experiment.

Methodological process framework.
Due to the lack of fault data in the actual operation of fuel cell engine sensors, the purpose of this paper is to inject faults into the sensors to construct a fault data set.
Fault injection 1: slowness changes fixed deviation failure; Fault injection 2: slowness changes complete deviation failure. In this paper, we rely on the fuel cell engine bench in the laboratory of Shandong University of Science and Technology to inject faults into the pressure sensor of the air supply subsystem. The dataset has a total of 5160 data records in 9 min. The dataset includes a total of 36 sensor data types such as current sensor, voltage sensor, compressor temperature sensor, controller temperature sensor, speed sensor, motor current sensor, motor power sensor, motor voltage sensor, etc. Since the air supply subsystem pressure sensor in the actual operation of the fuel cell engine may fail during cold start, the remaining 35 sensor data are selected as input and the air pressure sensor is selected as the output for the dataset. Firstly divide the training set: the test set is 7:3 (3612:1548). Fault injection 1 is then performed: the data in the train set remains unchanged, and only the output data in the test set is injected into the slowness changes fixed deviation failure, which is +0.1, +0.2, +0.3, +0.4 on the basis of the original values, respectively. Finally, fault injection 2 is then performed: the data in the train set remains unchanged, and only the output data in the test set is injected into the slowness changes complete deviation failure, which the values are 1, 1.5, 2.0, 2.5, respectively.
Two faults and different degrees of performance of each fault
A fixed deviation is a fault that adds a fixed value to the normal value to deviate the sensor from the normal state, as shown in Figure 6. Complete deviation is a direct change in the final value of the sensor, as shown in Figure 7. Due to the timing-series nature of the data set, this fault is equivalent to a sudden sensor deviation fault over a certain period of time.

Different degrees of fixed deviation.

Different degrees of complete deviation.
Specific operation steps
This paper uses 4° of sensor failure of 2 faults and performs Matlab machine learning 20 times for each fault to eliminate experimental errors. Record the RMSE of the train set results for each machine learning.
Machine learning results and analysis
The RMSE after each machine learning under the slow fixed deviation fault is shown in Figure 8, and the fixed deviation will be higher or significantly higher than the normal state at different degrees.

Fixed deviation with 20 RMSE.
In addition to the fact that the fixed deviation is 0.1, there are many coincidence points with the normal state, and other fixed deviation faults of different degrees will be significantly higher than the normal state. Different degrees of fixed deviation faults can be clearly distinguished. After averaging RMSE, the law is more obvious as shown in Figure 9.
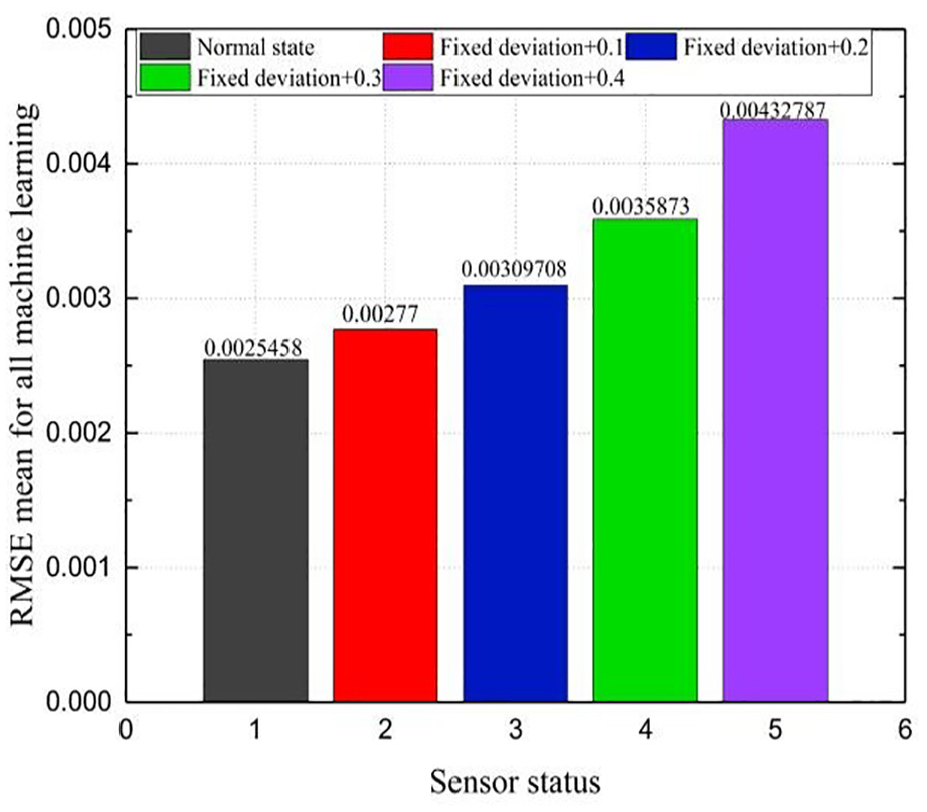
Average of RMSE of fixed deviation.
Explanation of the coincident points in Figure 10: When the test set data is randomly sampled after changing, more normal data from the training set is included. This leads to a reduction in the RMSE of the training model. Conversely, if there is a random sampling of more contaminated data from the test set, it increases the contamination level of the failure data in the entire dataset, resulting in an increase in the RMSE of the trained model.

Complete deviation with 20 RMSE.
It can be observed that the RMSE sensitivity is higher for different degrees of complete deviation faults compared to fixed deviation faults. The average RMSE values of 20 iterations are depicted in Figure 11 revealing a clear differentiation between different fault degrees.

Average of RMSE of complete deviation.
According to the average of RMSE, different degrees of faults can be distinguished and fault types can be diagnosed. The reason why the degree of differentiation of a complete deviation fault is higher than that of a fixed deviation is due to varying levels of contamination after data transformation. A complete deviation fault with a progression of 0.5 exhibits greater pollution severity compared to a fixed deviation fault with an increasing deviation of 0.1.
Determination of fault residuals
Firstly, the average RMSE of the machine learning results is calculated for both the fault state and the normal state. This difference is presented in Table 1 as the residual value for gradual fixed deviation in the fault state and normal state. Determining the residuals of different faults provides a reliable method for identifying sensor faults during the actual operation of fuel cell. Therefore, this paper proposes the following method: collect 9 min of data and conduct 20 machine learning cycles. Record the RMSE for each training set and calculate the average. The difference between the RMSE in the unknown state and the normal state is then assessed, and the residuals are calculated accordingly. Finally, the obtained residuals are compared with the residual law mentioned above. By identifying these residuals, the objective of detecting fixed deviation faults and assessing fault severity can be achieved.
Fixed deviation fault residuals.

The residuals for calculating the complete deviation fault are displayed in Table 2. It is evident that the residual values for different degrees of complete deviation faults exhibit good discrimination. Moreover, there is still a certain level of discrimination between the residual values of complete deviation faults and fixed deviation faults. The underlying reason for the variation in residuals among different faults lies in the fact that different sensor values contaminate distinct datasets. Indeed, both random deviation and systematic deviation have distinct impacts on the process of training machine learning models. This can be attributed to the high sensitivity of machine learning algorithms to variations in data extraction and model construction. In terms of residual changes, it is important to note that as the contaminated data deviates further from the true values, the RMSE value of the training set tends to increase. But the closer the polluted data is to the actual value (this situation is also a failure), the smaller the RMSE value of the train set. The incorporation of residuals enhances the efficiency of fault identification. In this study, the fundamental logical sequence for diagnostics is: data extraction, machine learning iterations conducted 20 times, computation of the RMSE for the training set, averaging the RMSE values, and subsequent calculation of residuals. These calculated residuals are then compared against pre-designed fault injections to determine the specific type of fault. The specific residuals corresponding to all faults in this paper are illustrated in Figure 12, providing evidence of the effectiveness of the proposed method.
Complete deviation fault residuals.


Summary of fault residuals.
Instance verification
After determining the basic fault residuals and fault identification methods, this paper tests the effectiveness of the method through examples.
The first example involves injecting sensor failure in the same backpressure for a certain period of time, resulting in a complete deviation of 1.2. After performing the same machine-learning steps, the results are shown in Figure 13.

The RMSE at a complete deviation of 1.2.
It can be found that the RMSE mean value is 0.0107421, the residual difference with the normal value is 0.00820141, and between 0.010088800 and 0.00582790 is consistent with the residual distribution law between the complete deviation 1.0 and the complete deviation 1.5 in the previously determined residual table. It is inferred that the residual law under the back pressure is established and a sensor fault with a complete deviation 1.2 is successfully identified according to the residual.
The sensor fault injection is depicted in Figure 14, with all time periods exhibiting normal values except for the indicated deviations of 1.2 and 1.5. Diagnosing this fault based on threshold setting proves challenging due to the sporadic occurrence of the fault and its deviation value coinciding with the normal state value of some other time period. The machine-learning outcomes presented in Figure 15 provide additional insights.

Two types of intermittent complete deviation fault.
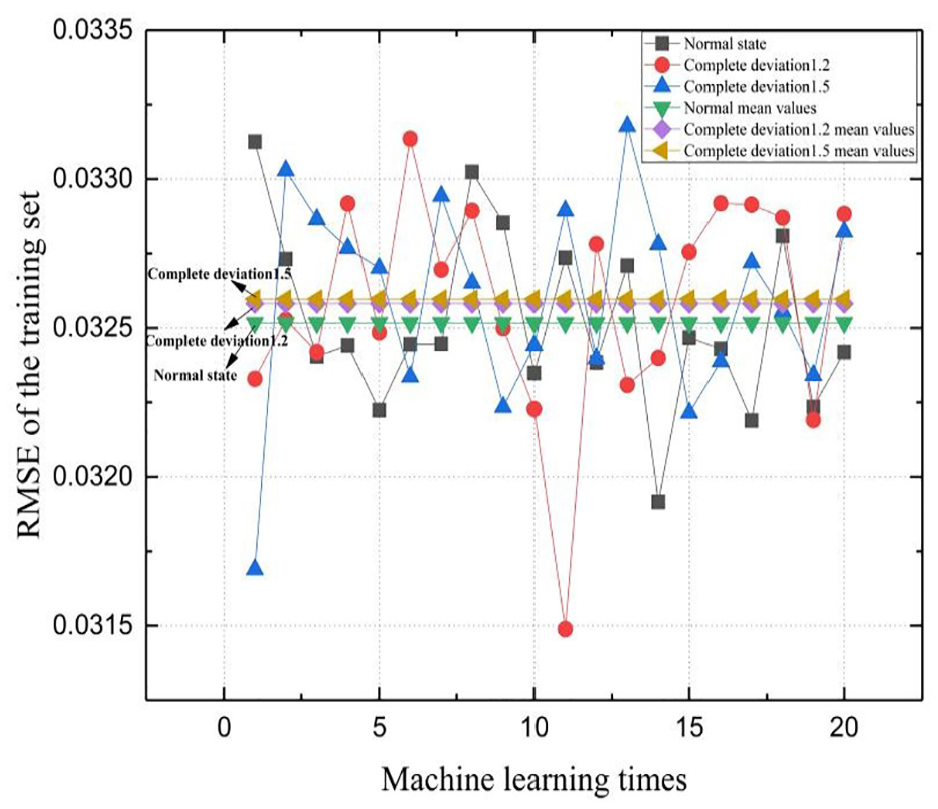
RMSE for varying degrees of intermittent complete deviation.
The second example is an intermittent fault, which is difficult to identify in line with the real scenario. This can be observed in Table 3. As can be observed from Table 4, the mean values of RMSE during the intermittent fault state exhibit a significant increase compared to the normal state. This indicates that the presence of faulty data in the dataset adversely affects the modeling accuracy of the final training set.
Time of occurrence of intermittent fault.

Intermittent fault residual values.

Moreover, under the influence of this back pressure, a similar residual pattern can still be identified, as shown in Table 4. Fault 1.2 and fault 1.5 can achieve a difference of 33%, which can effectively distinguish fault categories.
Additionally, the greater the deviation from the normal value, the higher the corresponding residual value. Based on these findings, the paper proposes utilizing the existing methods for residual determination and fault identification.
In short, the residual law discovered by RMSE reflects the challenges encountered when inputting normal sensor values and outputting faulty sensor values while establishing data models. Theoretically, this law can be used to identify various sensor states.
At the same time, this paper uses 10-fold cross-validation, divides 10% of the original dataset into the validation set, and compares it with other algorithms, in Figure 16, as shown in the Table 5, Residuals is the difference between the fault state of 1.5 and the normal state, and the results of tree learning can be obtained from the table compared with others. Moreover, RMSE’s Residuals are more distinguishable than other indicators, and they still do not change by orders of magnitude under faults. As can be seen from the figure, the tree still maintains good accuracy in the fault state.

Algorithm comparison: (a) linear regression, (b) tree and (c) Gaussian SVM.
Comparison of different indicators.

As shown in Table 6, the proposed method can achieve a 33% difference rate between different fault degrees of intermittent faults that are difficult to identify, indicating that it has better discrimination than traditional methods.
Comparison of results.

The selected pressure sensor is prone to condensate to interfere with the pressure sensor value during the low-temperature cold start, and the selection standard is determined by the power of the fuel cell engine. Under steady-state operating conditions, the pressure sensor should maintain accuracy and stability to ensure that the pressure of the air supply system is effectively monitored, so as to ensure the safe and efficient operation of the system. Under drastic load changes, the sensor fault signal can affect the transient behavior of the system, and the net power of the faulty system can be about 0.2 kW lower than that of the non-faulty system. 42
Conclusion
In this paper, a Random Forest-based method for sensor fault identification was proposed. Firstly, faults were injected into the sensor, and a fault dataset was constructed based on the induced faults, specifically focusing on gradual fixed deviation and gradual complete deviation. To address the issue of dataset contamination and its interference with the accuracy of the training model, this paper investigated the performance results under such interference to identify sensor failures. The mean values of the RMSE in the training set were used to determine the residuals between the fault states and normal states. The results demonstrated that this diagnostic method is independent of the accuracy of the algorithm’s test set and the trained model. Only errors in the basic training model needed to be considered, and failure types could be identified by comparing unknown states with normal states. This method was universally applicable to various sensors. Compared with the traditional method, this method can still ensure a certain prediction accuracy with other non-faulty sensors when the target sensor fails, and at the same time, the Random forest is used to capture the characteristics of uneven distribution and abnormal data distribution in the data set, which is better helpful to identify sensor faults, The proposed method can diagnose the sensor data of the actual fuel cell engine within 9 min in about 12 s.
The dataset used in this paper was derived from monitoring data during the operation of a fuel cell engine with no voltage drop characteristics. This method can also identify faults in various sensors by simply finding the residual between the normal state and the unknown state. In other words, if you need to diagnose a sensor fault, you only need to set this sensor as the output value of the Random forestmodel and set other sensors as input values. By fully utilizing the information from each sensor of the fuel cell and training the machine, a black box model can be obtained. This article utilizes machine learning in Matlab, and the Matlab code is 3 KB, making it highly suitable for in-vehicle diagnostic scenarios.
In the future, the research direction should be combined with the cloud data platform to realize the fault diagnosis of multi-sensor system driven by big data, and the method should be extended to other multi-sensor systems.
Footnotes
Handling Editor: Simona Merola
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: 1. Qingdao postdoctoral support project (QDBSH20220202020), 2. Qingdao Natural Science Foundation (23-2-1-110-zyyd-jch), 3. National Natural Science Foundation of China under grants (62203279), 4. Shandong Natural Science Foundation (ZR2023QF073, ZR2023QE208).