
Abstract
Bearing faults can cause heavy disruptions in machinery operation, which is why their reliable diagnosis is crucial. While current research into bearing fault analysis focuses on analyzing vibration data under constant working conditions, it is important to consider the challenges that arise when machinery runs at variable speeds, which is usually the case. This article proposes a multistage classifier for diagnosing bearings under time-variable conditions. We validate our method using vibration signals from five bearing health states, including a combined fault case. Our approach involves decomposing the signals using Empirical Wavelet Transform and computing temporal and frequency domain attributes. We use the Expectation-Maximization Gaussian mixture model for optimization concerns to identify relevant parameters and train the Random Forest classifier with the selected features. Our method, evaluated using the Polygon Area Metric, has demonstrated high effectiveness in diagnosing bearings under time-variable conditions. Our approach offers a promising solution that efficiently addresses speed variability and combined fault recognition issues.
Keywords
Introduction
Bearing is a crucial component of rotary machines, but it is also highly susceptible to failure. 1 Therefore, accurate diagnosis of bearings is essential to ensure the functionality of rotary machines 2 and the safety of employees. 3 As a result, many researchers have focused on this issue and developed new diagnosis strategies based on various condition monitoring techniques, including vibration, current, acoustic emissions, and temperature. 4 Signals are extensively used for bearing diagnosis due to their effectiveness in detecting and analyzing bearing faults. 5 The vibration signals provide crucial information related to bearing health and fault conditions, making them a valuable source for fault diagnosis. Various studies have demonstrated the significance of vibration signals in bearing fault detection and diagnosis, 6 this approach is favored because it effectively captures system conditions and degradation characteristics through vibration datasets. 7 However, the primary challenge lies in accurately extracting fault features from these datasets. Over recent decades, plenty of signal-processing methods have been developed to address various failure modes, characteristics, and data types. These methods aim to achieve early fault detection by eliminating unwanted components such as interference noise.8–10 Common time-domain techniques include autoregressive moving average, dimensionless factor, and singular value decomposition. Similarly, frequency-domain methods such as Fourier transform and spectral kurtosis have been widely applied.11–13 Additionally to these techniques, a wide range of time-frequency analysis tools are adopted for this matter. The Empirical Wavelet Transform (EWT) approach is the best method for analyzing this type of signal, as it allows for simultaneous insight into the time and frequency domains. 14 In Wang et al., 15 the EWT was employed to handle the complexity of bearing fault feature extraction under changing speeds. Many researchers have embraced the EWT technique, including Dong et al., 16 Xu and Ma, 17 Xi et al., 18 and Hariharan et al., 19 due to its potential to overcome the shortcomings of well-performing procedures such as Empirical Mode Decomposition (EMD), which suffers from the mode-mixing problem 20 and the lack of theoretical foundation, 21 and the time-varying spectral amplitude method because of its complexity and computational cost, parameter sensitivity. However, these methods have certain limitations. They can be time-consuming due to their extensive and intricate feature extraction processes. Moreover, the feature extraction itself is complex and requires substantial resources. It is important to note that extracting features for a specific fault detection technique applies solely to that particular issue and may not be suitable for a different fault diagnosis technique, especially when dealing with conditions that vary over time. After extracting the signal modes, calculating the statistical parameters is an essential step. However, some features may be irrelevant and deceptive. Hence, feature selection becomes crucial to keep only the discriminative parameters for training the classification model. Optimization algorithms can yield meaningful results in feature selection, and they have become a significant phase in the diagnostic process. For instance, in Wu et al., 22 the grey wolf optimization algorithm (GOA) delivered good results by flexibly learning important parameters of joint distribution adaption. Similarly, in Wang et al., 23 the Grasshopper Optimization Algorithm (GOA) improved the Support Vector Machine (SVM) classifier’s pattern recognition capabilities and demonstrated its usefulness in diagnosing rolling bearing faults. Additionally, in Van et al., 24 Particle Swarm Optimization ensured a higher accuracy of the proposed Least-Squares wavelet support vector machine (LSWSVM) by selecting the most relevant features. However, it is worth noting that all the mentioned algorithms were applied at constant speeds, while bearings usually operate under time-varying conditions. To address this, in Imane et al., 25 the Clan-based Cultural Algorithm (CCA) was applied in bearing diagnosis using time-varying vibration data. It provided promising results with accurate classification, but the treated cases did not include combined faults. Besides these techniques, deep learning algorithms have shown promising performance in bearing fault detection. However, while they have shown high accuracy, there are some disadvantages to using them. Deep learning algorithms require significant computational resources, including high-performance computing systems and large amounts of memory, to train and optimize the models.26,27 Also, they require large amounts of labeled data to train the models effectively.26,28 This can be a challenge in applications where data is insufficient or labeling is difficult or time-consuming. In addition, deep learning algorithms are often considered “black boxes” because they are difficult to interpret and understand.26,28 They are often criticized for their limited interpretability, making it difficult to understand how the model arrives at its predictions. This can be a disadvantage in applications where transparency and interpretability are important, such as in safety-critical systems.
This article discusses the diagnosis of bearings in time-varying settings, including combination defects, with five bearing health states, including combined defects using machine learning. First, we analyze the vibration signatures using the EWT to extract the AM-FM modes. Next, we compute statistical features in both time and frequency domains. To address the high computational cost of the wrapper optimization class and the independence of the filter class’s results from the clustering algorithms, 29 we applied the Expectation-Maximization-based Gaussian mixture model (EM-GMM) clustering algorithm to select only the features capable of distinguishing the exact number of classes. The final step involves supplying the selected attributes to the Random Forest (RF) classifier to train a robust model using only the discriminative elements. The article is structured as follows: Sections “Preprocessing and feature extraction based on Empirical Wavelet Transform,”“Fault identification with optimization algorithm based on expectation maximization Gaussian mixture model,” and “Fault patterns based on Random forest” provide the theoretical background on EWT, EM-GMM, and RF, respectively. Section “Experimental study” describes the data used, and the process, and presents the results and discussions. We conclude with a summary of our findings.
Preprocessing and feature extraction based on Empirical Wavelet Transform
Gilles
30
proposed the EWT intending to construct adaptive wavelets capable of extracting finite AM-FM components (modes)

The core concept of EWT involves creating bandpass filters on each

Flowchart of EWT.
Expressions 2 and 3 define the empirical scaling function and the empirical wavelets, respectively.
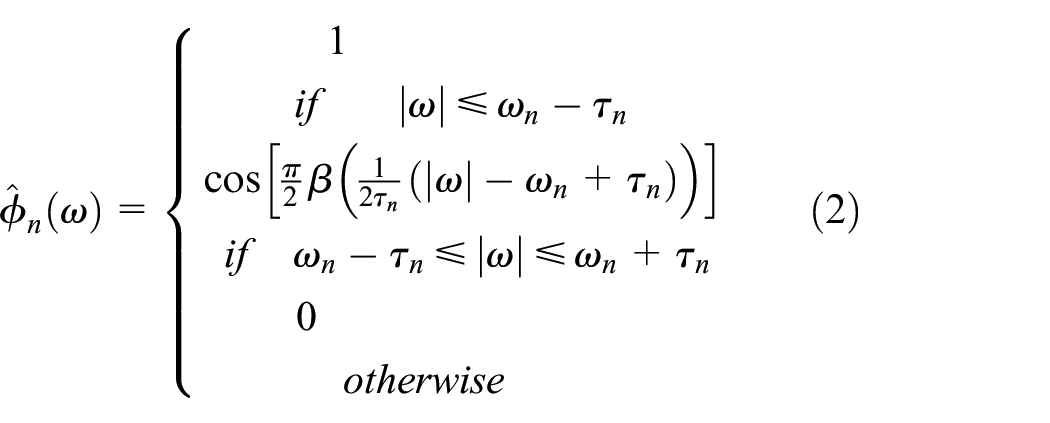
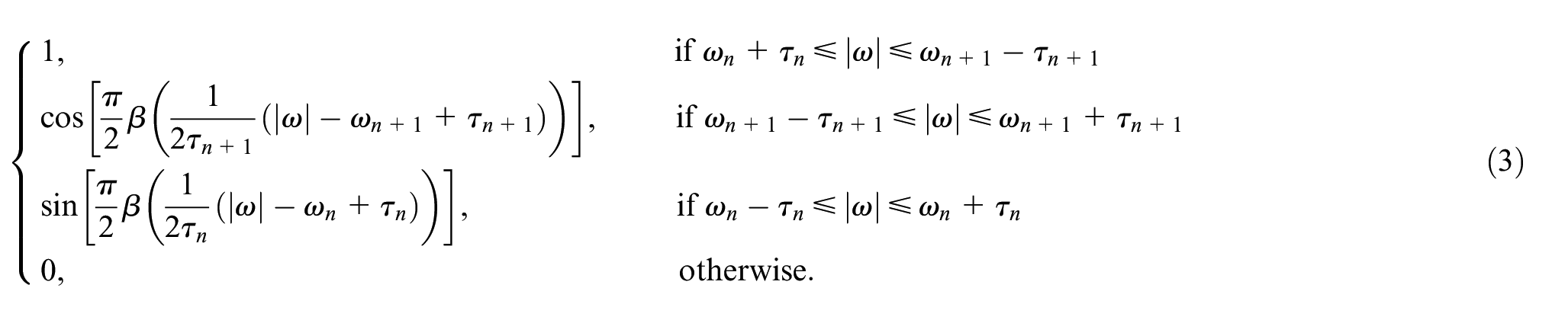
Among numerous functions that satisfy the properties, expression 4 is the most commonly used.

The EWT

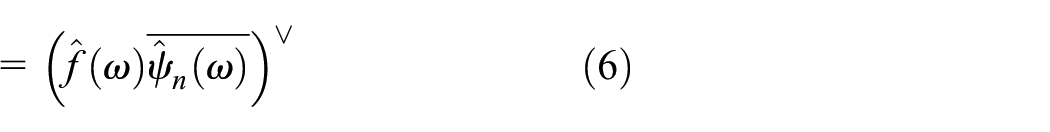
The approximation coefficients are calculated using equation (7).
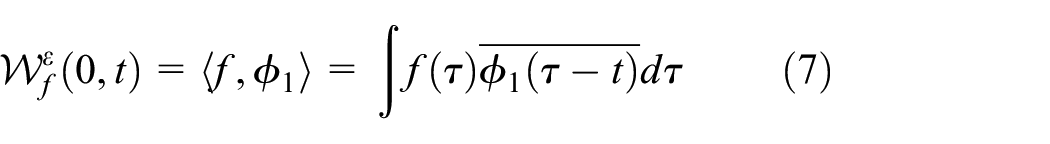
So the signal’s empirical modes


The original signal can be reconstructed using the equation (10).

Fault identification with optimization algorithm based on expectation maximization Gaussian mixture model
Gaussian Mixture Models (GMM) are commonly applied in data mining, pattern recognition, machine learning, and statistical analysis. 31
GMM aims to fit the data distribution of arbitrary shapes by finding the M latent Gaussian densities given by equation (11).

Where

And,


The estimation of the characterizing parameters is an essential step in the GMM. The Expectation-Maximization (EM) algorithm represents an efficient tool, 32 which seeks to identify the maximum likelihood estimate. 33
In the case of the discrete distributions, the likelihood is simply the joint probability of our data. We assume that each point is independent, and then the likelihood of all data is equal to the product of the likelihood of each data point, as explained in equation (15).

With

To find the maximum likelihood, we need to differentiate the equation (16). However, it is a difficult task. As a solution, we can utilize the log-likelihood to simplify this step by transforming the product into a sum, as shown in equation (17).
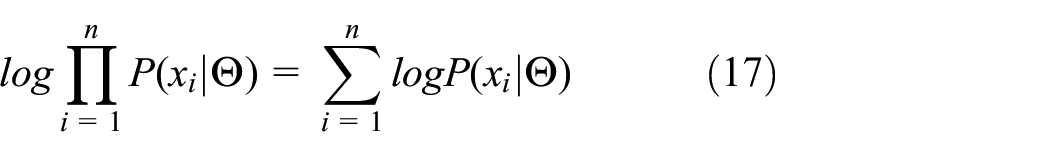
We denote

Where
In our study, we will take a fresh look at this technique and utilize it in feature selection.
Fault patterns based on Random forest
Random Forest (RF) is a classifier based on trees, consisting of multiple trees generated using random vectors sampled independently from the input vector.
34
The number of parameters used to determine the optimal split at each node is a subset of the total number of parameters selected randomly.
35
RF uses Breiman’s Classification and Regression Tree (CART) method to determine splits in training data and generate individual trees from a newly produced bootstrap sample of the training set to ensure that they differ significantly.
36
A classifier tree contains several nodes, each representing a specific condition. It takes either one or zero, resulting in two subnodes, and the variable at each node should achieve maximal homogeneity between the two resulting subnodes. This homogeneity can be quantified in various ways. For categorical classification, the Gini Index is the most popular method, and it is considered a measure of impurity. The Gini Index for node

Where

At the end, the split that maximizes
In classification, each tree releases a unit vote for the most popular class, 37 and then RF assigns a class for each sample by taking the majority of votes from all predictor trees.
Experimental study
Data-set description
This study is dedicated to the detection of bearing faults in varying rotational speed conditions. For this purpose, we opted for the “Bearing vibration data collected under time-varying rotational speed conditions” database, chosen for its significant value in evaluating the efficacy of various methods developed for bearing fault detection. This database provides a diverse array of vibration signals from bearings operating under a range of time-varying rotational speed conditions, rendering it an invaluable resource for assessing the performance of detection techniques in such dynamic scenarios. 38
The dataset utilized in our study is a more recent iteration of the one introduced by Huang and Baddour, 38 released in 2019. This updated database encompasses vibration signals collected from bearings exhibiting five distinct health states and operating under varying time-varying rotational speed conditions. Notably, each health state is subjected to two experimental conditions: specific bearing health states and variable speed conditions.
The bearing’s health conditions are:
Healthy
Faulty with an inner race defect.
Faulty with an outer race defect.
Faulty with a ball defect.
Faulty with combined defects on the inner race, the outer race, and a ball.
The data are acquired under:
Increasing speed
Decreasing speed
Increasing then decreasing speed
Decreasing then increasing speed
For more authenticity, three trials are repeated for each case with a sampling rate of 200,000 Hz for 10 s.
Experimental results and comparative study
The process of our proposed approach for early detection and classification is summarized in the flowchart shown in Figure 2, and it is divided mainly into three steps.
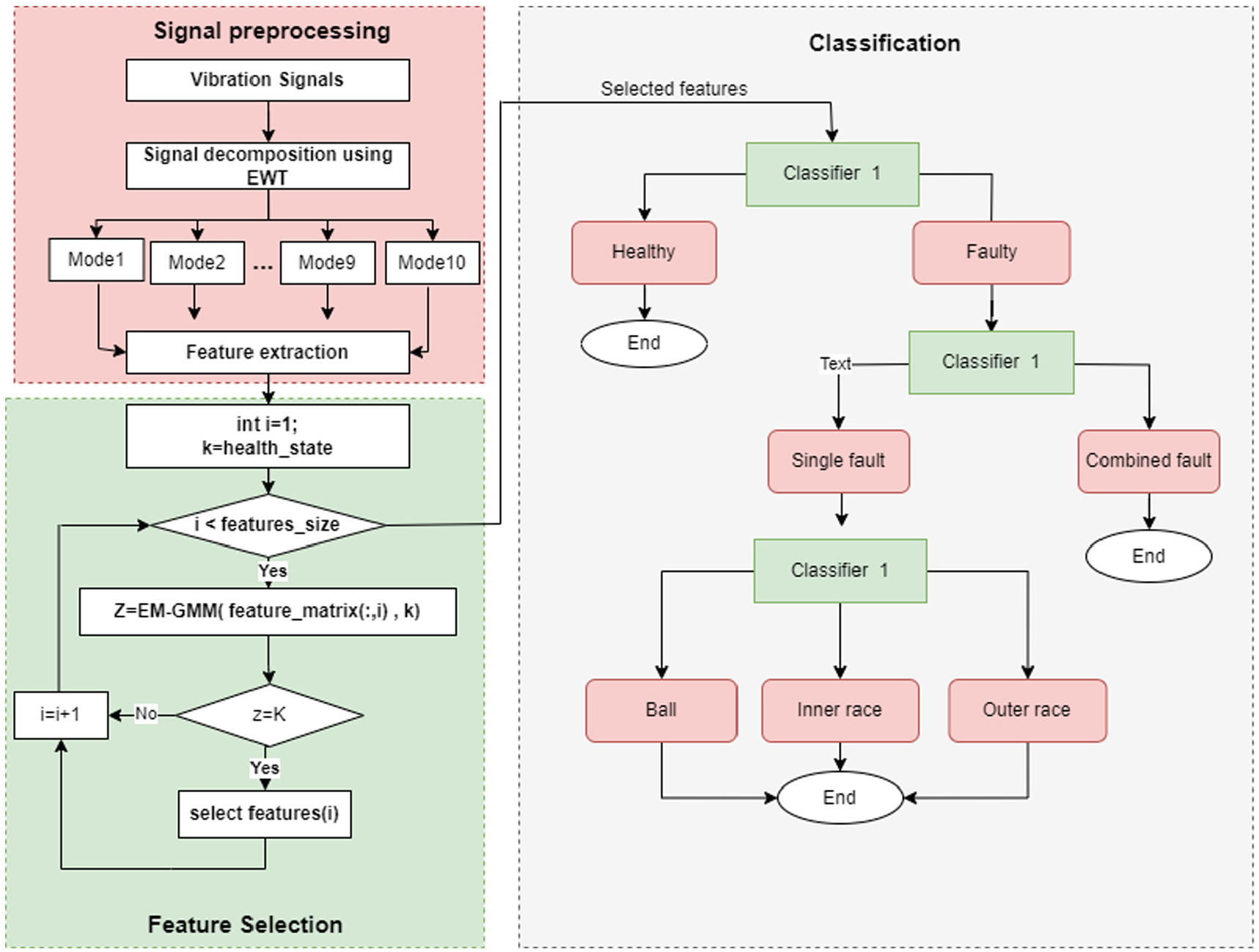
Flowchart of the proposed process.
Our procedure involves three key steps. Initially, we employ the Empirical Wavelet Transform (EWT) to meticulously extract the AM-FM modes embedded within the vibration signatures. This robust technique facilitates a precise decomposition of the signal into a predetermined number of modes. For our investigation, we deliberately selected 10 modes, as illustrated in Figure 3, this specific number of modes was chosen building upon the insights gained from our previous study, 25 which utilized the same database but focused on a classification task involving three health states only instead of the current five, we extensively explored the impact of varying the number of modes extracted using Empirical Wavelet Transform (EWT). Through rigorous experimentation and comparative analysis, we found that employing 10 modes yielded satisfactory classification accuracy and performance metrics results, strategically ensuring effective encapsulation of the vibration signature’s inherent characteristics. Subsequently, we calculate a comprehensive set of features for these 10 modes, as outlined in Table 1, resulting in 170 attributes. This extensive feature set provides a nuanced comprehension of the underlying characteristics of the vibration signature, enabling us to discern subtle changes and patterns that may serve as indicative markers.
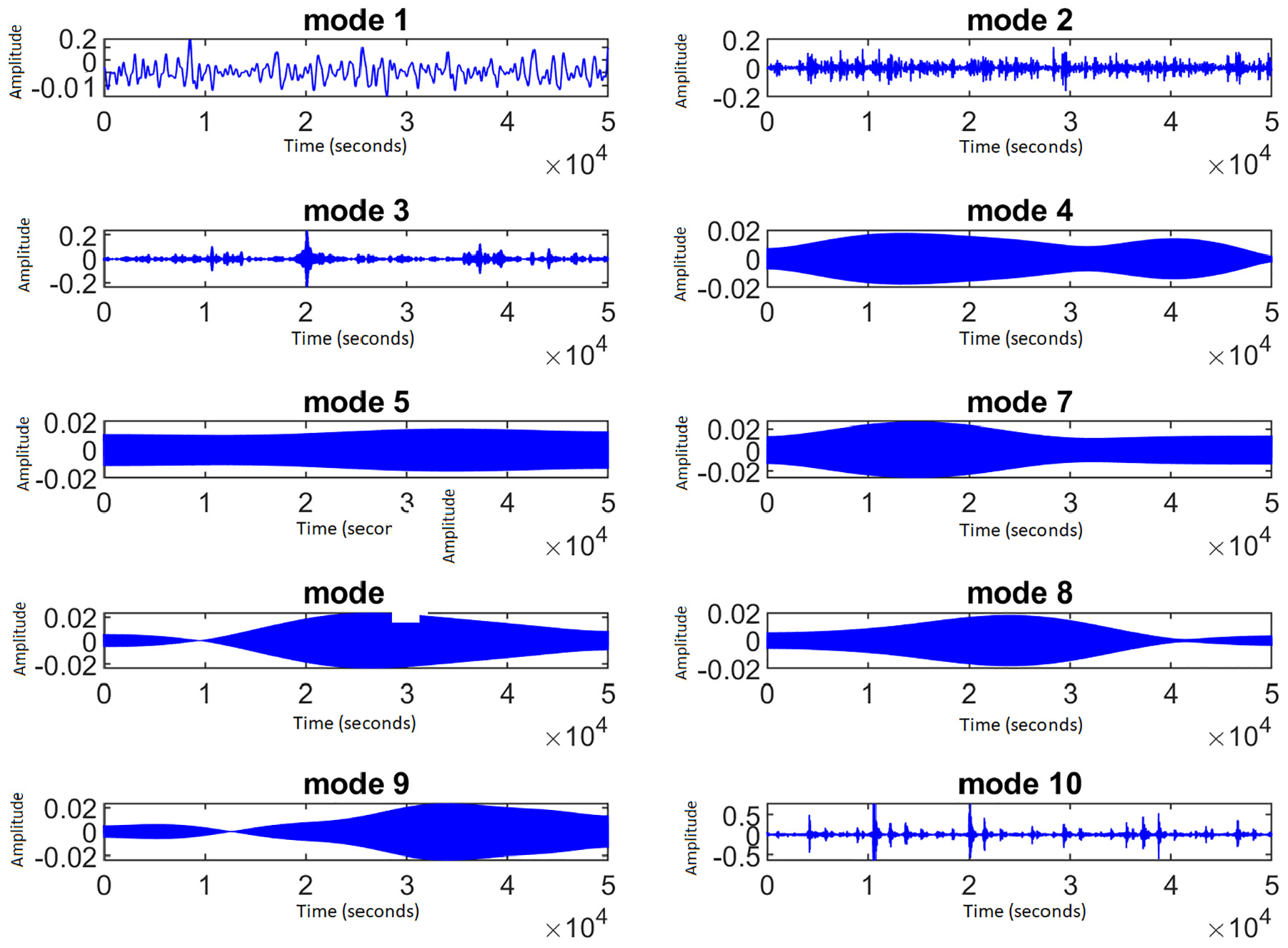
Extracted AM-FM modes using the EWT for bearing with faulty inner race.
Table of extracted features.

In the second step of our methodology, we employ the EM-GMM clustering algorithm to pinpoint the most pertinent set of features for each of the three delineated stages, as depicted in the classification part in Figure 2. This entails a meticulous examination of the data at each level individually, identifying elements that offer optimal differentiation between the various classes. Our approach involves selecting features that precisely distinguish the specific number of groups, a visual representation of which is illustrated in the feature selection part in Figure 2. This iterative process is repeated for each stage, systematically determining the discriminative features tailored to each level. The last step is to use the three selected sets

False alarm detection using binary classification
First, we carry out a binary classification using the Random Forest algorithm for the inner race, outer race, and the ball cases with the selected features by the Gaussian Mixture Model (GMM). The outcome of this process is summarized and presented in Table 2.
Binary classification results.

The results of the binary classification are very accurate. In the second step, the combined fault scenario will be assessed besides healthy data, utilizing a cascade of the three classifiers, as outlined in algorithm 2. The three classifiers should detect the fault for the combined case since the three parts are defective.

Table 3 presents the results obtained from utilizing the binary classifiers for the combined scenario.
Confusion matrices for the combined fault case using the three binary classifiers.

The precision in classifying healthy data remained consistently high across all three models. However, when dealing with combined fault data, the classifiers were tasked with identifying faults within specific components. The ball classifier exhibited flawless performance in detecting damage within the bearing combination involving the ball component. In contrast, the inner race classifier erroneously classified a significant portion of the defective bearing combinations, accounting for 13% of the total data. Similarly, the outer race classifier demonstrated limited proficiency, accurately classifying only 22% of the combined case data.
To gauge the accuracy of the predictions, we calculated accuracy by summing the true positives and true negatives and then dividing by the size of the predicted data. The resulting accuracy is 35%. This accuracy underscores the classification’s failure to detect the combined fault case.
Multi-stage classification
To showcase the effectiveness of our proposed procedure illustrated in the classification part of the flowchart Figure 2 and to simultaneously enhance accuracy and stability ratings for each scenario, we implemented a multi-stage classification approach using a random forest classifier and EM-GMM optimization algorithm for early detection and classification.
The initial stage involves classifying bearings into healthy and faulty categories. The subsequent stage determines whether the fault is singular or combined, and the final level focuses on localizing the defective element.
To initiate the process, we select features for the three stages depicted in the classification step in Figure 2 using the Gaussian Mixture Model (GMM). To showcase the efficacy of the GMM clustering algorithm in this selection process, we conduct a comparative analysis with widely-used optimization algorithms in bearing diagnosis tasks.
Table 4 presents the accuracy results of feature selection for the three stages, employing various optimization algorithms including EM-GMM, Simulated Annealing (SA), Grasshopper Optimization Algorithm (GOA), Grey Wolf Optimization Algorithm (GWO), Squirrel algorithm, and Clan-based Cultural Algorithm (CCA). The evaluation is performed using the Random Forest classifier, utilizing the holdout cross-validation method, and repeating the process 10 times to unveil any hidden variance across the 10 folds. The data are randomly divided into 90% for training and 10% for testing in each iteration.
Performance of optimization algorithms in different stages.

The findings in Table 4 underscore the superiority of the EM-GMM method over other optimization algorithms in terms of accuracy and stability. The achieved accuracy consistently hovers around 100% across all three cases, while the standard deviation (STD) remains nearly zero.
After training the three models, we cascade them as shown in the classification part of the flowchart in Figure 2 to classify the five states of the bearing. While this method has achieved a notable 100% accuracy rate, it’s essential to note that this accuracy becomes significant only when each class has an equal number of samples, which may not always be the case. Consequently, relying solely on this metric may not provide a comprehensive measure of the classifier’s performance.
To address this limitation, we introduce the Polygon Area Metric (PAM). 39 Unlike the conventional Classification Accuracy (CA), PAM incorporates five additional metrics, namely Sensitivity (SE), Specificity (SP), Area Under Curve (AUC), Jaccard index (JI), kappa (K), and F-measure (FM). These metrics collectively contribute to a more nuanced evaluation of the classifier’s performance, considering various aspects of its effectiveness. The parameters defining the Polygon Area Metric are as follows:





The Polygon Area Metric (PAM) calculates the area of a hexagonal shape formed by points representing the metrics CA, SE, SP, AUC, JI, and FM. This hexagon maintains a regular shape with six sides. For normalization, we divide the area by
Table 5 showcases the outcomes of the multi-stage classification procedure, evaluated using the Polygon Area Metric (PAM), across three distinct scenarios: employing all features, utilizing the selected elements, and incorporating the unselected elements. Figure 4 offers a more comprehensive visualization of the results, distinctly demonstrating that the classification utilizing the selected features attains the highest level of performance.
Polygon Area Metric parameters.


Polygon Area Metric for classification results using: (a) the selected features, (b) using all features, and (c) unselected features.
Conclusion
The imperative nature of bearing fault diagnosis highlights the demand for innovative methodologies, especially in addressing non-stationary conditions. This study introduces a robust multi-stage classification process meticulously designed for identifying combined faults in dynamic, time-varying scenarios, it represents a novel approach to addressing the complexities of bearing fault diagnosis, particularly under variable speed conditions. By breaking down the diagnostic process into stages, we effectively navigate the challenges associated with combined faults and variable operating speeds, providing a more robust and accurate diagnostic solution. We commence our method by decomposing vibration signatures from the “Bearing vibration data collected under time-varying rotational speed conditions” database containing five bearing health states, including a combined fault case to demonstrate the practical applicability of our approach in real-world industrial settings. This validation underscores the effectiveness of our method in addressing the challenges of speed variability and combined fault recognition, which are commonly encountered in machinery operations. We utilize for the signal processing the Empirical Wavelet Transform (EWT) to extract AM-FM modes and derive parameters spanning both time and frequency domains. In the subsequent phase, we employ the Expectation-Maximization Gaussian Mixture Model (EM-GMM) clustering method to select features adept at accurately discerning the precise number of fault classes. Subsequently, we trained classification models for each level utilizing the random forest classifier on the selected features for each stage. A meticulous evaluation employing the Polygon Area Metric (PAM) with six distinct parameters underscores the efficacy of our proposed procedure in adeptly detecting combined defects, even under challenging conditions.
The observed performance increase is due to inheriting several factors in the proposed method. Firstly, we opted for a stage classification approach instead of employing a single classifier for the entire task by utilizing three distinct trained random forest models, each dedicated to a specific stage of the diagnostic process. This division of labor allowed for more focused and specialized processing at each stage, leading to improved performance in fault diagnosis. Furthermore, the selection of features played a crucial role in enhancing the effectiveness of the proposed method. We employed an unsupervised feature selection algorithm to ensure the inclusion of discriminative and informative features. This approach allowed us to identify and prioritize the most relevant features from the input dataset without relying on labeled training data. By focusing on the extraction of robust and representative features, we were able to streamline the diagnostic process and enhance the discriminative power of the classifier ensemble.
Footnotes
Handling Editor: Aarthy Esakkiappan
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.