
Abstract
TBM tunnel surrounding rock classification is a key indicator for supporting decision-making and ensuring safe construction. And predicting the surrounding rock type accurately in advance is of great significance for TBM intelligent construction. This paper established the surrounding rock classification model based on support vector machine (LIBSVM), including preprocesses historical tunneling parameters, extracts data information that can accurately reflect the relationship between rock and machine, analyzes the correlation between different parameters and surrounding rock categories, and obtains highly relevant parameters. Based on the long short-term memory (LSTM), the prediction model of total thrust, cutter head torque, gripper pressure, cutter head rotate speed, and propulsion speed are established, which is the strongly correlated parameters with surrounding rock. Combining the parameter prediction model with the surrounding rock classification algorithm, the LSTM-SVM tunnel surrounding rock classification prediction model is established. The results showed that the coefficient of determination of the total thrust model, the cutter head torque, the gripper pressure, the cutter head speed, and the propulsion speed were 0.9825, 0.9396, 0.9974, 0.9843, and 0.9636. The overall prediction accuracy of the surrounding rock category can reach 86.0686%, which can provide a certain reference for predicting the surrounding rock condition in a short distance.
Keywords
Introduction
TBM is a kind of large-scale digital tunneling equipment, which is widely used in subways, water conservancy, highways, railways tunnel construction.1–3 In the process of TBM construction, the type of surrounding rock is the key index of surrounding rock stability evaluation and tunneling performance prediction.4,5 Predicting the surrounding rock classes accurately within a short distance is very helpful for the workers to formulate corresponding supporting measures in time. Moreover, the workers can conduct operation adjustment and preparation in time according to the judgment of geological conditions ahead. Therefore, it is of great significance to improve the TBM construction safety and effectiveness.
The traditional tunnel surrounding rock class is based on the data obtained from the current rock mass property test or various parameters through calculation, which cannot be directly predicted. At present, in terms of the research on the prediction of related properties of surrounding rocks of TBM tunnel at home and abroad, Liu et al. established an empirical model for TBM performance prediction of hard rock based on HC multiple regression analysis. According to the engineering data of different tunnels.6,7 Jamshidi established regression analysis prediction model of TBM cutting depth and surrounding rock brittleness index by using multiple regression analysis. 8 Yagiz et al. respectively adopted intelligent methods such as fuzzy recognition, neural network, and particle swarm optimization to establish the prediction model of TBM excavation rate and rock brittleness index. 9 Qiu et al. proposed an advanced classification method of surrounding rock class based on TSP203 system and genetic support vector machine. 10 Gao et al. used three circulatory neural networks to predict TBM boring parameters. 11 Wang et al. combined with large number of tunneling data, obtained that the cutter head torque has a significant correlation with the surrounding rock class, cutter head speed, and propulsion speed. Based on this, the prediction model of cutter head torque NSVR was established. 12 Zheng et al. used particle swarm optimization algorithm to optimize the support vector machine algorithm, and established a prediction model of tunneling load based on operation parameters. 13 Yu et al. has applied a novel semi-supervised method to establish the rock mass type prediction model ahead of the tunnel face. 14 Xu et al. predicted TBM operational indicators using various statistical, ensemble, and deep neural network machine learning methods, and compared the merits and demerits between different method. 15 Fu and Zhang put forward a spatio-temporal approach to forecast TBM’s penetration rate based on deep learning model. 16 Wang et al. proposed a parameters prediction framework for TBM thrust, torque, and net advance rate based on machine learning method. 17 Huo et al. established an advance prediction model of the rock mass category (RMC) with 99% prediction accuracy. 18 Feng et al. introduced Field Penetration Index to quantify TBM performance using big data and deep learning. 19 Kilic et al. used SMOTE method to identify TBM lithology through operational parameters, respectively. 20 And Heydari et al. investigated the relationship between various TBM operational factors. 21
In conclusion, these researches mainly focus on the prediction of single rock mass indicator and tunneling load during TBM tunneling. While relatively few studies on the prediction of surrounding rock class. Traditional research of surrounding rock classification is based on the characteristics of rock mass, whose prediction accuracy and timeliness are poor as the difficulty in obtaining related indexes and limited samples. The TBM operational parameters of TBM during construction process are affected by the types of surrounding rocks, which are all strictly sequential over time. Therefore, it is a time-efficient and accurate method for surrounding rock classification through TBM operational parameters. In terms of the parameter prediction using engineering data, most studies are focused on the selection and optimization of operational parameters. There are few researches on TBM operational parameters and surrounding rock classification prediction. Most of sample sets are small and some data are experimental data rather than actual engineering data. While a large number of sample data are required for machine learning method to establish a more accurate prediction model. So, it may be feasible that predicting the type of surrounding rocks based on the predicted TBM operational parameters by means of machine learning method.
In this paper, combined with the historical excavation data of TBM, the statistical analysis is carried out to obtain the characteristic parameters. Based on the support vector machine algorithm in machine learning LIBSVM, the surrounding rock classification is realized. Then, based on the long-term and short-term memory network, the characteristic parameter prediction model is established, and combined with the surrounding rock classification algorithm, the LSTM-SVM short-distance surrounding rock class prediction model is established to realize the prediction of the surrounding rock class model of TBM tunnel in the tunneling process.
Methodology
The primary objective of the paper is to establish an intelligent prediction model for TBM tunnel surrounding rock classification based on the corresponding relationship between the operating parameters and rock classification. Figure 1 shows a flow chart of the prediction process formulated for the study. The process is divided into five steps: (1) collecting the original TBM data from TBM acquisition system for each tunnel ring, including all monitoring information during TBM operation. (2) Pre-processing the data to ensure clear and consistent results, including extracting the operating parameters in stable tunneling state, calculating the mean and variance of the data, and analyzing the correlation between data. (3) Establish the surrounding rock classification model according to TBM operating parameters sample set and rock mass class labels. (4) Establish the tunneling parameters prediction model based on the TBM operating parameters sample set. (5) Establish the surrounding rock class prediction model combing the surrounding rock classification model with tunneling parameters prediction model. Conducting five steps can achieve real-time prediction for the surrounding rock classification.

Flow chart for prediction of TBM surrounding rock class
Establishment of the database
Geological conditions project overview
The data in this paper came from the main tunnel construction project with a total length of 19.87 km. An open TBM is used with excavated diameter of 7.0 m. The construction section of the project contains class II, class III, class IV, and class V surrounding rocks. The lithology of the surrounding rock is mainly tuff and tuff breccia, which are all hard rocks. The various surrounding rocks data provides a good data base for subsequent research. Based on the Basic Quality method, the exposed surrounding rocks of each ring are classified and matched with the tunneling parameters. The proportion of the collected surrounding rock class data is shown in Figure 2, where class II rock accounts for the largest proportion with 57.1%, and class IV takes up the minimum with 2.78%.

Proportion of surrounding rock class data.
Engineering data preprocessing
The original data only the data collected in the stably advancing status can represent the interaction between rock and TBM machine. While the collected data in the abnormal tunneling conditions has a negative impact on the establishment of classification model. Therefore, in order to ensure the accuracy of the model training, the data filtration should be carried out before modeling, which including filtering data in non-tunneling status, filtering data in start-up and shut-down status, and filtering data in abnormal tunneling status.
(1) Filtering data in non-tunneling status
In the process of TBM construction, gripper change in step, surrounding rock support, cutter replacement, and machine maintenance all should be conducted with no advancement of TBM. Therefore, it is necessary to remove the data in these statuses, which is valueless for the analysis of the surrounding rock class. Then, filtering is carried out according to the binary discriminant function proposed by Wang et al. 12



Where, f is a binary discriminant function, D values in 0 or 1,
(2) Filtering data in start-up and shut-down status
The normal tunneling of TBM consists of start-up status, stable tunneling status, and shut-down status. Start-up and shut-down status contain acceleration and deceleration stages in each TBM operating cycle. These unstable data should be eliminated which may cause interference to the classification prediction of surrounding rocks. The data in start-up and shut-down status are culled according to the following rules: if the interval time between two breakpoints is less than 300 s, all data between two breakpoints are culled; if the interval between two breakpoints is more than 300 s, the data within 200 s after the start-up point and within 60 s before the stop point are eliminated. The curves of advance speed change with time a certain period before and after elimination processing is shown in Figure 3.
(3) Filtering data in abnormal tunneling status

Diagram of propulsion velocity over time: (a) before filtering and (b) after filtering.
Filtering data in abnormal tunneling status is conducted according to the abnormal value of penetration. The penetration in normal tunneling status is mainly distributed between 0 and 32.7 mm/r. the penetration data is divided into groups according to the size, where the size distribution and cumulative percentage are shown in Figure 4.

Distribution of penetration data.
It can be seen from Figure 4 that the average value in the tunneling status is 6.95 mm/r, which basically presents normal distribution. The data with penetration less than 13 mm/r account for over 97%, and the maximum penetration is 32.7 mm /r, which is obviously abnormal. Therefore, the data with penetration above 13 should be filtered.
Correlation analysis between operating parameters and surrounding rock classes
The data set recorded by TBM includes hundreds of types of data, many of which have no relation with TBM tunnel and geological parameters. These data should be excluded to reduce computation and improve accuracy of surrounding rock classification model. Therefore, it’s necessary to select the operating parameters closely related to the surrounding rock classes from the data set. So, the correlation direction and degree between different boring parameters and surrounding rock classes are discussed, and the parameters with high correlation are selected as data samples of the classification model.
The correlation coefficient is a quantity representing the degree of linear correlation between variables, which is represented by
Variation range of correlation coefficient and its meaning.
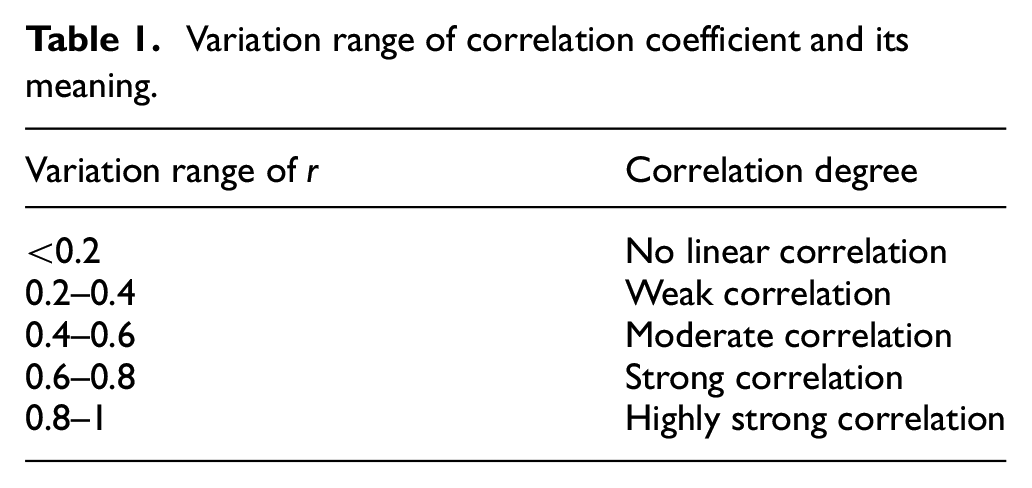
In this paper, Pearson correlation coefficient is selected to calculate the relationship between parameters and surrounding rock classes.

Where,
The detailed characteristics of TBM operating parameters are analyzed based on Pearson correlation coefficient, and the correlation between TBM operating parameters and the surrounding rocks of Class II, III, IV, and V is obtained. The parameters above with strong correlation are shown in Table 2.
Correlation analysis between different parameters and surrounding rock classes.

Surrounding rock classification model based on LIBSVM
Classifier selection
In order to realize the classification of surrounding rock more accurately, it is necessary to select the classifier with high performance. Firstly, the classifier needs to perform well in a certain number of training sets and avoid overfitting to the greatest extent. Secondly, the classifier should have the ability to classify samples in a non-linear manner when dealing with geological data in different alternate surrounding rock classes. SVM has strong generalization ability and high robustness, which is selected from many machine learning methods.20–22 The LIBSVM is used to deal with multi-classification problems by means of voting. Its basic idea is to construct N(N−1)/2 class two classifiers out of N categories, and identify test samples using voting method. Compared with other multi-class support vector machine algorithms, LIBSVM has the advantages of fewer sub-classifiers and shorter training time.
Feature extraction and selection
Extracting and selecting appropriate feature parameters from the original parameters not only reduces the computational overhead, it also significantly improves the performance of the classifier, both of which are significant for an accurate identification of the surrounding rock class. In order to accurately reflect the condition of the surrounding rock, the time per revolution of the cutterhead is used as the time window. The cutterhead rotate speed range from 1 to 7.7 rpm, so the time window is set as 60 s, which is the lowest value of the rotation speed. It indicates that every 60 pieces of feature parameters in the time domain are taken as a sample to construct feature vector. Based on the analysis of the correlation and change rule of operating parameters and surrounding rock classes, feature vectors [x1, x2, x3, x4, x5] is finally selected as the input vector for training and test, where denotes the average total propulsive force, the average cutter head torque, the average gripper pressure, the average cutter head rotation speed, and the average propulsion speed, respectively.
Surrounding rock class prediction model based on LSTM-SVM
LSTM method
TBM operating parameters change with time and are non-stationary time series. And because the output of traditional machine learning methods such as support vector regression or random forest is only determined by the current input without the help of previous learning information, they are also not suitable for real-time prediction of TBM tunneling parameters. 11 These traditional regressions models cannot act as real-time predictors in a practical sense, because they only reflect the mapping relationship between current parameters and input parameters, which is close to function fitting and cannot provide prediction values of operating parameters based on in situ data in the next period. In recent years, due to the rapid development of neural network, a variety of deep learning algorithms (such as recurrent neural network and convolution neural network) have been produced. Among them, recurrent neural network, namely RNN, can add a variety of gate operations to improve the training ability and efficiency. It is one of the most powerful tools to predict non-stationary time series, and the prediction effect is far better than the traditional machine learning method.
Recurrent neural network (RNN) has a cyclic structure, in which the previous output of hidden nodes is used to generate the response of the current input, so it is usually used to process the prediction task where the input samples are time series. Its source is to characterize the relationship between the current output of a sequence and the previous information. From the network structure, the recurrent neural network will remember the previous information and use the


Where,

Where,
Long-term memory unit LSTM (Long Short-Term Memory)
23
combines three kinds of gate operations in its hidden node, including input gate, forget gate, and output gate, whose unit structure is shown in Figure 5. Its state is divided into two vectors: short-term state

Basic cell structure of LSTM.
Formulas (8–13) summarize how to calculate the long term state, short term state, and output of a unit in a single instance at each time iteration.
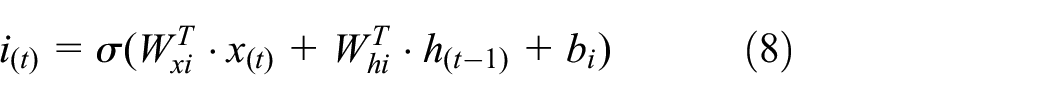



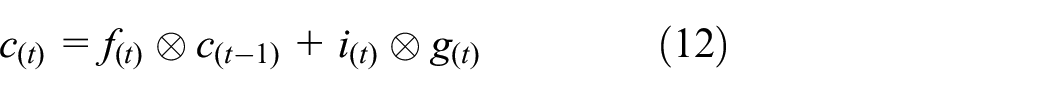

Where,
Data preprocessing and model evaluation indexes
By performing feature extraction on the original tunneling data of each parameter, the new sample sequence is established as 38,400. Then, the sequence is divided into two time-continuous subsequences: the first 90% and the last 10%. The former is used to train the prediction model and the latter is used as a test set. Secondly, in order to improve the prediction accuracy, reduce the training time of the model, and avoid the influence of the different dimensions of each data on the LSTM network model, the Z-score method is used to standardize the data vector based on the time series data of tunneling parameters. The input data vector is normalized to a standardized sequence with a mean of 0 and a standard deviation of 1. The standardized expression as shown in (14):

Where,
Regression (prediction) model has many evaluation indexes, which can directly reflect the accuracy of prediction results. Based on the research of a large number of time series prediction, Root Mean Square Error (RMSE), Mean Absolute Percentage Error (MAPE), and Coefficient of Determination (R2) are chosen as the evaluation indexes of the accuracy of prediction results.
(1) Root Mean Square Error:

(2) Mean Absolute Percentage Error:

(3) Coefficient of Determination:

Where, N represents the number of prediction samples,
Prediction model of operating parameters
Predicting the five TBM tunneling parameters should be conducted before establishing the surrounding rock prediction model. Parameter prediction model based on LSTM network includes: input layer, LSTM layer with 288 nodes, fully connected layer and output layer with 1 node (logistic regression layer). The network uses the Adam optimization algorithm to optimize the loss function, which is different from the stochastic gradient descent algorithm (SGD) used in the traditional BP neural network. It combines the characteristics of adaptive optimization algorithm (AdaGrad) that is sensitive to sparse matrix information and RMSprop algorithm that has good convergence to the unstable objective function, while adding a momentum term to avoid the search direction swings, speed up the convergence. Adam optimization algorithm also has the advantages of simple adjustment of super parameters such as learning rate and suitable for large-scale data and application. In the network model, the number of iterations, the gradient threshold, and the initial learning rate is set as 250, 1, and 0.005, respectively. Moreover, the learning rate decline cycle and decline factor is set as 125 and 0.2 respectively. The whole process of training is shown in Figure 6.

LSTM network flowchart for parameter prediction.
Before establishing the prediction model, it is necessary to transform the data of the training set. The historical operating parameters of a certain time step is taken as the input variables, and the parameter value of the next time step is taken as the output variables. It indicates that the previous boring parameter data

It means that when a time-continuous sequence of five operating parameter data are input to the trained LSTM-based predictor f, the five operating parameter value in the next time
Experiment results
Establishment of the database
Because the surrounding rock classification model takes every 60 data in the time domain as a sample and its mean value or standard deviation is taken as the feature for recognition, the direct prediction of 60 data in the next minute cannot reflect the characteristics of the sample well, which will increase the error of prediction result. To solve this problem, the characteristics of each sample should be predicted directly. First of all, preprocess the data, take every 60 s as a sample, extract its mean value and other features, and re-establish the sample set for training and testing. Taking the total thrust as an example, Figure 7 is the original effective thrust data, and Figure 8 is the new sample set established after feature extraction. It can be seen from figures that the sample set after feature extraction can reflect the change rule of total thrust with time, without changing its characteristics in time domain. Therefore, the new sample set can also reflect the change rule of surrounding rock class. It’s effectively to improve the prediction accuracy of surrounding rock class by using the feature values of operating parameters to directly identify the feature values of the next stage.

Original boring data of total thrust.

Total thrust boring data after feature extraction.
Training based on LIBSVM model
Four thousand sets of feature vectors [x1, x2, x3, x4, x5] of different surrounding rock classes are extracted from the original operating parameters, where each class have 1000 sets. The values 1, 2, 3, and 4 are used to define the output of the four classes of surrounding rocks: II, III, IV, and V, respectively. In order to uniform the variation range of each feature value in the feature vector, all feature values are normalized and linearly transformed into [−1, +1]. Then, 4000 sets of feature vectors and corresponding surrounding rock classes construct the sample set. According to the recommended ratio widely used in machine learning research, the sample set is randomly divided into two groups with a ratio of 6:4.
The LIBSVM model is used to train and test the sample set. According to the design experience and recognition results, the radial basis function is selected as the kernel function of LIBSVM. In addition, the kernel function parameters γ and penalty coefficient

Ten-fold cross-validation results of LIBSVM (using training set).
The classification test results of the model are shown in Figure 10, in which 1–400 are class II, 401–800 are Class III, 801–1200 are class IV, and 1201–1600 are Class V. Table 3 shows the identification results of the LIBSVM model. The overall recognition accuracy reaches 92%, which can better classify the surrounding rock of the TBM tunnel.

Recognition results of test set classification.
The classification test results of LIBSVM (confusion matrix).

Training of the prediction models for each feature parameter
Establishment and verification of the total thrust prediction model
In order to investigate the influence of input window width on the prediction accuracy for the total thrust prediction model, the total thrust prediction model with different input window width has been established. The size of the input window is set as 1, 3, 5, 10, 30, respectively. The total thrust data training set is input into the model. The loss function of the training step is calculated after completing the forward propagation process. Then, the weight parameters are updated by the Adam optimizer until the training ends to output the network model. The test set data is input into the network for model prediction, and the optimal value is selected as the input window of the total thrust prediction model through the prediction results and model evaluation indexes. The test is carried out based on above settings, and the predicted results of the model are shown in Figure 11. The influence of window width on total thrust prediction error is shown in Table 4.

Test accuracy of the total thrust prediction model with different window widths.
Influence of window width on total thrust prediction error.

As can be seen from Figure 11, R2 first increases and then decreases with the increase of the input window width of the model, and the prediction accuracy is the highest when the window width is 3, reaching 0.8616. With the increase of the input window width of the model, MAPE decreases first and then increases, and the smallest error is 3.1007% when the window width is 3. The RMSE rule is the same as the above two indexes. Comprehensively considering the three evaluation indicators, the input window width of the total thrust prediction model is selected to be 3.
In order to study the overall prediction effect and stability of the model, 3840 sample size test set is used to test the model, and sample is input, where the sliding window width is 3. In indicates that
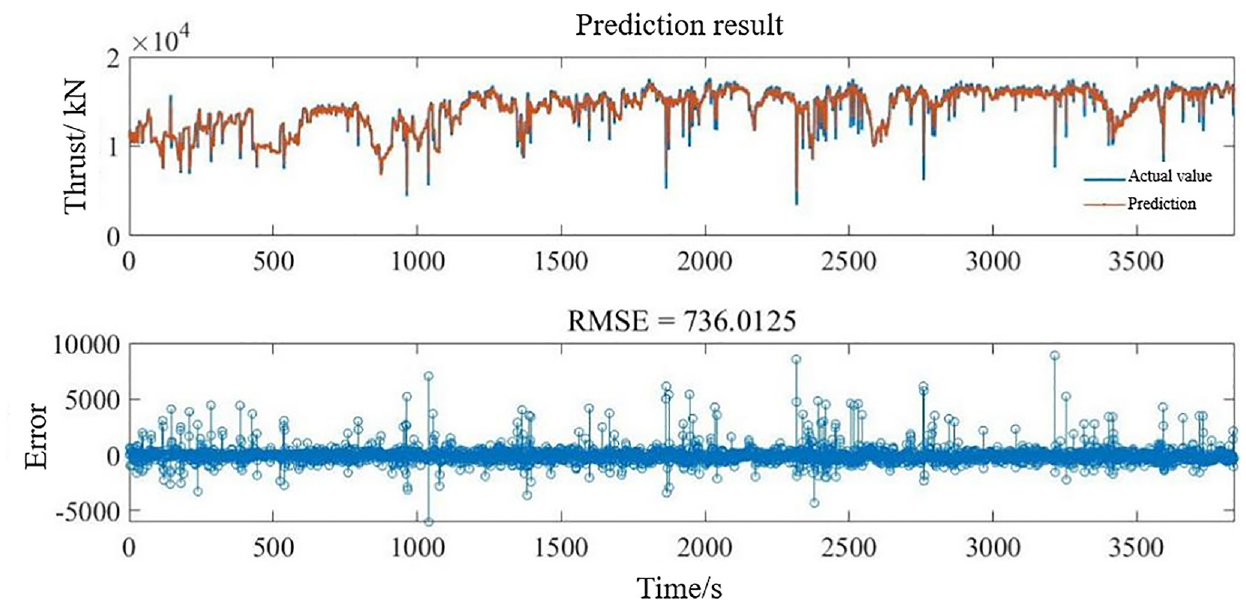
Prediction result of total thrust.
Figure 12 shows the comparison and error between the predicted data and the actual data of the total thrust test set, where the determination coefficient, MAPE, and RMSE is 0.8616, 3.1352%, and 736.0125. It can be seen from Figure 12 that the prediction error at the time of thrust value mutation point is relatively large. It may be caused by geological conditions, artificial operation, and other objective reasons. Moreover, the large total thrust value may result in parameters fluctuate greatly in a certain period of time to obtain inaccurate prediction. Overall, the predicted value is roughly the same as the actual value.
Establishment and verification of other parameter prediction models
The other four parameters are modeled and optimized by the above method. The influence of the input window width of each parameter prediction model on the prediction accuracy is shown in Figure 13, and influence of window width on prediction error is shown in Table 5. The optimal input window width and test accuracy of test set for each parameter are shown in the table, and the prediction effect is good.

Test accuracy of each parameter prediction model with different window width: (a) cutter head torque, (b) gripper pressure, (c) cutter head speed, and (d) propulsion speed.
Test results of other parameters prediction model.

Test of LSTM-SVM surrounding rock class prediction model
After the prediction model of five parameter characteristics is established, the prediction of surrounding rock class can be carried out. The data within the length of pile 2 + 500.0 to pile 2 + 710.0 were selected for testing because the surrounding rocks under this length includes class II, Class III, and Class IV. Among them, 2 + 500.0–2 + 610.0 + 635.0 is class II, 2 + 610.0–2 + 635.0 is class IV, and 2 + 635.0–2 + 710.0 is class III. It can verify the accuracy of the model as maximum as possible. According to the prediction process, firstly, extract the characteristics of the five kinds of boring parameters under the mileage, and then input them into the model according to their respective window widths for prediction. The prediction results are shown in Figure 14. Among them, the determination coefficient of the total thrust model is 0.9825, the cutterhead torque is 0.9396, the gripper pressure is 0.9974, the cutterhead rotate speed is 0.9843, and the advance speed is 0.9636. And the prediction effects are all good.
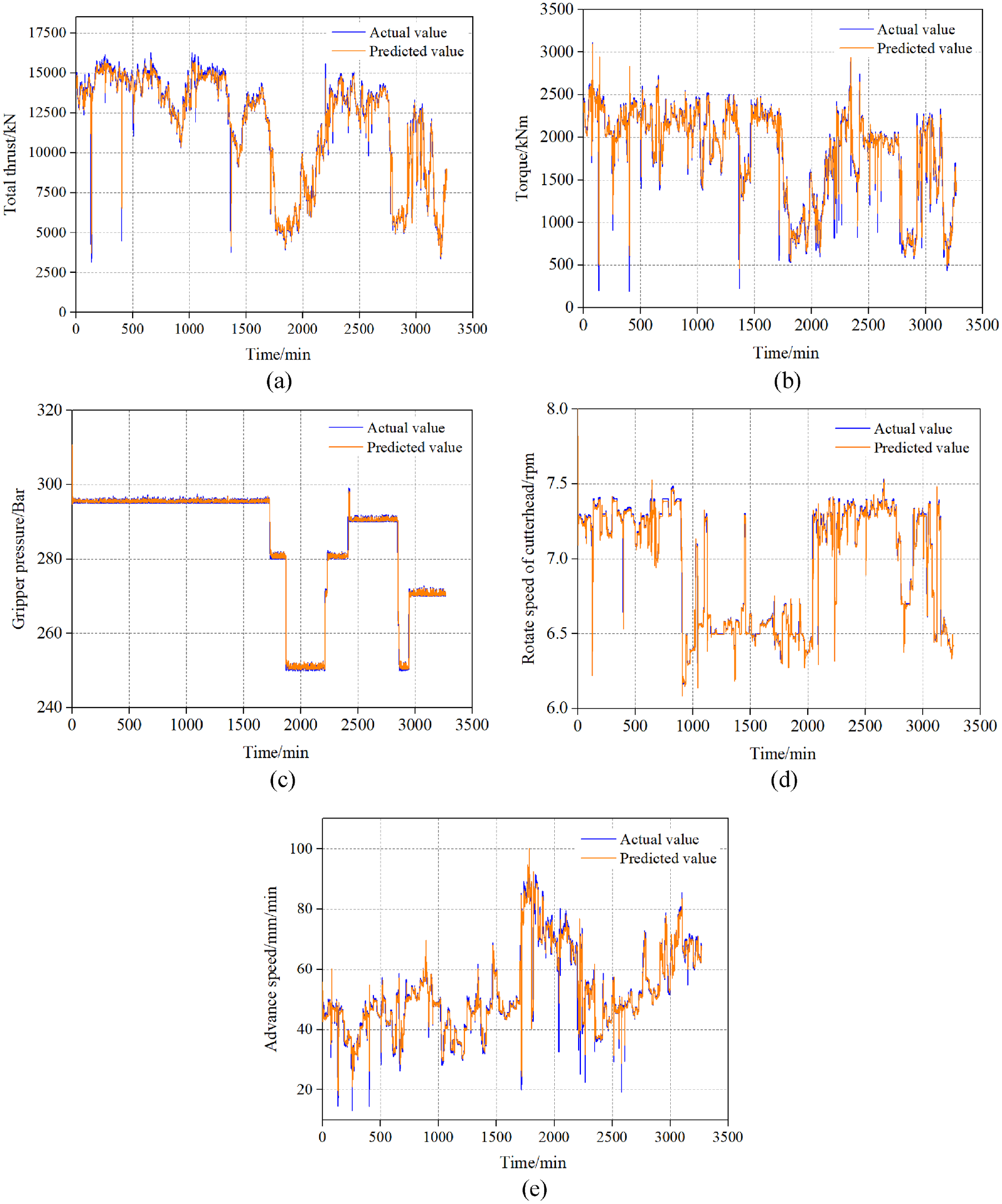
The prediction of five parameters: (a) total thrust, (b) cutter head torque, (c) gripper pressure, (d) cutter head speed, and (e) propulsion speed.
The surrounding rock is classified according to the prediction results of parameter feature values, and the results are shown in Figure 15(a). It can be seen that the overall prediction accuracy of the surrounding rock class prediction model can reach 86.0686%, which can provide reference for the prediction of the surrounding rock condition in the next stage. In order to further determine the source of the error, the actual value under this mileage is also substituted into the model for recognition. The result is shown in Figure 15(b), and the recognition accuracy is 87.0178%, which is similar to the prediction accuracy. Table 6 shows the identification prediction results of the surrounding rock classification using actual operating parameters. Therefore, the main error of the prediction model is the recognition error of the classification model, instead of the prediction effect of each parameter.

The prediction results of the surrounding rock classification: (a) predicted operating parameters and (b) actual operating parameters.
The prediction results of the surrounding rock classification using actual operating parameters. (confusion matrix).

Conclusions
In this study, an intelligent prediction method for the surrounding rock classification model was proposed based on the TBM operating parameters. The prediction process consists of four steps: firstly, total thrust, cutterhead torque, gripper pressure, cutterhead rotate speed, and cutterhead advance speed are selected from the original data of TBM, through eliminating non-boring state and abnormal segment data and analyzing the correlation between each parameter and surrounding rock class. The feature vector of classification model is established, which is composed of the mean value of five operating parameters in each 60 s time window. Secondly, the LIBSVM is used for train and test of the classification model by means of 10-fold cross-verification method. The results show that the optimal penalty coefficient is 0.35, kernel parameter is 0.1768, the training accuracy of using this set of parameters is 98.25%, the accuracy of the test set is 92%. High accuracy of the test proves that the performance of LIBSVM algorithm is excellent. Thirdly, prediction model of five operating parameters is established based on LSTM network. The relationship among the prediction accuracy and time window width were studied, and the optimal input window width of each model has been verified by the test set. The results show that the decision coefficient of the total thrust model is 0.9825, the cutterhead torque is 0.9396, the gripper pressure is 0.9974, the cutterhead rotate speed is 0.9843, and the cutterhead advance speed is 0.9636. Finally, the LSTM-SVM model for the tunnel surrounding rock classification prediction is established, combining the parameter prediction model with the surrounding rock classification algorithm. The overall prediction accuracy of surrounding rock classification can reach 86.0686%. It can provide a prediction-based control method that operators can regulate the TBM operating parameters and formulate corresponding supporting measures beforehand rely on the surrounding rock classification prediction result. It can improve tunneling performance and safety of the TBM construction.
Footnotes
Handling Editor: Sharmili Pandian
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Special funding support for the construction of innovative provinces in Hunan Province (2019GK1010).