
Abstract
Active suspension provides better vehicle control and safety on the road with optimal driving comfort compared to passive suspension. Achieving this requires a good control system that can adapt to any environment. This article uses a deep reinforcement learning method to develop an optimal neural network that meets the comfort requirements according to ISO 2631-5 standards. The algorithm trains the agent without any prior knowledge of the environment. Various simulations were performed, and the results were validated with the literature and the standard until the appropriate reward function was found. Simple and consistent road profiles were used while maintaining constant system parameters during training. The results show that suspension based on deep reinforcement learning reduces vehicle body acceleration and improves ride comfort without sacrificing suspension deflection and dynamic tire loading. The controller expects the RMS value of the acceleration to be 0.228 with a minimum overrun of the suspended mass.
Keywords
Introduction
Passenger safety and comfort, as well as the safety of the load carried by the vehicle, are some of the greatest concerns of researchers and manufacturers of heavy goods vehicles. This is evident from the amount of research published throughout this decade. 1
The shock absorber is the centerpiece that plays the role of a conductor in the suspension system, which tries to harmonize movements to maintain the maximum possible stability without sacrificing safety. There are three types of suspension systems: active, semi-active, and passive. Each of these systems offers benefits and drawbacks. For instance, the passive suspension offers appropriate performance in a restricted frequency range, while the semi-active mechanical system changes the coefficient by changing the viscosity of the shock absorber, making it efficient in a wide frequency band. However, the technique is limited, hence the need for a suspension system that has highly modular dynamic behavior, which is the active suspension. In this suspension system, we find a spring, a shock absorber, and an actuator that exerts an adaptive counter-force to meet the requirements of stability and safety.
The actuator control is the most delicate phase in an active suspension system, which requires a good servo system, such as commonly used controllers like PID, LQR, etc. Engineers are not strictly limited to using one of these types, and they are free to develop or merge control techniques to have a more optimal custom solution. According to studies, there is no perfect solution, but we can achieve good results. However, the complexity of systems increases, and added external influencing factors (like the behavior of the road) can cause the regulator to lose its performance.
Hence the refuge toward artificial intelligence, which makes it possible to predict the behavior of the shock absorber and react accordingly to the state, is a kind of imitation of the behaviors of living beings. For example, the reference Salem and Aly 2 showed that Fuzzy Logic, an approach used in AI (artificial intelligence), works better than PID in the daily model grounded on two types of road conditions.
Neural networks can be combined with several traditional controllers like Proportional integral-derivative (PID), Linear-quadratic regulator (LQR), etc., and the neural network aims to detect road roughness to improve the performance of these traditional controllers by varying their parameters according to road conditions.3,4
However, the neural network is rarely used as a controller itself. Despite many motivating trials, such as the one that trained its neural network with an optimal classical controller, the results show that the performance of neural networks exceeds that of traditional controllers. 5
Another method of reinforcement learning (or machine learning) has recently been used in various fields such as economics, games, aviation (drone control), and even the automotive field. This technique has gained momentum and great success in various fields, as shown in the results obtained from the studies carried out, such as in this article, 6 which studied suspension control in vehicles and trains. The results are highly motivating, surpassing conventional controllers and even smart controllers like artificial neural network (ANN) and FUZZY logic. The main idea of reinforcement learning is to develop the suspension environment that interacts with the agent throughout the learning phase, the objective of which is to maximize the reward function to achieve the best neural network performance. The results obtained by the articles 7 are optimal compared to the Linear Quadratic Gaussian (LQG), and show an improvement of 62% compared to the passive suspension.
This work is a continuation of the research carried out by Anis Hamza.
State of the art
Influence of the suspension on the human body
When driving a vehicle on the road, the wheels encounter a variety of obstacles with random and variable distributions, both spatially and temporally. This unevenness in the road can lead to vibrational movements. The intensity of these movements depends on the profile of the obstacle and the vehicle’s speed.
The wear of a suspension part can lead to the failure of the shock absorber. This can harm the handling, direction, or braking of a car and damage other parts of the vehicle. The effect that can be noticed is that the car begins to bounce, squat, or dive excessively. All these actions can make driving uncomfortable and dangerous, increase the difficulty of controlling the vehicle, and the risk of aquaplaning.
The solution for detecting damper malfunction is through specific diagnosis while exciting the damper and comparing the measured values with the predicted ones. 8 With artificial intelligence, there is a new method of identifying and diagnosing shock absorbers. The principle consists of analyzing the squealing noise of the shock absorbers. 9 This method of early fault detection can be a solution for the automotive industry.
Comfort is a physiological feeling of well-being associated with the properties of the driver’s environment in a moving vehicle.
When the whole body is subjected to prolonged vibrations, it has harmful effects on the organs of the human body such as lumbar pain, early degeneration of the spine, rapid heartbeat, pelvic osteoarthritis, 10 visual disturbances, pain in the neck and shoulders, etc.11,12 The driver’s sensitivity to vibrations inherent in the use of the vehicle depends on the frequency of road conditions.
As an example, studies have been conducted on the exposure of an agricultural tractor driver to suspension for different durations, which showed that 92% of the people studied suffered from health problems as a result of long periods of sitting in a vehicle.13,14
According to ISO 2631-5, 15 the standard methodology for assessing the exposure of individuals to vibration containing repeated shocks, the most dangerous vibrations for the human body are in the following frequency range [4…15 Hz]16,17:
Between 4 and 8 Hz: the vibration of the whole body is significant.
Between 8 and 15 Hz: the vibrations are transmitted to the whole body through the spine.
Vibration can be rated according to ISO 2631-5, which measures weighted root-mean-square (RMS) acceleration, defined as follows 15 :

RMS: Acceleration
T: Time (s)
The ISO 2631 standard is devoted to the assessment of health risks and provides a guideline on comfort. The health alert diagram (Figure 1) shows the health alert zone (which is in red) is a health risk zone that is a function of the duration of exposure to vibration. 18
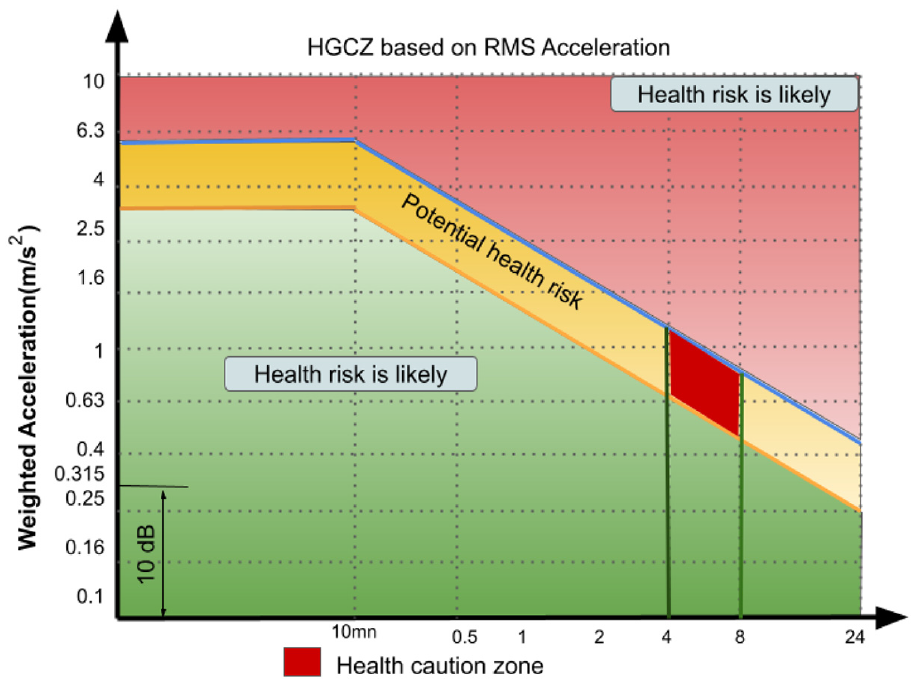
Health guidance caution zone (HGCZ) from (ISO 2631-5).
Suspension system study
The suspension is a component that connects the vehicle with the wheels, and it ensures relative movement between them. The device acts as a vibration insulator to protect the vehicle and provide ride comfort while maintaining tire contact with the road, so they have a grip for rolling. 19 The suspension system generally consists of two main elements:
Springs: Support the vehicle’s weight and allow up and down movement to absorb road shock. Its mission is to transform kinetic energy into potential energy; or vice versa. There are several types of springs (pneumatic, coil, torsion bar, and leaf). There are several types of springs, such as multi-leaf springs, which have very limited travel of 50–75 mm with a high coefficient of friction, which dampens the oscillations of the suspension and lightens the task of the shock absorber.
Shock Absorbers: Control spring oscillations, helping to maintain vehicle control over bumps and corners. The damper is designed to dissipate the kinetic energy produced by the various modes of excitation. Such as single tube, twin-tube, compensating chamber, and gas chamber shock absorbers. 20 Automotive suspension vibration energy can be recovered using regenerative shock absorbers to convert vibration energy into electrical energy, effectively reducing vehicle fuel consumption. According to comparative studies, it has been found that dampers with regenerative behavior are more reliable than others, specifically the hydroelectric damper. 21
Tire: Its primary function is grip, but it also plays a role comparable to the shock absorber by deforming. It is an essential component in controlling the behavior of a vehicle. It transmits the longitudinal forces necessary for acceleration and braking and the lateral forces for turning.
More precisely, the suspension of heavy trucks has seen a significant evolution toward high performance. Today, the demand for more efficient shock absorbers meets safety and comfort requirements.
Reducing driver fatigue by isolating the vehicle’s components, as well as its loading from vibrations excited by bad road conditions, requires a reduction in the coefficient of friction and better control of suspension oscillation. This requires working on a new performance standard for shock absorbers.
A new generation of suspensions with a reduced coefficient of friction, such as air suspensions or parabolic leaf suspensions, have a very low damping coefficient and significant vertical travel of up to 230 mm. These features optimize vehicle control and performance.
Coil springs, also called coil springs, have supplanted leaf suspensions in passenger vehicles, offering optimal performance adapted to the vehicle. They can be used in low-tonnage trucks. Pneumatic suspensions (bellows filled with a compressible fluid, the air is used for heavy vehicles) replace leaf springs. These air bellows can work at a constant volume or air mass (injection of air into the bellows by a compressor) or static charge22,23 (Figure 2).

Mechanical and pneumatic suspension: (a) the high coefficient of friction of these springs limits the suspension travel to approximately 50–75 mm and (b and c) the travel of these suspensions can go up to 230 mm. 24
We can classify the suspension into three different types:
Passive suspension: This type of suspension does not ensure vehicle stability. 25 The dynamic behavior of the system changes as a result of variations in spring stiffness and damping coefficient.26,27
Semi-active suspension: The main idea behind semi-active control is to change the characteristics of energy dissipation devices in real-time, with minimal energy input. The principle of operation of a semi-active suspension system is to modify the damping coefficient, which requires only a reduced energy source. For example, Pierce showed that changing the piston orifice diameter is sufficient, or another type of semi-active rheological magnet (MR) damper that uses a magnetic fluid that interacts with the magnetic field produced by the magnetic coil to change the oil flow and break the piston movement. 28
Active suspension: An active suspension system is a passive shock absorber equipped with an actuator. The role of the actuator is to transmit a calculated force (using information collected from sensors attached to the vehicle) to suppress the vibrations of the vehicle, ensuring greater comfort and safety for the driver (shown in Figure 3). Unlike other passive and semi-active suspension systems, active suspension provides greater flexibility to react to unpredictable forces caused by road roughness and vehicle load, even while driving. In theory, all this control freedom provides better driving comfort and ideal wheel holding. However, to use this technology effectively in a real car, we need an intelligent system that can control it. Unfortunately, active suspension remains a complicated and expensive solution, which explains why it is only used in several high-end car models or truck ranges.29–31
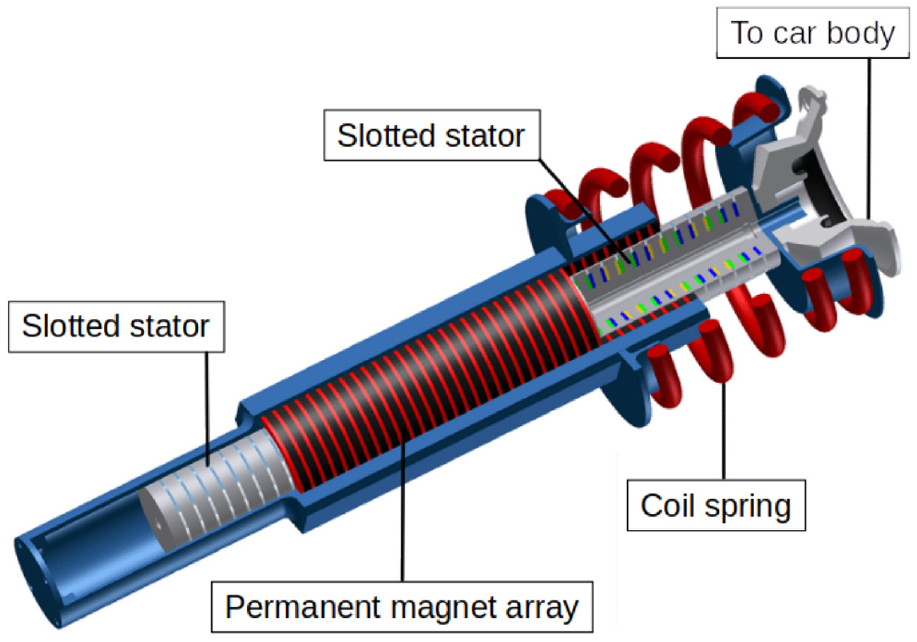
The electromagnetic active suspension system.
Several studies have investigated the different types of vehicle suspension systems from the point of view of complexity, efficiency, maintenance, and lifespan. All this study is analyzed and summarized in Table 1.
Comparative study of suspension systems. 32

Several studies have shown that the electromagnetic actuator is more efficient than the hydraulic actuator, given its simplicity of manufacture and dynamic behavior, despite the limitations in terms of structure and complexity of the hydraulic system. The high cost of manufacturing and system maintenance also poses problems in terms of efficiency.
The linear electromagnetic motor (Figure 3) may be the right choice as an actuator for an active suspension system. Studies have shown that the finite force density of electromagnetic systems can be as high as 663 kN/m3, compared to hydraulic and pneumatic systems. In addition, the ability to regenerate energy through the transfer of linear motion directly into electrical energy reduces overall electrical consumption. The linear suspension movement can also be a stored energy source, which leads to reduced overall consumption. The cylindrical shape and the absence of attraction force, and the active force generated in real-time, offer potential to the active suspension. All these advantages improve performance in terms of comfort, safety, and total control of the vehicle. 33
Active suspension sits at the top of the pyramid of suspension techniques. This adaptive suspension system is capable of adapting to various changes, such as vehicle loading or different phases of evolution like acceleration, braking, and turning. Sensors measure the inclination and acceleration of the wheels, as well as the anti-skid and steering wheel angle, among other parameters. All this information is analyzed by a computer, which controls the supply of the cylinder, enabling the system to compensate in real-time for the body’s movements. This technology can anticipate the roughness of the road and other potentially dangerous situations, explaining the manufacturers’ focus on this technology.
Active suspension control system
The actuator is a crucial component of an active suspension system. It acts as a regulator, applying a force between the sprung and unsprung mass, and ensuring the system’s dynamics according to state variables. This results in a better driving quality, with excellent vehicle maneuverability and improved wheel contact with the road.
The active suspension system requires sensors to measure physical parameters such as vertical displacement, speed, and acceleration. These measurements provide important information for the system’s operation, including vehicle comfort, suspension travel, and tire condition estimation since it’s not possible to measure tire compression directly.34,35
The actuator requires a servo system to reach and maintain the desired setpoint value more quickly. The objective of this study is to decrease the frequency of the suspended mass, resulting in zero acceleration. Various algorithms and control techniques are available, which can be classified into three categories, as shown in Figure 4.
Linear controllers
Non-linear controllers
Controllers based on learning technique.

Control techniques for a suspension system. 37
Several control algorithms include neural networks, fuzzy Logic, iterative control, vector control, scalar control, etc. However, all control techniques had advantages and limitations. Most control techniques have various problems such as:
Sensitivity to parameter variations and external disturbances.
Weak dynamic responses
Configuration complexity
Each control technique led to at least one problem. No control technique has been implemented to solve all these problems simultaneously while providing high precision control. 36 Below is a comparative table of control techniques according to their advantages and disadvantages (Table 2).

In this context, to find an optimal solution for any internal or external variation of a suspension system, the science of decision-making opens the horizon to reinforcement learning, which can optimize trajectories, plan movements, or establish routes dynamically.
The control algorithm gives a value to the power amplifier, and the amplifier translates this value into bidirectional electrical power to the electromagnetic motor. The system uses the compression force to harvest energy and store it. Thus, the amplifier functions as a generator and provides power to extend or contract the motor to ensure the vehicle’s comfort and safety. 34
Reinforcement learning
Deep learning, more precisely reinforcement learning (RL), attracts researchers for its ability to solve complex problems. In RL, agents can imitate the human learning process to achieve a designated goal, and they are trained on a mechanism of reward and punishment. The agent perceives the current state of the environment and performs actions for which it is rewarded for good moves and punished for bad ones. In doing so, the agent tries to minimize bad moves and maximize good ones.40–42
Reinforcement learning uses several algorithms that have a single objective, and the agent must find the policy that maximizes the sum of the rewards over time. We can classify these learning algorithms into two classes, one of which is based on a model and the other without a model, or we can combine the two. The choice of the algorithm is specific to the objective of our problem. Figure 5 shows the various algorithms.

Taxonomy model of deep reinforcement learning (DRL). 43
According to Poole and Mackworth in their book, 44 if one uses model-based learning, it is much more efficient from the point of view of experience and neural network maturity. However, in return for free learning (without a model), the agent will be confronted with new experiences, which include a certain inaccuracy and imprecision of the state. This will be an advantage throughout the learning phase in the improvement of the policy. Several approaches propose to combine these two techniques. 45
Another classification of deep reinforcement learning is based on the type of stimulation used to optimize the agent’s reaction. A positive model uses favorable stimulation of the system, while a negative model uses an undesirable stimulus to distract the agent from a specific action.
Our suspension system is based on the interaction between the agent and the environment. The realization of an optimal strategy requires precise parameterization and an environment based on mathematical formulas. 46 Deep reinforcement learning (DRL) application in active suspension control addresses several challenges, such as safety and ride comfort. Given the complexity of the suspension model (non-controllable internal and external parameters), model-free algorithms are a solution for the non-linearities of the suspension system. It allows one to actively learn in real-time without pre-learning to be functional in an unknown environment.
Choice of algorithm
The agent’s decision-making function (control strategy) represents a mapping of situations to actions. Given the importance of choosing an algorithm, performance studies of these DRL algorithms are carried out. For example, drone flight control studies include hovering, landing, random waypoints, and target tracking. All DRL algorithms have their pros and cons.
In a study by Mr. William Koch in 2019, learning algorithms such as Proximal Policy Optimization (PPO), Q-learning, Deep Q-Network (DQN), and Deep Deterministic Policy Gradient (DDPG) were used to ensure stable and fluid autonomous navigation of drones. The study analyzed the angular velocity to reach a target velocity
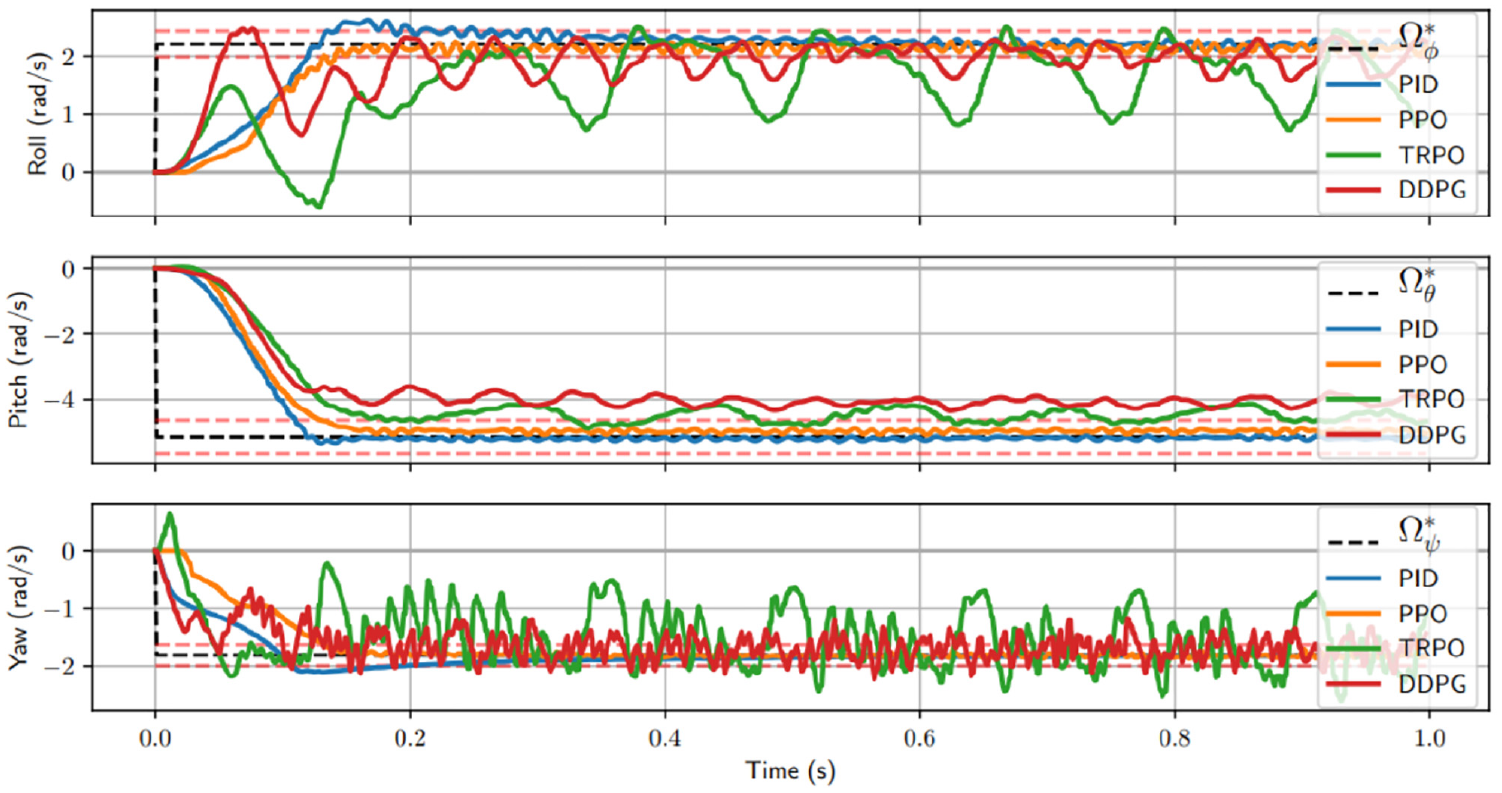
The best learning (RL) reinforcement agent response compared to PID. with a target angular velocity equal to
According to a comparative study of the behavior of algorithms on the stability of drones, it was noted that the TRPO and DDPG algorithms have extreme oscillations. This leads us to discard these types of algorithms in our suspension system because they generated instability in both the roll and yaw axis of the drone, resulting in instability during flight. According to this study, the PPO algorithm is more precise, faster, and produces the smoothest navigation with the minimum error. This is why Song et al. 48 trained the drone using the PPO algorithm for AlphaPilot and Airsim drone racing tracks due to its excellent performance and simple implementation.49–51 So to stabilize our suspension system, we will use the Proximal Policy Optimization (PPO) algorithm.
Numerical modeling
Researchers often use two different approaches to solve control problems, such as ANN 52 and fuzzy logic. 53 ANN uses interconnected neurons that learn and adjust their behavior based on expected input and output, while fuzzy logic uses fuzzy sets and decision rules to provide outputs. The researchers chose ANN as a method for stabilizing a vehicle because it is better suited for modeling nonlinear systems like vehicle suspension. The dynamic characteristics of suspension are very complex and difficult to model with simple mathematical equations. ANN is capable of learning these characteristics and adjusting its behavior accordingly.
However, for our study, we opted for reinforcement learning instead of ANN because the latter requires a large amount of training data, which can be difficult to collect for real-world driving scenarios. Reinforcement learning is an unsupervised approach in which an agent interacts with its environment to learn how to make decisions by maximizing a reward. This method is more flexible and can adapt to unforeseen situations in the environment, making it more robust for stabilizing a vehicle. Additionally, reinforcement learning allows for directly optimizing the desired reward, in this case, the stability of the car, which can lead to better overall performance.
Our model consists of two suspended and unsuspended masses, respectively Ms and Mus, supported by two shock absorbers and two springs. This model is similar to the passive model but includes an actuator between the sprung and unsprung mass, as shown in Figure 7 below. The active damper generates forces under the demand of a control strategy. The simplicity of this model facilitates the analysis and optimization of the calculation.
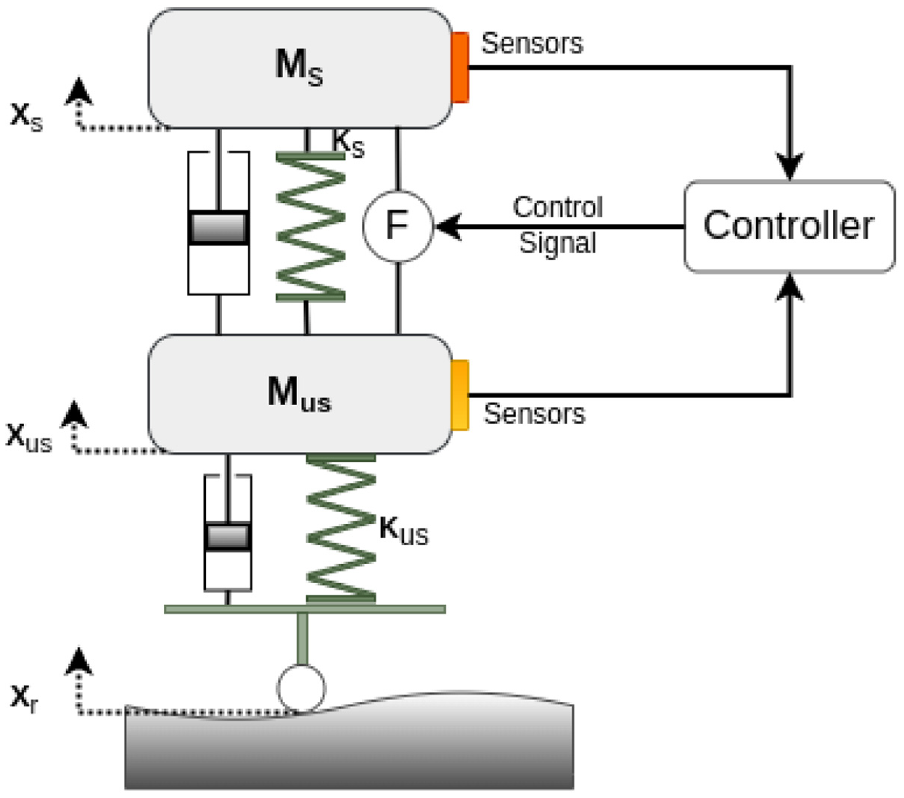
Active suspension model.
Mathematical formula of an active damper
In our model with two degrees of freedom (Figure 7), we use the general theorems of mechanics based on the fundamental principle of dynamics. The suspension system considers the vertical movement of the body
Sprung mass:

Unsprung mass:

Equations (2) and (3) present the mathematical models of a vehicle suspension system knowing that:
From (2) and ((3)), the following state space equations can be formulated:

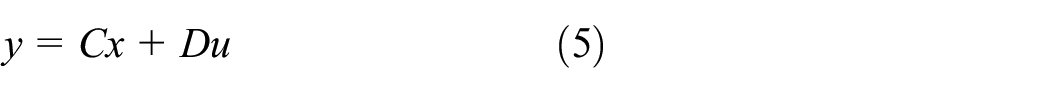
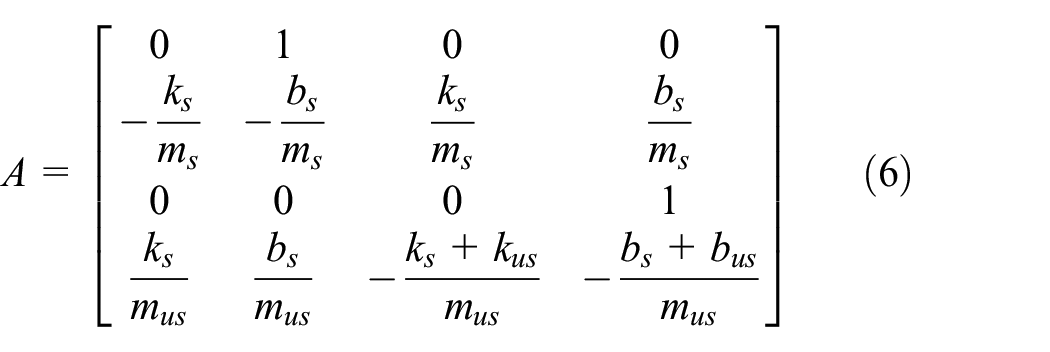





The equations (4) and (5) describes the state space representation of the vehicle’s suspension system, where:
The actuator plays the role of a regulator between these components (suspended mass and unsprung mass) while minimizing the acceleration of the suspended mass and eliminating the effect of wheel travel. Note: if we deactivate the actuator, we give it zero force, and we return to the behavior of a passive damper. The force of the actuator varies between
Numerical simulation with reinforcement learning
Our contribution in this work is to combine the PPO algorithm with active suspension. The global process is as follows: the road information is generated according to ISO 8608 and fed into the suspension system model. Meanwhile, the control performance index of the current time

Reinforcement learning model.
During the reinforcement learning phase, a rectangular shape was used for the road to simplify the problem and reduce the complexity of the environment. This created a more controllable and reproducible environment for learning, making it easier to evaluate the model’s performance. However, this shape may not represent all real driving situations, and the model’s performance may be limited when facing unexpected or unknown situations. Nonetheless, our model will behave according to imposed rules and will be validated in advance using this learning method with a reproducible road profile. To increase reliability, we can diversify the learning environments so that the model can generalize to different situations encountered during learning.

where
Active suspension control based on the proximal policy optimization algorithm
The PPO algorithm belongs to the policy gradient (PG) family. The basic idea is to update the policy to maximize the probability of actions that provide the greatest future reward. It does this by running algorithms in the environment and collecting state changes based on the agent’s actions. Collections of these interactions are called trajectories. Once one or more trajectories are captured, the algorithm examines each step, verifies whether the chosen action yields a positive or negative reward, and updates the policy. The environment represents the physical behavior of our suspension system, with its state representing the accelerations and displacements of the suspended and unsuspended mass, and its action being the value of the force that must be exerted.
Trajectories are sampled through step-by-step interaction with the environment. To perform a single step, an agent selects an action and passes it to the environment.
Agent Update: Policy update: The basis of the PG algorithm is the formula for updating the weights of a network (Formula 13).
The gradient is the positive or negative direction of the weights in which the policy change will make actions more likely in a given state.

Visualization of the neural network update: We move to the visualization of the neural network update once the trajectory is completed (step 1). All values (log probabilities, values, and rewards) are recorded. After the end of the trajectory, the rewards and benefits are discounted (step 2) (where advantages = discounted return − expected return). In step 3, the loss of each step is calculated. Finally, in step 4, we calculate the average of all these losses and update it with gradient descent (see Figure 9).

Neural network update diagram.
Algorithm PPO: OpenAI proposed PPO to solve the problem of the gradient policy’s learning rate convergence. If the step size is too large, the policy diverges, and if it is too small, the calculation time will be very long. PPO adds a factor, the probability ratio, to prevent large updates from occurring and makes the policy gradient less sensitive.55,56

L: Loss function.
The first term inside the min is
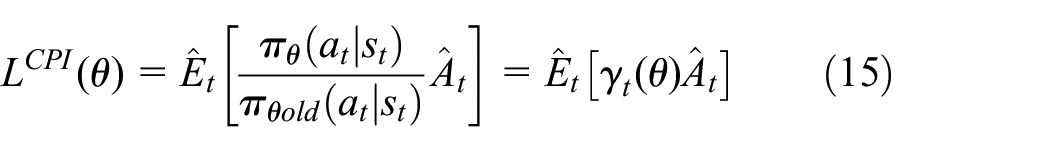

Moreover, the second term

Reward function
The reward function plays a crucial role throughout the learning process as it indicates the quality of the action undertaken by the agent after transitioning to the next state, with quality varying between positive or negative values. The reward is then transferred to the neural network via back-propagation, and the optimization method adjusts the neural network parameters to minimize errors. During the reinforcement learning phase, the agent receives a reward value from the environment.
Therefore, the choice of the reward function is a key element in the design of any control system, including active vehicle suspension systems. The reward function defines the goals of the control system and evaluates the system’s performance in terms of these goals. In this Table 3, we have compiled and compared the reward functions used in several studies to stabilize an active suspension system. We also evaluated the pros and cons of each reward feature in terms of the performance of the active suspension system. This comparison helped us to choose the most suitable reward function for achieving an effective and efficient active suspension system.
Benchmarking reward functions for performance optimization of an active suspension system.

The reward of our suspension system is studied according to four objectives that must be expected simultaneously. The first is to minimize the acceleration of the suspended mass
Figure 10 shows the four objectives of the work. The more the values converge toward the origin (converges toward zero), the more we have good stability of the suspended mass and good wheel adhesion. Our contribution is to develop a formula that seeks a compromise between all these constraints. Several reward formulas are tested and studied in the result part. The following (formula 18) presents the general reward function.
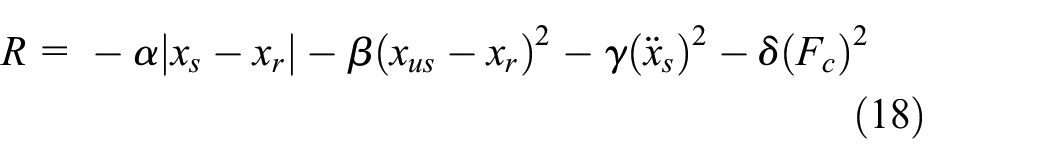
Where:

Convergence of objective parameters throughout learning.
Result and discussion
In this article, we used Google Colab Pro to build a 1/4 active suspension system model, and the suspension parameters are shown in Table 4. The actor network and the critic network of the PPO algorithm were eight- and ten-layered neural networks, respectively. The learning rates of the actor network
Parameters for the quarter active suspension.

Hyperparameters for the proximal policy optimization structure.

The results obtained from the intelligent controller with a reward function (equation (18)) after the training phase are compared with the passive suspension. The results show that we obtained a reduction of 53.24% and 35.60%, respectively, in acceleration and displacement compared to the passive suspension. The reduction results of the chosen reward function are shown in Table 6 and Figure 11.
Reduced overshoot values for stepped road entry.


Sprung mass displacement on rectangular road profile.
Figure 12 presents the simulation results of the acceleration of the unsprung mass compared to the passive suspension. The proposed method significantly improves the acceleration of the vehicle body, leading to more stability.

Sprung mass acceleration on rectangular road profile.
However, evaluating comfort solely by the acceleration limit method does not capture the behavior of the suspension throughout the journey. Therefore, according to the ISO 2631 standard, 15 one can use the Root Mean Square (RMS) acceleration method, which calculates the average acceleration over a certain period of time. 60 The comfort reference values are shown in Table 7.
System settings.

Several reward functions were tested during the neural network optimization phase. To evaluate the performance of each model, the hyperparameters for the proximal policy optimization algorithm were set as shown in Table 5. After each test, the root-mean-square (RMS) values were calculated and evaluated according to ISO 2631-5. The results obtained showed that the reward function played a guiding role throughout the learning phase. As described later, our objective was to work on several aspects, such as the stability of the suspended mass and the dynamics of wheel movement, to ensure better grip with the road.
According to the reward, formulas studied, in which we gradually introduced the constraints such as:
The distance between the road condition and the unsprung mass
The distance between the state of the road and the suspended mass
The acceleration of the suspended mass
The objective is to minimize acceleration while maintaining the wheel’s grip on the road and keeping up with the suspended mass.
To optimize the results, we adjusted the weights of each constraint so that the agent maximizes its reward, which generates stability of the suspension system with optimal values.
After several tests, we noticed that the agent controlled our suspension system according to the latter reward criteria. The system exhibited a uniform behavior of displacement of the unsprung mass in the logarithmic form with RMS, which can reach up to 0.180
The integration of the force exerted on the actuator U as a criterion in the reward formula aims to minimize the phenomenon of wheel deflection. The result reaches its target toward more stability of the wheel with an RMS of the order of 0.250
Several articles have used the reinforcement learning method, for example, that of Fares and Younes, 54 who used the critical actor algorithm, but the results obtained with the PPO algorithm are more efficient.
Comparison between the results:
Critical actor algorithm: profile of the road used during the learning phase (square signal of amplitude
PPO algorithm used by our model: profile of the road used during the learning phase (square signal of amplitude
It is clearly concluded that the PPO algorithm with the reward function 4 listed in the Table 8 is more efficient than the critical actor algorithm.
Analysis of RMS values according to reward functions.

Simulation of different road levels
To validate the control performance and robustness of the PPO-based active suspension system, road profiles were created in accordance with ISO 8608,61,62 and the road characteristics were described using the special

Road classification according to ISO 8608 [1]with road unevenness coefficient

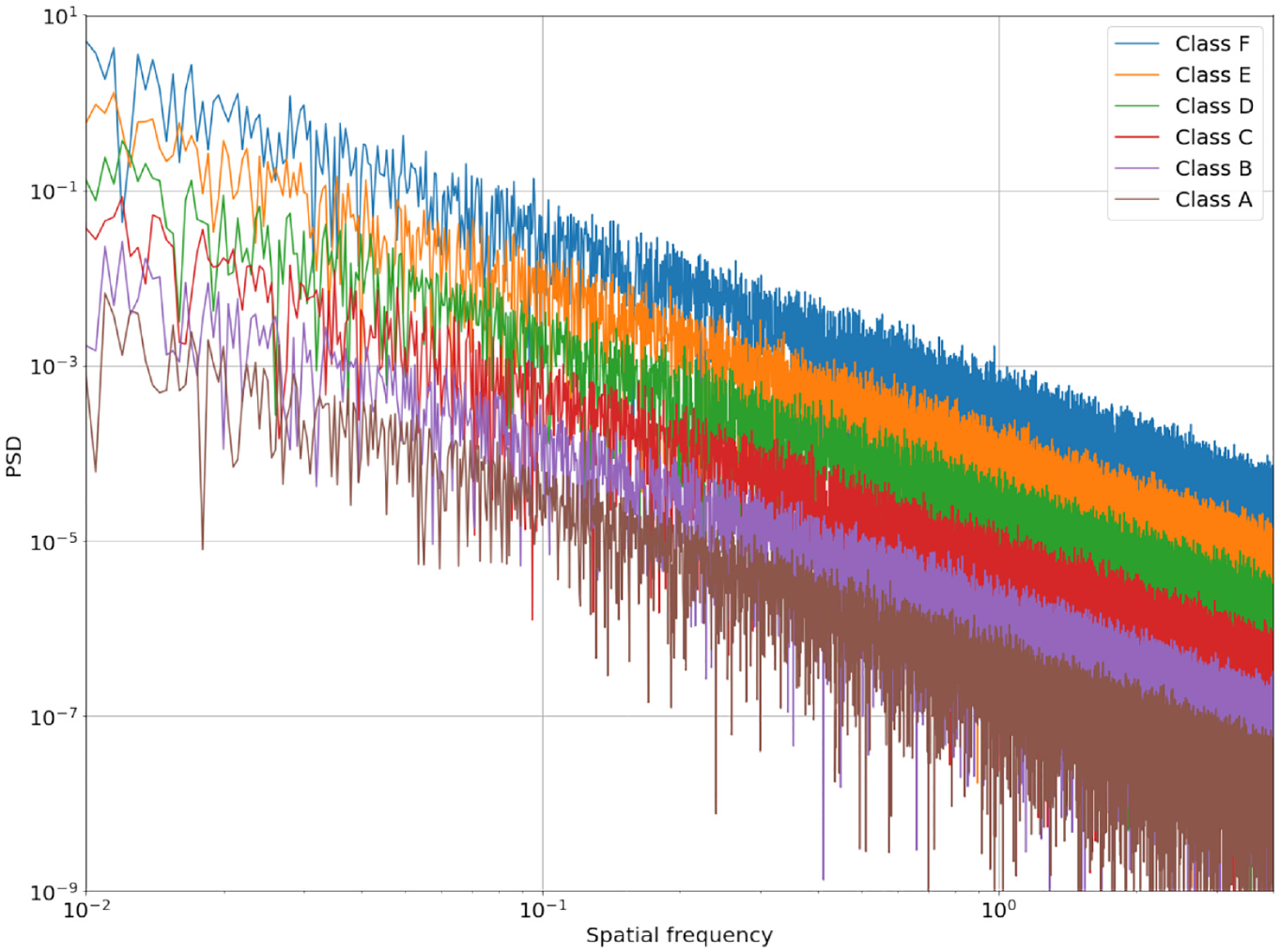
The various PSDs of different classes utilized to stimulate the model in this paper. 63
knowing that :
Throughout the simulation, the same conditions apply. Specifically, for a vehicle speed of 20 m/s, the result is shown in the Figure 14.

Movement of the suspended mass on different types of road (A, B, C, D, E, and F): (a) class A, (b) class B, (c) class C, (d) class D, (e) class E, and (f) class F.
Results of the acceleration of the suspended mass
After simulating the passive and active suspensions under class D road conditions, the results showed a significant decrease in acceleration, which could reach up to 62.5%, as depicted in Figure 15. This improvement effectively enhances ride comfort and stability. Moreover, the dynamic stability characteristics of the active suspension with delay have been improved. Therefore, we can conclude that the proposed reinforcement controller is capable of meeting the design and simulation requirements.

Sprung mass acceleration on class D road profile.
To further support our findings, it would be valuable to conduct physical experiments to validate the results obtained from the simulations. Furthermore, future work can focus on testing the proposed controller on other road conditions to investigate its performance in different scenarios.
Evaluation
Several simulations were conducted to evaluate and compare the results obtained. The simulations were conducted in the OpenAI Gym environment, and the same set of hyperparameters were used throughout all phases of the simulations to ensure consistency. To conduct these simulations, we utilized the cloud simulator “Google Colab Pro,” which is based on Jupyter Notebook and offers a high-performance computing environment with 32 GB of RAM and either a Tesla T4 GPU or NVIDIA Tesla P100.
Figure 16 shows the convergence process of the algorithm, which appeared to stabilize at around 0.4e7 episodes. The simulation process lasted approximately 6 h and required more than 30 trials to find optimal convergence. Despite the long time it took to find optimal convergence, the results obtained from the simulations were reliable and justified the time and effort spent conducting them.

Total reward during a number of time steps.
Jin et al.64–66 used the Active Suspension of In-Wheel-Drive Electric Vehicles (IWMD-EV) solution. In order to achieve better driving comfort and reduce the force applied to the motor bearing in the wheel, a robust H
If we now compare our solution, the RL controller, with the work of Jin et al., we find that the results at the RMS level of the acceleration of the body are very close, approximately
A dedicated active suspension system typically consists of a set of sensors, actuators, and a control unit. The sensors measure the vehicle’s motion and the road conditions, while the actuators adjust the suspension components (such as dampers, springs, and anti-roll bars) to optimize the ride quality and handling. On the other hand, a reinforcement learning controller uses machine learning algorithms to learn the optimal suspension settings for a given driving scenario. The controller receives feedback from sensors on the vehicle’s motion and makes adjustments to the suspension settings to optimize the ride quality and handling.
Both approaches have their advantages and disadvantages. A dedicated active suspension system provides more precise control over the suspension settings and can respond more quickly to changes in driving conditions. However, it requires more complex hardware and software, which can increase the cost and weight of the vehicle. A reinforcement learning controller, on the other hand, can adapt to different driving scenarios and learn from experience, which can lead to better overall performance. However, it requires a significant amount of computing power and can be difficult to train and optimize.
In summary, both approaches have their strengths and weaknesses, and the choice between them depends on the specific requirements of the IWMD-EV and the preferences of the designer.
Analysis of the results and performance of our reinforcement learning-based controller for active suspension compared to recent works by Hamza and Ben Yahia 1 and Swethamarai and Lakshmi 67 proposing controllers such as Artificial Neural Network (ANN), Proportional, Integral, and Derivative (PID), Fractional Order PID (FOPID), and Adaptive Fuzzy tuned Fractional Order PID (AFFOPID) controllers, demonstrates the effectiveness and efficiency of our proposed method in this paper. The results are listed in Table 10.
Level of comfort of the different types of regulators.


 Very bad suspension behavior (a great risk to the health of the driver, and poor adhesion of the vehicle with the road)
Very bad suspension behavior (a great risk to the health of the driver, and poor adhesion of the vehicle with the road)
 The suspension control with PID minimizes the acceleration of the suspended mass, the results vary between fair and average
The suspension control with PID minimizes the acceleration of the suspended mass, the results vary between fair and average
 The suspension control with FOPID to exceed the medium to above average
The suspension control with FOPID to exceed the medium to above average
 The suspension control with AFFOPID surpasses from average to good
The suspension control with AFFOPID surpasses from average to good
 The control with the neural network belongs to the family of good suspension controllers that ensure good driving comfort
The control with the neural network belongs to the family of good suspension controllers that ensure good driving comfort
 The controller by reinforcement goes from good to excellent comfort and more driving stability
The controller by reinforcement goes from good to excellent comfort and more driving stability
The superior performance of the reinforcement learning controller significantly outperforms that of ANN and AFFOPID, attributed to the constant improvement in RMS values (from
Conclusion and outlook
In this study, we utilized the Proximal Policy Optimization (PPO) algorithm in deep reinforcement learning to overcome the drawbacks of conventional suspension methods. We conducted studies and tests to optimize the neural network on the reward function using 13 different reward functions in both uniform and square road conditions. The results showed that reinforcement learning provided better comfort and improved driving stability and vehicle safety, with near-optimal results. Additionally, the results highlighted the importance of the reward function as a guide throughout the learning phase. A clear reward function leads to optimal neural network results that meet all the intended goals.
We compared our results with the ISO 2631-5 standard to evaluate the degree of comfort of our solution. The Root Mean Square (RMS) of the acceleration of the suspended mass was reduced to 0.118
These results encourage further research on reward function optimization and exploration of other algorithms such as Asynchronous Advantage Actor Critic (A3C), Deterministic Policy Gradient (DPG), and Deep Deterministic Policy Gradient (DDPG). Furthermore, continuous learning under more complex perturbations could enhance reinforcement learning. We should also consider optimizing the number of epochs and the learning rate to provide further neural network optimization.
Footnotes
Handling Editor: Chenhui Liang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.