
Abstract
Based on the crowding distance algorithm of Non-Dominated Sorting Genetic Algorithm-II (NSGA-II), three improved algorithms are proposed: side length optimization strategy, diagonal optimization strategy, center optimization strategy. Zero-Ductility Transition (ZDT) series functions and Diode-Transistor Logic with Zener diode (DTLZ) series functions are used to calculate and compare the convergence and diversity of three improved algorithms and NSGA-II. The center optimization strategy based NSGA-II is confirmed to be the optimal algorithm. The body-in-white (BIW) optimization functions are established and optimized by center optimization strategy based NSGA-II, and the most appropriate BIW structure is calculated and verified by mode tests. The result shows: after the optimization, the BIW total mass increment is less than 3%, the first torsional mode frequency increment is more than 15%, and the torsion stiffness increment is more than 10%.
Introduction
Non-Dominated Sorting Genetic Algorithm-II (NSGA-II) is a fast elite multi-objective optimization algorithm. NSGA-II is improved from Non-Dominated Sorting Genetic Algorithm (NSGA). 1 It was proposed by Deb et al. 2 in 2002. NSGA-II has the advantages of fast convergence, low computational complexity, and high robustness. It is suitable for optimization problems in low objective dimensions, 3 and is widely used in selective combinational optimization problems, 4 including assignment problems,5,6 allocation problems, 7 vehicle routing problems, 8 and scheduling problems.9,10
At present, the research in the optimization of NSGA-II mainly focuses on direct improvement and hybrid improvement. The direct improvement NSGA-II is to improve the algorithm performance by modifying its mathematical principle directly. Based on genetic algorithm, the core mathematical ideas of NSGA-II are the generation, assignment, and screening of data. 2 In order to optimize the data generation mechanism, some scholars focus on improving the crossover and variation of parental individuals to improve the diversity and convergence of the algorithm. For example, Zhao et al. 11 has combined the optimal and the worst crossovers to evaluate the offspring solution set, and Cao et al. 12 used two mutation operators: patch cells and constraint steering as genetic operators, and using four-point binary crossover, Laplace crossover, and non-uniform mutation as NSGA-II genetic operators. 13 To optimize the data screening mechanism, some researchers have introduced the new offspring population both generated by NSGA-II and by the difference algorithm into the screening mechanism to ensure the diversity of improved NSGA-II. 14 However, there are few improvement studies on data assignment in direct improvement methods. The direct improvement method modifies the mathematical principle of NSGA-II in a more direct form, which can fundamentally improve the performance of the algorithm and reduce the computational cost.
The hybrid improvement NSGA-II combines NSGA-II with other optimization algorithms, this improves the convergence and diversity of the original NSGA-II. Based on data generation, Yuan and Dai 15 has introduced the reverse learning mechanism into the initialization and evolution process of NSGA-II, and a new arithmetic crossover operator is proposed, which improves the convergence and calculation accuracy of the algorithm. Based on data assignment, in Fettaka et al., 16 the crowding distance calculation of NSGA-II is improved by cosine similarity algorithm, which makes the next generation population gather in the preferred direction. This method is applied to the material design of thermal barrier ceramic coating. Based on data filtering, in Zhang et al., 17 new offspring chromosomes are predicted by combining traditional NSGA-II algorithm with frontier prediction algorithm, which makes the algorithm better approach the Pareto frontier of difficult constraints and unconstrained problems while keeping the computational cost similar to NSGA-II. Hybrid improvement is the most used optimization method at present, but this method is usually complicated and has high computational cost.
To sum up, the existing NSGA-II improvement studies mainly focus on improving the data generation mechanism and filtering mechanism. However, there are few studies that analyze the assignment mechanism of the algorithm from a mathematical perspective.
This study proposes three improved strategies to improve the distribution of solutions based on the traditional crowding distance calculation of NSGA-II, and comprehensively compare its performance differences. The improved NSGA-II is applied to the optimization of body-in-white (BIW) structure, and the effectiveness of the model is verified by the BIW free mode test.
NSGA-II
The main algorithm flow of NSGA-II is: firstly, the initial population members are generated randomly. Secondly, Pareto ranks of the initial population are assigned using fast non-dominated sorting approach. Thirdly, new members are generated by genetic algorithm (GA) and selected by Pareto ranks. After that, new members are combined with the initial population. Then, Pareto ranks of the combined population are assigned by fast non-dominated sorting, and the crowding distance of each combined member is calculated by crowding distance operator. Finally, the next generation members are selected from the combined population based on elite-preserving approach. The new generation are evolved as the flow above until the generation conditions are met.
The implementation of NSGA-II relies on fast non-dominated sorting approach, crowding distance operator, and elite-preserving approach.
Fast nondominated sorting approach
Fast non-dominated sorting approach calculates and arranges Pareto ranks of the population. Pareto rank is a classification method based on Pareto dominance concept, which is defined as: for a M components multi-objective optimization problem

If no variable dominants
In fast non-dominated sorting approach, the members with the highest Pareto dominance relationship form the first non-dominated front. And the Pareto rank of the first non-dominated front is 1. Then the first non-dominated front is removed from the population. The first non-dominated members in the remaining population form the second non-dominated front, and its Pareto rank is 2. So does the Pareto rank of 3, 4, 5, … The initial population is divided by Pareto ranks, as shown in Figure 1. 2

Pareto rank of the population.
Crowding distance
The crowding distance is used to estimate the dispersion of the members in the same Pareto rank. When comparing two different solutions, the solution of the larger crowding distance is considered to have a better dispersion situation. In NSGA-II, the more evenly the population members are distributed in target space, the better solutions will be.
The crowding distance of member i is
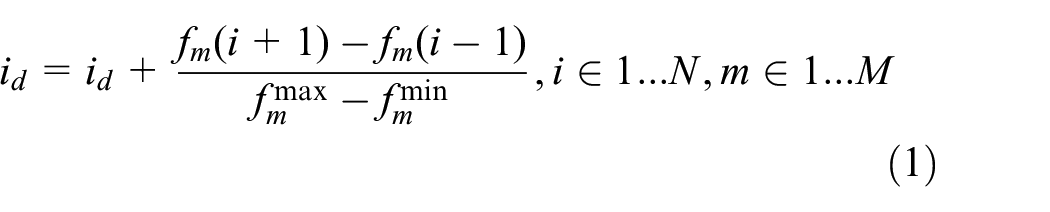
Where
Geometrically, the crowding distance is half of the circumference of the largest hyperrectangle that the member forms in the target space. In two dimensions, the crowding distance is half of the circumference of the largest rectangle. As shown in Figure 1, the crowding distance of member i is half of the circumference of the red rectangle.
Elitist-preserving approach
The elite-preserving approach selects better solutions from the combined population to form the next generation. The approach firstly compares the Pareto rank of each member, and selects the members of high Pareto rank. If two members have the same Pareto rank, the member of larger crowding distance is preferentially selected until the next generation is filled up.
At the beginning of the algorithm cycles, the algorithm could select all members with higher Pareto ranks, such as Pareto rank 1 and rank 2, etc., while the members of lower Pareto ranks would be selected optimally by comparing the crowding distance. At the end of the algorithm cycles, the offspring generations are almost formed by higher rank Pareto data, and the member selection is made through comparing the crowding distance. Therefore, in elite-preserving approach, the Pareto rank has a great influence at the beginning of the cycle, while the crowding distance gradually becomes more important when the number of the algorithm cycles increases.
Improved NSGA-II
The shortcoming of NSGA-II
When the number of the algorithm cycles increases, the algorithm preferentially selects the members with larger crowding distance as the next generation.
As shown in equation (1), the crowding distance of individual i depends on the difference of

The problem of crowding distance.
As shown in Figure 2 and equation (1), the crowding distance of individual 2 is:

Where,
The crowding distance of individual 3 is:
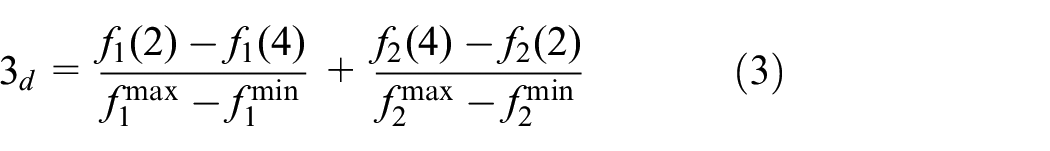
If
As shown in Figure 2, the current crowding distance operator ensures that the previous and next individuals are dispersed as much as possible, but cannot guarantee the dispersion of two adjacent individuals. If all members of the next generation are calculated in the current crowding distance approach, the solutions would not be evenly dispersed. Three NSGA-II improving strategies are proposed in view of this problem. The three improved algorithms are optimized from the perspective of individual geometric position. The difference is that they each refer to the position of the previous individual, the position of the right angle point, and the position of the geometric center.
Side length optimization strategy
If the pervious and next individuals are scattered and the target individuals are far away from the previous individual, the dispersion of the solution set can be greatly improved. As shown in Figure 2, if individual 2 is far away from individual 1 and 4, and individual 3 is far away from individual 2 and 4, the solution set has a great dispersion.
The distance between the current individual and the previous individual is calculated in equation (1), and the formula of side length optimization strategy based NSGA-II (SLOSB-NSGA-II) is shown in equation (4):

Where,
As shows in Figure 2, the crowding distance of individual 2 calculated by SLOSB-NSGA-II is:

The current individual and the previous individual are made scatter by SLOSB-NSGA-II while the previous and next individuals are also made scatter. This ensures the uniform dispersion of the whole result set.
Diagonal optimization strategy
If the target individual is close to the vertex closest to the origin of the largest hyperrectangle formed by the previous and next individuals, the dispersion of the solution set is large. As shown in Figure 2, if individual 2 is close to point E, individual 2 is dispersed from individual 1 and individual 3. The diagonal optimization strategy based NSGA-II (DOSB-NSGA-II) is proposed according to this principle, and its formula is shown in equation (6).
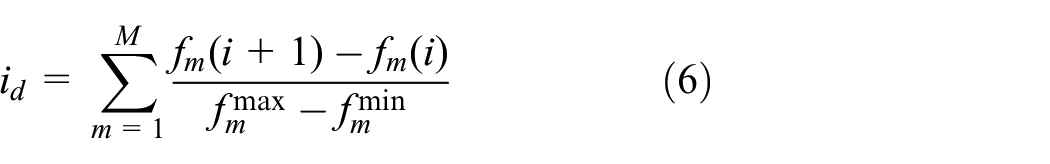
As shown in Figure 2, the crowding distance of individual 2 calculated by DOSB-NSGA-II is:

The current individual is made close to the vertex closest to the origin by DOSB-NSGA-II when the distance between previous and next individuals is large, therefore the solution set is dispersed uniformly.
Center optimization strategy
If the current individual is close to the center of the maximum hyperrectangle formed by the previous and next individuals, the solution set has a good dispersion. In Figure 2, if individual 2 is close to the center point O, individual 2 is dispersed from individual 1 and 3. The central optimization strategy based NSGA-II (COSB-NSGA-II) is proposed according to this, and is shown in equation (8).

As shown in Figure 2, the improved crowding distance of individual 2 calculated by COSB-NSGA-II is:
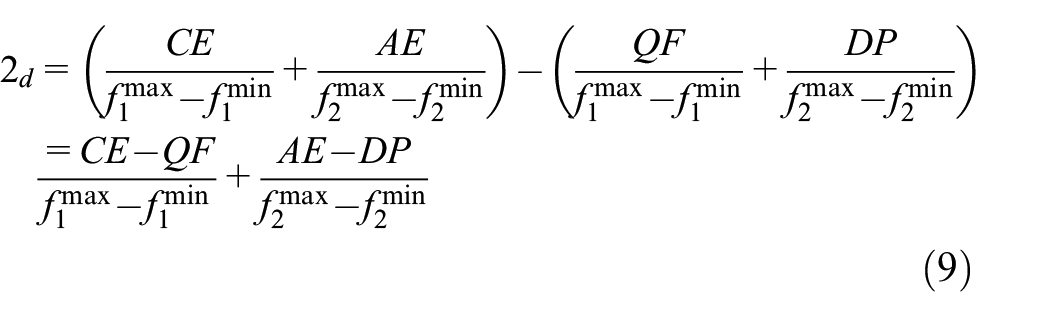
The current individual is made close to the geometric center of the hyperrectangle by COSB-NSGA-II when the distance between the previous and the next individuals is large, then the whole solution set is dispersed uniformly.
Algorithm performance comparison
Two-dimensional functions ZDT1-ZDT3 and high-dimensional functions DTLZ1-DTLZ3 are used as objective functions. NSGA-II 2 and three improved algorithms are used to optimize objective functions. After the optimization, the optimized data are calculated by IGD (reverse generation distance) evaluation function. The IGD evaluation function calculates the convergence and diversity of the algorithm. The smaller the IGD value is, the better the comprehensive performance of the algorithm is. The mathematical formula of IGD is shown as equation (10).

Where, P is the algorithm optimization solution,
For two-dimensional functions ZDT1, ZDT2, and ZDT3, IGD function results with iteration times of 500, 1000, 1500, and 2000 are counted respectively in order to analyze the influence of iteration times on the results. The maximum, average, and minimum values are shown in Table 1 by repeating the calculation of the above results for 100 times.
Comparison of IGD maximum, average, minimum results of ZDT functions.

Where, the bold data are the average results, and the data with * are the best value.
For DTLZ function, the optimization results of 3, 5, 8, and 10 dimensions are calculated respectively. The number of iterations of DTLZ1, DTLZ2, and DTLZ3 are 700, 250, and 1000 respectively according to the characteristics of the function. The calculation is repeated for 100 times, and the maximum, average, and minimum values are shown in Table 2.
Comparison of IGD maximum, average, minimum results of DTLZ functions.

Where, the bold data are the average results, and the data with * are the best value.
In Tables 1 and 2, overall, the average IGD values of three improved algorithms are smaller than that of NSGA-II, which indicates that the performance of the improved algorithm is superior to the original. It can also be seen from Tables 1 and 2 that the average IGD values of COSB-NSGAII algorithm are smaller than those of original NSGA-II algorithm. When the dimension of the objective function is lower than 5, as for ZDT functions, COSB-NSGA-II has the largest number of best values, as for three-dimension DTLZ, COSB-NSGA-II is also the unique algorithm to have smaller IGD value than NSGA-II, which means the IGD values of COSB-NSGA-II are also better than SLOSB-NSGA-II and DOSB-NSGA-II, indicating that the COSB-NSGA-II has better comprehensive performance.
The Pareto frontier results of ZDT1-ZDT3 and DTLZ1-DTLZ3 optimized by COSB-NSGA-II are shown in Figures 3 to 5, and Figures 6 to 8.
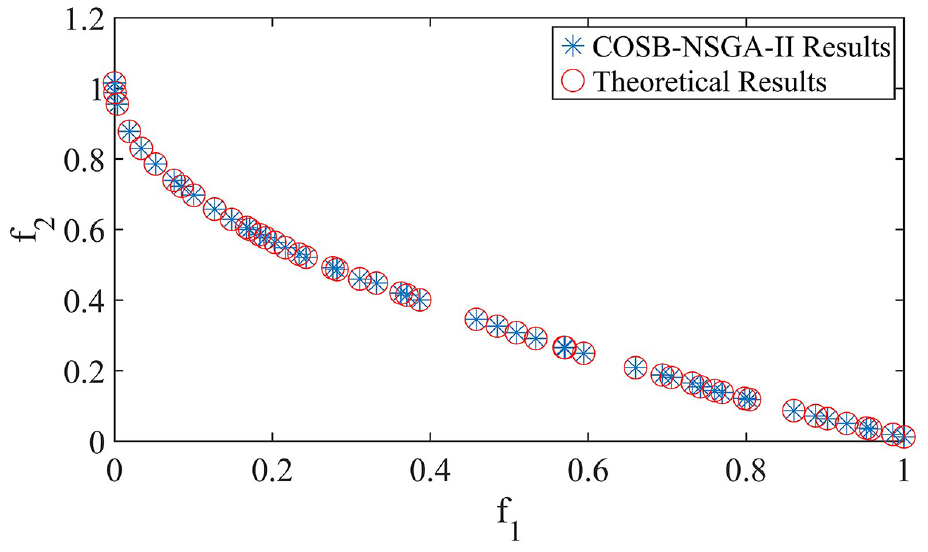
Pareto frontier results of ZDT1 optimized by COSB-NSGA-II.

Pareto frontier results of ZDT2 optimized by COSB-NSGA-II.

Pareto frontier results of ZDT3 optimized by COSB-NSGA-II.

Pareto frontier results of DTLZ1 optimized by COSB-NSGA-II.

Pareto frontier results of DTLZ2 optimized by COSB-NSGA-II.

Pareto frontier results of DTLZ3 optimized by COSB-NSGA-II.
Structure optimization of body in white
Body-in-white (BIW) structure optimization is established based on the finite element (FE) model. The frequency design sensitivity analysis (DSA) is firstly carried out, and the design variables are selected according to the DSA ranking results. After that, the BIW neural network surrogate model is established based on the relationship of the design variables with the BIW first torsional mode and static bending-torsion stiffness. Choosing three design variables as objectives: the BIW total mass increment, the first torsional mode frequency increment, and the torsion stiffness increment. Then, optimization functions are established and optimized by COSB-NSGA-II because it performs best on three-dimension optimization problems among three improved strategies, and the most appropriate BIW structure is calculated and verified by mode tests.
Finite element model of BIW
The finite element model of BIW is shows as Figure 9.
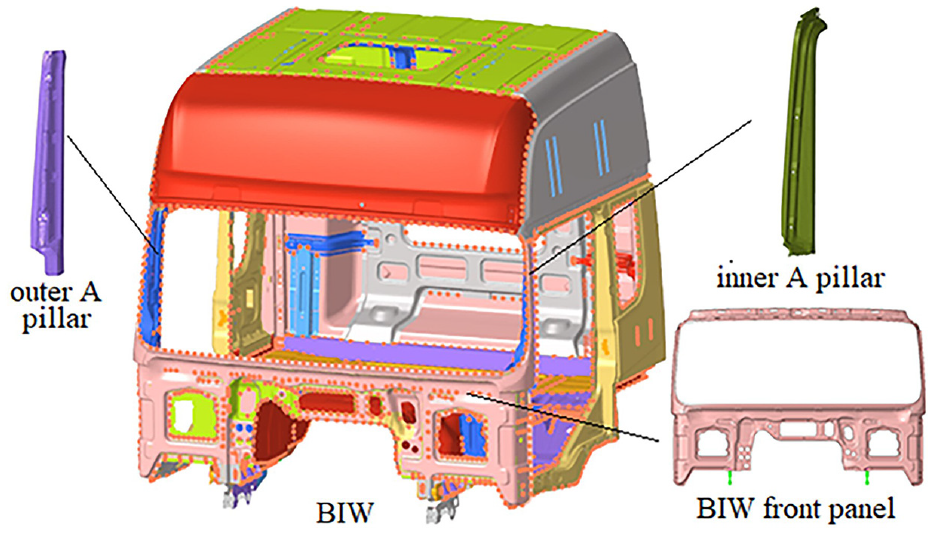
BIW finite model.
The BIW FE model is composed of sheet metal models. The FE model is preprocessed before the simulation. Some unimportant points, lines, surfaces, and holes are firstly deleted in Hypermesh. After that, Quad and Tria are used on two-dimensional mesh drawing of the model. The elastic modulus, Poisson’s ratio, and density of each sheet metal model are assigned according to actual materials. RBE2 and RBE3 units are adopted to take place of spotwelds and bolt connections. The design parameters of the FE model are shown in Table 3.
Finite element model parameters of BIW.

BIW surrogate model
The improved strategy of NSGA-II cannot be used in the optimization of BIW structure directly, therefore a BIW neural network surrogate model is established based on FE model to describe the relationship of design variables with first torsional mode and bending-torsion stiffness.
The selection of design variables of surrogate model
Design sensitivity analysis (DSA) is used on the BIW FE model to select design variables of the surrogate model. The design sensitivity is the partial derivative of the DSA result with respect to DSA design variables. The model thicknesses are taken as the DSA design variables and the BIW mode frequency is taken as the DSA result. The design sensitivity of each sheet metal model is calculated by OptiStruct Solver. The DSA results are ranked in order, and the top five sheet models are shown in Table 4.
Sorting results of DSA.

The design sensitivity greater than 0.5 indicates that the model has a great influence on the BIW mode frequency. 18 Therefore, the design variables of the surrogate model are: the thickness of the BIW front panel, inner A pillar, and outer A pillar respectively.
BIW first torsional mode
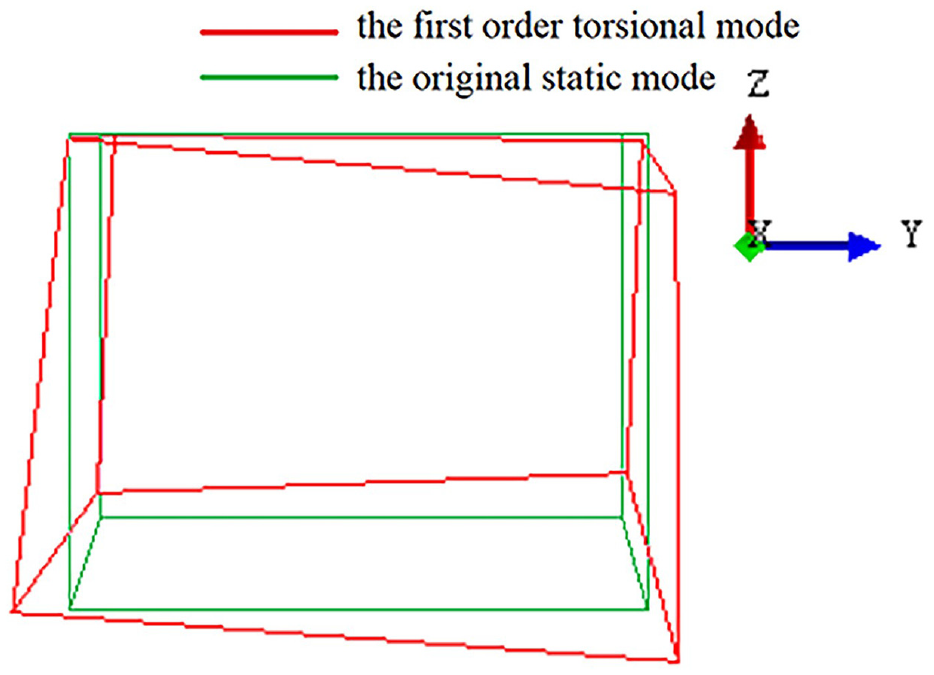
The first torsional mode and bending-torsion stiffness of BIW are calculated by FE simulation. The first torsional mode is calculated in free conditions. The analysis boundary conditions are unconstrained. The calculation frequency range is set from 0.1 to 100 Hz to avoid rigid body modes which are close to 0 Hz. The first torsional mode of original BIW calculated by OptiStruct Solver is 17.04 Hz, as shown in Figure 10.

First torsional mode of BIW.
BIW static bending-torsion stiffness
The static bending-torsion stiffness of BIW is calculated as shown in equation (11).

Where, G is the bending-torsional stiffness, T is the loading force, L is the distance between front and rear suspension mounts, d1 and d2 are the displacement of loading points respectively, and B is the distance between front left and front right suspension mounts. Physically speaking, T stands for BIW longitudinal length, and B stands for the transverse length. For a BIW, T and B are fixed. If the deformation is smaller under loading, the stiffness of BIW will be larger.
Finite element statics analysis method is used to calculate d1 and d2. Two rear suspension mounts are constrained in six degrees of freedom. Two coplane and opposite vertical forces F are applied on two front suspension mounts respectively. Both forces are 1000 N. Boundary conditions are shown in Figure 11.

Boundary conditions for BIW static analysis.
The result of statics analysis is shown in Figure 12.

Results of BIW statics analysis.
Neural network surrogate model
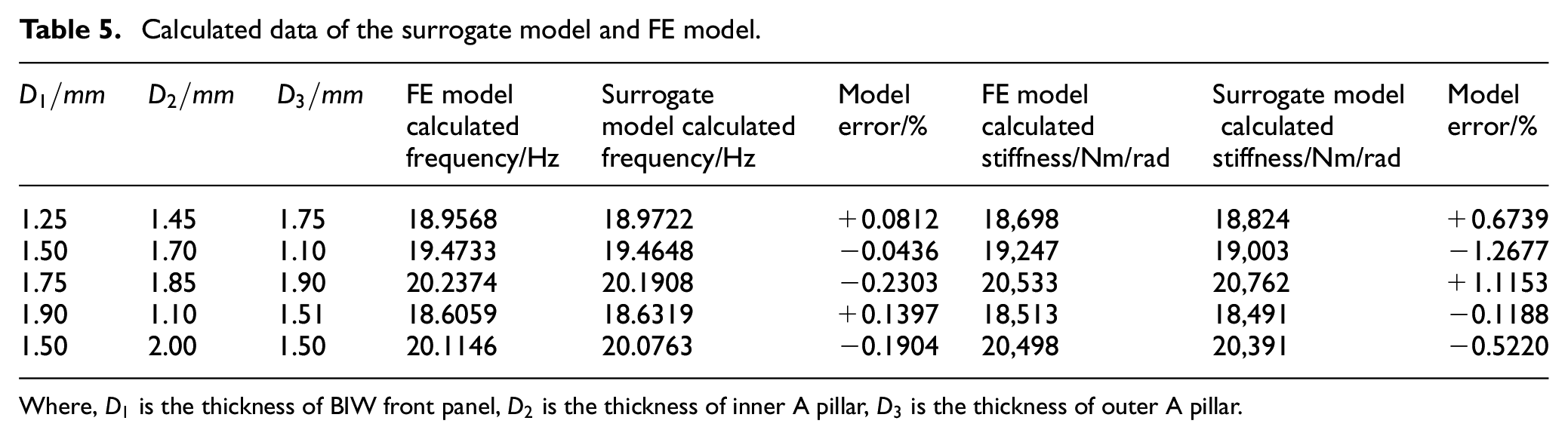
BP artificial neural network surrogate model is established to describe the relationship of design variables with the first torsional mode and static bending-torsion stiffness. Design variables are taken as the input layer of the surrogate model. The first torsional mode and static bending-torsion stiffness are taken as the output layer. The number of middle layer is 7. The BP neural network surrogate model is built with three layers of 3 × 7 × 2 structure. Input layer parameters are selected by interpolation. The design variable with greater influence on DSA results has more interpolation. The thickness of BIW front panel is 1, 1.25, 1.5, 1.75, 2 mm; the thickness of inner A pillar is 1, 1.333, 1.666, 2 mm; the thickness of outer A pillar is 1, 1.5, 2 mm. The parameters of input layer are combined to 60 sets of data. The surrogate model calculated values and the FE simulated values are shown in Table 5.
Calculated data of the surrogate model and FE model.
Where,
In Table 5, the model error is small, so the neural network surrogate model can be considered correct.
BIW structural optimization
The optimization functions are shown in equation (12).

Where,
The COSB-NSGA-II algorithm is adopted to optimize the BIW optimization functions. The optimal solution is selected based on: the BIW total mass increment is less than 3%, the first torsional mode frequency increment is more than 15%, and the torsion stiffness increment is more than 10%.
The optimal solution set obtained is shown in Table 6.
The optimal solution set.

For the convenience of model manufacturing and engineering testing, the thickness of the sheet metal models are chose as integer according to Table 6. The thickness of BIW front panel, the inner A pillar, and the outer A pillar is selected as 2.00, 2.00, and 1.00 mm respectively. The trial-produced samples are made and verified by the BIW free mode test.
In the test, the BIW is suspended by hammock and soft rubber rope, and acceleration sensors are installed at the eight corners of BIW to measure the mode data. The first torsional mode is applied by two vibration exciters. The exciting force angle of each vibration exciter is 45°. One vibration exciter is located in the front of BIW, and another is in the rear, as shown in Figure 13. The excitation signal is random initiation signal, and the bandwidth is 500 Hz.

BIW free mode test.
BIW free mode test values are calculated in LMS TEST.LAB software as shown in Figure 13. The first torsional mode test result is 20.1826 Hz. The surrogate model calculated mode is 20.1803 Hz as shown in Table 6, the model error is 0.01%. Which proves the correctness of the results and the correctness of NSGA-II in BIW structure optimization. First torsional mode test results is shown in Figure 14.
First torsional mode test results.
Conclusions
Three NSGA-II improved algorithms are proposed: side length optimization strategy based NSGA-II (SLOSB-NSGA-II), diagonal optimization strategy based NSGA-II (DOSB-NSGA-II), and center optimization strategy based NSGA-II (COSB-NSGA-II). The performance differences between NSGA-II and the three improved algorithms are compared by ZDT, DTLZ test functions, and IGD values. The results show that the performance of the three improved algorithms is better than original NSGA-II, and COSB-NSGA-II has the best performance among the three improved algorithms.
The surrogate model is established by BIW finite element model and used to describe the relationship between sheet metal model thickness and BIW mass, first torsional mode and static bending-torsion stiffness. The surrogate model and COSB-NSGA-II are used to optimize the BIW structure. The BIW total mass increment is less than 3%, the first torsional mode frequency increment is more than 15%, and the torsion stiffness increment is more than 10%. The optimization results are verified by BIW first torsional mode test. This study provides a reference for the improvement of NSGA-II algorithm and its application in BIW structure optimization.
However, the current research only compares the improved algorithm with the original NSGA-II, and only applies it to the optimization of BIW. The comparison between these improved algorithms and other studies, the diversified evaluation and the application in other engineering aspects need further research.
Footnotes
Handling Editor: Chenhui Liang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors acknowledge the support from the National Key R&D Program of China (No. 2018YFB0106200).