
Abstract
Rolling bearings are present ubiquitously in mechanical equipment, timely fault diagnosis has great significance in guaranteeing the safety of mechanical operation. In real world industrial applications, the distribution of training dataset (source domain) and testing dataset (target domain) is often different and varies with operating environment, which may lead to performance degradation. In this study, a cross-domain fault diagnosis of rolling bearing method based on distance metric transfer learning (DMTL) and wavelet packet decomposition (WPD) is proposed. The Mahalanobis distance is adopted for learning the intrinsic similarity or dissimilarity between instances and learned by simultaneously maximizing the intra-class distances and minimizing the inter-class distances for target domain. The features of source domain and target domain are first extracted from original vibration signals by WPD which is a powerful tool in dealing with non-stationary signals and can provide meticulous analysis. Then, the DMTL model is adopted to eliminate the error propagation across different components, which can weaken the weight of low-quality instances and enhance the weight of high-quality samples. Finally, the k-nearest neighbor (KNN) classifier is applied to accomplish the cross-domain intelligent fault-type classification. The superiority and effectiveness of the proposed fault diagnosis model is validated by two diagnosis cases. The experimental results demonstrated that the proposed method performs better than other compared methods in recognizing various fault types and has the capability in handling the complex cross-domain adaptation scenarios.
Keywords
Introduction
Rolling bearings play an indispensable role in equipment, which are prone to breakdown since they often operates with awful conditions, such as high temperature, heavy loads, high rotating speed, and etc., and almost 45%–55% of rotating machinery failures are rolling bearing faults.1–3 Unexpected failures may boost the cost of operation, maintenance and even lead to catastrophic casualties. 4 To ensure the safety and reliability of the rotating machinery, accurate and efficient diagnosis of incipient faults is extremely important.
Conventionally, the fault diagnostic techniques collect and process various signals with the goals of resuming from malfunctions or faults and precluding from future failures as early as possible.2,5 Data-driven fault recognition approaches related to artificial intelligence techniques or machine learning techniques, such as support vector machine (SVM), k-nearest neighbor (KNN), and artificial neural network (ANN), etc., have been extensively studied to improve existing techniques with the goal of more accurately and effectively dealing with various complex problems, such as varying load effect and noise contamination.6–8 Additionally, deep learning methods have been widely used for condition recognition over the past decades.9–11 These intelligent recognition techniques have achieved great success in distinguishing operating conditions of various machines under complex working environment.
Despite huge success, most of the intelligent recognition methods work well under two general hypotheses: one is abundant labeled training samples are available; the other is the training and testing dataset are drawn from the identically probability distribution. However, in real-world scenarios, the performances of these methods may dramatically decline because of the variations between the distributions of training data (source domain) and testing data (target domain). 12 The distribution of collecting dataset varies with the operating environment, such as the installation conditions of experimental platform, motor loads, humidity, temperature, and etc., which is known as cross-domain learning problem. 13 The variations (domain shifts) could cause a great discrepancy between the features extracted from the signals obtained from experimental settings and the signals collected from actual operating situation.
Recently, transfer learning methods have received extensive studies, which can adapt a machine learning model trained by dataset of source domain to a different but related target domain.14–16 The learning strategies of most published transfer learning methods can be roughly divided into three categories: feature-based methods, instance based methods and metric-based methods. 17 The feature-based learning aims to discover a feature subspace in which the recognition model trained in source domain is qualified for target domain.18,19 Instance-based transfer learning aims at reweighting the source samples according to the shared information provided by target data, which the reweighted instances can be further analyzed.20–22 Metric-based methods, distance metric learning (DML) algorithms, aims to learn an optimal distance metric for measuring sample pairs similarity or dissimilarity by exploiting meaningful correlations between instances in source and target domain, 17 which can effectively reduce the distribution divergence between domains and extract the weakly discriminative information. 23 Cao et al. proposed consistent distance metric learning to estimate the instance weights under covariate shift situations, which the Euclidean distance metric was utilized to determine sample pairs correlation. 24 Huang and Zhou presented an unsupervised metric transfer learning method (UMTL) to learn domain invariant features with more discriminative information via Maximum Mean Discrepancy. 25 Most existing transfer learning algorithms use the Euclidean distance to estimate the dissimilarity or similarity between the samples in source or target domain.
However, the Euclidean distance is adopted to measure the dissimilarity and similarity between samples in most existing transfer learning techniques, which may decline the transfer learning performance since Euclidean distance would not maximize the inter-class distances while minimizing intra-class distances. 26 Ahmadvand and Tahmoresnezhad presented Metric Transfer Learning via Geometric Knowledge Embedding, Mahalanobis distance metric and the graph optimization were employed to reweight the instance weights of source samples for distribution matching. 17 Xu et al. put forward a metric transfer learning framework to encode metric learning in transfer learning. 27 Therefore, Mahalanobis-distance-based transfer learning can effectively minimize the distance between source and target domains.
Inspired by the strategy of transferring knowledge from source domain to target domain, a cross-domain fault diagnosis of rolling bearing method based on distance metric transfer learning (DMTL) and wavelet packet decomposition (WPD) is proposed in this study. Based on the metric learning, the Mahalanobis distance instead of Euclidean distance is adopted in the objective function of cross-domain adaption for learning the intrinsic similarity or dissimilarity between instances. Then, the intra-class distances of target domain are maximized and the inter-class distances of target domain are minimized to improve recognition accuracy by using the intrinsic information among samples from different domains with labels. Experimental investigations are carried out to demonstrate the feasibility and effectiveness of the proposed method for rolling bearing fault diagnosis.
The rest of the article is organized as follows. In section II, the principle of DMTL is introduced. Then, the fault diagnosis model based on the DMTL and WPD algorithm is presented in Section III. After that, the practical cases are studied to validate the superior performance of the proposed model in Section IV. Finally, some concluding remarks are summarized in Section V.
Principle of distance metric transfer learning
Suppose the domain
Since there is a discrepancy between the distribution of source domain and target domain, the labeled samples of source domain cannot be directly applied to learn a distance metric for target domain. To address this issue, the labeled samples of source domain are reweighted meanwhile preserving the distance relation among data in source domain and target domain, which can provide discriminative information for target domain. In this study, a reweighting instance strategy called distance metric transfer learning (DMTL) is investigated, and the objective function of DMTL method consists three parts as follows:

where the first term
Gegularization term of distance metric learning
Since the Mahalanobis distance is learned by information theoretic metric learning which is helpful for classification problems,
27
Mahalanobis rather than Euclidean distance metric learning for target domain is applied in this study. Assuming

where

Here, the regularization term of distance metric learning
Regularization term of instance weights
To avoid the potential issues in studying the instance weights

where
The density ratios

Here, equation (5) can be transformed by the optimization problem as follows:


Since the logarithmic function is convex, the optimal solution of equation (6) can be calculated by gradient ascent approaches. As seen in equation (6), all the samples of source domain and target domain including labeled and unlabeled are adopted to deduce parameters
To improve the performance of knowledge transferred across domains, the Mahalanobis distance metric in terms of
Loss function of prediction model
The loss function of prediction model with learned Mahalanobis distance metric

where

Substituting equations (3–4), and equations (7–8) into equation (1), the objective function of DMTL method can be obtained:

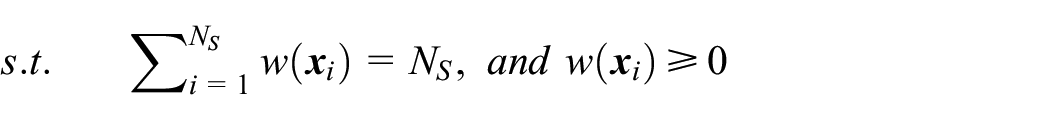
where
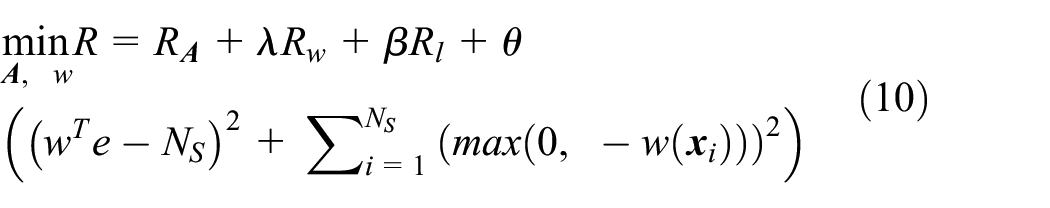
where
Since the equation (10) is non-parametric, an alternating optimization algorithm is introduced to learn metric

where
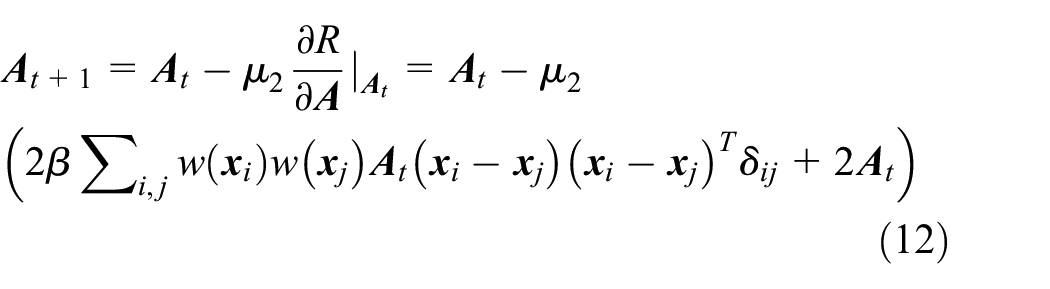
The metric
Process of fault diagnosis by distance metric transfer learning
The sensitive features of source domain and target domain are first extracted from original vibration signals by using a unified feature extractor. The vibration signals of fault bearings are generally non-stationary, and WPD is a powerful tool in dealing with non-stationary signals which can provide more meticulous analysis.
28
WPD can effectively decompose a signal into both high- and mid-frequency information along with the corresponding frequency regions, which is widely used for fault diagnosis.6,28,29 Therefore, the features related to WPD including the relative energy in a wavelet packet node (REWPN) and the entropy in a wavelet packet node (EWPN) is extracted, where the REWPN denotes the normalized energy of the wavelet packets node, and the EWPN indicates the uncertainty of normalized coefficients of the wavelet packets node.
6
For a give sample
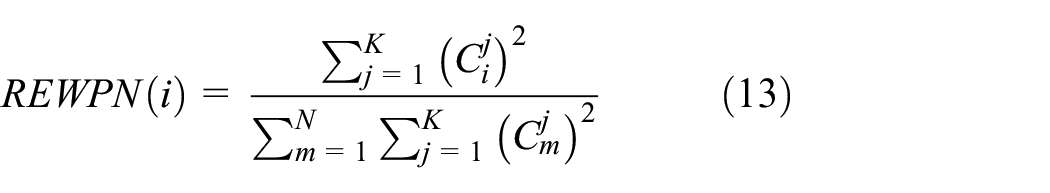
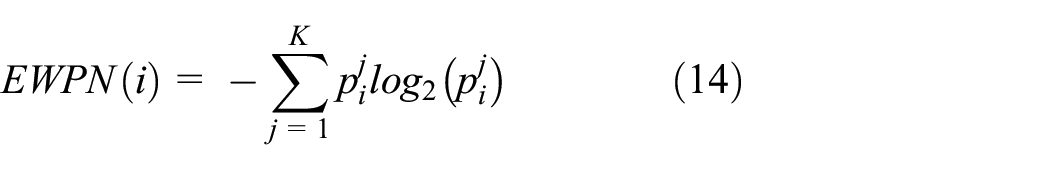
where
After the construction of feature set, a transfer learning strategy of improving predictive performance is put forward. Since DMTL can effectively eliminate the error propagation across different components, a fault diagnosis model based on the DMTL is proposed in this study, which contains model training stage and diagnosis stage, and the flowchart of proposed fault diagnosis method is shown in Figure 1. The heterogeneous features of source domain and target domain are first constructed from original vibration signals, which are subsequently normalized by l2-norm. Then the optimal instance weights are obtained by DMTL which can weaken the weight of low-quality instances and enhance the weight of high-quality samples of source domain in training stage, and the KNN classifier is trained using adjusted samples of new subspace. The optimal weights of test samples are obtained by trained DMTL model in diagnosis stage, the obtained features are fed in trained KNN model to recognize the running state of rotating machinery. The corresponding decisions or control measures can be put forward by the classification results.

Overall framework of the proposed fault diagnosis method.
Experimental and results
Experiment design and datasets
To validate the performance of proposed method, two cross-domain roll bearing fault diagnosis scenarios are conducted. Rolling bearings are vulnerability components for rotation machinery, the frequent faults of rolling bearings are inner race fault, outer race fault and ball fault. 5 In engineering practice, the status of bearings is monitored by using vibration signals and temperature of system. Then a real-world run-to-failure bearing fault diagnosis are conducted to further demonstrate the performance of the proposed method. The detailed description is shown in Table 1.
Details of datasets.


Bearing test rig.
Experimental results
The sensitive features of source domain and target domain containing REWNs and EWPNs are first extracted from original vibration signals. The wavelet packet node energy features obtained by Daubechies2 (db2) wavelet packet decomposition were discovered to attain better recognition performance for bearing fault diagnosis after a lot of experiments on a serials of Daubechies wavelets.
6
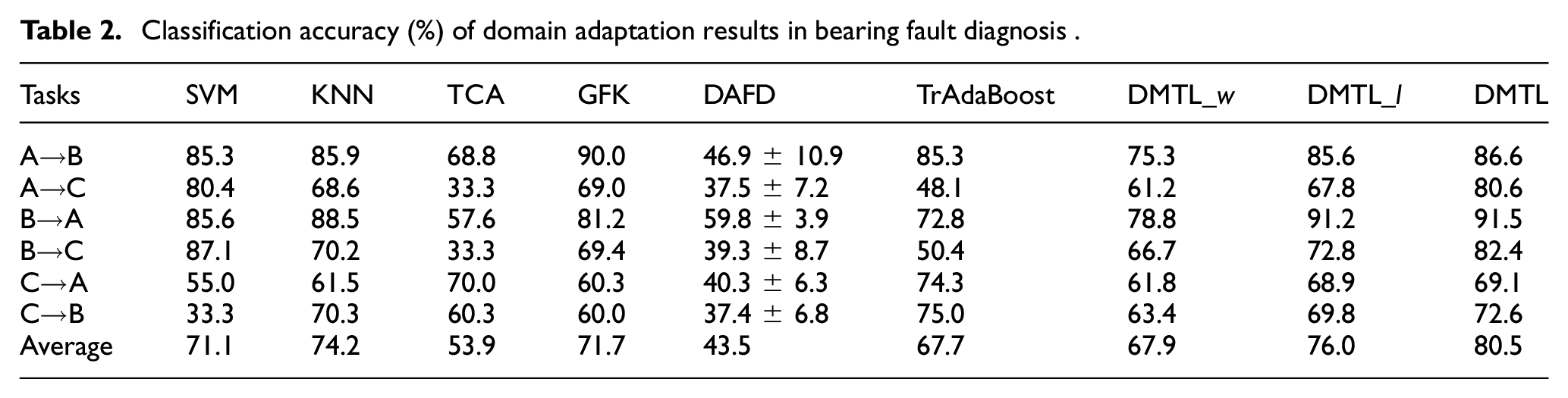
Herein, the db2 is adopted as the mother wavelet function to implement binary WPD for vibration signals, and the maximum decomposition level is set to 4. After the construction of feature set, a transfer learning strategy of improving predictive performance is put forward. Additionally, to further investigate the effect of the instance weights of source-domain labeled samples and learned Mahalanobis distance metric to the overall performance, a reduction of DMTL denoted DMTL_w only adopts instance weights, and a reduction of DMTL denoted DMTL_l only considers the learned Mahalanobis distance metric. Where the metric
To validate the advantage of the proposed DMTL method, several popular state-of-art supervised learning methods and transfer learning methods are conducted for comparison, including Support Vector Machine (SVM),
30
k-nearest neighbor (KNN),
31
Transfer Component Analysis (TCA),
32
Geodesic Flow Kernel (GFK),
33
Deep neural network for domain Adaptation in Fault Diagnosis (DAFD),
34
and TrAdaBoost.
20
SVM and KNN are conventional pattern recognition methods. TCA, GFK, and DAFD are subspace-based transfer learning methods, TCA is the representative method of feature-based transfer learning approaches, GFK learns the transferable features by constructing geodesic flow kernel, DAFD is a transfer learning method based on deep neural network which has been widely used in fault diagnosis. TrAdaBoost is the representative method of instance-based transfer learning approaches. Detailed parameter settings of above methods are described as follows. The Guassian kernel is applied in SVM classifier, and the tradeoff parameter is 1. For KNN, the number of nearest neighbor ranges from 1 to 63, and the optimal results are selected. For TCA, the optimal hyperparameters are obtained by Bayesian optimization approach, where the regularization tradeoff parameter
Classification accuracy (%) of domain adaptation results in bearing fault diagnosis .
Classification accuracy (%) of domain adaptation results in bearing fault severity diagnosis.

Sensitivity analysis for different parameters in dmtl
Different parameters may influence the classification performance of DMTL, the sensitivity studies on the parameters of DMTL were conducted in this section.

Sensitivity analysis of number of nearest neighbors K.

Sensitivity analysis of number of instance pairs C.

Sensitivity analysis on trade-off parameters λ and β.
Conclusions
In this study, a cross-domain fault diagnosis model based on distance metric transfer learning (DMTL) is proposed to recognition the operating condition of rolling bearing when the labeled samples in target domain is insufficient. DMTL reweights samples in source domain by maximizing the intra-class distances and minimizing the inter-class distances for target domain, and the objective function is defined on basis of Mahalanobis distance instead of Euclidean distance. The features of source domain and target domain are first extracted from original vibration signals by using wavelet packet decomposition (WPD). Then, the DMTL model is adopted to eliminate the error propagation across different components, which can weaken the weight of low-quality instances and enhance the weight of high-quality samples. Finally, the k-nearest neighbor (KNN) classifier is applied to accomplish the cross-domain intelligent fault-type classification. The effectiveness and superiority of proposed DMTL and WPD method is verified through two transfer recognition experiments. Compared with other peer methods, the proposed method has better fault diagnosis effect in cross-domain adaption tasks, which implies that the proposed method possesses accurate recognition performance in target domain than other compared ones by using only a few of labeled target samples and massive source samples.
Footnotes
Handling Editor: Chenhui Liang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is sponsored by the National Natural Science Foundation of China (Grant No. 52005168), the Green Industry Technology Leading Program of Hubei University of Technology (XJ2021005001), and the Scientific Research Foundation for High-level Talents of Hubei University of Technology (GCRC2020009).