
Abstract
Parallel machines scheduling problems with continuous availability of machines are NP-hardness (non-deterministic polynomial-time hardness) and have become very popular for the last decade; there is still very limited literature on this problem. The purpose of this paper is to focus on the problem of scheduling n independent jobs to be processed on m unrelated identical parallel machines with availability constraints to minimize the maximum completion time of jobs (makespan). For this NP-hard problem, a mixed-integer linear programming (MILP) model is proposed to find an optimal solution for this problem. Two metaheuristics, tabu search (TS) and simulated annealing (SA) are proposed to solve large scale problem. Moreover, the performance of the solution obtained by the proposed metaheuristics is evaluated based on a lower bound, which decreases the time required to find the optimal solution. Extensive experiments are carried out to assess the performance of all proposed metaheuristics. The computational results highlight the ability of the proposed metaheuristics to obtain optimal solutions for most of the instances compared with the solutions of the proposed MILP model and lower bounds. Moreover, SA and TS can provide good efficiency for the problem in any jobs size and any machine size, but TS provides worse CPU time as the size of jobs become large.
Introduction
Parallel machine scheduling has been an interesting topic of research due to the breadth of its potential applications,1–6 which include scheduled drilling mechanisms in printed circuit board manufacturing facilities, textile industry activities, dicing of semiconductor wafers used in computer manufacturing, and ship docking systems. 7 This popularity has grown significantly in recent years as a result of the development of parallel processor computing systems. 8 A parallel bank of machines is a significant configuration from both a theoretical and practical perspective. It is an extension of the single machine and a subset of the flexible flow shop from a theoretical viewpoint. It is significant from a practical perspective since the presence of resources in parallel is frequent in the real world. Additionally, parallel machine approaches are frequently employed in decomposition procedures for sequential systems. 9
In this article, we considered the problem of scheduling unrelated identical parallel machines with availability constraints. In this problem, there are n independent jobs and m unrelated identical parallel machines. Job j (j = 1, 2, …, n) becomes available for processing at time zero and requires a processing time pij if job j is assigned to exactly one machine i (i = 1, 2, …, m). Preventive maintenance actions are often carried out to keep the manufacturing system at the desired level of operation by preventing failures before they happen. There is only one maintenance period that occurred for each machine i [tBi, tEi]. The main objective is to determine the set of job sequences that processes all jobs and minimize makespan, Cmax, which is the completion time of the latest finished job. The Graham scheduling notation α | β | γ for the problem is represented by Rm | availability | Cmax.
Several studies,5,10–18 have been proposed to solve parallel machine scheduling using different metaheuristic algorithms to minimize different objective functions such as makespan, total tardiness, the weighted sum of completion times, and the number of tardy jobs. Computational studies were carried out to determine the heuristics’ performance and execution time. It observed that TS and SA outperform other metaheuristic algorithms, and as a result, TS and SA are recommended for this problem. Fanjul-Peyro and Ruiz 19 proposed a set of simple iterated greedy local search-based metaheuristics for unrelated parallel-machine scheduling for makespan minimization, which produces solutions of remarkable quality in a very short amount of time. Vallada and Ruiz 20 applied a genetic algorithm (GA) to the scheduling of unrelated parallel machines subject to machine and job sequence setup times. The proposed GA consists of a simple local search and a crossover operator improved with local search; it showed excellent performance as a model for large- and small-scale experiment. Fanjul-Peyro and Ruiz 21 presented mathematical formulations for mixed-integer programming based on two generalizations of non-identical parallel machine scheduling for makespan minimization. The first is a condition under which not all parallel machines should be employed but a subset. The second is that there is no need for managing all available jobs. Extensive testing demonstrates that the two suggested methods significantly improve the results. Balin 22 developed a GA and fuzzy processing time simulation technique for scheduling a set of unrelated parallel machines. The obtained results were compared to those obtained when the LPT rule was used. The results of the proposed method were excellent and easy to achieve. There are two metaheuristics proposed by Joo and Kim 23 : the self-evolution algorithm and a GA for assessing job allocation and non-identical parallel-machine scheduling for the aim of minimizing the makespan. Several randomly generated instances were used to compare the meta-heuristic algorithms’ efficiencies with optimal solutions. Fleszar et al. 24 hybridized a variable neighborhood descent search algorithm with mathematical programming for scheduling jobs on unrelated parallel machines in order to minimize the makespan. Joo and Kim 25 developed a hybrid GA with dispatching rules for scheduling a series of jobs on non-identical parallel machines with sequence- and machine-dependent setup times and machine-dependent processing times with the aim of minimizing the makespan. Geyik and Elibal 26 developed a fuzzy linguistic technique for solving non-identical parallel-machine scheduling considering the learning effect and uncertain processing times.
It is well known that parallel machines scheduling problems with continuous availability of machines are NP-hard. 27 With availability constraints, unrelated parallel machine scheduling problems are NP-hard for the makespan objective.28–30 Although scheduling problems with availability constraints have become very popular for the last decade, there is still very limited literature on this problem. Therefore, this paper aims to propose a mathematical model to optimize the unrelated parallel machines scheduling problem under availability constraint to minimize makespan. To do this, a new mixed-integer linear programming (MILP) model is developed to find an optimal solution for this problem. In the second step, two metaheuristics, tabu search and simulated annealing are presented to solve the MILP model in the case of larger-scale problems and the obtained results compared with a proposed lower bound to assess the effectiveness of the proposed metaheuristics solutions.
The main contributions of the present research are as follows.
A new mixed-integer linear programming (MILP) model is developed for unrelated parallel machine scheduling problems to minimize the makespan with availability constraints. It can handle all unreliable machines in the system.
Preventative maintenance actions are developed for unreliable machines.
Efficient metaheuristic algorithms are suggested to solve the scheduling problem.
A lower bound is developed to evaluate the solution obtained by the proposed metaheuristics.
The rest of the paper is organized as follows. Section 2 the problem and presents the formulation of the developed mixed-integer linear programming model, the synthesis of lower bound, and numerical example. Sections 3, 4, and 5 display the suggested metaheuristics, computational analysis and results, and sensitivity analysis, respectively. Finally, Section 6 presents conclusions and future work.
Problem formulation
Problem definitions
The considered problem is depicted as follows. There are n jobs, which are processed on m unrelated parallel machines. The scheduling problem has following assumptions on jobs and machines.
At most one machine can process just one job at a time;
At time zero, all jobs are available for processing and all machines are available;
No jobs can be processed on more than one machine at a time, and each job operation must be completed;
The processing times and PM windows are fixed and known in advance.
The main objective is to minimize the makespan for all jobs under availability constraint of machines. The Graham scheduling notation is represented by Rm | availability | Cmax. The problem Rm | | Cmax is a classical unrelated parallel machine problem and NP-hard, 14 where there is no availability constraint. Since our problem Rm | availability | Cmax is more general than Rm | |Cmax it is obviously NP-hard.
Formulation of the mixed integer linear programming model
This section proposes a mathematical model (using some constraints from Al-Ahmari et al. 31 ) for unrelated parallel machine scheduling problem under availability constraint to minimize makespan. The mixed integer linear programming model is sated as follows:

Subject to

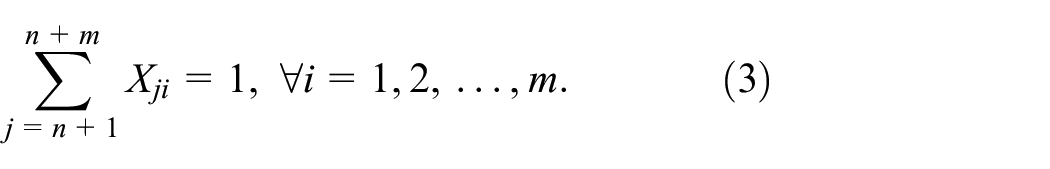




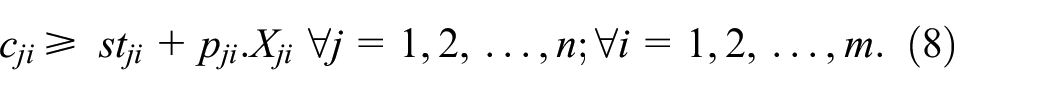
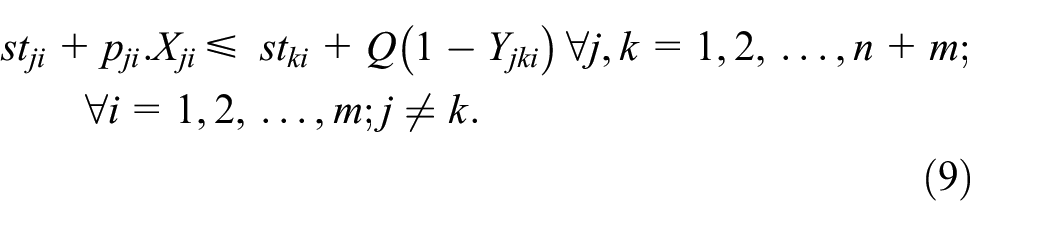







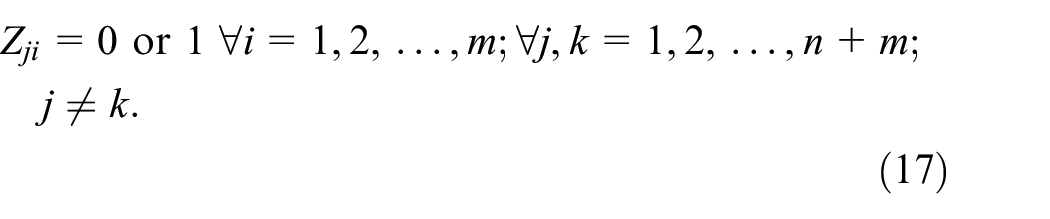
Objective (1) minimizes the maximum completion time of the solution. Constraint (2) guarantees that each original job j in n is performed on exactly one machine. Constraints (3, 4, and 5) guarantee that periods of unavailability are completed and only one unavailability period is allocated to each machine i. Constraints (6 and 7) confirm that assigned jobs must appear once in their sequence on the same machine. The job j completion time is determined by constraint (8). Constraints (9 and 10) confirm the correct order of the jobs and the completion time of job k should be greater or equal than the job j completion time. Constraints (11 and 12) confirm that the starting time and completion time of the dummy jobs have to respect the preventive maintenance period [tBi, tEi]. Finally, constraints (13–17) define the non-negativity and integrality of the variables.
Lower Bound
In this section, we propose the LBs – LB1 and LB2, which we use to assess the performance of the metaheuristic method used to find the best makespan. Let

The valid first lower bound

Since each job must be scheduled, a second lower bound

Therefore, a valid lower bound

Numerical Example
Consider an unrelated parallel machine scheduling problem that consists of three machines i = 1, 2, 3 operating nine original jobs j = 1, 2, …, 9 and three dummy jobs j = 10, 11, 12 denoting to preventive maintenance of machines. The job processing times on machines
The job processing times (h).

The preventive maintenance periods.

The optimal MILP model solution and decision variables.

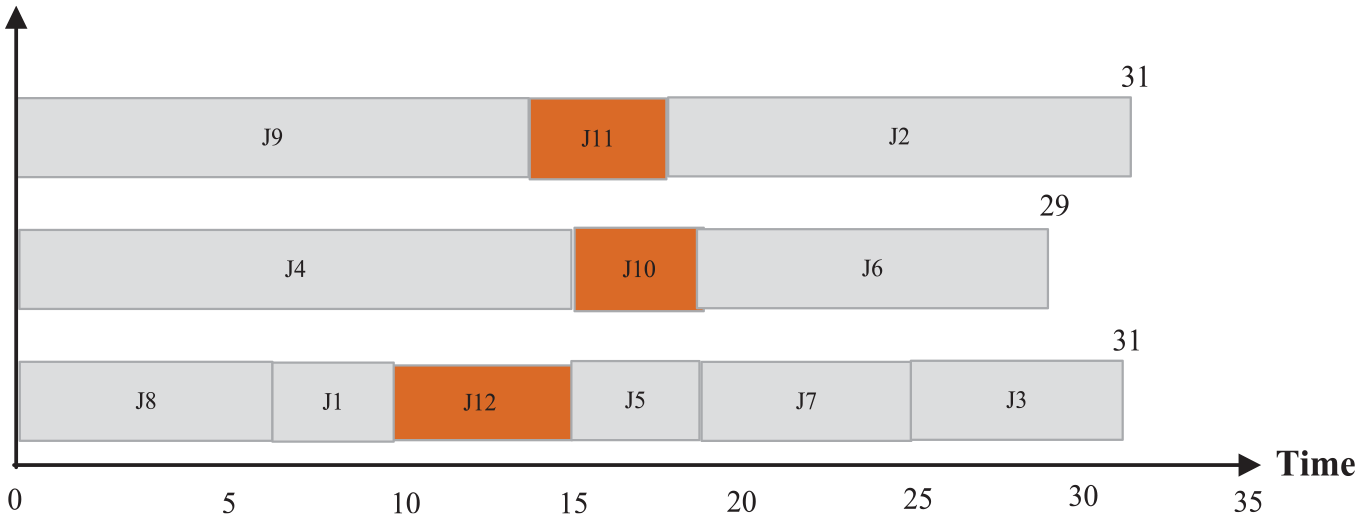
Gantt chart of the optimal sequence for jobs using MILP.
Metaheuristic Algorithms
Tabu Search
Tabu search is a popular metaheuristic search approach using local search techniques for optimization problems Glover. 32 Tabu search is carried out using a neighborhood or local search mechanism to iteratively move from one feasible solution A to an improved solution B in the neighborhood of A until a stop condition is satisfied. In order to prevent solutions previously visited, tabu search uses memory named tabu list to store results about the search process. The tabu list is updated in each TS iteration. The risk of rejecting solutions, which have not yet been created may occur due to the restrictions in the tabu list. Tabu results are then tested for such parameters, which are known as aspiration criteria. If the tabu value is better than the best objective value found earlier, the tabu will accept the solution and delete its move from the tabu list. TS has many factors or parameters, which must be tuned before its searching starts. Initial solution, the next element, the tabu list, the aspiration condition, and the stopping condition are main stopping of the TS. In this study, the initial solution for TS has been set by the dispatching rule longest processing time (LPT) policy, which sequences tasks or jobs in a descending order of processing time. In addition, to generate new candidate solutions for TS algorithm, we used the pairwise interchange operator. According to preliminary experiments, the number of candidates generated was 50. The size of the tabu list is set to 10 elements and the first-in-first-out (FIFO) technique is used to update the tabu list based on the same preliminary experiments. As previously reported, the aspiration criteria were applied (when a move leads to a better solution than the previously found best solution value). Finally, the stopping criteria is then defined such that computational times (in s) are similar in each algorithm or if the lower bound is reached. The general TS algorithm is constructed in Algorithm 112,33:

Simulated annealing
Simulated annealing is a popular metaheuristic and has been applied in several combinatorial problems.
34
Algorithm 2 includes the implemented SA algorithm for estimating the makespan. Simulated annealing improves several initial solutions to achieve the stopping criterion and the output is the best global solution found. For each individual solution, the following procedures are stated: (1) obtain the initial solution using LPT rule; (2) set the initial temperature

Computational Results
The proposed metaheuristic algorithms and the computational experiments for all instances has been coded and implemented using MATLAB R2015a on the computer with Intel(R) Core (TM) i7-4702MQ CPU @ 2.20 GHz, 16 GB RAM.
Data generation
The metaheuristic algorithms proposed in this paper are conducted and evaluated computational experiments were implemented using randomly generated test 32 instances with fixed the number of jobs 10, 12, 15, 20, 50, 70, 100, 150 and number of machines 2, 3, 5, 7. The jobs processing times are integer values and generated randomly according to the uniform distribution as U(1, 100). The starting times of the preventive maintenance periods tBi are drawn from the uniform distribution on
Parameter tuning
In metaheuristics design, tuning parameters is an important issue. Each metaheuristics has its parameter values that affect its effectiveness. For this, experimental runs are conducted for parameters values of algorithms, and Table 4 shows the best setting of parameters for two algorithms.
The best setting for SA and TS parameters.

Experimental results
There are two types of instances, which are small sized instances with n = {10, 12, 15}, m = {2, 3, 5, 7} and large sized instances with n = {20, 50, 70, 100}, m = {2, 3, 5, 7}. Table 5 shows the experiments results of small sized instances. Table 5 display the optimal MILP model solution by Lingo and relative percentage deviation (RPD) of 15 replications computed with the equation (22) by metaheuristic algorithms for each test instance, where “Average RPD,”“Min RPD,” and Max RPD are the average, minimum, maximum RPD of the metaheuristic algorithm solution from the optimal solutions.

Comparisons metaheuristics for small sized instances.

where
In order to validate lower bounds shown in equations (21) and (22), it is important to investigate if the observed differences in the optimal solution and the lower bound values of small sized instances that computed by MILP presented in Figure 2 are statistically significant. The significant differences can be computed using two-sample t-test. Table 6 displays the mean, standard deviation, and p-value of t-test at the 95% confidence level. The t-test indicates that statistically significant differences are not occurred with p-value = 0.781 between the optimal solution and lower bound values. Therefore, the developed lower bound is valid and can be applied to different sized instances.

Comparison lower bound with optimal solution for small sized instances.
Comparisons LB with optimal solutions using t-test.

Table 7 shows the experiments results of large sized instances, the lower bound, and relative percentage deviation (RPD) of 15 replications computed with the equation (23) by metaheuristic algorithms for each test instance.

Comparisons metaheuristics for large sized instances.

Where
To evaluate the proposed algorithms, it is important to investigate if the observed differences in the makespan and CPU time values for proposed algorithms with small and large sized instances are statistically significant. The significant differences also can be computed using two sample t-test. Table 8 displays the mean, standard deviation, and p-value of t-test at the 95% confidence level. The t-test indicates that statistically significant differences are not occurred in makespan with p-value = 0.057 and 0.205 for proposed algorithms with small and large sized instances, respectively. Meanwhile statistically significant differences are not occurred in CPU time values with p-value <00000 and <0000 for proposed algorithms with small and large sized instances. Thus, SA and TS give good performance on both jobs size per machine and any machine size. However, TS provides worse CPU time as jobs size per machine and machine size become large as shown in Figures 3 to 8.
The t tests with 95% confidence on the Cmax and CPU time for all problem instances and Algorithms.
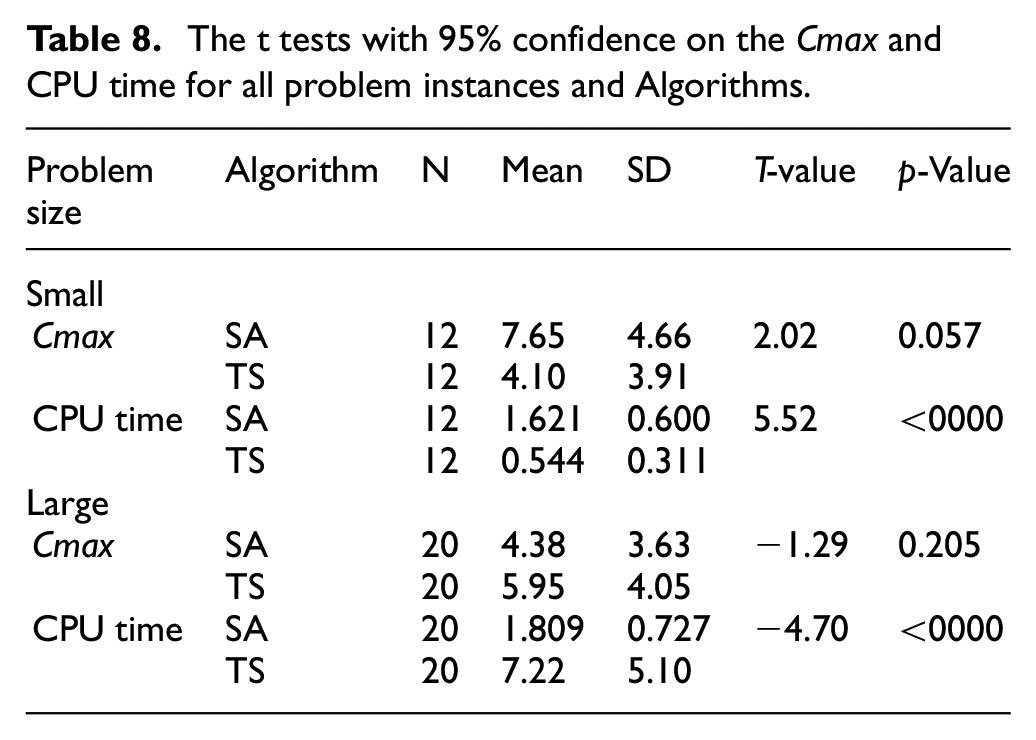

Box plot of overall average RPD for Cmax of small sized instances.
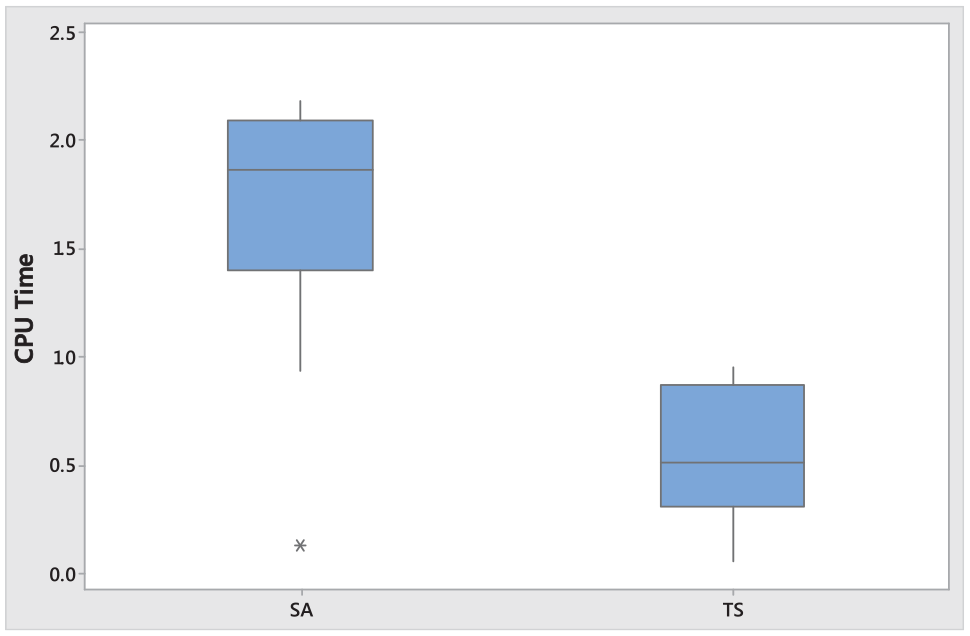
Box plot of overall average for CPU time values of small sized problem.

Box plot of overall average RPD for Cmax of large sized problem.

Box plot of overall average for CPU time values of large sized problem.

Box plot of average RPD for Cmax versus a number of machines of large sized problem.

Box plot of average RPD for Cmax versus a number of instances of large sized problem.
Figures 3 to 6 display the Box Plot of the overall average RPD for Cmax of small sized instances, CPU times of small sized problem, Cmax of large sized problem, and CPU times of large sized problem, respectively. We can clearly see from Figures 3 and 4 that in respect of Cmax and CPU time, TS has a better performance than the SA in small sized problem. Meanwhile in large sized problem, SA has a better performance than the TS in respect of Cmax and CPU time as shown in Figures 5 and 6. Figures 7 and 8 also present the Box Plot of the average RPD values for Cmax of large sized instances versus the number of machines (m) and number of jobs (n) per machines, respectively. It can be noticed that the Cmax of the proposed algorithms increases significantly, as the jobs number per machine and the machines number increases, and SA provides better performance in any machine size and any jobs size than TS.
Sensitivity analysis
A two-factor analysis of variance is used to study the effect of the number of jobs and the number of machines on the average relative percentage deviation RPD of the algorithms. Average relative percentage deviations were obtained for the eight different jobs sets (10, 12, 15, 20, 50, 70, 100, 150) and four different machines sets (2, 3, 5, 7), each with five replications. Table 9 summarizes these results. As the table indicates, the p-values of n, m, and their interaction nm are less than 0.05, therefore, the factors n, m, and nm have the greatest effect on RPD. This fact is illustrated in Figures 9 and 10. As the diagrams demonstrate, increasing the number of jobs and machines increases the RPD. The reason is that by increasing the size of sets n and m, the probability of discovering feasible interchanges increases.
Sensitivity analysis of the results of the RPD.

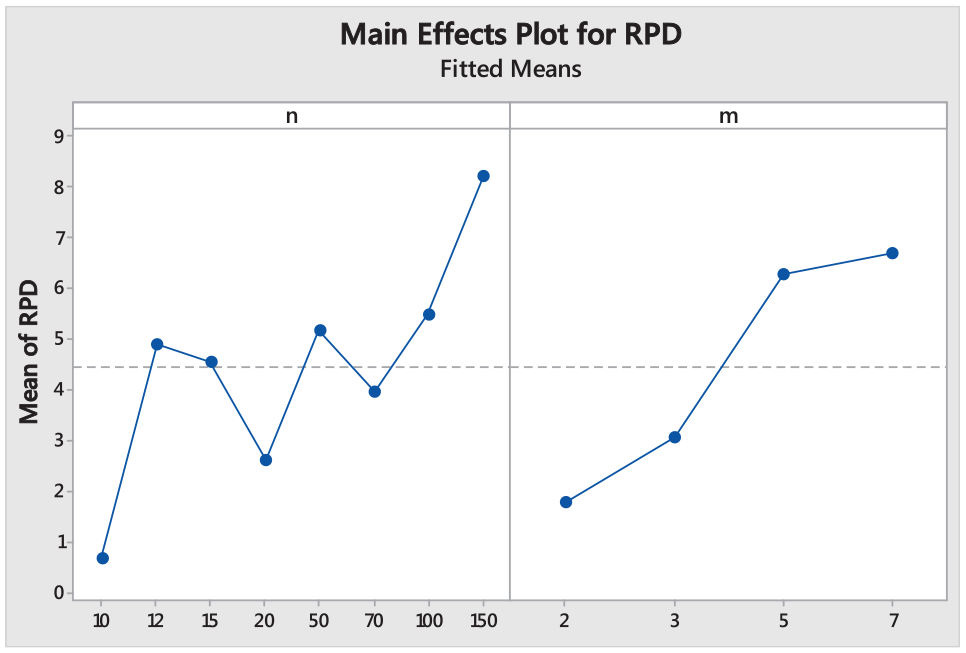
Sensitivity analysis of the RPD results using the main effects plot.

Sensitivity analysis of the RPD results using an interaction plot.
Conclusions
This paper proposes an optimal solution to unrelated parallel machine scheduling problems subject to preventive maintenance to minimize the maximum completion time of jobs. The first step is to formulate the problem using a mixed-integer programming model in order to find the optimal solution. The problem is NP-hard, which means that it cannot be solved in polynomial time with jobs n > 15. In many cases, the time required to solve this type of problem increases exponentially as n increases. To improve solution efficiency, we proposed two metaheuristics: tabu search and simulated annealing. The parameters of the proposed two algorithms were defined in such a way that they were compatible with the problem structure, and then the optimal set of parameters for the two algorithms was identified using experimental design. A lower bound is proposed to assess the accuracy of the obtained solution by the proposed metaheuristics to reduce the time for searching for the optimal solution. In addition, the t-test is used to test the significant differences between the proposed metaheuristics results. The performance of the proposed metaheuristics is examined and validated with two instance groups. The main results of the present research are as follows.
The proposed metaheuristics are very effective and efficient to obtain optimal solutions for most of the cases compared with the solutions of the proposed MILP and lower bounds.
The overall average relative percentage deviation RPD of SA with small-sized problems is 7.646%, while TS is 4.101%. Therefore, TS outperforms SA in considered small-sized problems.
For large-sized problems, the overall average relative percentage deviation RPD of SA is 4.377%, while TS is 5.946%. Therefore, SA outperforms TS in considered large-sized problems.
SA has a better performance and consumes less time than TS as the size of jobs becomes large.
Further study should be considered for the assessment and implementation of some useful information in metaheuristics to evaluate how SA and TS work with other optimization techniques. Moreover, the proposed method can be extended for the considered scheduling problem with limited buffer capacity constraints.
Footnotes
Appendix
Handling Editor: Chenhui Liang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors are grateful to the Raytheon Chair for Systems Engineering for funding.