
Abstract
This study investigates the efficiency and thematic completeness of manual versus artificial intelligence (AI)-assisted qualitative analysis of nurses’ insights into the recovery process for patients who have had emergency abdominal surgery (EAS), specifically understanding barriers and facilitators to recovery. EAS is associated with significant mortality and complications, and nurses play a crucial role in patient recovery. Extracting actionable insights from qualitative data is labor-intensive, with traditional methods requiring extensive person-hours and being susceptible to inter-coder drift. Rapid qualitative analysis (RQA) offers a streamlined approach, and commercial large language models (LLMs) may accelerate and augment qualitative research, promising semi-automated data coding and synthesis while maintaining human oversight. This study systematically compared four analytic workflows: manual RQA, ChatGPT-o3 analysis of human-generated summary notes, Microsoft Copilot GPT-4 analysis of cleaned transcripts, and ChatGPT-o3 analysis of cleaned transcripts. Manual RQA took approximately 30 person-hours, while each of the LLM-assisted methods ranged from four to eight person-hours, demonstrating significant time savings. The LLM-generated codebooks captured nearly all concepts and were highly rated by nurse participants for thoroughness, action-orientation, and relevance to their roles. The findings suggest that a pragmatic hybrid approach, using human note-taking, AI analysis, and human review, offers an effective balance of speed, ethical AI use, and rigorous qualitative analysis for implementation science. While LLMs reduced labor and provided comprehensive thematic coverage, human input and analysis remains vital to support qualitative rigor.
Keywords
1. Introduction
Emergency abdominal surgery (EAS) carries significant morbidity and mortality associated with high major complication rates and worsening quality of life (Aggarwal et al., 2019; Lau et al., 2024; Tengberg et al., 2017). A 2024 systematic review showed that physical and psychosocial recovery is often incomplete for 3–12 months after EAS, underscoring the mismatch between a “successful” operation and lived postoperative outcomes (Khanderia et al., 2024). Best-practice paradigms for Enhanced Recovery After Surgery (ERAS) consistently assigns nurses a frontline role in education prior to surgery, recognizing complications early, needs-based tailored patient education, and documenting nursing-specific barriers to pathway adoption (Brown & Xhaja, 2018).
Digital health interventions offer a promising avenue to support patients after EAS. A recent Lancet Digital Health review found 126 digital interventions for postoperative monitoring. However, 80% of those interventions were still in development and “none had reached [large-scale] implementation” (McLean et al., 2023). This highlights a significant gap in real-world evaluation and underscores the need for robust implementation science solutions to translate these promising digital health tools into effective clinical practice for EAS patients.
A crucial foundational step in the digital health design-to-intervention pipeline, particularly within implementation science, is extracting actionable insights from qualitative data (Brown et al., 2025; Palinkas & Zatzick, 2019). Traditional methods for qualitative analysis include transcription, data cleaning, codebook creation, and thematic analysis (Brown et al., 2025). Traditional thematic analysis typically requires iterative line-by-line coding by multiple researchers.
In fast-moving healthcare environments, especially in the context of implementation science where adaptive interventions are key, timely qualitative findings are vital to achieving actionable results (Brown et al., 2025; Palinkas & Zatzick, 2019). Epistemologically, this study adopts a pragmatic stance. We are not seeking a single objective truth, nor are we engaging in deep constructivist meaning-making. Instead, our goal is utility: identifying actionable clinical barriers rapidly to improve patient care. To bridge the gap between evidence and practice, researchers have increasingly turned to accelerated approaches that preserve analytic rigor while reducing turnaround time (Vindrola-Padros & Johnson, 2020). While accelerated approaches such as Framework Analysis, Applied Thematic Mapping, or Agile Thematic Synthesis offer rigorous structures for analysis, they often entail resource-intensive cycles that can delay the translation of evidence into practice (Gale et al., 2013; Guest et al., 2012; Riley et al., 2013). RQA methods streamline or eliminate transcription; condense data management; and use structured templates, summary matrices, and/or direct audio processing to accelerate analysis (Brown et al., 2025). Such approaches are well-suited to real-world/implementation research, where timely feedback is critical to adapting interventions (Brown et al., 2025; Palinkas & Zatzick, 2019).
Large language models (LLMs) are increasingly used to augment, rather than replace, qualitative research, especially with thematic analysis (Brondani et al., 2024; Feuston & Brubaker, 2021; Hitch, 2024; Marshall & Naff, 2024; Morgan, 2023; Rodrigues Dos Anjos et al., 2024). The strengths of their use lie in processing large datasets quickly and helping surface themes that may otherwise be missed (Bano et al., 2024; Feuston & Brubaker, 2021; Hitch, 2024). Generative AI tools can accelerate both deductive (Xiao et al., 2023) and inductive (Perkins & Roe, 2024) coding, but most approaches still keep a human-in-the-loop to ensure analytic rigor (De Paoli, 2024; Perkins & Roe, 2024).
Newer LLMs can generate codes and synthesize themes at unprecedented speed, an advantage for implementation scientists who need rapid insights. However, the evidence base is still emerging. Benchmarks show wide variability in agreement with human-coded themes (38–85%) and highlight risks such as prompt sensitivity, hallucinated categories, biased outputs, and opaque decision-making (Castellanos et al., 2025; Chubb, 2023; Kondo et al., 2024; Morse et al., 2025; Sakaguchi et al., 2025; Wachinger et al., 2025). Without robust prompt engineering including iterative prompting and contextual scaffolding, LLMs can produce shallow or imprecise themes (Morse et al., 2025; Sakaguchi et al., 2025). Some studies omit quantitative agreement measures altogether or rely on custom metrics, limiting cross-study comparability (Brondani et al., 2024; Castellanos et al., 2025; Kondo et al., 2024; Sakaguchi et al., 2025; Wachinger et al., 2025). This indicates a need for tools to quantify agreement, allowing for true benchmark comparisons. Thus, there is a need for consistent benchmarking tools and deeper evaluation of when and how LLMs can support rigorous qualitative analysis in health informatics (Bergman et al., 2024). Together, these concerns point to the need for systematic evaluations of LLM performance, focusing on efficiency, thematic completeness, and ethical integrity in qualitative health informatics research.
To capture nurses’ insights into the recovery process for EAS patients, we conducted qualitative sessions designed to explore barriers and facilitators to optimal recovery. The rich data corpus yielded from these discussions served as a robust test-bed for evaluating various qualitative analysis approaches. This study systematically compared four distinct analytic workflows: a traditional manual rapid qualitative analysis and three innovative AI-assisted variants. We then analyzed the efficiency and thematic completeness of each approach.
2. Methods
2.1. Design, Setting, and Participants
To capture nurses’ insights into the recovery process for EAS patients, we conducted six 60-minute Zoom sessions (16 participants total) with registered nurses and/or nurse practitioners recruited by email from hospitals in California and Minnesota. All participants had experience caring for patients with abdominal surgery, with their scope of practice ranging from direct patient care to care coordination.
Semi-structured interview guides were used to explore barriers and facilitators to optimal EAS recovery both in-hospital and after discharge. Sessions were facilitated by an experienced moderator and recorded in Zoom. Institutional Review Board approval was obtained from both clinical sites and all participants provided verbal consent. Participants received a $100 incentive for participating in these Zoom interview sessions, and an additional $20 for completing the follow-up member-checking questionnaire.
2.2. Data Sources and Analytic Workflows
Each session produced two complementary data sources: 1. 2.
The goal of this work is to compare the results of four pathways for analyzing the qualitative data from these sessions (Figure 1 and Table 1). Both the summary notes and verbatim transcripts served as the raw material for the manual RQA as well as the three AI-assisted workflows described in detail below. Additionally, AI was utilized to merge the resulting four baseline codebooks into a single reference codebook, which served as the basis for assessing thematic cross-coverage across the different workflows. Comparison of manual and AI-assisted qualitative analysis workflows Characteristics of Analytic Workflows

2.3. Manual Rapid Qualitative Analysis (W1)
Three team members (including two nurses), all with experience in qualitative research and analysis, reviewed the six audio recordings by listening in full and capturing detailed notes. Each team member built an initial list of barriers and facilitators emerging from the sessions they reviewed. The team members then met to reconcile terminology and clarify concepts within their own reviews. Guided by that discussion, each team member reorganized the material from their sessions into preliminary themes and subthemes. Further discussion resolved remaining discrepancies and produced the final codebook of agreed-upon themes, subthemes, and definitions that covered all sessions.
2.4. ChatGPT-o3 Analysis of Summary Notes (W2)
A researcher uploaded all deidentified summary notes (described above) as attached files into the ChatGPT-o3 interface (March 2025 release) with the prompt below. For simplicity, we used the term ‘focus groups’ throughout the prompts: The attached documents contain raw notes from focus groups conducted with nurses who care for patients who have undergone emergency abdominal surgery. I want you to take on the role of a qualitative analysis expert, and conduct two tasks. We will be using this analysis to develop interventions to help these patients. The two tasks are as follows: 1. Organize the notes: Please merge and organize the notes. Format the notes for readability and output it as a new, structured file (.docx). 2. Codebook Creation: We intend to conduct a qualitative thematic analysis of the notes. Please analyze the notes to identify key themes and subthemes, ensuring that they capture the main topics discussed by the participants. Create a structured codebook that includes: a. A list of themes and subthemes b. Definitions for each theme and subtheme
We noticed that ChatGPT-o3 generated exactly the same number of subthemes within each theme, so we followed up with this prompt: I see you put 4 subthemes for each theme. Reanalyze the notes and consider whether this is the right number. It would be fine to have more subthemes in some categories than others.
ChatGPT-o3 then generated a revised structured codebook.
2.5. Cleaning and Pre-processing of Transcripts (W3 and W4)
Institutional policy required that raw participant data be processed only with a university-approved LLM (Microsoft Copilot GPT-4). Because the University’s version of Copilot could not accept file uploads and enforced an 8,000-character limit, we chunked the deidentified text into ∼8,000-character segments and cleaned each transcript by submitting each ∼8,000-character segment into Copilot with the following prompt: The text below contains raw transcripts from a focus group conducted with nurses who care for patients who have undergone emergency abdominal surgery. Please clean the transcripts by removing irrelevant content (e.g., timestamps, filler or nonsense words) while preserving the meaning and accuracy of the discussions. Format the cleaned transcript for readability. <followed by the segment of transcript>
2.6. LLM Analysis of Cleaned Transcripts (W3 and W4)
After cleaning the transcripts, we fed each fully cleaned transcript into Microsoft Copilot GPT-4 (for W3) and ChatGPT-o3 (for W4) using the following prompt: We intend to conduct a qualitative thematic analysis of the transcript. Please review all of the work we did and identify key themes and subthemes, ensuring that they capture the main topics discussed by the participants. Create a structured codebook that includes: A list of themes and subthemes; Definitions for each theme and subtheme <followed by the fully cleaned transcript>
We then entered the following prompt into both Copilot and ChatGPT-o3: Following are qualitative codebooks identified from each of 6 sessions with nurses caring for patients who had emergency abdominal surgery. Analyze these codebooks for overlap and create a single codebook of barriers to recovery that encompasses these themes and subthemes. <followed by the codebooks>
Copilot GPT-4 and ChatGPT-o3 each generated a single codebook.
2.7. Evaluation of the Codebooks
We employed two approaches to evaluate the codebooks: 1) checking their coverage against a synthesized codebook, and 2) gathering feedback from nurse participants.
2.7.1. Creation of Synthesized Codebook
Once we had codebooks for our four workflows, we entered the following prompt into ChatGPT-o3: I have 4 different codebooks created for these focus groups that I can provide to you. I would like you to analyze the alignment between them.
ChatGPT-o3 responded by asking for clarification on format, content, desired depth of comparison, output format, and any exclusions or special rules. Our responses specified: I will paste them as text. They do contain definitions. I want a high-level map of which major themes and subthemes overlap in concept... A single consolidated table (themes × codebooks) plus a narrative summary work is great. I do also want recommendations for harmonizing or merging the four codebooks... Include positive-outcome codes for now. I want closely related codes be merged.
ChatGPT-o3 generated the synthesized codebook.
2.7.2. Nurse Participant Feedback on the Codebooks
We invited the 16 nurse participants to provide feedback on the four codebooks, with data collected and managed using the secure, web-based software platform REDCap (Research Electronic Data Capture) hosted at the University of Minnesota (Harris et al., 2009). The participants rated how well each codebook reflected their perspective as a nurse using a Likert scale (Not at all, Slightly, Somewhat, Mostly, and Completely). They also provided open-ended responses on what each codebook got right and wrong, an overall ranking of the codebooks, and what appealed to them about their top choice. Participants received a $20 incentive for completing the follow-up survey.
3. Results
Manual RQA (W1) Codebook

ChatGPT o3 Analysis of Notes (W2) Codebook

Copilot Analysis of 6 Sets of Themes/Subthemes (W3) Codebook

ChatGPT-o3 Analysis of 6 Sets of Themes/Subthemes (W4) Codebook

Synthesized Codebook

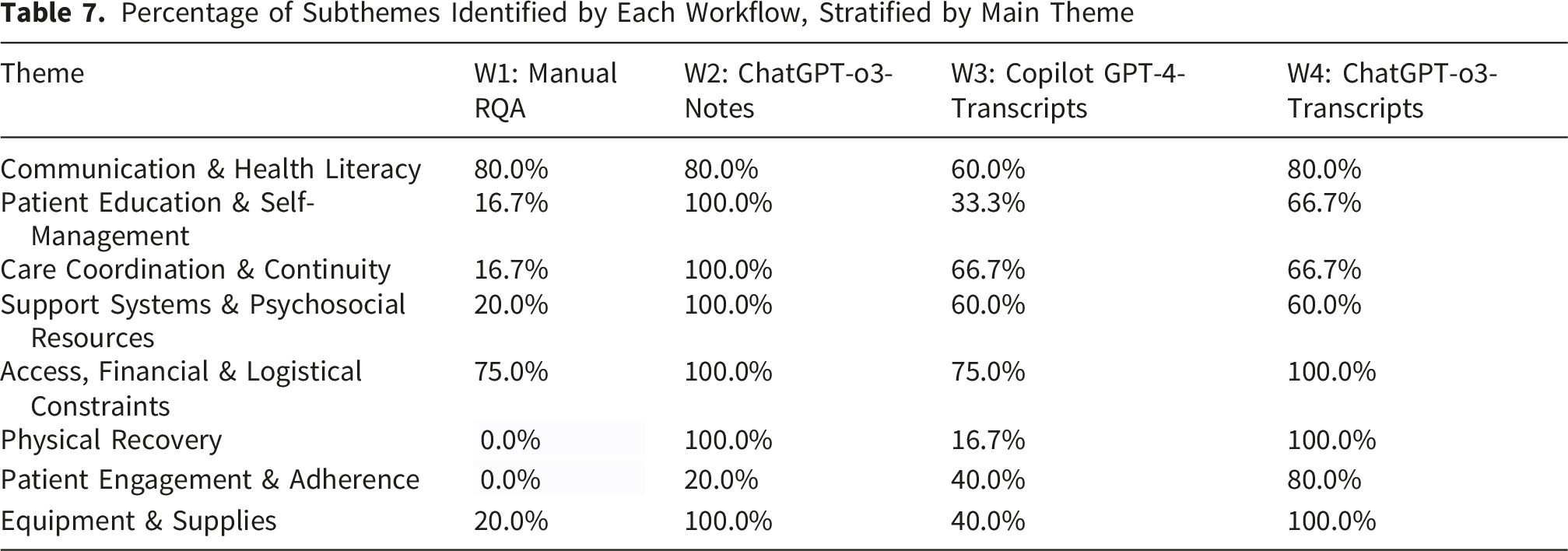
3.1. Thematic Coverage of Codebooks
Percentage of Subthemes Identified by Each Workflow, Stratified by Main Theme
Detailed Thematic Coverage of Codebooks

3.2. Nurse Participant Feedback on the Codebooks
Six of the 16 participants (37.5%) responded to the REDCap survey (Harris et al., 2009). Figure 2 presents participants’ rankings of the codebooks, with ChatGPT-o3-Notes (W2) being rated as the best match, followed by ChatGPT-o3 transcripts (W4), Copilot transcripts (W3), and Manual RQA (W1). Participants’ qualitative feedback on their top-ranked choices consistently highlighted the comprehensive and actionable nature of the AI-generated codebooks. Comments included: “Includes the steps that would improve our weaknesses,” “...addressing all potential barriers and what can be done to alleviate those barriers,” “The teaching and getting the patient prepared is what we strive for… ensuring that caregivers and family [are] available to learn in case the patient is unable,” “Better highlights communication barriers [and] offers more concrete details on barriers,” “Very thorough, accurately depicts [the] full picture of patient interventions for surgery and recovery,” and “It feels like it fits my role the most.” Nurse rankings of codebooks
4. Discussion
This study rigorously compared the efficiency and thematic completeness of four distinct qualitative analysis workflows applied to a common corpus of 16 nurse interviews and mini-focus groups: a manual rapid qualitative analysis workflow and three LLM–assisted workflows. Our findings demonstrate substantial time savings with LLM integration while achieving high thematic coverage, corroborated by participant feedback.
Specifically, manual RQA (W1) required approximately 30 person-hours. In contrast, the LLM-assisted workflows significantly reduced labor: ChatGPT-o3 on researcher notes (W2) required ∼8 person-hours, and both Copilot on full transcripts (W3) and ChatGPT-o3 on full transcripts (W4) each took ∼4 hours. The higher time for transcript-based LLM analysis was primarily due to institutional technical limitations (file-upload and prompt-length limits) rather than methodological constraints. In an unrestricted environment, these workflows would likely take less than 30 minutes, highlighting an infrastructural rather than a methodological bottleneck.
Beyond efficiency, the workflows produced codebooks of varied granularity and completeness. While W1 resulted in 3 themes and 10 subthemes, W2 yielded 10 themes and 47 subthemes. Workflows W3 and W4 provided an intermediate level of detail. Crucially, the two transcript-based LLM workflows (W3 and W4) captured nearly all concepts present in our 8-theme, 42-subtheme harmonized framework, yet required approximately 85% less time than manual RQA (W1), even with the current institutional inefficiencies. This demonstrates that LLMs can not only accelerate analysis but also achieve comprehensive thematic coverage when prompted to generate codes. Nurse participant preferences (W2, W4, W3, W1) echoed the order shown in the thematic completeness analysis, with all LLM workflows preferred by nurse participants to the manual RQA.
The divergence in thematic completeness between the models may be attributable to specific architectural differences. ChatGPT-o3 utilizes advanced ‘chain-of-thought’ reasoning and operates with a significantly larger context window compared to the GPT-4 architecture powering the Copilot workflow. These capabilities allow for more robust data synthesis, enabling the model to retain and connect disparate narrative threads across lengthy transcripts, a critical advantage when analyzing the dense, unstructured accounts typical of qualitative interviews.
These results echo and extend a growing empirical literature on LLM-assisted qualitative analysis. One study demonstrated that ChatGPT generated complete inductive codebooks for health-services interviews in under 15 minutes, achieving high macro-level concordance with human gold standards (Bijker et al., 2024). Another reported a 70% reduction in analyst time and strong inter-rater agreement (Cohen’s κ between 0.72 and 0.95) when GPT-4 drafted codes (Liu et al., 2025). Our work corroborates these findings within a nursing context, showing that when LLMs are tasked with generating, not just assigning, codes, near-complete thematic coverage is achievable.
However, none of the workflows were without limitations. LLMs occasionally exhibited “hallucinations,” such as generating duplicate categories or imposing a fixed number of subthemes (e.g., four under every parent theme) even when the content did not warrant it. For instance, Copilot GPT-4 notably missed several details related to “Equipment and Supplies” that ChatGPT-o3 captured. These observations reinforce prior cautions about LLM “creativity” and underscore the critical need for robust human oversight and quality assurance at every stage of LLM-assisted qualitative analysis (Jiang et al., 2024).
Participant feedback on the codebooks provided further insights into what constitutes a “good” codebook from an end-user perspective. Of the 16 nurse participants invited, 6 (37.5%) completed the evaluation survey. While this sample size limits statistical generalizability and introduces potential response bias (where respondents may be those most engaged with the topic), the qualitative feedback provided offers critical preliminary validity checks from a content-expert perspective. Key takeaways from nurse participant preferences for the top-ranked codebooks (primarily LLM-generated) included:
These participant preferences provide a framework for systematically characterizing the limitations of the less-performing AI workflows. By inverting the attributes most valued by the nurses, specifically thoroughness, action-orientation, and role fit, we can categorize the primary limitations of the LLM outputs as follows: 1. 2. 3.
Regarding interpretive depth, we acknowledge that current LLMs prioritize breadth and speed (semantic analysis) over the nuanced, latent interpretation that sustained human immersion in the data yields. However, when the goal is rapid implementation rather than theory generation, this trade-off is acceptable. The AI successfully identifies the what (barriers) even if it occasionally misses the deeper why (latent meaning), satisfying the pragmatic requirements of the study.
Based on our findings, particularly the balance of efficiency and thematic completeness demonstrated by the LLM-assisted workflows and the positive participant feedback, we recommend a human-in-the-loop protocol for projects requiring rapid yet thorough qualitative insights, such as those in early design cycles or iterative implementation science: 1. 2. 3. 4. 5.
This proposed protocol preserves the crucial cognitive benefits of team members’ immersion in the data (taking notes) while strategically outsourcing the most time-consuming mechanical steps to LLMs. These findings are particularly beneficial for implementation scientists who often require faster data translation within resource-constrained environments.
However, ethical considerations in using LLMs for qualitative analysis remain paramount. Researchers must prioritize alignment with institutional policies regarding the protection of participant data. Awareness of these privacy protections is crucial, particularly for compliance with privacy laws and/or policies. While these workflows are recommended for rapid data translation with large datasets, especially within implementation science, LLM outputs must always be cross-referenced against the original data to maintain analytic rigor and mitigate the risk of hallucinations. The integration of LLMs into qualitative workflows necessitates a re-evaluation of data governance and interpretive responsibility. While LLMs can efficiently synthesize patterns, they lack the agency to assume accountability for clinical insights. We posit that the ‘Human-in-the-Loop’ safeguards utilized in this study are not merely quality assurance mechanisms but fundamental ethical requirements. When delegating thematic synthesis to AI, the final accountability for the validity of findings must remain solely with the human research team. Researchers must actively audit AI outputs to ensure that efficiency gains do not come at the cost of erasing minority perspectives or propagating hallucinated clinical associations that could impact patient safety.
This workflow necessitates a re-conceptualization of reflexivity. In AI-assisted qualitative research, the researcher’s role shifts from primary analyst to expert auditor. Bias does not disappear; rather, it shifts upstream to the prompt engineering phase and downstream to the validation phase. Reflexivity therefore requires the researcher to critically examine not just their interpretation of the data, but how their prompts may have constrained or directed the model’s outputs.
Additionally, we acknowledge that the specific models evaluated (ChatGPT-o3 and GPT-4) are already becoming obsolete relative to emerging architectures. However, the methodological implication holds: as models evolve to generate richer outputs, the risk of plausible-sounding hallucinations may increase. Future qualitative methodology must therefore shift focus from mere coding efficiency to rigorous interpretive auditing, ensuring that as AI tools become more capable, human oversight evolves to detect increasingly sophisticated errors.
Finally, it is important to acknowledge that numerous forms of qualitative analysis and theoretical approaches are better suited for human-only analysis, particularly when the researcher’s embodied role and deep contextual understanding are central to the inquiry.
5. Conclusion
This study provides compelling evidence that integrating LLMs into qualitative data analysis significantly reduces labor while achieving comprehensive thematic coverage of nurse-identified recovery barriers. Specifically, LLM assistance captured virtually all concepts present in a synthesized codebook, far surpassing the thematic breadth of manual RQA in a fraction of the time. Yet, our findings also underscore that human reconciliation remains essential to validate LLM outputs, correct duplications and omissions, and ultimately uphold qualitative rigor. We propose a pragmatic hybrid approach, involving dual LLM analyses of human notes and transcripts, a human review session and, ideally, member-checking, as an optimal strategy. Beyond the specific context of EAS, this study highlights the transferability of AI-assisted RQA to broader qualitative inquiry. The structural components of our hybrid workflow, including the defined prompt architecture, the use of summary notes for velocity, and the ‘human-in-the-loop’ validation protocols are domain-independent and readily adaptable to other applied fields such as public health, education, or organizational science. However, the interpretive accuracy remains domain-dependent. As evidenced by the nuanced differences in model performance, the effectiveness of the human check relies on content expertise. Researchers applying this method elsewhere must therefore ensure that the human auditor possesses deep subject-matter knowledge to detect the specific, plausible-sounding hallucinations that generic models may generate within specialized domains. This protocol offers a powerful harmonization of analytical speed, ethical LLM utilization, and the generation of translatable insights crucial for advancing implementation science.
Footnotes
ORCID iDs
Ethical Considerations
This study was approved by the University of Minnesota and University of California, San Francisco Institutional Review Boards.
Author Contributions
Conception and Design (JM, LW, GM), Data Collection (JM, AT), Data Analysis (JM, CM, ST, AF), Drafting Manuscript (JM, CM, ST, AF), Critical Revision of the Manuscript (JM, CM, ST, AF, AT, EW, GM)
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by an award from the Agency for Healthcare Quality and Research (AHRQ) R18 HS029616 and by the University of Minnesota Center for Learning Health System Sciences (CLHSS), a collaboration between the Medical School and School of Public Health. The content is solely the responsibility of the authors and does not represent the official views of the AHRQ or CLHSS.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Deidentified study data will be made available upon reasonable request.