
Abstract
In response to the challenges posed by the COVID-19 pandemic on traditional Photovoice studies, this article explores the potential of digital technologies to transform the methodology rather than merely adapt it. We introduce velfies (self-recorded video performances), a digital evolution that enhances participant agency by allowing them to shape the research narrative through multimodal and performative elements, such as voice, gesture, and movement. This approach shifts participants from being mere observers to active performers, enriching the research process with diverse, multimodal expressions. Our study with university students, focused on interactions with innovative pedagogies, demonstrates how velfies can deepen engagement and provide richer, more nuanced data. We argue that this performative, digital approach expands Photovoice methodology by bridging the gap between participant experience and researcher interpretation, capturing the complexities of lived educational experiences with greater depth and nuance.
Introduction
Visual methods have long played a central role in participatory research, offering ways to engage deeply with participants’ experiences and perspectives. Photovoice, introduced by Wang and Burris (1997), remains one of the most influential participatory action research methods, enabling participants to document and reflect on their environments through photography (Bandauko & Arku, 2023; Harley, 2012; Rania et al., 2019; Yang, 2023). Since its inception, Photovoice has been widely applied across disciplines including education, public health, and anthropology, illustrating its adaptability (Ciolan & Manasia, 2024; Guell & Ogilvie, 2015; Oliffe & Bottorff, 2007; Power et al., 2014; Rania et al., 2021), helping marginalized communities or underacknowledged participants voice their concerns and advocate for change. However, despite its participatory ethos, critiques highlight how Photovoice remains constrained by researcher-driven analysis, as researchers often lead the thematic coding of images and narratives, creating a methodological gap between participant-generated data and researcher-led meaning-making (Capous-Desyllas & Bromfield, 2018; Chen, 2023; Ng et al., 2024).
This gap has prompted calls for Photovoice to become more responsive, inclusive, and truly participatory (Wang & Hannes, 2020). One response to these critiques has been the expansion of Photovoice into digital formats, aligning with broader methodological trends toward multimodal (Kress, 2010), performative, and technology-mediated qualitative research (Borish et al., 2021; Li & Ho, 2019; Roy et al., 2021).
To address these limitations, the paper introduces velfies—video selfies (Knoblauch, 2004; Sterling-Fox et al., 2020) —as an evolution of Photovoice, providing a more dynamic and participatory form of audiovisual expression. Velfies are a form of native video data— that is self-recorded videos created by participants in everyday settings without direct researcher intervention, similar to video diaries or personal clips (Knoblauch et al., 2014, p. 437). Rather than being researcher-directed, these videos reflect participants’ own framing, intentions, and self-presentation, offering a more immersive and agentic form of visual storytelling. Velfies align with multimodal approaches (Kress, 2010), emphasizing embodied meaning-making, sequential unfolding of experiences, and digital circulation (Craig et al., 2021; Fazeli et al., 2023; Knoblauch et al., 2014; Li & Ho, 2019).
Building on multi-method autobiographical approaches (Bagnoli, 2004), the funds of identity theory (Esteban-Guitart, 2023; Esteban-Guitart & Moll, 2014), and multimodal analysis (Jewitt, 2017), we conceptualize velfies as identity artifacts that mediate self-representation and meaning-making. These digital self-expressions function as tools through which individuals negotiate their identities, integrating elements of personal experience, cultural narratives, and social interaction.
Velfies challenge the analytical divide between participant experience and researcher interpretation (Esteban-Guitart, 2023; Fazeli et al., 2023) by positioning participants as both producers and subjects, allowing for self-curated, first-person narratives that are inherently reflexive and participatory. In comparison with traditional Photovoice, which relies on static, text-based interpretations (Börner et al., 2024), velfies embrace diverse communicative modes that integrate gesture, voice, and embodiment. This shift enables a richer, more dynamic mode of storytelling that captures the fluidity and complexity of lived experience beyond what text alone can convey (Barad, 2006; Fazeli et al., 2023; McLeod, 2014).
The adoption of video-based methodologies has fundamentally reshaped qualitative research, allowing for the integration of movement, voice, spatial context, and sequentiality (Fazeli et al., 2023; Knoblauch & Schnettler, 2012; McNaughton, 2009; Roy et al., 2021; Schmidt & Wiesse, 2019; West et al., 2022). Fazeli et al. (2023) highlight digital storytelling as a powerful tool for individuals to articulate their realities, struggles, and social positions. It allows for the construction of rich, first-person narratives that blend recorded voice, still and moving images, and music, offering an engaging means of conveying lived experiences. Unlike static images, video data enable researchers to analyze the evolving dynamics of interaction, self-presentation, and environmental context (Fitzgerald et al., 2013). Velfies offer a richer approach to self-expression, expanding digital storytelling (Borish et al., 2021; Craig et al., 2021; Roy et al., 2021). Building on insights shared by Craig et al. (2021), video data provides deeper perspectives into participants’ emotional states and reactions, surpassing transcript-based analysis, which often overlooks subtleties such as tone, hesitation, and facial expressions.
This methodological evolution is deeply informed by posthumanist perspectives, which challenge anthropocentric and researcher-centered approaches to knowledge production (Barad, 2006; Braidotti, 2019). Posthumanism conceptualizes meaning-making as an entanglement of human, technological, and environmental agents, challenging the notion of an autonomous, self-contained subject (McLeod, 2014). From this lens, velfies are participant-driven forms of self-expression and co-produced assemblages (Deleuze et al., 2007) in which bodies, digital interfaces, and algorithmic infrastructures intra-act to shape narrative performances (Kumpulainen et al., 2023; Renold & Ringrose, 2017).
Velfies depart from traditional video diaries and interview-based formats in three distinct ways. First, they are inherently self-performed, meaning that participants actively curate and shape their own representations or first-order constructs (Bagnoli, 2009; Esteban-Guitart, 2023; Heinrich et al., 2024; Knoblauch et al., 2014), rather than responding to structured interview prompts. Second, they foreground the performative dimensions of experience, integrating gesture, vocal tone, movement, and visual framing as part of meaning-making (Craig et al., 2021; Jewitt, 2017), displaying an ‘orchestration’ (Knoblauch et al., 2006) of communicative modalities and objects in space and time. Third, they offer a multimodal research and identity artifact that combines spontaneity, reflexivity, and self-expression within a single audiovisual narrative (Bagnoli, 2009; Esteban-Guitart, 2023; Subero et al., 2018).
Methodologically, the paper builds upon interpretive video analysis frameworks, particularly Knoblauch et al. (2014), Fazeli et al. (2023), and Wang and Hannes (2020) which emphasize the analysis of visual-verbal interactions, embodied meaning-making, and sequential unfolding of experiences. Interpretive video analysis moves beyond text-based coding by examining the multimodal aspects of video as a research artifact (Borish et al., 2021). Fitzgerald et al. (2013) emphasize that video data should be analyzed in its own right rather than reduced to textual documentation.
Given this methodological context, the paper revisits the broader questions posed by Börner et al. (2024): To what extent do current Photovoice practices enable true self-expression for participants? How can we reconceptualize key concerns of Photovoice—such as co-production, ownership, and power dynamics—by integrating multimodal, self-expressive practices, such as velfies, into the research process? And ultimately, does this shift towards self-expression represent a departure from Photovoice as traditionally understood? If so, what does this transformation entail?
To address these questions, insights are drawn from the CAPTIVATE project (Ciolan & Manasia, 2023), which examined how university students engage with innovative pedagogies in higher education (Ciolan & Manasia, 2024). Specifically, this article: (1) describes the CAPTIVATE Photovoice project that led to the use of velfies to complement or replace photographs; (2) analyzes velfies as native videos, discussing the density and sequentiality of social interactions and the conditions of production; and (3) explores whether this shift towards performative self-expression represents an evolution—or even a departure—from traditional Photovoice methodologies.
The CAPTIVATE Project
The CAPTIVATE Photovoice study explored Science and Technology (S&T) students’ perspectives on innovative pedagogies in higher education, aiming to inform learning design. This research responded to increasing pressures to align pedagogy with evolving societal and technological demands (Ciolan & Manasia, 2024). Grounded in student-centricity (Bajada et al., 2019; Edeh et al., 2022; Kamp, 2019), the project created participatory spaces for students to document and categorize their learning experiences into clusters of innovative pedagogies (Istance & Paniagua, 2019; Jewitt, 2017; Kukulska-Hulme et al., 2023).
Methodologically, the study used Photovoice to capture students’ lived experiences, drawing on empowerment education, documentary photography, and autobiographical approaches (Bagnoli, 2004, 2009; Ciolan & Manasia, 2017). The funds of identity theory (Esteban-Guitart, 2023; Esteban-Guitart & Moll, 2014) further framed the research, emphasizing the complexity of knowledge production through personal narratives.
Designed at the onset of the COVID-19 pandemic, the study was conducted digitally, incorporating images and narratives. As teachers, we questioned whether students could effectively capture learning experiences through photographs. As researchers, we acknowledged that our backgrounds in educational policy and cognitive sciences shaped our understanding of pedagogical innovation. Our approach was informed by Jewitt’s (Esteban-Guitart, 2023; Jewitt, 2017) perspective, which emphasizes that human learning and behavior are inherently multimodal—encompassing visual, actional, and linguistic dimensions. This understanding shaped our methodological choices, ensuring that the research could effectively analyze diverse modes of expression, from speech to images, fostering an exploration of student experiences.
Conducting the study in a fully digital environment also required adapting reflexive methods. We implemented a ‘3D’ (dialogic digital discussions) strategy, combining online discussions and written reflections to track emerging insights, address biases, and integrate participant feedback iteratively. These iterative sessions allowed us to track shifts in understanding, address potential biases, and adapt our approach based on participant feedback.
After initial scoping meetings in March 2020, recruitment began using purposeful sampling (Emmel, 2013; Patton, 2015). The research team promoted the study through university social media and online advertisements, inviting interested students to learn more. A total of 127 students received project details and a digital consent form via Survey Alchemer™.
Of these, 63 students formally consented and joined initial group discussions. By the project’s active phase, 43 participants (33% of the initial pool) remained engaged. The final cohort was diverse, with participants aged 19 to 52 years (
Before documenting their learning experiences, participants attended two online synchronous training sessions. The first session introduced Photovoice methodology, project objectives, and ethical considerations, with particular focus on privacy, consent, and responsible image use in educational contexts. The second session provided hands-on technical training, ensuring students were comfortable with the digital tools for submission and analysis. Following Wang and Hannes’ (2020) guidelines, these sessions were interactive, allowing participants to engage with the research process effectively.
Students then embarked on a three-semester documentation period (March 2021–June 2022), capturing their experiences during fluctuating online and hybrid learning phases. Across the study, participants submitted 231 photographs, with individual contributions ranging from 1 to 11 images (
The study adhered to ethical standards and received approval from the relevant ethics committee (Ref. No. 16027/09/12/2020). To protect anonymity, all collected data were anonymized for reporting and publication. Additionally, data were made openly available (Ciolan & Manasia, 2023).
By researching with students (Börner et al., 2024) and engaging them as co-creators of the knowledge about pedagogical innovation, we intended to develop a better understanding of students’s views on their learning experiences. Rather than defining innovation in advance, we invited students to articulate their own perspectives. To facilitate this process, we shared images that represented pedagogical innovation from our viewpoints—not as data, but as prompts for discussion. This encouraged participants to critically engage with the concept and develop their own narratives, ensuring that the study reflected a diverse range of student experiences (Chen, 2023; Ferlatte et al., 2022; Oliffe et al., 2023; Warfield, 2017). To encourage dynamic exchanges between the researchers and participants, a virtual community integrating platforms such as WhatsApp and Microsoft Teams (see Figure 1) was established. The CAPTIVATE’s Community in Microsoft Teams.
To maintain engagement in this long-term study, researchers conducted regular check-ins, providing encouragement and discussing emerging themes. Experience Sampling Methodology (ESM) (Zirkel et al., 2015) was used, prompting participants to document their learning experiences through both random and event-based sampling (Bolger & Laurenceau, 2013). Morning reminders encouraged daily reflections, while event-based prompts allowed students to capture particularly innovative moments.
A digital Graffiti Wall on Miro (Figure 2) provided a shared space for participants to upload images and narratives, fostering collaboration and collective reflection. CAPTIVATE Wall in Miro. Note
During the data collection phase, the project transitioned from a participatory approach to a more expressive one, a shift initiated by participant feedback. Valentina, a 4-year student, highlighting this evolution, noted in her video documenting pedagogical innovation in higher education, “I know you said to take pictures of the learning experiences we liked, but I felt like a video would do more. It’s like I am really part of that experience”.
In response to Valentina’s insights, we invited all participants to consider using videos in addition to photographs. This suggestion resonated with many, who found videos more natural and representative of their active involvement in the educational experiences. However, participants who preferred not to use videos continued with photos and narratives freely, ensuring a flexible and participant-driven approach. A total of 17 participants recorded velfies (
Data analysis of photographs and narratives was conducted through an adapted protocol for interpretative phenomenological analysis applied to focus group discussions (Love et al., 2020). An extensive discussion of the research process and results can be read in Ciolan and Manasia (2024). Unlike the participatory and interpretative phenomenological analysis used for photos, our video analysis was non-participative but retained an interpretative focus. Following interpretive video analysis principles (Knoblauch et al., 2014), we viewed videos as an active construction of data, where researchers analyze the density and sequential unfolding of interactions and their embedded meaning rather than simply categorizing observed behaviors. While participant involvement was central to the photo analysis, video analysis was conducted collaboratively by the researchers. Specifically, we examined the social dynamics, conditions of production, and communicative affordances of the videos (Borish et al., 2021; Knoblauch et al., 2014).
The insights in this article emerged from post-study researcher debriefs and dialogic exchanges, where research questions were examined in relation to study procedures, data collection, and participant empowerment through velfies. These analytic processes evolved through researcher discussions and the writing of this article, refining our understanding of two interconnected perspectives: (1) velfies as an expressive and multimodal extension of Photovoice, and (2) the comparison between echo and performative velfies, analyzed as native videos through sequentiality, interaction, and meaning-making.
Analytical Perspectives
Velfies were not initially part of the CAPTIVATE study but emerged organically as participants sought alternative ways to express their experiences. Their introduction required a distinct interpretative approach, as they differed from static images and narratives. Rather than presenting research findings, this section explores velfies’ methodological role as native videos—both as research tools and identity artifacts—enhancing Photovoice as an expressive and participatory methodology.
Velfies as an Expressive and Multimodal Extension of Photovoice
The CAPTIVATE project examined pedagogical innovation as a lived experience in an S&T university, emphasizing participation within fluid epistemologies. To accommodate participants’ diverse digital habits (Esteban-Guitart, 2023; Jewitt, 2017), we adopted an omnichannel approach (Casais, 2023), integrating digital tools at every stage—from recruitment to data analysis and dissemination. This aligns with Börner et al.'s (2024) argument that digital research environments require continuous adaptation.
To foster engagement and trust, we maintained open communication, shared materials on familiar platforms, and encouraged shared decision-making (Bindels et al., 2014; Pope, 2020). As in other digital Photovoice studies (Ferlatte et al., 2022; Oliffe et al., 2023; Rania et al., 2021), social media and digital channels broadened accessibility, attracting over 100 potential participants. While many opted out, self-selection resulted in low attrition and a highly engaged cohort. However, digital recruitment also introduced biases, potentially excluding students with limited access to online platforms (Black & Faustin, 2022; Börner et al., 2024; Chen, 2023; Oliffe et al., 2023).
To support participation, we implemented multimodal communication via Microsoft Teams, WhatsApp, Miro, and Survey Alchemer™, providing multiple entry points for engagement. Although Microsoft Teams was the university’s official platform, some participants found it difficult to navigate, especially on mobile devices: You know, I will be more present in WhatsApp. It is difficult to find the classrooms and messages in Teams when connecting from the mobile phone.
As a result, WhatsApp facilitated more seamless interactions, fostering a sense of ease and familiarity (Börner et al., 2024; Fisher & Monahan, 2023; Hoover & Morrow, 2015). This preference was reinforced by Mădălina, a 23-year-old student, who stated during training: I am totally biased ! I love WhatsApp because I have my emoticons and gifs. I cannot write without them!
As participants engaged with digital tools, they increasingly preferred video-based storytelling over static images, prompting a methodological shift toward velfies (see Figure 3). Velfies offered a more immersive and performative means of documenting learning experiences (Sterling-Fox et al., 2020), aligning with broader trends in digital and performative research (Borish et al., 2021; Heinrich et al., 2024; Jewitt, 2017). This transition reinforced participant agency, allowing them to shape the research process itself (Börner et al., 2024). Screenshots From Velfies Illustrating Participant Engagement and Social Dynamics in a Co-created Research Artifact Contextual description: The velfie explores community pedagogies, emphasizing how students first formed close peer connections, which in turn fostered a more engaged and collaborative learning environment. Excerpt A: ‘At first, we were just classmates working on the same project. But as we collaborated, we built something more—our own community. Learning became easier when we felt supported, and sharing ideas felt natural, not forced’. Excerpt B: ‘We are learning and laughing together’. The text overlay translates “Thank you for watching!”.
Traditional Photovoice studies primarily generate images of objects, contexts, or other individuals (Kennedy et al., 2016; Yi & Zebrack, 2010). In contrast, velfies foregrounded self-representation and social engagement. Of the 32 submitted velfies, 24 featured the participant alongside peers who, while not formally enrolled in the study, consented to be filmed. This shift altered the social modality of participation, transforming velfies into multiply stories (Hong, 2021). Theodora, a second-year Master’s student, captured this collective aspect:
I am so glad that we can do this together. We are all roommates, and it felt strange to participate in this without them.
CAPTIVATE embraced fluid epistemologies, recognizing knowledge production as dynamic and co-constructed rather than researcher-imposed (Barad, 2006; Rubini & Viteritti, 2023). This adaptability allowed methodological shifts to emerge organically, reflecting participants’ preferred modes of expression (Esteban-Guitart, 2023). The transition to velfies exemplified this, as students actively curated their representations, blending visual, verbal, and performative elements (Fazeli et al., 2023; Li & Ho, 2019).
Beyond enhancing self-expression (Bagnoli, 2009; Esteban-Guitart, 2023; Jewitt, 2017), velfies simplified participation, making it easier to share experiences. This accessibility was particularly relevant for participants less inclined toward writing. Mihai, a Master’s student, expressed this sentiment during a focus group: ‘I don’t like writing. I like taking photos, but writing is not like me. Videos were just perfect for not doing it’, said Mihai, a Master’s student.
Participants felt comfortable sharing both reflections and challenges. Mirela, a second-year student, noted: “[…] It feels good to share with someone the fact that I really feel exhausted. It’s not like I am doing something exceptional, but it’s hard. I focus on projects, homework, classes, and nothing else. I hope my future life will be nothing like this”.
Similarly, Radu, reflected on the impact of velfies in articulating emotions: “I wasn’t sure what to say at first, but when I started recording, it all just came out. I didn’t realize how much I needed to say until I saw myself speaking”.
Diana highlighted the advantage of video over static images: “I could have just taken a picture of my desk, but that wouldn’t show how I actually feel. In the video, you can see my tired face, you can hear my voice—it’s different. It’s more real”.
These quotes affirm the co-participatory approach, highlighting how velfies amplified participants’ voices and fostered trust through self-disclosure and embodied communication. This aligns with Ottoni et al. (2023) and Black and Faustin (2022), who found that digitally mediated environments enhance participant-researcher engagement and rapport.
Real-time interactions on WhatsApp and Teams further strengthened these connections, creating a togethering environment (Revsbæk & Beavan, 2024; Rubini & Viteritti, 2023) that facilitated dialogue and knowledge sharing. As shown in WhatsApp exchanges (Figure 4), participants used informal language and emotive responses—such as heart emojis and hugging icons—reducing hierarchical barriers and reinforcing relational closeness. This direct, unfiltered communication encouraged greater openness and engagement, making participants feel more comfortable expressing their thoughts. Whatsapp Exchange Illustrating Informal Rapport and Affective Communication.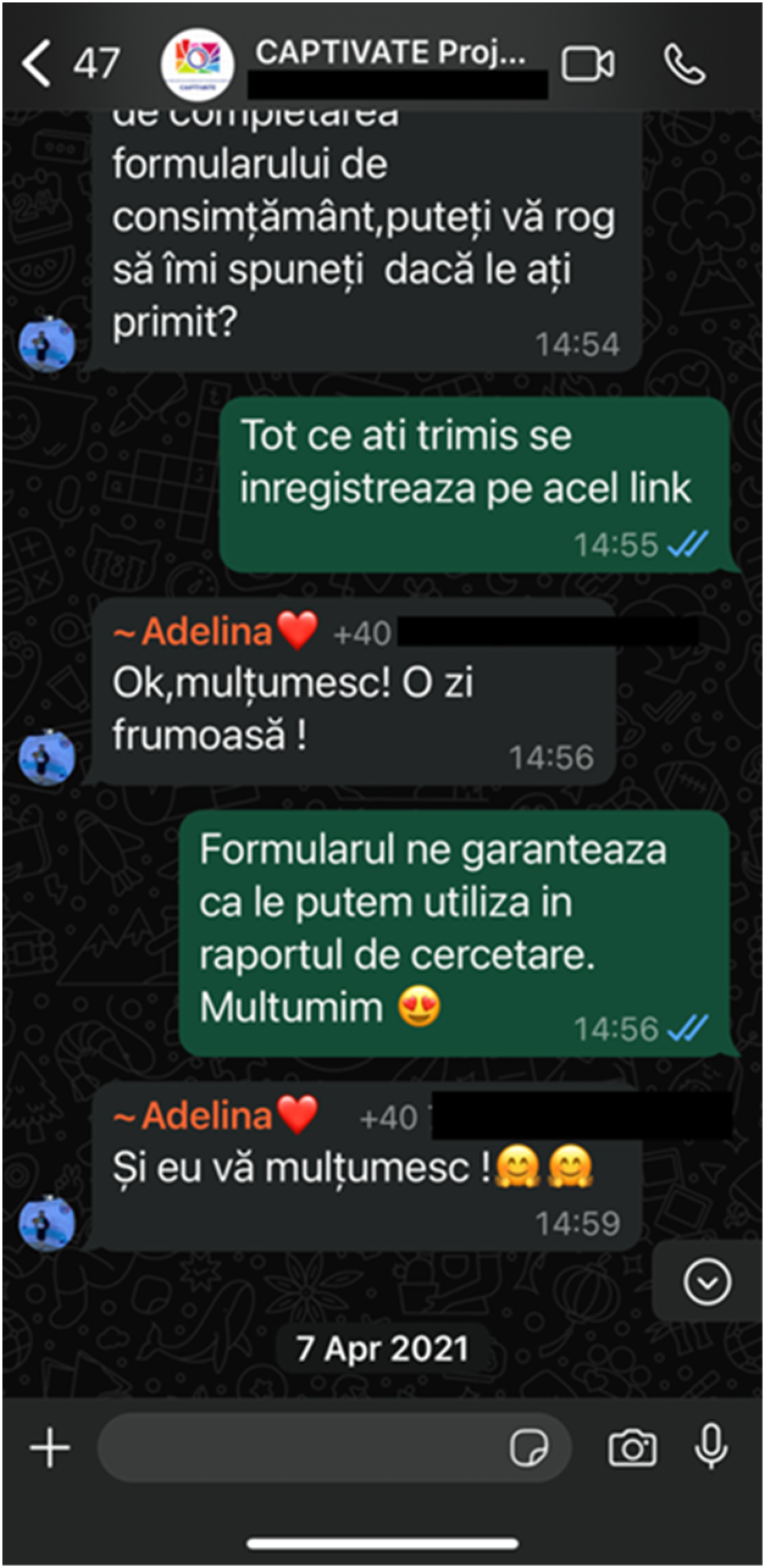
Raluca emphasized this trust-building aspect,
1
stating: ‘I felt like we weren’t just participants, but part of a conversation where our opinions mattered. The messages, the emojis, the way we talked—it all made it feel natural and real.’
Beyond text-based exchanges, velfies fostered trust by allowing participants to share reflections on their own terms. The ability to record, review, and edit before sharing gave them control over their narratives, reducing pressure and encouraging authenticity.
Figure 5 illustrates this process, showing a participant directly addressing the camera with a steady frame, using personal narration to articulate a transformative learning journey. This moment of self-representation highlights how velfies function as identity artifacts, shaping both personal reflection and self-expression. A Participant Engaging in A Self-Reflective Velfie, Using Direct-to-Camera Framing to Convey Personal Insights and Emotions. Contextual description: This velfie explores the impact of visible teachers—those who, rather than adhering to a specific pedagogical approach, engage deeply with students through their passion and presence. The participant reflects on how such a teacher played a crucial role in their educational journey, emphasizing that engagement and encouragement were more transformative than any particular method. The narrative evolves into a personal testimony, underscoring the lasting influence of meaningful teacher-student connections on educational opportunities. Excerpt: ‘Today, I am standing in front of the camera and I can speak with determination and hope. Education has been the key that opened doors to a better future for me. I know that every child deserves this chance, and I will continue to fight for it’.
Building on this, Figure 6 illustrates how collaborative velfies fostered trust among participants. Filming with peers eased self-consciousness, making expression more natural and engaging. As one participant reflected, ‘It’s not just about getting things done—it’s about sharing ideas, supporting each other, and making the process enjoyable.’ This shared storytelling strengthened teamwork and deepened connections, reinforcing the social dimension of learning. Collaborative Velfie Fostering Teamwork and Shared Storytelling. Contextual description: The velfie discusses community pedagogies with a focus on student-led learning. The participants explain how their group developed an inner community by teaching and supporting one another. They reflect on how explaining even the simplest concepts to peers reinforced their understanding and created a more engaging and effective learning process. This approach was introduced by a teacher who encouraged them to apply peer teaching as a learning strategy. Excerpt Frame A: ‘What we love about this course is that we work in teams. The project is challenging, but having a Friem (a team built on friendship) makes all the difference’. Excerpt Frame B: /It's not just about getting things done—it’s about sharing ideas, supporting each other, and making the process enjoyable. In this Friem, we learn, create, and grow together’.
The CAPTIVATE project frames velfies as native videos (Knoblauch et al., 2014) and identity artifacts (Esteban-Guitart, 2023), emphasizing their multimodal, performative nature beyond traditional Photovoice methods. This self-recorded format enhances agency, as participants control how they present their experiences. Figure 7 illustrates this dynamic, showing how participants curated their velfies—not only framing personal reflections (Frame A) but also crafting messages for a wider audience (Frame B), reinforcing their role as active storytellers. Frames From a Velfie Illustrating Self-Representation and Narrative Control. Contextual description: Filmed in a rural setting, this velfie captures the participant’s reflections on a service-learning project. She expresses a sense of reward and impact, emphasizing how her involvement made a difference in a local secondary school. Excerpt A: ‘My story about how I got involved in service-learning can be your story too’. Excerpt B: Support education! Together, we can make a difference.
This agency redefined traditional power dynamics in participatory research (Ng et al., 2024). Velfies gave participants control over their narratives, allowing them to decide what to share, omit, and emphasize—asserting ownership over their self-representation. This aligns with Christensen (2019), who advocate for shared data ownership in participatory methods.
Velfies also shed a new light on the processes of co-production and performativity (Oliffe et al., 2023). Some participants staged their velfies, incorporating gestures, movement, and environmental elements to enhance engagement. Others filmed collaboratively, reinforcing a sense of togetherness.
As Maria, an undergraduate student, described: We recorded this together because we all felt the same. It was weird to talk alone, but with my friends, it felt like we were telling our story.
The shared authorship extended to how participants framed their velfies as productions, explicitly crediting themselves as creators (see Figure 8). By adding production titles, they reinforced their role as storytellers, transforming their velfies from passive documentation into intentional, self-directed narratives. Participant-Generated Production Credit Screen, Illustrating Self-Authorship and Intentional Storytelling in Velfies.
This transition—from impersonal visuals like static screen captures to personalized, expressive velfies—highlights the potential of video-based methods in participatory research (Itzik & Walsh, 2023).
Ultimately, the integration of velfies in Photovoice research offered a two-fold opportunity. First, velfies aligned data collection with participants’ everyday digital practices, making research participation more naturalistic and contextually relevant. Second, velfies facilitated a dynamic co-production process, allowing for greater expressivity and participant agency within safe, trust-based environments (Berger, 2015). As illustrated in Figure 9, the informal posture and close proximity of participants emphasize the relational and collaborative dimensions of velfie creation, reinforcing the sense of shared authorship and engagement. A Collaborative Velfie Capturing Peer Engagement and Shared Storytelling. Contextual description: This Velfie Highlights Peer Engagement, Featuring Formal Participants and Others Who Willingly Took Part. While One Individual Takes the Lead in Narrating, the Entire Group Actively Contributes, Greeting to the Audience. The Relaxed Posture and Close Positioning of Participants Highlight the Informal, Trust-Based Environment that Velfies Foster, Reinforcing the Relational Aspect of Digital Storytelling. Excerpt: ‘Hello Everyone! We are [They Say Their Names] and This is the Story of Our Project’.
Echo and Performative Velfies: Two Modes of Narrative Expression
We applied Knoblauch's et al. (2014) interpretive video analysis to examine velfies, emphasizing sequentiality, spatial configurations, and interactional dynamics in meaning-making. Rather than viewing them as static records, this approach recognized velfies as evolving communicative acts shaped by embodied interactions, narrative construction, and intentional framing (Jewitt, 2017; Mondada, 2018). Their multimodal nature—gestures, spatial positioning, and intonation—required analysis of both production context and social influences on meaning (Kress, 2010; Wang & Hannes, 2020).
As native video artifacts (Knoblauch et al., 2014), velfies demanded a sequential analytical approach. We conducted iterative viewing and detailed transcription to examine their structure, considering the recorder’s intent, framing choices, recording conditions, and technological affordances (Jewitt, 2017; Jewitt & Price, 2012; Knoblauch & Schnettler, 2012; Mondada, 2018). Metadata analysis of equipment, resolution, and frame rates further revealed how technological constraints shaped self-representation.
Beyond documentation, velfies served as self-representations and tools for identity negotiation in digital spaces, expanding discussions on visual and performative methodologies in qualitative research (Davey & Benjaminsen, 2021; Fazeli et al., 2023; Parsons et al., 2023). By integrating movement, voice, and performative elements, velfies enhance Photovoice’s expressive potential, bridging personal reflection and collective engagement.
Comparison Between Echo and Performative Velfies.

Through our analysis, we observed that echo velfies often reinforced participants’ existing narratives, memories, and affiliations, functioning as introspective tools that emphasized continuity and self-reflection (Esteban-Guitart & Moll, 2014; Moll et al., 1992). Participants tended to adopt static framing, maintain direct eye contact, and minimize movement, creating an intimate, testimonial aesthetic (Bordwell & Thompson, 2008; Nichols, 2017). that underscored the personal nature of their reflections (see Figure 10). Screen Captures from Echo Velfies. Contextual description A: The participant reflects on the importance of preparing for the future, describing a learning experience at a company. With her thesis co-supervised by an industry representative, she highlights the experience’s impact on her professional development. The velfie maintains a steady, direct-to-camera framing, with a personal narrative focus. Excerpt A: It does not matter how well equipped [intellectually] you are. There is always something new to be learned. Contextual description B: The velfie narrates Ilona’s story, a high school student who struggled with a lack of encouragement and qualified teachers. She later discovered a project where students helped pupils improve their learning and decided to join. As the video progresses, the narrative shifts from third person to first person, revealing that the participant and Ilona are the same, emphasizing a personal journey of transformation. Excerpt B: ‘Without education, dreams stay dreams!’.
We learned that echo velfies often follow a linear progression, with speakers maintaining a stable position and addressing the camera directly, emphasizing personal experiences and reflections. As illustrated in Figure 11, this videos capture a deeply personal mode of expression that aligns with vlog-style testimonials (Lange, 2011). Echo Velfie, Where the Participant Maintains a Stable Position and Direct-to-Camera Framing. Contextual description: This velfie explores the impact of digital tools in education, emphasizing their role in enhancing multiple aspects of learning, including students’ emotional engagement. Excerpt: ‘Sometimes, learning is about more than just facts. It’s about emotions, relationships, and finding meaning in what we study. That’s why emotional education should be a priority in schools’.
Our findings indicated that while echo velfies emphasized self-reflection and continuity, some participants treated velfies as performances, deliberately shaping their narratives with an awareness of their audience. It became clear that performative velfies transformed storytelling into an interactive and dynamic process, incorporating experimentation, improvisation, and social interactions (Esteban-Guitart, 2023; Jewitt, 2017; Subero et al., 2018). Participants integrated movement, engaged with their surroundings, and structured their recordings as co-constructed experiences (Goffman, 2007; Nichols, 2017). In Figure 12, for example, the participant moves dynamically, gesturing while addressing a peer. The shifting camera angles and outdoor setting contribute to an interactive, spontaneous feel. The excerpt, ‘Let me tell you... today I participated in an activity that I really enjoyed’ reflects the participant’s enthusiasm, with variations in tone and pacing enhancing engagement. A performative velfie example with dynamic sequencing, shifts in tone, movement, and rhetorical elements. Contextual description: The velfie features a staged discussion where students share their experience discovering design thinking and using Lego bricks to develop solutions for real-world challenges. Their enthusiasm is evident as they engage in dialogue, occasionally posing rhetorical questions like, “And you know what we have to do now?” to maintain engagement and emphasize key moments in their process. Excerpt
The study revealed that performative velfies enhanced storytelling through spatial variation and interactive engagement (Knoblauch et al., 2015). Participants structured their narratives dynamically, transitioning between settings and using gestures to emphasize key moments. Figure 13 presents a reenacted service-learning project structured episodically, transitioning from a problem statement (Excerpt A), to student-led tutoring (Excerpt B), and concluding with a collective reflection on the importance of education (Excerpt C). Performative Velfie with an Episodic Structure. Contextual description: The velfie reenacts a service-learning project through a staged scenario with an episodic structure. It begins by presenting a challenge (Excerpt A), follows the students as they support underprivileged peers in preparing for exams (Excerpt B), and concludes with a collective and enthusiastic reflection on the importance of quality education (Excerpt C). Excerpt A: 21
st
century education has its bugs, we can solve it! Our journey is about service-learning! Excerpt B
A key distinction between echo and performative velfies emerged in participants’ verbal and gestural delivery. Echo velfies featured steady, introspective monologues, with participants using a measured tone and intentional pauses to emphasize key points. This approach fostered self-exploration and unfiltered narration (Wang & Hannes, 2020). Ioan, an undergraduate student, reflected on this experience stating: “Today's review session was different—we didn’t just revisit the theory; we actively applied it. By creating test questions, I realized how well I understood the concepts and where I needed more clarity. It was an engaging experience because it wasn’t just about getting the right answers but about thinking critically and learning through a different kind of review.” (Ioan, undergraduate student)
This consistent delivery reinforced the testimonial nature of echo velfies. In contrast, performative velfies featured more dynamic speech patterns, with participants varying their tone, volume, and rhetorical strategies such as direct address, repetition, and contrastive phrasing. These elements indicated an awareness of audience reception, suggesting that some velfies were intentionally crafted not just for personal reflection but as communicative acts designed to engage and persuade. Figure 14 illustrates this approach, showing participants using rhetorical techniques to reflect on the significance of education, inviting the audience to consider how learning shapes lives and creates opportunities: In a world where knowledge is power, illiteracy remains a barrier for many. Education is not just about acquiring information; it is about transforming lives, opening doors, and creating opportunities. Today, we reflected on why learning matters and how it shapes our future. (Frame A) Frames from a Performative Velfie where Participants use Reflective Questions to Introduce a Learning Experience About the Relevance of Education. Contextual description: The velfie captures a challenge-based learning experience, combining ideation and mentoring sessions. Participants reflect on how these sessions helped them discover their strengths and engage more deeply with the learning content. Excerpt B: “What does it really mean to be educated? Is it just about acquiring knowledge, or is it about how we apply it to change our lives and the world around us?”; Excerpt C: “Education is not just a privilege; it is a right. It opens doors, creates opportunities, and gives people the power to shape their own futures. Without it, we remain trapped by limitations imposed by circumstance.”; Excerpt D: “In the end, learning is more than just a process—it is the foundation of progress. So, how will you use your education to make a difference?”.
Beyond verbal strategies, performative velfies demonstrated how gesture, movement, and facial expression shaped communication. Just as tone and phrasing emphasize speech, physical movements reinforced emotions, highlighted contrasts, and engaged the audience visually (Davey & Benjaminsen, 2021; Parsons et al., 2023). The analysis revealed a spectrum of gestural expressivity, ranging from subtle, minimal movements to highly dynamic body language.
The analysis revealed that spatial configurations and gestural expressivity played a crucial role in shaping meaning within velfies. In echo velfies, participants remained centered in the frame, using subtle hand gestures and facial expressions to reinforce their spoken words (Figure 11, Figure 15). These micro-expressions punctuated discourse, conveying nuances such as uncertainty, emphasis, or enthusiasm. In contrast, performative velfies incorporated full-body gestures, head tilts, and expansive arm movements, often synchronized with speech for heightened expressivity. This alignment of verbal and non-verbal modalities supports Knoblauch et al.'s (2014) argument that video-based narratives are interactional and embodied rather than purely textual. Some participants intentionally gestured toward objects or other individuals within the frame, using deictic markers (e.g., pointing, nodding) to integrate the physical environment into their narrative (Macdonald et al., 2024; West et al., 2022). Close-up Framing in an Echo Velfie, Using a Neutral Indoor Background.
Spatial configurations further shaped the communicative function of velfies. In echo velfies, individuals positioned themselves in close-up or medium-close shots with neutral or indoor backgrounds (e.g., desks, bookshelves, blank walls - Figure 15), reinforcing personal introspection and ensuring that attention remained on their facial expressions and verbal content.
By contrast, performative velfies utilized wider frames, shifting focal points, and spatial movement to enhance storytelling. Some participants repositioned themselves mid-video, transitioning between different settings (e.g., indoors to outdoors, seated to standing – see Figure 16), using spatial variation to expand their narrative. These movements transformed the velfie from a stationary reflection into an enacted experience, aligning with performative research methods that emphasize the co-construction of meaning through space and movement (Knoblauch et al., 2014). Frames from a Performative velfie illustrating Spatial Transitions and Dynamic Movement. Contextual description: The velfie depicts a staged discussion among students on how a teacher’s behavior and interactions influence their interest in a subject. The narrative unfolds across multiple settings, transitioning between indoor and outdoor environments to emphasize different perspectives. Excerpt: ‘Our teacher isn’t like the others. One day, she brings a guest speaker; the next, there’s music playing while we work. It’s not just about teaching—it’s about making us feel involved, making the class come alive. She even brought us a coffee machine!’.
The degree of interaction in velfies varied, distinguishing solitary narratives from co-constructed storytelling. Most echo velfies featured participants speaking directly to the camera without external input. However, some velfies introduced interactional complexity, incorporating dialogues (refer to Figure 17), off-screen responses, or engagement with peers. In these collaborative velfies, additional voices and gestures shaped the narrative, creating a dynamic, participatory exchange. This shift positioned certain velfies as relational artifacts rather than solely personal reflections, aligning with the social modality of video production (West et al., 2022). Performative Velfie Incorporating Dialogue. Contextual description: This velfie captures a moment of peer feedback during a mobile app development task. The interaction demonstrates informal yet constructive engagement as students test the app and share spontaneous reactions.
Researcher Reflexivity
Interpretive video analysis in the CAPTIVATE project assumes that recorded actions are meaningful performances shaped by participants (Knoblauch, 2014). This approach required reflexive engagement with velfies, prioritizing participants’ self-ascribed meanings over externally imposed coding frameworks (Knoblauch et al., 2014). Researchers then developed second-order constructs, linking these expressions to broader theoretical and methodological concerns.
Recognizing velfies as curated rather than unfiltered representations, we accounted for their performative nature—what participants chose to reveal, omit, or emphasize. To avoid overinterpretation, we conducted iterative analyses, cross-referencing interpretations within the research team and discussing potential misreadings of nonverbal cues, affect, and spatial arrangements (Knoblauch et al., 2006, 2015). These discussions ensured that meaning was co-constructed rather than imposed.
Differentiating between spontaneous and staged performances was central to our analysis. Some participants recorded unscripted, self-reflective monologues, reinforcing the testimonial authenticity of echo velfies. Others intentionally staged their velfies, incorporating reenactments, humor, and audience engagement. One participant, for example, narrated a walk-through of their academic environment, using gestures and dramatic pauses to enhance storytelling. This distinction aligns with ethnographic perspectives that treat audiovisual narratives as actively constructed rather than passive artifacts (Paganopoulos, 2022).
Divergent interpretations also emerged regarding sincerity and performance. One researcher viewed a participant’s discussion of time management struggles as genuine self-disclosure, while another noted shifts in tone, gaze, and self-conscious laughter, suggesting an awareness of audience reception. This reflexive dialogue highlighted the importance of analyzing velfies beyond verbal content, considering affective, spatial, and interactional elements (Knoblauch et al., 2015).
Velfies also fostered trust and self-expression in ways that static Photovoice did not. Anca, reflecting on academic challenges, shared: I don’t usually talk about this, but somehow, saying it in the video makes it easier—it’s like I’m telling myself, but also sharing it with others.
This underscores how velfies created an expressive, confessional space that traditional methods may not have elicited. Through reflexive analysis, we recognized our role not only as interpreters but as facilitators of meaning-making, navigating the interplay between self-representation, audience awareness, and research participation. Instead of extracting meaning from velfies, we approached them as situated, performative acts shaped by both personal expression and the research context.
Final Discussion and Conclusion
This article builds on insights from the CAPTIVATE study to position velfies as an extension of Photovoice, demonstrating their potential to enhance participatory research in digital environments. By integrating multi-method autobiographical approaches and funds of identity theory, we explore how velfies function as identity artifacts—multimodal constructs that enable participants to narrate, negotiate, and perform their identities within research settings. More than a participatory tool, velfies serve as instruments of inquiry, reinforcing the idea that audiovisual self-representations actively construct meaning rather than merely capturing reality.
We identified two types of velfies: echo velfies, which prioritize self-exploration and unfiltered narration, and performative velfies, which engage audiences through rhetorical techniques. Echo velfies extend Photovoice’s tradition of introspection and self-documentation, using voice, tone, and embodied emotion to deepen self-reflection beyond static images. Performative velfies emphasize interaction and shared meaning-making, shifting Photovoice from individual storytelling to a more dynamic, participatory process. While echo velfies capture personal continuity, performative velfies foster engagement and co-creation, expanding Photovoice’s expressive and social dimensions.
Velfies challenge the static representation of experience in traditional Photovoice methods. Unlike photographs, which are often interpreted post hoc through textual analysis, velfies enable sequential meaning-making—an unfolding of identity through movement, speech, and performativity. This shift from captured image to performed narrative enhances participant agency, allowing for first-person, reflexive storytelling (Esteban-Guitart, 2023; Itzik & Walsh, 2023; Jewitt, 2017; Yi & Zebrack, 2010). In CAPTIVATE, participants embodied their experiences through reenactment, improvisation, and intentional framing. This performative dimension aligns with expanded ethnography (Paganopoulos, 2022), where video functions as a public-facing act of knowledge production rather than a private self-reflection (Bordwell & Thompson, 2008; Hong, 2021).
Beyond participatory methods, velfies expand the concept of identity artifacts (Esteban-Guitart, 2023; Esteban-Guitart & Moll, 2014), reinforcing that self-representation is not only visual but also kinetic, spatial, and interactive (Craig et al., 2021; Jewitt, 2017). Their multimodal composition—gesture, intonation, environment, and movement—creates layered identity performances, making them particularly valuable in researching fluid and evolving identities (Bagnoli, 2004; Esteban-Guitart, 2023; Itzik & Walsh, 2023). This highlights the role of velfies in participatory methodologies, where identity articulation benefits from dynamic, multimodal engagement rather than static images or written reflections.
The methodological significance of velfies extends across disciplines, offering valuable insights for education, digital ethnography, health communication, and research with marginalized communities. In digital ethnography, velfies capture affective and spatial interactions, providing a more embodied sense of place, movement, and emotion than text-based or still-image data (Macdonald et al., 2024; West et al., 2022). In health research, video diaries have been used to document patient narratives, emotional responses, and treatment journeys, demonstrating their potential as therapeutic and self-reflexive tools (Sterling-Fox et al., 2020). Yet, integrating velfies into participatory research demands careful consideration of technological access, digital literacy, and ethical safeguards (Macdonald et al., 2024; West et al., 2022). While smartphones facilitated immediate and informal participation in our study, disparities in device quality and internet access influenced participants’ ability to produce and share velfies (Fazeli et al., 2023; West et al., 2022). Future studies should address these inequalities by providing training and digital facilitation to ensure equitable participation.
Beyond accessibility, researchers must critically assess how velfies are framed—whether as spontaneous, self-reflective tools or as staged, co-created narratives—to align methodological choices with research goals. While this study highlights their methodological potential, CAPTIVATE did not originally include velfies, meaning their limitations emerged organically rather than being systematically analyzed. However, digital storytelling research has identified similar challenges (Macdonald et al., 2024; West et al., 2022). Velfie-based data requires multimodal analysis, where researchers must interpret gesture, tone, movement, and sequencing alongside verbal content (Knoblauch et al., 2014). This complexity makes velfie analysis more time-intensive than traditional text-based or photographic data, requiring iterative viewing and detailed transcription (Fazeli et al., 2023; West et al., 2022). Technology access disparities also shape participation, particularly for those lacking high-quality recording devices, stable internet, or digital literacy (Black & Faustin, 2022; Chen, 2023). As with digital storytelling, differences in device quality—such as resolution, stabilization, and audio clarity—can create inconsistencies in data quality (Macdonald et al., 2024; West et al., 2022).
Ethical concerns around privacy, data security, and consent also require attention. Unlike still images, velfies inherently contain identifiable facial features, voices, and environmental context, making anonymization difficult (Abma et al., 2022). Participants may also feel uncertain about how widely they want their velfies shared, particularly if their views or emotional states evolve over time. Ensuring long-term participant control over their data remains a persistent ethical challenge (West et al., 2022). Another consideration is the tendency to structure narratives into coherent, linear stories. Participants may feel pressure to create “neat” narratives with clear resolutions, even when their experiences are complex, messy, or unresolved (Macdonald et al., 2024; West et al., 2022). Velfie research must remain conscious of this tendency, ensuring that participants feel free to express uncertainty, ambiguity, or nonlinear experiences rather than shaping their stories to fit expected formats.
Another key challenge is participant burden and digital fatigue. Research has shown that self-recording and editing can be emotionally taxing, particularly when discussing sensitive topics (Davey & Benjaminsen, 2021; West et al., 2022). Some participants may experience fatigue from repeated recordings, heightened self-consciousness, or emotional strain from sustained self-reflection (Fazeli et al., 2023). The expectation of technological competence in video editing and storytelling may also be overwhelming for participants unfamiliar with digital tools. Future research should explore ways to reduce participant burden while still maintaining the expressive and participatory advantages of velfies.
Addressing these challenges requires methodological flexibility, including alternative participation formats, secure data management strategies, and ensuring that velfies remain an empowering rather than exclusionary research tool. Future studies that deliberately integrate velfies from the outset could provide a more systematic understanding of their limitations, including digital fatigue, participant burden, and the negotiation of authenticity in self-recorded videos.
Ultimately, velfies represent more than a methodological innovation; they mark a shift in knowledge production. By blurring the boundary between documentation and performance, they invite dynamic engagement, positioning participants as co-producers of meaning rather than passive subjects of research (Abma et al., 2022; Ottoni et al., 2023). As digital research evolves, velfies stand not just as tools but as transformative agents, reshaping how lived experience is documented, constructed, and interpreted. Do velfies simply adapt participatory methods to digital research, or do they signal a paradigm shift in qualitative methodologies? Their power lies not only in what they reveal but in what they inspire—a more expressive, multimodal, and agency-driven approach to narrative construction, identity articulation, and research participation.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.