
Abstract
Qualitative research is important to advance health equity as it offers nuanced insights into structural determinants of health inequities, amplifies the voices of communities directly affected by health inequities, and informs community-based interventions. The scale and frequency of public health crises have accelerated in recent years (e.g., pandemic, environmental disasters, climate change). The field of public health research and practice would benefit from timely and time-sensitive qualitative inquiries for which a practical approach to qualitative data analysis (QDA) is needed. One useful QDA approach stemming from sociology is flexible coding. We discuss our practical experience with a team-based approach using flexible coding for qualitative data analysis in public health, illustrating how this process can be applied to address multiple research questions simultaneously or asynchronously. We share lessons from this case study, while acknowledging that flexible coding has broader applicability across disciplines. Flexible coding provides an approachable step-by-step process that enables collaboration among coders of varying levels of experience to analyze large datasets. It also serves as a valuable training tool for novice coders, something urgently needed in public health. The structuring enabled through flexible coding allows for prioritizing urgent research questions, while preparing large datasets to be revisited many times, facilitating secondary analysis. We further discuss the benefit of flexible coding for increasing the reliability of results through active engagement with the data and the production of multiple analytical outputs.
Keywords
Introduction
Health equity research aims to understand and improve the well-being of communities that are systematically excluded from healthcare and public health resources. Leading public health scholars have championed strengthening qualitative research science (Griffith et al., 2017, 2023; Shelton et al., 2022; Stickley et al., 2022; Teti et al., 2020) recognizing it as a valuable tool for advancing public health and health equity. Qualitative approaches enable researchers to obtain deep contextual understandings of the pathways by which social determinants of health and inequities in these factors affect individual and community health (Adkins-Jackson et al., 2022). It offers nuanced perspectives on the complexities of how individuals and communities experience and overcome these inequities. By amplifying the voices of those directly impacted by structural inequities, qualitative research offers potential to ground interventions in individual and community-level lived experiences (Griffith et al., 2023; Jeffries et al., 2019; Shelton et al., 2017, 2022), contexts that might be overlooked with strictly quantitative methods.
Despite the growing recognition of qualitative research’s utility for health equity, leading public health journals tend to publish more quantitative research (Stickley et al., 2022). Many researchers face barriers to applying qualitative methodologies, including the time and resources needed for data collection and analysis and limited or inadequate training experiences (Silverio, S., Hall, J., & Sandall, J., 2020; Vindrola-Padros et al., 2020). Further, team-based analysis of large qualitative datasets presents additional challenges, including recruiting and training team members, ensuring effective coordination and alignment on goals and methods, and maintaining coding consistency (Beresford et al., 2022).
The ability of qualitative research to illuminate structural drivers and solutions to health inequities increases the demand for methodological guidance in public health. Valuable guidance exists on building collaborative teams to analyze large datasets within time constraints (Bates et al., 2023; Giesen & Roeser, 2020; Vindrola-Padros et al., 2020), transitioning to methods that leverage virtual tools and support geographically dispersed teams (Roberts et al., 2021; Singh et al., 2022), and coding (Beresford et al., 2022; Locke et al., 2022)—a common, time-consuming qualitative data analysis technique (QDA) across various disciplines. However, little step-by-step guidance exists on coding qualitative data in a way that can effectively answer urgent public health questions in a timely manner. Furthermore, while there is pragmatic guidance for novice health equity researchers and practitioners on qualitative analytic strategies (Saunders et al., 2023), there is insufficient guidance on managing large, multifaceted projects or datasets involving teams with varying levels of expertise.
We need enhanced strategies to make qualitative methodologies more accessible and applicable in health equity research. This will enable qualitative and quantitative data to be used in partnership to provide a more holistic understanding of the social determinants of health by elucidating how health experiences are shaped and providing a deeper contextual understanding of the relationship between structural factors and health outcomes (Adkins-Jackson et al., 2022). Our field could benefit from developing and disseminating methods for analyzing large qualitative datasets and establishing structures that enable the efficient use of the data for multiple analyses.
Sociology scholars have proposed flexible coding as an effective approach for multidisciplinary teams working with large datasets, leveraging the capabilities of qualitative data analysis software (QDAS) (Deterding & Waters, 2021). In theory, flexible coding accommodates larger qualitative datasets and diverse team involvement with interdisciplinary perspectives. Flexible coding structures data in a way that streamlines collaborative coding and enables reanalysis. This structuring also facilitates involving novice coders in robust research, and enhances interpretation, dissemination, and translation of research findings through the production of multiple outputs throughout the analysis process. Moreover, this structure enhances analysis efficiency, facilitating community-based participatory research (CBPR). By segmenting the data, community-academic partnerships can conduct prioritized, focused, and timely review of specific topics based on community needs, focusing on the most urgent research questions. As a result, the process becomes more efficient and responsive, accelerating the transfer of knowledge into practical application. Yet, there is a paucity of practical guidance on applying flexible coding guidelines and managing the process for practice-based fields such as public health and research questions and approaches that involve community-academic partnerships.
This paper addresses these gaps by outlining the use of the flexible coding method for nimble CBPR seeking to leverage large qualitative datasets and multidisciplinary teams. It shows how flexible coding supports timely and rigorous qualitative data analyses that are poised to inform policy, systems, and environmental transformations to promote health equity. As we demonstrate in the following sections, employing a flexible coding approach facilitates an accessible and meaningful engagement process for community-academic partnerships to analyze qualitative data and addresses challenges many qualitative teams face. To advance the application of flexible coding for time-sensitive health equity research, we provide a comprehensive overview of our step-by-step methods. This process allowed us to address multiple research questions concurrently, organizing and equipping our team with practical tools for rigorous analysis. While we present a public health research project as a case study, we recognize and encourage this guide’s application across diverse disciplines engaging in qualitative analysis.
Setting
Project Context
To provide context into our approach, we use examples from two ongoing studies from our research partnership using a tailored flexible coding approach. Guided by the National Institute on Minority Health and Health Disparities (NIMHD) Research Framework and the Multisystemic Promotores/Community Health Worker Model (Matthew et al., 2017; Montiel et al., 2021), these studies aimed to develop a roadmap for community-centered recovery following the COVID-19 pandemic. These studies emphasized CBPR approaches (Israel et al., 1998), with community partners guiding every stage— research question identification, participant recruitment, data collection, analysis, and dissemination.
Project Datasets.

The second study is through the California Collaborative for Public Health Research (CPR3) initiative. It builds on findings from CATALYST highlighting pandemic-related mental health inequities and involves a secondary analysis of the data from CHWs and Orange County residents (48 of the 63 transcripts and 112 of the 127 participants). Using a popular education approach — a participatory, discussion-based method that actively engages communities to integrate their lived experiences to advance health equity (Wiggins, 2012)—we engaged CHWs in discussions to identify visions for mental health equity, community resilience, and future mental health promotion during public health crises.
Team and Research Structure
Role Structure.

Prior to this study, our team collaborated on a longitudinal evaluation of a community-level COVID-19 equity intervention. During that evaluation, we explored strategies to equip a wider team, beyond the primary researcher (PR), to conduct qualitative data analysis on a large dataset in a timely manner. Given the limited qualitative training in public health, we recognized a need for a structured approach to involve team members with varying levels of expertise. This experience also highlighted the importance of assessing the quality of the coding process throughout. Additionally, the qualitative dataset provided rich insights that prompted us to revisit the data, leading us to recognize the need for a structure, such as flexible coding. These experiences informed the recommendations and practices outlined in the following section.
Process
Flexible Coding Process Overview (Adapted From Deterding & Waters, 2021).

Notes: QDAS indicates qualitative data analysis software; RQ indicates research question; PR: Primary Researcher; ACT: Analytical Coding Team; ICA: Inter-Coder Agreement; ICT: Indexing coding Team; CIT: Community Interpretation Team.
Establishing Effective Practices for Data Collection
Establishing effective practices during data collection is crucial to conduct subsequent analyses. For our team, these practices first involve developing, in collaboration with community partners, a robust interview and focus group guide rooted in key topics related to the overarching research questions. Then, prior to data collection, the team familiarizes themselves with the guides, to allow for the benefits of semi-structured interviews, while ensuring all topics are discussed. Where feasible, we audio or video record the discussions to enable us to work with transcripts instead of relying solely on our notes and to capture nuances in interactions and tones that we can reference later in the analysis. Additionally, a two-person interview team enhances the quality of data: one individual trained in qualitative data collection facilitates the conversation, while the other focuses on note taking, recording, and observations. This second role, usually filled by a student, also serves as a training opportunity in qualitative data collection. The interview team drafts individual respondent-level memos promptly within 24-h post-data collection to capture immediate insights and nuanced details, enriching the collected data. Further, assigning unique identifiers to the different datasets and individuals simplifies the naming convention, allowing a systematic respondent ID classification.
To ensure clarity and efficiency, we provide a detailed overview of the entire process in advance, including roles, responsibilities, timelines, and specific tasks like prompt memo completion, thereby making the workflow transparent to all team members. These practices prepare the team for the subsequent data analysis phase.
Considerations in Selecting Qualitative Data Analysis Software
There are several factors to consider when selecting the tools to use for qualitative data analysis, including the ability to facilitate the generation of inter-coder agreement (ICA); suitability for use by teams of different sizes (we opted for flexibility with open seats rather than individual licenses); easy version control of main files; compatibility across different operating systems (e.g., Mac, Windows); and flexibility in analysis capabilities such as generating reports, creating matrices, and visuals. Most major software packages cover these key capabilities. Throughout our process, we have used Atlas.ti as our QDAS, but recognize the capabilities are similar across other software.
A Four-Stage Flexible Coding Process
As data collection progresses, we begin with a four-stage process for flexible coding, adapted from Deterding and Waters (2021, see Table 3). The process includes preparing transcripts and other artifacts for flexible analysis (Stage 0); applying index codes to the raw data to identify segments of the data that relate to specific topics of focus (Stage 1); applying analytical codes to relevant indexed subsets of the raw data, based on specific research questions (Stage 2); and refining the analysis iteratively (Stage 3). This structured framework begins after some data collection has occurred. We detail linear steps in our analysis, while acknowledging the iterative nature of the process (Locke et al., 2022).
Stage 0: Preparing for Flexible Analysis
We adhere to the guidance Deterding and Waters (2021) outline for transcription and database design to structure our source materials. For example, we establish a transcription protocol with detailed instructions for the transcriptionists. While a professional transcription company handled this task in our case, it can alternatively be undertaken by members of the research team. The protocol begins with instructions on formatting the transcripts. We use verbatim transcriptions and include periodic timestamps, facilitating convenient revisiting of the source recordings for evaluating tone of voice or facial expressions when deemed necessary by the analysis team in subsequent stages. We also incorporate the respondent’s unique identifier within the transcript body along with the interviewer’s initials (in cases involving multiple interviewers) instead of using generic ‘respondent’ and ‘interviewer’ names. This practice allows for easier data identification when reviewing excerpts and enables the consideration of potential interviewer effects during subsequent analysis stages.
We also provide guidance for redaction, where we remove identifying details while retaining crucial contextual information. For instance, we omit titles that pose identification risks (e.g., “City Mayor”) but maintain the city they represent. When positions are less identifiable (e.g., “CHW in Santa Ana”), we retain both details for context preservation. This becomes valuable when analyzing the data to recognize important details without returning to the source recordings. Lastly, we implement a standardized file naming structure for all transcripts, incorporating the participant’s or event’s identifier, the date, and the interviewer’s initials. For instance, the format might resemble “CHW01_12Feb23_MM”. We also incorporate transcription validation (usually by a more novice team member) to ensure necessary data has been redacted. Lastly, when transcripts require translation into English, we retain both the original language and the English transcripts. Once the transcripts are ready, we gather all the memos and notes from the interview team. These transcripts, memos, and any other source material are saved in a QDAS file.
The team then moves to assigning respondent-level attributes to each individual transcript file. Attributes are participants’ personal characteristics relevant to the study. This is similar to applying a code to a whole transcript to describe transcript characteristics. Attributes allow us to review differences and similarities in codes across different categories or attributes (i.e. race, gender, geography). For our project, respondent-level attributes are assigned to show person-level data from the participant demographic information collection, including participants’ gender, race, city, age group, and the interviewee set/segment/group (e.g., OC CHWs, OC residents, CA CHWs) (Table 1).
QDAS Design for CATALYST Study. Note: OC: Orange County; CHW: Community Health Worker; IRP: Institutional representative and policymaker; CA: California.
Stage 1: Organizing the Dataset through Indexing
With the database set up, our focus shifts to preparing for the analysis phase.
Developing Indexing Codebook
Analysis begins with indexing, a step in which we categorize our data by topics of focus. Indexing is foundational for flexible coding, as future analyses draw upon indexed segments of data. Accordingly, we recommend two coders index the data and assess coding agreement.
Example of an Indexing Codebook Based on an Interview Guide.

Index Coding and Validation
Once the indexing codebook is ready, the ICT applies these codes to the transcripts (Figure 2). The indexing codebook is added to the QDAS source file to begin indexing. Initially, we begin with the data collected thus far; if further data collection ensues, seamless integration into the project is facilitated by indexing the new data and incorporating it into the source file. Each ICT coder is assigned transcripts to index. They do a first pass to broadly capture each question asked under an index code. Given the non-linear nature of semi-structured interviews and focus groups, they then do a second pass, addressing one or two index codes at a time, identifying if that topic is discussed elsewhere, until all index codes are applied. Each index coder usually dedicates about 2 hours to indexing a transcript from an interview or focus group that lasted 1–1.5 hours. Due to the nature of the topic of our project, our data is often coded under several index codes. For example, a participant may discuss how mental health issues affected their chronic diseases in the same paragraph, which would get indexed both under ‘COVID-19 and mental health’ and ‘COVID-19 and chronic disease’. This underscores the importance of recognizing that certain passages can be relevant to multiple index codes. Properly capturing this one-to-many relationship is crucial because researchers focusing on different areas, such as mental health or chronic diseases, will rely on these index codes to access pertinent data. If the passages are not indexed accurately, important information could be overlooked. Example of Index Coding Based on Interview Guide.
We strongly recommend paired indexing, wherein two index coders independently index the same transcript, assess their ICA, and reconcile differences to generate a consolidated indexed transcript. This process is guided by the Krippendorff’s α coefficient, a common measurement for ICA, with a score of 0.8 and above indicating high reliability (O’Connor & Joffe, 2020). Once this level of agreement is reached, coders could proceed with distributing the remaining transcripts (i.e. split coding) and discuss any indexing questions that arise thereafter. Paired indexing guarantees thoroughness, minimizes errors, and serves as an effective training tool for novice coders, helping them become proficient in using QDAS and understanding the coding process. Under time or resource constraints, this process may be applied only until coders gain confidence in indexing and using QDAS, instead of being applied to all transcripts.
Once index coding is complete, we use the QDAS functionality of constructing a matrix of code-document analysis to verify if all index codes are in every transcript (Figure 3). Where this is not the case, the ICT returns to the transcripts to determine if the topic was not discussed or if it was an oversight in the indexing process. Example of Atlas.ti Code-document Analysis.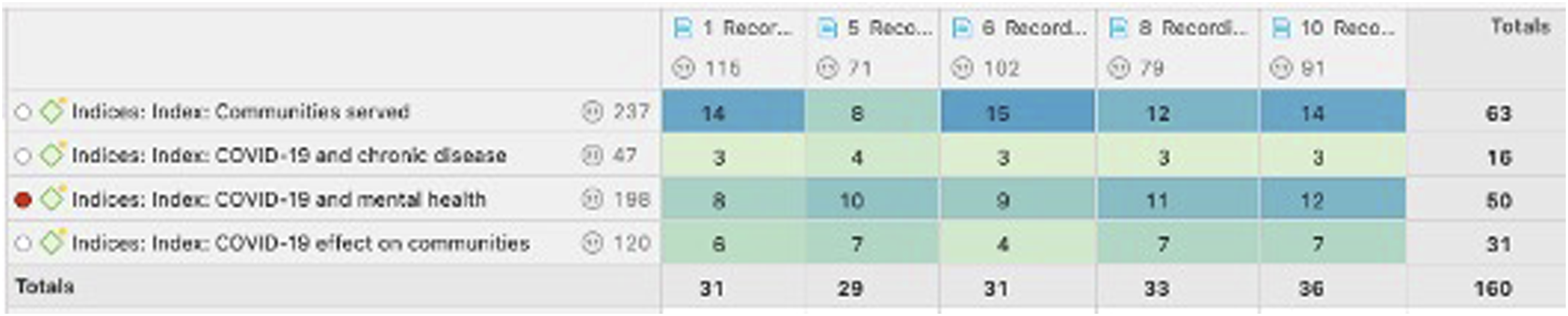
During indexing, a crucial practice involves the concurrent creation and maintenance of reflective memos. The indexing team generates respondent-level memos (one for each transcript they code), along with cross-case memos to document patterns, emerging similarities, and differences across their transcripts. This process serves a multifaceted purpose, contributing to refining our analysis during this crucial research phase while nurturing the development of memo-writing and analytical skills within our team, especially among those new to this process. Writing memos is an important step for researchers to begin describing and analyzing what they are observing, while also being reflexive on their positionality with respect to the participants and topics. During this stage, the ICT begins a list of potential “analytic codes” and their definitions as ideas and insights emerge. Insights from these memos can be shared with the Community Interpretation Team (CIT) to inform the potential focus and directions for the first analysis.
Stage 2: Applying Analytical Codes Based on Each Research Question (RQ)
The subsequent phase involves analytical coding, a stage guided by each individual research question. During this phase, the primary researcher develops unique analytic codes to address a research question, and the analytic coding team systematically applies these codes to the relevant segments of the text. This stage allows the involvement of multiple researchers, each dedicated to different research questions within the overarching study.
Defining the Research Question and Dataset
The first step involves the PR selecting a focused research question (RQ), based on the overarching study or inquiries emerging during data collection, indexing, and discussions with community partners and the CIT. Each RQ undergoes feedback and refinement in a community partner forum prior to analytical coding. Subsequently, the PR outlines the RQ’s aims and objectives to provide a detailed articulation to guide coders on when, why, and what to code. Furthermore, this helps narrow down the datasets needed to address the question. For example, is the question encompassing the voices of CHWs only, or should it also include the voices of community residents? Once the dataset is determined, the PR is ready to identify the specific index codes needed.
Identifying the Index Codes
With the dataset selected, the PR is ready to identify the index codes for their RQ. In some cases, the choice is direct. For example, when working on the mental health project, the mental health index code was selected from all transcripts. Similarly, when looking into the impact of language on CHW efforts, the language index code was selected. When a research question could span multiple index codes, or the PR is new to the project and not well-acquainted with the interview guide and index codes, the PR conducts a focused review of a subset of selected transcripts to identify the relevant index codes for their research question. These transcripts are thoughtfully chosen to represent the overall population and the dataset type (e.g., attributes), considering factors such as including both interviews and focus groups (if present in the selected dataset) or incorporating samples from each perspective type included in the analysis (e.g., IRPs, CHWs, and residents). For instance, two transcripts per group are reviewed. Within this subset, the PR applies a new designated code, labeled with a concise name for the research question (e.g., RQ3), a process we refer to as indexing for the RQ. This indexed subset is then reviewed to identify the original index codes it overlaps with, determining the index codes to be included in the analysis (Figure 4). This is often done through a code-co-occurrence analysis, a feature of the QDAS. Process of Identifying Multiple Index Codes that Apply to a Research Question.
Developing the Analytical Codebook
After selecting index codes, the data corresponding to these index codes is aggregated. This data reduction process simplifies the analysis by narrowing the researcher’s focus, wherein they read these specific sections rather than entire transcripts. For instance, in the mental health analysis, mental health index codes encompass approximately 13% of the total quotations in the transcripts.
Alongside this indexed data, the PR reviews the ICT and interview teams' memos. They then formulate the initial analytical codebook tailored to their research question, including inductive (e.g., informed by qualitative data) and deductive codes (e.g., concepts from existing theories or frameworks) and noting the boundaries and connections across these codes. This step focuses on systematically linking concepts from Stage 1 to the data. The codebook can contain the following fields: 1) Code Name, 2) Definition, 3) Example quotes, and 4) Boundaries between the codes (e.g., distinctions between codes). Recognizing the codebook as a living document, the Analytical Coding Team (ACT) and PR meet multiple times to refine the codebook, including feedback sessions with the CIT, consultations with the research team, and revisiting the literature. Finally, the ACT, comprising two or more coders selected for their interest, training, and availability convenes to discuss the codebook, examine sample quotes, address initial queries with the PR, and implement necessary modifications such as clarifying code definitions or boundaries.
Example of an Analytical Codebook.

Example of Multiple Concurrent Research Questions (RQ).

Note. CHW: Community Health Worker; IRP: Institutional and policy representatives; OC: Orange County.
aThe numbers refer to the numbered index code within each dataset.
Applying Analytical Codes
To streamline communication around each research question, we utilize a dedicated channel (e.g., Slack), linking the Principal Researcher (PR) and the ACT.
To start the process, each ACT member independently codes within the same selected indices in a transcript. Then, they meet with the PR to discuss initial coding insights, address any challenging codes, and outline the coding timeline. An effective strategy when feasible includes the PR first coding a transcript for the ACT to independently code, ensuring consistent codebook application.
Following this, the coders move to the remaining transcripts, concentrating on applying 1-2 analytic codes at a time to each selected index code, until all analytical codes have been applied in each transcript. Focusing on a small subset of the codes at a time to only the applicable sections of a transcript enhances the reliability and validity of the coding process. When feasible, the ACT does paired coding, independently coding the same transcripts and systematically evaluating ICA. The ACT initially meets after coding 5–10% of the transcripts. The coders maintain a shared file where both coders independently keep notes on the transcripts they have coded up to the meeting point. During ICA meetings, the team documents any discrepancies or changes needed. The team also communicates while independently coding if they have questions on how to apply a code or doubts on a particular transcript. If changes to the codebook are required, the coders go back to transcripts previously coded and code again for any edited or new codes to reflect changes. Paired coding is done until they reach an overall 0.8 ICA. They also assess the ICA for individual codes to ensure all are meeting the standards of 0.8 ICA. Once 0.8 ICA is achieved, and taking into consideration the timing constraints and the team’s coding experience, the team may implement split coding (Campbell et al., 2013; O’Connor & Joffe, 2020) for the remaining transcripts. In our projects, achieving a 0.8 ICA typically requires coding 2-5 transcripts. Through split coding, the ACT divides the remaining transcripts for independent coding, with continuous open discussions for any new insights or questions, ensuring consistent and accurate coding across the team.
Simultaneously, each coder maintains a memo, encompassing respondent-level (e.g., subset of one transcript) and cross-case analyses. This could be a written memo or “analytical maps” (Singh et al., 2022). The memos highlight noteworthy aspects, identify intriguing elements, address ambiguities, examine unexpected occurrences, assess the utilization of specific codes, and propose potential analytical foci. The PR actively engages with the memo, posing clarifying questions, encouraging coders to revisit data for a more comprehensive understanding of phenomena, and evaluating the uniqueness or representativeness of certain phenomena within the dataset. This step is critical to ensuring that the team remains close to the data, and that the qualitative research process is iterative. This serves to deepen and accelerate qualitative analysis and is a critical precursor to writing the manuscript or other dissemination materials (e.g., public-facing summaries of emerging findings).
Example of Estimated Timing for Indexing and Coding One Research Question.

aTime estimates vary according to level of experience with coding and prior familiarity with the data (e.g., interviewer indexing transcript vs. researcher indexing transcript that they did not collect).
bIndexing involves applying all the indexes, applying 1-2 indices at a time and re-reviewing transcripts to ensure that transcripts were fully indexed. This is a one-time activity.
cThe time analytic coding takes depends on the number of codes in the analytic codebook.
Stage 3: Refining the Analysis
Once all transcripts are coded, the PR is ready to deepen the analysis, aiming to establish theoretical contributions grounded in the data. The ACT creates a final reflective memo, harnessing new ideas and patterns they observe. To create this memo, the ACT leverages several QDAS capabilities, including code-document analysis querying to produce a matrix showing code frequency within each document or querying the co-occurrence of attributes and codes to identify any patterns and negative cases. In the memo, they describe key codes, summarize their observations and the patterns present, and include quotes describing their observations.
The PR engages with the reflective memo to move the analysis along by identifying guiding categories and patterns/themes. The PR uses this final memo, the coded data, and the QDAS reports to fully understand the data and refine the data-based theories. They also use the literature to guide what to scrutinize in the coding/analysis and use it to sensitize and deepen the analysis. Throughout this process, the PR meets regularly with the ACT to discuss initial findings and gaps. The PR and ACT revisit the coded data frequently to validate concepts or recode for any new concepts. In this stage of analysis, the PR works closely with much reduced data, attentively organized into analytical codes and can use the QDAS capability to test the theories and patterns that are forming. The PR then organizes and groups the emerging findings from the codes into categories, followed by patterns and themes -- all of which begin to create a narrative and theoretical framework grounded in the data.
The PR and ACT then prepare these groupings for review and discussion with the CIT. The CIT guides the analysis and points to areas where we might need to revisit the data to deepen the analysis. The PR and the ACT continue this process iteratively, reviewing their analysis and revisiting the data until they can move from descriptive to interpretative analysis. To continue to deepen the interpretive analysis, the PR and the ACT work through the different data sources (e.g., transcripts, memos, literature). They note details such as observations across different participants/sources of data (racial/ethnic groups, participant ages, interviews vs. focus groups), negative cases to earlier patterns, discrepancies between the data and expectations, surprising findings, and analogies used by participants or coders. All this helps move the narrative forward, with themes telling a story, rather than simply describing observations at surface level.
Discussion
We have distilled our experience working with a large dataset and a diverse team in a community-academic partnership into a step-by-step summary for applying flexible coding in qualitative data analysis for health equity research. Our practical guidance, based on the original description of flexible coding by Deterding and Waters (2021) is tailored for public health, and practice-based approaches, making complex methodologies more approachable for novice researchers and enabling meaningful multidisciplinary community-academic research. Nonetheless, this guide can apply across multiple disciplines and for datasets of varying sizes, as it provides a systematic method for structuring and coding the data.
We draw from our collective experiences working on these projects and implementing a standardized flexible coding approach to offer key lessons learnt to assist research teams in adopting a flexible coding strategy. These key lessons and opportunities include maximizing the qualitative dataset’s impact, responding to community priorities, standardizing data analysis with a diverse team, continuously engaging with the data, forming and supporting the analytic coding team, and training qualitative scholars.
Maximizes Data Impact
Our outlined flexible coding approach extends the utility of our data beyond traditional analysis methods. It helps prioritize urgent public health topics for immediate attention while also preparing the data for future and secondary analyses. This is critical, considering the time-intensive demands of qualitative methods for researchers, community partners, and participants—such as developing the facilitation guides, recruiting participants, and conducting and participating in interviews or focus groups.
Enabling secondary data analysis is a key benefit of flexible coding, and it is a practice that should be encouraged in public health (Ruggiano & Perry, 2019). As health equity researchers, we aim to minimize the burden of participation and maximize participants’ contributions, recognizing that many participants come from communities facing significant structural inequities. A flexible coding approach organizes the data to facilitate revisiting and conducting focused secondary analysis, eliminating the need to start an analysis from scratch if new priorities or research questions emerge. For future and secondary analysis, researchers can leverage the indexed data by selecting only the relevant index codes and reviewing the corresponding memos of those involved in data collection and index coding.
Responsive to Community Priorities
Through this practical approach to qualitative data analysis, we can engage in authentic community-based participatory qualitative research, where community partners prioritize and guide the research process. For effective health equity research, academic teams must rely on having an established community-academic partnership – true involvement of community in every step is critical for health equity. This process enables teams to identify and prioritize key pressing questions to address. For instance, our collaboration allowed CHWs and community and academic partners to identify and prioritize multiple research questions, ensuring findings could be quickly incorporated into their urgent advocacy work. This required us to prioritize specific research questions and conduct rapid and focused data analysis to ensure our findings were useful and relevant.
Provides Standardization and Leverages Technology
Standardizing the QDA process is crucial for enhancing project planning, particularly when tackling new research questions within existing datasets and outlining future projects and grants. Through this process, we have gained detailed insights into the various steps and the expected timing of tasks. This has helped us foster more integrated community-academic partnerships, as we define the processes to authentically integrate community partners in analysis and dissemination, an essential part of CBPR (Israel et al., 2018), but a common gap. A deeper understanding of processes conducive to authentic engagement can significantly aid partnerships in planning and budgeting their projects.
This standardization also allows us to effectively utilize advancements in software technology. Flexible coding encourages consistent use of various QDAS capabilities to strengthen the analysis. The integration of emerging artificial intelligence (AI) capabilities to assist with analysis is a promising avenue (Morgan, 2023). AI could assist with initial indexing and memo writing, potentially reducing early-stage coding time. Nevertheless, researchers must remain deeply engaged with the data throughout the analytic process and adopt processes to assess the quality of any aspects of qualitative data analysis supported by AI.
Encourages Continuous Engagement with the Data
By not attempting to answer all research questions at once, flexible coding enables us to easily investigate in-depth different facets of the data. Flexible coding addresses the challenge coders face of applying numerous codes to transcripts, where specific codes are applicable only to specific segments of transcripts (Giesen & Roeser, 2020). This process increases the reliability and validity of coding, as coders can focus on one topic at a time across a subset of a transcript, making the task more focused and less time consuming.
The creation of multiple research artifacts (including various memos) throughout different phases enhances the quality of the data analysis process, offering numerous opportunities to guide the study’s direction, enhances validity, and provides another integrity check of findings and interpretations (Locke et al., 2022). Moreover, this iterative, engaged process prioritizes discussions with community partners to ensure alignment with their priorities, a critical practice for promoting health equity. The flexible coding structure allowed our team to share and have joint discussion of all outputs with community partners for their input (e.g., determining key attributes, review of index codes, identifying research questions, informing the codebook, interpreting the initial analysis to identify emerging themes).
Through this process, the lead researcher remains engaged with the coders and reviews coding reports and memos throughout the process, not simply at the end. As is common in qualitative research, the researcher plays a critical role in the data analysis, interpretation, and dissemination (Wa-Mbaleka, 2020). Contrary to quantitative research, we acknowledge the influence of the researcher and as such, endorse researcher reflexivity (Denzin & Lincoln, 2011; Rankl et al., 2021). Reflexivity of community-academic partnership members is also critical to engaging in the qualitative data analysis process. Importantly, we note that continuous engagement of all researchers increases the strength of the analysis, ensuring different viewpoints and different artifacts are available at different phases.
Accommodates Different Team Models
A flexible coding approach enabled us to accommodate different team models. It allowed students in our academic lab to contribute to and learn QDA without being involved in every aspect, accommodating the varying task durations and students’ tenure in the lab. Additionally, this approach enabled different investigators to conduct focused research based on their specific interest area. Nonetheless, varying team capacity and availability can impact team formations.
A key team is the ACT, often formed based on students’ interest and current QDA experience. We strongly recommend every ACT designate a lead coder with strong qualitative experience to oversee the team. Based on team composition, there can be potential variation in the number of meetings an ACT will need to ensure alignment on codebook implementation and address discrepancies. Several factors can impact ICA. One common challenge is an overly complex codebook with too many codes, which can lead to unclear choices and potential overuse of double and triple coding. This suggests a need for simplifying the codebook. Additionally, rarely used codes may indicate a mismatch with the data or that coders are overlooking some codes due to the abundance of options. The codebook must have clear definitions and examples (Table 5) to help coders understand the intended use of the code and to have boundaries for the codes when needed. Lastly, new coding teams should discuss and define their coding approaches (sentences, or paragraphs, etc.), considering the project’s goals. For example, coding full paragraphs may be more suitable for projects aiming to include personal anecdotes or stories, while projects requiring smaller segments or powerful one-line statements may benefit from coding smaller sections.
Serves as a Training Tool
Tailored flexible coding is an important training tool, which facilitates a team-based approach to coding large datasets that strengthens individual and collective capacity for QDA. Using a flexible coding approach also serves as an effective means of training novice coders in qualitative data analysis, allowing them to grasp the methodology by initially applying index codes, an inherently simpler process. Tailored flexible coding provides an opportunity to grow the qualitative skills of our public health workforce -- by engaging students and those new to qualitative methodologies in concrete steps as they build upon their familiarity with QDA (Figure 5). Nonetheless, we also call for more formal qualitative training through the curriculum for both undergraduate and graduate Public Health programs. Tailored Flexible Coding Steps to Gain Qualitative Data Analysis Experience.
Strengths and Limitations
This paper has several strengths, as well as some considerations relevant to the scope of focus and generalizability to other contexts. This paper focuses specifically on the process of QDA with a flexible coding approach. While other phases of qualitative research are not within the scope of this paper, we acknowledge good analysis is impacted by strong practices in the design and data collection phases of the research project. It is essential to note that qualitative methods and methodologies alone may not inherently align with the goals of health equity and health justice research. Aligning research goals with a critical health equity stance should guide method selection (Bowleg, 2017). Lastly, while our process involved a large team, the concepts discussed could be applied by smaller teams or individuals analyzing qualitative data, particularly with large datasets, expanding the reach of our findings beyond our team’s scope. This process has applicability beyond what we have used it for. While we argue for its benefit in public health and with large datasets, flexible coding is a systematic approach to structuring data for reliable analysis that can benefit most qualitative analysis. Any team, researching any topic, and with any amount of data could benefit from this type of process or ideas from this process.
Conclusions
This paper sought to describe a tailored flexible coding approach for practice-based fields such as public health, particularly health equity scholarship that incorporates a community-based participatory research approach. Given the growing scale and frequency of public health crises (e.g., pandemic, environmental disasters, climate change), the field would benefit from timely and time-sensitive qualitative inquiries for which a practical approach to QDA is needed. Insights and processes delineated here have strong potential to contribute valuable information on community- and practice-based evidence and offer implications for policy, systems, environmental, and programmatic transformations, beyond what can be gleaned from quantitative research alone.
Footnotes
Acknowledgements
We extend our sincere appreciation to the invaluable contributions and dedicated support provided by our partnership members: Latino Health Access, Orange County Asian and Pacific Islander Community Alliance, Radiate Consulting, GREEN-MPNA, and AltaMed. Their commitment to these research efforts has been instrumental in guiding the research questions, shaping the research approach, and interpreting and disseminating findings. A heartfelt thank you goes out to the Community Health Workers (CHWs) and Community Scientist Workers (CSWs) whose invaluable insights and tireless efforts in engaging our communities have been pivotal in shaping our understanding of the critical work of CHWs in the COVID-19 pandemic. We are also immensely grateful to all participants whose involvement made this research possible. We express our gratitude to advocates promoting health and racial equity and to the individuals who shared their stories, resilience, and aspirations, shaping the essence of this research. Special recognition is extended to the University of California, Irvine (UCI) students whose commitment, enthusiasm, and assistance greatly facilitated our research efforts and significantly contributed to the success of this project. We also acknowledge the representatives of UCI Program in Public Health for their support and collaboration. Additionally, we are thankful for the financial support of several institutions and agencies.
Author Contributions
M.M. and A.M.W.L. conceptualized this study. M.M. led the writing and revision process. M.M., M.P., A.Z., N.C., B.M., S.T., S.Z., G.M.H., J.B., P.C., M.A.F., A.M.W.L. were all actively involved in this research process and contributed to the manuscript writing and revision process.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Research reported in this RADx® Underserved Populations (RADx-UP) publication was supported by the National Institutes of Health Loan Repayment Program; the National Institute on Minority Health and Health Disparities under Award Number (U01MD017433); the California Collaborative for Pandemic Recovery and Readiness Research (CPR3) Program, which was funded by the California Department of Public Health; and the University of California, Irvine Wen School of Population & Public Health, Department of Chicano/Latino Studies, Center for Population, Inequality, and Policy (CPIP) (California Collaborative for Pandemic Recovery), and Interim COVID-19 Research Recovery Program (ICRRP). The content is solely the responsibility of the authors and does not necessarily represent the official views of the funders Grant Number: U01MD017433; 140673F/14447SC.
Ethical Statement
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.