
Abstract
For the past thirty years, qualitative psychology researchers have focused on the study of written or spoken word while relegating the study of visual communications to children or those deemed unable to speak (Reavey, 2021, p. 2). Thus, the discipline now pays much attention to the collection and analysis of spoken or written words but significantly less to visual and auditory expressions of experience (Reavey, 2021, p. 3), and most transcription methods for psychology researchers are those designed for interviews that only capture the spoken word. However, these transcription methods have yet to account for the current context of ubiquitous, technologically mediated interactions. People from diverse groups use social media platforms such as YouTube and TikTok to interact using speech, audio and video. While they offer rich data for qualitative psychology researchers, the tools to capture such multimodal expressions are still in early stages of development within the discipline (Marshall et al., 2021). In this article, we present a transcription structure that allows for the recording of both speech and visual elements in audiovisual content. Inspired by methods from communications and visual anthropology, the Four Column Analysis Structure (or, FoCAS) allows for the simultaneous analysis of both audio and visual data by allowing for the transcription of four dimensions: (1) timestamp, (2) setting, (3) scene, and (4) audio. Based on its application in two completed studies and one study in progress, we describe the development of the FoCAS, how to set it up, transcription conventions, and how to analyze qualitative data using all four columns. We additionally discuss sampling considerations and the advantages and disadvantages of the structure. By expanding the amount of meaningful data that can be captured by qualitative transcription, we hope the FoCAS can be used to create more multidimensional, rigorous analyses of audiovisual data.
Introduction
Gadamer (Gadamer, 1989, p. 165) noted, Every work of art, not only in literature, must be understood like any other text that requires understanding, and this kind of understanding has to be acquired. […] Understanding must be conceived as a part of the event in which meaning occurs, the event in which the meaning of all statements, those of art and all others of tradition-is formed and actualized.”
Likewise, to understand the meaning embedded in the “event” of media, the qualitative analysis of audiovisual data must include analysis of the visual alongside the audio (i.e., spoken word), as it is a necessary part of storytelling (Reavey, 2021, Marshall et al., 2021). The spoken word and the visuals involved in this type of data both have rich and critical information to convey.
Today, Gadamer’s words (Gadamer, 1989) about understanding the context of meaning are more relevant than ever for qualitative researchers who have an abundance of audio-visual data sources to choose from to answer research questions about a range of topics. This includes online videos, vlogs, and social media posts on platforms like Instagram, TikTok, and YouTube. Across the globe, people use these audiovisual tools to share information about their experiences, meaning-making, and lifestyles. In addition, the cessation of in-person research during the COVID-19 pandemic, for many researchers, led to innovations such as turning to existing online data sources, such as social media portrayals of experiences. We exist in a moment of highly accessible, algorithmically personalized media, that informs and interacts with human behaviors, so studies of human behavior need a way to analyze this data rigorously that is appropriate for the platform.
However, lack of a cohesive and recent analytical method that accommodates both audio and visual information limits researchers’ ability to work efficiently with this data-that is, in a way that equally prioritizes both the audio and visual information. The two-column coding system recommended by Rose (2011) comes close, as it deconstructs film and television content into dialogue and camera work. The system also lends itself well to the narrative structure analysis Rose (2011) suggested, which translates aspects of the narrative into numerical frequencies and descriptive statistics. However, this system has been used to analyze productions with teams of professionals planning every shot and sentence of dialogue toward a narrative end. It is less adept in the present landscape of socially significant videos being created and shared by everyone from professional filmmakers to adolescents in their bedrooms. Further, the structure of Rose’s system sacrifices the flexibility to accommodate other forms of qualitative analysis used throughout the social sciences, such as thematic analysis or interpretive phenomenological analysis.
Without adequate analytical methods, researchers might focus on one source and ignore the other. For example, in our lab’s recent analysis of how young women who have experienced adolescent intimate partner abuse describe the maintenance of their abusive relationships, we described the characteristics of the YouTube method used (i.e., “storytime”; Hegel et al., 2022, p. 820) but only analyzed the YouTubers’ spoken dialogue (Hegel et al., 2022). We sought to address this limitation in our future work, which led to the development of our Four Column Analysis Structure (FoCAS) described here.
Purpose
In this paper we explain the development of FoCAS, describe and illustrate how to use it as a tool for qualitative analysis, and discuss its advantages and disadvantages based on our experience thus far. In doing so, we pull from two studies recently completed in our lab, and one in progress: one examining YouTube influencers’ descriptions of self-care (Knowles & Cummings, 2023), one evaluating how adolescents who menstruate use vlogs to discuss dysmenorrhea (Mohammed et al., 2023), and one assessing how parent vloggers depict families evacuating wildfire (Deleurme, n.d.). This transcription method can work for any audio-visual data that utilizes a video camera and dialogue. Your data source can include publicly accessible material (for example, posts on social media websites), or materials behind a pay wall (such as paid movie and television subscription services, like Netflix or Crave). Video content may include entire films, portions of films, episodes of television, one scene, a single video, a TikTok, or even a public Story (Facebook, Snapchat, Instagram).
Coding Multimodal Meaning
To enrich psychological approaches to audiovisual research, we draw upon Stuart Hall’s (1980/2006) theory of encoding and decoding to grapple with the challenges of analyzing meaning across modes of communication. Hall (1980/2006) argued that in the “aural-visual forms of the televisual discourse” (p. 164), communicative events are encoded with meaning through their production, circulated among consumers, then the meaning is decoded by the consumers who use and reproduce the communication. These codes of meaning between consumer and producers may seem aligned through a process of naturalization but are rarely (if ever) symmetrical (Hall, 1980/2006). He uses advertising as an example wherein each visual sign “connotates a quality, situation, value, or inference, which is present as an implication or implied meaning” (Hall, 1980/2006, p. 168), and whose decoding depends on the social position of the viewer. Decoding requires the audience to interpret the signs of the audio-visual material through the particular cultural “maps of meaning” (Hall, 1980/2006, p. 169) that “have the whole range of social meanings, practices, and usages” (Hall, 1980/2006, p. 169) bound to them.
The FoCAS draws influence from this theory to conceptualize how audiovisual meaning can be translated and analyzed alongside speech. Viewing audiovisual content as communicative events, the FoCAS calls upon the transcriber and analyst to decode the meanings that creators encode into their productions, and gain insight to how such meanings are engaged and reproduced in the world. By tracking their decoding of audiovisual and verbal data simultaneously, researchers engage in a deconstructive process to explore the relationship between both elements of the data. This decoding process is explicit and reflexively generated, acknowledging that interpretation is constructed by the analyst and transcriber’s cultural backgrounds and positionalities. By identifying the qualities at work in the content, researchers can more abstractly look at the lived implications of the discourse for consumer practices and behaviors.
Setting Up the Four Column Analysis Structure
The FoCAS’ columns are: (1) timestamp, (2) setting, (3) scene, and (4) audio. Figure 1 shows one way of setting up the initial file with each column as well as video and project characteristics we have found helpful to record. Researchers should tailor these characteristics to match what is most useful for them. Blank template of the FoCAS structure. Note. The project characteristics section of this image includes details specific to the self-care influencer study, such as “URL”, “uploaded by”, and “influencer anonymized name”. Researchers will need to adjust the characteristics to those most appropriate to their own study.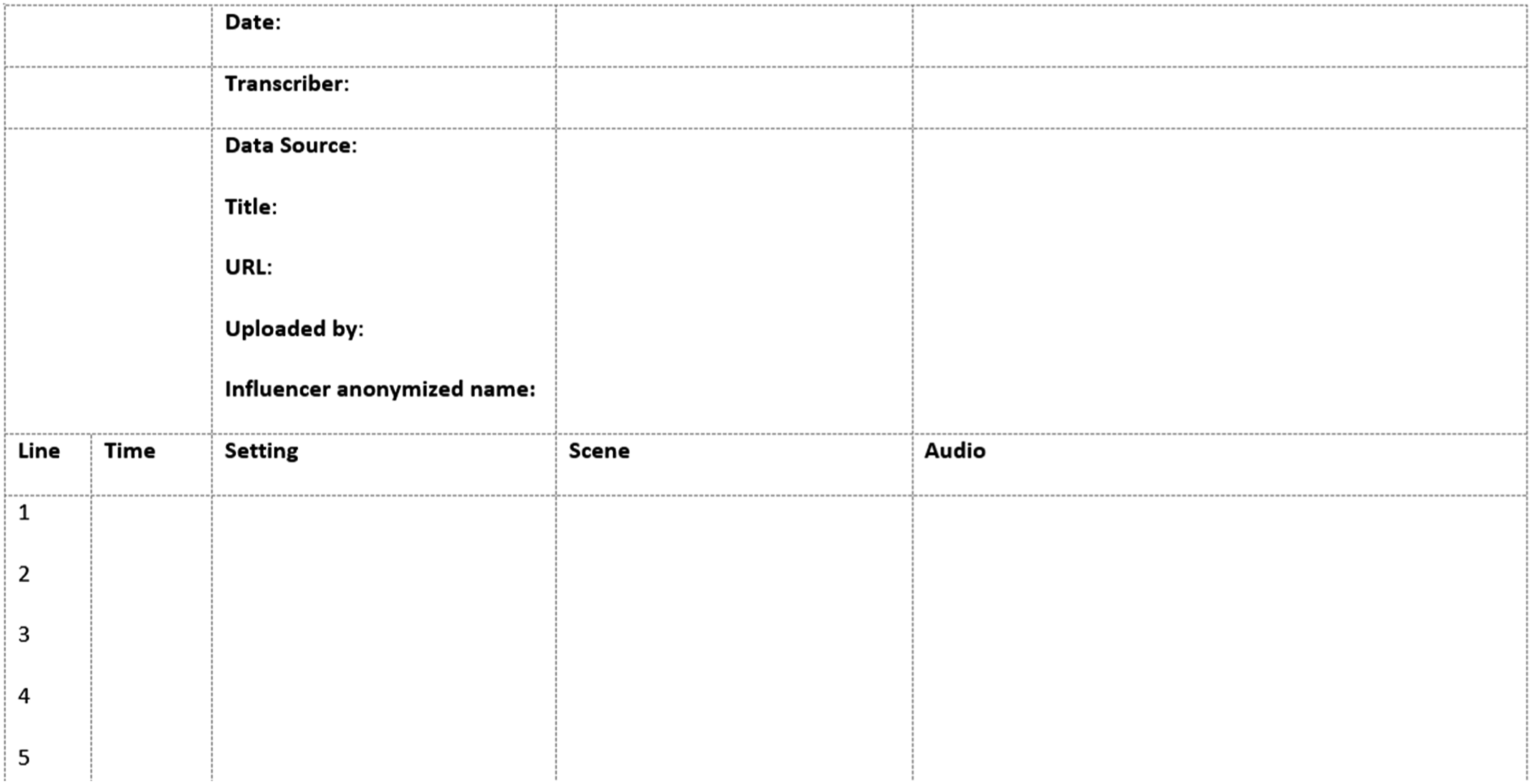
Data should be transcribed from left to right, starting with the line and time stamp, then transcribing the relevant information in the setting and scene, followed by the dialogue. Any sections of the video that are deemed irrelevant to the research question or otherwise fall under exclusion criteria can be omitted from the transcript (see Sampling Considerations for more information). We now define each column and provide more details for their transcription. Figure 2 provides an example of the FoCAS with all four columns filled in with data from our self-care influencer project. FoCAS structure with data from the start of a YouTube video filled in.
Setting
Visual data is descriptively recorded in two columns: setting and scene. These columns cumulatively constitute the mise-en-scène, which describes “a result of decisions about what to shoot and how to shoot it” (Rose, 2016, p. 73). The setting column covers “what to shoot” and in this column the transcriber notes any “objects, items, and surroundings that were visible” (Knowles & Cummings, 2023, p. 8). In doing so, the researcher acknowledges that the objects in frame carry meanings that help identify the social world in which the video takes place, and that these visual meanings are subject to interpretation and re-interpretation from the perspective of the researcher’s particular cultural position (Hall, 1997). Transcription of this section hinges upon the idea that “social texts-objects and things-are texts of materiality” (Mitchell, 2011, p. 37). As Mitchell (2011) describes, objects are the “social accessories of institutions and everyday life that are imbued with history and with meanings” (p. 36). The displayed objects represent meaningful information about the video creator’s social location; how they are positioned in the world thus informs the way they experience it (Mitchell, 2011). The setting therefore gives the researcher meaningful information about the video creator’s own cultural backdrop. This holds particularly true for videos in which the video creator is telling their own story, as the setting holds many of the decisions they have made about how the story ought to be told.
Ultimately, the objects and surroundings will be rigorously interpreted using approaches and criteria determined by the researchers, but the transcription of these aspects is a simpler process. For example, in our dysmenorrhea vlog study, the setting column of one transcript read “Larger vehicle (SUV/van) with dark seats and sunroof […] wearing a purple team sweatshirt; minimal/no make-up”. The transcriber made note of the space in which the vlogger was filming (“larger vehicle”), the qualities of that space (“with dark seats and sunroof”), and the appearance of the vlogger (“a purple team sweatshirt […] no make-up”).
For analysis, the car setting was eventually coded as conveying that the video had an impromptu, on-the-go feeling to it. The “dark seats and sunroof” illustrates a car which might indicate a higher socioeconomic status. The attire of the vlogger (“sweatshirt”, “no make-up”) further contributed to the casual, informal feeling of the vlog first introduced by the fact that it was filmed in a car. The transcriber followed this description with “[setting the same throughout]” to indicate that the setting did not change for the remainder of the transcribed video. That is, for ease of transcription we recommend only entering changes in setting or scene in the FoCAS (see Figure 3 for an example). Building codes down each column with visual codes synthesized separately from audio during analysis.
Similarly, in the self-care influencer study, the transcriber described one setting as “Bright bedroom, marble look wallpaper on the headboard wall”. The bedroom setting of the video indicates familiarity and sharing private or personal matters. Meanwhile, the marble wallpaper was an aesthetic trend at the time the video was published (Archer, 2022), indicating that the video aligned with such trends of the moment.
Scene
While the setting column captures “what to shoot” (Rose, 2016, p. 73) the scene column captures how images are shot. The scene column is used to document the actions happening on screen, with attention to how the gaze of the camera affects expression. 1 Comparable to the action lines of a screenplay, this column records what the people or things on screen are doing and how the camera conveys this action. The data recorded in this column conveys how the story is being told. Knowledge of terms to describe camera techniques (such as focus, types of shots, pan, tilt, and roll) can be helpful for the transcriber to articulate what they are seeing, and may be helpful for the analyst to be familiar with how these techniques can be used to convey meaning. However, while this knowledge can enrich the transcriber’s descriptive toolkit, it is not a necessary skill, as not all audiovisual content will have been produced with these terms in mind. Many videos shared on social media platforms are not produced by people with background knowledge of film techniques, yet these creators still intentionally express their experiences through these audiovisual productions. With this in mind, we encourage researchers to use the terminology recognizable and most meaningful for them. A transcriber can use the most accessible language available to them to take note of the actions taking place in each shot, such as the “poses, gazes, sincerity, and energy” of the people on screen (Knowles & Cummings, 2023, p. 8), which provide meaningful information about how the creator has decided to tell their story. Such actions will later be analyzed through interpretation to explore their symbolic and tonal significance to the work.
For example, in a transcript from the study on dysmenorrhea vlogs, the first line in the scene column read “Holding the camera-shaky; casual eye contact, speaking casually; adjusting her hair and talking with her hands throughout” (Figure 2). This line lists actions that take place throughout the video. The transcriber noted the positioning of the camera (handheld) and further identified the filming style as “shaky”, then described the actions and movements of the vlogger, who held a casual conversation with the camera. The transcriber additionally noted the use of body language, and that the vlogger was speaking so casually that she was appearing to absentmindedly adjust her hair throughout the video. The transcription illustrates a video that lacks professional polish. The shaky handheld camera creates an improvised, storytime effect, as though she was speaking with a friend on a video call.
In contrast, a line from a scene column in the self-care influencer study reads “Couple is “sleeping/just waking up”, close up shot of her waking up, stretching arms out; Camera changes to full shot of her stretching in bed”. The transcriber records a specific scene that opens the video. A shot of the couple sleeping is followed by a “close up shot” of the influencer waking up, then a jump cut to a “full shot” of her stretching in bed, might indicate that this scene was staged, scripted, and edited for continuity in post-production. This video lacks the authenticity and spontaneity of the previous video, which means it must be interpreted differently. The more polished finish serves a different purpose for the influencer’s relationship with the audience, which can be considered during interpretation.
Audio
The audio column focuses on the video’s dialogue, as with many qualitative researchers’ use of transcribed audio data (e.g., from interviews). Transcription here requires attention to what people say and when they say it. While this section can be transcribed according to the researcher’s preference for interview transcription conventions, we have found orthographic transcription to be the most efficient for our research questions so far. Orthographic, or verbatim transcription focuses on recording spoken words as data (Braun & Clarke, 2013). Words are recorded without punctuation, although sounds such as “erm” and short pauses can be accounted for (Braun & Clarke, 2013). Other transcription styles factor in how the words are being said using more paralinguistic indicators. This conveys more information about how the words were expressed so that the analyst can more closely approximate the speaker’s meaning. However, because this transcription system already accounts for visual data that informs how the words are being spoken, the transcription of dialogue relies less on these indicators, although researchers could incorporate them if they would be helpful for a particular research question (see Sampling Considerations). Video sharing services (such as YouTube) might have transcriptions already available. Although these computer-generated transcripts will need to be edited, they translate well into orthographic transcripts.
Unlike traditional orthographic transcription, the dialogue is not a conversation between multiple people. Therefore, one does not need to identify who is speaking in this column if the speaker has already been identified in the scene column. If there are multiple speakers, however, the speaker of a line can be indicated by an abbreviated name in all capital letters, assigned by the transcriber. The dialogue additionally does not have to begin on a new line.
Transcribers can also use this column to describe non-diegetic dialogue, or how the dialogue contrasts with non-diegetic sounds. For example, background music can be indicated by “[happy music throughout]”, a voiceover can be indicated by “[voiceover]” or “[overdubbed speaking]” before the text, and voice effects can be indicated using asterisks (see Figure 4). Formatting the dialogue column is also different than in a traditional interview transcript. For example, only the parts of the dialogue deemed relevant to the research question need to be transcribed. Any sections of unrelated dialogue (deemed so based on the pre-established sample inclusion and exclusion criteria) can be indicated by “[…unrelated dialogue]” and a jump in the time stamp, which can be seen in Figure 5, or above the dialogue column in Figure 3 to indicate omission of introductory content. There may also be empty lines in the audio column to accommodate longer descriptions of setting and scene. In these situations, time stamps can also have empty lines in between them so that they align with changes in scene, setting, and audio (Figure 4). Spacing of transcription accommodates text in other columns so that overall transcript reflects the order of events. Note. Audio effects, non-speech expressions, and visual transition effects are noted using brackets and asterisks. Speaker changes are indicated by three-letter, capitalized name abbreviations. Omission of “unrelated dialogue” correlated with a 25 second timestamp jump.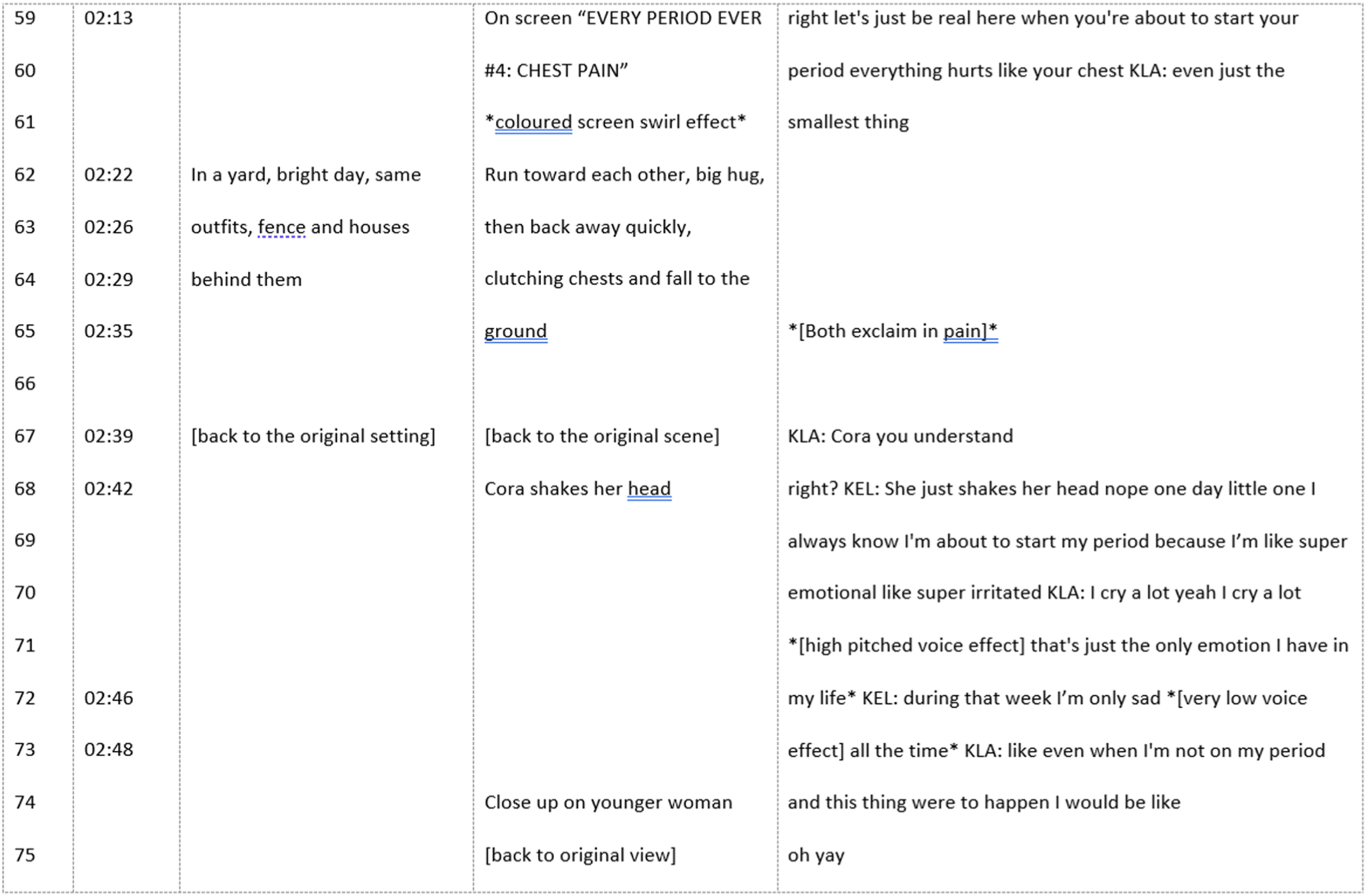

Timestamp
The timestamp column ties the setting, scene, and dialogue together. That is, the timestamps provide an anchor across the three remaining columns. The transcriber should check how each column is aligned by denoting simultaneous occurrence with time stamps. Like the line numbers in a traditional transcript, the timestamps in the “time” column are primarily for ease of reference during analysis and writing stages. However, unlike the line numbers, not every line needs to have a timestamp. While line numbers help the analyst reference the transcript for dialogue data, timestamps help the analyst reference the video for visual data. Timestamps are used where important visual data appears, regardless of whether or not it is accompanied by dialogue. Figure 6 shows timestamps only at 1:08 and 1:22 correlating with the vlogger pointing to her watch and raising her hands above her head, informing the analyst that there are significant actions occurring in the video at these points. Building codes from left to right across the FoCAS columns.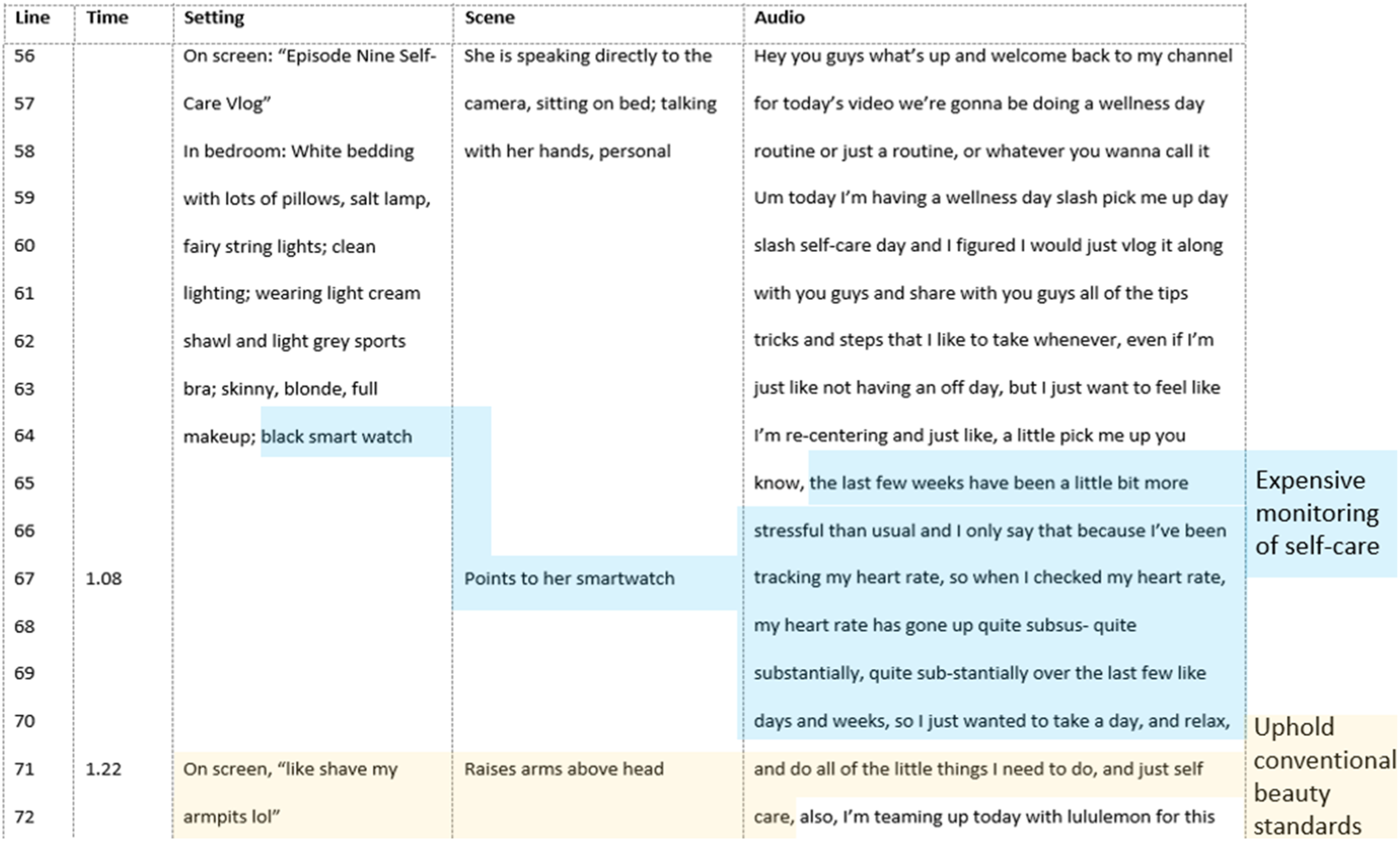
In the FoCAS approach, timestamps are particularly useful when there is a change in the setting or scene to indicate that the visual data has shifted in a dramatic way. Additionally, time stamps can be used to indicate a jump past any sections of the video that are unrelated to the research question and thus not transcribed, such as advertisements. If preferred, timestamps can also be used in place of line numbers; for our dysmenorrhea vlog study, timestamps for every 3 seconds stood in place of line numbers. Ultimately, the basic function of time stamps is to ground the transcript when many things are happening on screen at once, as the simultaneous occurrence of these phenomena will be key to analysis.
Sampling Considerations
A sample of audiovisual content with clearly defined boundaries around its scope and relevance will lend itself to easier transcription. In practice using the FoCAS, we have found four considerations essential for designing the research sample: the scope of available content, length of content, inclusion and exclusion criteria, and relevant audiovisual elements.
Exploring the Scope of Available Content
Depending on the research question and type of media being analyzed, the inclusion and exclusion criteria may need to be developed after a period of exploring “what’s out there”, or what already exists on a given platform and how it relates to the research question. For example, to examine influencers, Knowles and Cummings (2023) used publicly (i.e., widely) available data. They found that a portion of self-care content on YouTube came from mental health professionals, and they subsequently decided to exclude videos from any creators who were mental health professionals, determining they would quite likely provide different recommendations that influencers. Like keywords, hashtags can be useful for this preliminary search. Hashtags are words on social media preceded by a “#,” and a useful search tool for social media. Creators use them to increase engagement by specifying the relevance of their content, meaning that researchers can search for these hashtags when investigating the topic. 2
Ensuring Content Length is Appropriate for Research Question
Length of the data source is another consideration. For example, while considering sampling for the dysmenorrhea vlog project, we found several relevant TikTok hashtags. However, the length of TikTok videos (i.e., 3 minutes max) did not lend themselves to deep analysis needed to answer our research question of how adolescents meaningfully present their experiences with menstruation on social media. We found more appropriate data sets in vlogs, thus limiting the scope of our investigation to vlogs on YouTube.
Clear Criteria for Inclusion and Exclusion
We recommend that researchers carefully consider the inclusion and exclusion criteria for the project before selecting sections of material appropriate for the research question. For example, Knowles and Cummings (2023) wished to examine how YouTube influencers (i.e., “popular social media creators, with differing levels of reach, who engage regular viewers by generating content that is effective at attracting and retaining these viewers” p. 5), portrayed and recommended self-care practices to their viewers. The setting and scene of these videos were determined to lend critical insights to that research question. As such, certain sampling considerations were made. For example, videos chosen were in the vlog style, as commonly used by influencers to show day to day activities. In contrast, a study by Hegel et al. (2022) investigated how adolescents describe their experiences with abusive relationships on YouTube. These researchers chose videos that used a Storytime format (i.e., monologues about a specific life event told as though having a one-on-one conversation with the viewer) because the format was more frequently used for discussion of intimate topics.
Pre-Determining the Relevant Audiovisual Elements
The transcription of the visual material is another layer of consideration that should stem from the research question. That is, the transcriber will want to document the visual aspects that most meaningfully contribute to answering the research question. They will need a clear idea of what dimensions of the visual material they are looking for before they begin transcribing the material. In preparation for this stage, outlining ideas about what aspects of the visual material might be most relevant to the research question, such as lighting changes, color schemes, or facial expressions of characters, can help prevent the transcriber from getting overwhelmed with visual information. In our analysis of parenting vlogs from wildfire evaluations, for example, it has been helpful to note when parents are looking at and speaking to their child(ren) versus the audience/camera.
Additionally, outlining the most potentially relevant dimensions of the data ahead of time and anchoring them in the research question helps ensure the transcriber does not overlook the mundane. If the transcriber is very familiar with the video content (for example, if they have enough personal experience with the content that it feels “normal”), they may become “clouded with the conventions of acquaintance” (Mannay, 2016, p. 28), such that they may overlook elements of the video or dismiss them as uninteresting. However, elements that may be deemed unnoteworthy are still deliberate parts of the picture that contribute to the overall meaning being conveyed. Therefore, to leave them out of the transcription means they get left out of coding and ultimately not considered for the cumulative interpretation. At the same time, it is important to recognize the potential to “drown” in data. Thus, a discerning approach that systematically anchors these decisions in the research question can be an important and clarifying practice.
Examples of Analytical Approaches
In practice using this model, we have successfully used two analytical processes thus far, grounded in reflexive thematic analysis. Thematic analysis is a method for “identifying, analyzing, and reporting” patterns of meaning across qualitative data (Braun & Clarke, 2006, p. 79). Reflexive thematic analysis further signifies our deliberate decision to incorporate reflexivity into the research process by using memos to track our subjective influences over data analysis and interpretation (Birks et al., 2008). In conducting thematic analyses using the four-column transcription method, both studies followed the same six steps, drawn from Braun and Clarke’s (2006) phases: First, we familiarized ourselves with the data by transcribing the videos and/or by reading and re-reading the transcripts, while memoing our initial reactions and ideas. Second, we generated initial codes about the data, highlighting anything that struck us as interesting and relevant to the research question. After generating all codes and reviewing them for relevance, we began searching for themes by collating the codes into potential themes that respond to the research question. Fifth, we reviewed these themes to see if they held consistent with the associated codes and with the data set, then defined and named them. Finally, we reported the themes in written form, relating them back to the literature and research question. Throughout this process, we used memos to exercise reflexivity over our relationship with the data (Birks et al., 2008).
However, both our example studies used reflexive thematic analysis in slightly different ways, further illustrating the flexibility in the FoCAS approach. For example, Knowles and Cummings (2023) coded across the four columns to account for simultaneous occurrences in the transcript (Figure 3). With multiple columns contributing to each code, the generated codes are rigorously informed by the video presenter’s speech, body language, and setting. The final analysis was, therefore, a thematic synthesis of the visual and audio data. This is illustrated in Figure 6.
In contrast, our study of dysmenorrhea vlogs coded and thematically organized the visual and audio data separately, thus giving the story primacy while accounting for its context. The highlights in Figure 3 illustrate how we read down each column to generate codes and synthesized them during later analysis. The visual data was additionally analyzed using compositional interpretation (Rose, 2016), which requires analysts to consider how the composite parts of the work’s visual content and production decisions cumulatively affect the viewer. These composite parts were then translated into codes and thematically organized. In our final report, the visual interpretation enriched the dialogue themes, which laid out the tonal backdrop of dysmenorrhea stories and how vloggers express varying levels of concern using video production.
The FoCAS is flexible enough that, despite vloggers in each dataset using visuals differently, the analysts were able to evaluate and implement the most suitable approach to coding and organizing data.
Strengths and Limitations
We have found the FoCAS helpful in multiple ways. By incorporating the visual elements of our data sources into our analysis of stories, we have more information about how video content creators represent their experiences. The structure is an innovation on older methods designed exclusively for television and film, as it is flexible enough to accommodate social science research methods outside of film studies. The structure can be adapted for multiple research questions, and does not prescribe any particular analytic approach. Indeed, because it is a “structure” rather than a methodology, it allows researchers to use the analytical techniques with which they are most familiar.
While we recommend the FoCAS, we also acknowledge that it has two current limitations. First, the structure requires some more thoughtful consideration of the research question and sampling strategy than traditional social science transcripts. To avoid “drowning in data”, the window of relevance to the research question must be tightly defined before transcription begins, which may take some additional time. The FoCAS is also limited by its testing, as it has not yet been tested with videos or films longer than an hour. Future research with the FoCAS- both by ourselves and others-can further refine the structure.
Conclusion
Qualitative social science researchers who work with modern audiovisual data, such as that obtained from social media content, can benefit from transcription methods that place equal emphasis on both spoken and visual information. Both “traditional” transcription approaches that prioritize verbal data and systems developed for film and television have limitations when applied to social media data. To address these limitations, we developed the Four Column Analysis Structure (FoCAS) to assist us with the simultaneous analysis of audio and visual data. This method transcribes four dimensions: (1) timestamp, (2) setting, (3) scene, and (4) audio. Our method is flexible, can be adapted for a range of research questions, and can be combined with arange of analysis methodologies.
Footnotes
Author’s Note
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.