
Abstract
Labeling or classifying textual data and qualitative evidence is an expensive and consequential challenge. The rigor and consistency behind the construction of these labels ultimately shape research findings and conclusions. A multifaceted methodological conundrum to address this challenge is the need for human reasoning for classification that leads to deeper and more nuanced understandings; however, this same manual human classification comes with the well-documented increase in classification inconsistencies and errors, particularly when dealing with vast amounts of documents and teams of coders. An alternative to human coding consists of machine learning-assisted techniques. These data science and visualization techniques offer tools for data classification that are cost-effective and consistent but are prone to losing participants’ meanings or voices for two main reasons: (a) these classifications typically aggregate all texts configuring each input file (i.e., each interview transcript) into a single topic or code and (b) these words configuring texts are analyzed outside of their original contexts. To address this challenge and analytic conundrum, we present an analytic framework and software tool, that addresses the following question: How to classify vast amounts of qualitative evidence effectively and efficiently without losing context or the original voices of our research participants and while leveraging the nuances that human reasoning bring to the qualitative and mixed methods analytic tables? This framework mirrors the line-by-line coding employed in human/manual code identification but relying on machine learning to classify texts in minutes rather than months. The resulting outputs provide complete transparency of the classification process and aid to recreate the contextualized, original, and unaltered meanings embedded in the input documents, as provided by our participants. We offer access to the database (González Canché, 2022e) and software required (González Canché, 2022a, Mac https://cutt.ly/jc7n3OT, and Windows https://cutt.ly/wc7nNKF) to replicate the analyses. We hope this opportunity to become familiar with the analytic framework and software, may result in expanded access of data science tools to analyze qualitative evidence (see also González Canché 2022b, 2022c, 2022d, for related no-code data science applications to classify and analyze qualitative and textual data dynamically).
Keywords
Introduction
After qualitative evidence has been collected and all textual data from interviews, focus groups, site visits, social media posts, and other sources have been compiled into textual databases, researchers need to label, code, or classify the information to ease comparison and draw shared meanings (Coffey & Atkinson, 1996; Miles & Huberman, 1994). Nonetheless, labeling or classifying textual data and qualitative evidence is an expensive and consequential challenge (Coffey & Atkinson, 1996; Miles & Huberman, 1994); put simply, the rigor and consistency behind the construction of these labels may ultimately shape research findings and conclusions (Belotto, 2018).
A multifaceted methodological conundrum when addressing this challenge is the need for human reasoning for classification that leads to deeper and more nuanced understandings; however, this same manual human classification comes with the well-documented increase in classification inconsistencies and errors, particularly when dealing with vast amounts of documents and teams of coders (Chang et al., 2021; Poth et al., 2021). An alternative to human coding consists of machine learning assisted techniques based on data science and visualization and natural language processing (NLP). These techniques offer quantitative tools for data labeling and classification that are cost-effective and consistent but are prone to losing participants’ meanings or voices for two main reasons: (a) these classifications typically aggregate all texts configuring each input file (i.e., each interview transcript) into a single topic, code, or tag; and (b) the words that configure texts are analyzed outside of their original contexts (Eickhoff & Wieneke, 2018).
From this view, the analytic conundrum and challenge in text classification of big data entails both taking advantage of the consistency in the classification process that is gained with quantitative tools but doing so without altering participants’ inputs, contributions, and experiences and without losing contextual elements of those experiences. Moreover, this efficiency and reliability should not happen at the expense of losing our human reasonings and input, which are fundamental to recovering or rebuilding meanings and to strengthening our understandings.
To address this challenge and analytic conundrum, we present an analytic framework and free software tool that is designed to leverage the power of machine learning, text mining, and advanced text visualization to classify textual data or qualitative evidence while fully leveraging the benefits of human reasoning in both this classification and also during our sense-making processes. From this perspective, the goal of this study is to address How can researchers classify vast amounts of qualitative evidence effectively and efficiently without losing context or the original voices of research participants and while leveraging the nuances that human reasoning bring to qualitative and mixed methods analyses?
Our proposed analytic framework was designed to mirror, as closely as possible, the line-by-line coding employed in human/manual code identification but relying instead on latent Dirichlet allocation, text mining, Markov chain Monte Carlo (MCMC) simulations, Gibbs sampling, and advanced data retrieval and visualization. More importantly, these analytic procedures are conducted via a no-code, cost-free software application (see González Canché, 2022a) that (a) offers a comprehensive set of outputs that provide complete transparency of the classification process and (b) aids in recreating the contextualized, original, and unaltered meanings embedded in the input documents, as provided by participants.
Meaning and Context Preservation
Our emphasis on “original and unaltered meanings” is particularly important for our proposed analytic framework. As briefly mentioned, currently available classification approaches using text mining and machine learning require the analyses of words outside their original context (Eickhoff & Wieneke, 2018). During standard and traditional machine learning text classification processes, these decontextualized words are also normalized (i.e., potentially altered) to facilitate their eventual mathematical handling and statistical classifications. Notably, these classified outputs traditionally do not attempt to retrieve or preserve original texts; instead, the potential meaning loss is treated as a price to be paid for the gain in time efficiency. This implies that text analysts must form their understandings by relying only on these modified and decontextualized resulting classified texts.
Example of Original and Modified Texts.

Types of Textual Data Sources Handled
Our analytic framework, and its corresponding free software application, supports the classification of unstructured data or qualitative evidence in the form of interview transcripts, focus group transcripts, essays, policy briefs, open-ended responses in survey research, and even social media posts.
To illustrate the software capabilities along its suite of outputs, we offer access to a publicly available textual databased consisting of 153 essays as provided by Pahl (2012), that can be accessed at González Canché (2022e). As part of our analytic framework, instead of offering a single classification per each document uploaded, we first decompose each input file (i.e., essay) into dozens, hundreds, or even thousands of texts, and these resulting texts are then ready to be classified. This document-to-text decomposition is important because it makes it possible to retrieve a multiplicity of meanings per input document (i.e., essay) instead of automatically classifying each document into a single topic, which is how traditional machine learning text classifications currently work. 1
As part of this demonstration, we illustrate how this classification process can be completed in minutes, rather than weeks or months. However, we also illustrate that this resulting classification is only the first step of our analytic journey. Once these classes or codes are retrieved, the expertise of the research team is fundamental to bringing these classes or codes “alive” by rebuilding their meaning based on the unaltered and contextualized original voices of research participants.
Purpose of the Study
The purpose of this paper is to showcase all the elements required to address the methodological conundrum of how to rely on machine learning and text classification while minimizing the loss of context and leveraging the nuances that human reasoning brings to the analysis of qualitative evidence. Accordingly, in this study we illustrate all the practical analytic steps guiding our analytic framework and provide a hands-on example, concentrating primarily on the outputs of the analysis and its interpretation, to formally introduce this framework and software tool as Latent Code Identification (LACOID) to IJQM readers.
We offer access to the textual database required (González Canché, 2022e) along with the software tool (González Canché, 2022a, Mac https://cutt.ly/jc7n3OT, and Windows https://cutt.ly/wc7nNKF) required to replicate the analyses presented so that qualitative and mixed methods researchers can experience firsthand the entire analytic process. We hope that this opportunity to become familiar with the analytic framework and free software tool results in its widespread application.
Structure of the Manuscript
In the following section we present a summary of human code identification (HUCOID), understood as the process where human coders are trained to identify codes or classes in qualitative data. We also describe computer-assisted techniques based on data science, machine learning, and NLP that we refer to as machine learning code identification (MACOID). In addition, we describe how we conceptualize the integration of HUCOID and MACOID and how such an integration benefits the entire analytic process. In this respect, given that our proposed framework builds from quantitative and qualitative methods that are integrative rather than competing, we also offer a brief discussion of the epistemological lenses driving this integration, where both approaches are classified as holding a fully mixed equal-status design (Alexander et al., 2019; Fetters, et al., 2013; Jason & Glenwick, 2015; Teddlie & Tashakkori, 2009).
An important contribution of the proposed analytic framework is our goal to reduce or avoid code aggregation bias that consists of classifying large amounts of text under a single code, when such a text may be configured by a myriad of classes or codes. Accordingly, in a subsequent section we present our analytic strategy specifically designed to minimize or avoid this issue. In this study we refrain from overly technical details regarding NLP and topic modeling that can be found elsewhere (see González Canché, 2022b). Instead, we focus on the practical applications of the framework and software and on the relevance of each of its outputs for our meaning-building process.
Human and Machine Learning Code Identifications
In this section we discuss the two approaches that we, as qualitative and mixed methods researchers, have typically employed for classifying text data and qualitative evidence. Note that instead of being specific about strategies or methodologies for qualitative or quantitative coding, we focus on the overall processes in both the manual (human-driven) and machine (computer-driven) code-identification processes.
Human Code Identification (HUCOID)
The predominant approach to addressing this labeling or classification challenge consists of qualitatively, or manually, coding textual data. Although this manual code identification process greatly benefits from humans’ nuanced and contextualized understandings (Poth et al., 2021), it remains a time-consuming and expensive process that is prone to human errors and inconsistencies, particularly when dealing with large-scale qualitative projects (Chang et al., 2021; Poth et al., 2021) and in situations that require the rapid retrieval of understandings of participants’ experiences and actions to make decisions or implement strategies (Ho et al., 2021). 2
Note that although computer-assisted qualitative data analysis (CAQDAS) software such as ATLAS.ti, NVivo, or MAXQDA may ease this human or manual labeling or coding challenge (Humble, 2019; Tesch, 2013), the coding process remains time consuming and labor intensive because both the process and the final product fully depend on researchers’ individual inputs and coding decisions. That is, CAQDAS software is not yet capable of being trained to learn and identify text pieces that may be good candidates for specific codes or labels. From this view, CAQDAS software remains completely dependent on human inputs, which are subject to coding inconsistencies and errors, especially when dealing with vast amounts of documents and teams of coders (Chang et al., 2021; Poth et al., 2021).
A common strategy for minimizing subjectivity and room for interpretation in human code assignment is through intercoder agreement (Belotto, 2018; Eickhoff & Wieneke, 2018; Miles & Huberman, 1994). In this validation process, “team members separately code (a sample of) the given data set [and then] compare and discuss the assigned codes and applied coding rules and recode the data according to the agreed solution… [to] correct for discrepancies in individual judgment, and for joint mistakes that become apparent during analysis” (Eickhoff & Wieneke, 2018, p. 904). From this view, the intercoder agreement test/training may increase coding reliability, but, once more, depending on the scale of the project, the costs in both time and resources may become unaffordable, particularly when dealing with time-sensitive information. Relatedly, despite this training effort, the final product is, once more, still subject to inconsistencies, particularly in this era of big data (González Canché, 2022b).
Machine Learning Code Identification (MACOID)
An alternative yet seldom used analytic approach to tackling this labeling challenge relies on machine- and data science–driven tools involving NLP, text and data mining, machine learning, and topic modeling to identify patterns in unstructured data (Chang et al., 2021; Grün & Hornik, 2011; Ho et al., 2021; Lynam et al., 2020; Poth et al., 2021). These computer- and statistically-powered analytic tools are designed to deal with large-scale textual or written data sources and are capable of classifying vast amounts of textual data or unstructured information faster, better, and more consistently than humans (Chang et al., 2021; Eickhoff & Wieneke, 2018; Janasik et al., 2009; Lynam et al., 2020; Poth et al., 2021) by mathematically learning word-to-text distributions and offering the probabilistically most suitable classification solution based on thousands of learning trials.
In terms of the performance of these quantitative techniques when handling time-sensitive data, a recent special issue of the Journal of Mixed Methods Research (see Fetters & Molina-Azorin, 2021) demonstrated how these computer-assisted techniques helped researchers deal with the deluge of COVID-19 data that needed to be rapidly and rigorously analyzed to strengthen policy development.
Limitations of MACOID
Despite these important contributions of MACOID, this analytic strategy has two main limitations. One is procedural and the other is conceptual and analytical, as we describe next.
Conceptual and Analytical Limitation
The conceptual limitation relates to the analytic conundrum we described in the opening section. This analytic conundrum associated with the use of these techniques assisted by machine learning and data science is that, even though these tools are excellent at applying rules to detect patterns better or more consistently than humans (Chang et al., 2021; Ho et al., 2021; Poth et al., 2021), their main limitation is the “absence of human reasoning around classification” (Poth, 2021, p. 351), which may lead to overlooking nuances and context in the classified texts. From this view, MACOID’s outputs would not convey any social meaning and would remain abstract and nonsensical without human intervention.
To address this limitation, we offer a balanced analytic framework that, after textual data or qualitative evidence is collected, relies first on MACOID as a strategy to consistently apply rules across thousands of decomposed text inputs and then, second, on human input to create or recreate the social meanings embedded in these outputs. From this perspective, rather than treating MACOID and HUCOID as competitive frameworks, our analytic approach integrates them. More specifically, we can express this integration as a purposeful reliance on human reasoning via guided qualitative analyses of the quantitative outputs rendered by MACOID to retrieve the meaningfulness of the original and contextualized pre-processed information.
Procedural Limitation
Despite MACOID’s analytic power and the possibility of applying these computer-assisted tools using open-source, cost-free software (like the R Project for Statistical Computing), it poses a procedural limitation; namely, its use and application remain conditioned on statistical and computer programming expertise. For example, Chang et al. (2021) mentioned that “deep linguistic analysis of text-based research data are still reserved for investigators or research teams with a computer science background” (p. 400). This computer-programming knowledge represents an important hurdle that has prevented qualitative and mixed methods researchers with no training in NLP and computer or statistical programming from leveraging the benefits of machine learning–driven tools to classify textual data.
This study addresses this procedural limitation by completely eliminating computational, technical, and even financial barriers associated with implementing and using MACOID (NLP, machine learning, and text classification and visualization tools) to conduct fully integrative analyses of large-scale textual and qualitative data. To this end, we offer a completely cost-free and computer programming–free rigorous software application 3 that fully implements the mixed methods integrative framework guided by the following epistemological lenses.
Epistemological Lenses
The main premise of our analytic framework is that despite the added accuracy and efficiency of using computer-assisted NLP techniques to identify latent codes, 4 those techniques might fall short in yielding relevant findings and valuable conclusions without qualitative and nuanced understandings of the contextualized meanings of those latent codes based on the original and unaltered textual data. Considering this premise, we consider it important to discuss the epistemological lenses driving the MACOID and HUCOID integrations, a framework we henceforth refer to as latent code identification (LACOID).
Understanding epistemology as the nature, origin, and limits of human knowledge (Stroll & Martinich, 2022), LACOID is guided by the epistemological belief that knowledge can be built from machine learning and text classification analyses of qualitative evidence, but only if this output is fully integrated with the qualitative analysis of this classified, unaltered, and contextualized qualitative information. This implies that the original voices, as expressed by research participants, must be preserved and contextualized in their original document inputs, even including the location of these texts and words within their original and unaltered discourses.
From this perspective, this resulting qualitative analysis may be enriched and contextualized because LACOID was built to never lose the original voices and contexts that give qualitative evidence its meanings and nuances. Empirically, with this context preservation as our priority, participants’ unmodified voices (i.e., original sentences or paragraphs) must preserve their original position in each document uploaded to LACOID thus strengthening the reconstruction of contextualized meanings embedded in those machine-learned latent codes.
Accordingly, LACOID’s epistemology represents a fully mixed, equal-status design, wherein rigorous, valid, and useful knowledge is achieved only by integrating the quantitative analysis of qualitative evidence with the qualitative analysis of the resulting classified codes. This analytic strategy implies that if one of these approaches is conducted poorly, the entirety of the analysis may fall short in (re)constructing the meaning and knowledge embedded in our qualitative evidence.
Moreover, note that although LACOID will always consistently identify latent codes without altering original meanings or texts from input documents, this does not mean that the resulting knowledge would be always useful or informative. If the data-gathering process of these input documents lacks methodological rigor, or if data are collected without internal consistency or validity, LACOID would not be able to fix or solve this data-input quality problem. More to the point, although LACOID’s algorithms do not suffer from bias toward certain groups based on its unsupervised classification nature (which means that the learning process starts without any pre-conceived notions), if the qualitative data do contain these biases (i.e., our participants discourses are themselves biased toward certain groups), the classified results will still reflect these issues, precisely based on the fact that LACOID does not alter meanings or original texts. That is, bringing these two points together, LACOID, by itself, would not know whether the input information holds a certain quality standard or whether this input information is subject to biases. Accordingly, quality assurance and equity issues need the expert and qualitative analysis of the research team because LACOID is not programmed to detect these highly consequential issues. This, once more, reflects the relevance of a fully mixed, equal-status design (Alexander et al., 2019; Fetters, et al., 2013; Jason & Glenwick, 2015; Teddlie & Tashakkori, 2009), where both qualitative and quantitative perspectives are fundamental in the knowledge-building process. (Figure 1). Procedural diagram.
Practical Software Application and Outputs
Figure 2 summarizes the main components of the LACOID analytic framework. The first thread is qualitative and involves collecting qualitative evidence that needs to be transcribed as part of the inquiry process. For the quantitative thread, LACOID was designed to execute the machine learning, text classification, and visualization procedures with a few clicks. Indeed, the whole quantitative process entails the following steps, upon which we expand below (with additional details in the applied example in the “Outputs and Findings” section): 1. Select the type of text decomposition to be applied when uploading documents. Here the options are sentences or paragraphs 2. Upload documents 3. Execute text normalization and cleaning 4. Decide whether to remove or retain common words 5. Select parameters for machine learning. Recommended values are 500 samples to establish baseline parameters (also known as burning samples), and learning process based on 5000 iterations (Raftery & Lewis, 1991); see appendix. 6. Execute metrics assessments 7. Select optimal number of latent codes 8. Execute the classification Main components of the LACOID analytic framework.

 .The text decomposition is automatically applied based on the selection in Step 1.
.The text decomposition is automatically applied based on the selection in Step 1. (i.e., text mining or NLP; see appendix).
(i.e., text mining or NLP; see appendix). .
. to find the optimal number of codes. See appendix and applied example, and Nikita and Chaney (2020) and González Canché (2022b).
to find the optimal number of codes. See appendix and applied example, and Nikita and Chaney (2020) and González Canché (2022b). based on the result of the metrics executed in Step 6. See applied example.
based on the result of the metrics executed in Step 6. See applied example. that will render the Nth number of codes selected in Step 7. See applied example.
that will render the Nth number of codes selected in Step 7. See applied example.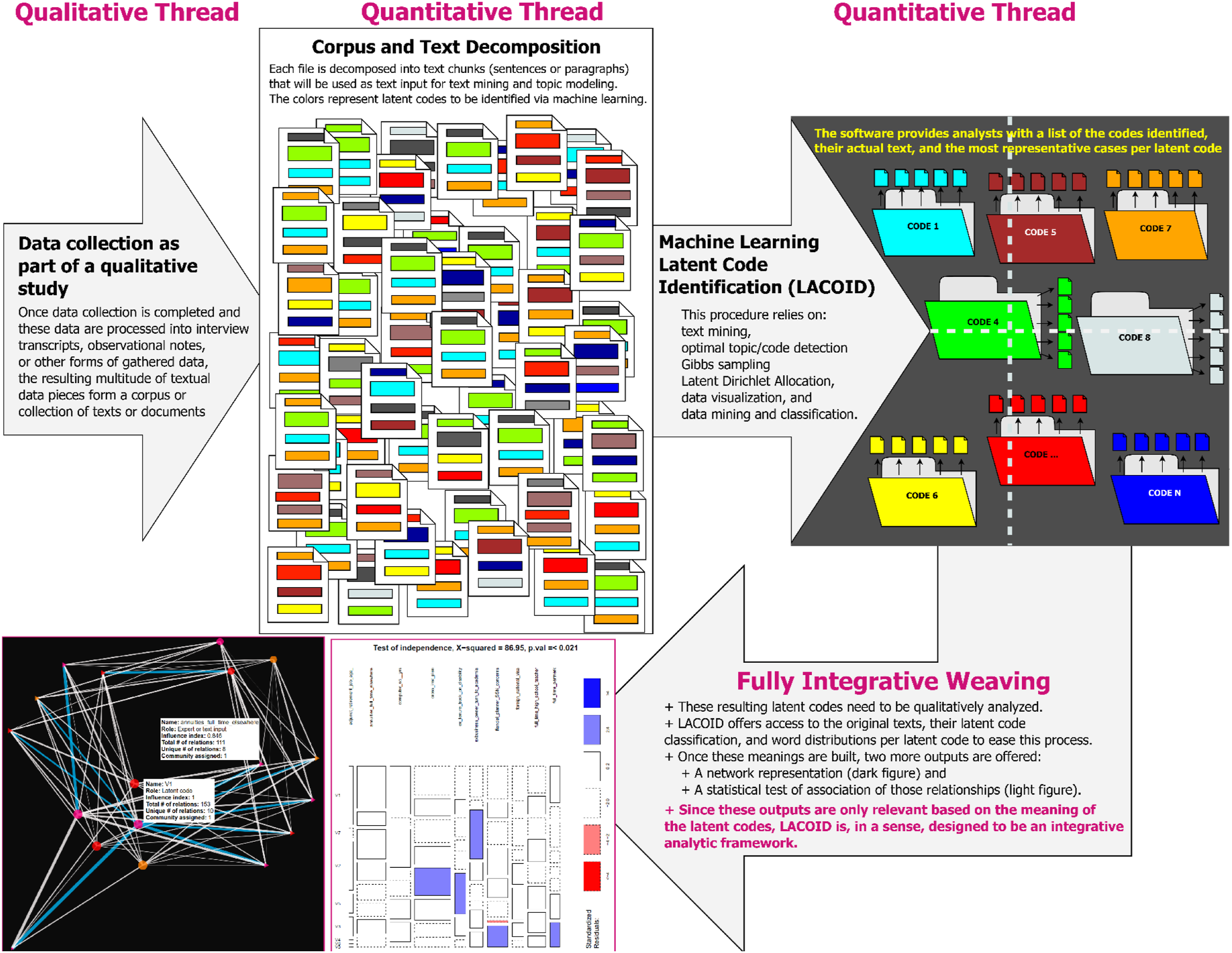
Latent Code Identification Outputs
Before elaborating on these steps, we first want to discuss the set of outputs that LACOID will automatically make available.
After Step 6 is executed, LACOID will generate a plot to ease the detection of the optimal number of codes. Based on this plot, researchers may then proceed to classify the entire textual database, as we illustrate below.
After Step 8 is executed, the following outputs will be generated: • An interactive distribution of the words configuring each latent code • Two databases containing (a) All codes with the original and cleaned texts; and (b) Up to the top 20 most representative texts per each of the latent codes. • A statistical test of group-to-code association (see “Hypothesis Testing of Group and Latent Code Association” section below) • An interactive network visualization of texts and code association and relevance (related to the statistical test) • A database measuring file-to-code strength that may be merged for posterior quantitative modeling.
5
In addition to these outputs, all texts that did not meet an inclusion criteria (by being too vague to convey meaning, as explained below) are also available for download and analyses. This database is added for transparency; it is not necessarily considered an output of LACOID but rather a byproduct of the steps required to conduct LACOID.
Data and Methods
In this section, we briefly describe the data employed in our example along with data preparation steps for hypothesis testing and network visualization that are computed automatically by LACOID based on the resulting classified collection of texts.
Data
The textual dataset analyzed is publicly available. These data correspond to the School Leavers Study (Pahl, 2012), a collection of 154 essays “written by school children from the Isle of Sheppey in 1978… collected as part of a wider ethnographic study” where Pahl “investigat [ed] the changing patterns of work, the division of labour, unemployment, deindustrialisation, and the informal economy” (para. 3). Specifically, participants were asked 10 days before leaving school (most at age 16) “to imagine that they were nearing the end of their life, and that something made them think back to the time when they left school. They were then asked to write an account of their life over the next 30 or 40 years” (para. 4).
Note that these essays are publicly available here https://cutt.ly/8EBKXjm. This collection of files is in rich text format (“.rtf”), but for researchers’ convenience LACOID was designed to handle Microsoft Word (“*.doc” not “*.docx”) files.
6
Accordingly, before uploading these files to LACOID, we made two changes: the first was the transformation from rich text format to “*.doc” Word format. These Word files are available here https://cutt.ly/nENMH6P or here González Canché (2022b) (to use, simply unzip and upload to LACOID). The second change consisted of modifying the file names to allow for group comparisons. Specifically, following the documentation provided by Pahl (2012), here https://cutt.ly/NEBKLKC, and the rationale presented in Figure 3, explained next, we created input file names that capture gender, age, and original essay ID. That is, with the combination of Essay ID 1, Gender male, and Age 16, Hypotheses testing framework and file name change rationale. we created a name file called became boy_sixteen_1.doc. Similarly, when the combination was
we created a name file called became boy_sixteen_1.doc. Similarly, when the combination was  , the resulting file name became “girl_sixteen_90.doc.” Finally, when the combination was
, the resulting file name became “girl_sixteen_90.doc.” Finally, when the combination was  , the file name became “girl_seventeen+_154.doc.”
, the file name became “girl_seventeen+_154.doc.”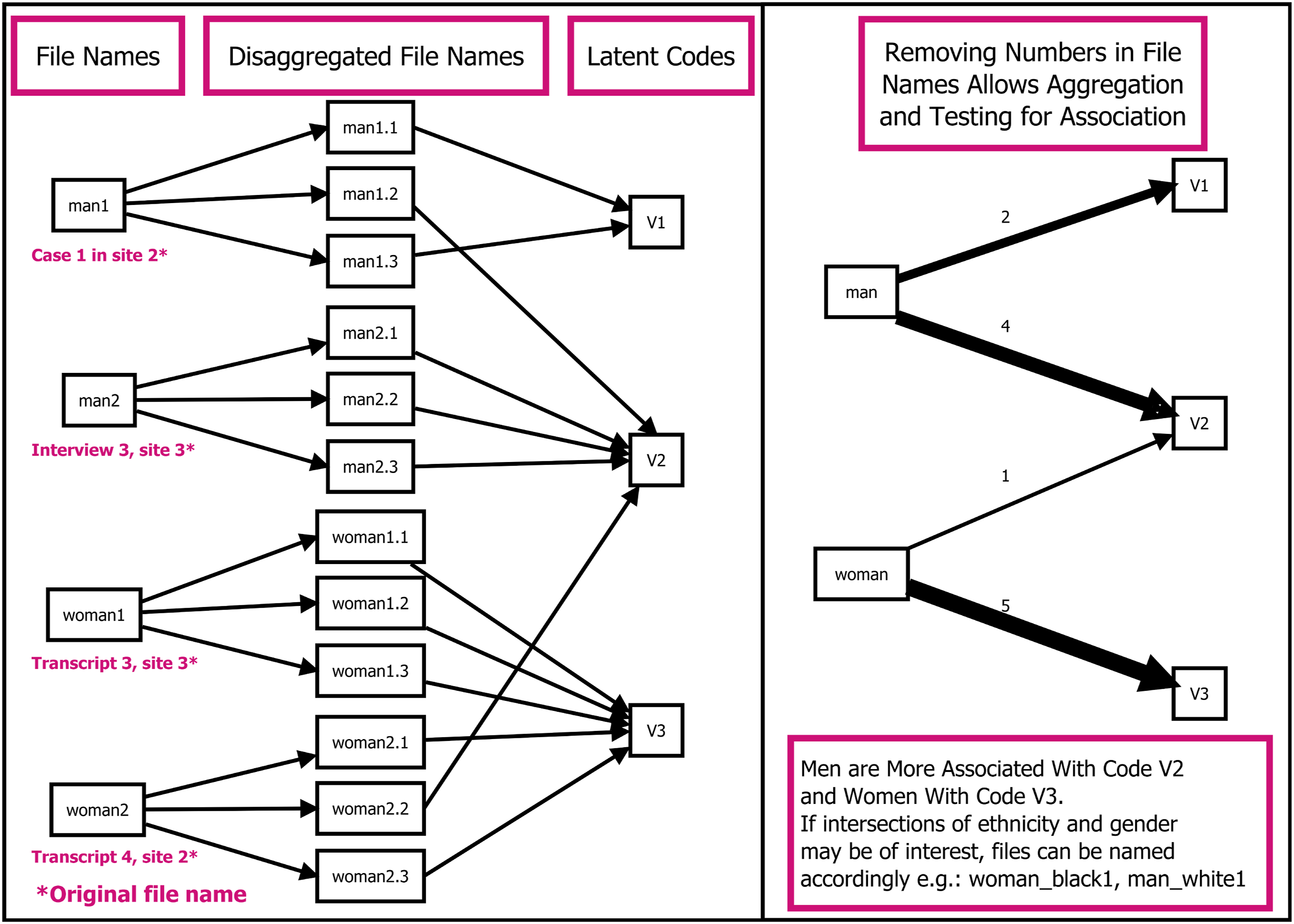
The use of “sixteen” or “seventeen” to account for ages in the file naming process (as opposed to “16” or “17”) is required because LACOID removes numerals from file names in order to group responses and test hypotheses of association. Specifically, as we explain in more detail below, all responses of “boy_sixteen_
With these changes, the resulting groups across the 154 essays made available by Pahl (2012) were distributed as follows: “boy_sixteen_.doc” n = 89, “girl_sixteen_.doc” n = 51, “girl_seventeen+_.doc” n = 13, and “girl_fifteen_.doc” n = 1. Note that of the 154 essays, one respondent was 15 years old. If left in the analytic sample, this single case and its associated latent codes would be considered a single group to be compared against others. Accordingly, we removed this respondent from the analytic sample. Her essay, however, can be read in the file called “girl_fifteen_125.txt” located in the same folder shared above (https://cutt.ly/nENMH6P). Latent Code Identification ignores this file when uploading all Word files given the “*.txt” extension of this document.
Hypothesis Testing of Group and Latent Code Association
Before explaining in more detail the analytic steps described in the “Practical Software Application & Outputs” section above, let us note that the LACOID software was also automatically programmed to conduct a hypothesis test that estimates whether groups of participants (or individual participants) are more or less likely to be associated with certain latent codes. We emphasize the change of file names because this hypothesis test is conducted based on the names of the input documents. Given the relevance of this process for our integrative purpose, we next elaborate on the rationale followed by an explanation of the hypothesis test.
Hypothesis of Group and Latent Code Association
First, let us clarify that if no names are changed, LACOID will test whether certain individual actors are more or less prone to be more associated with some latent codes than with others. This statistical test aligns with the hypothesis generation integration goal (Fetters, 2020) and, by default, tests the relation of all uploaded documents with the identified latent codes. Nonetheless, inspired by Ho et al. (2021), who tested for differences across groups rather than across individuals, if researchers prefer to test whether certain groups are more or less associated with certain latent codes, they can test these hypotheses by following this simple rule: name each file (or Word document) to be uploaded to LACOID based on the group that will be compared in the association tests, followed by a number.
To describe this individual or group test, we turn to Figure 3. This figure contains two panels describing how LACOID handles the input documents. To begin, let us assume that we have four documents (or files) as shown in the left panel of Figure 3; the original names of these files are shown in magenta. If we leave these names unchanged and load them to LACOID, each original file will be decomposed in sentences or paragraphs to avoid latent code aggregation bias (LCAB—as described in its own subsection below). Taking the first file as an example, “Case 1 in site 2” will become “Case 1 in site 2.
In terms of group comparison (right panel of Figure 3), assume that we have identified that Case 1 and Interview 3 are men, and Transcripts 3 and 4 are women. Accordingly, if we wanted to test for differences between men and women in their associations with the latent codes, we could simply name their respective Word files as follows: man1, man2, woman1, and woman2. However, if instead we wanted to make comparisons across sites, note that Case 1 and transcript 4 belong to site 2 and interview 3 and transcript 3 belong to site 3. Accordingly, we could also have named these files as site_two1, site_two2, site_three1, site_three2. This latter naming approach resembles the example we present in our applied section below. Note that in this latter case, although we are still capturing the site number, we used words to capture this number, rather than numbers. This is based on LACOID’s need to remove numerals to create group comparisons. That is, if we named our files site_2.1, site_2.2, site_3.1, site_3.2, when LACOID removes numerals, we would retain one single group called
For the sake of clarity, let us note that LACOID was programmed to add another numeral to each decomposed text chunk (in both the sentence and paragraph decompositions) to identify each classified text’s location in its original file and ease the retrieval of context for our participants’ meanings (see our explanation associated with Table 1 below). For example, the text associated with “woman2.2” in Figure 3 indicates that this is the second text chunk (i.e., sentence or paragraph) for the file input named “woman2.” Furthermore, recall that as part of LACOID, and as depicted in the left side of Figure 3, each of these decomposed texts are to be assigned to a given latent code (represented by V1, V2 and V3 in Figure 3). In following with our woman2 example, Figure 3 indicates that one of her texts (woman2.2) was identified as belonging to the latent Code V2 and the other two texts were classified as V3.
Programatically, LACOID removes all numerals in the “
In sum, when the original Word documents names are changed, as depicted in Figure 3, this test of independence will assess whether some groups are more likely to be ascribed to a given latent code or set of latent codes than other groups. However, if no text names are changed based on group ascription (i.e., man vs. woman), then the resulting test of independence will be conducted at the individual-file level (based on the original Word document that was uploaded). That is, when no document names are changed to assess group analyses, then the number of comparisons is based on the number of documents uploaded rather than on the potential groups of interest. Finally, as depicted in Figure 3, the intersection of two or more attributes at the document-name level can also be added to include, for example, the intersection of gender and ethnicity, following the same rationale (e.g., woman_black1, woman_black2, …, man_white3) or site of interest like “man_site_three1” or “woman_site_two1” to conduct even more aggregated analyses. As stated above, in our application example we tested whether the intersection of gender and age yielded significant results.
Network Representation of Group and Latent Code Association
Regardless of whether we change file names to represent groups or if individual documents with latent code associations are captured, the relationships tested via Chi-squared tests are automatically plotted in a sociogram or network representation. Specifically, as shown in the bottom left section of Figure 2, participants’ or groups’ decomposed texts may be heterogeneously distributed across the collection of latent codes identified. The network presentation (shown at the bottom left section of Figure 2 and in Figure 7) also highlights the strongest connection of participants’ or groups’ texts with a given latent code (with a blue line/link, as opposed to white). Moreover, in the interactive HTML network rendering (see Figure 7 and its interactive version here https://cutt.ly/nE96btS), when researchers click on a latent code or actor (or group, as explained in the next paragraph), an information box will show how many text chunks this actor or group contributed to the analysis and how many unique connections each actor/group and latent code have. For example, if there were 10 latent codes identified, and a given actor or group has five unique relations, this indicates that this actor or group did not provide text chunks that were classified in half of the latent codes. In the case of latent codes, when clicking on a given latent code in this HTML representation, the resulting information box will show how many actors contributed text chunks that were classified under that latent code. That is, if there were 20 unique actors and a given latent code had 19 unique connections, this would mean that one of the actors did not provide any text chunk that was classified in that latent code. 7
In sum, both the hypothesis test and this network representation aim to showcase how individuals or groups may be heterogeneously associated with the resulting latent codes. Since the input associations are based on original documents that were decomposed into sentences or paragraphs with the resulting latent codes, it is worth elaborating on the meaning of document decomposition and its role in avoiding LCAB.
Text Decomposition as a Strategy to Avoid Latent Code Aggregation Bias (LCAB)
Conceptually, the color schemes represented in the “Corpus and Text Decomposition” section of the process in Figure 2 indicate that a single document is configured by a collection of latent codes rather than representing a single latent topic. This multiplicity of latent codes configuring each individual document is perhaps the biggest departure of LACOID from similar approaches that rely on topic modeling (see Eickhoff & Wieneke, 2018; Lynam et al., 2020). For example, Eickhoff and Wieneke (2018) applied topic modeling to 7356 research articles spanning 40 years, allowing each full article to be ascribed to just a single latent topic. Because this “one complete file to one latent code” approach may lead to loss of meaning, or a form of aggregation bias, LACOID first decomposes each input file or document into its more granular textual components, at the sentence or paragraph levels, without losing the original location of these components in their original file (see Figures 2 and 3, for example) and then applies the machine learning and text classification algorithms to identify the distribution of latent codes within a document. Given the salience of this process to avoid LCAB, the following subsection discusses this text decomposition.
Line-By-Line Coding Goal
Latent Code Identification aims to resemble as closely as possible the line-by-line HUCOID processes (Charmaz, 2014, in Poth et al., 2021) while relying on NLP and machine learning tools. In qualitative or manual analytic processes for identifying codes, a single participant’s response to an interview question or a single paragraph in an essay or document, for example, is configured by sentences that may be coded into similar or different codes or labels (see Saldaña, 2013). In the following example, Saldaña (2013, p. 5) shows that a one-paragraph essay is configured by five codes, with each code accounting for a unique sentence:

Although not every sentence in a document is to be strongly identified with a code (see our explanation of most representative texts in Figure 6 and an explanation of this process in Table 2), if no purposeful text decomposition is implemented, the multiplicity of meanings configuring full documents will be aggregated into a single topic, which may lead to the loss of these multiple meanings due to aggregation—or LCAB. On the other hand, following Saldaña’s (2013) example, along with our additional analyses of previously manually coded texts in our own work and the work of some of our colleagues, it follows that when full documents are decomposed before being subjected to NLP (involving text cleaning, mining, and topic modeling) the possibility of LCAB will be minimized or even completely avoided. In line with this analytic goal, LACOID offers researchers the option of decomposing their documents at either the sentence or paragraph level.
Document-to-Sentence Decomposition
Sentence-level decomposition follows the line-by-line HUCOID rationale and decomposes all documents into their configuring sentences; each sentence then becomes a valid text input to be classified via LACOID. This text decomposition is clear, methodical, and objective. From machine-learning and text-classification perspectives, not only would this approach minimize or avoid LCAB but it would also increase the statistical power across Gibbs sampling and MCMC iterations (see the online appendix) by adding more text inputs to the machine learning process—resulting in big textual data (i.e., thousands of text inputs). Additionally, the LACOID end product will still group sentences conveying similar or strongly related meanings into the same latent codes, and this may even help detect potential plagiarism issues—see our discussion of the discovery of an identical sentence in our findings section.
One potential challenge of this approach, however, is that this nuanced text delimitation is more computationally expensive; that is, a single interview transcript may become hundreds or thousands of LACOID text inputs, and to the extent that more documents are uploaded, the resulting text inputs may reach tens or hundreds of thousands.
Sentence-Length-Inclusion Threshold
A related challenge is that despite increasing the sample size by including more text inputs, decomposing a document to sentences increases the chance that a proportion of these sentences may not be linguistically meaningful. Accordingly, a strategy to trim text that may not be useful in capturing meaningful pieces of information 8 —and in doing so reducing the computer power required to implement LACOID—consists of applying a sentence-length-inclusion threshold.
In this respect, linguists (see Cutts, 2009; Myhill, 2008) have recommended that the appropriate length of words per complete and clear sentences in the English language is 18.2 words on average, with a typical range of 9.71–28.15 words (Myhill, 2008). Similarly, Cutts (2009) recommended that, for plain English documents, the average sentence range be 15 to 20 words. Based on this information, to be conservative and minimize the risk of dropping meaningful sentences, LACOID was programmed to retain original sentences with at least 10 words by default, or the lower range found by Myhill (2008).
9
Note that this threshold includes stop words (words that by themselves convey no meaning as describe below); this means that although our threshold consists of original sentences with at least 10 words, our actual LACOID analyses may include text chunk inputs with fewer than 10 words. To illustrate what we mean, consider the following 13-word sentence, which meets the inclusion criterion: “Keep the average sentence length of your document around 20 to 25 words.”
After applying standard text-cleaning preparation techniques, such as transforming words to lowercase and removing stop words (see Text Mining” below), the original sentence to be included as a text input in LACOID becomes: “keep average sentence length document around 20 25 words”
From this example, the “cleaned” sentence included in the LACOID analysis contains nine words. Based on our threshold and also based on tens of thousands of sentences we employed to test LACOID, in no instance did the cleaning process retain single-word sentences. This latter point is noteworthy because text input word variation is relevant for topic modeling, given that this process assesses both the probability distributions of words configuring a text to a given latent code and the probability distributions of texts to latent codes throughout thousands of iterations in the machine learning process (Griffiths & Steyvers, 2004).
Finally, in the pursuit of complete transparency, LACOID allows researchers to download a database with all the excluded sentences (those with original sentence lengths of fewer than 10 words, as shown in the applied section below) along with their file name and their position (sentence number) in the original documents. This database is automatically generated after all input files have been uploaded, and it can be accessed by saving it to a local hard drive. For details, see the “Data Upload and Text Decomposition” section below.
Document-to-Paragraph Decomposition
The second type of text decomposition supported by LACOID requires a more conscious and strategic delimitation process by researchers. In this case, researchers may pre-process their documents to “manually” prepare the text inputs. That is, researchers may go over their transcripts and decide that a 10-page document, for example, contains 50 text chunks (which can be paragraphs or simply text blocks delimited by a blank line) to be classified into a given number of codes based on NLP, and then feed this document to LACOID. They may replicate this process with all their documents before uploading them to LACOID. To be clear, in this instance, researchers simply need to separate any meaningful text chunk they have identified with a blank line before uploading it to LACOID. Once uploaded, LACOID will automatically decompose each file into n text chunks as pre-delimited by researchers.
Returning to the 10-page example, if 50 text chunks are provided in a given document, LACOID assesses the optimal number of latent codes to be identified for these 50 text inputs, which is an integrative exercise in and of itself. That is, researchers strategically pre-delimit text chunks as texts inputs, and then LACOID identifies their latent codes. Just as with the sentence delimitation, this process also assesses text length and removes text chunks that do not meet the minimum word threshold discussed above. Note that, also based on hundreds of documents delimited by blank lines that we have used to test LACOID, in no instance was a text chunk removed due to failing to meet the 10-word minimum length threshold.
Although LACOID’s paragraph decomposition process is straightforward, the possibility of LCAB is again present because there is a nonzero chance that text chunks potentially accounting for more than one latent code will be aggregated into a single latent code. 10 Relatedly, researchers’ decision processes when delimiting these texts may potentially be affected by inconsistencies in text delimitation—that is, this delimitation process requires applying decision rules, which may be challenging when dealing with a large collection of texts or teams of text delimitators. On a positive note, paragraph delimitation is less computationally expensive and, to the extent that the delimitation process is rigorous and consistent, the remaining integration process may be even more straightforward given researchers’ familiarity with the text based on the pre-delimitation exercise. Having said this, the default selection that LACOID implements is sentence decomposition, but researchers may update this choice with a single click in LACOID’s user interface. 11
Meaning Retrieval Post-LACOID
Given that machine learning requires the analyses of words outside their original context (Eickhoff & Wieneke, 2018), this learning and classification process per se is useless in preserving the richness of the original and contextualized written data or information. To address this limitation, LACOID provides researchers with tools to describe the resulting codes as a function of their word frequencies (descriptive meanings, as suggested by Miles and Huberman, 1994), as shown in Figure 5, and to decipher or rebuild their deeper meanings based on their original contexts (or even their inferential meanings, as also suggested by Miles and Huberman), as shown in Figure 6.
Regarding the descriptive meanings (Miles & Huberman, 1994), LACOID provides a descriptive tool to quantify word frequency distributions per code (Figure 5). Conceptually, in addition to serving as a descriptive tool, the distance of codes represented in the dark box quadrant plane in Figure 2 (top right) also captures how similar (i.e., based on smaller distances) or dissimilar these latent codes are. Specifically, the top right section in Figure 2, represented with folders, shows a quadrant plane separated with dotted lines. In this representation, codes that are within the same quadrant (i.e., intraquadrant) have textual content that is more similar than codes located in different quadrants. That is, Code 5 is more similar to Code 7 than to Codes 1 or 6. Similarly, Code 4 is more neutral in its content given its central location, which implies that its respective textual content shares information with codes located in other quadrants. More details are discussed in our applied example (see “Outputs and Findings”). To access the interactive LACOID output, follow this link https://cutt.ly/XE9ZV71 or see Figure 5.
With the goal of deciphering or rebuilding deeper, unaltered meanings, LACOID was programmed to provide automatic access to the cleaned and normalized text chunks that were classified by LACOID as well as to the original sentences or paragraphs that contain the exact words provided by the research participants. For example, in building from our sentence length example discussed above, our output may not alter meanings or original texts following this rationale. Assume that the first sentence in our first input document is “Keep the average sentence length of your document around 20 to 25 words.” Assume also that this file is called doc1.doc. If we chose to decompose this file into sentences, the ID of this first sentence would be doc1.doc.
The information in Table 1 allows us to identify the file of origin (doc1.doc1 with the number “1” indicating that this sentence is the first in that document), the position of the text or sentence in that document (doc1.doc
 (see Figure 6 and Table 2).
(see Figure 6 and Table 2).Example of Classification Process and Text to Code Contribution and Group Fit.

aDivided by the highest probability within that code.
bAverage contribution of group divided by highest contribution by group.
Outputs and Findings
This procedural section showcases how to execute LACOID and discusses the outputs for analyses and integration.
Data Upload and Text Decomposition
In Steps 1 and 2 of the LACOID execution process, we uploaded 153 essays that were decomposed in 3222 sentences with a minimum length of 10 words. Of these 3222 sentences, 768 had fewer than 10 words and were thus excluded. Latent Code Identification allows users to download a dataset containing these excluded cases for exploration. Specifically, this dataset file includes two columns: “doc_id” and “text”. The former matches the name of the original uploaded file. The last number in “doc_id” includes the location of the text in that file. In the example below, for the file “boy_sixteen_1.doc” the first sentence, or “text,” was “Reflections.” Because this text is shorter than 10 words, it was excluded. Latent Code Identification identifies empty lines with a “.” as in the case of the text “boy_sixteen_2.doc.1” that had an empty line before this participant started his essay with the text “Reflection.” 12

Text Mining

Step 3 of the LACOID execution process consists of text data cleaning and normalization following the text mining procedures discussed in the appendix. During this process, some texts may be dropped due to being too infrequent in the document-term matrix (see appendix) to meaningfully contribute to classification. In our analyses, 27 sentences were excluded, but for the sake of space, we present only four of them in the figure shown next.
The words configuring these texts are outliers (and hence removed from LACOID) because they appear in less than 2% of all other texts (based on the sparsity level of 98%). These texts can also be found in their original documents based on their Text IDs. Finally, this output also shows the 10 most frequent words. Some words may be too common to be useful in the classification (i.e., essays on COVID-19 having as a frequent word “COVID”) and can be excluded from the analyses (Schütze et al., 2008). We did not face this problem and thus did not remove any words—see also Figure 9 and 10 as shown in González Canché (2022c). To remove words, simply identify them by their position. For example, to remove the words “school” and “first,” which are in the sixth and 10th positions, respectively, type “6, 10” in the box corresponding to Step 4 (without quotations but with the comma separator) and click “Trim Common Words.” To reinstate words after they have been removed, simply execute Step 3 again; there is no need to reupload the data in Step 2.
Metrics Assessment
Step 5 includes the burn-in and MCMC/Gibbs sampling with default recommended values of 500 and 5,000, respectively (Raftery & Lewis, 1991). This step renders a plot (Figure 4) with all four metrics at once to select the optimal number of topics, ranging from 2 to 60 latent codes. Metrics assessment signaling two feasible solutions (circles added by research team).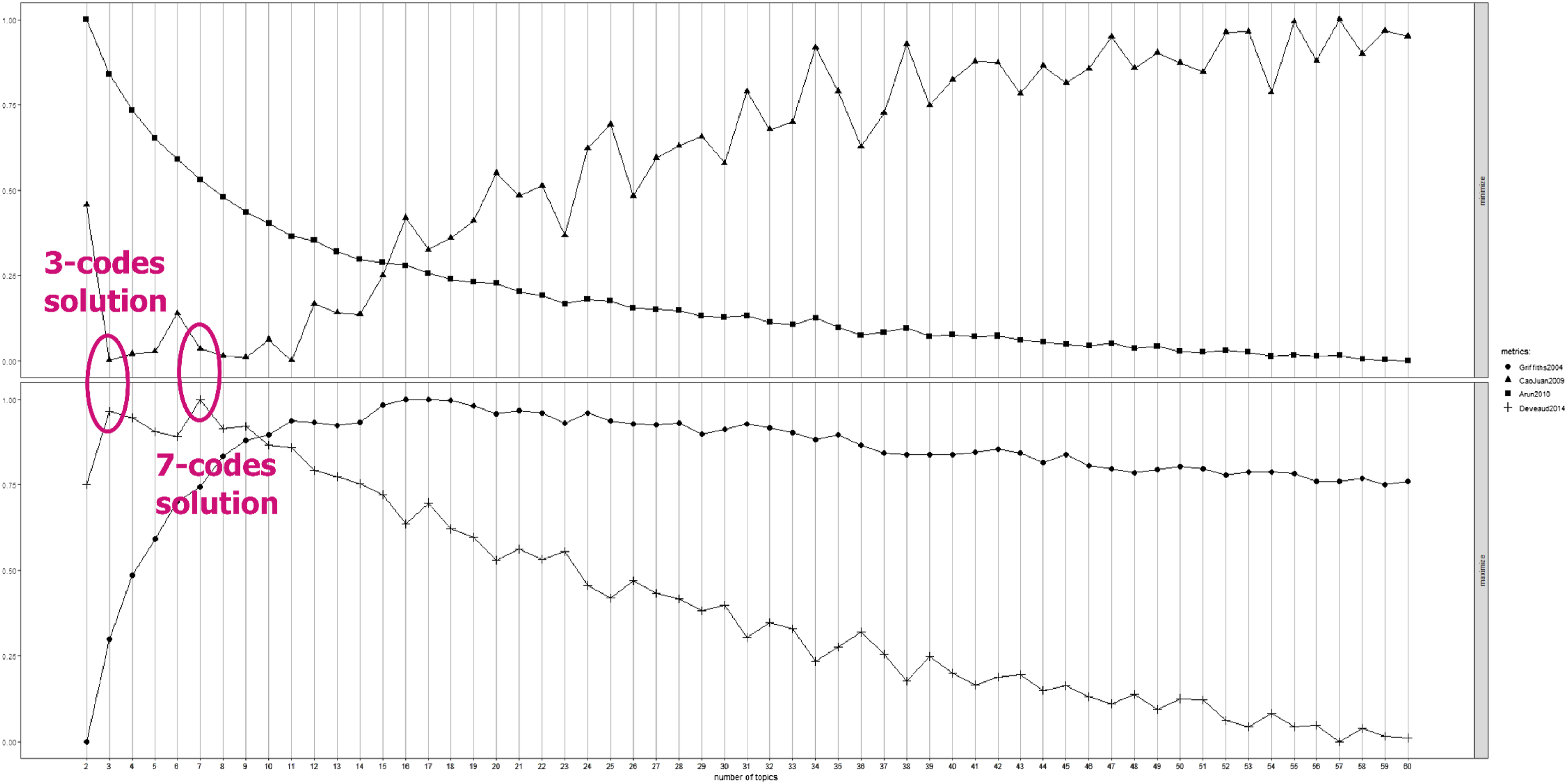
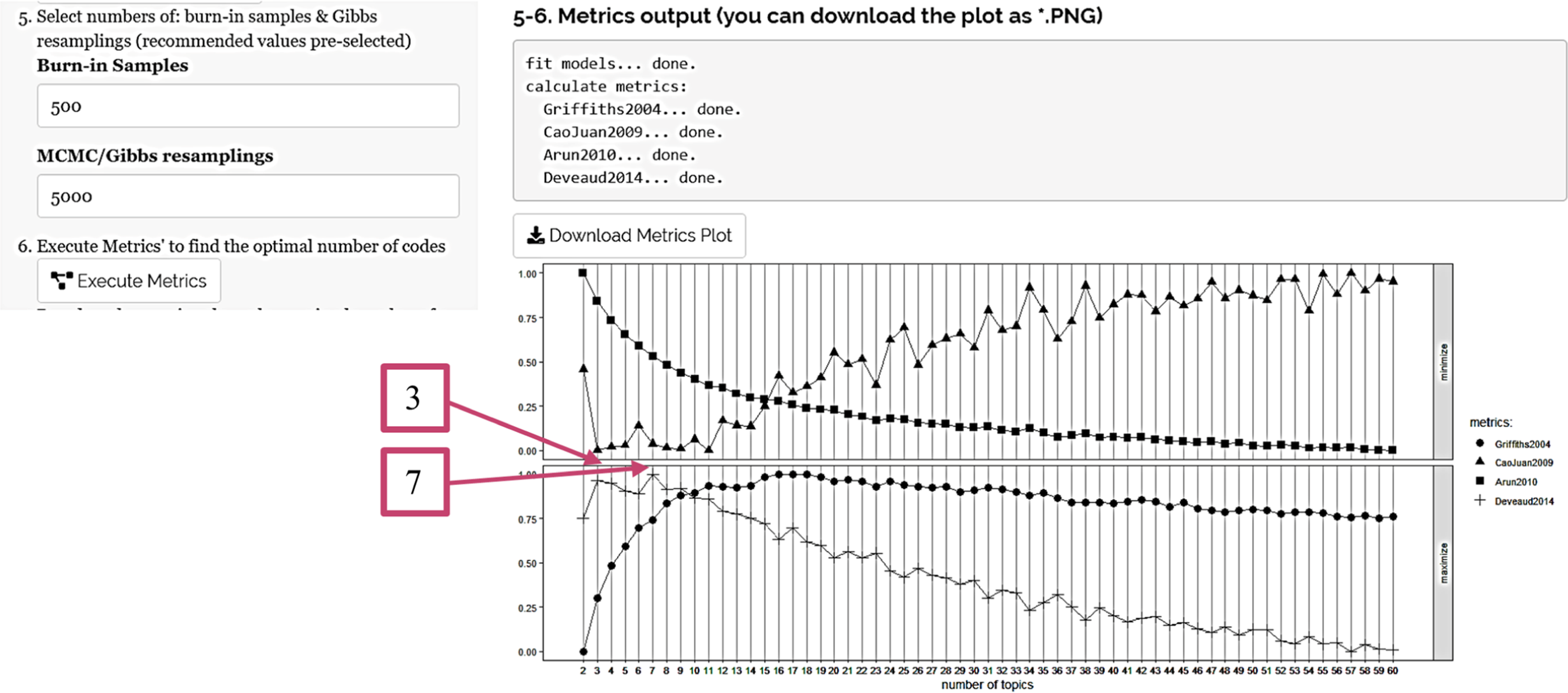
The plot indicates that across 5000 iterations, there are two candidates—three and seven—for the optimal number of codes based on dissimilarity (Deveaud et al., 2014) and low correlation (Cao et al., 2009); because there is more than one candidate optimal number of codes, further assessment about pros and cons of these candidacies is depicted next.
Latent Code Identification Execution and Selecting the Optimal Number of Codes
To further evaluate the optimal number of codes, we executed LACOID twice, first with three codes in Step 7 and then with seven codes. The results indicate that using three codes (available here https://cutt.ly/XE9ZV71) renders the most differentiable latent codes (see Figure 5). Codes 3 and 2 are located in the two lower quadrants, and Code 1 is in the upper quadrant. When we ran LACOID with seven codes (available here https://cutt.ly/aE9ZLSb), Code 6 fell in the center of the quadrants, meaning that its content was shared among the other codes. Interactive summary of text to code distributions in the three-codes solution (interactive version here https://cutt.ly/XE9ZV71).

To aid with the meaning-building process, the interactive plots automatically generated by LACOID dynamically update the word frequencies in two ways: by clicking on a code (Codes 3 and 7 were selected in the plots above—not to be confused with the three-code and seven-code solutions) and by clicking on a word. For example, in the graphs shown below, the word “child” was clicked; the disappearance of all remaining latent codes indicates that only Codes 3 and 7 contain this word in their corresponding texts. As further discussed below, these codes capture meanings related to starting a family, having kids, and being married.
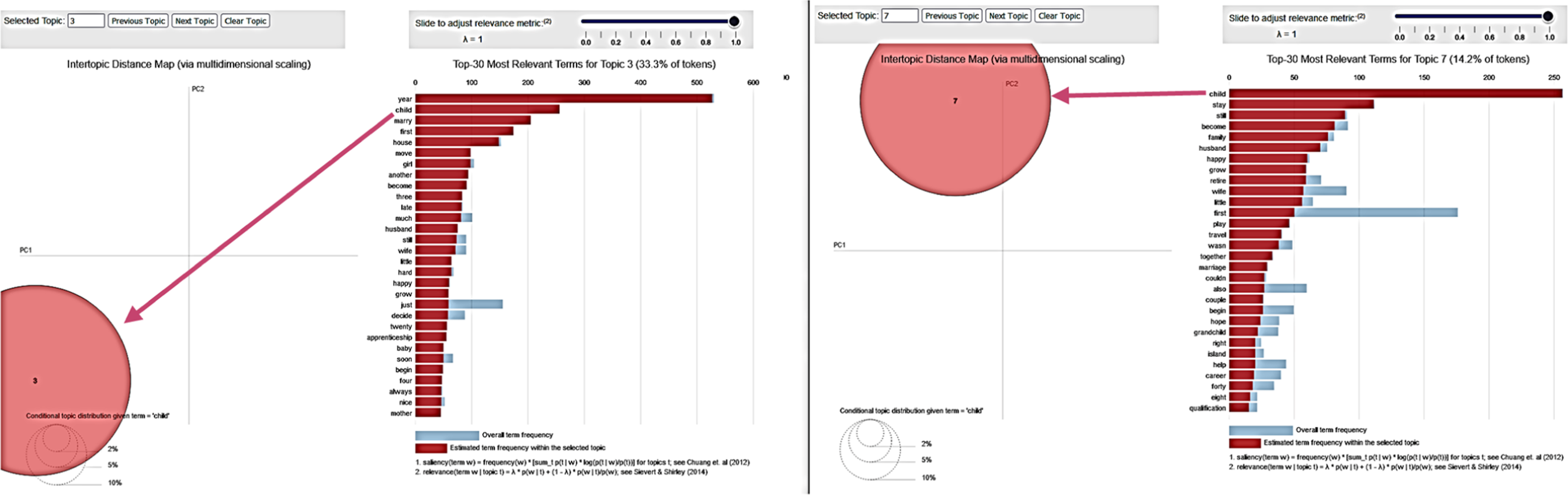
Although this analysis is useful, in cases where there is no consensus regarding the optimal number of codes, like in this study, choosing the final number of latent codes should not be based exclusively on analyzing these plots. Instead, a deeper analysis of their most representative texts should be conducted. Due to space limitations, we cannot show the entirety of this process, but quite similar to our analyses shown next (i.e., after a careful analysis of the original texts associated with each solution), and also by noting the clear lack of latent code overlap in the plot quadrant rendered by the three-code solution, we selected this three-code option to conduct our integrative analysis.
Meaning-Building and Meaning-Retrieval Processes
A closer inspection of the interactive three-code solution (see Figure 5 or https://cutt.ly/XE9ZV71) indicates that the following descriptions were primarily or uniquely representative of each code:
LACOID was designed to strengthen these understandings—retrieved from code-to-word distributions—by making it easy to retrieve and analyze the most representative texts per code. As can be seen in the graph below, researchers have the option to download the fully classified dataset or the dataset containing the 20 (or fewer) most representative original texts per code. These databases also include the text inputs that were used in the actual topic modeling (normalized and text mined/cleaned words) in case these actual text inputs help with understanding the latent code meanings. In our analyses, we present the three most representative texts per code.
The “relative text contribution” column in this table (and in Figure 6 and Table 2) identifies texts that best capture the meaning of each latent code. The “relative group fit” column measures the extent to which the texts configuring each latent code coherently or exclusively represent that code. We programmed LACOID so that both measures have a maximum value of 1—see González Canché (2022c) for a more technical explanation of these measures. Main LACOID output showing most representative texts, relative Text contribution, relative group fit, original/unaltered Text, and text-mined Text.
Following González Canché (2022c), let us elaborate on the process LACOID follows to identify text to code relevance. For convenience, note that we are only including three texts and that the results obtained from the metrics assessment indicated that a two-code solution is associated with the most optimal classification outcome.
The texts contained in Table 2 show that the first response is clearly aligned with a career focused standpoint for this participant mentioned “My career is the most important aspect of my life.” The columns called “Code 1” and “Code 2” represent the two-code solution. Note that LACOID’s output does not include these two columns, instead it shows a column called “code” (see Figure 6) that identifies the resulting classification of each text (shown as LACOID Result in Table 2) based on the following rationale. Each text is given a probabilistic value of representing each of the optimal codes selected in the metrics assessment (see Table 2 under columns “Code 1” and “Code 2”). Accordingly, assuming a two-code solution in Table 2, this translates into the following scenario: although the first text was classified as Code 1, in reality, after thousands of iterations in the learning process, its probability of being associated with this code given its words configuration was 90%, with the remaining 10% being associated with the second code. That is, this text had a 10% chance of representing Code 2 as well. 13 In the case of the second open-ended response or text, which is clearly more ambiguous for it reads “My family is as or more important than my career” these probability distributions were 45% and 55% of being classified in Code 1 and Code 2, respectively. Finally, the third sentence that reads “For me, the best day is a family day not an office day” had an 80% probability of being representative of Code 2. Taking all this information into account, we then know that, although the second response was more ambiguous than response 3, and this second sentence was also close to being classified as Code 1, it was classified under Code 2 given its higher probability value (i.e., 55% VS 45%). In this respect, note that topic modeling does not traditionally offer a measure of how strong the texts to codes associations are. That is, although our example clearly shows that texts 1 and 3 are more strongly associated with Codes 1 and 2, respectively, than text 2 is with Code 2, topic modeling would not provide this information as part of standard outputs. To address this limitation typical of topic modeling, LACOID’s main outputs (both in the fully classified dataset and the dataset with the most representative responses) offer two measures to assess text to code strength and detect the most representative texts per code.
In the LACOID output shown in Figure 6, The columns that allow the identification of text representativeness are “Text Contribution” and “Group Fit.” The text contribution is populated by dividing the probability of each text to be classified in the code where such a text was actually classified over the maximum probability of a text being classified in that same code. That is, taking text 2 in Table 2, for example, we have that the maximum estimated probability of a text being classified under Code 2 was 80% (text 3); however, the probability of this text 2 to be classified in Code 2 was 55%. Accordingly, the text contribution or representativeness of text 2 for Code 2 is the result of dividing
The second assessment is group fit. This assessment takes the average probability values obtained by each code given the probability of their configuring texts to being classified in such a code and then divides the resulting code average probabilities by the maximum average value observed across all codes. Specifically, in the case of Code 2, this average value is estimated from .55 and .80 (the probabilities of its configuring texts 2 and 3 to be classified in Code 2). This average value is .675. In the case of Code 1, this average value is .90. Since .90 is the maximum average value observed across all codes, Code 1 will have the maximum group fit for its average is divided by the maximum average across codes. In the case of Code 2, its average is divided by the maximum code group average (or
In a sense then, these two fit measures allow us to assess individual text to code contribution while also estimating how consistently were these texts to being classified under their corresponding codes. Since these fit measures are a function of the optimal code number identified with the metrics assessments, all LACOID steps are interconnected across the entire classification process.
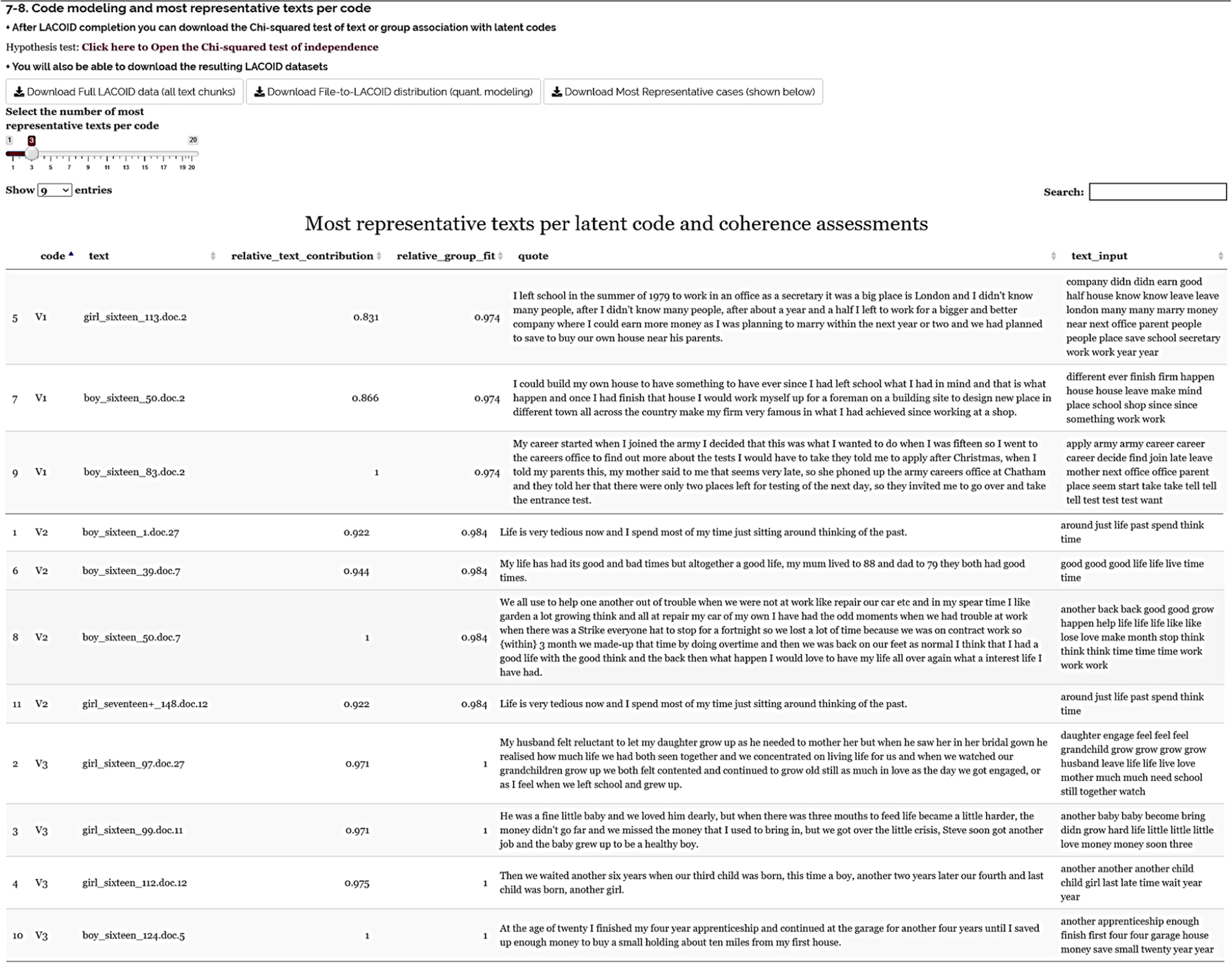
With this explanation in mind, each latent code will then have at least one text with the highest value, whereas there will be only one latent code with a value of 1. In the figure above, for example, the third code has the highest relative group fit, and within each code, there is one text that best captures the latent meaning of each code.
In the case of Code 1, the text “boy_sixteen_83.doc.2” is its most representative text. Congruent with our previous descriptive analysis, this text captures the start of a career in the army. The “cleaned” version under the column text input shows that this actor used “career” three times—hence measuring word frequency per text. The other two most representative texts also mention leaving school and starting to work. Accordingly, we named this latent code
In the case of Code 2, its most representative text was provided by “boy_sixteen_50.doc.7,” and this text captures thinking about past good times and things they used to do. The second most representative text (boy_sixteen_39.doc.7) describes when his father and mother died and how they “had good times.” The third most representative text appeared twice in the essays (the implications of this duplication are discussed below). This content corresponded to “boy_sixteen_1.doc.27” and “girl_seventeen+_148.doc.12” and indicated that their lives are tedious, and they constantly remember the past. Based on this content, we are naming this code
The analytic power of text mining, sentence decomposition, and LACOID are demonstrated with the identification of this duplicate case, which resulted in the same “relative_text_contribution” value (0.922) and prompted us to go back to the original essay files (as downloaded from the original study) to corroborate that LACOID did not alter texts. We found that both essays differ in content but close with the exact same sentence. From a methodological perspective, the implications of this duplicate detection are that (a) since both texts have the same word distributions, they have the same relative text contribution, (b) LACOID is useful to detect potential plagiarism at the sentence level—or even potential issues in data preparation, and (c) when there is a “tie” in the relative text contribution, we programmed LACOID to deploy all instances (configuring IDs and text chunks), even if the deployment of this information resulted in showing more than the expected number of most representative text chunks. That is, we selected to show the top three most representative cases, but LACOID deployed four instances, since one instance had the same relative text contribution.
The third latent code has the highest group fit. Code 3 also had two texts tied in their representativeness, but the input texts were not exact copies. In the most representative text “boy_sixteen_124.doc.5” described finishing his apprenticeship and saving to buy more properties. In the second most representative text, “girl_sixteen_112.doc.12” described how long they waited for the arrival of their third and fourth children. The tied cases also referred to their children growing up and their family lives. Based on this content, we named this code
Hypotheses Generation as Part of Integration
Although a deeper qualitative analysis may be strengthened by analyzing the context where texts were provided, for our practical demonstrative purposes, let us rely on our initial qualitative understanding of the meaning of these codes to showcase how we can test if there is an association between the intersection of gender and age and these three latent codes. To assess these relationships, LACOID offers two more outputs. One is the network depiction of the distribution of these group–code relationships (see interactive plot here https://cutt.ly/nE96btS, where clicking on lines and circles [latent codes] or triangles [groups] provides more information about these relationships—see Figure 7). The second is the statistical test (using Chi-squared) for these relationships—Figure 8.
14
Network depiction of group distributions and associations with latent codes (interactive version here https://cutt.ly/nE96btS). Hypothesis testing output based on chi-square (red and blue rectangles are most influential).

The network depiction shows that for all three groups, the code

Although the network depiction is useful, it does not formally test whether these observed relationships are stronger or weaker than expected under the hypothesis of no association. The Chi-squared test (Figure 8) shows statistically significant results (p-values computed by Monte Carlo simulations are not zero but smaller than three decimal places) indicating associations across attributes and classified responses that are not the result of random chance. Specifically, note that the responses provided by boys 16 and girls 17 + are slightly more frequently associated with
Latent Code Identification’s Output Integration with Quantitative Databases
The latent codes generated at the document level may be merged with more traditional quantitative analyses like regression models. That is, in the same way that we captured the most prevalent associations of groups with latent codes (blue links in the network depiction), we programmed LACOID to measure the strongest relation of each essay author (i.e., Word file) to these latent codes (or the distribution of these classifications). Specifically, one of the three downloadable datasets resulting from executing Steps 7–8 is called “File-to-LACOID distribution.” This database contains the distribution of all latent codes IDs (LACOID) across all input files—see figure above. As discussed earlier, our analytic sample includes 153 essays, hence this database contains 153 rows (the first row in the Excel file is “column names”).

The column “Tot_number_LACOID” accounts for how many LACOIDs each file contained and the columns starting with “Weight” indicate the total number of texts for each participants that were classified under each of the resulting codes. For example, “boy_sixteen_11.doc” and “girl_seventeen+_152.doc” had nine and seven LACOIDs, respectively. Accordingly, given that for this boy seven of these text contributions were classified under Code 1 or V1, 77.8% (or
This resulting table has an inherent quantitative nature. If researchers have other individual- or input text-level related attributes of interest, such as socioeconomic status, college enrollment, or site’s contextual attributes of these text documents (e.g., interview transcripts, observation notes), these classified responses may be merged with such attributes to address quantitative questions. For example, assume that our participants’ transcripts have attributes indicating college enrollment. Considering this attribute, we can ask: “are participants strongly associated with the latent code
Discussion of the Findings
These relationships shown in Figures 7 and 8, suggest that the foci of the essays of boys age 16 and girls age 17 + are slightly more concentrated on transitioning to the job market, careers, and training (Code 1 or V1 in Figure 8), whereas the essays of girls age 16 tend to be more focused on home and family life family growth (Code 3 or V3 in Figure 8) with the opposite being true for girls age 17+. Although these associations were retrieved from the integration of computer or statistically assisted machine learning and NLP algorithms and the initial qualitative analyses of these resulting classifications, neither these categories nor these associations should be taken as the only form of valid knowledge or the only understandings to be retrieved from these essays. To the contrary, there are many more nuanced and important responses in the textual database that deserve further attention. For example, some essays clearly denote depression and suicidal thoughts. Participant “boy_sixteen_4.doc” mentions being constantly depressed, not being happy, and simply waiting to die. Participant “boy_sixteen_7.doc” more blatantly mentioned suicide: I am now 59 and I don’t want to live any longer, so I will leave all my money and property to my wife and children (including the one at university). Retire with them and on my 60th birthday, I will kill myself (I hope).
Although some instances of these feelings can be inferred from Code 2 or V2 “
Based on this discussion, although we appreciate the consistency and time-efficiency of the application of computer rules and machine learning in classification, we should never forget the analytic power of human nuance to be gained from reading the original essays and finding more balanced understandings.
Contribution to Qualitative and Mixed Methods Literatures
Compared to previous methodological and applied contributions to the mixed methods literature, LACOID offers two major points of departure. The first is LACOID’s explicit efforts to democratize access to these rigorous and sophisticated analytical and statistical tools by removing all computer and statistical programming requirements (see also González Canché, 2022a, 2022b, 2022c), for related no-code data science applications to analyze qualitative evidence). We programmed the software infrastructure of LACOID and provided this applied example to be fully transparent, reproducible, and accessible locally and cost-free. Local access is important in the design phase to minimize the risk associated with uploading data to servers. Although we purposefully analyzed a collection of publicly available data to motivate the replication of our analytic procedures, we recognize that most typical projects cannot share data, and that data protection and confidentiality should be prioritized, which is why we designed LACOID to run locally.
The second point of differentiation of LACOID is that we developed it to mirror (to the best of our abilities) the qualitative process of coding data (or HUCOID) in a line-by-line fashion. Our main motivation to decompose texts consisted of avoiding or minimizing latent code aggregation bias (LCAB), where latent meaning may be lost due to using a multiplicity of sentences as a unique text input in the machine learning and classification processes. As discussed earlier, our application example empirically corroborated the relevance of decomposing texts before applying NLP and text classification procedures.
Another contribution of LACOID is hypotheses generation (and testing) through an integrative framework. As depicted in our procedural diagram, the only way for this hypothesis-testing process to be meaningful is by having a clear understanding of latent codes. And as depicted in our example, this understanding is possible only via the weaving of qualitative and quantitative threads. From this view, LACOID is designed to “force” this integrative process as a fundamental part of the meaning-building, hypothesis-testing process.
Moving Forward
To close this methodological guidance study, we offer a set of questions that may help researchers and practitioners guide their research projects using LACOID. These questions are not prescriptive but rather are designed to spark scientific curiosity during the integration of the quantitative and qualitative analytic threads required by LACOID as a mixed methods analytic integrative framework. The information in square brackets is provided to contextualize further these questions based on understandings gained in our analyses. These questions are: 1. What are the optimal number of latent codes embedded in our textual database? (a) Is there a unique or clear solution? Or are there competing, feasible solutions? [In this study we found two solutions—one with three codes and the other with seven codes.] (b) If there is more than one feasible solution, what approaches and decision-making processes can researchers use to select one solution over the other? (c) Are there any limitations associated with the final solution selected? For example, does selecting the lower number increase the chance of LCAB, wherein texts that may be associated with other latent codes are aggregated into a less optimal number of codes? The answer to this question can only be reached with the qualitative analysis of these solutions following the approach discussed in this study and with the added nuance gained from reading the original texts and using the competing LACOID solutions as guides. [In addition to our qualitative analyses, the clear/nonoverlapping delineation of the three-code solution allowed us to discard the competing seven-code choice.] 2. What is the contextualized meaning of these codes? (a) How does the word-to-code distribution and codes’ quadrant locations aid in the meaning-building process? (b) Can similarities and differences be observed in competing optimal solutions? [In our renderings, Code 3 and Code 7 overlapped in family formation, as highlighted with the selection of the word “child” as an example.] (c) How do the word-to-code distribution and quadrant positions fall short in capturing these contextualized meanings? [Although these quantitative techniques are useful for gaining an initial understanding, the original texts should still be analyzed.] (d) Does the analysis of original texts lead to understandings that are congruent with those gained with the word-to-code distributions? (e) Does the analysis of the text-mined data contribute to a better understanding of the meaning of these latent codes? (f) Is the analysis of the most representative text along with measures of within-code coherence and within-group coherence useful in improving our qualitative understandings? (g) Is there any evidence of plagiarism or potential text preparation issues [like in the case of the use of the exact same sentence we found in our example]? 3. Is the analyses of group association relevant for the research project? If so, what groups or intersections across groups [e.g., gender and age in our case] are more meaningful? (a) Is there any statistical association? If so, how is this statistical association explained by qualitative understandings? (b) What were the strongest associations found? (c) Are these depictions useful in strengthening qualitative understandings? If so, how or in what ways? (d) How useful is it to observe that each group is not exclusively or uniformly linked to only one latent code but rather there is a distribution of groups to latent codes? (e) How does the community detection process of LACOID compare to the statistical analyses? [In the example, girls were identified as belonging to Code 2 and Code 3 as communities, but the statistical tests indicated differences wherein the age 16 group was more frequently associated with Code 3 than expected, and the age 17 + group was less associated with this same code than expected—see Figure 8. What are the meanings and implications of these variations?] 4. Finally, how can the integrative analyses of the association of the answers to these questions help improve our understandings of the inherent structures embedded in these texts? (a) Can these latent codes be used in more traditionally quantitative analyses like regression models?
Overall, and to close, LACOID’s epistemological goals may be realized only to the extent that these latent codes are decoded with the contextualized understandings embedded in the original texts. The power of human nuance and knowledge of the topic of study is the best asset that qualitative and mixed methods researchers have to leverage the machine-learning and artificial intelligence analytic power that NLP and LACOID bring to the mixed methods table. The time has come to fully remove the computer and statistical programming barriers to these powerful analytic tools. We hope LACOID may truly serve to expand access and strengthen mixed methods in qualitative research via efficient and effective classification and hypotheses testing, based on the effective unaltered and contextualized retrieval of participants’ meanings. Please see also González Canché (2022c, 2022d, 2022e), for related no-code data science applications to analyze qualitative data dynamically.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Author Note
This project was sponsored by research grants from the National Academy of Education/Spencer Foundation, TIAA, and SAGE OCEAN Concept Grant. The content does not represent the views of those organizations and foundations. Contact information
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research received financial support from Spencer Foundation, National Academy of Education, and SAGE OCEAN; Concept Grant.