
Abstract
Evaluating the intercoder reliability (ICR) of a coding frame is frequently recommended as good practice in qualitative analysis. ICR is a somewhat controversial topic in the qualitative research community, with some arguing that it is an inappropriate or unnecessary step within the goals of qualitative analysis. Yet ICR assessment can yield numerous benefits for qualitative studies, which include improving the systematicity, communicability, and transparency of the coding process; promoting reflexivity and dialogue within research teams; and helping convince diverse audiences of the trustworthiness of the analysis. Few guidelines exist to help researchers negotiate the assessment of ICR in qualitative analysis. The current article explains what ICR is, reviews common arguments for and against its incorporation in qualitative analysis and offers guidance on the practical elements of performing an ICR assessment.
Introduction
The power of qualitative research in shedding light on questions concerning experience and motivation is increasingly recognized by research funders and policy-makers. This growing popularity brings demand for specific, step-by-step guidelines on implementing the various stages of qualitative analysis. Several practical how-to guides have been published to date (e.g., Attride-Stirling, 2001; Braun & Clarke, 2006; Charmaz, 2006; Joffe, 2012; Roberts et al., 2019; Smith et al., 1999). Such resources enhance the accessibility and consistency of qualitative research and provide valuable teaching aids. However, few guidelines exist to help researchers navigate the assessment of intercoder reliability (ICR) in qualitative analysis. The current article seeks to fill this gap. It explains what ICR is, reviews common arguments for and against its incorporation in qualitative analyses, and offers guidance on the practical elements of performing ICR assessment.
The recommendations offered are based on a thorough review of the literature on ICR, as well as the authors’ own research experience. The authors of this article are social scientists who conduct qualitative research to explore lay thinking, feeling, and experience concerning a range of topics including climate change (Smith & Joffe, 2009, 2013), emerging infectious diseases (Joffe, 1999; Joffe et al., 2011), neuroscience (O’Connor & Joffe, 2013, 2014a, 2014b, 2015; O’Connor et al., 2012), earthquakes (Joffe et al., 2013, 2018), sexuality (Lavie-Ajayi & Joffe, 2009; O’Connor, 2017), cities (Joffe & Smith, 2016), economics (O’Connor, 2012), and mental illness (O’Connor et al., 2018; O'Connor & McNicholas, 2019). Although the authors’ primary disciplinary affiliation is social psychology, they have conducted qualitative research projects in many interdisciplinary contexts, involving collaborations with sociologists, anthropologists, engineers, psychiatrists and lawyers, among others. The current article is designed to be relevant to those working with qualitative techniques across the social sciences. It will be particularly useful to those new to ICR, though experienced researchers will also benefit from its review of the variety of perspectives on and practical approaches to ICR assessment.
In the authors’ own research, data collection methods of choice have usually been in-depth interviews (often using Joffe and Elsey’s [2014] free association Grid Elaboration Method) and media analysis of both text and imagery (e.g. O’Connor & Joffe, 2014a; Smith & Joffe, 2009). Many of the examples offered in this article have these forms of data in mind; in particular in-depth interviews, since these pose particular challenges in ICR assessment and have received little specific attention in the ICR literature (Campbell et al., 2013). However, the ICR issues reviewed are broadly relevant to all forms of qualitative data, which include focus groups, free-text survey responses, diaries, and other written documents.
This article is equally broadly based regarding the analytic approach selected. In principle, ICR could be incorporated into any qualitative analysis that involves coding text or images. In practice, ICR is more popular within some analytic traditions than others. For instance, practitioners of content analysis often present ICR as a fundamental imperative of that method (Lombard et al., 2002; Neuendorf, 2002). In contrast, some grounded theory researchers see ICR as inappropriate due to the recursive, incremental nature of grounded theory’s analytic process (Oktay, 2012). The question of ICR’s epistemological compatibility with qualitative paradigms is discussed below. The authors of this article have most often applied ICR within thematic and content analysis and found it improved the quality, transparency, and reception of analyses.
What Is ICR?
ICR is a numerical measure of the agreement between different coders regarding how the same data should be coded. ICR is sometimes conflated with interrater reliability (IRR), and the two terms are often used interchangeably. However, technically IRR refers to cases where data are rated on some ordinal or interval scale (e.g., the intensity of an emotion), whereas ICR is appropriate when categorizing data at a nominal level (e.g., the presence or absence of an emotion). Most qualitative analyses involve the latter analytic approach.
ICR should also be differentiated from intracoder reliability. This refers to consistency in how the same person codes data at multiple time points. That is, if the same person returns to the data at another time, will they code it consistently? Evaluating intracoder reliability may prove a useful exercise in promoting researcher reflexivity (Joffe & Yardley, 2003). However, it is not particularly common in qualitative research. When “reliability” is discussed, it usually refers to the intercoder level.
A further terminological distinction is between ICR and intercoder consistency. Many qualitative research teams include an element of comparison between individual team members’ impressions of the data, but may refrain from quantifying the degree of consensus. For example, Thomas and Harden’s (2008) approach of thematic synthesis suggests that independent researcher identification of themes could be followed by group discussion of overlaps and divergences. The term “reliability” implies that researchers have gone beyond this to formally compute a measure of intercoder agreement. The current article primarily focuses on quantified measures of reliability, since the existing literature offers little practical guidance on performing and interpreting ICR assessment. However, many of the issues discussed may also be relevant to researchers applying less structured evaluations of intercoder consistency.
ICR and the Coding Process
In the analysis phase of qualitative research, the social scientist must introduce a more conceptual understanding of the data (Gaskell, 2000). In most qualitative analyses, this involves the development of a coding frame that captures the analytically significant features of the data. The coding frame is typically a list of codes, which may be organized according to higher-order code categories, accompanied by code definitions and example data segments. The coding frame constitutes the analytic instrument with which the raw data is reduced, classified, and synthesized into a more conceptual framework (Gaskell, 2000). Once developed, the coding frame is applied systematically to the data. This means the data are segmented into data units and each data unit is labeled with codes that index its analytically relevant content. ICR can be calculated in the coding phase of qualitative analysis to assess the robustness of the coding frame and its application.
It is important to note that coding is just one stage in qualitative analysis. Codes can be conceptualized as the basic “building blocks” with which the structure of the analysis is constructed. After coding is completed, depending on the analytic approach used, codes are usually clustered into themes or narratives that are interpreted according to relevant theory. It is generally accepted that different analysts, with different theoretical commitments, will organize codes into themes in different ways (Armstrong et al., 1997). As long as researchers are transparent about their rationale for the thematic structure developed, this is not problematic; indeed, this level of interpretative flexibility is the raison d’être of qualitative research. The logic of applying ICR to the earlier coding phase is that coding is the first place where the analysis begins to move beyond the raw data into a more abstract conceptual framework. Haphazard or inappropriate coding at this stage fundamentally compromises the analysis’ claims to offer a faithful and trustworthy characterization of the data. Qualitative researchers have proposed numerous different steps to substantiate the credibility of the coding process (Bauer et al., 2000; O’Brien et al., 2014; Popay et al., 1998; Seale & Silverman, 1997; Yardley, 2000). One among these is ICR: by increasing the consistency and transparency of the coding process, ICR can help provide confidence that specific efforts were made to ensure the final analytic framework represents a credible account of the data.
Current Practice Regarding ICR
Consideration of ICR is relatively common, although by no means ubiquitous, in qualitative research. A 2018 search for the key words “qualitative” and “intercoder reliability” or “inter-coder reliability” yielded over 1,000 results on Scopus, and over 16,000 on Google Scholar. More specific information regarding the prevalence of ICR comes from the content analysis literature. 1 Lombard et al. (2002) report that of content analysis articles published in the mass communications literature between 1994 and 1998, 69% mentioned ICR. However, many reports of ICR calculations were vague and/or used inappropriate methods. An earlier audit of content analysis articles in consumer behavior and marketing journals between 1978 and 1989 found 48% used independent judges, but 31% reported no reliability coefficient and the method of calculating reliability was unclear in an additional 19% (Kolbe & Burnett, 1991). A more recent analysis of content analysis articles in two communications journals also found high levels of incomplete information and inappropriate testing and reporting practices (Feng, 2014). It should be noted that these studies relate only to the content analysis literature. Content analysis is the analytic tradition with the highest affinity for ICR; for instance, Neuendorf (2002, p. 141) states reliability is “paramount” in content analysis and content analytic results are “useless” without its establishment. As such, the above estimates of ICR’s frequency are likely to exceed its prevalence in the broader qualitative literature.
The practice and evaluation of qualitative research is often guided by published checklists that stipulate steps that improve the quality of an analysis (Barbour, 2001). Some recommendation of multiple coding often appears on such checklists (Barbour, 2001). For instance, the Consolidated Criteria for Reporting Qualitative Studies requires specification of the number of coders (Tong et al., 2007) and the National Institute for Health and Care Excellence (2012) quality appraisal guidelines query whether the analysis was reliable and whether data were coded by multiple people. Additionally, some peer-reviewed journals (e.g., Social Science & Medicine, Journal of the Society for Social Work and Research, Journal of Nutrition Education & Behavior) publish criteria for authoring and reviewing qualitative studies that include recommendations of ICR (Wu et al., 2016). ICR may therefore assist with achieving certain dissemination and impact pathways.
The inclusion of ICR in such quality criteria may suggest that in certain scholarly communities, ICR has become mainstreamed as a standard and expected step in qualitative analysis. Feng’s (2014) study suggests ICR became more commonly reported in the 2000s, although inappropriate statistical procedures also grew around this time. The past decade has seen a general movement from calculation of basic percentage agreement, which statisticians agree is an inadequate index (Cohen, 1960; Hallgren, 2012; Lombard et al., 2002), toward more formal statistical tests such as Krippendorff’s α (Feng, 2014). However, there remains considerable dissensus regarding the most effective way to conduct ICR assessment and more fundamentally regarding its propriety within a qualitative paradigm. The following sections review the arguments commonly raised in favor of and against the inclusion of ICR assessment in qualitative analysis.
Arguments in Favor of ICR
The most commonly cited rationale for performing an ICR assessment is to assess the rigor and transparency of the coding frame and its application to the data (Hruschka et al., 2004; Joffe & Yardley, 2003; MacPhail et al., 2016; Mays & Pope, 1995). Achieving high ICR can satisfy the research team and audience that the coding frame is sufficiently well specified to allow for its communicability across persons (Joffe & Yardley, 2003). For example, in cross-cultural studies of lay responses to earthquakes (Joffe et al., 2013) and HIV/AIDS (Joffe, 1999), ICR assessment provided confidence that data collected in different languages and cultural contexts was consistently coded, allowing for exploration of similarities and differences across cultural data sets. Although qualitative research, by definition, places value in the analyst’s interpretation of data, the ultimate purpose of doing and publishing research is to share it with others (Yardley, 2008). ICR helps qualitative research achieve this communicative function by showing the basic analytic structure has meaning that extends beyond an individual researcher. The logic is that if separate individuals converge on the same interpretation of the data, it implies “that the patterns in the latent content must be fairly robust and that if the readers themselves were to code the same content, they too would make the same judgments” (Potter & Levine-Donnerstein, 1999, p. 266). Performing an ICR assessment ensures multiple individuals can understand and contribute to the analytic process. ICR therefore provides confidence that the analysis transcends the imagination of a single individual (Kurasaki, 2000).
One undeniably important element of ICR is an external quality-signaling function. Reporting ICR can help persuade readers that the analysis was performed conscientiously and consistently (Kurasaki, 2000). ICR can thus serve as a badge of trustworthiness. Indeed, some journal editors and reviewers may request or require a measure of ICR before agreeing to publish qualitative studies (Wu et al., 2016). Given qualitative research is still viewed with suspicion in some quarters, a concrete quality indicator demonstrating the rigor of the research procedure can greatly assist researchers in increasing the reach and influence of their research. This may be particularly welcome when communicating research to multidisciplinary audiences who may not be familiar with qualitative analysis (Hruschka et al., 2004).
This said, ICR need not be undertaken for exclusively extrinsic concerns. In many researchers’ experience, the primary advantages of ICR are internal to the research process (Barbour, 2001; MacPhail et al., 2016). First, ICR motivates researchers to ensure consistency in coding decisions. This is important when data coding is distributed across multiple researchers, as large projects frequently necessitate (Burla et al., 2008; MacPhail et al., 2016). It is especially critical for cross-cultural or cross-linguistic studies, as in the studies by Joffe (1999; Joffe et al., 2013) mentioned above. ICR ensures workloads can be shared without compromising the internal cohesion of the analysis. Additionally, even at an intracoder level, awareness that one’s coding will be compared to that of others can provide an incentive to maintain high coding standards. Coding can be monotonous, and it is easy for the coder’s mind to drift. The self-disciplinary function of embedding some monitoring into the process should not be underestimated.
Second, ICR fosters reflexivity and dialogue within the research team. Echoing Barbour (2001), the content of intercoder disagreements can be equally, if not more valuable than the ultimate degree of consistency. Any inconsistencies the ICR process reveals should be discussed among coders to clarify the conflicting interpretations responsible. These discussions should inform the refinement of the coding frame to improve precision (Joffe & Yardley, 2003). For example, early ICR assessment in an interview study of laypeople’s associations with neuroscience (O’Connor & Joffe, 2014b) identified numerous codes that, while reflecting basic concepts in the theoretical framework used by the primary researcher, were not clear to an external researcher recruited to second-code the data (e.g., “self-control,” “causal attribution”). This revelation impelled the revision of the coding frame to more tightly define the focus and boundaries of these conceptual codes. The iterative developments prompted by ICR mean that the ICR process itself is often more valuable than the final scores (MacPhail et al., 2016). The benefits of discussion between researchers are acknowledged by many researchers who opt not to quantitatively measure ICR, yet include a phase of informal intercoder comparison and discussion. Such collaborative exercises are undoubtedly intrinsically beneficial, but formally computing ICR makes these discussions more systematic and informed, by revealing codes’ relative reliability status and efficiently directing attention to the specific codes proving ambiguous. The result is a more explicit and well-defined coding frame (Joffe & Yardley, 2003), which is the primary tool for analyzing the data.
Finally, although many qualitative studies are purely exploratory, some have tangible, real-world repercussions. For instance, Hruschka et al. (2004) describe qualitative studies undertaken to inform policy in the Centers for Disease Control and Prevention, which must be acted on by policy-makers from multidisciplinary backgrounds. As another example, an interview study by O’Connor and McNicholas (2019) was used to derive recommendations for how clinicians should communicate psychiatric diagnoses to young people and their families. Qualitative findings may influence governmental or organizational policy, case-specific decisions in medical or legal contexts, or the distribution of public or charitable funds. With such consequences at stake, any effort to increase confidence in the evidence-base is welcome.
Objections to ICR
ICR is by no means universally accepted as beneficial for qualitative studies. Perhaps the most frequently aired objection is that ICR essentially contradicts the interpretative agenda of qualitative research (Braun & Clarke, 2013; Hollway & Jefferson, 2013; Vidich & Lyman, 1994; Yardley, 2000). Much of this relates to the epistemological status of reliability within the qualitative tradition. In quantitative research, reliability relates to the stability of findings across time, contexts, and research instruments. By the logic of positivist research, if a finding is reliably substantiated across these dimensions, it is more likely to represent an objectively “true” phenomenon rather than an artefact of the research process (Bauer et al., 2000). In contrast, most qualitative epistemologies reject the notion of a single, objective, external “reality” the scientific method can directly reveal. Instead, qualitative scholars see their research field as composed of multiple perspectival realities that are intrinsically constituted by an individual’s social context and personal history (Bauer et al., 2000). Qualitative researchers’ role is not to reveal universal objective facts but to apply their theoretical expertise to interpret and communicate the diversity of perspectives on a given topic. Within this epistemological framework, researcher reflexivity and active personal engagement with the data are resources, not “noise” to be minimized (Yardley, 2008).
Inarguably, complete objectivity is not a realistic expectation while coding latent content (Potter & Levine-Donnerstein, 1999) and indeed may not be a desirable one. Krippendorf (2004) notes textual meanings only arise in the process of somebody conceptually engaging with them; some degree of interpretation is therefore necessary to discern the meaning a particular segment of text holds. Affirming the analytic necessity of interpretation does not, however, negate the possibility of producing an analysis that is systematic, explicit, and transparent (Bauer, 2000). Qualitative researchers have proposed alternative quality criteria that substitute the typical standards used in evaluating quantitative research (Bauer et al., 2000; Popay et al., 1998; Seale & Silverman, 1997; Yardley, 2000). Along with ICR, these include transparent reporting of the analytic procedures, producing “thick description” with plentiful samples of raw data, triangulation between numerous studies, attention to deviant cases, and asking research participants to validate the legitimacy of analytic interpretations.
Some researchers strongly object to the inclusion of ICR in qualitative analysis because they see it as an unwarranted attempt to import standards derived for positivist research (Guba & Lincoln, 1994; Madill et al., 2000). For instance, Stenbacka (2001, p. 552) states, “reliability has no relevance in qualitative research, where it is impossible to differentiate between researcher and method.” Likewise, Braun and Clarke (2013) assert reliability is not an appropriate criterion for judging qualitative work and that quantitative measures of ICR are epistemologically problematic.
It is possible that some of the antagonism toward ICR arises from the mere word “reliability” and its conventional association with a quantitative paradigm. Indeed, some critics of ICR suggest alternative concepts such as “dependability” or “trustworthiness” may be acceptable (Braun & Clarke, 2013). It can be argued that the aim of attaining acceptable ICR does not necessarily imply there is a single true meaning inherent in the data, which is the concern underpinning most epistemological objections to ICR (Braun & Clarke, 2013). Rather, it shows that a group of researchers working within a common conceptual framework can reach a consensual interpretation of the data. While this can be trivialized as merely proving that different researchers can be trained to interpret data in similar ways (Joffe & Yardley, 2003; Yardley, 2000), this in itself is not an insignificant achievement. As Yardley (2008) acknowledges, a wholesale rejection of any transferability of qualitative findings is unproductive: if findings were entirely idiosyncratic to individual studies, there would be little point in doing qualitative research. Indeed, valorizing the sanctity of the analyst’s unique interpretation could be read as highly individualistic—which is ironic, given much qualitative research orients to a social constructionist epistemology. Within an intellectual community, it should be possible to develop confidence that researchers are analyzing data using a common conceptual framework. ICR is one way of establishing, rather than just assuming colleagues are understanding and using conceptual tools in similar ways.
An arguably more significant risk of ICR is the false precision that numerical information can convey. Research shows inclusion of entirely nonsensical mathematical information can inflate judgments of the quality of research reports (Eriksson, 2012). Merely including a high ICR figure may lead to unjustifiably positive judgments of otherwise weak studies. The skewing effect of quantitative information is particularly problematic for students or newcomers to qualitative research. In the authors’ experience of teaching thematic analysis in undergraduate psychology programs, students who initially struggle with the open-ended nature of qualitative analysis can become disproportionately fixated on achieving satisfactory ICR at the expense of the substantive analytic work. It might therefore be advisable to defer teaching ICR until students are more comfortable with the core tenets of qualitative analysis. However, for an experienced qualitative researcher, incorporating a numerical measure of ICR need not compromise analytic depth. Additionally, many qualitative analyses draw on quantitative information, such as frequency counts of the number of interviews that contain a given code (Maxwell, 2010). If researchers intend to include numerical information in the analytic results, validating that through initial ICR assessment is good practice.
While the costs and benefits of ICR are inevitably specific to the research context in question, in the authors’ experience the gains usually outweigh the risks. However, it is important to maintain perspective in relation to one’s research questions and prevent ICR from becoming the focal point of an analysis. ICR is never an end in itself; it is merely a means to the ultimate goal of achieving an insightful and robust qualitative analysis.
Practical Considerations: Performing an ICR Assessment
Manual or electronic?
With today’s technological resources, the coding process is greatly aided by specialized qualitative analysis software packages, particularly when large quantities of data are involved. Some software packages, such as NVivo, Dedoose, and QDA Miner, contain an integrated ICR calculation tool. Others may not have an inbuilt ICR function, but coding patterns can be exported to external tools (e.g., the coding analysis toolkit at http://cat.ucsur.pitt.edu/). However, in the authors’ experience, the process by which automated ICR tools calculate an ICR figure is often opaque and overly sensitive to inconsequential differences in coders’ files (e.g., when coders have selected data units that differ by a mere punctuation mark). An alternative means of retaining control over the process is to export coding data from a qualitative platform to a statistical software package (e.g., SPSS) and calculate reliability there. The process the authors have devised to do this is described in detail below.
Despite the popularity of qualitative software packages, some researchers prefer or are forced by resource constraints to perform analyses manually. Hand-performed coding, aided by colored highlighters and sticky notes, does not preclude ICR calculation but will almost certainly make it more difficult. If a researcher wishes to perform ICR and has no access to specialist packages, performing the coding using a generic word processing package such as Microsoft Word (e.g., by indexing the codes through the “Comment” function) or tabulating assigned codes in a spreadsheet would make the intercoder comparison more efficient.
How many coders?
A minimum of two independent coders is necessary to establish ICR. The inclusion of additional coders beyond this depends on the pragmatic resources and requirements of the specific project. For large data sets where coding must be divided between multiple researchers, it may be important to establish that all coders are applying the coding frame in consistent ways. In such cases, the addition of any new researcher may require a further ICR calculation to assess this individual’s performance.
As Campbell et al. (2013) acknowledge, the reality of many qualitative research projects, particularly in early-career contexts, is that a single coder codes the majority of the data. In such cases, ICR can be obtained by recruiting an additional person to code a sample of the data. Once satisfactory reliability has been established, the primary researcher then proceeds to code the remaining data alone.
What proportion of the data should be multiply coded?
While some studies apply multiple coding to the entire data set, resource constraints usually mean ICR is calculated on just a subset of the data. However, there is little consensus regarding the proportion of the data set that facilitates a trustworthy estimate of ICR (Campbell et al., 2013). Depending on the size of the data set, 10–25% of data units would be typical. It is important this subsample is selected randomly or using some other justifiable criteria (e.g., selecting a member of each group in a stratified sample) to ensure representativeness of the entire data set.
Rather than investing several days double-coding a sizable amount of data, only to reveal poor reliability caused by easily soluble issues with the coding frame, it may be judicious to first double-code a small amount of data (e.g., one interview). Informal comparison of code patterns should reveal any obvious problems with code definitions or interpretations. The coding frame can then be refined before commencing the formal independent double-coding with the larger subset of data.
Some researchers opt to implement ICR testing across repeated rounds until satisfactory reliability is achieved (Campbell et al., 2013; Hruschka et al., 2004). For instance, in a study of a HIV prevention trial in South Africa, MacPhail et al. (2016) used a stepwise method that recalculated ICR and refined the coding frame after each individual transcript. Although resource intensive, this method helps improve reliability due to more opportunities to clarify code definitions and remove redundant codes. However, it is possible this reliability may simply reflect “interpretive convergence” (Hruschka et al., 2004) between this particular group of coders rather than any noticeable improvements in the transparency and external communicability of the coding frame.
What level of independence should the coders have?
It is generally accepted that the physical double-coding should be performed independently without conferral between coders. However, advice differs regarding the level of interaction coders should have prior to commencing the coding. Some researchers, whose analytic approaches prioritize increasing the coding frame’s external objectivity, recommend coders should be people external to the research team who had no role in designing the coding frame (Kolbe & Burnett, 1991). Such an approach requires consideration of ethical and data protection implications involved in passing raw data to an external individual.
However, as previously discussed, many researchers value ICR not as a measure of “objectivity” but as a means of reflexively improving the analysis by provoking dialogue between researchers. If one aim of performing an ICR check is to identify areas needing clarification, some discussion between coders is necessary to identify how and why interpretations conflict. In such cases, a first round of independent coding could be followed by a meeting where differences are discussed, the coding frame is revised, and a second round of independent coding commences (Campbell et al., 2013; Hruschka et al., 2004).
Whether prior training of coders is required depends on the depth of the analysis. If codes are simply categorizing surface-level features of data (e.g., whether a newspaper article is an opinion piece or news report), merely possessing a clearly specified coding frame should be sufficient to allow an entirely independent coder to commence. However, if the analysis involves coding more “latent” features of the data, which require greater degrees of interpretation, the coder may need training in relevant theoretical concepts. The issue of code depth is discussed in more detail below.
How should data be segmented?
The specific data “units” or segments coded differ across studies depending on the research aims. At the broadest level, each source of data could be coded as a single data unit—for example, holistically coding a whole interview or entire media article as one entity. Other study protocols might instruct coders to segment data into smaller prespecified coding units, for example, each paragraph or each response to an interviewer’s question. More fine-grained analyses may code each individual line or sentence. Finally, some studies will not prespecify any consistent data unit and instead code ad hoc segments the researcher determines to be conceptually meaningful; for example, a block of sentences that organically elaborate one cohesive idea. Figure 1 shows an example of the latter form of coding in ATLAS.ti, taken from the analysis reported in Joffe et al. (2013).
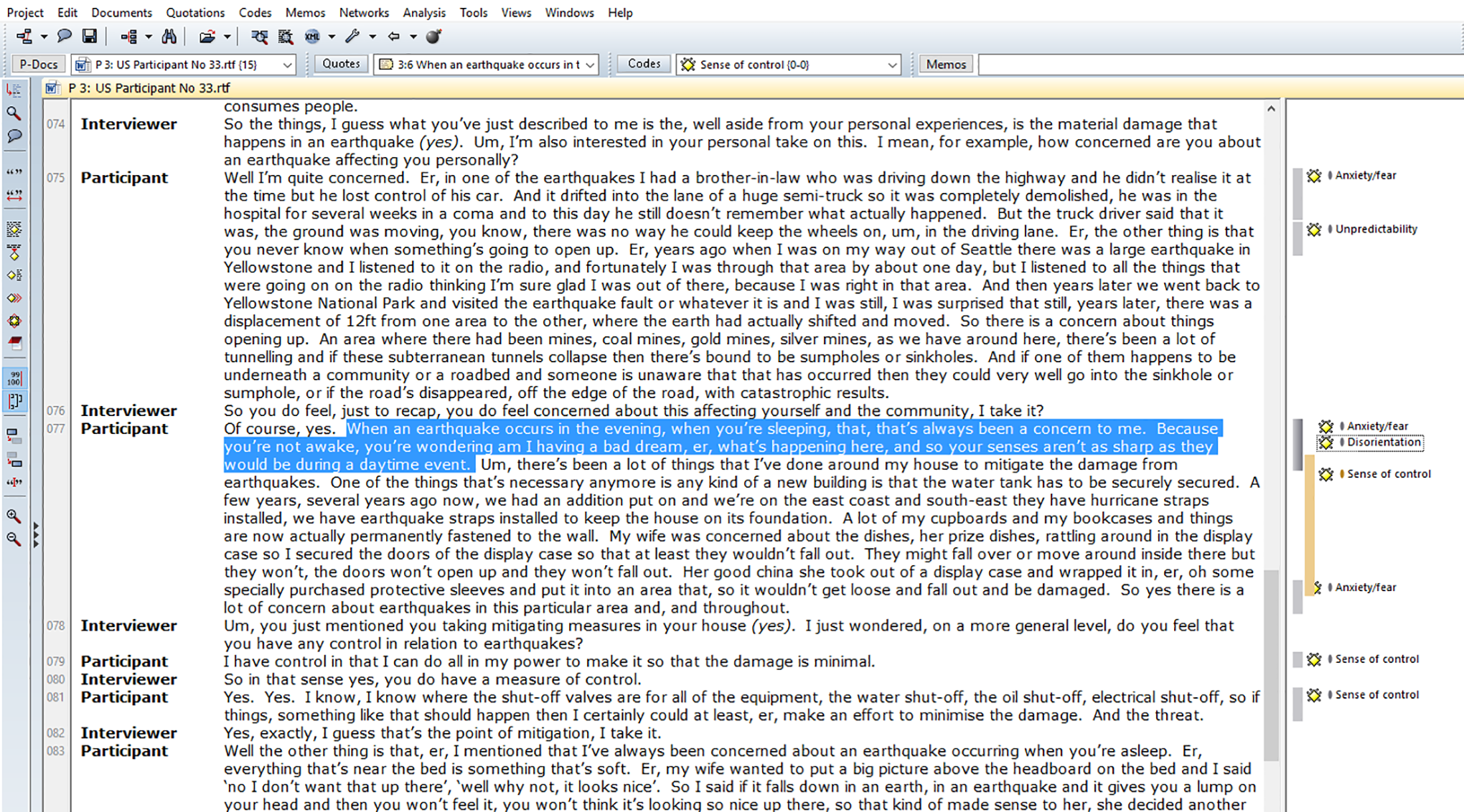
Example of coded interview data in ATLAS.ti (Joffe et al., 2013).
Each of these strategies has distinct strengths and weaknesses, which must be evaluated according to their coherence with the research aims. In general, larger units of analysis are associated with greater validity: the more data units’ original contextualization is preserved, the more valid their interpretation. The meaning of a particular structural element (e.g., a sentence) can often be difficult to ascertain in isolation from its neighboring text. However, coding larger units invites an increased degree of complexity, as it is more likely they contain a range of different (sometimes contradictory) ideas. This poses a challenge when operating an “exclusive” coding strategy that allows for only one code to be assigned to each data unit, though it is less problematic when the protocol allows for coding with multiple codes. However, coding large data units often involves a compromise of analytic sensitivity: the linguistic nuances that are central to many qualitative questions can be lost. In relation to ICR specifically, longer text units are usually associated with poorer reliability (Hruschka et al., 2004).
The “unitization problem” is often a distinct challenge for researchers analyzing interview data (Campbell et al., 2013; Hollway & Jefferson, 2013). Interview data can often be rather unsystematic, with respondents taking variable time to communicate an idea and abruptly jumping between topics. To faithfully capture the meanings conveyed, an ad hoc data unitization strategy, where the researcher determines how to segment the transcript into conceptually meaningful quotes, is often appropriate. This has been the authors’ preference in analyzing interview data in the past. However, this can cause challenges for ICR, as there is no guarantee that different coders will select the same quotes when applying codes. Without any predefined guidance regarding data units, some individual coders (“lumpers”) orient toward selecting larger, more contextualized segments, while others (“splitters”) apply codes more specifically to short segments. This can cause major difficulty in any form of automated ICR calculation: When coders’ selection of text segments varies by a mere digit or punctuation mark, automated systems can record these as different data units and the calculated ICR coefficient is compromised (MacPhail et al., 2016).
Kurasaki (2000) proposes one strategy for managing this issue: allowing coders to select their own segments, then randomly picking certain lines in the document, and comparing codes recorded within a radius of five lines. In the authors’ previous research, they have developed an alternative strategy very similar to one described by Campbell et al. (2013). This approach takes as its premise that consistency in where coders choose to start and end quotes is of minimal analytical significance 2 : more important is ensuring that when given a certain segment of text, similar codes are applied. In this method, one researcher first approaches the transcript, segmenting it as they see fit and applying relevant codes. Campbell et al. (2013) suggest this should be the principal investigator or person most familiar with the subject area, who is therefore more qualified to determine the “meaningful conceptual breaks” (Campbell et al., 2013, p. 304). Once the first coder has saved the coded transcript, they can then create a second document where the data segments are visible but the codes removed. Some qualitative software programs, such as ATLAS.ti, allow users to “unlink” the codes; this creates an uncoded file that can then easily be passed to a second coder. 3 Another option may be to highlight the relevant data segments in a text document. The second coder then uses their own judgment to code the segments they have received.
This example of an ICR-amenable coding strategy illustrates how the conditions necessary for ICR assessment can constrain coding practices. It is incumbent on individual researchers to determine whether the benefits ICR offers for a particular project outweigh the sacrifices of analytic flexibility involved.
How many codes?
The number of codes in the coding frame must be dictated by the research questions and diversity of content within the data. A further variable impinging on code quantity relates to whether the analysis permits exclusive or multiple coding (i.e., whether the protocol stipulates that each data unit can have just one or multiple codes). Multiple coding is often necessary to authentically capture meaning in complex data such as interviews (Campbell et al., 2013) and usually inflates the total number of codes. In relation to ICR, it is worth being aware that the more codes are available, the lower ICR is likely to be (Hruschka et al., 2004; Roberts et al., 2019). This is because it is difficult for coders to familiarize themselves with a lengthy coding frame and hold all potential codes in their working memory when considering many data units. Additionally, very elaborate coding frames often include some codes with low frequency of occurrence, which may not meet the minimum number of observations required for certain reliability statistics to be performed. MacQueen et al. (1998) suggest researchers concerned with achieving satisfactory reliability should work with an upper limit of 30–40 codes. Hruschka et al. (2004) recommend a limit of approximately 20 and further suggest that for semistructured interview data, codes should be specific to particular interview questions. Another potential rule of thumb is to disallow more codes than there are interviews or other relevant data units.
These suggested upper limits should not be taken as dogma. As always, the analytic aims particular to each study should be the primary consideration in designing the analysis. Code comprehensiveness should not be sacrificed purely for the sake of achieving ICR. With enough time and attention, it is possible to implement ICR procedures that reduce the load on coders’ cognitive resources. A well-structured, conceptually and visually clear coding frame minimizes the burden on coders’ working memory. Campbell et al. (2013) additionally suggest grouping codes into “families” of related codes and taking multiple family-specific “passes” at the data, coding according to one family of codes at a time. With complex coding frames, this absolves coders of the requirement to bear all codes in mind simultaneously.
How interpretative should codes be?
Different research questions require different “depths” of coding. This relates to the study’s level of interest in cataloguing “manifest” surface-level content or deeper “latent” meanings. Some coding will record unambiguous, purely factual data (e.g., geographical location). If coders are conscientious, such coding should be near-perfectly synchronous. Other codes will index descriptive information that requires some interpretation but should nevertheless be relatively apparent. For instance, O’Connor (2017) found high ICR when coders were asked to judge whether newspaper articles expressed a supportive, antagonistic, or neutral attitude toward same-sex marriage. In developing even straightforward codes, researchers should avoid assuming anything is “obvious” (MacQueen et al., 1998): the more explicitly defined the codes, the more transparent the process and the higher ICR is likely to be (Joffe & Yardley, 2003).
Some qualitative studies involve coders deploying high levels of interpretation in coding latent features of the data, which may require familiarity with relevant theoretical concepts. More conceptually sophisticated coding frames typically produce lower ICR calculations. However, this consideration alone should not deter researchers from including more interpretative codes in their coding frame: consistency with study aims should always be the primary consideration. Theoretical relevance or meaning should never be sacrificed for reliability (Hruschka et al., 2004). To minimize confusion, a coding frame can include not only examples of typical manifestations of a complex code but also specify its qualifications and exclusions (e.g., “this code does not apply to instances where…”; Boyatzis, 1998; Roberts et al., 2019).
How should ICR be calculated?
Numerous measures of ICR are available. Previous reviews of the literature indicate the most common method is simply reporting the percentage of data units on which coders agree (Feng, 2014; Kolbe & Burnett, 1991). Miles and Huberman (1994) suggest reliability can be calculated by dividing the number of agreements by the total number of agreements plus disagreements. However, percentage-based approaches are almost universally rejected as inappropriate by methodologists because percentage figures are inflated by some agreement occurring by chance (Cohen, 1960; Hallgren, 2012; Lombard et al., 2002). Additionally, while the percentage agreement approach appeals to researchers due to its apparently straightforward manual calculation, attempts to perform this calculation can reveal unanticipated complexities. This occurs especially when the protocol allows for multiple coding of data units. If one coder has applied three codes to a piece of text, and another coder has applied four, with two codes overlapping between coders, it is not obvious how that should be quantified. The procedure becomes even more complex if there are more than two coders (McHugh, 2012).
Statistical tests developed for measuring ICR include Cohen’s kappa, Krippendorff’s alpha, Scott’s pi, Fleiss’ K, Analysis of Variance binary ICC, and the Kuder-Richardson 20. The statistical foundations of these measures are beyond the scope of this article but are fully discussed elsewhere (Banerjee et al., 1999; Davey et al., 2010; Feng, 2013; Hallgren, 2012; Hayes & Krippendorff, 2007; Rust & Cooil, 1994). The primary advantage these statistics offer over percentage agreement is correction for the probability a certain amount of agreement occurs by chance. These tests can also be used to assess the reliability of codes that have been applied nonexclusively (i.e., multiple codes applied to a single data segment). Krippendorff’s alpha appears to be increasing in popularity (Feng, 2014) and is often preferred for its flexibility: it can incorporate more than two coders and incorporate ordinal, interval and ratio as well as nominal data (Lombard et al., 2002). Chi square, Cronbach’s alpha and correlational tests such as Pearson’s r are not appropriate measures of ICR (Lombard et al., 2002).
While it is possible to perform such analyses by hand, most contemporary researchers rely on algorithms embedded in their qualitative analysis or statistical software. The authors of this article have generally adopted the strategy of exporting each coder’s coded data from ATLAS.ti into SPSS. The SPSS files generated present each data unit as a row and each code as a column (see example in Figure 2). If a code has been applied to a data unit, the relevant cell shows 1, and if that code has not been applied, the cell records 0. If the two coders’ ATLAS.ti files were consistently structured in terms of codes available and text segments coded, the two SPSS files can be merged. In this merged data set, each code should have two corresponding columns representing both coders’ applications of that code (the variable naming system should clearly indicate which coder is responsible for each column). SPSS’ statistical functionalities can then be used to implement whatever statistical test has been chosen.
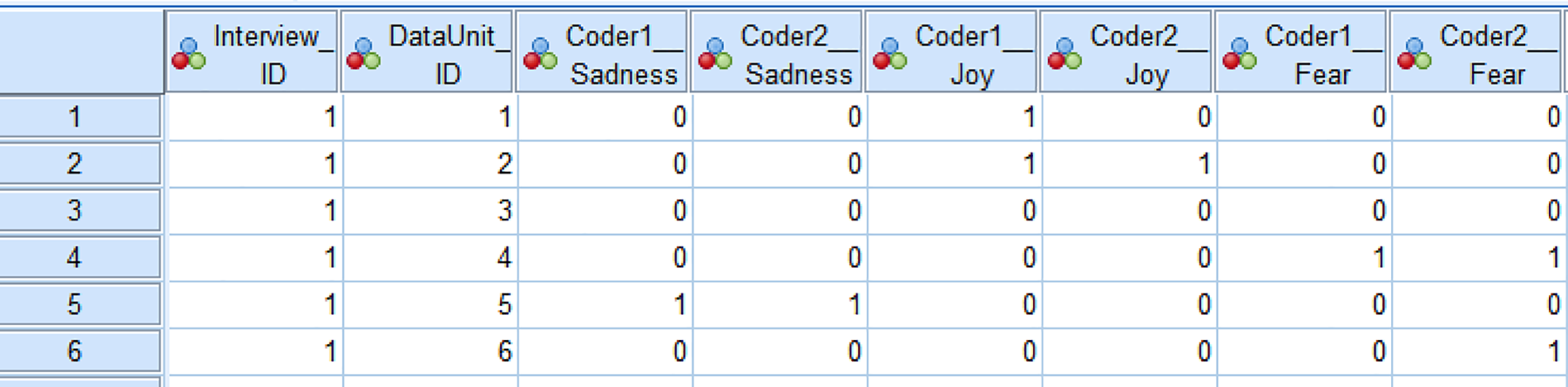
Example of how both coders’ decisions are represented in SPSS. The column variables include IDs for the interview and data unit (quote) in question, and both coders’ decisions regarding applications of three emotion-related codes. Coding patterns are largely similar, except only Coder 1 applied joy to Data Unit 1, while only Coder 2 applied fear to Data Unit 6.
How should results be presented?
It is relatively common to present ICR using a single pooled or average value that represents the reliability of the coding frame as a unitary instrument (Feng, 2014). For example, Burla et al.’s (2008) analysis of experiences of low back pain reports a single kappa statistic that encompasses the coding frame as a whole. This gives a concise way of summarizing the results of the ICR process.
However, caution should be exercised regarding decisions to collapse ICR into a single summary statistic. First, if the aim of ICR is to improve the coding frame, assessing reliability on a code-specific level is critical to identify codes that require refinement. Second, pooling all codes’ reliability figures means codes with poor reliability can be “hidden” or canceled out by codes that perform very well (usually because they are codifying more straightforward manifest content). Nevertheless, presenting the reliability figure for each individual code remains infrequent in published reports (Feng, 2014), perhaps due to space constraints. A parsimonious alternative may be to present the range and distribution of all codes’ ICR performance, perhaps with supplemental individual coefficients in an appendix.
How should results be interpreted?
There is considerable inconsistency in the interpretation of ICR results. Mere statistical significance is never an acceptable indication of ICR: understanding results requires interpretation of the coefficient in question. For percentage agreement approaches, there is no universally accepted threshold for what indicates acceptable reliability, but Miles and Huberman (1994) suggest a standard of 80% agreement on 95% of codes. Most of the commonly used statistical tests of ICR present results on a scale between −1 to +1, with figures closer to 1 indicating greater correspondence. Neuendorf (2002) reviews “rules of thumb” that exist for interpreting ICR values, observing ICR figures over .9 are acceptable by all, and over .8 acceptable by many, but considerable disagreement below that. Researchers often cite Landis and Koch’s (1977) recommendation of interpreting values less than 0 as indicating no, between 0 and 0.20 as slight, 0.21 and 0.40 as fair, 0.41 and 0.60 as moderate, 0.61 and 0.80 as substantial, and 0.81 and 1 as nearly perfect agreement.
All such guidelines are ultimately arbitrary, and the researcher must judge what represents acceptable agreement for a particular study. Studies that influence important medical, policy, or financial decisions arguably merit a higher ICR threshold than exploratory academic research (Hruschka et al., 2004; Lombard et al., 2002). For instance, McHugh (2012) proposes a more conservative system of acceptability thresholds when using Cohen’s kappa coefficients in the context of clinical decision-making. Whatever interpretative framework is chosen should be stipulated in advance and not decided post hoc after results are viewed.
How should results be acted on?
Again, there is no universal agreement regarding how to manage low-performing codes. Much depends on whether the researchers are approaching ICR as a one-off validation of the coding process or as a tool through which the coding frame can be progressively improved. Some researchers may opt to discard codes below a certain ICR threshold. Others may modify poorly performing codes and double-code a further sample of data with the revised coding frame, repeating this process until an acceptable ICR is attained. Others may judge that ICR’s utility is purely in refining a theoretically dictated coding frame and that ICR results should not inform decisions about retaining or removing codes selected for their conceptual importance. The appropriateness of any such approach can only be judged in relation to the specific research aims and context.
Researchers must also decide how to treat instances of intercoder disagreement when finalizing the “definitive” coded data set. Some research teams may introduce a third coder and adopt a “majority rules” decision. Others may decide the judgments of one coder (usually the PI or more experienced researcher) outweigh those of the other. Finally, some research teams may adopt a consensus approach where disagreements are discussed and joint decisions reached. Campbell et al. (2013) describe such a strategy of “negotiated agreement” (Campbell et al., 2013, p. 305), which ultimately increased reliability from 54% to 96%.
Once the coding frame is finalized, it should be systematically applied to the entire data set. This typically involves the recoding of data originally coded during the ICR process (MacQueen et al., 1998).
Suggested Procedure for ICR Assessment
The preceding section lays out the decisions that must be taken when designing an ICR assessment within qualitative research. The advantages and drawbacks of the various options will necessarily be relative to the specific research question and context, and the researcher must decide and justify which options are most appropriate.
Figure 3 presents a suggested procedure for the various steps of ICR assessment. Before beginning the coding, the researchers must make a priori decisions regarding the number of coders, amount of data that will be coded in duplicate, the unit of coding (i.e., sentences, paragraphs, conceptually meaningful “chunks”), the conceptual depth that codes will capture, the reliability measure that will be calculated, and the threshold that will indicate acceptable reliability. These decisions are necessarily project-specific and should be dictated by the research aims rather than the proximate goal of attaining acceptable reliability.

Suggested procedure for intercoder reliability assessment.
The practical process of coding begins with immersion in the data, usually through intensive reading. Through this familiarization, the research team develops a first draft of a coding frame that may, depending on the project, contain either or both inductive and deductive codes. In this suggested procedure, the first coder then applies this coding frame to the data, ideally using a qualitative software package. Coder 1 moves through the subset of data included in the ICR test, segmenting the data into data units and labeling them with relevant codes. Once complete, the coded file is saved. Coder 1 then duplicates the file, removes the code names they have assigned, and passes to Coder 2 a “clean” file that displays the breaks indicating the data units, but not their associated codes. Coder 2 then uses the coding frame to independently code the data units that are visible on the cleaned file. It may be beneficial to first informally compare coding on a small quantity of data (e.g., one interview), to clarify any immediately apparent code misinterpretations before formal reliability evaluation begins.
To compute reliability, both coded files can be exported into a statistical program such as SPSS (some qualitative packages allow files to be converted automatically; others require initial conversion to a CSV file). The two statistical data files can then be merged so they appear as illustrated in Figure 2. The functionalities of the statistical software can be used to compute the reliability statistic of interest for each code in the coding frame. Results should be interpreted according to the a priori threshold of acceptable reliability. Codes that fall short of the threshold can be evaluated to identify potential reasons for inconsistency of interpretation, and removed or revised in accordance with the team’s best judgment. The revised coding frame can be evaluated using the same process, preferably on a different subset of data. Once the research team is satisfied with the overall reliability of the coding frame, the entire data set can be coded by a single coder or team of coders.
Conclusion
The value of qualitative research lies in its sensitivity to the diverse meanings people derive of particular issues within particular contexts: method and analysis can and should be adapted to suit the specific features of the phenomenon under investigation. This makes it difficult to generate one-size-fits-all guidelines. However, a consensus has developed regarding the value of maintaining a set of quality criteria that help researchers design their studies and help audiences differentiate high- from low-quality research (Bauer et al., 2000; O'Brien et al., 2014; Popay et al., 1998; Seale & Silverman, 1997; Yardley, 2000). ICR is one candidate quality criterion. It may not be appropriate for every qualitative study and is not a “magic bullet” for those studies that do include it. ICR attests to the robustness of the coding process, which structures the entire subsequent analysis. However, it is no guarantee of the trustworthiness of either prior data collection and preparation or subsequent theme generation and reporting. A broad sensitivity to accepted principles and practices in the qualitative tradition remains paramount.
In appropriate research contexts, ICR assessment can improve both the internal quality and external reception of qualitative studies. Key benefits include improving the systematicity, communicability, and transparency of the coding process; promoting reflexivity and dialogue within research teams; and helping to satisfy diverse audiences of the trustworthiness of the research. By collating the key arguments for and against ICR and outlining the practical requirements of performing it, this article endeavors to equip researchers make informed decisions about whether and how to incorporate ICR assessment into their analyses.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Dr. O'Connor's work on this article was supported by the European Union’s Horizon 2020 research and innovation programme under grant agreement No 702970.