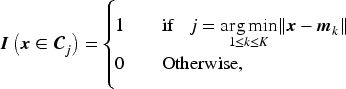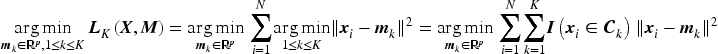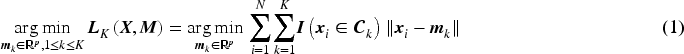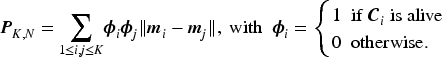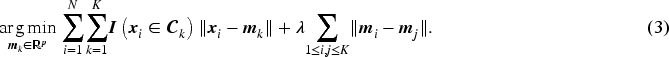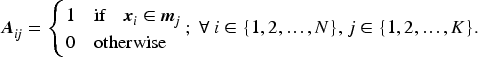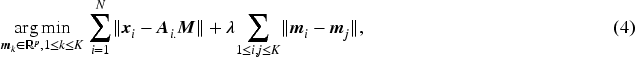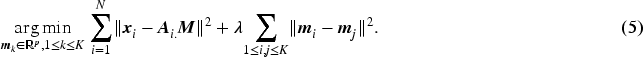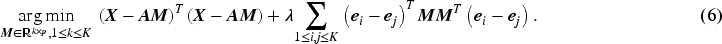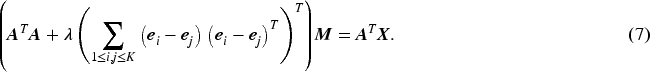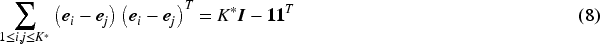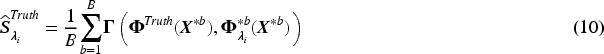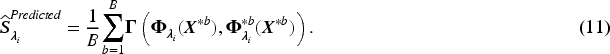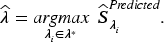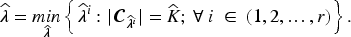Unsupervised learning is a major class of machine learning techniques where response information is missing or unavailable. Among these techniques, clustering plays a central role by grouping objects based on a chosen similarity measure. K-Means is one of the most established and widely used clustering methods, known for its simplicity and computational efficiency. For continuous data, K-Means performs well when the number of clusters is known and correctly specified. However, it faces convergence and overfitting challenges when is unknown. These issues stem from K-Means’ objective function, which monotonically decreases as the number of clusters increases—leading to a tendency to overfit. In this article, we propose an augmented K-Means algorithm that introduces a penalized version of the standard K-Means objective, designed to guard against overfitting and promote model parsimony when is unknown. We establish key optimality properties of both the traditional K-Means loss function and the proposed penalty term. Extensive simulation studies on benchmark datasets demonstrate the improved performance of the proposed method, including accurate identification of the true number of clusters. Extensive simulation studies on benchmark datasets demonstrate the improved performance of the proposed method, including accurate identification of the true number of clusters. Additionally, we apply our approach to the clustering of globular galaxy datasets—an example of truly large-scale (“Big”) data—to further illustrate its effectiveness.
Unsupervised learning problems arise when there is no available information about the response or outcome variable, yet it remains necessary to draw inferences from the observed input features. Clustering is a core task in this setting, aiming to partition the data into distinct groups based on shared characteristics among the features. This process helps reveal the natural structure of the data, offering insights that are both meaningful and applicable across a wide range of domains. A variety of clustering techniques exist, differing K-Means in how they segment the data space into clusters of observations. Broadly speaking, the goal is to ensure that observations within a cluster are more similar to each other, while observations in different clusters are more dissimilar—according to a chosen similarity or distance measure. Clustering mechanisms can be partitioned K-Means into two subcategories with respect to mechanism of forming clusters, namely,
Hierarchical clustering: Objects are clustered in a top-down or bottom-up hierarchy based on a chosen distance metric and linkage function, resulting in a tree-like structure. Examples include Agglomerative clustering and Divisive clustering.
Connectivity-based clustering: Each cluster is represented by a “center” and is constructed via minimizing the distance metric between cluster objects to the center, e.g., K-Means clustering, Medoid based clustering etc.
Each of these methods can be implemented using either a deterministic approach or a probabilistic, model-based framework. Both approaches have their own advantages and disadvantages, and their popularity largely depends on the application domain (e.g., social sciences, marketing, genetics, infectious disease hotspots, astronomy, etc.) as well as the ease of interpretability within that domain. Recent developments in clustering includes density-based approaches (Ester et al., 1996), graph-based/spectral clustering (Shi & Malik, 2000), convex clustering (Chi & Lange, 2015; Radchenko & Mukherjee, 2017; Tan & Witten, 2015) etc. In this article, we are focusing on the Connectivity-based clustering mechanism, especially, K-Means clustering which depends upon the choice of the or cluster centers, and a distance metric. For continuous data, the Euclidean norm is the most popular, albeit, other distance measures (e.g. , etc.) are also explored and in turn, each norm imposes different probability distribution in case one want to exploit the duality between loss and probability distribution. K-Means with Euclidean norm is not only simple to implement and interpret but also has a strong connection with Gaussian mixture models. For a fixed cluster number theoretical results exist showing the consistency of K-Means under various regularity conditions (MacQueen et al., 1967; Pollard, 1981). Nevertheless, a fundamental problem with this type of clustering is the choice of cluster number as is often unknown. In this situation there is a tendency of mixture models to overfit on real data (Nguyen, 2013). Several works also have addressed this issue through various criteria for choosing optimal cluster numbers including “model-free” approach. Fraley and Raftery (1998) addressed the problem of cluster choice for model-based clustering via BIC criterion, Sugar and James (2003) optimized the cluster number of K-Means through distortion-based measure, Fang and Wang (2012) introduced clustering stability-based idea for choosing optimum cluster number, de Amorim and Hennig (2015) utilized feature rescaling to achieve optimal clusters in K-Means. In this paper, we make four key contributions. First, we theoretically prove that when is unknown, the K-Means algorithm minimizes the underlying loss function as , where is the number of data points. This represents the most complex model possible and ultimately defeats the purpose of clustering. Second, to address this overestimation issue, we propose a penalty function on the number of clusters, which is minimized when , thus encouraging the simplest model. Third, we combine the loss and penalty functions to develop an augmented, penalized version of K-Means, and we study its properties under various tuning parameter selection criteria. Fourth, we address another computational limitation of standard K-Means: its non-recursive optimization. Specifically, for each value of , K-Means restarts the optimization from scratch, without leveraging the solution from the previous iteration. This leads to non-monotonicity in the clustering solution with respect to , as the algorithm explores multiple potentially suitable values. Our modified K-Means algorithm improves this by reusing the solution from the previous step, allowing each optimization for a given to build on the result from -th stage clustering. This not only accelerates computation but also makes the method scalable and manageable for truly massive datasets (as in our example).
The rest of the article is organized as follows. In Section 2, we discuss some issues with standard K-Means clustering and propose remedies to address these problems. Section 3 presents modifications to the K-Means algorithm for the automatic detection of the number of clusters in a dataset. The optimization methodology and the method for tuning parameter selection are elaborated in Sections 4 and 5, respectively. Simulation studies and applications to a real data problem are provided in Sections 6 and 7, respectively. Finally, Section 8 offers concluding discussion with future directions. For the sake of brevity, all proofs have been provided in the supplementary material.
Properties of K-Means Clustering
At first we will concentrate on some convergence properties of standard K-Means clustering problem. Assume the data in hand is matrix , each is a -dimensional vector. In any clustering mechanism, we partition the data matrix into possible clusters with is an assignment set. For center-based clustering, a data point is part of cluster if
where is Euclidean norm and is the center for cluster . Particularly, In K-Means clustering, the main idea is to choose centers and update them in such a fashion so that the sum of distances of all points from their respective cluster center is minimum. Therefore the optimization problem for K-Means solves,
with where represents the cardinality of a set and is the matrix of cluster centers. Theoretically , however in most practical situations and chosen as the maximum plausible cluster number. It is well known that the above optimization works well for known for fixed (MacQueen et al., 1967; Pollard, 1981). However, if the value of the actual cluster number is unknown and treated as a parameter with , the above loss function will yield a trivial minimum at i.e., each observation is its own cluster center and we will have , which is the lowest possible value of the K-Means objective function. The same is true for a slightly more generalized K-Means loss function,
where the distance functions is any norm following these properties,
and attains 0 only if (non-negative property),
(homogeneous property),
(triangular inequality).
Note, Euclidean norm is a special case and in fact for any norm is also going satisfy these conditions. The aforementioned properties of the distance function are the necessary foundations for the proofs of the following propositions and theorems. Next, we will propose a general result on distance norm following the aforementioned properties, for any three p-dimensional points.
For three points , we have
If has the convex form for some then .
For all other , .
The proof is trivial from homogeneous and triangular inequality property of distance function under any norm.
The proposition can be extended for any convex set containing a set of points . In the next Lemma, we propose a result on the optimization under any convex set.
For a convex set , the optimizer of for all will be unique.
Lemma 1 states that, within a convex set, the point that minimizes the sum of distances to all other points in the set is unique. Leveraging this result, one can establish the uniqueness of the solution to a given loss function under the assumption of convexity. Together, this lemma and the preceding proposition provide the foundational tools necessary to prove the next two theorems, demonstrating that the solution to the optimization problem under consideration in K-Means (in equation 1) is indeed unique when the convexity condition is satisfied. It is to be noted that, if is the cluster center of cluster then we consider center as, , i.e., each cluster center can be represented as a convex combination of the points in the cluster. The characteristic of solution to the K-Means optimization described in equation (1) with unknown is described in the next theorem.
The loss function is a monotone decreasing function in and reaches its minima at , for each .
Theorem 1 shows that unless we specify the cluster number of a K-Means, the underlying optimization problem denoted by will always encourage more complex model with high number of clusters. In other words, given as a cluster center matrix, if we introduce another cluster center by optimizing equation (1) to get cluster center matrix , then it is guaranteed to hold . Thus, the naive K-Means for an unknown number of clusters is an ill-posed problem, which necessitate a penalty parameter to guard against it.
It is evident from Theorem 1, K-Means with unknown will always encourage a large number of clusters and the need to regularize the optimization function in equation (1) to prevent overfitting. The penalty term chosen for this work is,
Since the contribution of the penalty term is only for the clusters that are alive i.e., if both and is 1, therefore we can reduce the penalty as
It is to be noted here that has a trivial minimum at since all the observations fall within a single cluster and will have higher values as . In a sense, it behaves exactly oppositely to that of the loss function in equation (1). This type of penalty function using the Gaussian norm was first considered by our group in Ghosh and Dey (2009). Later Hocking et al. (2011) considered a and Lindsten et al. (2011) considered a penalized version of it. Though intuitively this makes sense, but none of these developments are without any direct proof about the properties of the considered penalty. In Theorem 2 we study the behavior of the penalty as a function of the .
The penalty is a monotone increasing function in and attains maximum at , under the assumption that each cluster center lies in the convex hull of the cluster .
Theorem 2 states that when the number of clusters varies, the proposed penalty when minimized will always favor the simplest model, i.e., one in which all points belong to a single cluster. Furthermore, as we increase the number of clusters from to in the same -dimensional feature space, the corresponding penalty values satisfy and the penalty reaches its maximum when . This behavior of the penalty term, when combined with the loss function in equation (1), provides the necessary balance for selecting the optimal value of .
In the next section, we describe an augmented versus of K-Means clustering which combines the loss (in equation (1)) and penalty (in equation (2)) in a regularized framework. The monotone nature of both terms ensures parsimonious model selection, with appropriately chosen regularization parameter.
Reformulation of K-Means Clustering
The augmented version of the K-Means problem solves following optimization problem,
The first part of the optimization governs the assignment of data points to clusters, while the second part constrains the number of cluster centers. Thus, with an appropriate choice of the tuning parameter , the augmented K-Means simultaneously optimizes both the cluster centers and the number of clusters. Next, we reformulate the optimization problem in equation (3) using matrix notation, where denotes cluster assignment matrix
Each element of denotes the cluster assignment of observation , whereas is the matrix of cluster centers. Thus equation (3) can be reformulated as,
where denotes the -th row of . Note, that the optimization problem stated above is fairly general and should work for any choice of distance norm, though, for the K-Means algorithm with continuous features, the natural choice is Euclidean norm or it squared version. It should be also noted different non-concave norms can be also chosen separately for loss and penalty terms as it is done in the regression context for LASSO type problems (Bach et al., 2012) and clustering via regression-based approach Wu et al. (2016). Albeit, the different norms in Loss and Penalty will lead to differential contraction (Grossmann & Winkler, 2013) which needs to be studied further theoretically, this may also be dictated by the nature of feature space (e.g., discrete, continuous, Boolean, etc.) based on which clustering is performed. For this work, we stick to squared error loss (or square of Euclidean norm) due to its acceptability and ease of computation. Under that we have the following optimization problem,
The loss function in above equation can be rewritten as Whereas it can be easily shown that the difference between cluster centers can be written as, where is a -dimensional vector of zero’s with at -th position. Thus our optimization problem of 5 boils down to
Note that we still need to pre-specify a value of (as an upper limit) for the optimization in equation (6). Given this value, our algorithm is capable of selecting the optimal number of clusters within the range . The most liberal choice of is the total number of samples or . However, this choice comes with a potential drawback: longer run-times, as the computational complexity of K-Means is proportional to the upper limit of the possible number of clusters. In most practical scenarios, and thus, the runtime can be significantly reduced by choosing a that is not too large.
Optimization of Augmented K-Means Clustering
In this section, we discuss the optimization of the penalized K-Means problem defined in equation (6) and provide an algorithm to determine the optimal number of clusters for a given tuning parameter . To obtain the optimized cluster centers, we differentiate equation (6) with respect to and equate to and obtain,
More simplification of equation (7) is possible through some algebraic manipulation. Following Chi and Lange (2015), for we can obtain,
where is a length vector of 1 and is a indicator matrix. Moreover, the matrix in the right-hand side of equation (8) is symmetric. Therefore, from equation (7) and (8), solution to the estimated cluster centers for a fixed number of cluster (in this case, ) are,
We have also derived an unbiased estimator of the degrees of freedom for the fitted model (see Appendix 4), which can be used to compute any goodness-of-fit statistic. Note that for a fixed number of clusters, the optimized cluster centers can be estimated directly. However, the problem at hand involves simultaneously estimation of both the number of clusters and the cluster centers. To address this, we propose Algorithm ??, which performs a grid search to jointly optimize the cluster number and the estimated cluster centers . Using Algorithm ??, one can obtain appropriate cluster assignments for all data points. Note that the algorithm operates for a fixed value of the tuning parameter . Since the optimization problem includes a penalty on the cluster centers, the value of influences both the number of clusters and the resulting cluster centers. As with any regularization-based approach, selecting an appropriate tuning parameter is crucial in penalized K-Means. It significantly impacts not only the quality of the resulting clustering but also the convergence behavior of the algorithm. In the following section, we describe the criteria used for selecting the tuning parameter.
Selection of Tuning Parameter
The estimated number of clusters and the corresponding cluster assignments in penalized K-Means clustering depend on the value of the non-negative tuning parameter . Smaller values of tend to yield more clusters, while larger values encourage fewer clusters, thereby controlling the trade-off between model fit and model complexity. To appropriately tune , we adopt a clustering stability-based approach, as proposed in Fang and Wang (2012), Sun et al. (2012) and Wang et al. (2016) for the penalized K-Means framework. A cluster assignment is considered stable if perturbations in the data (e.g., through subsampling) result in minimal changes to the clustering outcome. The stability measure utilized in Sun et al. (2012) and Wang et al. (2016), tunes both the number of clusters and the Lagrangian tuning parameter . However, since the penalized K-Means algorithm provides the optimal number of clusters for fixed , we adapt the stability-based selection procedure to optimize only the tuning parameter . The modified stability selection mechanism for identifying the most appropriate value of along with the corresponding for a given dataset is described next.
Suppose that we have optimized the Algorithm 1 on the set of values, to obtain corresponding cluster assignments with estimated number of clusters respectively. If available, then let us denote the original assignments or true labels as . Draw many bootstrap samples without replacement , each with observation from the original data . Remember for fixed we have optimized assignment with clusters for . Therefore for each we optimize Algorithm 1 on each bootstrap sample such that, we obtain exactly clusters with assignments where denoting the bootstrap sample. We define two types of stability measure,
If the true labels are available then we define the true stability as the average agreement between the true labels and the predicted assignments in the bootstrap samples,
where is some concordance measure between the cluster assignments.
For data without any class or label information, the predicted stability measure is defined as the average concordance between the predicted cluster assignment and the corresponding cluster assignments on the bootstrap samples , evaluated using a chosen measure of association ,
A common choice for the association/concordance measure in is the Rand Index (Rand, 1971). The stability index defined in Sun et al. (2012) can be written in terms of Rand Index as, , with two cluster assignments and . Several drawbacks of the Rand Index as a similarity measure have been identified. Morey and Agresti (1984) and Fowlkes and Mallows (1983) showed the high dependence of the Rand Index on the number of clusters and it converges to 1 with an increase of cluster number, which we also have observed. Moreover Rand Index also suffers from association by random chance. Thus it yields higher values for certain random clustering that does not coincide with the true labeling of the data. Nonetheless, the concept of concordance captured by the Rand Index remains valuable, particularly for detecting the number of clusters. To address these limitations, we adopt the Adjusted Rand Index (ARI; see Halkidi et al., 2002; Hubert & Arabie, 1985) as the measure of association . ARI is a standardized version of the Rand Index that corrects for both random chance and the inflation caused by higher numbers of clusters. ARI index value is equal or close to 1 only for the homogeneous assignments on bootstrap samples and true/predicted assignments and close to 0 for a random partition. The best value of tuning parameter and corresponding cluster number is chosen as
If multiple values of produce the optimal , then we choose the best and in the following manner. Let are the values corresponding to optimal with cluster numbers respectively. Then we have the optimal cluster number, and estimate of the tuning parameter
Simulation Study
The performance of the augmented K-Means clustering algorithm is first evaluated on several simulated benchmark datasets. Four separate benchmark datasets are selected for testing purposes, as detailed below:
Three Gaussian clusters (Tan & Witten, 2015) are generated with and . The data matrix is generated from . The mean vectors are assigned as respectively for three clusters. The points are equally distributed among the three clusters such that each point corresponds to a unique cluster.
Second simulated setup is the four corners data from Karami and Johansson (2014). A total number of points are chosen in such a way that each belongs to a specific corner.
The outlier data (Karami & Johansson, 2014) with points are also considered in the simulation study. Data consists of two large half-circular regions and two smaller outlier regions.
The final benchmark dataset used in the simulation study is the crescent full moon dataset (Karami & Johansson, 2014), which consists of 500 data points arranged in a circular region and another 500 points forming a half-moon shape.
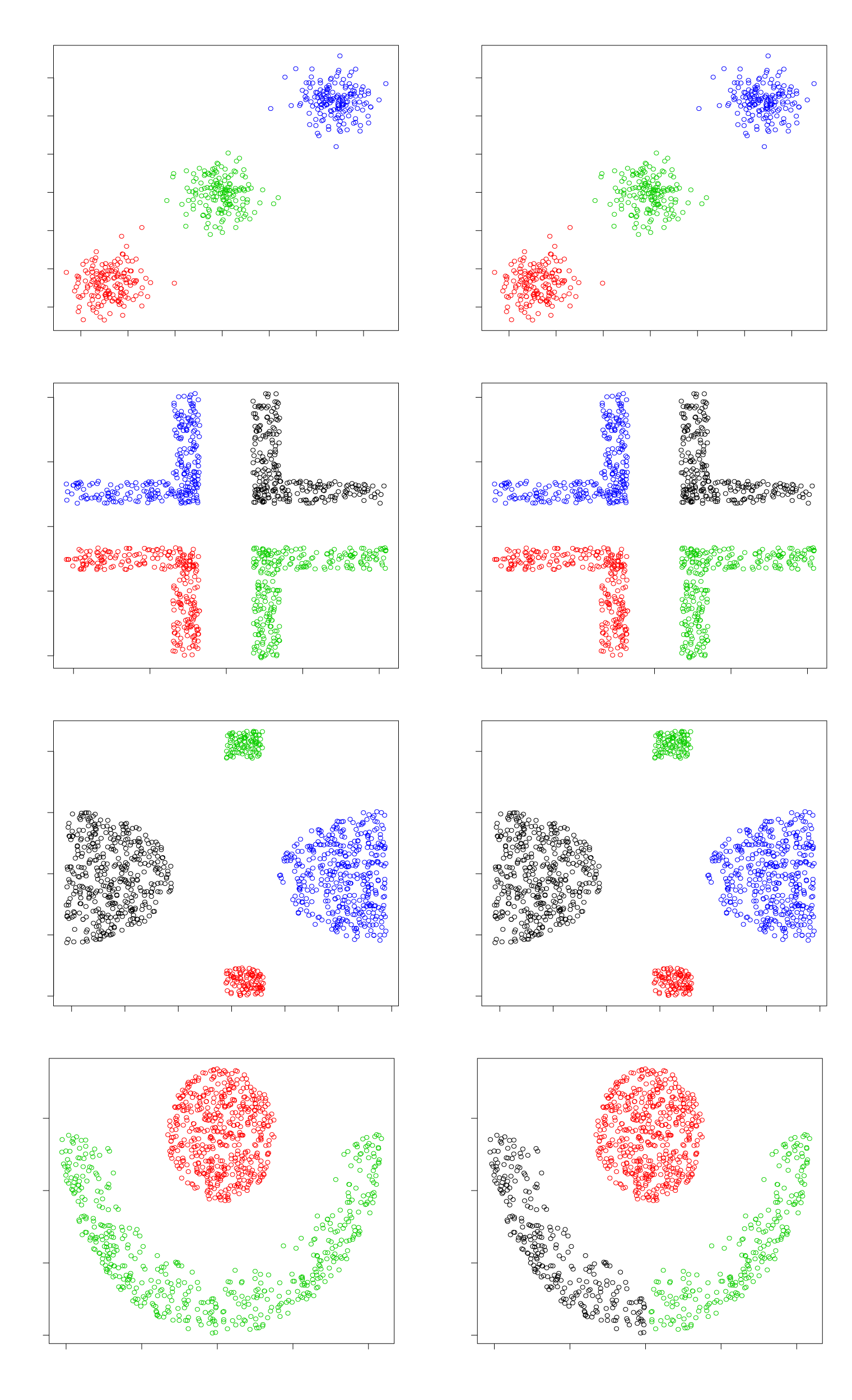
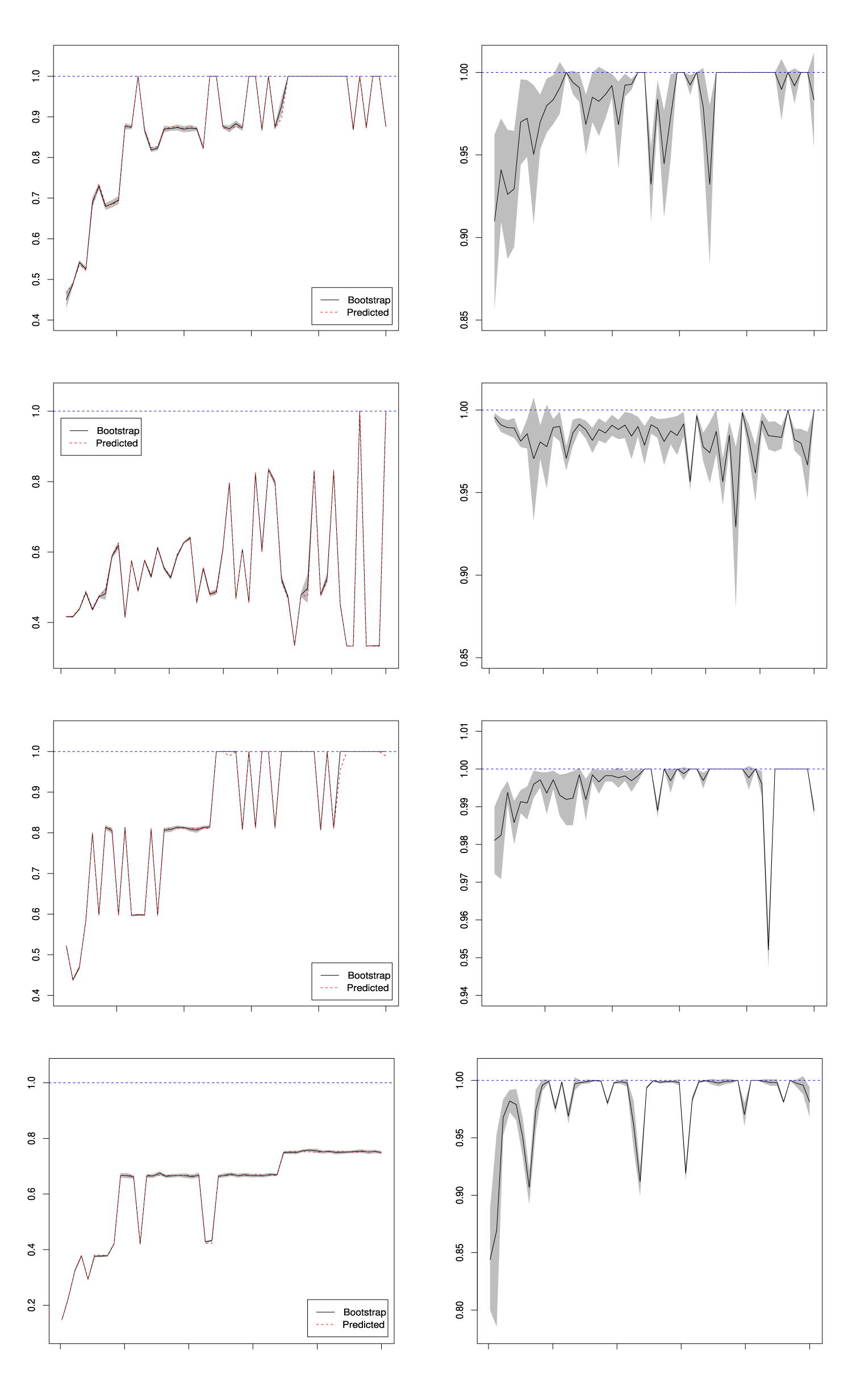
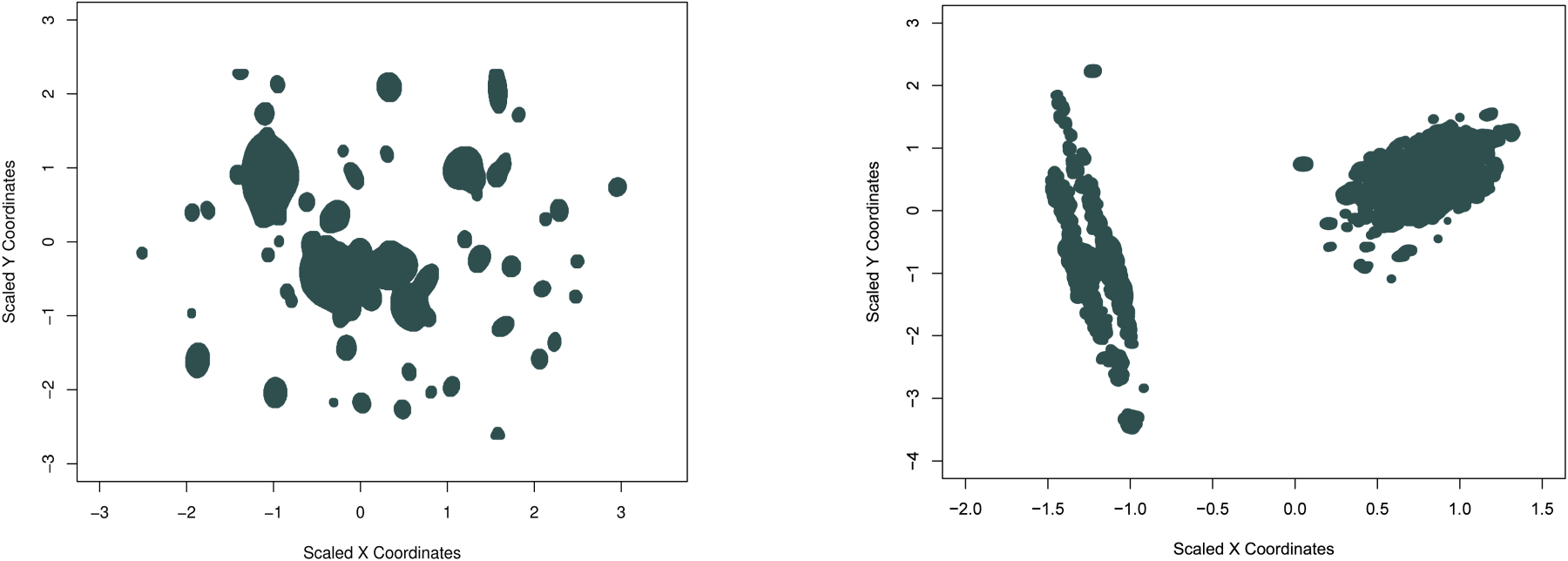
On each of the datasets, we have optimized the penalized K-Means algorithm on a grid of values. For each , the algorithm is optimized to obtain the best cluster number . The optimum and corresponding cluster number is chosen via the stability measure mentioned above. Figure 1 illustrates the original cluster assignments alongside the best predicted cluster assignments for the four simulated examples. The first row of the panel corresponds to the Gaussian clusters, the second row to the corners data, the third row to the outlier data, and the fourth row to the crescent full moon dataset. The proposed augmented K-Means clustering method accurately detects both the number and the locations of clusters in all cases, with the exception of the crescent full moon data. In that case, the method partitions the crescent moon into two separate clusters. This result is not unexpected, as a key assumption in augmented K-Means is that the cluster center should lie within the convex hull of the points in that cluster. This assumption is violated in non-convex structures like the crescent moon. Thus, for the non-convex shape of the crescent moon, the best possible clustering while adhering to the convex center construction constraint is shown in the last plot of the right panel in Figure 1. It is worth noting that with an appropriate choice of a loss function that accounts for non-convex cluster structures, it is possible to modify the optimization problem presented in equation (3). However, such a modification would require further methodological developments to effectively solve the resulting optimization problem, which is beyond the scope of the current paper.
True Cluster Assignment (Left Panel) vs. Predicted Cluster Assignments (Right Panel). The X and Y Axes Represent the Two Dimensions Used for Data Generation and Clustering.
The next panel of plots in Figure 2 demonstrates the performance of the augmented K-Means clustering algorithm for different values of tuning parameter . In all the plots, we kept the values of along the x-axis, and the versions of the ARI along the y-axis. The plots are arranged in the same order of benchmark datasets as Figure 1. The plots on the left panel show the predicted ARI (in red dashed line) and the bootstrap version of ARI (solid black line) calculated with respect to the true response values. The close resemblance between the two curves is clearly visible, showing the stability of the proposed measure for identifying the best tuning parameter. The preferred choice of clusters is the clusters corresponding to the chosen tuning parameter. We see several ties of values (yielding ARI as ) in the first three plots in the left panel of Figure 2. In those cases, the best choice of is determined as mentioned in Section 5, which is the minimum value yielding one. This is not true for the fourth dataset of crescent full moon though, where ARI never reached unity as the best clustering detected by our algorithm is not an exact match with the truth. The plots in the right panel show the predicted ARI (solid line) along with its confidence bound with respect to the predicted clusters for each value of . An almost identical pattern as the true ARI (in the left panel) can be noticed for the predicted ARI. A similar idea is implemented to break the ties and choose the best values of tuning parameter and corresponding optimum cluster assignments. The plots in the right panel of Figure 1 showing the cluster assignments correspond to the optimum choice of chosen through the predicted ARI. Note that for real data though, we do not observe any response/outcome, calculating the ARI is therefore infeasible and we resort to the predicted ARI, to optimize the tuning parameter for the proposed augmented K-Means algorithm.
True and Bootstrap Version of Adjusted Rand Index (Left Panel) and the Predicted Adjusted Rand Index (Right Panel) in the Y-axis and for Different Values of Along the X-axis.
Application on Globular Clusters Detection
Clustering is a very common problem with many application domains and as such our algorithm proposed in this article is fairly general. We choose the field of astronomy as the detection of star clusters and galaxies is a very important and challenging problem with unknown cluster numbers. This field often produces a single image large enough so that it cannot be loaded in the memory of a personal computer resulting in truly Big Data () (Estévez, 2016; Loredo et al., 2009; Mickaelian et al., 2016). For our purpose, we considered publicly available NASA Hubble telescope images. These galaxy(s) or star clusters are globular in nature and thus can be categorized into convex clusters via a clustering mechanism based on centers. We intend to test the performance of the augmented K-Means algorithm to detect the number and location of globular clusters present in an image of galaxies and star clusters. Two separate images with distinct characteristics are considered for this work, both downloaded from NASA (2015) and NASA (2017) respectively. Figure 3 shows the original images, with lots of possible galaxy and star clusters from Hubble deep space image (left) and two sister galaxy images (right). Some pre-processing mechanism was implemented on the images to remove the noises before running the clustering mechanism. The image pre-processing steps are as follows,
First we converted the color image to gray-scale. This is done as otherwise color temperature at each pixel poses as a separate dimension.
The images are then processed, in order to remove the background noises and detect pixel values (location and intensities).
Pixels are segmented and those with intensities more than the percentile are considered for the analysis, rest ignored.
Image data are arranged to have a final data frame with pixel locations and corresponding gray-scale intensities.
Note that, other pixel intensity percentiles can be considered, but we stick with as it provided the best noise reduction of the images. We utilized the (R Core Team, 2015) package “imager” (Simon, 2017) for the image pre-processing. After pre-processing, the denoised images are shown in Figure 4, where the colored space is the pixels considered for the clustering analysis. Before denoising the Hubble deep space image, we had around pixels and their corresponding intensity values, which were reduced to after the pre-processing. Similarly, for two sister galaxy images, we had pixels which after noise reduction was scaled down to pixels for the final analysis. Analogous to the simulation study we optimized the augmented K-Means algorithm for each tuning parameter value to obtain the predicted clusters. We have chosen a fine grid of values ranging from 0 to 10, for our analysis. The number of possible cluster numbers are considered as 100 and 10 respectively for the two data sets. The model optimization is computationally expensive and requires large memory for both data and storage. Thus, is not possible to run on normal desktops or laptops even with parallel frameworks. We utilized the grid computing nodes of Wayne State University to run the optimization algorithm and final prediction.
Lots of Galaxies Image (Left) and Two Galaxies Image (Right).
Image After Preprocessing for Galaxy Cluster Data (Left Panel) and Two Sister Cluster (Right Panel).
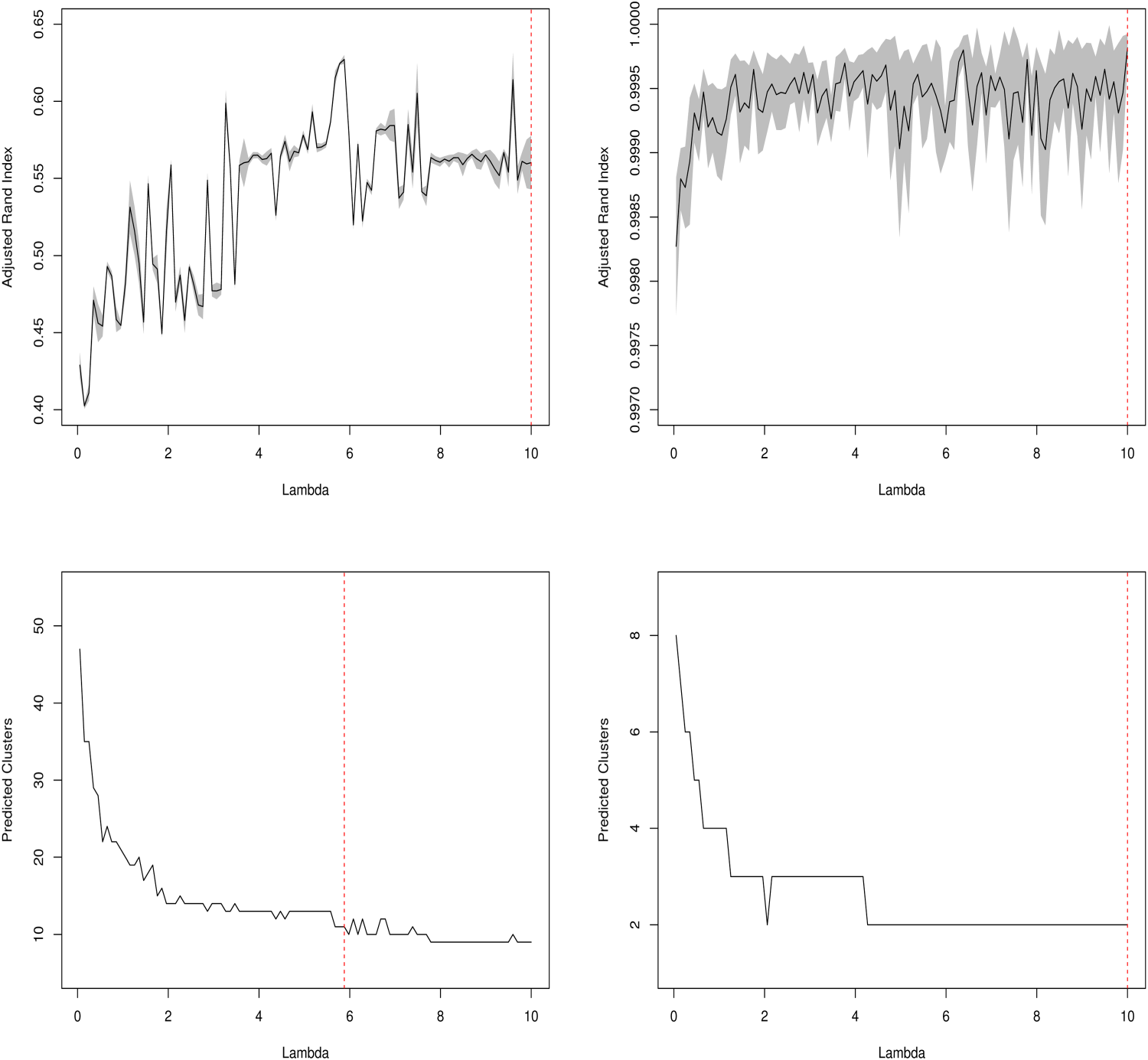
Predicted Adjusted Rand Index ( Row) and the Estimated Clusters ( Row) for Galaxy Cluster Data (Left Panel) and Two Sister Cluster (Right Panel) with the Predicted Tuning Parameter (Red Dashed Line).
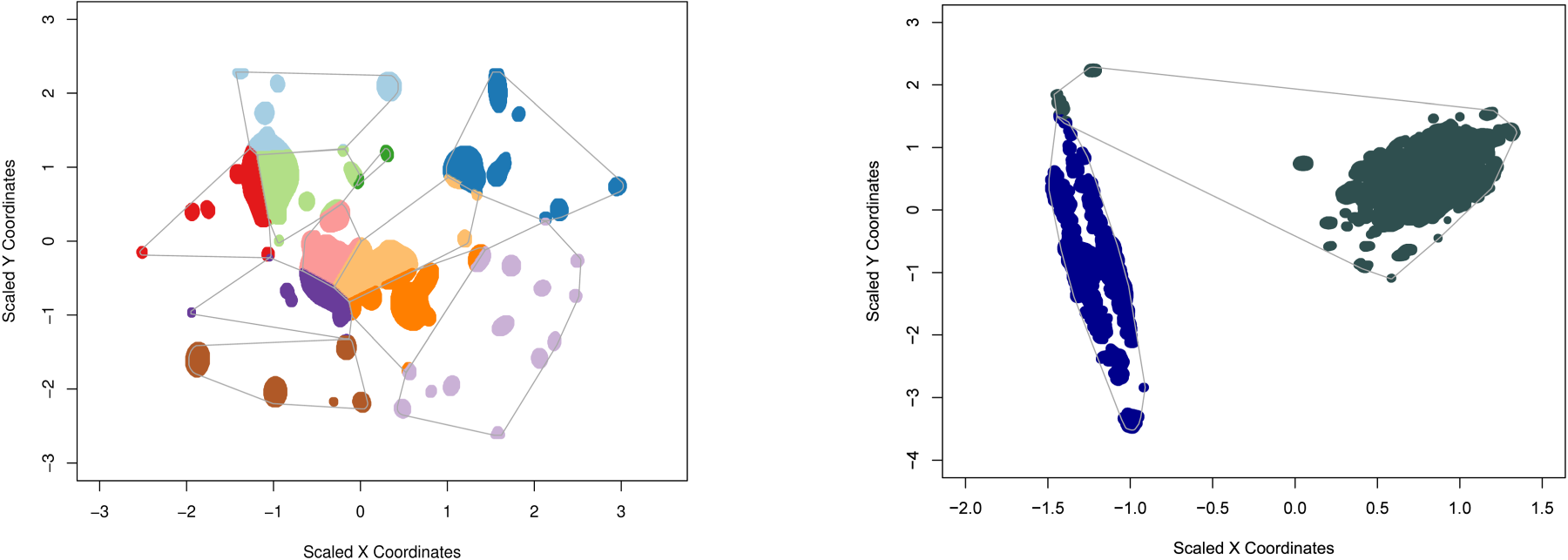
Predicted Clusters and Corresponding Assignments for (Left) Galaxy Cluster Data with 11 Clusters and (Right) Two Sister Galaxy with 2 Clusters. The Line Within Each Figure Indicates the Outer Shape of Each Cluster.
The next panel of plots in Figure 4 shows the images after the pre-processing and thresholding. In Figure 5 we have plotted the predicted ARI values and the estimated clusters for both datasets. An optimum value of the tuning parameter is presented as the red dashed line. For all the plots, we kept the values of along the x-axis the predicted ARI (for 1st row of the panel), and the predicted cluster number (for 2nd row of the panel) along the y-axis. It can be observed that the optimum cluster number for the Hubble deep space image is 11 whereas 2 clusters are observed for two sister galaxies. Finally in Figure 6, we have shown the best cluster assignments among different galaxies. A point to note is that the images (as drawn) are the 2D representation of the original 3D space (consisting of pixel x-coordinate, pixel y-coordinate, and intensities). Moreover, the optimization of clusters is done in the transformed space rather than the original space. If we revert to the original space, the assignments are better, but the pictorial demonstration is not optimum.
Conclusion and Future Direction
Despite its limitations and computational challenges when applied to large, heterogeneous datasets, K-means clustering remains one of the oldest and most widely used clustering algorithms. However, traditional K-means is prone to overfitting and often converges to local minima. In this work, we revisit the method with the aim of mathematically characterizing some of its limitations. To address these issues, we propose a penalized version of K-means clustering that enables automated selection of the number of clusters, followed by cluster assignment. Our approach relies on the appropriate selection of a tuning parameter, which plays a crucial role in balancing model complexity and fit. There are several directions in which this work can be extended, and we outline a few of these as potential avenues for future research.
In typical cluster analysis, all available features are often assumed to be useful. However, in practice, not all features are equally informative—or even relevant—for the clustering task. This motivates the incorporation of feature selection prior to clustering, as discussed in Raftery and Dean (2006) and Witten and Tibshirani (2010). Effective feature selection can significantly influence the resulting cluster structure, including the estimated number of clusters. However, stepwise procedures—where features are selected first and the number of clusters is determined afterward—may be suboptimal, as errors introduced in the earlier step cannot be corrected later. Consequently, the simultaneous selection of relevant features and the optimal number of clusters remains a challenging and largely unresolved problem.
As noted throughout the paper, our method is based on K-means and is therefore best suited for convex clusters, where the notion of a cluster center is naturally meaningful. However, real-world data often exhibit non-convex or even irregularly shaped clusters, where this concept becomes less interpretable. In such cases, alternative formulations of the clustering objective are required. Pan et al. (2013) investigated clustering methods involving non-convex penalties, and more recently, Wu et al. (2016) proposed computationally efficient adaptations of such approaches. Nevertheless, both studies continued to rely on convex loss or distance functions. The estimation of the number of clusters under non-convex loss functions remains a challenging and largely unresolved problem.
Centroid-based clustering under non-convex metrics represents a compelling area for future research, posing both theoretical and computational challenges. Another promising direction involves clustering data that do not follow a continuous distribution, which demands the development of novel distance metrics. Identifying the number of clusters in such settings presents an intriguing and worthwhile avenue for further investigation.
Supplemental Material
sj-pdf-1-mod-10.1177_15741699251377692 - Supplemental material for Penalized K-Means Clustering: Another Look at Its Statistical Properties
Supplemental material, sj-pdf-1-mod-10.1177_15741699251377692 for Penalized K-Means Clustering: Another Look at Its Statistical Properties by Prithish Banerjee, Shreyo Ghosh and Samiran Ghosh in Model Assisted Statistics and Applications
Footnotes
Acknowledgments
The suggestions from the three referees and other members of the editorial team have greatly helped in polishing the paper.
ORCID iD
Samiran Ghosh
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental materials for this article are available online.
ChiE. C.LangeK. (2015). Splitting methods for convex clustering. Journal of Computational and Graphical Statistics, 24(4), 994–1013.
3.
de AmorimR. C.HennigC. (2015). Recovering the number of clusters in data sets with noise features using feature rescaling factors. Information Sciences, 324, 126–145.
4.
EsterM.KriegelH.-P.SanderJ.XuX. (1996). A density-based algorithm for discovering clusters in large spatial databases with noise. In KDD (Vol. 96, pp. 226–231).
5.
EstévezP. A. (2016). Big data era challenges and opportunities in astronomy-how SOM/LVQ and related learning methods can contribute? In WSOM (p. 267).
6.
FangY.WangJ. (2012). Selection of the number of clusters via the bootstrap method. Computational Statistics & Data Analysis, 56(3), 468–477.
7.
FowlkesE. B.MallowsC. L. (1983). A method for comparing two hierarchical clusterings. Journal of the American Statistical Association, 78(383), 553–569.
8.
FraleyC.RafteryA. E. (1998). How many clusters? Which clustering method? Answers via model-based cluster analysis. The Computer Journal, 41(8), 578–588.
9.
GhoshS.DeyD. K. (2009). Model based penalized clustering for multivariate data. In Advances in multivariate statistical methods (pp. 53–71). World Scientific.
10.
GrossmannC.WinklerM. (2013). Mesh-independent convergence of penalty methods applied to optimal control with partial differential equations. Optimization, 62(5), 629–647.
11.
HalkidiM.BatistakisY.VazirgiannisM. (2002). Cluster validity methods: Part I. ACM Sigmod Record, 31(2), 40–45.
12.
HockingT. D.JoulinA.BachF.VertJ. -P. (2011). Clusterpath an algorithm for clustering using convex fusion penalties.
13.
HubertL.ArabieP. (1985). Comparing partitions. Journal of Classification, 2(1), 193–218.
14.
KaramiA.JohanssonR. (2014). Choosing DBSCAN parameters automatically using differential evolution. International Journal of Computer Applications, 91(7), 1–11.
15.
LindstenF.OhlssonH.LjungL. (2011). Clustering using sum-of-norms regularization: With application to particle filter output computation. In 2011 IEEE statistical signal processing workshop (SSP) (pp. 201–204). IEEE.
16.
LoredoT. J.RiceJ.SteinM. L. (2009). Introduction to papers on astrostatistics. Annals of Applied Statistics, 1, 1.
17.
MacQueenJ. (1967). Some methods for classification and analysis of multivariate observations. In Proceedings of the fifth Berkeley symposium on mathematical statistics and probability (Vol. 1, pp. 281–297).
18.
MickaelianA. M.AbrahamyanH. V.GyulzadyanM. V.MikayelyanG. A.ParonyanG. M. (2016). Multi-wavelength studies of the statistical properties of active galaxies using big data. Proceedings of the International Astronomical Union, 12(S325), 32–38.
19.
MoreyL. C.AgrestiA. (1984). The measurement of classification agreement: An adjustment to the rand statistic for chance agreement. Educational and Psychological Measurement, 44(1), 33–37.
NguyenX. (2013). Convergence of latent mixing measures in finite and infinite mixture models. The Annals of Statistics, 41(1), 370.
23.
PanW.ShenX.LiuB. (2013). Cluster analysis: Unsupervised learning via supervised learning with a non-convex penalty. The Journal of Machine Learning Research, 14(1), 1865–1889.
24.
PollardD. (1981). Strong consistency of k-means clustering. The Annals of Statistics, 9(1), 135–140.
25.
RadchenkoP.MukherjeeG. (2017). Convex clustering via l1 fusion penalization. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 79(5), 1527–1546.
26.
RafteryA. E.DeanN. (2006). Variable selection for model-based clustering. Journal of the American Statistical Association, 101(473), 168–178.
27.
RandW. M. (1971). Objective criteria for the evaluation of clustering methods. Journal of the American Statistical Association, 66(336), 846–850.
28.
R Core Team. (2015). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria.
29.
ShiJ.MalikJ. (2000). Normalized cuts and image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(8), 888–905.
30.
SimonB. (2017). imager: Image processing library based on ’CImg’. R package version 0.40.2.
31.
SugarC. A.JamesG. M. (2003). Finding the number of clusters in a dataset: An information-theoretic approach. Journal of the American Statistical Association, 98(463), 750–763.
32.
SunW.WangJ.FangY. (2012). Regularized k-means clustering of high-dimensional data and its asymptotic consistency. Electronic Journal of Statistics, 6, 148–167.
33.
TanK. M.WittenD. (2015). Statistical properties of convex clustering. Electronic Journal of Statistics, 9(2), 2324.
WittenD. M.TibshiraniR. (2010). A framework for feature selection in clustering. Journal of the American Statistical Association, 105(490), 713–726.
36.
WuC.KwonS.ShenX.PanW. (2016). A new algorithm and theory for penalized regression-based clustering. The Journal of Machine Learning Research, 17(1), 6479–6503.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.