
Abstract
Background:
Advancements in artificial intelligence technology, such as OpenAI’s large language model, ChatGPT, could transform medicine through applications in a clinical setting. This study aimed to assess the utility of ChatGPT as a clinical assistant in an orthopedic hand clinic.
Methods:
Nine clinical vignettes, describing various common and uncommon hand pathologies, were constructed and reviewed by 4 fellowship-trained orthopedic hand surgeons and an orthopedic resident. ChatGPT was given these vignettes and asked to generate a differential diagnosis, potential workup plan, and provide treatment options for its top differential. Responses were graded for accuracy and the overall utility scored on a 5-point Likert scale.
Results:
The diagnostic accuracy of ChatGPT was 7 out of 9 cases, indicating an overall accuracy rate of 78%. ChatGPT was less reliable with more complex pathologies and failed to identify an intentionally incorrect presentation. ChatGPT received a score of 3.8 ± 1.4 for correct diagnosis, 3.4 ± 1.4 for helpfulness in guiding patient management, 4.1 ± 1.0 for appropriate workup for the actual diagnosis, 4.3 ± 0.8 for an appropriate recommended treatment plan for the diagnosis, and 4.4 ± 0.8 for the helpfulness of treatment options in managing patients.
Conclusion:
ChatGPT was successful in diagnosing most of the conditions; however, the overall utility of its advice was variable. While it performed well in recommending treatments, it faced difficulties in providing appropriate diagnoses for uncommon pathologies. In addition, it failed to identify an obvious error in presenting pathology.
Keywords
Introduction
The emergence of ChatGPT, a large language model (LLM) developed by OpenAI, has sparked discussions across disciplines on potential applications in research, education, and clinical practice. 1 ChatGPT is a generative pretrained transformer, meaning it is a neural network that has been trained on a vast quantity of text. It can answer a variety of queries, via a novel text response, in a human-like manner. While it has no specific medical training, it has access to massive quantities of data, allowing it to answer many scientific and clinical questions. Indeed, Kung et al 2 reported that ChatGPT was able to pass the United States Medical Licensing Examination (USMLE) battery of examinations and suggested that LLMs have the potential to aid in clinical decision-making.
While these results are promising, there remains significant work before this technology can be safely and efficiently incorporated into a clinical setting. For example, Patel and Lam proposed the application of ChatGPT to discharge summaries and provided an example of an AI-generated summary; however, they did not assess this application in any rigorous or systematic way. 3 Furthermore, not all proposed applications have been successful. Wagner and Ertl-Wagner found that, when prompted with questions pertaining to clinical radiology, a third of ChatGPT-generated responses were incorrect, and references provided were either incorrect or inauthentic. 4 Still, Lee et al 1 suggested the possibility for ChatGPT to provide “curbside consults,” noting its ability to synthesize large quantities of data, such as those in medical records. Finally, a recent publication by Seth et al 5 demonstrated the ability of ChatGPT to provide general information regarding carpal tunnel syndrome to patients. They suggested that LLMs could potentially function as supportive tools for clinicians.
Similarly, multiple papers from salient literature, cited in our manuscript, suggest LLMs had the potential to aid in clinical tasks.6-11 Furthermore, an updated GPT, known as GPT-4, with more advanced capabilities was recently released. 12 This study aims to assess GPT-4’s ability to diagnose conditions, suggest an appropriate workup, and provide treatment options to assist orthopedic surgeons in the clinical setting.
Methods
Nine original clinical vignettes, representing various presentations of both common and uncommon hand pathology based on real patients, were prepared by an orthopedic surgery resident and an independently practicing fellowship-trained orthopedic hand surgeon. The conditions included trigger finger, Dupuytren’s contracture, sagittal band rupture, radial nerve palsy, lateral epicondylitis, De Quervain’s tenosynovitis, posterior interosseous nerve syndrome, swan neck deformity, and mallet finger. ChatGPT was presented with these vignettes and instructed to generate a differential diagnosis, create a workup plan, and expound on treatment options as if it were assisting a surgeon in an orthopedic hand clinic.
To ensure fair testing, ChatGPT was allowed to justify its reasoning if it failed to include the correct diagnosis in its differential. In addition, to test ChatGPT’s attention to detail, one of the diagnoses (radial nerve palsy) was presented with an incorrect nerve distribution.
Once ChatGPT responded to all the vignettes, 4 independently practicing fellowship-trained orthopedic hand surgeons scored ChatGPT’s response on 3 criteria: correctness (was the diagnosis, workup, and treatment correct), appropriateness (was the workup and treatment appropriate for the patient in the vignette), and helpfulness (was the diagnosis and treatment helpful for general orthopaedist, generalist, or hand surgeon who may not have experience with the pathology). They used a Likert scale ranging from 5 (strongly agree) to 1 (strongly disagree), and scores were averaged between all fellowship-trained orthopedic hand surgeons across all 9 vignettes. After independently scoring the responses, the surgeons came together and discussed each response to generate a consensus statement on ChatGPT’s diagnosis, workup, and treatment. Any dissenting opinions from the surgeons are supported via citations to the relevant literature. The vignette for trigger finger and the associated response can be seen in Table 1. All vignettes were presented and scored in a similar fashion. All other vignettes and surgeon consensus can be found in supplemental tables (Supplemental Table 1, Supplemental Table 2, Supplemental Table 3, Supplemental Table 4, Supplemental Table 5, Supplemental Table 6) and individual responses for each vignette in Figures 1 to 3.
Trigger Finger.

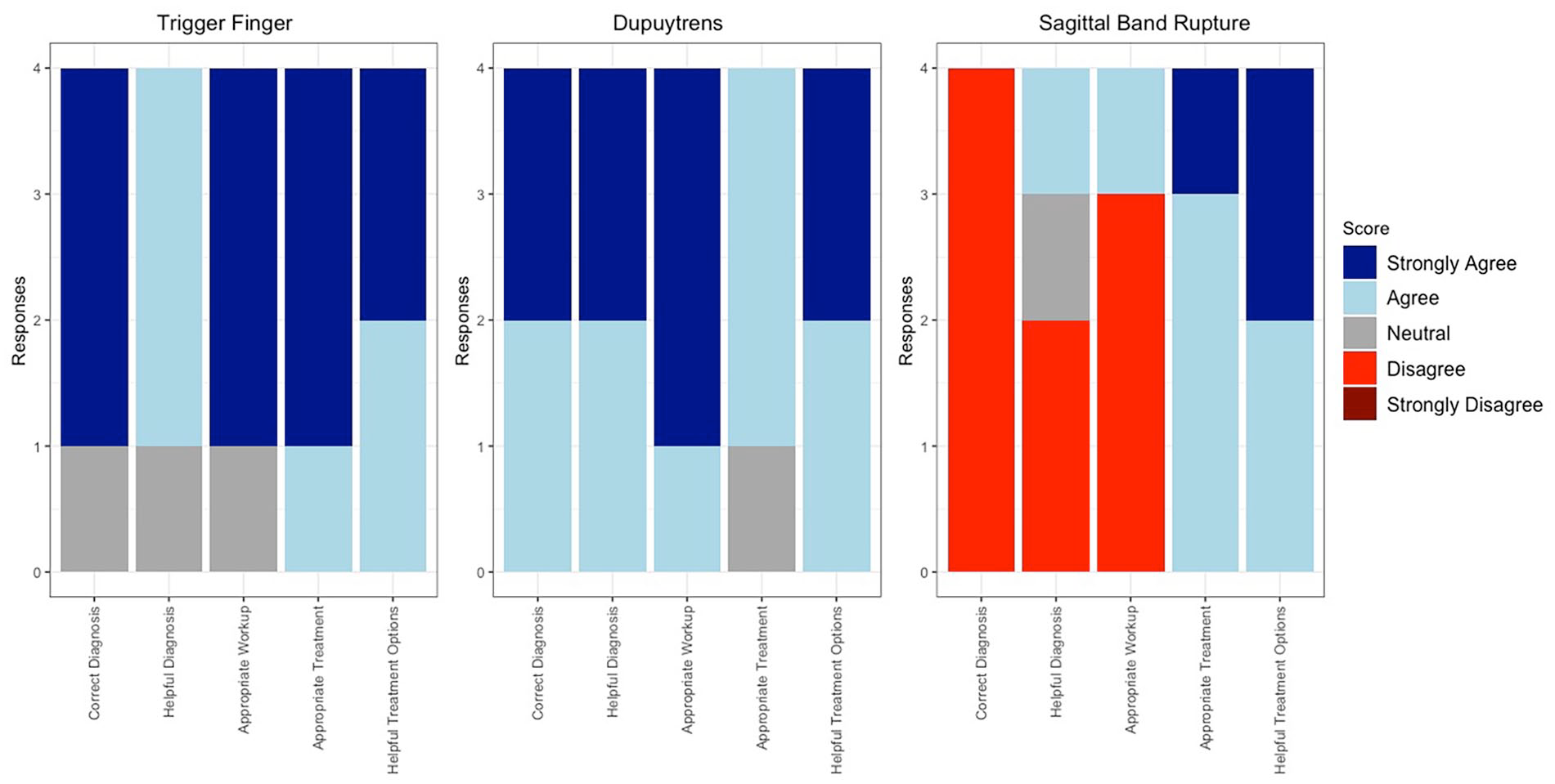
Stacked bar graph depicting individual surgeon responses to each vignette’s 1, 2, and 3 Likert survey.
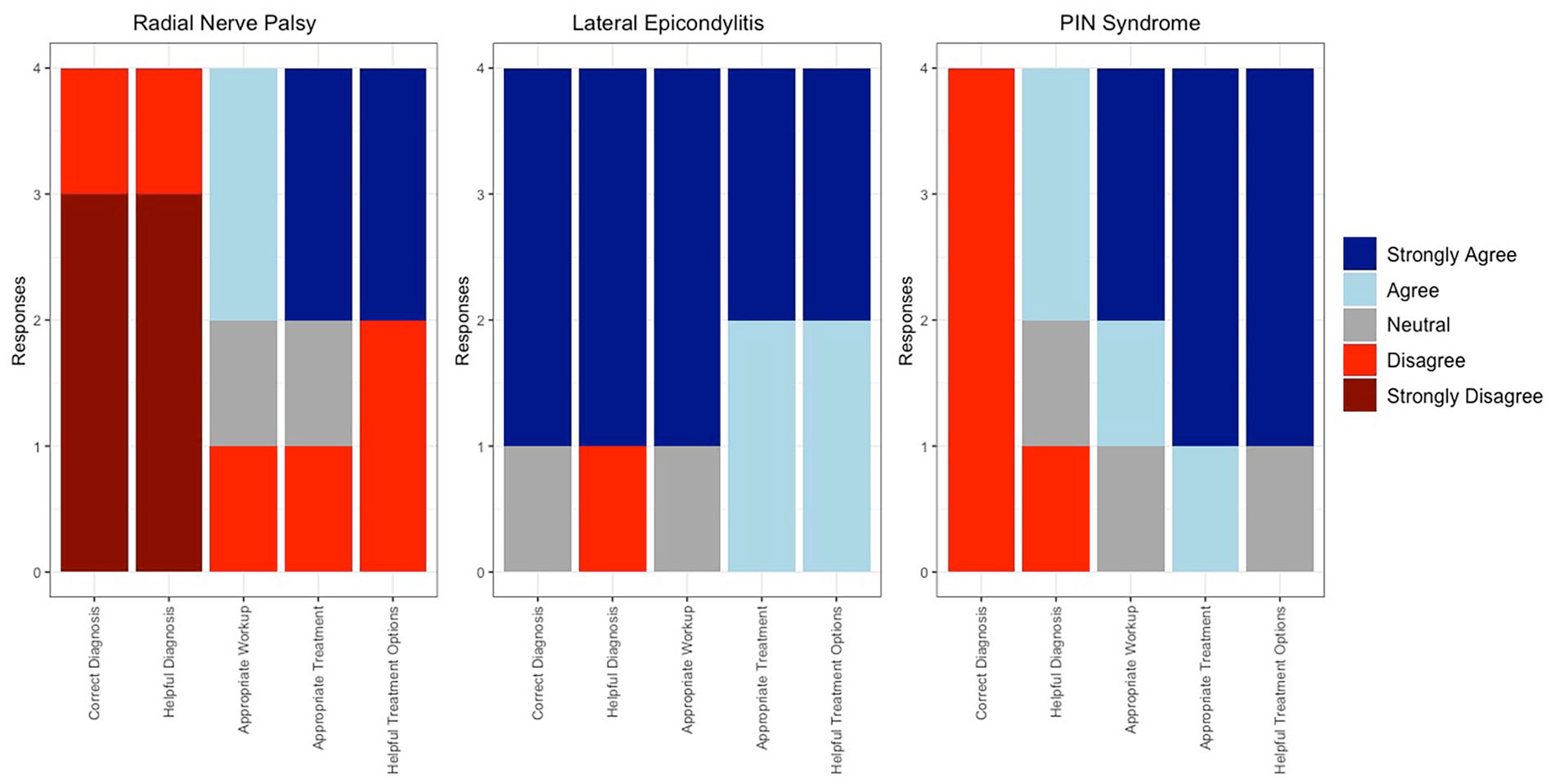
Stacked bar graph depicting individual surgeon responses to each vignette’s 4, 5, and 6 Likert survey.
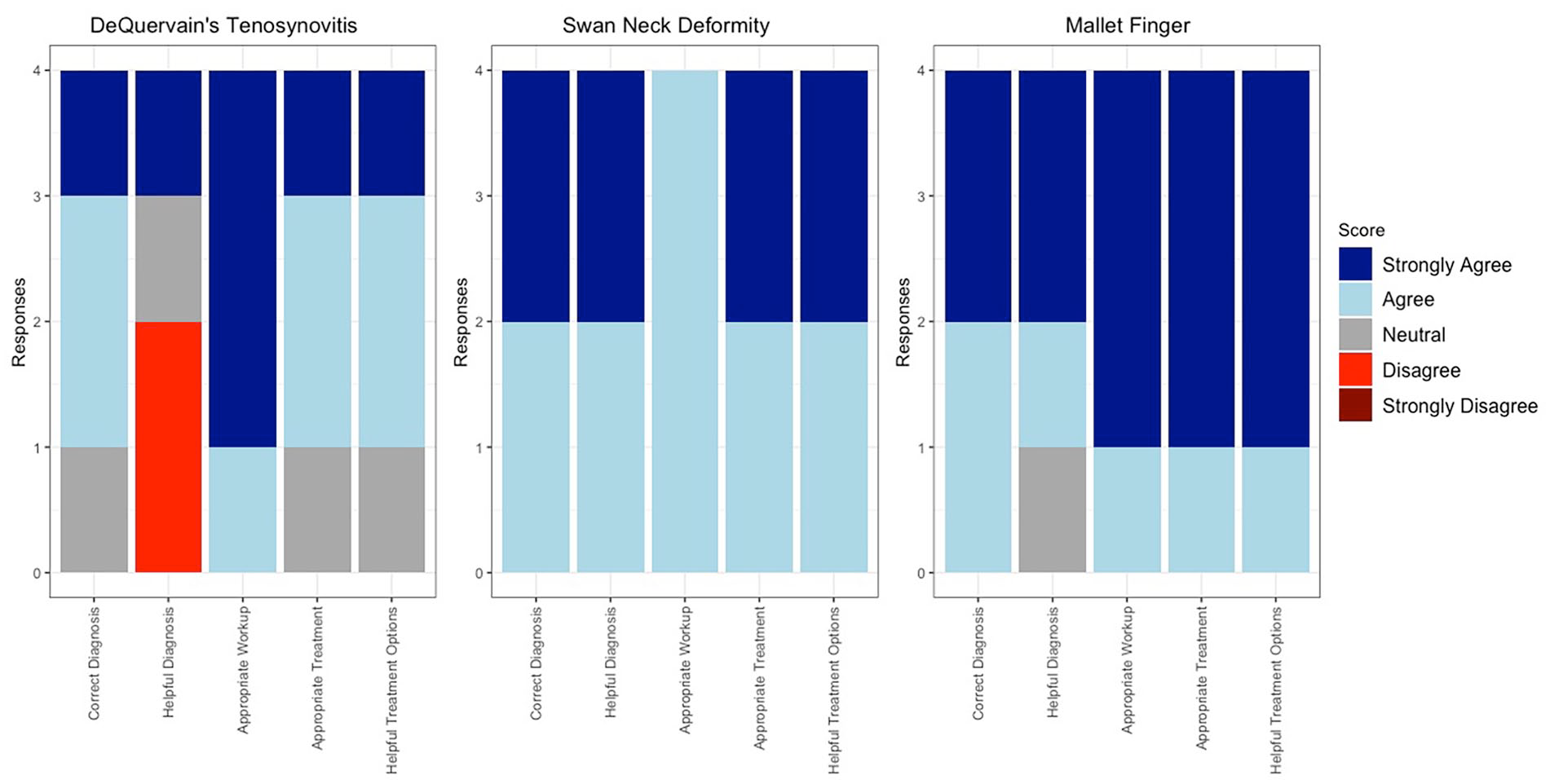
Stacked bar graph depicting individual surgeon responses to each vignette’s 7, 8, and 9 Likert survey.
Results
ChatGPT accurately diagnosed 7 out of the 9 vignettes, resulting in a 78% accuracy rate. It misidentified sagittal band rupture (Table 2) and posterior interosseous nerve syndrome and failed to detect the incorrect nerve distribution in radial nerve palsy (Table 3). In terms of diagnostic performance, ChatGPT received a score of 3.8 ± 1.4. For guiding patient management, it scored 3.4 ± 1.4, while the appropriateness of workup for the actual diagnosis scored 4.1 ± 1.0. ChatGPT scored 4.3 ± 0.8 for an appropriate recommended treatment plan for the diagnosis, and 4.4 ± 0.8 for the helpfulness of treatment options in managing patients. Figure 4 shows the distribution of overall responses.
Sagittal Band Rupture.
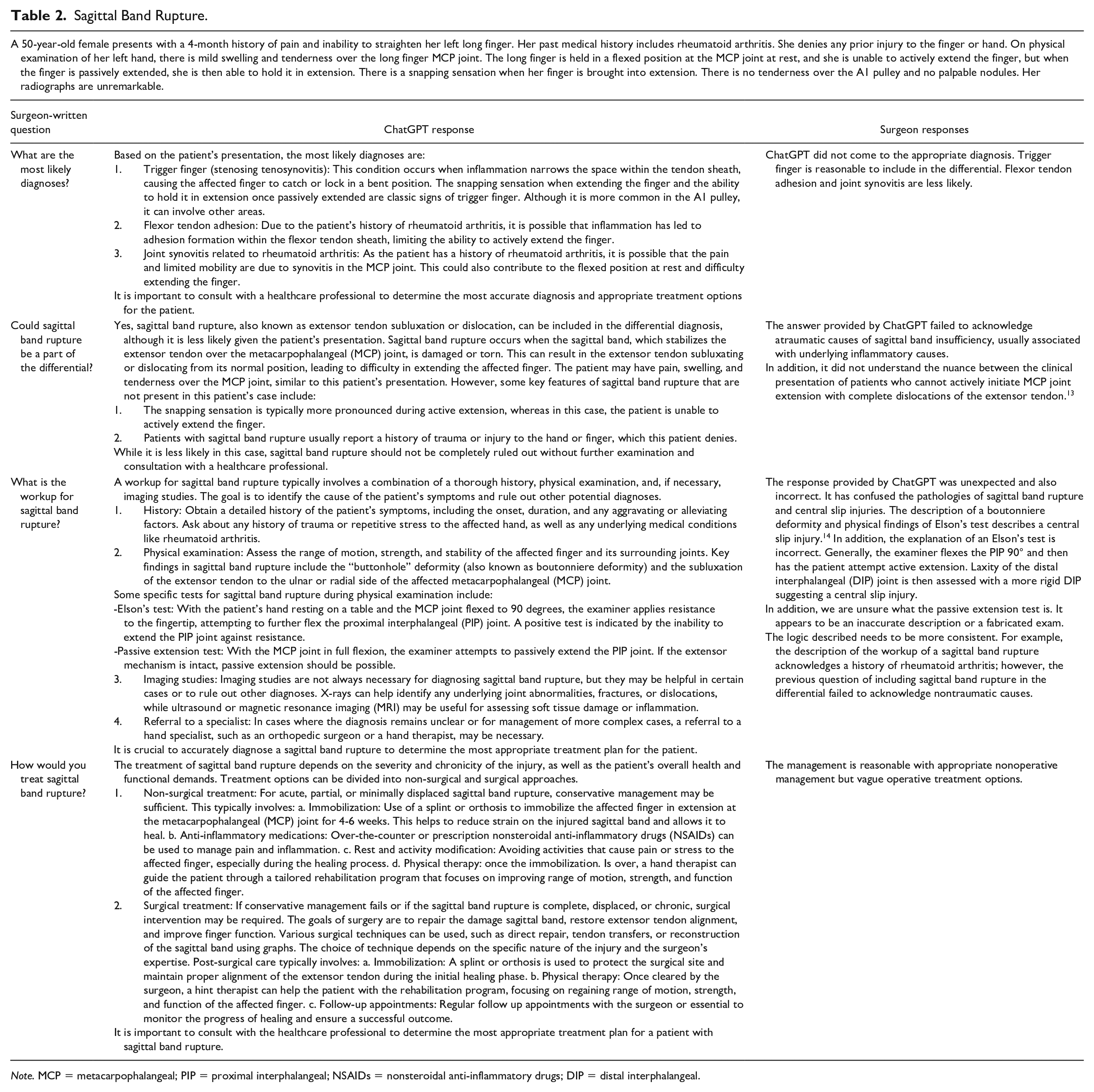
Note. MCP = metacarpophalangeal; PIP = proximal interphalangeal; NSAIDs = nonsteroidal anti-inflammatory drugs; DIP = distal interphalangeal.
Radial Nerve Palsy.
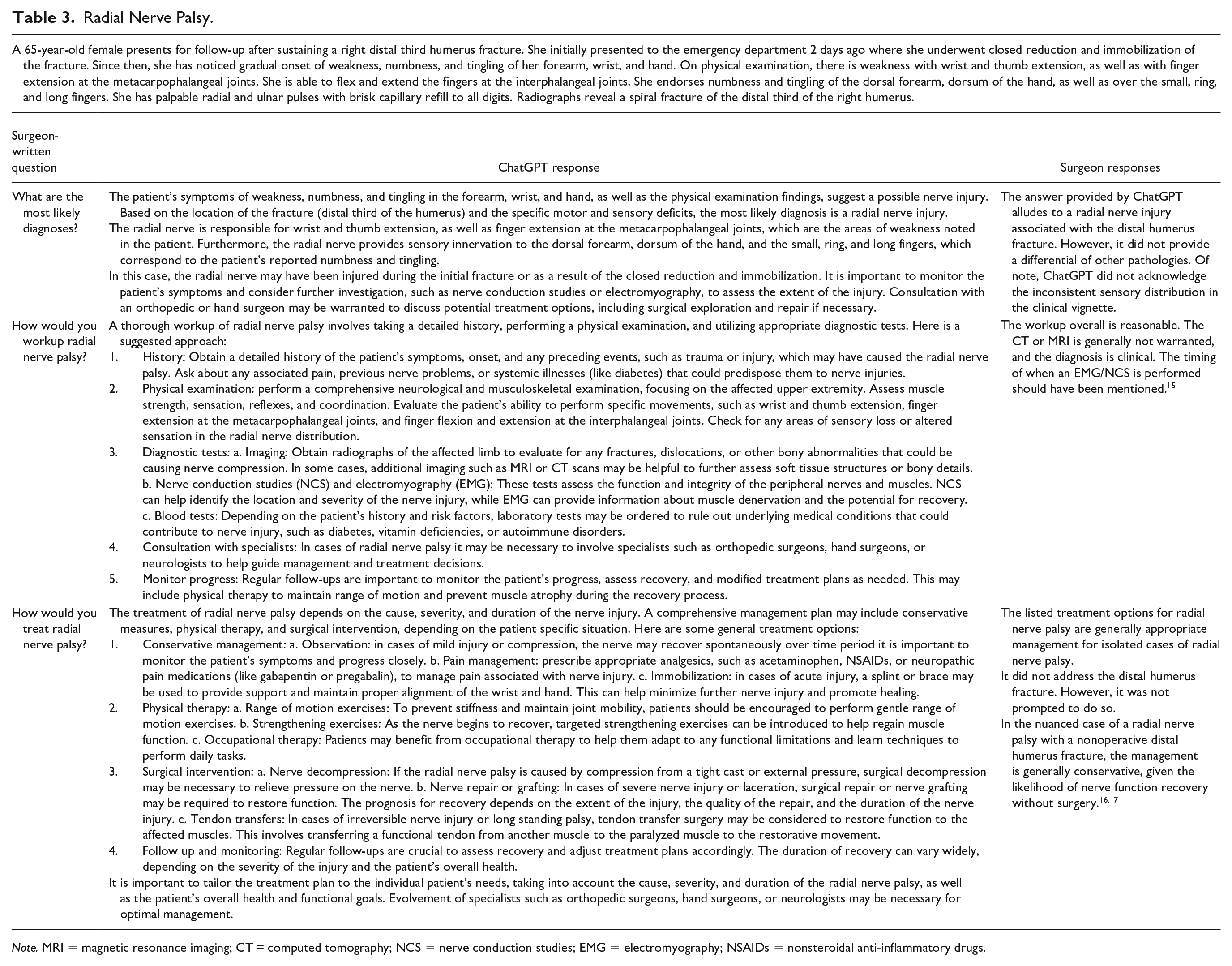
Note. MRI = magnetic resonance imaging; CT = computed tomography; NCS = nerve conduction studies; EMG = electromyography; NSAIDs = nonsteroidal anti-inflammatory drugs.
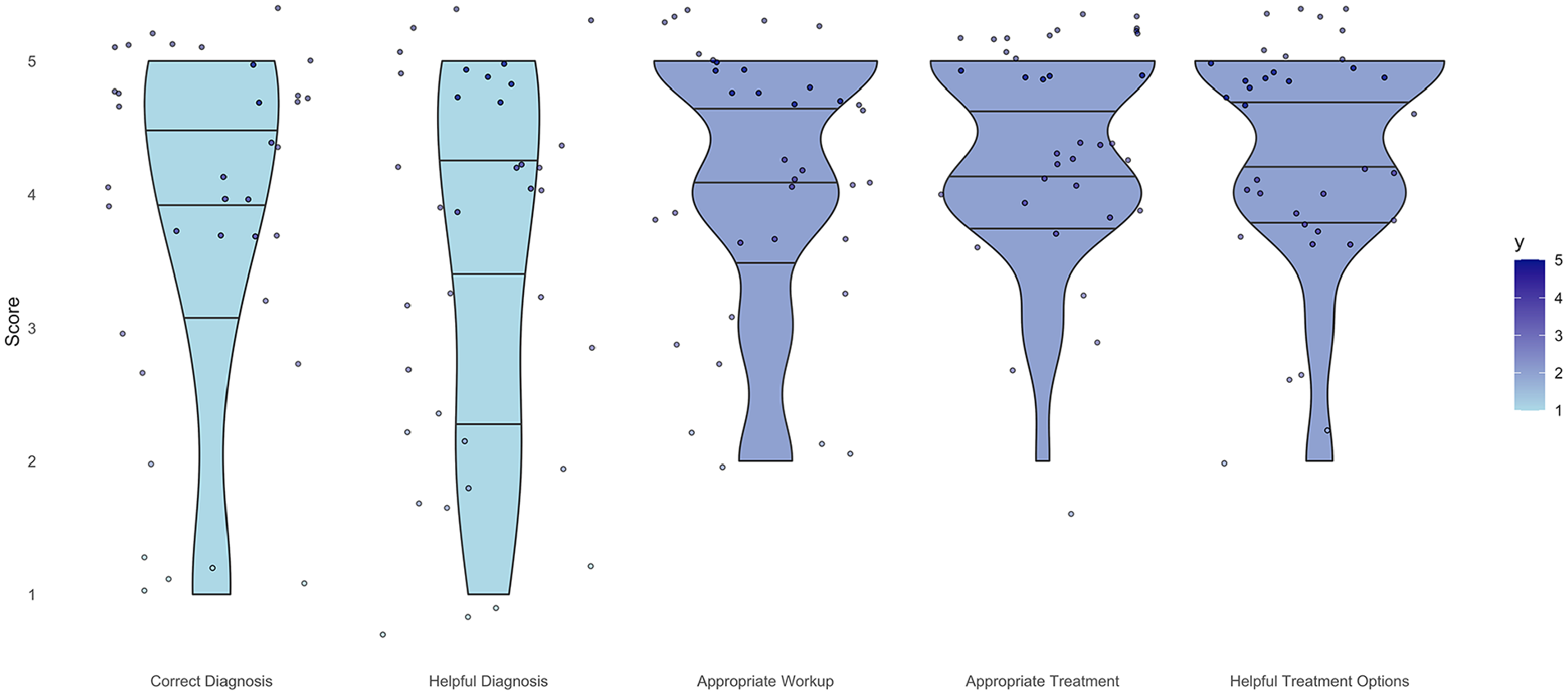
Violin plot of surgeon responses for each likert survey question demonstrating the spread of response over all questions.
Discussion
Seth et al 5 assessed ChatGPT’s ability to provide general information about carpal tunnel syndrome to patients and suggested that LLMs could potentially serve as a surrogate medical practitioner or supportive tools for clinicians. This study assessed the ability of ChatGPT to assist a clinician in generating a differential diagnosis, selecting appropriate workup, and treatment when presented with 9 vignettes representing a diverse set of hand pathology. Overall, ChatGPT correctly identified the correct diagnosis 7 out of 9 times (78% correct), was generally successful in explaining potential workups, and was able to explain both operative and nonoperative treatment options for a variety of conditions. Importantly, the ChatGPT failed to identify an atypical presentation of radial nerve palsy, where the distribution described was inconsistent with the radial nerve. This is cause for concern, as it suggests the ChatGPT may be unable to detect the nuances necessary to provide effective and safe care. While ChatGPT excelled in many areas, demonstrating tremendous promise for integration into the clinic, its utility to a fellowship-trained surgeon may be limited in the clinic.
Our findings are similar to published findings in other disciplines. Seth et al 5 evaluated ChatGPT’s ability to disseminate clinically relevant information to patients in the context of carpal tunnel syndrome. They concluded that while ChatGPT has the capacity to convey medical information to patients, it is restrained by its indiscretion in supplying nonexistent and inaccurate references and information. Grünebaum et al 18 assessed ChatGPT’s responses to various queries related to obstetrics and gynecology. They noted that, while answers were frequently well-constructed and reasonable, ChatGPT often demonstrated a lack of insight and inability to grasp the nuance of both technical questions and more complex, abstract aspects of human language. Barat et al, 19 who assessed ChatGPT’s ability to provide guidance in interventional radiology, found that ChatGPT provided correct answers only 40%. While ChatGPT was able to generate coherent, plausible responses, many answers lacked the nuance or specificity required to be useful in the clinical setting.
Other studies have assessed ChatGPT’s ability to educate patients and have produced promising, but similarly mixed results. Juhi et al 20 assessed ChatGPT’s ability to provide patients advice regarding medications and drug interactions. While ChatGPT was able to identify 39 out of 40 drug interactions, the authors noted that many explanations were inconclusive or unclear. Furthermore, ChatGPT was able to answer basic-level questions about diabetes and diabetes care 21 ; however, another study noted several inaccuracies and limitations, such as the stochasticity of AI-generated responses and the endpoint of training data. 22 Interestingly, when comparing ChatGPT’s ability to answer frequently asked questions in arthroplasty, Dubin et al 23 found that ChatGPT more frequently sourced answers from government or academic publications relative to Google, which provided more information from commercial sources. Still, they did not rigorously assess the veracity of the answers, and simply concluded that patients should corroborate this information with their physician.
While our assessment was generally favorable, there are several important limitations of ChatGPT that may hinder its incorporation into the clinic. First, ChatGPT’s knowledge is only as comprehensive and accurate as the data it was trained on. Importantly, the current iteration of ChatGPT is only trained on data up to September 2021; therefore, it may lack information on more recent literature and advances. Furthermore, it is a generally trained LLM, meaning it lacks medical and orthopedic specific training data, potentially hindering its performance. However, this does make the possibility of an orthopedic-trained ChatGPT more enticing, as the generally trained ChatGPT performed impressively without specific training.
Second, “hallucinations,” a seemingly confident, coherent response generated by ChatGPT that is not backed by its training data, are common. More plainly, ChatGPT may generate a response to an objective question that is fabricated but presents it as factual. Not only are there concerns regarding the origin and implications of these hallucinations, but the cogent way this false information is presented compounds the issue. Both clinicians and patients need to be aware of this potential and ensure the correctness of ChatGPT’s recommendations with a credible source.
Finally, recommendations or evidence provided by ChatGPT are difficult, or impossible, to validate. While it presents information in a clear, concise manner, when asked to provide references, it will fabricate citations. 24 These citations, to an unsuspecting reader, will appear legitimate, but titles and identifiers are frequently falsified or incorrectly identify a source for the material. Furthermore, these false references can bolster the perceived validity of false, biased, or otherwise incorrect information, creating concerns for patient safety.
Our study has a number of important limitations. First, we primarily assessed hand pathology. While ChatGPT is ostensibly trained on general knowledge, the specific scope and breadth of its knowledge is unclear. It is not possible to generalize our findings to other fields; therefore, further testing of the AI chatbot is still warranted in other disciplines and subspecialities. Second, our assessment only included relatively short, text-based vignettes, many with textbook presentations. In clinical practice, imaging, the physical exam, and history taking skills are all important components of patient care. Further research is still required to assess ChatGPT’s ability to incorporate and synthesize multimodal streams of information that may not be as clear. Third, our assessment of ChatGPT’s performance is limited, both due to the subjectivity of the evaluation process and also due to lack of comparison. Future work may draw stronger conclusions by comparing ChatGPT’s performance to that of hand surgeons. Finally, our study was limited to only 9 vignettes and did not have a comparison or control group. Future studies can build upon this work by testing a greater sample of vignettes and incorporating a comparison or control group.
Conclusion
Given our findings, ChatGPT is likely not a useful resource for surgeons in the clinic at this time. Although ChatGPT successfully diagnosed multiple conditions in hand surgery based on clinical vignettes, it made multiple errors. While, in the future, there may be a role for natural language models in clinics, further work and technological advancements are still necessary to safely incorporate ChatGPT or similar technologies into patient care. This study cannot endorse the use of ChatGPT in the clinical setting at this time.
Supplemental Material
sj-docx-1-han-10.1177_15589447241257643 – Supplemental material for Evaluation of a Large Language Model’s Ability to Assist in an Orthopedic Hand Clinic
Supplemental material, sj-docx-1-han-10.1177_15589447241257643 for Evaluation of a Large Language Model’s Ability to Assist in an Orthopedic Hand Clinic by Travis Kotzur, Aaron Singh, John Parker, Blaire Peterson, Brian Sager, Ryan Rose, Fred Corley and Christina Brady in HAND
Supplemental Material
sj-docx-2-han-10.1177_15589447241257643 – Supplemental material for Evaluation of a Large Language Model’s Ability to Assist in an Orthopedic Hand Clinic
Supplemental material, sj-docx-2-han-10.1177_15589447241257643 for Evaluation of a Large Language Model’s Ability to Assist in an Orthopedic Hand Clinic by Travis Kotzur, Aaron Singh, John Parker, Blaire Peterson, Brian Sager, Ryan Rose, Fred Corley and Christina Brady in HAND
Supplemental Material
sj-docx-3-han-10.1177_15589447241257643 – Supplemental material for Evaluation of a Large Language Model’s Ability to Assist in an Orthopedic Hand Clinic
Supplemental material, sj-docx-3-han-10.1177_15589447241257643 for Evaluation of a Large Language Model’s Ability to Assist in an Orthopedic Hand Clinic by Travis Kotzur, Aaron Singh, John Parker, Blaire Peterson, Brian Sager, Ryan Rose, Fred Corley and Christina Brady in HAND
Supplemental Material
sj-docx-4-han-10.1177_15589447241257643 – Supplemental material for Evaluation of a Large Language Model’s Ability to Assist in an Orthopedic Hand Clinic
Supplemental material, sj-docx-4-han-10.1177_15589447241257643 for Evaluation of a Large Language Model’s Ability to Assist in an Orthopedic Hand Clinic by Travis Kotzur, Aaron Singh, John Parker, Blaire Peterson, Brian Sager, Ryan Rose, Fred Corley and Christina Brady in HAND
Supplemental Material
sj-docx-5-han-10.1177_15589447241257643 – Supplemental material for Evaluation of a Large Language Model’s Ability to Assist in an Orthopedic Hand Clinic
Supplemental material, sj-docx-5-han-10.1177_15589447241257643 for Evaluation of a Large Language Model’s Ability to Assist in an Orthopedic Hand Clinic by Travis Kotzur, Aaron Singh, John Parker, Blaire Peterson, Brian Sager, Ryan Rose, Fred Corley and Christina Brady in HAND
Supplemental Material
sj-docx-6-han-10.1177_15589447241257643 – Supplemental material for Evaluation of a Large Language Model’s Ability to Assist in an Orthopedic Hand Clinic
Supplemental material, sj-docx-6-han-10.1177_15589447241257643 for Evaluation of a Large Language Model’s Ability to Assist in an Orthopedic Hand Clinic by Travis Kotzur, Aaron Singh, John Parker, Blaire Peterson, Brian Sager, Ryan Rose, Fred Corley and Christina Brady in HAND
Footnotes
Supplemental material is available in the online version of the article.
Ethical Approval
This study was approved by our Institutional Review Board.
Statement of Human and Animal Rights
This article does not contain any studies with human or animal subjects.
Statement of Informed Consent
Informed consent was not required as no patients were involved with the study.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.