
Abstract
In the field of fabric defect detection, the development of algorithms has been hindered by issues such as poor quality and limited quantity of open-source datasets. Traditional data augmentation methods offer limited improvements in model performance, while generative data augmentation methods are plagued by difficulties in training generative models, susceptibility to artifacts, and the need for re-labeling. To address these challenges, this paper proposes a blind super-resolution algorithm for fabric defect data augmentation. The model is based on Real-ESRGAN and has been optimized specifically for the resolution degradation module to better adapt to the resolution degradation process in fabric images. Subsequently, a novel loss function named Local Blur Discrimination Loss is designed to address the local blur phenomenon and suppress the generation of fabric artifacts during the super-resolution process. Finally, both subjective evaluations of super-resolution effects and objective comparisons of data augmentation performance were conducted during the experimental phase. The subjective assessments demonstrate that the proposed method outperforms the baseline model. Additionally, in terms of objective performance, augmenting the DAGM2007 dataset using the proposed model, the detection model's accuracy (P) increased by 7.4%, recall (R) increased by 1.0%, and the mean average precision (mAP) increased by 2.5%, surpassing commonly used traditional vision-based data augmentation algorithms.
Keywords
Introduction
The quality of textile products directly affects their pricing and, consequently, the overall growth of the industry. As a result, textile quality inspection represents an indispensable and crucial step in the textile production chain. 1 Among various inspection tasks, fabric defect detection is one of the most critical processes, primarily aimed at preventing defects from compromising fabric quality, which significantly impacts the value and marketability of textile products. Traditionally, fabric quality monitoring has been performed manually through visual inspection, relying on the personal experience of workers to evaluate fabric quality. 2 However, this method presents several inherent limitations. First, the low degree of mechanization results in slow inspection speeds. Second, the subjectivity of manual visual inspection often leads to inconsistent and less objective evaluations, increasing the likelihood of misdetections and omissions.
Automated fabric defect detection technology has gradually become a prominent research focus in this field. The emergence of computer vision has introduced a new direction for fabric defect detection, aiming to automatically identify and isolate defect regions using feature extraction algorithms, followed by classification through machine learning classifiers. Building on this approach, numerous advanced algorithms have been developed, offering innovative perspectives and effective methods for fabric defect detection. Data is the most crucial driving force in both machine learning and deep learning. For fabric defect detection tasks, deep learning-based models can be categorized into supervised, semi-supervised, and unsupervised approaches based on the availability of labeled data in the training set. 3 Supervised learning methods treat defect detection as a classification problem by leveraging the differences between defective and non-defective samples. These methods require large volumes of labeled data to train models effectively, enabling the extraction of features that distinguish defects from non-defects. Semi-supervised learning combines the strengths of supervised and unsupervised approaches, typically utilizing a small amount of labeled data along with a large amount of unlabeled data for training. Unsupervised methods, in contrast, do not rely on labeled datasets and instead learn features directly from unlabeled data, which are then used to detect fabric defects. Despite their potential, these methods often face limitations in accuracy, particularly for detecting subtle defects. Their reliability remains insufficient to meet the stringent requirements of real-world applications. This is especially true in scenarios involving complex backgrounds or high levels of noise, where challenges such as model robustness and generalization capabilities continue to hinder practical implementation. 4 Consequently, supervised models that utilize large volumes of labeled data typically demonstrate superior performance compared to semi-supervised and unsupervised models, which rely on limited or no labeled data. However, the effectiveness of such deep learning models depends heavily on the availability of a comprehensive and extensive dataset encompassing a wide variety of defect types. To address this issue, augmenting existing fabric datasets using certain algorithms to increase training data and improve dataset quality is one approach, and data augmentation is one of the solutions.
Data augmentation can be categorized into traditional computer vision-based methods and deep learning-based methods. Traditional computer vision-based data augmentation methods have limited effectiveness in improving model performance. Moreover, due to the limited ability of traditional visual enhancement methods to alter the distribution of image features, they may increase the risk of model overfitting. 5 Among these, deep learning-based generative data augmentation methods6,7 better meet the requirements of deep learning detection tasks and have been widely applied in downstream tasks such as fabric defect detection. 8
Xu et al. 9 proposed a Generative Adversarial Network (GAN) model for data augmentation in fabric defect detection. Firstly, the dataset undergoes preprocessing to generate defect localization maps, which are then combined with non-defective fabric images and fed into the network for training, facilitating better extraction of defect features. Additionally, the fusion of defects and textures is enhanced using a dual U-Net network.10,11 Random noise and multi-head attention mechanisms are introduced to enhance the model’s generalization ability and improve the authenticity and diversity of the generated images. Finally, the newly generated defect image data is merged with the original defect data to achieve data augmentation. Lu et al. 12 proposed a deep adversarial data augmentation method called DefectTransfer to address the scarcity of fabric defect data. This method employs a cut-and-paste approach to enhance defect images by cutting defects and pasting them onto defect-free images. Before pasting, random transformations are applied to the defect regions, including scaling, rotation, and translation. Furthermore, an adversarial transformation algorithm is proposed to enhance the blending of the pasted defect areas with the original images. Wang et al. 13 conducted experiments to augment fabric defect datasets using geometric transformations and generative adversarial networks, with the generated data constrained by structural similarity. The effectiveness of this data augmentation method was validated using Faster R-CNN. 14 Zheng et al. 15 proposed an algorithm for augmenting composite fabric data using conditional generative adversarial networks. 16 Initially, fabric warp and weft morphologies are statistically analyzed, and artificial labels are generated based on the statistical results. These artificial labels are then inputted into a conditional generative adversarial network incorporating the Pix2PixHD algorithm to synthesize composite fabric data images. Li et al. 17 proposed a Defect Location Sensitive Generative Adversarial Network (DLS-GAN) for industrial fabric defect data augmentation. This method employs two encoder-decoder structures to first extract defect features and position information, and then transfer defect features to defect-free images using a defect feature transfer module to generate corresponding defect images. Chen et al. 18 introduced a fabric data augmentation method based on RDN-LTE. Initially, the fabric dataset is downsampled to generate pairs of LR-HR image pairs, which are then fed into the SFENET model for shallow feature extraction. Subsequently, defect semantic information is extracted from the deep layers of RDN, and then shallow features are fused with deep features using the LTE algorithm. 19 Finally, upsampling is performed to reconstruct features through super-resolution. Although the enhanced dataset resulted in a certain increase in accuracy in the detection experiments, the training process is complex and computationally intensive. Table 1 summarizes the advantages and disadvantages of the aforementioned methods.
Comparison table of advantages and disadvantages of each method.

In summary, most deep learning-based fabric image data augmentation studies rely on purely generative or direct defect transfer approaches.20 –22 These algorithms operate in an unsupervised manner during both training and generation, controlled only by random numbers to introduce differences between generated images. Consequently, such methods require more manual supervision when used for dataset augmentation, to filter usable data. Figure 1 illustrates the experimental results of data augmentation for the defect category “warp breakage” using a purely generative approach (generative adversarial networks). It can be observed that data generated by purely generative models often contain a large amount of severely distorted data, which cannot be utilized for tasks such as object detection or semantic segmentation. This is because fabric defect samples exhibit significant differences between samples and contain numerous texture variation defects, making the unsupervised training process of purely generative models more challenging. Furthermore, both detection and segmentation tasks require data labeling or mask creation. Directly generated images do not have definite defect locations or shapes. Even with good generation results, changes in defect positions and shapes require re-labeling of the data, leading to significant human effort wastage. 23

Data generation results of broken meridians: (a) Real data, (b) Better generation results, and (c) Distorted generation results.
In summary, current research on image data augmentation methods is constrained by the poor quality and limited quantity of open-source datasets, as well as the challenges associated with training models. These limitations result in restricted model generalization capabilities, suboptimal data augmentation performance, low-quality generated data, and reduced efficiency and instability in model training. To address the aforementioned issues, this paper proposes a fabric data augmentation method based on Real-ESRGAN. 24 The advantages of this method are as follows:
Real-ESRGAN is an unsupervised blind super-resolution method. Unlike other super-resolution methods, it does not require LR-HR image pairs for the super-resolution task, eliminating the need for prior calibration. This reduces the cost of data preparation while increasing its flexibility, allowing for more adaptable application across various scenarios and image types.
Super-resolution-based data augmentation does not alter the spatial feature distribution of the data itself. Compared to other generative data augmentation methods, the augmented dataset does not require re-labeling, allowing the reuse of annotations from before the super-resolution enhancement.
Adjusting the high-order resolution degradation module for fabric images replaces Gaussian noise with Poisson noise. Poisson noise has less destructive effect on the detailed features of fabric data compared to Gaussian noise, reducing the difficulty of model training.
Designing a local blur discrimination loss function and applying it to the model’s backpropagation process suppresses the local blur phenomenon in super-resolution models when processing fabric images. It also acts to suppress the generation of artifacts, stabilizing the model training process.
Experimental results based on the DAGM2007 dataset 25 demonstrate that the proposed data augmentation algorithm improves the accuracy, recall rate, and average accuracy of detection models. Furthermore, it outperforms traditional vision-based data augmentation methods.
Methods and principles
Real-ESRGAN
Generate model RRDBNet
The generative model used by Real-ESRGAN is RRDBNet, composed of 23 Residual Dense Blocks (RDB) 26 and upsampling modules. The Residual Dense Blocks are primarily responsible for learning and extracting features from the input, while the upsampling modules are responsible for reconstructing the image in super-resolution based on the learned features. It is evident that the core of the generative model lies in the Residual Dense Blocks used for feature extraction. The performance of this structure directly impacts the model's ability to reconstruct detailed effects in the input image after super-resolution. Its key features include residual connections and dense connections. The structure of the RDB is illustrated in Figure 2.

Structure diagram of residual dense blocks.
For neural networks, deeper architectures often enable the extraction of more intricate features. 27 However, excessively deep networks can lead to overfitting. Residual structures effectively address issues such as vanishing gradients, exploding gradients, overfitting, and model degradation caused by deepening networks. Among these, residual connections play a crucial role in residual dense blocks.28,29
In addition, many studies have not fully utilized the feature information from different convolutional layers of the model. For generators in generative adversarial networks, the ability to extract features is crucial. If the generator fails to accurately reconstruct the data distribution of the training set, it can lead to a training process heavily biased towards the discriminator, resulting in training collapse. 30 To address this issue, dense connections incorporate the outputs of each convolutional layer as part of the input features for subsequent modules. However, this approach also increases the computational complexity of the model.
Discriminant model U-net
Real-ESRGAN chooses the U-Net 31 as its discriminator model. The U-Net is a classic model in the segmentation field, known for its distinctive architecture consisting of an encoder-decoder combination. Due to its network structure resembling the letter “U,” it is named U-Net. The basic structure is illustrated in Figure 3.

U-net structure diagram.
The encoder of U-Net primarily compresses the input image and extracts its deep semantic features. Subsequently, the acquired semantic information is fed into the decoder. The decoder, based on the semantic features of the input image, progressively reconstructs the image from highly abstracted semantic features through upsampling. To prevent the loss of shallow-level feature information during the encoding process, U-Net employs skip connections. These connections feed shallow features from the encoder to the decoder at the corresponding feature scale to assist the decoder in image reconstruction.
With its encoding-decoding architecture, U-Net possesses stronger feature extraction capabilities compared to architectures like Visual Geometry Group(VGG). 32 Additionally, U-Net’s output matches the input size, and each pixel value in the output represents a genuine probability. In contrast, VGG returns a single value. U-Net can more fully express the authenticity of the entire image, making it more suitable for image super-resolution tasks. However, the structure of U-Net is more complex, which poses a risk of unstable training. To address this, Real-ESRGAN utilizes spectral normalization 33 instead of batch normalization commonly used in Convolutional Neural Networks(CNNs) to stabilize the training process of the discriminator model.
Loss function
Generate model loss function
The loss function of the Real-ESRGAN’s generative model comprises pixel loss (L1 Loss), perceptual loss, 34 and adversarial loss, 35 and is determined by the weighted summation of these three components to derive the final generative model loss function.
The pixel loss computes the pixel-level difference between the model’s predicted values and the ground truth values, calculated using the L1 norm of matrices. For image super-resolution tasks, the objective of the model is to make the generated super-resolution image (SR) as close as possible to the real high-resolution image (HR). Therefore, the L1 loss calculates the error between the values at corresponding pixel positions of SR and HR. Its formula is shown in equation (1).

The perceptual loss is a commonly used loss function in deep learning image generation tasks. Traditional loss functions mostly rely on calculating distances in Euclidean space, which makes it difficult to measure the perceptual quality of images according to human perception. However, in Real-ESRGAN, the perceptual loss is computed using a pre-trained VGG-19 model to measure the difference between two images, placing greater emphasis on the perceptual quality of images and aligning more closely with human perception of image quality.
Specifically, in Real-ESRGAN, the perceptual loss is typically computed by feeding the SR image and HR image separately into a pre-trained VGG-19 model. The activations of the first five convolutional layers of the model are extracted to obtain their feature representations within the network. These feature representations are then used as inputs to compute the L1 loss between them, aiming to optimize the distance between the SR and HR images in the feature space. The perceptual loss can be calculated using equation (2).

The objective of the adversarial loss in the generative model is to make the generated images more similar to real images. Therefore, the computation of this loss involves feeding the SR images generated by the generator into the discriminator model D, and then computing the binary cross-entropy loss (BCE Loss) between the output of the U-net and the ground truth label matrix(

Discriminant model loss function
The calculation method for the discriminator model’s loss is similar to the GAN Loss. However, since it needs to possess both the ability to discriminate real images and the ability to discriminate fake images, it requires separate optimization for different inputs. The specific computation method is illustrated in equation (4).

In the equation,
Fabric resolution degradation module
Compared to other super-resolution methods, Real-ESRGAN also has an advantage in explicit modeling-based blind super-resolution. 24 For non-blind super-resolution algorithms, preparing data requires pairs of images, namely low-resolution images and real high-resolution images, which imposes a significant burden on data preparation and training.
For explicit modeling-based blind super-resolution methods, during training, the input image is treated as the high-resolution image. It undergoes resolution degradation through a predefined image degradation module to produce the low-resolution image. Finally, the loss is computed based on the comparison between the HR image and the super-resolved image obtained from the LR input. Classic image degradation models can be summarized as equation (5).

As shown in the equation above, classical degradation models first apply a blur filter to the HR image for blurring, followed by downsampling and noise addition, and finally JPEG compression. To simulate the image resolution degradation process in real scenarios, Real-ESRGAN has made some improvements to this stage by employing a high-order degradation model. Specifically, this involves repeating the above process twice and, in the final step, using a bandpass filter to simulate the ringing noise commonly present in real-world scenarios. This involves multiple degradation steps and various degradation parameters. High-order degradation models simulate real-world image degradation through repeated degradation processes, each potentially employing classical degradation models but with different hyperparameters. This approach allows for a more comprehensive simulation of real-world image degradation, generating low-resolution images that closely resemble real-world scenarios for training purposes. This specialized processing also enables Real-ESRGAN to effectively remove common artifacts in fabric images, such as ringing artifacts 36 and overshoot artifacts. 37 Figure 4 illustrates the degradation process of the high-order degradation model.

Real ESRGAN high-order degradation process.
The motivation behind applying the high-order degradation process in Real-ESRGAN was to address super-resolution tasks in real-world scenarios. By introducing various types of noise to the images, the model aims to obtain rich interference information, thereby enhancing its robustness.38,39 However, this approach may not be suitable for super-resolution tasks involving fine and intricate textures, such as fabric images. From Figure 4, it can be observed that the degraded LR defect image almost completely loses any texture characteristics of the fabric compared to the HR defect image. For fabric images with barely distinguishable textures, the restoration of super-resolution becomes exceedingly challenging, potentially exacerbating the generation of artifacts. In the context of fabric image super-resolution tasks, artifacts may introduce texture features that do not belong to the fabric itself, posing significant challenges for subsequent defect detection stages.
It is evident from Figure 4 that the addition of Gaussian noise severely disrupts the texture information in the image. Gaussian noise is an additive noise independent of the image itself,40,41 affecting the entire image uniformly without considering the pixel values of the image. Consequently, it can degrade the fine details and the distribution of pixel values in the image. Moreover, Gaussian noise uniformly distributes across the image, causing overall blurring and obscuring fine details. In certain cases, Gaussian noise may introduce false edges or artificial textures, further degrading image quality. These effects are detrimental to defect detection, as they hinder the accurate identification and analysis of defects. The training objective of the generative model is to learn the feature distribution of the input images and map them to a high-dimensional data space. Excessive addition of Gaussian noise may cause the generative model to learn the feature distribution of the noise rather than that of the images themselves, potentially leading to unstable training and increased generation of artifacts.
Therefore, this study replaces the Gaussian noise in the degradation module with only Poisson noise. Compared to Gaussian noise, Poisson noise causes less disruption to the fine details and texture features of the image, manifesting more as black-and-white speckles. Additionally, Poisson noise, being proportional to image intensity, becomes more noticeable in low-brightness areas and has minimal impact on images captured under normal lighting conditions. It is commonly used to simulate noise generated by camera sensors, aligning with the practical conditions of fabric image acquisition. Furthermore, Poisson noise effectively contributes to resolution degradation, making it a useful factor in modeling real-world scenarios. The effect of Poisson noise is illustrated in Figure 5.

Comparison of effects before and after adding Poisson noise: (a) Original image, (b) Add Gaussian noise, and (c) Add Poisson noise.
Design of local fuzzy discriminant loss
The quality of fabric images generated by the baseline model is not stable, with most of the super-resolved images exhibiting partial blurriness, as depicted in Figure 6. Specifically, the left side of the red curve in the image appears noticeably blurred compared to the right side.

shows an example of a locally blurred image.
To address this issue, this paper proposes an efficient method for locally blurry detection in SR images to identify instances of partial blurriness in fabric images. Subsequently, based on the results of the blurry detection, a loss function is designed to weight the SR and HR images, enhancing the penalty on regions affected by local blurriness. This guides the optimization process of the generative model.
For SR images, clear regions contain rich high-frequency information, while blurry regions lack high-frequency information comparatively. If we directly apply residual operations with HR images, the residual image would include genuine detail information added after super-resolution. Using this residual image directly as the penalty weight matrix for blurriness would overly penalize genuine detail information, which is unreasonable. The next step will be to consider how to amplify the difference between blurry and clear regions in SR images.
The sharpening operation can enhance high-frequency information in images. For clear regions, they already contain sufficient high-frequency information, so sharpening would not lead to significant perceptual differences in pixel intensity. However, for locally blurred areas, sharpening can enhance edges and detail information, adding high-frequency components. At this point, the SR image after sharpening, when compared with its own residual, would produce different effects on blurry and clear regions. Sharpening can be calculated using equation (6).

In the equation,

Self residual effect.
Due to the less abundant high-frequency information in the blurry regions compared to the clear areas, the changes after sharpening will be more pronounced in the blurry regions. However, there won't be significant differences between the sharpened and original images in the clear regions. As depicted in Figure 7, the residual image Res obtained after the residual operation exhibits very noticeable widespread pixel grayscale feature changes in the originally blurry areas, while the clear regions show dense grayscale variations within a small range.
After the self-residual operation, the resulting Res image already exhibits noticeable distinctions between the blurry and clear regions of the SR image. However, it cannot be directly used as a blur penalty weight. It's worth noting that the grayscale changes in the blurry regions are not significant within a small range, while the clear areas show pronounced differences in grayscale within a small range. This suggests a significant difference in the variance of the data distribution between the two. Therefore, by simultaneously calculating the local variance Var for both the clear and blurry regions, this paper can obtain a local variance map. The calculation of local variance is illustrated in equation (7).

In the equation,

Local variance effect.
The areas in the SR image that require increased loss penalty are the blurry regions, corresponding to higher values in the weight matrix. Conversely, the sharp areas should not be excessively penalized, so their corresponding values in the weight matrix should be smaller. In grayscale pixel representation, larger pixel values correspond to whiter pixels. Therefore, it is necessary to compute the reciprocal of each element in the local variance matrix and obtain the weight matrix for the local blur discrimination loss function. The overall process of preparing the weight matrix is illustrated in Figure 9.

Weight matrix preparation process: (a) SR image, (b) Self residual error Res, (c) Local variance Var, and (d) Weight.
The local blur discrimination loss function can be computed by weighting the SR image and HR image with the weight matrix and then calculating their L1 loss. This can be expressed by equation (8).

Indeed, aside from local blur, the occurrence of artifacts in generated images is a common issue in generative modeling tasks, as illustrated in Figure 10. This phenomenon can arise due to various factors such as training instability, dataset quality, and hyper parameters. The presence of artifacts significantly affects the reliability and stability of the model. Therefore, addressing artifacts has always been an inevitable aspect of generative tasks. 42

Example of artifact region.
Indeed, in the context of fabric images, artifacts often manifest as spurious textures, where the model incorrectly synthesizes texture information not inherent to the fabric itself. Consequently, these artifacts exhibit significant perceptual differences compared to other regions of the image. Their perceptual manifestation is similar to that of local blur, both presenting as regional texture discrepancies.
For local blur, sharpening the self-residuals of the SR image relies on different degrees of blur between two regions, effectively extracting the blurry regions. Similarly, for artifacts, their edges exhibit significant grayscale differences compared to normal texture regions. Additionally, artifacts often display distinct levels of sharpness compared to normal texture areas. Therefore, employing the sharpening self-residuals method can also detect the presence of artifacts to some extent. The effectiveness of the local blur detection algorithm for artifact detection is illustrated in Figure 11.

Detection effect on artifact areas: (a) Images with artifacts appearing and (b) Pseudo shadow region weight matrix.
Experiment
Subjective effect comparison experiment
To visually demonstrate the effectiveness of optimizing the resolution degradation module and designing the local blur discrimination loss function, this section will conduct a subjective comparison of super-resolution results. Figure 12 presents the actual effects of some original LR images from the dataset, SR images generated by the baseline model, and SR images generated by the optimized model.

Super-resolution effect display: (a) LR images, (b) Benchmark model SR effect, and (c) Optimized model SR effect.
From the images, it’s evident that both the baseline model and the optimized model can enhance the image details compared to the low-resolution LR images. Comparing the first and third rows, it’s noticeable that the optimized model, which utilizes the local blur discrimination loss as part of its loss function, shows a certain degree of suppression effect on local blurring. Specifically, in the enlarged detail regions of the first row, the SR image from the baseline model exhibits noticeable blurriness, while the SR image from the optimized model maintains consistent clarity throughout the image.
The two SR images in the second row exhibit significant differences, with the SR image from the optimized model showing far superior visual results compared to the baseline model’s SR image. This discrepancy arises from the instability of the model. The baseline model randomly adds Gaussian noise during the image resolution degradation stage, and when the kernel size of the Gaussian noise is chosen improperly, it can lead to excessive destruction of image detail information, thereby destabilizing the training process and causing instability in the model's super-resolution results. However, by adjusting the resolution degradation module of the model and replacing Gaussian noise with Poisson noise, the problem of complete destruction of image details during the random noise addition stage can be effectively resolved, enabling better guidance for the model to restore and add details.
It’s evident from the last row of Figure 12 that the baseline model introduces large areas of artifacts, commonly referred to as “pseudo-textures,” during the process of super-resolution reconstruction from the low-resolution LR images. In contrast, in the super-resolution results obtained from the optimized model, only a small number of artifact regions are present. This observation underscores the inhibitory effect of the local blur discrimination loss on artifact generation. In real-world fabric defect detection scenarios, the reduction of artifacts has significant implications. Artifacts, often appearing as abnormal structures or noise in images, may resemble fabric defects, leading to misclassification by detection systems. Minimizing artifacts can reduce the likelihood of such false positives while enhancing image clarity and contrast. This improvement enables detection systems to more accurately identify subtle defects and fine details on the fabric, thereby increasing detection accuracy. Furthermore, reducing artifacts simplifies subsequent processing steps, lowering computational complexity and workload. This enhancement allows the detection system to more quickly pinpoint defect locations and perform analysis, accelerating the defect identification process. Such improvements are critical for boosting the overall efficiency of production lines, contributing to smoother and faster operations.
After optimizing the resolution degradation module and analyzing the effectiveness of the locally blurred discriminative loss function, further experiments were conducted to validate the impact of the proposed super-resolution image enhancement method on the performance of a detection model. YOLOv5n was selected as the benchmark model to evaluate the effectiveness of data augmentation. The DAGM 2007 dataset, consisting of 2,100 images, was used in the experiments. Prior to inputting the dataset into the model, all images were resized to a consistent resolution of

Model detection results of different training sets: (a) Raw data+CutGan, (b) Raw data+CycleGan, (c) Raw data+StyleGan, (d) Raw data+SR, and (e) Raw data+OurSR.
From the graph, it is observable that detection models trained on datasets enhanced by other commonly used deep learning data augmentation models and the Real-ESRGAN before improvement exhibit instances of both missed detections and false alarms in fabric defect image detection. However, when using the dataset augmented with the method proposed in this paper combined with the original data for training, the resulting detection model can effectively identify each type of defect image in the dataset, with the highest confidence in the predictions of the detection network. This superiority is attributed to the comprehensive preservation of the original fabric image texture and defect features achieved by the super-resolution image enhancement method proposed in this paper, leading to an enhancement in the detection performance of the model.
Objective performance comparison experiment
To address the issues of poor quality and limited quantity of datasets in fabric defect detection, this paper conduct fabric data augmentation experiments based on blind super-resolution. Firstly, an objective analysis of the data augmentation effects of our approach is performed. Four image enhancement evaluation metrics are utilized for comparative experiments: Frechet Inception Distance 46 (FID), Peak Signal-to-Noise Ratio 47 (PSNR), Structural Similarity Index 48 (SSIM), and Learned Perceptual Image Patch Similarity 49 (LPIPS). FID measures the quality of image enhancement by comparing the difference between the distribution of enhanced images and real images; a lower FID value indicates better enhancement. PSNR is used to quantify the similarity between original and reconstructed images; a higher PSNR value indicates better image quality. SSIM assesses the similarity between two images by comparing their brightness, contrast, and structural information; a higher SSIM value indicates greater similarity between images. LPIPS evaluates deeper semantic feature information to measure image similarity; a smaller LPIPS value indicates greater similarity between images.
The calculation formula for each indicator is as follows:

In the equation,

In the equation,

In the equation,

In the equation,
The dataset chosen for the experiment is the DAGM2007 dataset, consisting of a total of 2100 images. The proposed method in this paper is compared with other commonly used deep learning data augmentation models. For each of the 10 categories in the dataset, 50 images are randomly selected for augmentation, resulting in a total of 500 images for comparison of augmentation effects, as shown in Table 2. It should be noted that “OurSR,” as shown in the table and mentioned in subsequent sections, refers to the efficient SR image enhancement method proposed in this study.
Comparison of enhancement effects of each method.
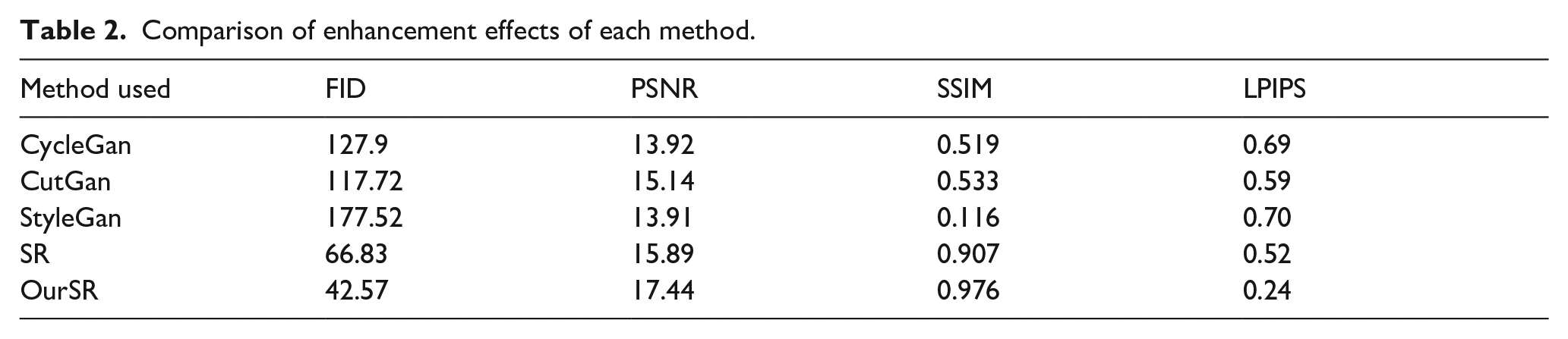
Analysis reveals that the optimized super-resolution enhancement method outperforms the pre-improved Real-ESRGAN model and other commonly used data augmentation models. Specifically, the proposed method performs best in terms of the FID value after image enhancement, exhibiting a decrease of 24.26 compared to the pre-improved Real-ESRGAN model. This indicates that the quality of fabric defect images enhanced using the method proposed in this paper is superior to those obtained using other comparative enhancement models. Additionally, by comparing the PSNR, SSIM, and LPIPS parameters in the table, we observe that the enhanced images generated by the proposed method exhibit higher similarity to real images, thus better preserving and restoring the texture features of the original fabric images.
After objectively analyzing the data augmentation quality of the proposed method, YOLOv5n is employed as the validation model to assess the training effectiveness of the super-resolution image enhancement method proposed in this paper. A total of 500 images are selected from the DAGM2007 dataset, comprising 10 categories with 50 images each, to serve as the training set for the detection model. Additionally, 210 images are allocated for the validation set, while the remaining 1390 images are designated as the test set. The allocation is not based on a more reasonable 8:1:1 ratio to reduce the proportion of the training set, emphasizing the effectiveness of data augmentation and facilitating cross-comparison with other data augmentation methods. Moreover, performance results are determined by the detection outcomes on the test set, ensuring the authenticity and robustness of the detection results, as the test set comprises a significant portion of images not involved in the model training process.
First, the proposed method is compared with traditional data augmentation techniques, which include image horizontal flipping, vertical flipping, adding Gaussian noise, and contrast adjustment. These methods simulate variations in orientation, pose, noise, and lighting conditions, which are beneficial for learning tasks with limited data. Examples illustrating these augmentation techniques are depicted in Figure 14.

Example of traditional data enhancement methods: (a) original image, (b) Horizontal flip, (c) flip vertical, (d) Gaussian noise, and (e) Contrast adjustment.
The experiment applies various traditional data augmentation techniques to the entire training set of 500 images, generating augmented versions of all images in the dataset. These augmented images are then combined with the original training set to create a new training set comprising 500 original images and 500 images augmented using traditional methods. To eliminate any potential influence of post-super-resolution images on the detection performance, no data augmentation is applied to the validation and test sets. The comparative results between the proposed method and traditional data augmentation techniques are presented in Table 3. The effectiveness of the proposed method on the training of the detection model was evaluated using three metrics: accuracy, recall, and mean Average Precision (mAP). Accuracy reflects whether the enhanced images contribute to more precise predictions by the model. Recall assesses the model’s ability to identify targets in the enhanced images; a higher recall indicates that the model can more accurately detect targets in the enhanced images, suggesting that the image enhancement method improves model performance. mAP serves as a comprehensive measure of the model's performance in object detection tasks on enhanced images. Higher mAP values indicate better performance in object detection, indirectly demonstrating the effectiveness of the image enhancement method. The experimental data in the table reveals that the super-resolution-based data augmentation method outperforms most traditional data augmentation techniques in enhancing recognition performance. This is primarily attributed to the fact that super-resolution enriches the details of the images based on the original image data, resulting in richer information compared to the alterations made by traditional data augmentation methods.
Horizontal comparison table of data enhancement experiments.

It is worth noting that in the experiment group where Gaussian noise was added as a data augmentation method, the recognition performance of the model decreased significantly on both the validation and test sets. This decline can be attributed to the excessive intensity of the added Gaussian noise, which disrupted the genuine structure of the data, leading to severe interference with the original features of the images. Consequently, the model struggled to extract useful information from this data, resulting in a degradation of its ability to learn from the original data. Moreover, the added Gaussian noise may not have been well-suited to the task itself. Fabric defect recognition involves identifying fine textures or edge information within the images, and the introduction of noise severely disrupted these details, leading to a decrease in recognition accuracy. This observation further validates the viewpoint proposed in this paper, namely that excessive noise, which disrupts the texture features of fabric images, should be avoided.
Notably, the experimental group using Gaussian noise for data augmentation achieved a recall (R) of 90.9% and an mAP@0.5 of 0.927, significantly lower than the baseline group’s 95.7% and 0.961, respectively, and performed the worst among all augmentation methods. The primary reason lies in the absence of data augmentation in the validation and test sets, combined with the excessive intensity of Gaussian noise, which disrupts the true structure of the data. This severe interference with the original image features hinders the model's ability to extract useful information, thereby impairing its learning capability. Moreover, Gaussian noise is poorly suited to the characteristics of fabric defect detection tasks. These tasks rely heavily on the recognition of fine textures and edge details in images, which are severely disrupted by the added Gaussian noise, leading to a decline in detection accuracy. This finding further supports the conclusion of this study, namely, that excessive noise that compromises texture features should be avoided in fabric image augmentation.
Regarding the experimental results of the optimized super-resolution method, it is evident that applying this enhanced dataset to the detection model led to an improvement in accuracy by 7.4%, recall by 1.0%, and average accuracy by 2.5% compared to using the original dataset for training.
The improvements in these performance metrics are not merely numerical but hold significant practical value. The 7.4% increase in accuracy substantially reduces missed and false detections in fabric defect detection, enhancing detection efficiency and minimizing reliance on manual inspection, thereby lowering labor costs. The 2.5% increase in mAP demonstrates improved precision in defect localization, which is critical for quality control and defect rectification. Overall, these advancements effectively reduce defect rates and rework, leading to significant cost savings and efficiency gains in real-world production processes.
Figure 15 provides an evaluation of the performance of the detection models enhanced by the method proposed in this paper as well as those enhanced by the aforementioned comparison data augmentation methods on the test set. The results indicate that the detection performance metrics of the models enhanced by StyleGan are the lowest, with the detection precision falling below 80%. Conversely, the models enhanced by CutGan and CycleGan exhibit detection performance metrics higher than those trained solely on the original data. This discrepancy arises because StyleGan severely disrupts the organizational texture features of the fabric during data augmentation, resulting in a decline in the quality of the fabric defect dataset. In contrast, employing the super-resolution image enhancement method improved in this paper yields the highest performance metrics across all detection tests. Furthermore, compared to the detection models enhanced by the Real-ESRGAN before improvement, the models enhanced by the method proposed in this paper demonstrate a 1.2% increase in F1 score.
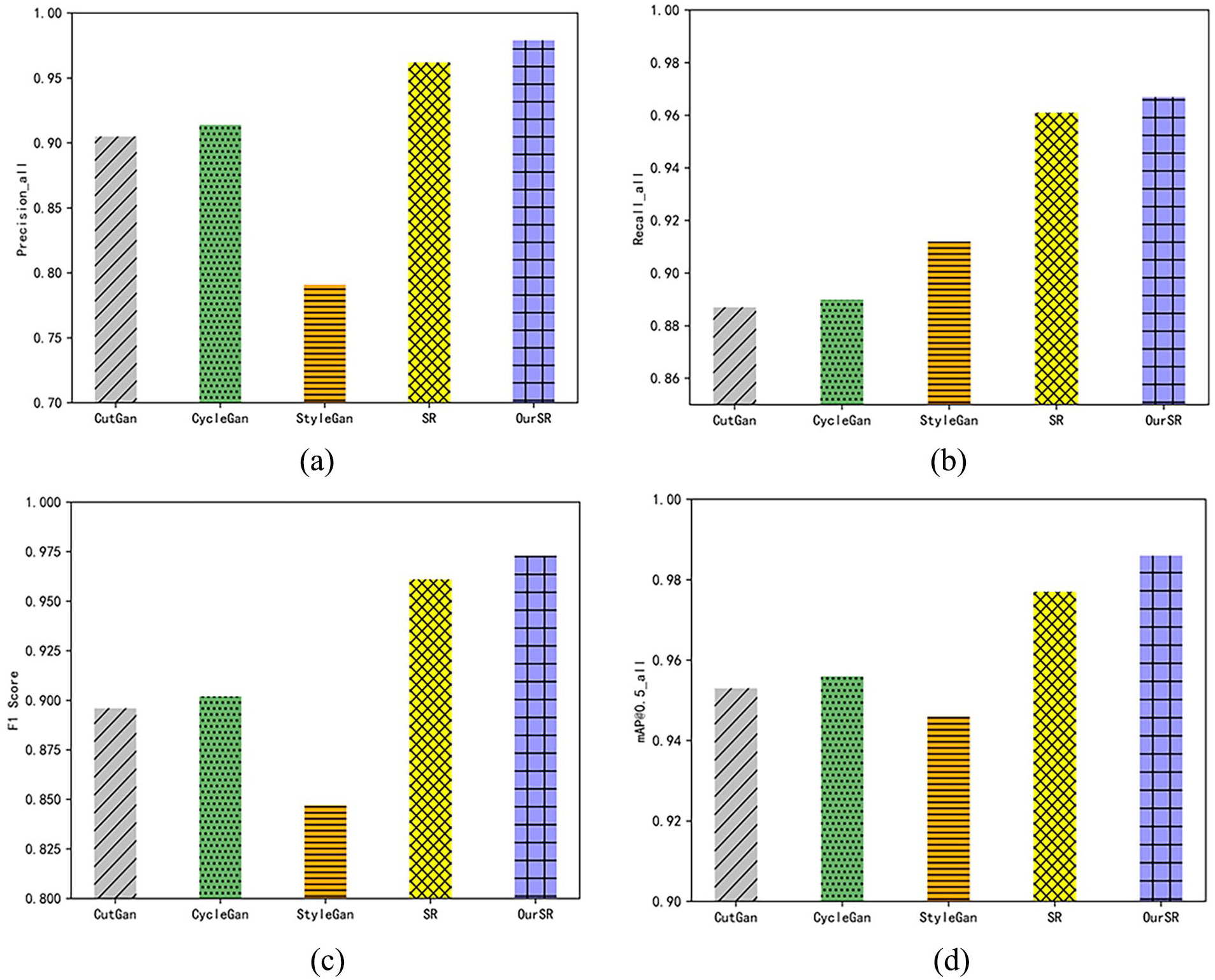
Comparison of indicators of different enhancement methods: (a) Comparison of precision rates, (b) Comparison of recall rates, (c) Comparison of F1 score, and (d) Comparison of mAP@0.5.
The improved Real-ESRGAN model demonstrates significant superiority over other augmentation methods, primarily due to two key optimizations. First, the model replaces traditional Gaussian noise in the resolution degradation module with Poisson noise. Gaussian noise, when kernel sizes are improperly chosen, often disrupts image details, leading to instability during training and suboptimal super-resolution results. In contrast, Poisson noise better approximates the characteristics of natural image noise, particularly under low-light conditions, where it excels. This substitution effectively prevents the complete loss of details, allowing the model to restore and enhance image features more effectively, thereby generating more stable and clearer super-resolution images. Second, the model incorporates a localized blur discriminative loss function to address the common issue of localized blur in super-resolution tasks. Traditional baseline models lack mechanisms to specifically handle blurred regions, often resulting in areas with inconsistent sharpness and texture. The localized blur discriminative loss optimizes the balance between blurred and sharp regions, producing sharper edges and clearer details while significantly reducing artifact generation. These two improvements not only enhance the effectiveness of image augmentation but also provide higher-quality data for the detection model, thereby improving performance metrics such as detection accuracy and recall.
To further investigate the impact of the data augmentation method proposed in this paper on the localization accuracy of the detection models, we compared the Decrease in Localization Performance 50 (DLP) values of the detection models enhanced by each data augmentation method. DLP represents the change in the model’s detection accuracy when the IoU threshold increases from 0.5 to 0.75, reflecting the variation in the model's localization accuracy. As shown in Table 4, the detection models enhanced by the data augmentation method proposed in this paper exhibit the smallest decrease in DLP values. Compared to the detection models enhanced by the Real-ESRGAN, CycleGan, CutGan, and StyleGan data augmentation methods before improvement, the DLP values of the models enhanced by the proposed method increased by 1.1%, 1.8%, 2.4%, and 3.3%, respectively, underscoring the effectiveness and advancement of the algorithm proposed in this paper.
DLP values of the detected model under different training data.

All the experimental results above indicate that when facing the challenge of insufficient textile defect sample data, the super-resolution data augmentation method proposed in this paper demonstrates remarkable advantages. This method not only preserves the texture features of the original textile images but also enriches the morphological characteristics of defects. Through the enhanced images, the detection model can more accurately capture textile defect targets, thereby significantly improving detection performance. This demonstrates that super-resolution data augmentation is an effective solution in scenarios with limited sample data. The proposed method directly contributes to advancements in fabric defect detection technology and, from a broader perspective, promotes the intelligent development of the textile industry. Enhancing defect detection technology is a vital step in the industry’s progression toward intelligent operations. By incorporating advanced algorithms and technical innovations, end-to-end intelligent management can be achieved—from raw material procurement and production to final product sales. This not only strengthens the industry’s competitiveness and sustainability but also provides robust support for addressing data scarcity in real-world applications.
Derived generalization experiments
The proposed data augmentation method was applied to the TILDA dataset,
51
which consists of fabric defect images collected in natural environments, to evaluate its generalization performance in real-world scenarios. The TILDA dataset contains authentic fabric defect images encompassing four common defect types: holes, threads, stains, and dirt. Following data preprocessing, a total of 395 images were selected for evaluating the model’s generalization capability, with all images resized to a uniform resolution of
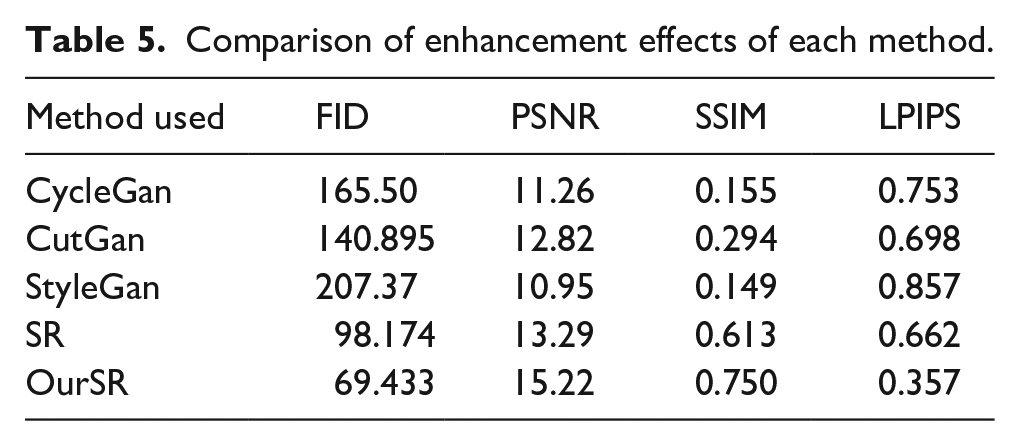
The experimental results, as shown in the Table 5, indicate that the performance metrics of the enhancement models on the TILDA dataset are slightly reduced compared to the DAGM2007 synthetic dataset due to the impact of complex acquisition environments on image quality. However, the proposed OurSR method demonstrated exceptional performance even in these challenging scenarios. In terms of image generation quality, OurSR achieved an FID score of 69.433, indicating a closer alignment between the generated images and the real data distribution. Regarding detail preservation, OurSR achieved a PSNR of 15.22 and an SSIM of 0.750, both substantially superior to other comparative methods, while attaining a remarkably low LPIPS value of 0.357. This further confirms that the generated images exhibit significantly reduced artifacts and improved visual consistency. These outstanding results can be attributed to two critical technical innovations. First, the incorporation of the local fuzzy discriminative loss effectively mitigated the common issue of localized blurring during the super-resolution process while substantially suppressing artifact generation. Second, the substitution of Gaussian noise with Poisson noise in the degradation module enhanced the authenticity of the images and preserved key fabric texture details. These advancements ensure the robustness and reliability of the OurSR method on the TILDA dataset, significantly improving the model's precision and resilience in complex environments. This demonstrates that OurSR offers a highly practical and effective data augmentation solution for fabric defect detection tasks.
Comparison of enhancement effects of each method.
Conclusion
To address the challenges of limited quality and quantity in datasets for fabric defect detection, this study proposes a blind super-resolution-based fabric data augmentation algorithm. First, the resolution degradation phase of Real-ESRGAN was thoroughly analyzed, and Gaussian noise was replaced with more stable Poisson noise. Subsequently, a localized blur discriminative loss function was designed, incorporating a self-residual operation to construct a weight matrix for loss penalization, effectively penalizing locally blurred images. The experimental results demonstrate significant improvements in the performance of fabric defect detection models using the proposed method. Specifically, after applying the proposed augmentation method to the DAGM2007 dataset, the YOLOv5n detection model achieved a 7.4% increase in accuracy, a 1.0% improvement in recall, and a 2.5% enhancement in mean Average Precision (mAP).
The proposed localized blur discriminative loss function effectively suppresses local blur phenomena in fabric images during the super-resolution process and enhances image quality by reducing the generation of artifacts. Compared to traditional data augmentation methods, the proposed approach outperforms in terms of image enhancement evaluation metrics, including FID, PSNR, SSIM, and LPIPS, thereby validating its effectiveness in image enhancement tasks. These advancements not only demonstrate the superiority of the proposed method but also achieve the initial research goals of improving the accuracy of fabric defect detection and minimizing artifact generation. Furthermore, experimental results indicate that the augmented data significantly enhance the localization accuracy of detection models, underscoring its potential for practical applications.
From a broader perspective, the proposed method advances fabric defect detection technology and provides a solid foundation for further exploration of super-resolution techniques in image enhancement and defect detection. By improving the quality of fabric defect datasets, the method contributes to the intelligent development of the textile industry, reducing reliance on manual inspection, lowering labor costs, and enhancing production efficiency and product quality. In the future, this method could be applied to other image datasets or industries, offering new insights for image enhancement, artificial intelligence in manufacturing, and industrial automation. This would further validate its universality and scalability across various domains.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the Research Project of the Zhejiang Provincial Department of Education (Y202455953), the Zhejiang Sci-Tech University Research Start-up Fund, China (No. 23242083-Y) and the Science and Technology Program of Zhejiang Province, China (No. 2022C01202, No. 2022C01065).