
Abstract
This study proposes an algorithm for classifying colour differences in dyed fabrics using random vector functional link (RVFL) optimised using an improved hunger games search (HGS) algorithm to replace the inefficient traditional classification methods. First, to prevent the HGS algorithm from easily arriving at the local optimal solution, we used the grey wolf optimiser (GWO) to generate the solution set of the HGS algorithm. Subsequently, to reduce the impact of the randomness of the input weight and hidden layer offset on the classification accuracy of RVFL, we used the improved HGS to optimise these two parameters of RVFL. Finally, the RVFL optimised using the improved HGS algorithm is used for classifying the colour differences of dyed fabrics. The performance of the proposed classification algorithm is compared with HGS algorithms improved using the whale optimiser, sine cosine algorithm, and Harris hawks optimiser. The results revealed that the proposed algorithm possesses several advantages, including the maximum, minimum, and average classification errors; good stability; and fast convergence.
Keywords
Introduction
The colour quality of dyed fabrics is an important index for the product detection of textile printing and dyeing enterprises. The traditional methods for classifying colour differences in dyed fabrics mainly depend on manual classification by experienced and skilled workers. This method is highly subjective and easily influenced by the visual fatigue of the classifier; therefore, this method cannot meet the requirements of the automatic production of dyed fabrics. A model for classifying colour differences in dyed fabrics is, therefore, required to establish the relationship between the colour feature information and evaluation index. Using this model, a reasonable classification can be performed according to the colour feature information. With the emergence of machine vision and intelligent learning algorithms, the algorithms to classify the colour differences of dyed fabrics based on intelligent learning are used to build high-precision models to meet the requirements of the automatic production of dyed fabrics.
Recently, many scientists have studied the colour differences of dyed fabrics to improve the automatic production of these fabrics.1,2 For example, Wang et al. 3 proposed a method for producing qualified dyed fabrics with unqualified dyed yarns. Xin et al. 4 proposed a method to classify the colour textures of coloured fabrics based on a double-sided back propagation neural network and co-occurrence matrix. Li et al. 5 used Levenberg-Marquardt optimised backpropagation algorithm to detect the L*a*b* value of the image of a fabric sample and subsequently combined the colour difference of the fabric, which was calculated using a formula. Zhang and Yang 6 reported that a support vector machine model optimised using a genetic algorithm was applied to evaluate the consistency of colour and uniformity of dyeing according to the measured correlation characteristics of the colour differences. Wang et al. 7 proposed a proofing strategy with a standard yarn arrangement to detect warp alignment errors by analysing different types of these errors in an attempt to develop an automatic warp colour detection system. Xie et al., 8 adopted the image pyramid principle to downsample images for correcting the illuminance of the images of warp knitted fabrics to improve the real-time online detection of the colour differences of these fabrics. Barua et al. 9 used a deep learning model to identify defects such as holes, missing yarn, yarn breaking, and dyeing that may occur during the production process of coloured fabrics. The application of neural networks to investigate the colour differences in fabrics provides a method for improving the production efficiency of these fabrics. However, most neural networks suffer from the disadvantage of a long training time. Deep learning requires several training samples and complicated calculations.10–12 To shorten the training time of traditional neural networks for detecting the colour differences of dyed fabrics, Zhou et al. 13 dynamically selected parameters and applied a differential evolution algorithm to optimise the parametric combination of a regularisation limit learning machine model, which can increase the classification accuracy pertaining to colour differences. Li et al. 14 employed an improved grasshopper optimiser to improve the bandwidth and penalty parameters of a kernel extreme learning machine to achieve a superior classification of colour differences. The application of the optimisation algorithm improved the classification accuracy of the neural network. In recent years, novel optimisation algorithms have been proposed, such as grey wolf optimiser (GWO), 15 sine cosine algorithm (SCA), 16 whale optimisation algorithm (WOA), 17 marine predators algorithm, 18 Harris hawks optimisation (HHO),19,20 hunger games search (HGS) 21 and dragonfly algorithm, 22 which have been widely used in research.
The learning ability of deep learning models is very strong; however, their design is complex. Additionally, the number of calculations required is large, and the requirements for hardware and cost are extremely high. Unlike deep learning algorithms, random vector functional link (RVFL) does not require high-quality computing hardware and has obvious advantages in computing volume. RVFL 23 randomly sets the weights of the hidden and input layers during the training process. The kernel of the RVFL ameliorates nonlinear raw data with the hidden layer learning to increase the nonlinear kernel raw data to enhance the generalisation ability of the RVFL. Based on the aforementioned study, this study proposes a classification method for the colour differences of dyes using an improved HGS optimised RVFL. The main objectives are as follows:
An HGS algorithm improved using GWO is proposed. In this study, we used the GWO algorithm to determine the initial population of the HGS algorithm. Because the location of the prime search agent is close to that of the optimal solution after processing, the HGS can largely avoid arriving at the local optimal solution.
The improved HGS algorithm is proposed to improve the hidden layer offset and input weight of RVFL. The hidden layer bias and input weight are the decisive factors affecting the classification performance and network stability of RVFL.
The improved RVFL is used for the classification of colour differences of dyed fabrics, and the stability, convergence, and significance of the proposed GWO-HGS-RVFL model are analysed.
Preliminaries
RVFL network
In the network proposed in Pao et al.,
23
N samples are present,

where

Equations (1) and (2) can be directly expressed as:

Equation (3) can be expressed as a matrix as follows:

where
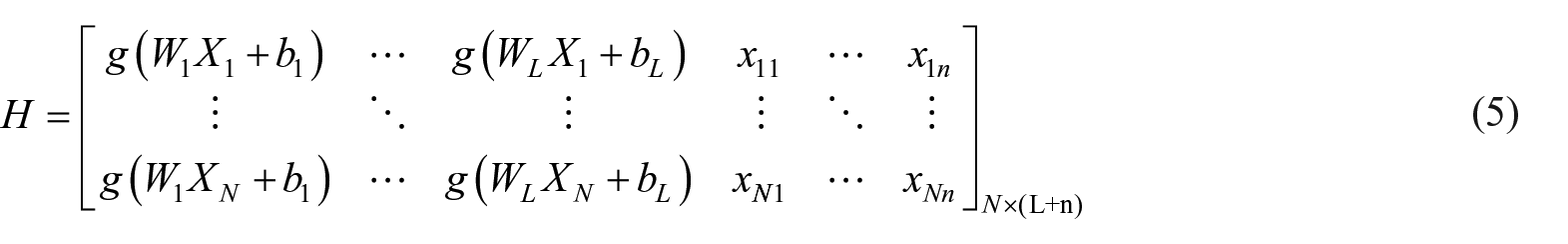


Furthermore,
GWO algorithm
The GWO algorithm 15 uses mathematical modelling of the hierarchy among wolves, as well as their encircling, tracking and attacking behaviour towards other animals, to mathematically express the lives of grey wolves and their methods of capturing prey. Grey wolves usually encircle their prey, and this behaviour can be expressed in the following mathematical form:


where t is the current iteration,
Grey wolves find a specific prey and surround it. The commander of the hunting operation is usually known as an alpha wolf, whereas beta and delta wolves may participate in these hunting operations as well, and allow search agents to improve their positions with respect to their initial positions. The position of the search agent is updated as follows:

When the prey stops moving, the grey wolf attacks it to complete the hunt. To model the approaching prey,
HGS algorithm
The HGS algorithm 21 can be used for global search and optimisation to avoid arriving at the local optimal solution. The activities and behaviours of a hungry animal can be represented by the following mathematical model:

where R is a random number located between [−a, a],

where


where
To mathematically model hunger in an individual,

Additionally, W2 is calculated as follows:

where hungry is the degree of starvation of the ith unit; N is the total number of units; SHungry represents the sum of the degrees of hunger of all the individuals and

where


where
Proposed model for classifying the colour differences in dyed fabrics
HGS algorithm improved using GWO
The HGS algorithm possesses excellent features. More specifically, the classification accuracy after convergence, as well as the convergence speed, of the HGS optimisation algorithm is high, and the algorithm can locate the optimal solution globally. The mathematical model of the approaching prey reveals that the random numbers and constants influence whether an animal will approach the prey, as well as the speed of this approach. Therefore, the HGS algorithm continues to arrive at the local optimal solution when seeking the best solution. Additionally, the process of seeking the optimal solution is slow. In contrast, the GWO algorithm retains the current optimal solution, as well as the second and third alternate solutions, owing to the strict hierarchical system of the algorithm. This enhances the ability of the algorithm to search for the optimal solution globally if the current optimal solution falls within the local area. The local optimal solution, as well as the second and third alternative solutions, can be used to search for the global optimal solution, which should rank among the top three solutions. Therefore, GWO is first applied to optimise the HGS algorithm and provide a suitable initial position for this algorithm. The location of the population search agent in the GWO algorithm after optimisation is ranked among the top three. Subsequently, all the population search agents are transferred to the HGS algorithm to initialise its population. At this point, the position of the search agent that has been determined is close to the optimal solution. This effectively prevents the solution from falling within the local area.
Optimised RVFL model for classifying colour differences
Hidden layer offset and input weight are decisive factors that affect the classification performance and stability of RVFL. Therefore, the randomness of the hidden layer offset and input weight will affect the classification accuracy of RVFL when classifying the colour differences of dyed fabrics. To reduce this effect, the HGS algorithm improved using GWO can be applied to optimise the aforementioned parameters and use them to initialise each individual in the population of RVFL. After the cycle, the position that allows the best classification is located and the hidden layer offset and input weight are assigned accordingly in an attempt to improve the stability and classification accuracy of RVFL. The classification error rate of RVFL on the test set is considered to be the fitness function of the optimisation algorithm as follows:

where F and N are the classification error rate and number of samples in the test sets, respectively,
The proposed model for classifying colour differences using GWO-HGS-RVFL for dyed fabrics is shown in Figure 1. The initial population directly influenced the astringent rate of HGS and ability of the algorithm to avoid arriving at the local optimal solution. The steps following steps are employed by GWO-HGS-RVFL to classify the colour differences in dyed fabrics:
Use high-precision industrial cameras to obtain the images required for the experiment and change the image format.
Calculate the colour differences within the images of the dyed fabrics, and classify the dyed fabrics according to the colour differences. Additionally, combine the features to generate the dataset required for the experiment.
Set the population size N of the GWO, and calculate the dimension of each individual in the population according to:
Update the rank of the wolf pack in GWO and rearrange the position of each search agent to form a matrix. Subsequently, pass the matrix to the hidden layer offset and input weight of RVFL. Use the test set to obtain each search agent in RVFL. Arrange the population positions according to the fitness level, and the alpha wolf is ranked first.
When the positions of all the individuals in the population have been saved and arranged according to the fitness level, the GWO algorithm can be terminated. Use the population positions to initialise the population of the HGS algorithm.
Initialise the other parameters and run the HGS algorithm. Subsequently, calculate the fitness level of the individuals within the population based on the classification accuracy of RVFL.
Update the parameters in the algorithm to calculate the values of hungry, W1 and W2, and subsequently calculate the parameters for every individual.
Update the position of every individual.
When the algorithm reaches the maximum number of iterations, save the position of the individual with the best fitness and pass the position as a parameter to RVFL.
Use the test sample to evaluate the classification model based on RVFL to classify the colour differences in dyed fabrics.

Model classifying the chromatic aberration of dyes using GWO-HGS-RVFL.
Experimental results and analysis
Six other algorithms are compared with the proposed GWO-HGS-RVFL algorithm. These include improved RVFL algorithms based on GWO (GWO-RVFL), HHO (HHO-RVFL), SCA (SCA-RVFL), WOA (WOA-RVFL) and (HGS-RVFL). The operating system used in this experiment is Windows 10, and MATLAB 2021b is used for programming.
Experimental setup
The data set is acquired using the device displayed in Figure 2, and a high-precision colour industrial camera is used to capture the images of the fabrics using standard light sources. The choice of the light source is crucial for classifying the colour differences of dyed fabrics because an inappropriate light source can cause colour distortion. Since this study classifies the colour differences of dyed cotton and polyester fabrics, D65, D50 and A light sources were chosen, which are the three most common light sources in the textile industry.
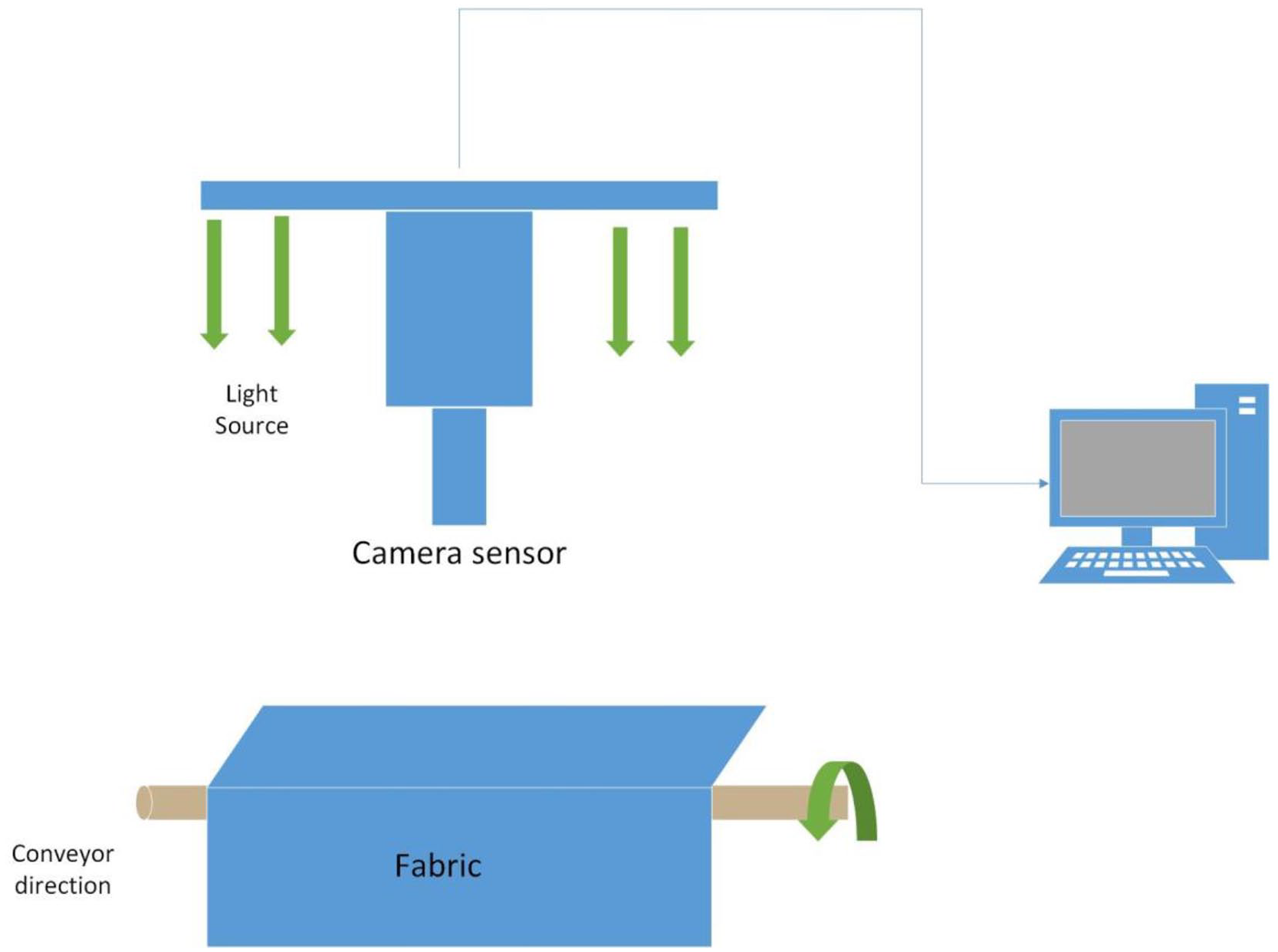
Diagram of the experimental setup.
The obtained images are transferred to a computer for processing to obtain the relevant dataset. The colour difference is calculated as follows:

The diagram of the device used in this experiment is shown in Figure 2, and the classification of the colour differences is shown in Table 1.
Intervals used for classifying colour differences.

The acquisition process of the dataset is described as follows:
Perform Gaussian denoising on the images captured by the camera, convert the image format, convert the RGB image to an HSV image, and calculate ∆H, ∆S, ∆V. Next, convert the image to the CLELAB colour space and calculate the values of ∆L, ∆a, ∆b.
Calculate the colour difference of each image and classify all the images according to the level assigned to the colour difference.
Combine the features and levels of each image to constitute a dataset. In this experiment, 1400 datasets are constructed. Each dataset has six features and a level category consisting of a total of seven dimensions.
Arithmetic parameter selection
Selecting the activation function
The choice of the activation function of the RVFL neural network affects the accuracy of RVFL. To maximise the accuracy of the experimental results, the number of nodes in the hidden layer of the network is set to 50, and the RVFL neural network applies five-fold cross-validation when using different activation functions. The results obtained are averaged for verification, and the algorithm is executed 10 times. The outcomes of these 10 executions are recorded, and the average value and standard deviation of these outcomes are calculated. As shown in Table 2, when using ‘sig’ as the activation function of RVFL, the classification accuracy of the neural network is only 0.002 smaller than the highest classification accuracy obtained from the ‘sin’ activation function. Additionally, the standard deviation of the classification accuracy obtained using ‘sig’ is the smallest among those obtained using the other activation functions. Based on the classification accuracy, applied ‘sig’ is applied as the activation function of the neural network in the next experiment.
Experimental results of the effect of the activation function of RVFL.

Effect of the number of nodes in the hidden layer of RVFL on the classification accuracy
In RVFL, the number of nodes is a key factor affecting classification accuracy. When the number of nodes is too low, RVFL cannot be fitted, thereby resulting in low classification accuracy. In contrast, when the number of nodes is too high, RVFL will be over-fitted, thereby making the neural network ineffective in classifying data other than training samples. This experiment tests the classification accuracies of the various algorithms according to the number of nodes in the hidden layer. The number of nodes in the hidden layer is increased from 5 to 100, and five-fold cross-validation is performed. Subsequently, the algorithm was executed 10 times and the average value was considered to be the final result. Table 3 and Figure 3 show the classification accuracies of the various algorithms for different numbers of nodes in the hidden layer.
Classification accuracies of various algorithms based on the number of nodes in the hidden layer.


Effect of the number of nodes on the classification accuracies of various algorithms.
Figure 3 reveals that if the number of nodes in the hidden layer is set between [5,50], the classification accuracy of a neural network increases with the increase in the number of nodes. However, when the number of nodes is set between [50,100], the classification accuracy increases relatively slowly and subsequently stabilises. After comprehensively analysing the images and tables we conclude that when the number of nodes reaches 80, the classification accuracy becomes relatively stable; therefore, the number of nodes in the hidden layer of the model was set to 80 in this experiment. In addition, we can conclude that the classification accuracies of HGS-RVFL and GWO-HGS-RVFL are better than those of the other algorithms when the number of nodes in the hidden layer is small.
Parameters of the improved HGS algorithm using GWO
Population size and the number of iterations play an important role in an optimisation algorithm and setting these parameters improperly consumes unnecessary resources. If these parameters are too large, the algorithm will execute for an extended duration and increase the time cost. However, if these parameters are too small, the algorithm will produce poor results, thereby resulting in low classification accuracy. In this experiment, different values are set for the two parameters, and different classification accuracies are obtained. These classification accuracies are then compared to obtain the best combination of the number of iterations and population size. The population size can assume five possible values, that is, 10, 20, 30, 40 or 50, and the number of iterations can assume six possible values, that is, 5, 10, 15, 20, 25 or 30. Additionally, 30 combinations of these two parameters are possible. We applied each combination to GWO-HGS-RVFL, averaged the results using five-fold cross-validation, and the final result obtained is the average of 10 executions of the algorithm.
Figure 4 displays the influence of different combinations of the two parameters on the classification accuracy of the algorithm, which is represented by the bubbles in the image. When the population number or number of iterations increases, the area of the bubble increases. For fixed population size, with the increase in the number of iterations, the classification accuracy of the algorithm gradually improves. Additionally, for a fixed number of iterations, with the increase in the population size, the classification accuracy of the algorithm improves gradually. However, when the population size is set to 40 or 50, the classification accuracy of the algorithm does not change substantially; therefore, we set the population size to 40. Because the convergence speeds of different algorithms are different, the number of iterations is set to 60 in this experiment.

Classification accuracy of the algorithm according to the population size and number of iterations.
Parameter settings for the various algorithms
To ensure the credibility of the results, the parameter settings are consistent with those of GWO-HGS-RVFL. The activation function of RVFL is set to ‘sig’, number of nodes in the hidden layer is set to 80, population size in the optimisation algorithm is set to 40, and number of iterations is set to 60.
Discussion of the results obtained from the algorithms
This experiment uses five-fold cross-validation for the algorithms, and the obtained results are averaged. The algorithms are executed 10 times to reduce the randomness of the results and improve their credibility. Table 4 displays the minimum value (Min), maximum value (Max), standard deviation (Stdv) and average value (Avg) obtained by executing various algorithms 10 times.
Comparison of the experimental results obtained from various algorithms (the optimal values are displayed in bold).

Convergence, significance and stability analyses of the algorithms
Stability analysis
Figure 5 shows a box diagram of the classification error rate of the algorithms used in this experiment. The algorithm uses five-fold cross-validation results to average the error rate of each algorithm, and the algorithm was executed 10 times. The classification error rate obtained is saved in the box and displayed in the form of a pattern diagram. The upper and lower horizontal lines of each box represent the maximum and minimum error rates obtained from the 10 executions of the algorithms. The open circles are abnormal points, and the lower and upper borders of each box represent the one-quarter and three-quarter digits of the error rates, respectively. The green horizontal lines inside the boxes represent the medians of the error rates. From the lengths of the boxes in Figure 5, the stability of GWO-HGS-RVFL can be observed to be substantially better than those of GWO-RVFL and WOA-RVFL, slightly better than that of HHO-RVFL, and similar to those of SCA-RVFL and HGS-RVFL. Additionally, Table 3 and Figure 5 reveal that the proposed GWO-HGS-RVFL algorithm in this study possesses a small error and good stability.

Classification error rate box plot of the various algorithm.
Algorithm convergence analysis
In Figure 6, the convergence speed of GWO-HGS-RVFL is compared with those of the other algorithms, in which the classification error rate is used to express the fitness. From the figure, we can clearly observe that the astringent speed of GWO-HGS-RVFL is much higher than those of the neural networks optimised using other algorithms. Additionally, when the number of iterations increases gradually, the fitness of GWO-HGS-RVFL is very low. The performance of this algorithm is excellent and obtained fitness is nearly the same as the final fitness of HGS-RVFL. GWO-HGS-RVFL reaches the smallest degree of fitness in the smallest number of iterations. The comprehensive analysis confirmed the superiority of GWO-HGS-RVFL.

Convergence analysis results of the various algorithms.
The no lunch theory 24 indicates that an optimisation algorithm cannot perform well when all its parameters are optimised. Therefore, we initialised the population of the HGS algorithm using GWO to improve the convergence speed of HGS and avoid the local optimal solution, thereby improving the classification accuracy of RVFL.
Difference between algorithms
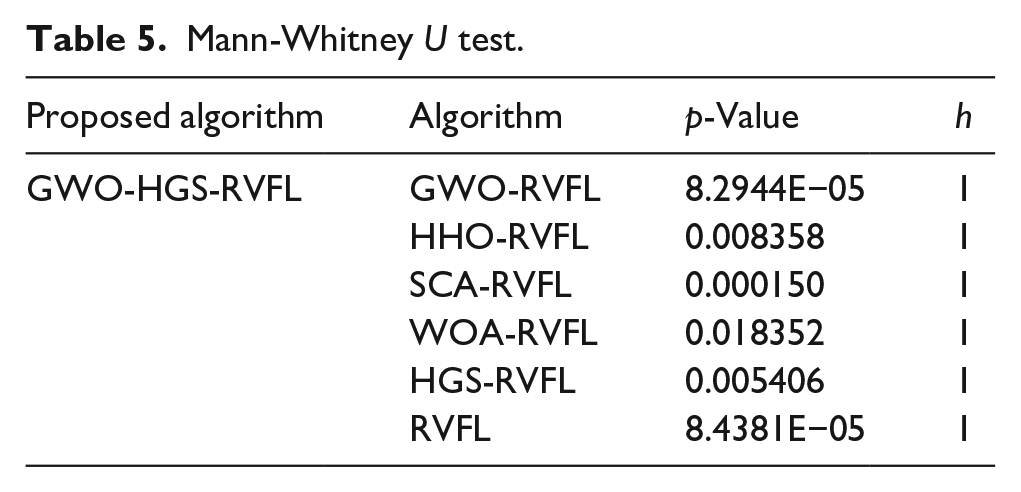
To determine the difference between GWO-HGS-RVFL and other algorithms, Mann-Whitney U test is used to analyse the experimental results. Similar to previous experiments, to increase the reliability of the results, we use five-fold cross-validation, each algorithm is executed 10 times, and the results of the 10 executions are averaged.
Table 5 reveals that the p-value of GWO-HGS-RVFL and the other algorithms is less than 0.05 and h is equal to one for all the algorithms; therefore, considerable differences exist between GWO-HGS-RVFL and the other algorithms. The experimental results prove that GWO optimises HGS and subsequently optimises RVFL, which results in obvious advantages over using HGS alone.
Mann-Whitney U test.
Conclusion
This study proposed an algorithm for the classification of dyes based on an improved HGS optimisation of the RVFL neural network. From the experimental results, we can draw the following conclusions:
The convergence analysis and corresponding graphs reveal that the HGS algorithm improved using GWO has a better convergence speed and higher accuracy than those of the other algorithms.
The stability analysis and box diagram reveal that the HGS algorithm improved using GWO has better stability than those of other algorithms.
GWO can be used to initialise the population of HGS. such that the probability of HGS arriving at the local optimal solution is greatly reduced.
Additionally, obvious differences exist between GWO-HGS-RVFL and other algorithms, and GWO-HGS-RVFL is superior to the other algorithms.
In the future, further research will be conducted on the application of the proposed algorithm in enterprises. Additionally, we will attempt to solve the real-time problems associated with online production at enterprises and process large amounts of data required for detecting and classifying colour differences.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by Zhejiang Provincial Department Education (No. FG2020056) and Zhejiang Provincial Key Research and Development Programme (No. 2021C03013).