
Abstract
With the continuous development of deep learning, due to the complexity of the deep neural network structure and the limitation of training time, some scholars have proposed broad learning, the Broad Learning System (BLS). However, BLS currently only verifies that it has excellent effects on some of the network training data sets, and it does not necessarily have excellent effects on some actual data sets. In response to this, this paper uses the effect of BLS in predicting the unevenness of yarn quality in the yarn data set, and proposes a BLS-based multi-layer neural network (MNN) for the problems, which is called Broad Multilayer Neural Network (BMNN).
Keywords
Introduction
In recent years, reducing production costs has always been one of the important goals for the survival and development of enterprises. For textile enterprises, the quality of the yarn quality forecast determines the level of production costs. Therefore, yarn quality prediction occupies an extremely important position in textile enterprises, and it is also one of the hot topics that experts and scholars have been paying attention to.
For the evaluation of the effect of yarn quality prediction, many scholars have always used strength as the index for evaluating yarn quality, and have done a lot of research on strength. Among them, Cheng and Adams 1 first tried to use a neural network to solve the problem of inaccurate force prediction in yarn quality prediction. Subsequently, in the period of the rapid development of neural networks, Furferi and Gelli 2 proposed a model based on feedforward back propagation (BP) artificial neural network to predict yarn strength. Mwasiagi 3 proposed a DE-ELM algorithm combining differential evolution (DE) algorithm and Extreme Learning Machine (ELM) to predict the strength of spun yarn; Zhenlong et al. 4 combined convolutional neural network (CNN) and BP neural network, and proposed a CNN-BP neural network to predict yarn strength; Hu et al. 5 considers the influence of time on yarn quality and strength, and proposes a yarn strength and quality prediction model based on artificial recurrent neural network (RNN).
However, the index for judging the yarn quality is not only the strength index, the unevenness of the yarn is also one of the extremely important indexes. The uniformity of the yarn determines the quality of the textile to a large extent, and the influence on the next process and the cloth surface is reflected in the following aspects: the first is to determine the end breakage of the next process, which affects the production efficiency. The second is to determine the difference in cloth surface, shading, color gradation. The third is to determine the mechanical and physical properties of the cloth surface.
The prediction problem of yarn unevenness is a nonlinear problem. A good solution to nonlinear problems is to use neural network to predict them, and many scholars have studied it. Üreyen and Gürkan 6 proposed the use of artificial neural network (ANN) to predict the unevenness of ring-spun yarn and compared it with the linear regression model. The results showed that: the prediction effect of using ANN to predict the unevenness of ring-spun yarn is better. Üte and Kadoğlu 7 used a multiple linear regression method to establish a model for estimating the uniformity of Siro spun yarn from cotton fiber characteristics. Aiming at the uniformity of blended yarns, Malik et al. 8 also uses ANN to predict the unevenness of yarn and compares it with multiple linear regression. The results show that the use of ANN is effective in predicting the unevenness of yarn. Wu et al. 9 aimed at the difficulty of optimizing weights and thresholds in neural network, and proposed a method of using the Mind Evolutionary Algorithm (MEA) to optimize the weights and thresholds of the BP neural network, and then predict the unevenness of the yarn. Ghanmi et al. 10 proposed a fuzzy artificial neural network prediction model based on expert experience on the prediction of yarn quality. This model combines ANN with fuzzy experts. The results show that this method has high accuracy. Singh et al. 11 studied several key production process parameters that may affect the unevenness of the yarn, including three process parameters: spring stiffness, conveying speed, and coil position. The results show that: coil position and stiffness of the spring have a great influence on the unevenness.
With the advancement of technology, people are facing more and more complex problems. The use of neural network alone can’t meet people’s requirements, so deep neural network came into being. However, deep neural network has its limitations: long training time, complex structure, numerous parameters, and it is difficult to find the optimal parameters. Because of the limitations of deep neural network, some scholars have proposed an alternative structure of deep neural network: Broad Learning System (BLS). The predecessor of the Broad Learning System is the functional link artificial neural network (FLANN), which was first proposed by Pao, 12 including a single-layer neural network. Subsequently, Pao and Takefuji 13 established a high-order neural network without hidden units. Without hidden units, there is no need to train and optimize the hidden units, which greatly reduces the running time of the network. Patra et al. 14 proposed the use of FLANN to identify nonlinear dynamic systems for nonlinear dynamic systems. Mahapatra et al. 15 used different polynomial functions to link artificial neural network to predict and classify Indian stocks and proposes four polynomial basis functions in the article: Chebyshev, Laguerre, Legendre, Power, which used different polynomials to enhance input to predict stocks. Zhang and Suganthan 16 introduced the random vector function link neural network (RVFLNN) into the image tracking field and combined it with the CNN to construct a new network convolutional random vector function link network (CRVFLNN). The new network is easy to train, and the training speed is faster, and there is no need to adjust the hyperparameters, so it can solve the problems in image tracking. Sahoo and Chakraverty 17 proposed the use of FLANN to predict the structural response of high-rise buildings due to seismic loads and compare them with multi-layer neural network. Experimental verification is carried out under two-story, five-story, and ten-story buildings, and the results show that using FLANN not only runs fast but also has high accuracy. Zhang et al. 18 proposed the use of RVFLNN to predict the temperature of subway stations, which met the requirements of the rapid prediction of subway stations. Sheng et al. 19 aimed at the limitations of the previous RVFLNN: only training on a specific training set, and proposed a sliding time window method based on RVFLNN for dynamic prediction of electronic equipment cabins. Chen and Liu 20 designed BLS based on the idea of RVFLNN for the problem that deep architecture and learning require extremely time-consuming training processes. There is no hidden layer inside the BLS. The feature nodes and enhancement nodes are all obtained by changing the input data through a random function. The weight calculation of the input and output only needs to do an inversion operation. At the same time, increasing the data of the enhanced node can increase the complexity of the model and meet the complexity requirements of the model. Yang et al. 21 used BLS to predict and analyze the throughput of port containers, and the results showed that compared with traditional time series-based models, using BLS has higher accuracy. Based on the previously proposed BLS, Chen et al. 22 carried out a mathematical proof of its universal approximation properties. It can be proved that BLS is a nonlinear function approximator, and several variants of BLS are proposed at the same time.
Based on the research of the above scholars, it can be known that many scholars generally believe that the problem of yarn unevenness prediction is a nonlinear problem, and most of them use neural network to predict it. BLS is also a nonlinear function approximator, which has the advantages of fast speed and high accuracy. Similarly, the current BLS has not proven its universal advantage in all data sets. In response to this problem, this article first uses a multi-layer BP neural network to predict the unevenness of the yarn and then uses BLS to predict the unevenness of the yarn. When it is found that BLS has a poor prediction effect in the current data set, a multilayer neural network based on the idea of BLS is proposed.
The main contributions of this paper can be summarized as:
(i) A feature selection method combining expert experience and Pearson coefficient is proposed;
(ii) Based on the idea of BLS, a multi-layer neural network based on the idea of BLS is proposed and called the Broad Multilayer Neural Network (BMNN);
(iii) Use the BMNN to predict yarn unevenness, and compare it with the multi-layer neural network and BLS to verify the reliability and superiority of BMNN in predicting yarn unevenness of small samples.
Data processing and feature selection
Data cleaning
There may be outliers in the data from the factory, and there may be noise between the data. This paper uses the method of expert experience to clean the data. The specific operation process is:
(i) Obtain experimental data from the factory database;
(ii) Eliminate noise data through expert experience. Since the data generated when the device is first started is inaccurate and contains serious noise, it is necessary to delete the noise data through expert experience to ensure the accuracy of the data;
(iii) Supplement or delete missing values in the data. The number of missing parameters in each data is determined in turn. If the number of missing parameters is greater than M, the data is judged to be unsupportable and is deleted. Otherwise, according to the idea of the nearest neighbor, we find out the K nearest neighbors of this data except for the missing parameters, and average them to supplement the missing values in the data;
(iv) Determine abnormal data through expert experience. Obtain the upper and lower limits of each parameter in the data through expert experience, and then judge whether the data is abnormal by judging each parameter to see if it exceeds the limit. If the data is abnormal, delete this data, otherwise, it is normal data;
(v) Normalize the data to eliminate the influence of dimensions.
Data normalization
In order to solve the inconsistency of each parameter unit of the data and to facilitate data processing, the normalization process is performed. The normalization processing method of data is:

Among them,
Feature selection based on statistics-Pearson correlation analysis
Pearson’s correlation coefficient is a commonly used method to statistically investigate the degree of correlation between two things, mainly used to explore the linear correlation between two independent continuous numeric variables. The Pearson correlation coefficient between vector

Judge the positive and negative correlation between
Feature selection based on expert experience
In the case of a small number of data samples, the expert experience will have a great impact on the result of feature selection.
The weight
(i) For each input parameter


Among them,
(ii) For each input parameter

(iii) Calculate the frequencies that fall within each set of weights;
(iv) Take the group median of the group where the maximum frequency is located as the weight of the input parameter
(v) According to the above steps, the influence coefficient of each input parameter given by the expert on the unevenness can be obtained, and the weight of each input parameter can be sorted.
Broad multilayer neural network
The Broad Multilayer Neural Network (BMNN) introduces the concept of feature nodes and enhanced nodes in BLS based on traditional multi-layer neural network. The feature nodes are used to extract the characteristics of the input data, and the enhancement nodes reflect the state of the input data and collectively serve as the first input layer. The weight between the input layer and the output layer is calculated through the multi-layer hidden layer network and the back propagation algorithm, and then the corresponding relationship is obtained.
Feature extraction
The multi-layer neural network based on enhanced nodes does not directly use the original data as the input layer, but first performs some transformations on the data

Among them,
Feature enhancement
Feature enhancement refers to the enhancement matrix transformation of the feature layer. Among them, the enhancement nodes are affected by all the feature nodes, reflects a certain state of the feature nodes, and is obtained by linear mapping and activation function transformation on the feature nodes. As shown in formula (7).

Among them,
Input layer
BMNN is developed based on the Random Vector Function Linked Neural Network (RVFLNN), where RVFLNN is shown in Figure 1.
Network structure of RVFLNN.
In RVFLNN, the input nodes are used as a layer, and the enhancement nodes are used as a layer. The structure of Figure 1 is deformed, the input nodes and the enhanced nodes are lined up and regarded as a whole, and a new simplified version of the network structure is obtained, as shown in Figure 2.

RVFLNN deformed network structure.
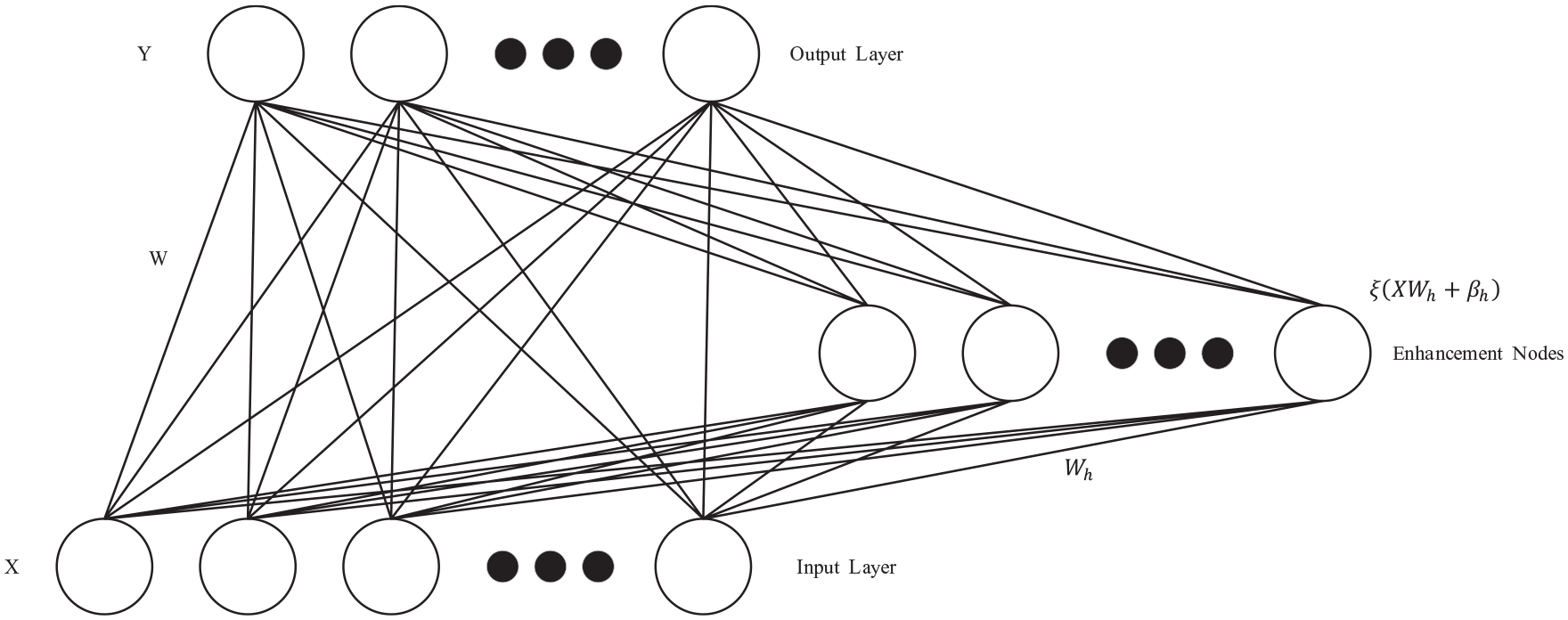
The input layer of BMNN is the same as the input layer of RVFLNN’s new simplified version of the network structure. The feature layer and enhancement layer are lined up through structural transformation, and they are regarded as one as the input layer of BMNN. Its specific structure is shown in Figure 3.

BMNN network structure.
As shown in Figure 3, the input layer is a combination of the feature layer and the enhancement layer, and its specific representation is shown in formula (8).

Among them,
Hidden layer
The hidden layer of BMNN performs a weighted summation of the output values of the neurons in the previous layer, performs nonlinear processing with the activation function, and outputs it as the input value of the latter layer. The output values of the t-th hidden layer are calculated as shown below.

Among them,
Output layer
When the output of the last hidden layer is obtained, the output value of the output layer is obtained through linear mapping and non-linear transformation. The output value is calculated as shown in formula (10a), (10b).

Among them,
Parameter update
In the BMNN network, the value of the feature nodes and the enhancement nodes will not change after being calculated and passed into the input layer, and the corresponding random bias will not change. The main changes in the BMNN network are the weight matrix and bias matrix from the input layer to the hidden layer, the hidden layer to the hidden layer, and the hidden layer to the output layer. This article chooses the Adam algorithm to update the weights and bias parameters. The main steps of the update are as follows:
(i) Calculate the loss function at
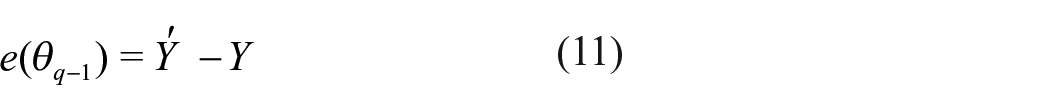
Among them,
(ii) Calculate the gradient at time
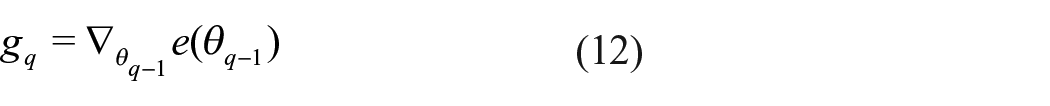
Among them, (iii) Using the idea of momentum algorithm, comprehensively consider the historical momentum and current gradient, and calculate the gradient of the current step;

Among them, the
(iv) Calculate the exponential moving average of the square of the gradient;

Among them, the
(v) Since


Among them, (v) Update the gradient parameters. The update of the gradient can be adaptively adjusted from the two angles of the gradient mean and the gradient square, and at the same time play a certain annealing effect.

Among them,
Experimental preparation
Data preparation
This paper uses the production data of “Combed compact spinning mechanism fine yarn (100 English counts)” from an Anhui company in China to test the forecasting effect of BMNN. In the data, we select the process parameters that influence the yarn: carding linear speed (m/min) (
Data cleaning
Use the above-mentioned expert experience method to clean up the data. There are a total of
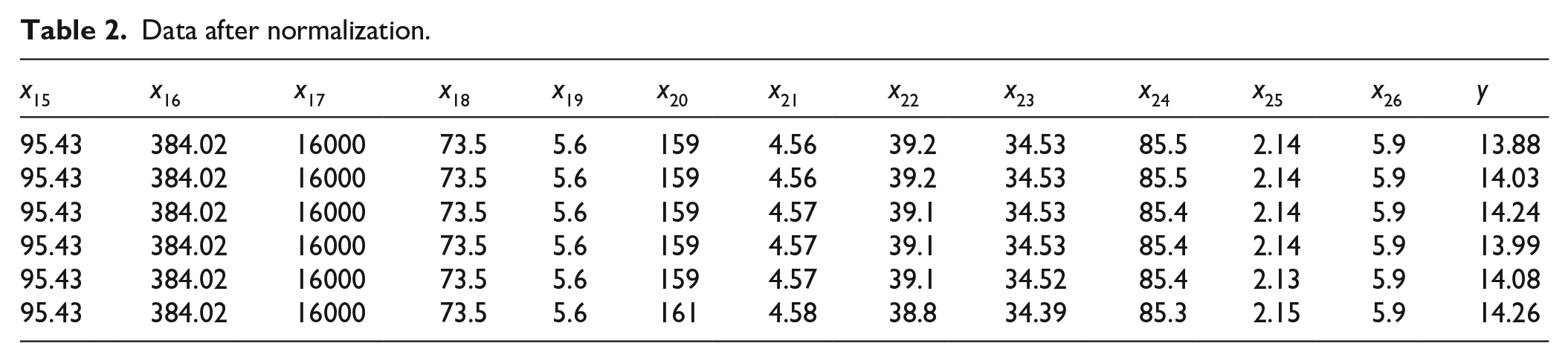
Data after normalization.

Data after normalization.
Feature selection
In the yarn production process, there are
Considering the limited scale of the data in this paper, feature selection based on statistics alone may misjudge some important features, and subjective opinions in feature selection based on expert experience alone may adversely affect the results. Therefore, this paper uses the combination of statistical-based feature selection and expert experience-based feature selection to perform feature selection together. The specific process is shown in Figure 4.
(i) Calculate the Pearson correlation coefficient of the input data, and obtain the Pearson correlation coefficient of the unevenness and each process parameter, as shown in Table 3;
(ii) Determine whether the Pearson correlation coefficient is greater than
(iii) Seven experts give relevant weights, calculate the final weights of each feature parameter by frequency method, and rank the weights;
(iv) Take the top
(v) Combine the features judged by Pearson’s correlation coefficient and the features obtained from expert experience to obtain the result of feature selection, as shown in Table 5.

Feature selection flowchart.
Pearson coefficient of unevenness and various process parameters.

The top 10 features with the highest weights given by expert experience.

Results of feature selection.

Model building
Due to its outstanding advantages, BP neural network has been widely used in data prediction and other issues in the past 10 years. When predicting the problem through modeling, the number of hidden layers in the BP neural network needs to be considered. In recent years, in the small sample prediction model, the four-layer BP neural network has become the mainstream due to its fast running speed and high accuracy.
Considering that the scale of the data in this article is only

BMNN construction flowchart.
Normalization processing
Because the input data units are not uniform, some parameters have a relatively large value range, such as process parameters: the average spindle speed has a value range of
Data after normalization.

Network initialization
BMNN’s network initialization includes three parts: initialization of weight matrix and bias, initialization of the input layer, initialization of the hidden layer and the output layer:
(i) Initialize the weight matrix and bias. Random initialization is a commonly used initialization method in current neural network research. This article uses random initialization to initialize weight matrix and bias;
(ii) Initialize the input layer. The initialization input layer includes: considering the data scale of this article, there are
(iii) Initialize the hidden layer and output layer. Initializing the hidden layer and the output layer includes two parts: initializing nodes and initializing activation functions. Initialize nodes: initialize the number of nodes in the two hidden layers to
Deviation calculation
(i) Calculate the input layer matrix
(ii) Calculate the output matrix
(iii) Calculate the training deviation
Algorithm termination conditions
After the network has calculated the training deviation, it needs to determine whether the algorithm stops or continues iteration according to the algorithm termination condition. The termination condition of the algorithm in this paper is to stop when one of the following two is met:
(i) Reach the maximum number of iterations;
(ii) Algorithm convergence. The training bias of the algorithm for
Update weights and biases
If the algorithm continues to iterate, the weights and offsets in the algorithm are updated according to the parameter update process.
Output model
If the algorithm meets the termination conditions, it exits the loop, outputs the generated model, and the algorithm stops.
Experimental verification
Use the BMNN algorithm to test the seven pieces of data in the test set. To prevent over-fitting and obtain a stable and reliable model, this paper uses cross-validation to select the test set and compare and verify it. In this paper, we choose random seeds from 0 to 9 and compare the predicted value with the real value by using MATLAB. The results obtained are shown in Figure 6 below.
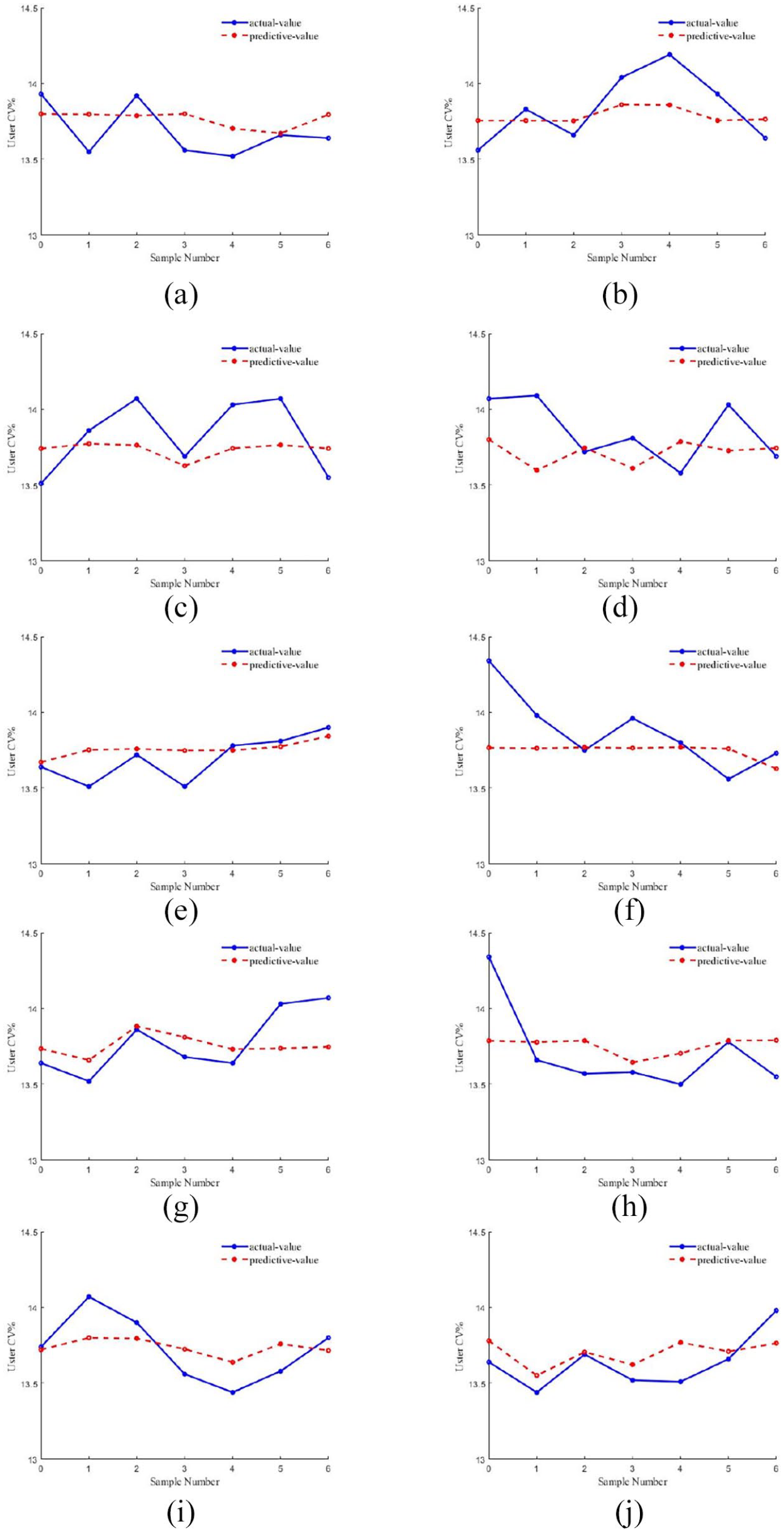
Comparison chart of predicted value and true value: (a) random seed = 0, (b) random seed = 1, (c) random seed = 2, (d) random seed = 3, (e) random seed = 4, (f) random seed = 5, (g) random seed = 6, (h) random seed = 7, (i) random seed = 8, and (j) random seed = 9.
It can be seen from the above Figure 6 that when using BMNN to predict, the prediction accuracy of the model changes with the selection of data. There are some as shown in Figure 6(a) to (e), (g), (i) and (j), the overall accuracy is higher, although there may be some data deviations, it does not affect the main performance of the model; some as shown in Figure 6(f) and (h), there are some data deviations.
To demonstrate the reliability and superiority of BMNN for yarn unevenness prediction, this paper conducts controlled experiments on BMNN using four-layer neural network and BLS.
First, we analyze the complexity and running time of the three algorithms, and the analysis results are shown in the Table 7. Where A denotes the number of iterations of the neural network, T denotes the size of the data, I denotes the number of neurons in the input layer, J denotes the number of neurons in the first hidden layer, G denotes the number of neurons in the second hidden layer, L denotes the number of neurons in the output layer, Q denotes the number of feature nodes, and R denotes the number of enhancement nodes.
The complexity and running time of the three algorithms.

Next, we analyzed the experimental results of the three algorithms. We compared the experimental results of the three algorithms using the method of selecting random seeds 0–9. The specific comparison results are shown in Figure 7 below.
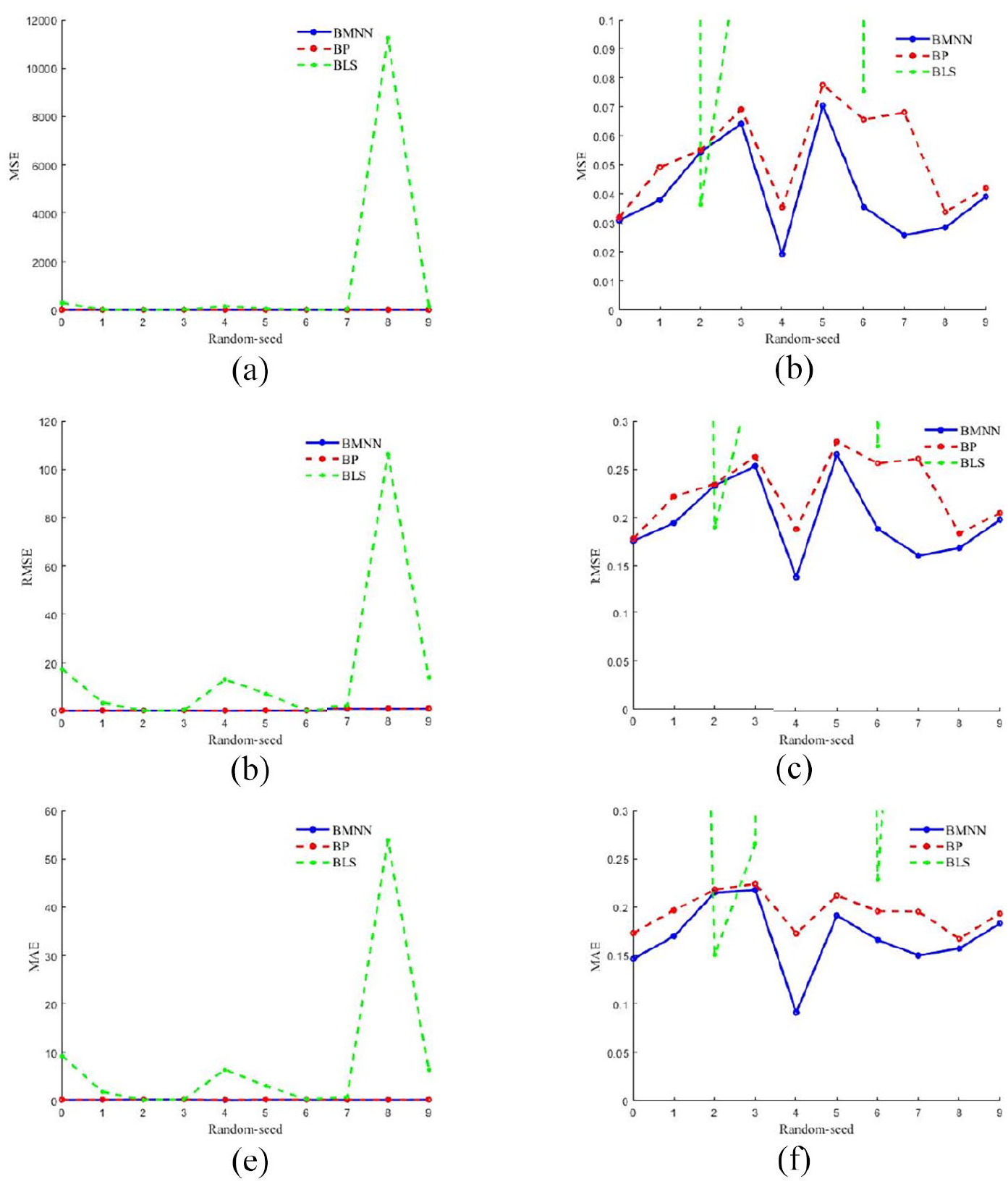
Model evaluation: (a) MSE evaluation index-large, (b) MSE evaluation index-small, (c) RMSE evaluation index-large, (d) RMSE evaluation index-small, (e) MAE evaluation index-large, and (f) MAE evaluation index-small.
Since BLS is too far apart from the evaluation indicators of BMNN and four-layer neural network, each evaluation indicator is represented by two graphs. Taking Figure 7(a) and (b) as examples, Figure 7(a) shows that the overall performance of BLS has a large gap with BMNN and four-layer neural network; when Random-seed = 2 in Figure 7(b), BLS has extremely good performance, which shows that in some accidental situations The BLS algorithm has extremely good performance, but it is not stable. At the same time, the overall effect of BMNN in Figure 7(b) is superior to the performance of the four-layer neural network, which illustrates the reliability and superiority of the BMNN algorithm. Summarizing the images under the three evaluation indicators in Figure 7 shows that the BMNN algorithm has extremely good reliability and superiority. Among them, the formulas of mean absolute error (MAE), mean square error (MSE), and root mean square error (RMSE) are shown in formulas (18)–(20), respectively.

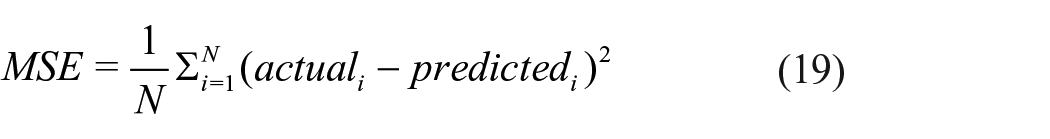

Among them,
Finally, we performed an F-test on the experimental results in order to justify the experimental results, and the results obtained are shown in Table 8.
Results of the F-test.

In order to better summarize the effectiveness of the algorithm, we analyzed the above results. Comparing the complexity of the three algorithms shows that: the complexity of the neural network algorithm is higher because the neural network algorithm requires iteration, and the BLS algorithm does not require iteration. The complexity of the BMNN algorithm is mainly related to the complexity of the neural network. Comparing the running time of the three algorithms, it can be seen that the running time of the BMNN algorithm is approximately equal to that of the four-layer neural network, and the running time of the BLS algorithm is shorter. Comparing the results of the three algorithms, it can be seen that the BLS operating effect is unstable, and it can achieve excellent results in individual cases, and the operating effect is particularly poor in individual cases; the four-layer neural network has stable operating results and can achieve good results; BMNN is a combination of two algorithms, which not only maintains the stability of the algorithm, but also ensures the further improvement of its accuracy.
Next, we correlated and analyzed the operational effects of these three algorithms with the structure of the model. BLS obtains the mapping matrix between feature nodes and enhancement nodes and the output, and then predicts through the mapping matrix. This method is convenient for explaining the rationality of the results. However, in the real data set, even if the same batch of yarn is produced, the quality of the final yarn will be different; at the same time, when the data scale does not meet the requirements, each piece of forecast data may be new data that has not appeared in the database. Therefore, if the prediction data exists in the database and the relevant features are extracted by BLS will produce excellent results; otherwise, it will not work. The four-layer neural network is a black box model. There are a large number of linear and nonlinear crossovers inside. Although the effect obtained cannot be explained, it generally produces a relatively stable effect, that is, the accuracy of the model is not high, but the error is not large too. The BMNN adds a hidden layer training process after extracting the features, and its purpose is to stabilize the final result and make up for the shortcomings of instability when using BLS prediction. The effect of BMNN under the real data set is also consistent with the network structure, not only the accuracy is improved, but the stability is consistent with the four-layer neural network.
Finally, we analyzed the limitations of the method.
(i) Although BMNN is an improvement on BLS and four-layer neural network, it is still a black-box model overall, which cannot explain the relationship between the extracted feature information and the final result;
(ii) In general, the complexity of BMNN is higher compared to BLS as well as neural network;
(iii) BMNN increases the generalizability of the model, but in some special cases, the accuracy is not guaranteed to be better than BLS;
(iv) If the data size is small, BMNN cannot guarantee the accuracy of the model.
In summary, we can conclude that the BMNN algorithm is suitable for parameter prediction under complex process situations with a certain size of data (related to the parameters of the data, if there are more parameters, more data is required).
Conclusion
This paper studies a multi-layer neural network based on the BLS. The model retains the advantages of the traditional BLS (proposes the concept of feature extraction and feature enhancement) and uses a multi-layer neural network to improve the BLS in some practical the effect on the data set. This paper proposes a method of combining expert experience and Pearson coefficients to perform feature selection on factory data after data cleaning. And compares the performance of the four-layer neural network, BLS and BMNN in the prediction of yarn unevenness in the case of small samples. After many different cross-validation comparisons, it is concluded that the prediction effect of BLS in this sample set is unstable, and it has an extremely good prediction effect in some occasional cases, but the effect is poor in most cases; the four-layer neural network has good results under general conditions; and BMNN not only retains the advantages of the stable prediction effect of the four-layer neural network, but also improves the accuracy compared to the four-layer neural network algorithm.
Footnotes
Acknowledgements
Thanks are due to Tingting Fan for assistance with the experiments.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Science and Technology Research Program of Henan Province, China (202102210181).