
Abstract
Fabric defect detection plays an important role in controlling the quality of textile production. In this article, a novel fabric defect detection algorithm is proposed based on a multi-scale convolutional neural network and low-rank decomposition model. First, multi-scale convolutional neural network, which can extract the multi-scale deep feature of the image using multiple nonlinear transformations, is adopted to improve the characterization ability of fabric images with complex textures. The effective feature extraction makes the background lie in a low-rank subspace, and a sparse defect deviates from the low-rank subspace. Then, the low-rank decomposition model is constructed to decompose the feature matrix into the low-rank part (background) and the sparse part (salient defect). Finally, the saliency maps generated by the sparse matrix are segmented based on an improved optimal threshold to locate the fabric defect regions. Experimental results indicate that the feature extracted by the multi-scale convolutional neural network is more suitable for characterizing the fabric texture than the traditional hand-crafted feature extraction methods, such as histogram of oriented gradient, local binary pattern, and Gabor. The adopted low-rank decomposition model can effectively separate the defects from the background. Moreover, the proposed method is superior to state-of-the-art methods in terms of its adaptability and detection efficiency.
Introduction
Fabric defect detection is the key phase of textile quality control. Traditional fabric defect detection is mainly performed through a visual inspection of skilled workers. However, its reliability is restricted by vision fatigue and human errors. An automatic visual textile detection system based on machine learning can provide a promising solution that not only reduces high labor costs but also improves accuracy and efficiency of fabric defect detection. 1
Traditional machine-vision-based fabric defect detection methods can be categorized into two categories,2,3 namely, non-feature extraction methods and feature extraction methods. Among the non-feature extraction methods, Gabor filtering is the most effective method. 4 However, it has strict requirements on filter parameters in order to achieve good performance. Li and Zhang 1 proposed an embedded machine vision system using Gabor filters and pulse-coupled neural network to automatically identify defects of warp-knitted fabrics, which consisted of image enhancement implemented by Gabor filtering with optimal parameters to make the defects more obvious, and image segmentation achieved by a parameter adaptive pulse-coupled neural network layer by layer. Bo et al. 5 proposed an unsupervised learning method of the training model without the image label, which uses k-singular value decomposition (k-SVD) method to learn the sparse dictionary from an image block, and then space pyramid pooling and orthogonal matching pursuit method to build hierarchical characteristics from a dictionary. However, this method would bring higher feature dimension and cannot be used in the visual task of large-scale database. Li et al. 6 proposed an effective fabric detection method based on biological vision modeling (BVM), which simulated the mechanism of biological visual perception and applied a robust feature descriptor from the biological modeling of P ganglion cells to characterize fabric texture, and then low-rank representation adopted to model visual saliency. In addition, image segmentation techniques, according to the image’s color, texture, shape features, and so on, can partition an image into homogeneous regions. 7 An image segmentation method based on Hough transform is used to detect the target contour directly by the global characteristics of image space and parameter space before and after image transformation. Mathematical morphology based on erosion, dilation, opening, and closing provides an effective approach to analyzing digital images. Morphological filters exploit geometric rather than analytic features of signals. 8 The advantages of the morphological over linear filtering are direct geometric interpretations, simplicity, and efficiency in hardware implementation.
Feature extraction methods are often widely used, mainly to extract fabric images’ texture, color, shape, and spatial relationship characteristics. Based on the extracted feature, template matching, 9 neighborhood information, 10 Fourier transformation,11,12 and wavelet decomposition13,14 are adopted to localize the defect region. Due to their diversity, fabric texture and defect are difficult to efficiently characterize using one kind of feature; this reduces the adaptivity of the defect detection methods. 15 Mak et al. 16 detected fabric defects using previously trained Gabor wavelet networks and morphological elements with a linear structural element. However, this method fails to detect the defect in the fabric images with black and white patterns. Tsai et al. 17 proposed a regularity measurement for defect detection in non-textured and homogeneously textured images using principal component analysis (PCA), which is an orthogonal transformation used to transform linearly and non-linearly the correlation of the source variables into a subspace in which the variables are not correlated. It is widely used in feature extraction and data compression, as well as typically utilized for data pre-processing in defect detection. Notably, the features of the scale invariant feature transform (SIFT) method 18 were originally extracted at scale-space extrema and used for feature point matching. The SIFT method is invariant to scale, rotation, and shift. The features of the histogram of oriented gradient (HOG) method 19 and later SIFT method 20 were densely computed by entire image pyramids. They all described the patch of an image in terms of image gradient histogram. On the basis of feature extraction, some methods are operated at the patch level instead of the pixel level, and each pixel is simply assigned the saliency value of its enclosing patch. 21 Furthermore, all image patches are treated as independent data samples for classification or regression even when they are overlapping.
With the advances of artificial intelligence, the feature extraction is gradually integrated by a deep-learning algorithm in the training process. Deep neural networks (DNNs), especially convolutional neural networks (CNNs), can automatically extract and learn in-depth features of an image, which have been proved to be better than hand-crafted features extracted by carefully designed algorithms. CNN’s convolution operation significantly reduces the number of parameters in a trained model and improves the model’s efficiency, thereby avoiding complex feature selection and manual extraction. 22 In addition, CNNs can directly process the original test images and generate the multi-layer feature of complex fabric texture images by multiple nonlinear transformations. Deep learning has achieved very good results in some tasks, mainly boosted by the feature learning performed, which allows the method to extract specific and adaptable visual features depending on the data. Hinton et al. 23 applied an unsupervised representation learning algorithm to help learning internal representations by providing a local training signal at each level of a hierarchy of features. Unsupervised representation learning algorithms can be adopted several times to learn different layers of a deep model. Several unsupervised representation learning algorithms retain many properties of artificial multi-layer neural networks, relying on the back-propagation algorithm to estimate stochastic gradients. Abid 24 adopted a polynomial interpolation and multilayer perceptron method to train a neural network to detect and locate regions of defects. Ren et al. 25 presented a generic deep-learning method that used a pre-trained network and transferred features to build classifier, and then convolved the trained classifier over input image to make pixel-wise prediction. Li and Yu 26 trained a DNN for deriving a saliency map from multi-scale features extracted using deep CNNs. Wang et al. 27 adopted a DNN to learn local patch features for each centered pixel. Weimer et al. 28 proposed a novel deep CNN architecture to detect defects, which took all types of defect-free and defective samples together as the input. Li et al. 29 proposed a discriminative representation for patterned fabric defect detection using Fisher criterion-based stacked denoising auto-encoders (FCSDA). Fabric images were divided into patches of the same size. Then, these fabric patches with defect-free and defective classes were used to train FCSDA. Finally, test patches were classified using FCSDA in defective and defect-free classes. Experimental results indicated that the FCSDA method could obtain the superior results on a complex Jacquard warp-knitted fabric.
Low-rank decomposition (LRD) techniques 30 can divide an image matrix into two parts: low-rank matrix and sparse matrix, where the low-rank matrix indicates a smooth background and the sparse matrix indicates the salient regions. It has been successfully used in a variety of applications, such as subspace segmentation, 31 visual tracking,32,33 image clustering, 34 and video background–foreground separation.35,36 Shen and Wu 37 provided a unified framework for integrating high-level knowledge and low-level features, which is based on the assumption that an image could be represented as the sum of the background being low rank and the salient regions being sparse. Peng et al. 38 introduced a tree-structured sparsity-inducing norm regularization to provide a hierarchical characterization for saliency detection through low-rank and structured sparse matrix decomposition. Yang et al. 39 proposed a saliency detection method of constructing an affinity matrix and scoring each node with its similarity to background and foreground cues through graph-based manifold ranking. Wang and Huang 40 proposed a salient object detection method using low-rank approximation and l2,1-norm minimization, which is based on an underlying assumption that an image is a combination of background regions being low rank and salient objects being sparse. The normal fabric images with complex textures have large visual redundancy, and the defects are outstanding from the background. The efficiently deep feature can make the background lie in a low-rank subspace, the defect region deviate from the background. Therefore, a novel fabric defect detection algorithm is proposed based on deep feature and LRD. Deep learning is used to extract a CNN feature, and the LRD model is used to separate the background and the defect region.
Normal fabric images with a complex texture have large visual redundancy, and the defects are more salient in the complex texture background. Considering these characteristics, applying the model of LRD to fabric defect detection is considerably suitable. Therefore, we propose an effective defect detection method based on multi-scale convolutional neural network (MCNN) and LRD techniques. MCNN was adopted to extract the fabric feature, and LRD was utilized to separate the defect information from the background.
This article is structured as follows. Section “Proposed algorithm” focuses on the specific procedures of the proposed algorithm. In section “Experimental results and analysis,” we comprehensively present experimental protocol and obtained results, as well as analysis. Finally, section “Conclusion” concludes the article and points promising directions for future work.
Proposed algorithm
Although fabric images have numerous kinds of defects and a complex texture, the defects are more salient in the complex texture background. Therefore, it is of great value to study the defect detection by combining a deep-learning method and LRD technology. The existing deep-learning method typically uses the features of the last convolution layer to carry out the target detection, which causes the loss of detailed texture information. Fabric image texture is relatively abundant, and the low-texture features for defect detection and recognition are crucial; so, a novel fabric defect detection algorithm is proposed based on MCNN and LRD, and its overall structure is illustrated in Figure 1. The multi-layer features are extracted and integrated by MCNN, preserving the semantic information of the high-level characteristics and the detailed texture information of the low-level features. LRD technique was then adopted to divide the generated feature matrix into the low-rank matrix that indicates the background and the sparse matrix that indicates the salient defect. In the end, the iterative optimal threshold segmentation algorithm was utilized to segment the saliency maps generated by the sparse matrix to locate the fabric defect area.

Overall structure of the proposed algorithm.
Unsupervised pre-training
When the labeled data are insufficient, an auxiliary supervisory training can be adopted, and fine-tuning the particular area can also improve its effectiveness. The current study adopts the sparse auto-encoder (SAE) to pre-train the filters of CNN, and its purpose is in line with the statistical characteristics of datasets and achieving a better initial value of filter sets. For each extracted patch, dictionary was generated by SAE, which can describe their characteristics. And then, sparse matrix was obtained through the linear combination. In the network, the overall cost function is defined as

where the first term is the traditional basic neural network, as shown in formula (2); the second is the sparse penalty factor, as shown in formula (3); and β is the weight parameter balancing the sparse penalty factor and J(W, b) as well as s2, which is the number of neurons in the hidden layer

where the first term is a mean-square-error term; hw,b denotes an activation function, which is actually a nonlinear transformation function with parameters w and b; and the second term represents a weight attenuation term to prevent overfitting, and the weight attenuation parameter θ is adopted to balance the above-mentioned two terms. Relative entropy is generally employed to measure the disparity between two probability distributions. The definition of relative entropy between two mean Bernoulli random variables of mean ρ and mean
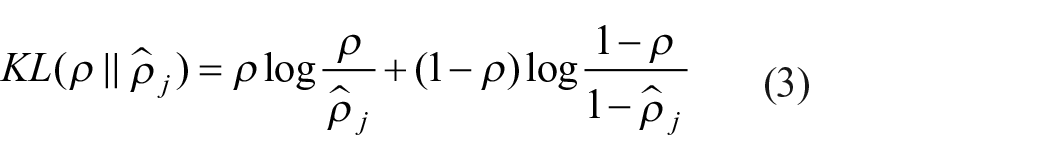
where ρ denotes the sparse parameter and is typically a smaller value close to 0 and
After the overall cost function is obtained, the parameters are updated according to the following formulas


where α is the learning rate. The latter two derivatives of formulas (4) and (5) are calculated by the back-propagation algorithm. The updating of the whole coding network is completed until the parameters are converged and the characteristic parameters W and b are obtained. It is known that m is the number of hidden layer nodes of layer l, and W(l) is then decomposed into a parameter set of the number m. Each parameter set is a filter, which leads to a pre-trained filter set.
MCNN feature extraction and training
Considering that the fabric image has complex texture and diversities, MCNN model can learn a hierarchy of features from the raw image input by automatically updating the filters during training on massive amounts of training data. So, the MCNN is adopted to extract a deep feature of fabric images. The architecture of the proposed MCNN is presented in Figure 2.

Multi-scale CNN and traditional CNN.
A typical MCNN architecture consists of several nested convolutional layers and pooling layers followed by fully connected layers at the end. In the convolutional layer, the feature maps of the previous layer are convolved with the learned convolution kernels, and an activation function then acts on that value to form the output feature maps. For each block of fabric images, its output size after convolution can be expressed as


where l denotes the image layer,

where

where s×s is the scale of the down-sampling template and
The fully connected layers are the last part of the neural networks. All of the neurons in the fully connected layers are connected to all of the units of the last layer. Therefore, the final output of the CNN fully connected layer can be expressed as

After combining all convolutional layers and pooling layers, the pre-training of SAE and MCNN’s supervisory training can achieve the optimal weight along with improved training speed. We present the parameter optimization for MCNN in Algorithm 1.

Given an input image or a patch, it is input to each channel of the MCNN for training. After training, the corresponding features are also represented by the feature vector, successively. The use of two-layer full connection reduces the characteristic dimension of training. Although the feature dimension is lower, the more texture information of fabric images is retained for further detection and identification.
LRD model and optimal solution
Given a test fabric image, it can be divided into image blocks {Bi}
i
= 1, . . ., N with different sizes, where N is the number of image blocks. The characteristic representation

where rank(

where
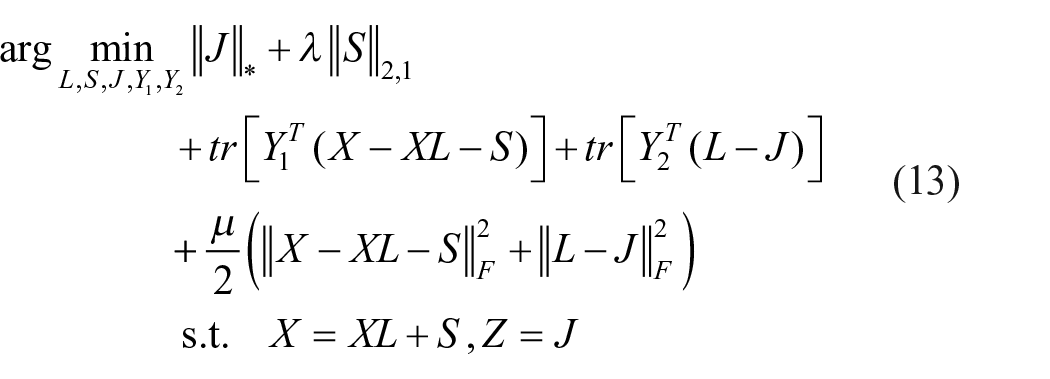
where Y1 and Y2 are Lagrange multipliers and

Generation and segmentation of the saliency map
The generated feature matrix

If

where g is a circular smoothing filter, “∘” is the Hadamard inner product operator, and “*” represents the convolution operation. The saliency map

Finally, the iterative optimal threshold segmentation algorithm 41 is adopted to segment the saliency map generated by the sparse matrix. Thus, the defective region is located.
Experimental results and analysis
In the current study, numerous simulation experiments were conducted on the fabric images to evaluate the performance of the proposed algorithm. We selected several kinds of fabric defect images from two fabric image databases (including broken end, netting multiple, hole, thick bar, thin bar, dot-patterned, and star-patterned, etc.). The first is the fabric database of the University of Hong Kong, and the second is the TILDA fabric image database of the University of Freiburg. All of the algorithms were coded and executed in MATLAB R2016a, and all of the experiments were implemented on a 3.30 GHz, Intel (R) Core (TM) i3-2120 CPU PC.
To reduce the computation cost of the proposed algorithm, a whole fabric image was first down-sampled to 256 × 256 pixels and then fed into the network as the input in the experiments. The training was carried out, and features were extracted for the image block by MCNN. The multi-layer feature was fused to realize the representation of the fabric image, and the feature matrix was then composed. The low-rank matrix and the sparse matrix were decomposed by the ALM. Finally, the iterative optimal threshold segmentation algorithm was used to segment the saliency map generated by the sparse matrix. Thus, the defective area of the fabric is located.
To demonstrate the effectiveness of the adopted feature extraction method, we first compare the other four feature extraction methods with our adopted MCNN method: (1) Shen and Wu 37 used intensity, texture, and orientation features plus low-rank matrix recovery (LRR) to detect an object; (2) Li et al. 19 adopted an HOG feature and an LRD algorithm to detect fabric defects; (3) Li et al. 6 applied the hierarchical information processing of the biological visual system and established BVM to characterize all types of fabric textures, which can quickly locate the salient object; and (4) Zhang et al. 42 proposed a Gabor feature and LRD to detect defects. Figures 3 and 4 indicate the detection results of these different feature extraction methods in a plain-texture fabric and patterned fabric defect detection. Figure 3 demonstrates the detection result of the plain-texture fabric, and Figure 4 illustrates the detection result of a patterned fabric. Figures 3(a) and 4(a) are the original fabric images; (b) to (f) are some saliency maps generated by Shen and Wu, 37 HOG + LRD, 19 BVM + LRD, 6 Gabor + LRD, 42 and our method, respectively; (g) shows our segmentation maps. It can be clearly seen from the experimental results that the five feature extraction algorithms have good detection performance for plain and twill fabric, except that the defect area of the third column and the fourth column are not continuous. For the fabric defect images with a plain weave, the fabric defect area in Shen and Wu 37 and Zhang et al. 42 can be highlighted in the visual effect. For the patterned fabric, the background texture is very complex, and the effect of saliency maps generated by the method of Shen and Wu 37 and Zhang et al. 42 is not ideal. However, the detection performance of our method is significantly enhanced. The reason is that MCNN can be more effective in extracting the texture information of fabric images compared with other feature extraction algorithms, and the LRD model was integrated into the proposed algorithm. The fabric defects were accurately segmented, and the defect area was more prominent and was located effectively.


Figures 3 and 4 show the saliency maps generated by different feature extraction methods in plain-texture fabric and patterned fabric defect detection. The first column indicates the original images; the second column indicates the saliency maps generated by Shen and Wu 37 ; the third column indicates the saliency maps generated by the HOG feature with the LRD model; the fourth column is the saliency maps generated by the BVM with the LRD; the fifth column is the saliency maps generated by the Gabor feature with the LRD model; and the last two columns indicate the saliency maps and segmentation maps generated by our algorithm, respectively.
In the MCNN network, we added batch normalization 43 before each activation layer. The batch normalization stores the running average of the mean and standard deviation from its inputs. The stored mean is subtracted from each input of the layer, and division by the standard deviation is also performed. It has been demonstrated that by applying batch normalization, overfitting is decreased, and higher learning rates for training are achieved. In addition, we applied the padding strategy that pads zeros around the borders of the feature maps after each convolution leading to unchanged output shape in each channel. In addition, the pooling strategy adopted in all of the pooling layers is max-pooling, which is robust to small distortions. The output of the max-pooling creates a new set of image channels that are then fed through another layer of convolutions and nonlinearities. Finally, the last fully connected layer generates the output vectors, which are then stacked to a feature matrix. The parameters of the network, such as weights of the convolutional filters, are optimized through back propagation.
The selection of a stride and convolutional kernel size are critical for training network parameters and improving MCNNs’ performance. A larger value of the stride parameter reduces accuracy, although the training speed is improved. If the convolutional kernel is small, the local feature of the image cannot be extracted effectively. Conversely, if the convolutional kernel is too large, the calculation complexity will be far higher. The current study adopted multi-scale input images to increase local invariant information and collocation of different sampling intervals with different sizes of the convolutional kernel to obtain feature invariance, thus ensuring that the detailed information of the fabric image texture is not lost. We selected the cross-entropy function as the loss function of our proposed algorithm, and during the MCNN training process, the stochastic gradient descent (SGD) with mini-batches of 50 samples was applied to update the weight parameters. We also incorporated the momentum and learning rate decay into the SGD optimizer, and the updating rules of the weights in each iteration are as follows



where i is the iteration index, w is the weight hyperparameter, μ is the momentum coefficient, v is the current velocity vector, a is the learning rate, d is the decay parameter of the learning rate, and ∇g is the average value of gradients with respect to w over the mini-batch at each iteration. In our experiments, the momentum parameter and the weight attenuation coefficient were set to 0.9 and 10−5, respectively. The learning rate was initialized to 0.1 and then reduced by half the increase of the number of iterations. Apart from that, the dropout strategy with a probability of 0.5 was applied to the last fully connected layers that also help to avoid overfitting. In addition, we initialized the bias value to 0 for every layer and chose the ReLU activation function according to the work of He et al. 44
An important parameter in neural network training is the iteration number. If it is too small, the network prediction error increased. Furthermore, the input defect images cannot be fully learned, resulting in low detection accuracy of the final multi-layer deep-learning algorithm; on the contrary, the long calculation time and the accuracy rate gradually increase with a higher number of iterations. Figure 5 illustrates the relationship between the number of iterations and both the loss function and the accuracy rate.

Relationship between the iteration number and both the loss and the accuracy rates.
As can be seen in Figure 5, the accuracy rate is improved as the increase of iteration number and stability are achieved. In the experiments, the number of iterations was set to 3600 for a compromise of iteration times and accuracy. When training from scratch, the performance did not seem to improve beyond 3600 iterations, thus paused the back propagation there. Although the performance was much lower than for the fine-tuned networks, the network learned to predict the fabric defect.
However, the accuracy rate was not a good measure for imbalanced datasets as performance on the defect detection. Therefore, in the current study, we adopted means and standard deviations of average precisions, recalls, F-measure, and mean absolute error (MAE). 45 The precision (also known as the positive predictive value or false positive rate, defined as TP/(TP + FP)) is the ratio of the correct significant region and the total detection area, which reflects the testing accuracy and measures the refused ability of the false detection rate in the test system error and test method. The recall (also known as sensitivity or true positive rate, defined as TP/(TP + FN)) is the probability of the correct significant area out of the total significant areas, which reflects the comprehensiveness of detection. Here, TP is the number of true positives, FP the number of true negatives, and FN the number of false negatives. The higher the precision and recall values, the better the detection effect, but there is a certain contradiction between the two. For example, when the detection area is very large, it can be used to ensure that the recall ratio is high, but the accuracy rate is not enough. To keep the balance between the two, it is necessary to adopt the F-measure value to synthesize the evaluation criteria of the two indexes. It is defined as

where

Comparison of our results with four feature extraction methods.
In Figure 6, the detection performance of our proposed algorithm is better than other existing methods, and the multi-layer features of MCNN for fabric defect description are more remarkable than some hand-crafted features.
Conclusion
Fabric defect defection is a key component of quality control in the textile industry. In the current study, we propose a novel fabric defect detection algorithm based on MCNNs and LRD. The proposed algorithm has two contributions: (1) the traditional methods of extracting features are replaced by MCNN to characterize a fabric defect image’s texture and (2) LRD is adopted to decompose the feature matrices in the low-rank and sparse parts. The detection results are obtained by segmenting the saliency map generated by the sparse part. The experimental results demonstrate that the proposed method can accurately detect the defect regions in various fabric defect images, even for images with complex textures, and it is superior to the state of the art.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant Nos 61772576 and 61379113), the Key Natural Science Foundation of Henan Province (Grant No. 162300410338), Science and Technology Innovation Talent Project of the Education Department of Henan Province (Grant No. 17HASTIT019), Intelligent Image Analysis Processing and Machine Vision Innovation Team in Henan Province (Grant No. 2018091), and the Henan Science Fund for Distinguished Young Scholars (Grant No. 184100510002).