
Abstract
In this article, an intelligent pilling prediction model using back-propagation neural network model and an optimized model with genetic algorithm is introduced. Genetic algorithm is proposed in consideration of the initial weight and threshold of back-propagation artificial neural network, and further improves training speed and the accuracy for prediction pilling of polyester–cotton blended woven fabrics. The results show that the maximum numbers of training steps of the optimized model by genetic algorithm are reduced from 164 steps to 137 steps compared with that of back-propagation model. The training fitness of optimized model by genetic algorithm is improved from 0.914 to 0.945. The simulation fitness is increased from 0.912 to 0.987. And the root mean square error decreased from 1.0431 to 0.6842. The optimized model by genetic algorithm shows a better agreement between the experimental and predicted values.
Keywords
Introduction
The pilling of fabrics is a classic problem for the apparel industries, especially for polyester blended fabrics. 1 Polyester–cotton blended woven fabrics which have crisp, wrinkle resistance, dimensional stability and moisture absorption properties have been developed and are more and more popular among people. However, polyester–cotton woven fabrics also have some disadvantages, such as easy pilling, which affect the appearance and handle of fabrics. It is realized that the problem of pilling is one of the biggest quality issues for polyester–cotton blended fabrics. But the problem remains.
Many factors have been identified to affect fabric pilling, which include fiber properties (type, 2 modulus, 3 friction coefficient 4 ), yarn properties (spinning method, 5 twist, 6 yarn count 7 ) and fabric properties (structure, 8 cover factor 9 ), whose synergism determines the pilling propensity. Many researchers have investigated the influence of numerous factors contributing to the pilling of fabrics. Beltran et al. 10 found that the larger the fabric cover factor is, the smaller the pilling tendency of the fabric is. The larger the yarn count is, the easier the fabric is prone to pilling. The effect of fabric thickness on pilling is first increased and then decreased. Li and Zhou 11 found that yarn twist has a great influence on the pilling performance of wool knit fabrics. Lohrasbi et al. 12 found that the warp and weft density of fabrics has a great influence on the pilling performance of wool fabrics. Kayseri et al. 13 used nonlinear regression analysis to study the effects of yarn twist, twist ratio, fabric density on pilling performance of fabrics and found that the effect of these factors was particularly significant. It can be seen from many studies that the factors such as fabric twist, twist ratio, warp and weft density, and fabric cover factor have important effects on pilling performance of fabrics. However, they did not consider the complex interactions of the numerous factors, and their synergistic effects on the pilling propensity cannot be fully understood.
The advent of artificial neural networks (ANNs) provides the opportunity to model the interactions among the numerous factors to predict the pilling propensity of fabrics. Back-propagation (BP) ANN which has the advantages of high nonlinearity, self-learning, and mapping is a very important and classical ANN. 14 It does not need to seek explicit relations and mathematical models between nonlinear sample data and can accurately approximate the best function of characterizing the training sample data to overcome many limitations and difficulties of the traditional methods. Furferi et al. 15 said that BP neural networks have been widely used in textile field since last decades, such as predicting drapability property, 16 air permeability, 17 wrinkle recovery, 18 dimensional stability, 19 thermal resistance, 20 UV (ultraviolet) protection, 21 and so on. There are also many studies on the application of BP model to the pilling propensity of wool fabrics 10 and cotton fabrics. 6 However, there is so far no research on predicting the pilling performance of polyester–cotton blended fabrics by using BP model. In practical applications, BP model has disadvantages, which include slow convergence rate and local minimum value. 22 Using genetic algorithm (GA) to optimize the initial weight and threshold of BP model can improve the training speed of neural network and overcome local minimum. Zhang et al. 23 used GA to detect and classify color-textured fabrics defects, and found that it was more feasible and applicable.
The aim of this study was to use BP model and optimized model with GA for predicting the pilling properties of polyester–cotton fabrics. Six parameters of fabrics were used as input variables. BP model and optimized model with GA were used to correlate six parameters with the number of pills. In order to validate the two models, the predicted values were then compared with the experimental values.
Materials and methods
Experimental materials
Selecting the appropriate input and output variables is the key to predict the pilling propensity of fabrics. There are many factors affecting the pilling performance of polyester–cotton fabrics. If each of the influencing factors is used as the input variable of the model, the model will become complicated, and the increase of variables will also increase the difficulty of sample data collection. Accurately selecting the factors associated with pilling as input variables will directly affect the accuracy of the predictive model. From previous work, yarn twist, twist ratio, warp density, weft density, fabric tightness, and fabric thickness are the most effective factors. Therefore, these six factors are used as the input variables of the model, and the number of pills on the surface of fabrics after pilling test is taken as the output variable.
Samples
The polyester–cotton blended fabrics where the content ratios of polyester fibers and cotton fibers are 65% and 35% (T65/C35) are widely used and representative. So this blended ratio is used in the experiment. The diameters of polyester fibers and cotton fibers are 16.5 and 23.4 µm, respectively. The lengths of polyester fibers and cotton fibers are 3.35 and 2.76 cm, respectively. A total of 30 fabric samples are selected randomly from a total of 100 samples that have been chosen for the entire experiment. And these samples come from the company. The sample specifications and fabric structure parameters are shown below in Table 1.
Fabric structural parameters and the number of pills.

Measuring pilling properties of fabrics
According to Martindale method of ISO 12945-2:2000, the polyester–cotton fabrics pilling test was conducted by YG (B) 401E Martindale wear-resistant instrument which was produced by Dalong Textile Instrument Co., Ltd. The degree of pilling was characterized by the number of pills on the surface of the polyester–cotton woven fabrics after 5000 pilling rubs. The specific results are shown in Table 1.
In order to avoid network paralysis caused by excessive raw data before prediction by using BP algorithm, the original data should be normalized. The original data in Table 1 should be standardized between [–1, 1], so that the data can be smoothed as much as possible to eliminate the prediction result. The standardized data can be used as the training sample of the model.
Analytical methods
The construction of BP model
BP model belongs to multilayer forward neural network. Increasing the number of network layers can make the result more accurate and reduce the error, but it will make the calculation too large and the training process is difficult to fit. Therefore, the classical three-layer structure BP neural network is adopted, which consists of input, hidden, and output layers.
There are training and testing parts in BP model. The 1–25 sets of data in Table 1 are used for training of the model, and 26–30 sets of data are considered as testing of the model. Six physical factors shown in Table 1 are regarded as the training input vector. And the number of pills is considered as the learning target data. Therefore, the number of input nodes of training is 6, the number of nodes of the output layer is 1, and the number of nodes of the hidden layer is calculated according to equation (1)

where N represents the number of hidden layer nodes, m represents the number of input nodes, n represents the number of output nodes, and a represents a constant between [1, 10]. The best hidden layer nodes are selected from the value range. The same samples with different node numbers should be trained to make the errors minimized. The error is evaluated by using mean absolute percent error (MAPE), root mean square error (RMSE), and mean absolute error (MAE). The specific calculations are as shown in equations (2)–(4)

where abs represents the absolute value, A(i) represents the model output value, B(i) represents the experimental value, and k represents the number of samples

where k represents the number of samples, A(i) represents the output layer prediction value, and B(i) represents the experimental value
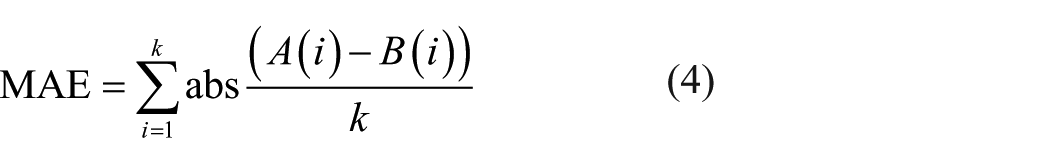
where abs represents the absolute value, A(i) represents the output layer prediction value, B(i) represents the experimental value, and k represents the number of samples.
The construction of optimized model with GA
GA is an adaptive search procedure derived from the theories of natural population evolution. BP model optimized by GA is to use GA to optimize the initial weight and threshold of BP neural network, which can more accurately predict the output results.
Population initialization
The individual coding method is real number coding. Each individual is a real number string, which is composed of the connection weight of the input layer and the hidden layer, the threshold of the hidden layer, the connection weight of the hidden layer and the output layer, and the threshold of the output layer. The individual contains all the weights and thresholds of the neural network. When the network structure is known, it can form a neural network with a determinate structure, weight, and threshold.
Fitness function
According to the initial weight and threshold of BP model, the training data are used to train BP neural network and to predict the output of the system. The absolute value of errors between the predicted output and the expected output is taken as the individual fitness value. The equation is as follows

where n is the output node of network, yi is the expected output of node i of BP neural network, oi is the predicted output of node i, and k is the coefficient.
Selecting
The GA selection has many methods such as roulette method and tournament method. The roulette method is adopted in this study, which is the selection strategy based on the fitness ratio. The selection probability pi of each individual i is shown in equations (6) and (7)


Crossover
Since real number coding is used for individual, the real number intersection method is adopted for crossover. The crossover method of chromosome ak and chromosome al in the j position is shown in equations (8) and (9)


where b is a random number between [0, 1].
Mutation
The gene aij of individual i is selected for mutation. The mutation method is shown in equations (10) and (11)


where amax is the upper bound of the gene aij, amin is the lower bound of the gene aij, r2 is a random number, g is the current number of iterations, Gmax is the maximum number of evolution, r is a random number between [0,1].
Results and discussion
Analysis of BP model
Determination of the number of hidden layer nodes
In this study, the Neural Network Toolbox of MATLAB (R2016a) mathematical software was adopted. A three-layer BP neural network is selected, which includes an input layer, a hidden layer, and an output layer. According to equation (1), the value range of the hidden layer node in this study is [4, 13].
As a result, the errors with different number of hidden layer nodes are shown in Table 2. It is seen from Table 2 that the best number of hidden layer nodes is 9 when the error is determined to be the smallest. This is mainly because if the number of hidden layer nodes is too small, it is not enough to reflect the law of data. The error value will fluctuate. Just like for nodes 7 and 8, the error values rise. However, if the number of nodes is too large, the network learning time will increase. And an over-fitting phenomenon may occur, which may also cause a large error. Therefore, the selection of the number of hidden layer nodes should be moderate.
Errors of different hidden layer nodes.

MAPE: mean absolute percent error; RMSE: root mean square error; MAE: mean absolute error.
Determination of input and output layer transfer function
The transfer functions of the input and output layers are chosen to make the predictions accurate. It denoted that MAPE, RMSE, and MAE must be minimized.
In the case where the network structure and the weights and thresholds are the same, the relationships between MAPE, RMSE, and MAE and the transfer function of the hidden layer and the output layer are shown in Table 3.
Errors of different transfer functions.

MAPE: mean absolute percent error; RMSE: root mean square error; MAE: mean absolute error.
It can be seen from Table 3 that the selection of transfer function of hidden and output layer has a great influence on the prediction accuracy of BP model. The transfer functions of the hidden layer and the output layer, in which errors are the smallest, are logisig and logsig, respectively: the logsig transfer function is an S type of logarithmic function, which is consistent with the law of pilling, and the tansig transfer function is an S type of tangent function. However, purelin transfer function is a linear function, which does not conform to the law of pilling.
Determination of training parameters
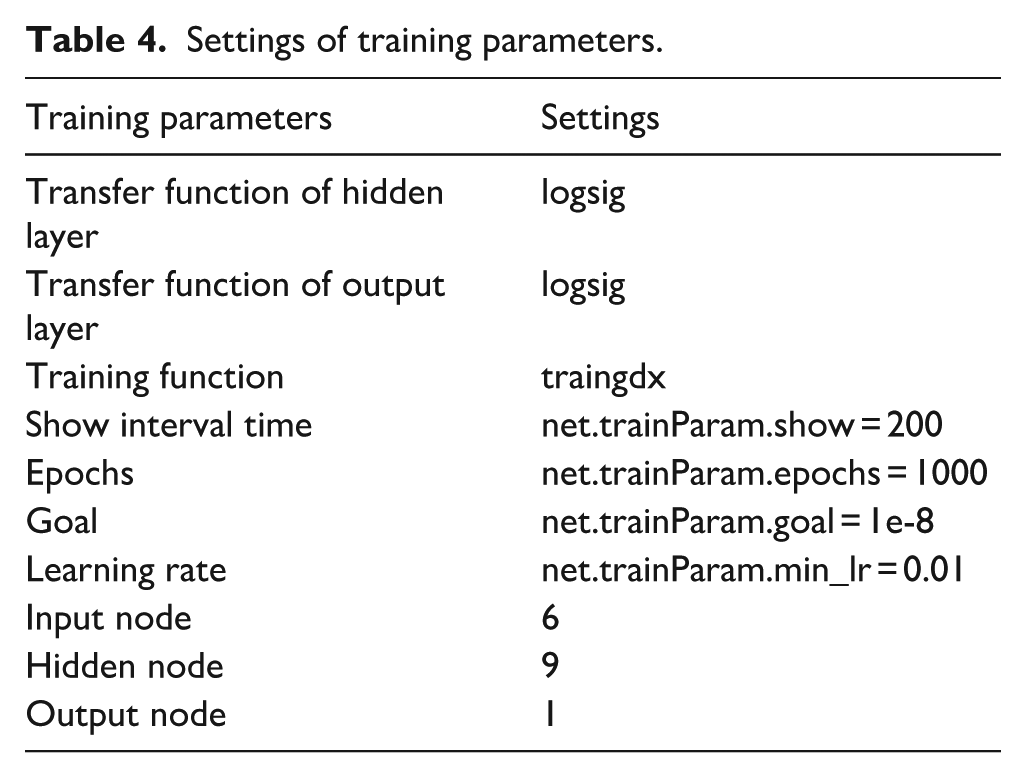
According to the above-selected parameters, the settings of the relevant training parameters are shown in Table 4.
Settings of training parameters.
According to the above training parameters, the BP network is trained. The performance function that comes with the neural network toolbox is the mean square error function. So the Y-axis of the error curve of the training is mean squared error, which is shown in Figure 1. As can be seen from Figure 1, the training step of BP neural network is 164. It means the network reaches the target value at this step.

The training error curve of BP neural network.
Analysis of optimized model with GA
A global search of the weights and thresholds of neural network is performed by using GA to determine its optimal solution. The local optimal solution is searched by using BP neural network. Then, the neural network is trained. The specific algorithm flowchart is shown in Figure 2.

Flowchart of optimized model with GA.
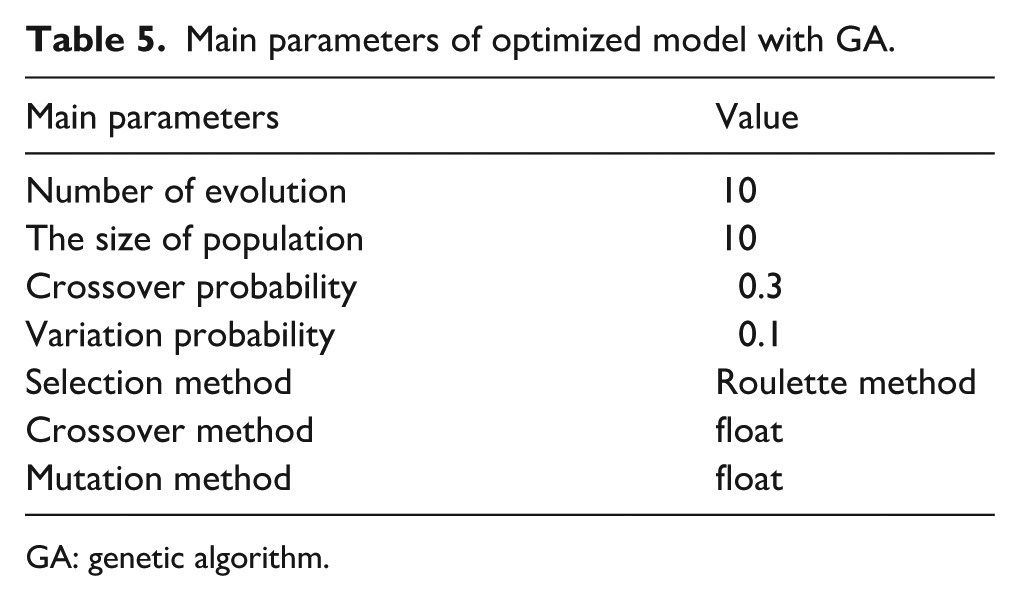
According to the above-mentioned population initialization and genetic methods, the main parameters of optimized model with GA are shown in Table 5.
Main parameters of optimized model with GA.
GA: genetic algorithm.
According to the training parameters of the above-optimized model, the network is trained. The performance function that comes with the neural network toolbox is the mean square error function. So the Y-axis of the error curve of the training is mean squared error, which is shown in Figure 3. It can be seen from Figure 3 that the training step of optimized model is 137. The comparison between Figures 1 and 3 demonstrates that the optimized model can reach the convergence more quickly than the BP model during the training process. This is because GA can overcome the local minimum of BP model.

The training error curve of optimized model with GA.
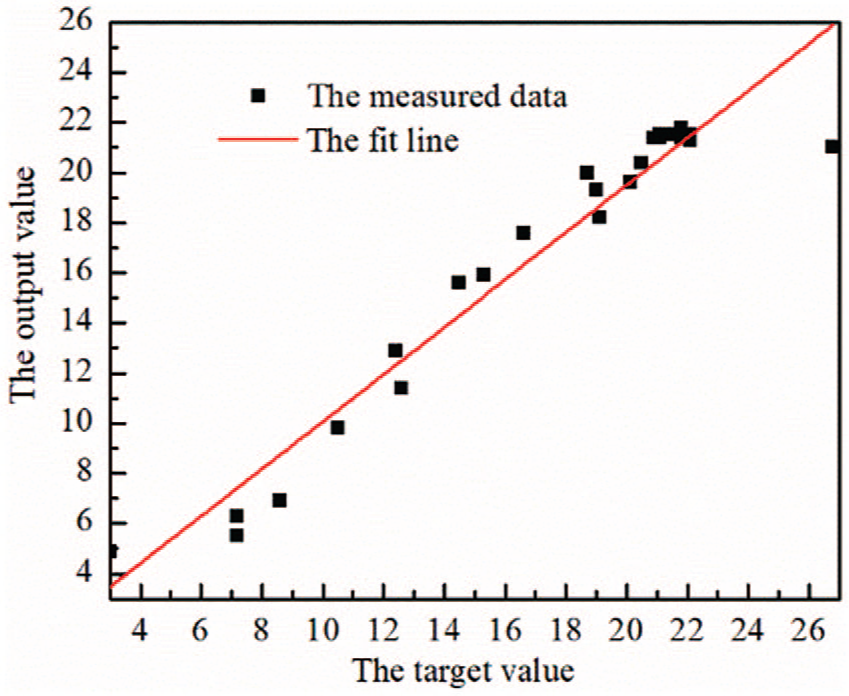
When neural work is used for prediction, the closeness between the real measured value and the predicted value of the neural network is generally characterized by the degree of fitness. The BP model and the optimized model with GA are trained by using the same data. The results of the two networks are shown in Figures 4 and 5. It can be seen from Figure 4 that the fitness of BP model is 0.914. It can be seen from Figure 5 that the fitness of optimized model with GA is 0.945. The above analysis shows that the optimized model is more consistent with the predicted value and actual value of pills of polyester–cotton blended woven fabrics.

Correlation analysis on training results of BP model.
Correlation analysis on training results of optimized model with GA.
The simulation results of the two models are analyzed. Figure 6 is the compared results between the measured values and the predicted values of the number of pills. It can be seen from Figure 6 that the predicted values of two models are basically consistent with the measured values. Moreover, the predicted value of the optimized model with GA is closer to the experimental value.

Comparison between the predicted and experimental values.
The correlation analysis of the simulation results of the two models are shown in Figures 7 and 8. It can be seen from Figure 7 that the fitness of BP model is 0.912. It can be seen from Figure 8 that the fitness of the optimized model with GA is 0.987. The analysis results indicate that the optimized model with GA is more effective in predicting the pilling property of polyester–cotton blended woven fabrics.

Correlation analysis on simulation results of BP model.

Correlation analysis on simulation results of optimized model with GA.
In order to verify the superiority of optimized model with GA, the prediction accuracy of the two models is compared by using three characteristic indexes, which include MAPE, RMSE, and MAE. The results of statistical indicators are shown in Table 6. It can be seen from Table 4 that the prediction error of optimized model with GA is the smallest, that is, the prediction accuracy is the highest. So the predicted effect is better than BP model.
Comparative analysis of prediction accuracy.

GA: genetic algorithm; BP: back propagation; MAPE: mean absolute percent error; RMSE: root mean square error; MAE: mean absolute error.
Conclusion
In this work, the pilling propensity of polyester–cotton woven fabrics was investigated. The BP model and the optimized model with GA were used to correlate the pilling property with the six parameters. To validate the two models in the training steps, training precision, and simulation precision, 30 samples were tested, and the predicted pilling property was obtained. The predicted values were then compared with the experimental values. The results show that the predicted values are very close to the experimental values, and the values predicted by optimized model with GA are closer than the values predicted by BP model to the experimental values. This shows that optimized model with GA can predict the pilling propensity of polyester–cotton woven fabrics with acceptable accuracy.
Footnotes
Acknowledgements
The authors would like to express thanks to Binzhou Huafang Engineering Technology Research Institute for supplying the samples.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.