
Abstract
Fifteen commentaries have either responded to, or been inspired by, our article about the automation failure construct, which introduced a taxonomy of failure mechanisms for consideration in the design of cognitive engineering experiments. Our rejoinder organizes these responses into those aligned with the objectives of the target article, those inspired by it, a couple that rehash our earlier articles, and one that seeks to put us all in our place. We conclude with an assessment of points of consensus and divergence in our shared apprehension of the automation failure construct.
Objectives: Intended and inspired
Skraaning and Jamieson (2024) sought to advance a dialogue about the operationalization of the automation failure construct for experimental research in human-automation interaction (HAI). Our approach began with close inspection of several commercial aviation accidents to highlight the intricacy of automation failure in safety-critical work settings. We then developed a taxonomy(at the encouragement of the Reviewers and Associate Editor) as an initial attempt to identify and group automation failure mechanisms. Our hope was that this initial organization of mechanisms would (i) prompt others to expand and reframe the automation failure construct and (ii) motivate the development and use of industrially representative failure mechanisms in cognitive engineering experiments. The Editor in Chief’s request to invite commentaries on Skraaning and Jamieson (2024) came after the article was accepted for publication.
Mapping the Objectives of the Target Article to the Aligned Objectives and Inspired Themes of the Fifteen Commentaries.
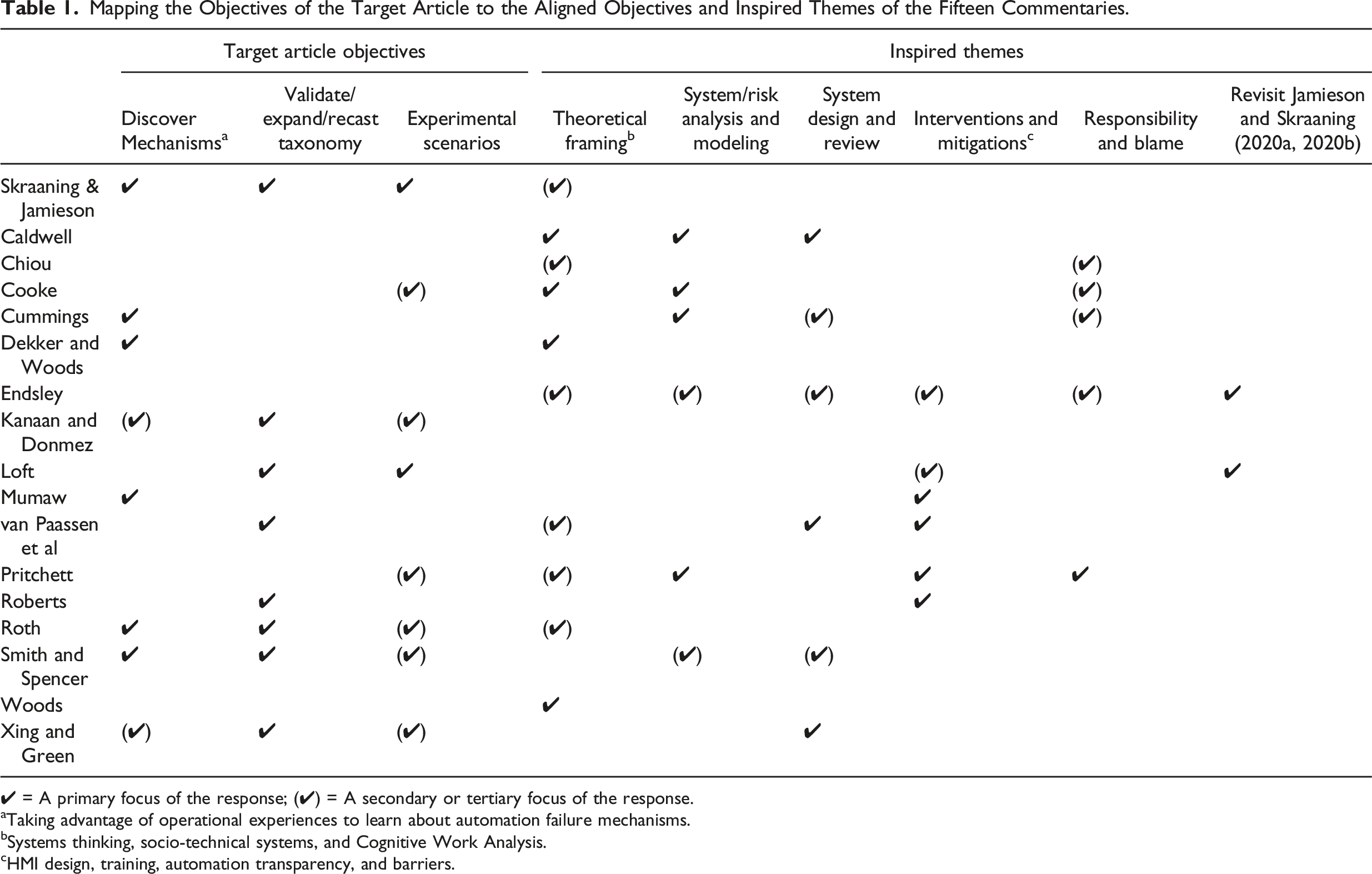
✔ = A primary focus of the response; (✔) = A secondary or tertiary focus of the response.
aTaking advantage of operational experiences to learn about automation failure mechanisms.
bSystems thinking, socio-technical systems, and Cognitive Work Analysis.
cHMI design, training, automation transparency, and barriers.
The meaning of a mechanism
Skraaning and Jamieson (2024) implicitly introduced mechanisms as the smallest meaningful unit of analysis in automation failure events. A mechanism could be seen as a modus operandi or a characteristic pattern of system behaviors discernable in an unfolding event. We use the mechanism notion to capture how components, regulating software, automatic systems, and/or human operators might work poorly, or work poorly together, and produce degraded socio-technological system states. Sensors that feed information to automatic systems may, for example, be misconfigured and thereby trigger erratic automation behavior, or automation could enter an unexpected mode of operation that unpredictably affects the system behavior. Other examples of a mechanism include a loss of power to automated systems, or when operators are inadequately trained to handle the automation. The mechanisms may thus be simple and isolated, as when a single automatic function is lost due to instrument failure, or complex and clustered as in our aviation cases. A mechanism could be detected, recognized, and responded to by operators or crews, or prevented or mitigated through design interventions. However, we seek to distinguish those effects and responses from the mechanism itself. Finally, a mechanism should not be confused with the trigger or root cause of an event. Since we draw inspiration from systems thinking, we avoid the notion of “linear chains of failure events” (Leveson, 2020, p. 60) that purport to offer a correct causal explanation of undesired outcomes.
Direct responses
Discovering automation failure mechanisms
Several readers responded to the acknowledged limitations of the initial taxonomy by contributing insights about automation failure from their domains of expertise. Roth (2024) extended our own nuclear power knowledge through a detailed examination of key facets of the Fukushima Daiichi accidents. She introduces “race” and “corner” interaction conditions as instances of Systemic Failures in automation components and logic which led to differing outcomes in similar plants exposed to the same catastrophic disturbance. She (along with Caldwell (2024), Cummings (2024), and van Paassen et al. (2024)) further introduces a class of failures arising from lack of design foresight, a mechanism that ought to have been included in our taxonomy from the outset. Roth also validates the systemic mechanism of automation being employed outside of its “operational design domain” or “design basis.”
Several commentaries enhanced our understanding of automation failure in surface transportation. Kanaan and Donmez (2024) and Roberts (2024) emphasize important distinctions in (i) operational context and (ii) user knowledge, expertise, and motivation between highly trained operators in industrial settings, and the often untrained general public operators in surface transportation. The latter supplement (and might prompt renaming of) the Human and Organizational Slips/Misconceptions category. Kanaan and Donmez (2024) add weather-related sensor failures and rear-end collisions due to automated braking as Systemic Automation Failure mechanisms. Cummings (2024) and Roth (2024) emphasize the role of computer scientists and engineers in anticipating operational conditions that create AI failure hazards. Cummings (2024) adds depth to our initial thinking about Systemic Automation Failures by (i) calling attention to the lack of regulatory requirements for machine vision and (ii) relating an instance where an AI vision system reasoned away sensed information that did not correspond with expectations.
Mumaw (2024), Dekker and Woods (2024), and van Paassen et al. (2024) expanded on automation failure in commercial aviation. Each of their commentaries offers insights that either validate or enrich the taxonomy. In particular, we share their critical reaction to the overly narrow interpretation of automation system boundaries that some designers cynically invoke to claim that automation “hasn’t failed” despite the evident insights that a systems perspective offers. Van Paassen et al. (2024) 1 capture this concisely, stating, “… to operators, it is mainly the functional aspects of automation that matter, and any failure leading to loss of automation support or even erroneous behaviour is relevant and seen by them as ‘failure of the automation’” (p. 6; emphasis added 2 ).
Mumaw (2024) compiled aviation automation incidents and accidents that illustrate many of the mechanisms expressed in the initial taxonomy and point to additional failure mechanisms (or varieties thereof). Illustrated mechanisms include the following: • Eastern Air Lines Flight 401: Inadvertent deactivation (Human and Organizational Slip/Misconception). • Asiana Airlines Flight 214; Turkish Airlines Flight 1951: (i) Automation works as intended but is outside its design basis (Systemic Automation Failure) and (ii) unexpected or hidden modes of operation (Human-Automation Interaction Breakdown). • Air Transat 236: Active automatic system camouflages failure at the component level (Systemic Automation Failure). • Midwest Express Flight 490: Instrument icing leads to loss of reliable airspeed indication (Elementary Automation Failure).
Additional/enriched mechanisms include the following: • Kenya Airways Flight 507: Automatic system not engaged. Suggests an expansion of the inadvertent activation/deactivation mechanism to include omission of activation (Human and Organizational Slip/Misconception). • Indonesia AirAsia Flight 8501: Partial loss of (or degraded) automation functionality: Whereas we had (and might still) characterized this mechanism as a pilot misconception (Human and Organizational Slip/Misconception), Mumaw’s account suggests an expansion of the Elementary Automation Failure category. • Aeroflot Nord 821: An active automatic system camouflages atypical control conditions that the automation compensates for until disengaged. This expands the Systemic Automation Failure mechanism that initially referred to camouflaging of component failure.
Van Paassen et al. (2024) and Dekker and Woods (2024) offer expanded accounts of the B737 MAX accidents. The former emphasize the reliance on layered implementation of discrete rules, both in the initial design that led to two catastrophic accidents and in the updated design that adds further condition logic triggering task initiation and execution. The latter cite two primary mechanisms in recounting these accidents: (i) hidden interdependencies in control software and (ii) “bad inputs to automated systems operating with high authority,” both arguably varieties of Systemic Automation Failure mechanisms. Their emphasis on the granting of high authority to “literal-minded machines” evokes “dysfunctional distribution of authority between humans and automation,” a mechanism included in Human-Automation Interaction Breakdowns.
These commentaries highlight how focused analysis of adverse operating experiences can lead to new insights without rushing to expand the analytical scope. In doing so, they (i) highlight the value of both intra- and inter-domain sourcing and characterization of automation failure mechanisms, (ii) underline both the benefits and risks of generalizing findings from one domain to another, and (iii) stress the difficulty of forming a single taxonomy. Despite these trade-offs and difficulties, the commentaries give credence to naming and organizing automation failure mechanisms in cognitive engineering.
Framing and organizing automation failure mechanisms
Many commentaries capitalized on our concession that, “This initial taxonomy could be expanded, reworked, or replaced with taxonomies adopting different purposes, perspectives, contents, and organizing principles” (Skraaning & Jamieson, 2024, p. 6). In this section, we focus on those contributions that emphasized reworking the taxonomy in a structural sense, noting that these efforts also tended to contribute to the discovery of additional mechanisms.
Smith and Spencer (2024) conveyed an earlier effort to develop, “…a taxonomy of factors contributing to automation failures” (p. (2) as part of a novel verification and validation (V&V) strategy for complex, inter-connected, and safety-critical autonomous aviation systems (see also Xing & Hughes Green, 2024). Like us and other commentators, they are keen to ascertain the risks of a variety of automation failures and assess proposed mitigations. They employed their taxonomy to develop knowledge elicitation questions to stimulate the thinking of subject-matter experts (SMEs) charged with generating “aberrant scenarios” to be employed in high-fidelity simulation. This application shares many similarities (e.g., how to plausibly instigate off-nominal factors and low probability events and how to cope with branching event trees with humans in the loop) with our focus on scenario development for crew performance assessment in a full-scope simulator. Similarly, their SME elicitation probes and process bear resemblance to the scenario development process in the OECD NEA Halden Human-Technology-Organisation (HTO) Project, including the reflection on experienced and hypothesized factors in the generation of new scenarios. In contrast, their probes also invite SMEs to consider how cognitive processes and other factors could contribute to the generation of scenarios. In the HTO Project, such considerations typically drive the research questions posed by experimenters that SMEs develop scenarios to help answer. As Smith and Spencer (2024) state, their inclusion of failure factors results in a broader and more detailed taxonomy as compared to the narrower focus of our taxonomy on failure mechanisms (i.e., machine-specific or machine-induced). We included some of these broader factors under the heading of Human and Organizational Slips/Misconceptions.
Setting aside the differences in objectives between V&V and human performance assessment, Smith and Spencer (2024) demonstrate that our two (independently developed) taxonomies overlap substantially. It is further encouraging to us that they find in our taxonomy mechanisms that might inform their knowledge elicitation probes to evoke new failure scenarios. Our common objective is that human factors evaluation, be it for experimentation or V&V, is grounded in scenarios that intentionally capture the variety of mechanisms and factors that operators could encounter in their work.
Van Paassen et al. (2024) invoke the Skills, Rules, Knowledge (SRK) framework to compare automation processes to human task performance as a structure for automation failure. Although adopting the SRK framework for automation appeals to Jamieson’s academic lineage, the link between the three levels (effectively two as the authors argue that present machines lack a sufficient world model to support Knowledge-Based Behavior) and their four classes of automation failure appears to falter as the comparison progresses. Their Basic Failure and Design-Induced Failures conform to Skill-Based and Rule-Based Behaviors, respectively, but the latter categories of Coordination and Systemic Failures are not as clearly aligned with a level of cognitive control. The identified need to engage in debugging in the context of their Systemic Failures does invoke Knowledge-Based Behavior.
Irrespective of any conformity to a guiding framework, van Paassen et al.'s (2024) four automation failure categories offer an intuitive classification scheme of their own. We see their Basic Failure category largely aligning with our Elementary Automation Failures category, plus the “faulty/unavailable sensor” mechanism in the Systemic Automation Failure category. We further recognize an opportunity to expand the “loss of power” mechanism to include loss of hydraulic and pneumatic functions as well. Design-Induced Failures appear to align fairly well with Systemic Automation Failure mechanisms, such as “automation operates outside its design basis” and “component failures go undetected by automation which continues pursuing generic operating goals.” Coordination Failures to our reading largely parallel Human-Automation Interaction Breakdowns. Finally, their category of Systemic Failure strikes us as a combination of ours of the same name and Human-Automation Interaction Breakdowns. We do appreciate the insightful distinction between common component failures in layered versus integrated functionality in legacy and newer multi-function automation systems, respectively. The revised taxonomy captures these contributions.
Loft (2024) poses two questions about the organization of the initial taxonomy. First, he asks what the difference is between Elementary Automation Failures “(failures in automation control, logic/programming, or malfunctioning hardware producing degraded/inaccurate output)” and “…Human-Automation Interaction Breakdowns resulting from automation providing misleading support to operators (low reliability automation)?”
We adopted natural classification to develop the taxonomy, organizing the mechanisms according to shared characteristics and inherent relationships, as in traditional biology. We have not grouped mechanisms as per their outputs or effects on operator experience and/or performance. Mechanisms in these two categories may have similar impacts on the operator but differ in that elementary failures involve a loss of automation functionality, while breakdowns address weaknesses of the human-automation interaction design.
Loft (2024) poses a second question about the difference between “Systemic Automation Failures being caused by automation working as intended but not conveying limitations or the automation having ‘hidden’ logic issues” and “Human-Automation Interaction Breakdowns caused by hidden modes of operation, failure modes that are not recognizable, or automation goals and capabilities being inaccessible to operators?”
From a systems design perspective, hidden modes of operation and unrecognizable failure modes are typically intentional (if inadvisable), while logical failures in the automation programming are unintentional.
In the context of surface transportation, Roberts (2024) characterizes failures in driving automation systems, distinguishing between automation failures (due to system limitations vs. system malfunctions), transparency (salient or not), and responsibility (caused by the system vs. human-system interaction). She aligns those distinctions with the three categories of Automation-Induced Human Performance Challenges with the aim of identifying appropriate preventions and mitigations (i.e., interfaces and training). Although this later alignment is beyond our intended scope (see below), we are encouraged that the initial taxonomy was amenable to her extensions without modification.
Finally, in the context of nuclear regulation, Xing and Hughes Green (2024) suggest that the performance influencing factors identified in the USNRC’s Human Reliability Analysis methodology could give further structure to the Human and Organizational Slips. Misconceptions category. We agree that this category can be significantly expanded to capture more of the breadth of human and organizational factor considerations in system design (and encourage readers to interpret our initial rendition of this category as a sample of such).
We deduce from the above and other commentaries that many cognitive engineering researchers share our view that efforts to organize the automation failure construct are warranted and useful. Moreover, we acknowledge that there is no privileged framework for effecting that organization and thus remain receptive to alternatives. For the purpose that we adopted—broadening the automation failure construct in human-automation experiments—we concur with Roth (2024), who states, “Whether various of these automation failures correspond to, are subsets of, or represent additional classes of systemic failures to the ones included in the Skraaning & Jamieson taxonomy is not clear-cut and perhaps not of highest importance” (p. 4).
Experimenting with automation failure mechanisms
Many commentaries endorse our call for a more ecologically valid and representative selection of automation failure scenarios in cognitive engineering research (e.g., Endsley, 2024; Loft, 2024; Pritchett, 2024; Roth, 2024; Xing & Hughes Green, 2024). Loft (2024) states: “…a major limitation of human automation research (including my own research) is that typically participants are exposed to fixed quotas of randomized automation failure, allowing little opportunity to develop understanding of the automation they are using, limiting their capacity to predict when automation failures might occur. Really, in most studies the only learnable context for system reliability is the frequency of automation failure. This contrasts sharply with my observations in aviation and defence field settings in which automation reliability is dynamic/context-driven, allowing nuanced human understanding of automation capabilities and limitations that enable prediction of when intervention is required” (p. 5).
Our own experience in nuclear power corroborates Loft’s observations, and Jamieson likewise admits to the same limitation in his own research (e.g., Reiner et al., 2017; Wang et al., 2009; cf. Bagheri & Jamieson, 2004).
Kanaan and Donmez (2024) present compelling evidence from a systematic literature review affirming the prevalence of automation failure scenarios in surface transportation research (extending far beyond DOA inquiry). From a review of 164 studies fitting their selection criteria, they place 93 automation failure events to the taxonomy, suggesting that the categories are sufficiently concrete and intuitive to inform scenario evaluation and design across strikingly different safety-critical domains (i.e., surface transportation, nuclear power, and aviation). “88% of the studies (n = 82) investigated Human Automation Interaction Breakdowns; specifically, situations where the automation enters ‘unexpected or hidden modes of operation that affect system behavior and/or redefine the safety envelope’” (Kanaan & Donmez, 2024, p. 3). A further “…20% of the studies (n = 22) focused on takeover scenarios which could be caused by failures in the automation control logic, the programming, or the hardware, and which can be attributed to elementary automation failures ….” Only two studies employed Systemic Automation Failures. They conclude the following: It appears that the scope of research on vehicle control automation is limited to a few types of failures from Skraaning and Jamieson’s taxonomy, and many of the studies examined similar takeover scenarios that may not capture the variety of failures that occur in the real world (Kanaan & Donmez, 2024, p.5).
With this conclusion, Kanaan and Donmez (2024) offer some validation of our impression that the cognitive engineering experimental literature is lacking in terms of the variety of automation failures implemented. Importantly, however, they use our own taxonomy to challenge our intimation that “sudden and unexplained loss of automation function” is the near-exclusive mechanism.
Kanaan and Donmez (2024) take their analysis further, asking what factors influence this narrow reliance in surface transportation. They offer several hypotheses: (i) speculation about how emerging automation technologies will fail, (ii) limited resources to develop more representative failure scenarios, (iii) absence of a need to vary automation failure to answer stated research questions, or (iv) convenience. They further note that de Winter et al. (2021) recently called attention to the same lack of variety and realism. By reflecting on these factors, empirical cognitive engineering researchers might recognize how failure mechanisms could manifest in new domains, imagine new ways to realize them in experimental scenarios, and introduce new research questions.
Kanaan and Donmez (2024) did identify two driving automation studies that employed Systemic Automation Failures. Similarly, Cooke (2024, p.3) related an experimental operationalization of what we would classify as a Human Misconception About Automation. Such examples could inspire development of experimental scenarios for automation failure in these and other domains.
Kanaan and Donmez's (2024) evidence-based observations boldly underline the value of dialogue about automation failure facilitated by this special issue and point to potential changes in empirical research direction.
In contrast to the above, none of the commentaries argue that current practices of operationalization of stereotypical automation failures in empirical cognitive engineering research are ecologically valid, representative, or otherwise defensible. This silence is conspicuous. A clear conclusion is that we collectively recognize the need to contend with the complexity of automation failure in our experimental programs. 3
A revised taxonomy of automation failure mechanisms
Figure 1(a) and (b) depict a revision to our initial taxonomy, incorporating many commentator suggestions. We reiterate that this is one taxonomy adopting a specific purpose (informing empirical investigation), perspective (industrial research and development), content (mechanisms), and organizing principle (natural classification by shared characteristics). Variations on all of the above (many of which are reflected in this special issue) can be valid. We also emphasize that the proposed taxonomy is meant to be illustrative and not exhaustive. Thus, we welcome efforts to continually expand on, revise, or recast the taxonomy to suit new uses. (a) Revised taxonomy of automation-induced human performance challenges and (b) other human performance challenges induced by human or organizational slips/misconceptions.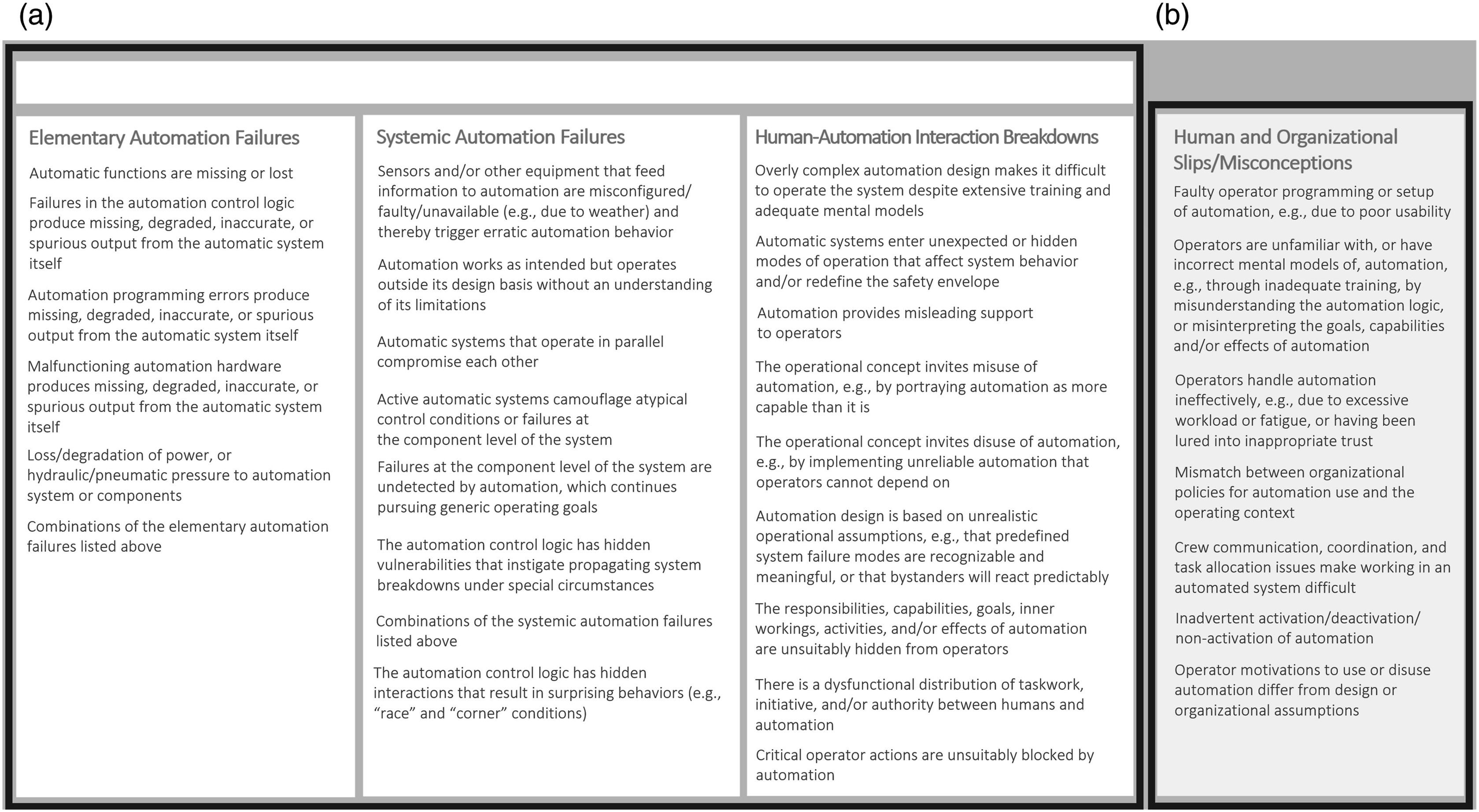
While the revised taxonomy reflects valuable input from many commentators, it also reveals three challenges that we contended with in forming both the initial and revised taxonomies. First, as we seek to account for more mechanisms and variations thereof, the logical complexity of each mechanism statement increases. Second, attributing the mechanisms to socio-technical causes (particularly for Human and Organizational Slips/Misconceptions) de-emphasizes the mechanisms themselves. Third, mechanisms incorporating more domain-specific features (e.g., weather) may not readily generalize across industries and operationalizations of scenarios. In summary, increasing the level of detail and precision of the mechanisms trades off comprehensibility and threatens to undermine the original objective of the taxonomy.
Digressions and inspirations
The first phase of our rejoinder has focused on direct responses that aligned with the objectives stated in our target article. In this phase, we selectively react to responses that adopted different objectives and acknowledge inspired commentaries. Many of the commentaries span two or more of those categories.
Scope and theory: “Let’s do it my way”
Pritchett (2024) is explicit in accepting the invitation to offer an inspired response, stating, “… I realize that I am taking a viewpoint here that is broader than that of Skraaning and Jamieson…” (p. 5). She lists three drivers of operational performance and safety (of which automation failure is at most a subset of one) and poses five questions that the HAI community should be addressing (a compelling call to PhD students). Her ethical emphasis on “ultimate responsibility” complements van Paassen et al.'s (2024) notion of “meaningful human control.” Finally, we wholly agree that, “Constructs such as ‘explainable AI’ are underspecified…” (p. 4) and suggest that invocations of “transparency” are often equally vague (cf. Rajabiyazdi & Jamieson, 2020; Skraaning & Jamieson, 2021).
Caldwell (2024), Pritchett (2024), and van Paassen et al. (2024) each invoke a framework from Cognitive Work Analysis (Vicente, 1999); Abstraction Hierarchy, SRK, and Strategies, respectively. Our intuition is that these powerful tools could be effective at supporting formative analyses of complex work systems with aims well beyond the intended application of the proposed taxonomy.
Despite our perception that Dekker & Woods' (2024) expanded account of the Boeing 737MAX accidents and resulting insights largely align with our own, we detect in their commentary a note of frustration with the target article not adopting their language and framing of “wrong, strong, silent, and difficult to direct literal-minded machines,” which (as their extravaganza of self-citation reminds us) is foundational to HAI. There is a reason for that. In consuming much of this literature, we experience an initial delight in the rich story-telling and florid expression, followed by a lingering doubt that it advances constructs that are amenable to experimental testing. It reminds us of the spike and crash in blood sugar that follows the consumption of fast-digesting carbohydrates. We’re initially delighted but soon hungry for something more substantial. The proposed taxonomy is not a coup attempt. It merely reflects a drive to translate operating experiences into realistic experimental scenarios. Adherents to doctrines that bypass systematic experimentation are unlikely to see much value in that effort.
Objectives: “Your model fails to satisfy my objectives”
Many commentaries find fault with our initial taxonomy for not satisfying objectives that we did not adopt.
Much of our experience of formulating this rejoinder is captured by the maxim, “You can control what you say, but you can’t control how people interpret it.” This is why we were initially reluctant to accede to the calls from the reviewers and Associate Editor to develop a taxonomy. And why we might have hesitated before agreeing to the journal using our article as a target for a special issue.
Many of the liberal interpretations of our intent are nevertheless worthy of discussion.
Endsley (2024) and Caldwell (2024) long for the proposed taxonomy to account for cause and effect relations (see also Loft's (2024) comments in Design Process). But taxonomies are generally used for classification and organization, not depicting relational dynamics. Had we sought to model cause-effect relations, we would have proposed an ontology or constructed some type of causal diagram. But this would have been superfluous to our objectives. Moreover, linear causal analysis seems inconsistent with systems thinking.
Still, Endsley (2024) characterizes this as nothing less than a failure of the proposed taxonomy. She asserts that her own depiction of automation failure remedies this alleged weakness. However, it is unclear to us how lists of events, automation features, barriers, and human performance outcomes, adorned with unexplained pastel color coding and a vague directional indicator, can account for cause-effect relationships. Had her commentary included more than a paragraph of lofty claims about this “model,” we could have offered more feedback.
Caldwell (2024) dwells on the target article and proposed taxonomy including the word “mode” without adopting Failure Modes and Effects Analysis (FMEA). We think this a strict interpretation of a term used colloquially in human factors (see Jamieson & Vicente, 2005). Nevertheless, in the context of the automation failure taxonomy, FMEA could act as both a discovery source and targeted use for failure mechanisms. In the former sense, we would have welcomed a commentary demonstrating how FMEA analyses revealed mechanisms missing from the proposed taxonomy. In the latter capacity, the contents of the taxonomy identify “failure modes” for inclusion in an analysis (see Xing & Hughes Green, 2024, p. 4). Moreover, FMEA would be well-served by a body of empirical evidence pertaining to the detectability of automation failures from across the taxonomy (as advocated above) and the efficacy of interventions and mitigations. However, there are several limitations to FMEA that warrant caution. For example, in FMEA there can typically be only one failure mode operating at a time (GSFC, 1996, p. 6), analyses are limited to known unknowns (Luft & Ingham, 1961), and causes and effects are typically identified in a linear manner. Finally, we express a concern that deterministic desktop analysis in the absence of empirical evidence can lead to unrealistic assumptions about human performance and the effectiveness of mitigations. Perhaps more modern applications or future iterations of FMEA can address these limitations and offer promise that the method can be useful as a tool for anticipating the implications of as yet unencountered Systemic Automation Failure mechanisms.
Socio-technical systems: “Are you true believers?”
Most prominently, Chiou (2024), Cooke (2024), Endsley (2024), and Roth (2024) all render direct or indirect criticism of the proposed taxonomy for not fully embracing the socio-technical systems (STSs) perspective. The most damning evidence for this evidently being our positioning Human and Organizational Slips/Misconceptions outside of the umbrella of “Automation-Induced Human Performance Challenges.” It seems that some suspect our systems thinking of being insufficiently systemic.
That the STS perspective is inherent to our thinking is reflected in the expansion of the automation failure construct beyond elementary automation failures to include Systemic Automation Failures and Human-Automation Interaction Breakdowns. But why, then, would we refrain from embracing Sebok and Wickens’ (2017) broad perspective on automation failure and count any unexpected automation behavior as a failure mechanism? Wouldn’t that be truly socio-technical of us?
Once again, the reason for that can be found in our stated objective. We sought a characterization of automation failure that is “…(i) sufficiently broad to encompass the range of operating experiences in complex work systems, yet (ii) specific enough that human factors researchers can agree on what aspect of the construct is being investigated” (Skraaning & Jamieson, 2024, p. 6). We sought to encourage the production and consumption of industrially relevant HAI experimental research. However, it has been our experience that it is difficult to realistically operationalize STS principles—even in high fidelity simulators. Thus, while we count ourselves among those theoretically committed to the STS perspective, and participate in a research program that is inherently socio-technical in nature, 4 we are necessarily selective about which socio-technical elements we include in any given experiment. 5 The proposed taxonomy is similarly restrained.
In effect, these STS advocates call for a further broadening of the automation failure construct beyond that proposed in the target article. But at what point would the construct become overly broad and admit all undesired HAI outcomes as automation failures, thereby threatening its specificity and utility? It is always possible to step back and adopt a longer view. We could, for instance, readily signal our STS credentials by extending the “Automation-Induced Human Performance Challenges” heading to include Human and Organizational Slips/Misconceptions (as some commentaries call for). 6 But can such an inclusive construct be effectively operationalized? Or is there an inherent limitation imposed by the real difficulty of constructing experimental scenarios?
As experimentalists inspired by systems thinking, we are receptive to STS resolutions to this dilemma. We welcome case studies and anecdotes that reveal additional failure mechanisms, test and redraw the blurry boundaries between categories, and inspire experimental scenarios. We encourage other researchers to operationalize Human and Organizational Slips/Misconceptions and test the human performance consequences thereof. However, we remain wary of expanding the automation failure definition/taxonomy to the point that the construct is overly-broad, draws few practically meaningful distinctions, and becomes susceptible to logical disconfirmation (Caldwell, 2024, pp. 2–3). We see little insights in the easy excuse that operationalization invariably fails to capture the complexity of the STS. And we (as experimentalists) are short of patience for language games that distract from the empirical objective.
Blame and responsibility: “Operator shamer!”
An associated anxiety is the matter of attribution of blame and responsibility. Chiou (2024) scrutinizes the taxonomy language of “automation failure” and “human performance challenges” and worries that these might not protect operators from being blamed for bad outcomes. She heads off the defense that supporting adjudication of blame was not among our objectives: “That may not be the intended purpose of the taxonomy, even though intent does not prevent it from being used that way” (Chiou, 2024, p. 2). Endsley (2024), deterred by neither purpose nor accuracy, states incorrectly that, “…the human and organizational slips/misconceptions all cite the operator as performing improperly in some way without identifying these issues as a consequence of automation design features or organizational actions” (p. 2). In fact, Figure 1(b) (Skraaning & Jamieson, 2024) clearly attributes most of these mechanisms to “poor usability,” “inadequate training,” “excessive workload or fatigue,” “policies for automation use,” and “task allocation.”
Although we hadn’t deemed it necessary to do so before, we hereby signal our allegiance to the following statement of virtue: “All automation-induced (and otherwise-induced but automation-affiliated) human performance challenges are attributed to external factors” (Kelley, 1973). To take a small step back from that absolute declaration, we subscribe to a restorative “just culture” (Dekker and Breakey, 2016) that does not tolerate reckless behavior. We might add that we assume that all of our human factors colleagues embrace these principles—although sadly this assumption does not necessarily hold in the interdisciplinary domains in which we work (see Lipták, 2014). To alleviate Chiou’s (2024) concern (to the extent that explicit statements of intent can do so), we rephrased some elements in the taxonomy to protect against mis-directed attributions.
Design process: “But can it do this?”
Another recurring critique of the proposed taxonomy is that it fails to adequately support one or more phases of the design process, including modeling, system design, or selection and design of interventions and mitigations (Caldwell, 2024; Endsley, 2024; Loft, 2024; Mumaw, 2024; van Paassen, 2024; Pritchett, 2024; Roberts, 2024). Caldwell states: One potentially problematic element … is whether the focus on “automation failure” is the appropriate level of analysis and critique for … elements of system design, analysis, and intervention (Caldwell, 2024, p. 1).
It is most certainly not.
Cooke (2024) and Pritchett (2024) both correctly state a need for modeling of (i) human (including team) performance (including monitoring and strategic selection) in joint systems or (ii) human-automation system dynamics. Although the target article was preceded by our experience in testing the predictive power of a human performance model, and while taxonomic distinctions might be reflected in such models, a taxonomy alone offers little to such efforts. Cooke (2024) advances more promising approaches to predicting STS responses. Loft (2024) proposes a “variation” on the proposed taxonomy to delineate precipitating events that cause elementary and systemic automation failures and then describe how automation and organizational factors moderate operator responses. In our view, this reads as a modeling effort perhaps even more ambitious than that of Cooke (2024) and Pritchett (2024) with the same incumbent limitations on taxonomic distinctions. We conjecture that one possible outcome of the special issue could be that commentators of similar mind might discover a collaboration opportunity to advance shared objectives.
Xing and Hughes Green (2024) highlight the relevance of automation failure varieties to regulatory review. They emphasize the need for a technical basis for regulatory activities, particularly for the challenges posed by (i) new reactor technologies and (ii) digital instrumentation and control modernization and new automation to the safety systems of existing facilities. They relate how the US Nuclear Regulatory Commission (NRC) relies on both operating experiences and the empirical literature to establish that basis. They corroborate the concern, “that results from human-automation-interaction laboratory experiments in simple multi-task contexts generally do not predict human performance with automation in complex control process systems” (Xing & Hughes Green, 2024, p.3) and consider the possibility that regulators could use validated taxonomies of automation failure as a tool for design evaluation.
Along the same lines, Endsley (2024) is finally correct to point out that the proposed taxonomy isn’t grounded in empirical evidence differentiating human performance impacts of each (sub)category. She will be encouraged to learn that we are following this approach in our current (i.e., still existing) Halden HTO Project experimental investigations of operator responses to systemic automation failures in nuclear process control (Skraaning & Blackett, 2022; Skraaning et al., 2023). We are first seeking evidence from realistic simulator studies that systemic failures produce human performance challenges and will then explore interventions if there are indeed operational safety concerns that generalize to our industrial domain.
Interventions and mitigations: “Let’s stay in our lane”
In my view, HF practitioners should not focus on automation failures or defining the range of automation failures. The important role we have is to specify how the interface conveys the automation’s state and behavior: when the automation fails and when the automation performs as designed (Mumaw, 2024, p. 2).
Mumaw’s fixation on interface design as the single expression of our professional insight is unnecessarily self-limiting in our view. He seeks to hone his craft by studying aviation cases to correct the “Automation Interface Failures” underlying the mismatch between automation state or behavior and the pilots’ understanding. This reactive approach seems antithetical to human factors science. Would it not be preferable to first uncover and understand recurring automation failure mechanisms before we identify how automation-induced human performance challenges can be prevented and mitigated?
Loft (2024) expresses surprise that we didn’t mention automation transparency (see also Caldwell, 2024; Endsley, 2024; Kanaan & Donmez, 2024). Of the many interventions and mitigations that are not captured by the proposed taxonomy, this is the one that has seemingly captured the hearts and minds of cognitive engineering researchers of late. In other work (Rajabiyazdi & Jamieson, 2020; Skraaning & Jamieson, 2017, 2021; Skraaning et al., 2020; Skraaning et al., 2019), we’ve called for a tempering of the exuberance about automation transparency.
Roberts (2024) emphasizes the importance of training to improve operator mental models as a prevention of or mitigation for automation failures (see also Chiou, 2024; Endsley, 2024; Kanaan & Donmez, 2024; Pritchett, 2024). She cites, for example, research by DeGuzman and Donmez (2022), which suggests that responsibility (of the operator) focused training may yield better mental models than limitation (of the automation) focused training. 7 Lacking expertise in this area, we can offer only cautious endorsement. The nature of systemic automation failures may invite questions about whether procedural training, which predominates in nuclear power plant operations, adequately prepares operating crews to engage in problem solving behaviors that we suspect are more conducive to effective mitigation of such events.
Potpourri
Finally, several commentaries raised points that we struggled to fit into the structure of our rejoinder.
The taxonomy offers no obvious insights into the automation/autonomy conundrum referenced by many contributors (Chiou, 2024; Cooke, 2024; Cummings, 2024; Dekker & Woods, 2024; Pritchett, 2024). Perhaps one of these colleagues will put forward a target article on that topic for the next special issue.
Closely aligned with the emphasis on STS, several commentaries emphasized a need to adopt Human-Automation Teaming (Cooke, 2024; Mumaw, 2024; Pritchett, 2024). The history of HAI research is marked by a progression of social metaphors, and the commentaries reflect the current transition from supervisory control to automation as a teammate. We suspect that our science will soon discover real limits to this metaphor as we struggle to create machine team mates (see Rieth & Hagemann, 2022; Shneiderman, 2020). A nice idea and a catchy phrase, we agree, but let’s not succumb to our own marketing too readily.
Cummings (2024) introduces a taxonomy for AI Hazard Analysis to augment the classic Swiss Cheese model in the context of surface transportation. Her taxonomy reflects a systems-thinking approach and includes layers for oversight, design, maintenance, and testing. She also echoes concerns about allocation of blame in human-AI systems, as discussed above.
Summary
In this rejoinder, we have highlighted the many points of agreement, extension, and critique found among the 15 commentaries.
In our view, the special issue has been a mixed success. On the one hand, we are encouraged by several apparently shared views: • We have observed, continue to observe, and anticipate further dramatic increases in automation functionality in safety-critical systems that precipitate profound experiences of automation dysfunctionality, • we believe that our science is highly relevant to understanding human(s) experience with that dysfunctionality and that our engineering offers insights for detecting, mitigating, and compensating for it, • the characterization of automation failure through mechanisms appears useful, • the automation failure scenarios that predominate in our empirical literature lack variety and are not representative of the operational experience of automation failure, • detailed review of operating experiences is a productive strategy for discovering new automation failure mechanisms, • there is value in forming conceptualizations of automation failure for a variety of purposes, • a taxonomy of automation failure mechanisms is a plausible means of enriching scenario design in cognitive engineering experimental research, and • systemic automation failures are under-studied.
On the other hand, the special issue reveals highly diverging objectives and perspectives: • There is little agreement on the objective(s) of characterizing automation failures (e.g., human performance modeling, design, test and evaluation, and apportioning blame), • there is a disagreement on the tools, frameworks, and models to be employed in characterizing automation failure or organizing failure mechanisms, • the pressure to broaden the automation failure conceptualization to account for more of the factors associated with human performance has an associated risk of sacrificing specificity and utility, • we do not agree on where to stop including those factors in a given model, and • we disagree on the suitability of the evidentiary basis and the maturity of human performance models to generalize to operational settings.
In our view, the taxonomy of automation failure has largely served its purpose as a scaffolding to build up the automation failure construct. It was intended to encourage the pursuit of, and aid in the design of, HAI experiments that better capture the experiences of coping with varieties of automation failure. Those who share our objectives appear to have embraced the implications and have proposed insights to further advance the construct through ongoing discovery of automation failure mechanisms, reflection on the shared and unique characteristics of those mechanisms, and inspiration to pursue representative scenarios in our empirical research. Those who have other objectives will not likely find further defense or iterations of such a taxonomy sufficient. If its demise inspires them to new insights and contributions, then we may be ready to dispose of the scaffolding.
Rehashing the “no proper test” critique of Jamieson and Skraaning (2020a)
Endsley (2024) used the special issue to undertake a two-front campaign against our earlier test of the lumberjack model predictions in a complex work setting (Jamieson & Skraaning, 2020a). It is easier to criticize than explain, so we must devote considerable space to a rebuttal to her two offensives.
The Important Parameter Assessment Questionnaire (IPAQ) as a measure of situation awareness
The first offensive in Endsley's (2024) campaign to discredit the findings of Jamieson and Skraaning (2020a) resumes the attack initiated by Wickens et al. (2020) against the systematic linear SA effect pointing in the opposite direction of the lumberjack model prediction.
An “unvalidated measure”
A reasonable deduction from the extensive literature on SA measurement is that significant challenges remain regarding the validity, reliability, sensitivity, intrusiveness, context specificity, and domain applicability of instruments. Thus, charges that an “unvalidated measure” has been employed in any study are both easily levied and barely informative. There is no measure of SA sufficiently validated for the process control domain 8 (Braarud & Pignoni, 2023; Xu et al., 2018) despite concerted efforts to produce them (e.g., Hogg et al., 1995; Lau et al., 2012, 2014, 2016a, 2016b). From our perspective, then, a meaningful disapproving critique of any SA measure used in that domain would presume deep contextual knowledge about the complex test environment in which it is employed and the control task to which it is applied 9 (Skjerve & Bye, 2011). IPAQ was developed and employed by researchers and subject matter experts who can lay claim to having that knowledge. Endsley’s critiques of IPAQ, in contrast, appear to rely on surface-level application of presumed best practices imported from other domains. Contextual knowledge relevant to her critique includes the simulated process model, operational concept, safety systems, automated functions, operating procedures, 10 control room design, staffing solutions, and test scenarios. This detail is far more than can be conveyed through a journal article. 11 Still, we devote some space to dispelling the misunderstanding behind her first attack.
In Jamieson and Skraaning (2023), we stated: “In the scenario, several pressure relief valves were meant to open and then close when the COPS sent a reset signal. However, one valve would fail to close. Because preconditions in the pressure relief system were not met for the subsequent procedure step, the automation was unable to proceed” (p. 2). This is correct, but it is also a simplification of the task for a space-constrained journal article. 12 It could leave the impression that IPAQ probes expected participants to retrospectively assess the importance of process parameters in relation to an isolated valve failure among many other scenario events.
In reality, the scenario had three phases. In the first phase, the crew performed a periodic test of the pressure relief system. This took approximately 30 minutes and involved the opening and closing of 16 pilot valves, followed by a check that every pressure relief valve closed as expected. One pilot valve failed and left the corresponding relief valve stuck in an open position. The operators were expected to use a coupled block valve to close the stuck pressure relief valve. The purpose of this phase was to give the crew an opportunity to observe the failure. The experiment included four scenario variants, each failing different relief valves. In the second phase, we introduced a disturbance where the pressure relief system contributed to keep the plant in a safe state. With a valve failure in the pressure relief system, operators were ideally expected to quickly close the block valve to prevent a rapid temperature fall and loss of coolant. The triggering disturbance was different for each variant, with variant 1 imposing an electrical failure closing the turbine bypass valve, variant 2 a leakage resulting in steam line isolation, variant 3 a leakage in the turbine hall, and variant 4 a condenser cooling pump trip. Finally, in the third phase, there was an automatic reactor trip, which once again actuated the pressure relief system and exposed the stuck valve failure. The operators were, as before, expected to close the block valve as soon as possible. During these events, the participants relied on operating procedures and were tested under four Degrees of Automation (DOA), with the four scenario variants randomly assigned to the DOA conditions. The scenarios were developed in collaboration with experts on the operation of nuclear power plants.
The description above should be sufficient to demonstrate that when the (professional nuclear power plant) operators assessed the importance of process parameters in relation to the valve failure (IPAQ), it was not an isolated event that they had to recall passively but rather a recurring theme that challenged the participants throughout the scenario. Endsley (2021) herself points out that, “…with increasing levels of domain expertise people rely more on running memory, actively updating and processing new information as the task proceeds, as opposed to passive working memory that simply tries to memorize information without further processing” (p. 140). Given deep conceptual knowledge of the cognitive work at hand, Endsley’s (2024, p. 4) fixation on hindsight bias seems selectively applied to IPAQ. Why would IPAQ’s retrospective assessment be less suitable than retrospective assessment employed in other SA measures that also rely on experienced operators’ running memory?
Dual tasking
Given the recurring pressure relief valve failure in our scenario, one might expect operators to learn a heuristic solution and correctly maneuver the block valve in all subsequent scenarios. That would have resulted in ceiling effects and minimal performance variability. In fact, we observed the opposite. The block valve heuristic was far from obvious and there was a substantial variation with respect to (i) whether or not the crews discovered the heuristic, adopted less productive approaches, or were unable to solve the scenario, (ii) at which point in the scenario the block valve heuristic was applied, or reapplied across scenario variants, and (iii) latencies in the implementation of the heuristic due to the unique character of each triggering disturbance and accumulating parallel taskwork. In realistic simulator experiments, scenarios develop organically with operators continuously monitoring for process deviations, while trying to diagnose and resolve accumulating problems that play out in parallel. Thus, Endsley's (2024) second line of attack that “subjects were not subject to dual tasking” (p. 5) is grossly incorrect.
Overlapping confidence intervals
Endsley's (2024) third attack in the anti-IPAQ offensive casts further doubt on the instrument based on visual inspection of overlapping confidence intervals from our study. This is a common misinterpretation of confidence intervals for within-subject effects (see Belia et al., 2005). Endsley appears to be unaware that these interval estimates include variance across repeated measurements for each participant (i.e., the autocorrelation per block or row in the RBF design, denoted by ρ), while that variance is removed from the error term in the within-subject analysis of variance (Cumming & Finch, 2005; Loftus & Masson, 1994). Hence, one cannot infer population differences between means from the inspection of overlapping confidence intervals for within-subject effects (in contrast to between-subject effects) but must instead rely on the p-value. Jamieson and Skraaning (2020a) sought to prevent incorrect inferences about mean differences by reporting confidence intervals for within-subject effects in a tabular format rather than graphically, but that tactic sadly failed to deter Endsley from this ill-informed attack.
An ineffectual first offensive
Endsley (2024) mounts a frenetic offensive to dismiss a systematic linear SA effect (p = .01) accounting for 30% of the IPAQ-variation in our full scope simulator experiment (Jamieson & Skraaning, 2020a; Figure 6). Perhaps because that effect points in the opposite direction of the lumberjack model prediction and the conclusions drawn by Onnasch et al. (2014). She does so by (i) relying on a hegemonic gold standard of “valid SA measures,” (ii) spinning incorrect characterizations of the cognitive work of process operators as reflected in our experiment, and (iii) succumbing to a common misapplication of a statistical practice. The offensive falters on these feeble attacks.
A more constructive engagement
We appreciate Loft's (2024) distinction between SA as (i) reportable conscious knowledge about the operating situation or (ii) operational knowledge situated in teamwork and the task execution through the user interface. IPAQ was a pragmatic attempt to combine these perspectives: Out of concern for the intrusiveness of traditional freeze-probe techniques (such as SACRI; Hogg et al., 1995; Endsley, 2021; Endsley, 2000), Halden Project scientists experimented with real-time assessment of situated operational knowledge through the use of eye movement tracking. The Visual Indicator of Situation Awareness (VISA) analyzed the operators’ attentiveness to scenario-specific areas of interest across the many process displays in nuclear power plant control rooms (Drøivoldsmo et al., 1998). These areas of interest conveyed important information about the process development in the scenario and were pre-defined by SMEs. VISA scores correlated with SACRI in two independent studies (r = −0.52, p < .01 and r = −0.53 p < .05 respectively; Drøivoldsmo et al., 1998), but the resource-intensive manual scoring of eye gaze-lines and dwell times rendered the instrument impractical. The motivation behind IPAQ was to capture some of VISA’s focus on scenario-specific and important process elements, while reducing data processing load, and without reintroducing potentially intrusive interruptions of the taskwork. To achieve these objectives, we placed greater confidence in the operators’ running memory and assessed SA upon completion of the scenario. Loft (2024) seems to acknowledge the trade-off between non-intrusive measurement and reliance on operator memory in realistic experimental settings. Without this backstory, he could not have known the theoretical underpinnings of IPAQ.
Loft (2024) is further critical of IPAQ’s dichotomous response scale. There is once again more to the story: The operators in our study responded to a six-item response scale ranging from 1-Unimportant to 6-Very Important, that is, expressing the perceived importance of process parameters for the progression of scenarios. It was the matching of operator ratings to the SMEs’ pre-defined assessment of parameter importance that drove us towards a dichotomous data format, as a standard subtraction of scores turned out to be misleading from an operational point of view. It was therefore decided to rely on a less nuanced but technically justifiable evaluation of agreement or disagreement between operators and experts. Thus, the dichotomization of IPAQ data evolved from the intricacies of raw data aggregation. One may also question whether averages derived from multipoint items are, in fact, psychometrically different from averages based on dichotomous items (see Dolnicar, Grün, B., and Leisch, 2011). We would have preferred more nuanced IPAQ raw data but feel confident that the SA results presented in Jamieson and Skraaning (2020a) were industrially and psychometrically meaningful.
Absence of task performance effects
Endsley (2024)continues her campaign against Jamieson and Skraaning (2020a) with an offensive to cast doubt on our failure to replicate task performance effects predicted by the lumberjack model. This offensive, like the first, is comprised of three attacks.
Sample size and statistical power
Endsley's (2024) first attack is a besmirching critique of the sample size and statistical power in our DOA experiment (Jamieson & Skraaning, 2020a). 13 In place of mounting a cogent argument, she wrongly states that we, “argue that somehow the power of the test is not important” (Endsley, 2024, p. 4). Rather we pointed out that retrospective analysis of observed power is a questionable practice and cited authoritative sources to substantiate that statement (Jamieson & Skraaning, 2020b, pp. 537–538). This position is by no means a devaluation of prospective power analysis, for example, to estimate the number of measurement points needed to reveal practically significant effects in experiments.
We have already acknowledged that the statistical power may have been on the weaker side for the response time and task performance indicators in our study (ibid.). We therefore performed and reported a statistically powerful (1-β = 0.94) reanalysis of an extended dataset from the same series of experiments (ibid). When equivalent data from two additional test scenarios were added to our original study, “the effects of DOA on response time and task performance were again statistically insignificant (p = .78 and p = .70, respectively)” (pp. 537–538). Endsley (2024) ignores this reanalysis and instead encourages us to report speculative trend results as systematic effects.
Order effects
A second attack targets our experimental design, pointing out that, “The authors do not report on any testing of order effects which could easily have contributed to the lack of statistically significant difference between conditions” (Endsley, 2024, p.4). In Randomized Block designs with individual operators or crews serving as the blocking variable (commonly referred to as repeated measures, or within-subject design), “the order of presentation of treatment levels should be randomized independently for each experimental unit” (Kirk, 1995, p. 254). Thus, as suggested in the name, randomization of presentation orders satisfies the assumptions of the experimental design. Endsley’s critique of the counterbalancing by randomization in our study is therefore feeble. We concede that it would have been a good practice to use sophisticated incomplete counterbalancing methods (e.g., Latin square or Graeco-Latin square counterbalancing) to control residual order effects, but these techniques have their own methodological compromises and costs (see Skraaning, 2003, pp. 37–44).
Other relevant factors
In a third attack, Endsley (2024) points out that, “There are several other factors that also could have contributed the lack of an LOA performance effect in the Jamieson and Skraaning study” (p. 4). We agree that DOA effects might be moderated by an array of factors. The lumberjack model, however, makes universal predictions about the human performance effects of increasing automation. Consequently, our critique of the model (Jamieson & Skraaning, 2020a; 2020b) focused on the absence of DOA main effects for experimental studies performed in lifelike experimental settings with convincing ecological validity. Endsley’s speculations about hypothetical interaction mechanisms in those experiments cannot save the lumberjack model. Two paths of redemption are open to its proponents. First, they can provide experimental results that demonstrate the generalizability of its universal predictions in representative test environments. Second, they can modify the model (see Kaber, 2018). Without either of these, Endsley’s conjectures merely serve to illustrate our central point that universal DOA predictions are problematic in complex industrial work settings (Jamieson & Skraaning, 2018).
An ineffectual second offensive
Endsley's (2024) second offensive probes for methodological weaknesses in Jamieson and Skraaning (2020a) to explain the absence of observed DOA effects on task performance, which are predicted by the lumberjack model. She does so by (i) resuming an attack initially launched by Wickens et al. (2020) but evading our earlier response to it (Jamieson & Skraaning, 2020b, pp. 537–538), (ii) portraying a within-subject counterbalancing method that satisfies the assumptions of the experimental design as insufficient, and (iii) invoking factors not included in the lumberjack model. This second offensive falters like the first.
More of the more constructive engagement
Valuing operator opinions
We agree with Loft (2024), and for that matter Wickens et al. (2020), that operator opinions are important. If we trusted those opinions blindly, however, there would be no reason to perform experiments. The lumberjack model makes no predictions about the operators’ perceived collaboration with automation or their perceived out-of-the-loop unfamiliarity, and is therefore not emphasized in our assessment of the model. As Loft suggests, it is still noteworthy that the participants experienced increasing automation of the operating procedures as challenging, but such subjective findings could, for example, be due to unfamiliarity with novel automation, negative attitudes towards automation, or experimenter bias. Hence, these results should be interpreted carefully and not be taken at face value just because they appear to align with the lumberjack model expectations. 14
Bayesian statistics
Loft (2024) advocates for the use of Bayesian statistics to overcome the logical flaws of null hypothesis testing (Cohen, 1994) in seeking to confirm or disprove the lumberjack model. We have some exposure to Bayesian statistical methods from Human Reliability Analysis (see, e.g., Groth et al., 2014). Although Bayesian methods present a compelling alternative, there is a risk that we substitute one broken method (ibid.) with another. We are specifically concerned that the initial beliefs about the plausibility of hypotheses (i.e., the prior distribution) can be highly subjective and might lead to ambiguous results (Gelman, 2008). A concerted effort might possibly address these concerns.
Conclusion
With three focused critiques of the peer-reviewed findings of Jamieson and Skraaning (2020a) now published in Human Factors and JCEDM, one wonders why this article has attracted such scrutiny. While the realism of our methodological approach is perhaps unfamiliar to many, it falls well within the norms of systematic experimentation in our discipline. And whereas that article has attracted criticism from human factors icons, Skraaning and Jamieson’s (2021) transparency findings arising from the same experimental setting with comparable methods won the Jerome H. Ely Human Factors Article Award. The contrast in reception of these similar works is confusing.
Our objective for responding in detail to Endsley's (2024), Loft's (2024), and Wickens et al.’s (2020) critiques is the same that we adopted for the target article: To increase the ecological validity and industrial representativeness of empirical practice in cognitive engineering. Our experience throughout this dialogue has led us to call for three changes in how we operate as an empirical science. 1. We are seeking greater precision, consistency, and care in the formation and propagation of cognitive engineering constructs, as in the present case for automation failure. For example, we have stated, “A reader of the human factors literature can be forgiven for lacking certainty about whether OOTLUF
15
is a cause of, an effect of, one in the same with, or merely a comorbidity with loss of SA” (Jamieson & Skraaning, 2020b, p. 537). 2. We seek more sober generalization of findings (i) from constrained laboratory experiments to the analysis and design of complex work systems and (ii) across industrial domains. For example, we have asserted that, “Based on the evidence available from experiments conducted in realistically complex work settings… the responsible message from the human factors community to system developers is that there is thus far no reliable pattern of task performance, work-load, or SA consequences attributable to LOA or DOA” (Jamieson & Skraaning, 2020a, p. 527). 3. We seek more equitable scrutiny of empirical findings. For example, we have pointed out that Wickens et al.’s (2020) critique of our SA-measurement methods seems disingenuous, “…given the liberal inclusion of indirect measures of SA in Onnasch et al.’s (2014) meta-study” (Jamieson & Skraaning, 2020b, p. 536).
We hadn’t expected so much of this special issue to be about a paper that we published in Human Factors four years ago. Nor, we expect, did the Editors. However, we conclude with a genuine expression of gratitude to Endsley (2024) for providing the opportunity through her inspired commentary and to the Editors for honoring their commitment to giving us space to respond to the full range of commentaries submitted in response to their broad call.
Epilogue: “Nonsense or not?”
If Woods (2024) were correct, there would have been no point in responding to the other commentaries, as their authors, like us, “…remain stuck in stale frames unable to keep pace with transformative change” (Woods, 2024, p. 1). None of us employ his Fluency Law, Law of Stretched Systems, Robust yet Fragile Theorem, Diversity Enabled Sweet Spots, Theory of Graceful Extensibility, Law of Demands, or Command-Adapt Paradox. Evidently, we are all “then.” Woods (2024) is “now.”
Pieces like Woods' (2024) commentary remind us of another story about Wolfgang Pauli. In an extended argument with Lev Landau, a prominent Russian physicist, Pauli retorted, “What you said was so confused that one could not tell whether it was nonsense or not” (Cropper, 2004, p. 257). Likewise, we cannot tell whether Woods (2024) is serving up anything more than a word salad.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Funding for this work was provided by the Institute for Energy Technology, OECD Halden Reactor Project, and the Natural Science and Engineering Research Council of Canada.