
Abstract
Affinity propagation (AP) clustering is a well-known effective clustering algorithm that outperforms other traditional clustering algorithms. However, the quality of clustering results depends considerably on related sensitive parameters (i.e., preferences and the damping factor). Thus, a feasible procedure based on golden section (GS) and the genetic algorithm (GA) is proposed. This procedure, called the “GS/GA-AP” algorithm, can perform proper global shared preference detection, including identifying a suitable number of clusters. A global shared preference is provided using the GS value between the minimum and maximum of similarities for AP as a default option, and the unsatisfactory clustering result becomes robust when the parameter with GA is selected. Finally, satisfactory experiments using one simulation data set and eight benchmark data sets are performed to verify the effectiveness of the proposed algorithm. The results indicate that GS/GA-AP clearly outperforms the original AP clustering algorithm.
1. Introduction
The implementation of knowledge mining in a massive scale data set generated or captured by sensors, smartphones, or other monitoring devices has been a provocative challenge in recent years, and techniques to address this challenge have been emerging continuously. Supervised learning techniques, such as classification, regression, and semantic web construction [1, 2], are effective in classifying, regressing, and extracting events and interval links from a large scale data set [3, 4], particularly from certain heterogeneous data sets, but may be inappropriate for at processing data set without prior knowledge. Therefore the unsupervised learning techniques, such as clustering [5], are unsuitable for extracting inner-connection within the data set and in accumulating prior knowledge for further processing.
Cluster analysis (or clustering) is the process of separating a set of abstract or physical objects into several classes of similar objects [6]. A cluster is a subset of the original object set, in which the objects are similar to one another and dissimilar to the objects in other clusters. Elementary cluster analysis methods are classified into four categories, namely, partitioning, hierarchical, density-based, and grid-based methods [6].
A partitioning approach is a process of separating an object set into several clusters, each of which contains at least one object. A hierarchical approach captures several hierarchical decompositions of an object set and consists of agglomerative and divisive methods that follow the bottom-to-top or top-to-bottom decomposition directions. The main idea of density-based approaches is to continue the growth of given clusters as long as the density of data points in the neighborhood exceeds the given threshold. A grid-based approach formulates a grid structure, which quantizes the object space into a finite number of cells, and cluster operations work on the grid structure. Numerous traditional and classical methods have been widely used in various computer science fields, and novel methods have been continuously emerging from research institutes and engineering projects.
Cluster analysis helps determine an appropriate or meaningful data partition on a given scientific data set and identify an exemplar configuration that exemplifies the data points; it aims to solve a fundamental problem in machine learning, that is, how each data point is characterized by the cluster or exemplar to which it belongs. The contribution of the aforementioned elementary clustering methods and other clustering methods, such as gene clustering [7], is focused on detecting an appropriate configuration, in which the enhanced updating rules or the selected parameters are customized or provided by experiments. These upgraded methods have been widely used in many computer science areas, such as artificial intelligence, pattern recognition, and gene sequencing [8, 9].
As a novel clustering method, affinity propagation (AP), which was devised by Frey and Dueck and published in Science in 2007 [10, 11], aims to identify an appropriate exemplar configuration and clustering assignments of data points in finite rounds of iterative calculation for responsibilities and availabilities, and the obtained square error of the clustering result of AP is considerably less than that of k-means. AP performs efficiently in many computer science and interdisciplinary fields, such as in clustering face images, detecting genes, and identifying key sentences and air-travel routes [10]; it has attracted the attention of researchers because of its excellent performance in recent years.
The genetic algorithm (GA) [13] tends to find a solution for combinatorial optimisation issues in the solution space. GA, which is derived from biological evolution in the natural environment that occurs over thousands of years, creates a simulation of solution evolution and elimination, in which a series of encoded candidate solutions is updated and an appropriate solution emerges after finite rounds of reproduction-crossover-mutation cycle. Despite its local optimum shortcoming, GA is popular and widely used because of its heuristic search function, rapid convergence, easy parallel implementation, and effective solution. GA has been developed well because of its effectiveness and contribution to the transition periods of many research areas.
AP is sensitive to its related parameters, namely, the damping factor, and preferences, which affect the numbers of iterations and clusters. The damping factor, which is represented by λ, is a common approach for controlling convergence and stabilizing the assignment of data points. A high damping factor restrains the updating of responsibilities and availabilities in the iterative calculation, whereas a low damping factor helps prevent the defective exemplar configuration and clustering assignments of data points. The damping factor is always specified as
Preferences are the control knobs that govern the cluster number, which is the required confidence level for data points to become definite exemplars that exemplify clusters. To become an exemplar, a data point is severely penalized and has to surrender to another candidate exemplar if a smaller preference value is assigned to it, thereby leading to a smaller cluster number in the clustering process. By contrast, more clusters can be gathered if each data point maintains a high preference value; thus, the data points are more confident in dominating clusters, which may lead to a situation in which numerous scraps of subsets exist in a disordered collection.
Each data point can be endued with its own preference value and has its own unique confidence level to dominate a cluster. All the preferences of data points can be set with the same value without prior knowledge, thereby providing all the points with equal opportunities to become an exemplar. In general, preferences can remain constant in the iterative calculation process when AP is running to achieve stable exemplar configuration, and breaking away from a wrong exemplar configuration is achieved via the dynamic adjustment of preferences. Thus, all the preferences commonly share the same value that remains unchanged during the entire clustering process for convenient preferences selection, which is called “global shared preference” [12]. We focus on selecting a global shared preference, and thus, the singular form “preference” is regarded as a synonym of “global shared preference” for simplicity, whereas the plural form “preferences” without the modifiers “global shared” exemplifies the vector constructed by the unique preference of each data point in this study if not mentioned specifically.
The quality of the AP clustering result can be upgraded by formulating the selection of the global shared preference. The enhanced result contributes to determining an improved inner-connection and accumulating prior knowledge within the original data set, which has motivated us to explore cluster number and AP quality dominated by preference and to design a feasible method for the proper preference selection. We propose a feasible procedure called “GS/GA-AP” algorithm for the proper detection of a global shared preference in this study. In GS-AP phase, preference is provided using the GS value between the minimum and maximum of similarities for AP, and a fitness function oversees the quality of the clustering result. If the clustering result is unsatisfactory compared with the original AP using the median as preference, we use GA to detect the proper preference for AP, and the proper preference and clustering results can be detected automatically.
The rest of this paper is organized as follows. Section 2 introduces recent research regarding AP, the preference selection for AP, and GA. Section 3 presents the common AP clustering algorithm, the origin of GS, and the fundamental GA. Section 4 describes the GS/GA-AP algorithm. Section 5 provides a brief explanation of the effectiveness of GS/GA-AP. Section 6 presents the evaluation experiments and the results of the original AP and GS/GA-AP algorithms, and Section 7 concludes the study.
2. Related Work
Some previous work had been already presented before Frey and Dueck published AP in Science in 2007. A prototype of AP using continuous sum-product probabilistic model was described in [14] by Frey and Dueck in 2006, which demonstrated the effectiveness of the prototype of AP algorithm on problems of clustering image patches for image segmentation and learning mixtures of gene expression models from microarray data. Dueck and Frey [15] applied a translation-invariant nonmetric similarity to AP in 2007, which achieved a much lower reconstruction error and classification error rate in Olivetti face data set. In 2008, Dueck et al. [16] modified AP and applied it to a subset selection of yeast genes that act as a drug-response footprint and a subset clustering of vaccine sequences that provided maximum epitope coverage for an HIV genome population. It is declared and demonstrated that AP performs well and was widely used in [10, 14–16].
Other researching successors start to improve the algorithm. An improvement of AP via a novel much simpler model [17] was presented by Givoni and Frey in 2009, which was based on a quite different graph model allowing easier derivations of message updating process for extensions and modifications. In 2010, Zhang et al. [18] proposed an algorithm called K-AP to exploit the immediate results of K clusters by introducing a constraint in the message passing process. In the same year, Tang et al. [19] designed PoissonAPS incorporating AP and Poisson to overcome the limitations of AP and automatically cluster SAGE data without user-specified parameters.
In 2012, Givoni et al. [20] extended AP in a principled way to solve the hierarchical clustering problem that was applied in a number of domains such as biology. In 2013, Wang et al. [21] proposed multiexemplar AP algorithm to provide a solution to multitopic and multiexemplar clustering problem, which was a great improvement for AP clustering algorithm. References [17–19] focus on accelerating the convergence speed of AP or applying AP to a hierarchical situation and [20, 21] serve interdisciplinary research, all of which propose the improvement of AP for clustering more properly or being used extensively.
Several papers concerning preferences selection in AP have been published. Wang et al. [22] presented an adaptive preferences selection method based on gradient descent to obtain the suitable clustering result. In 2010, He et al. [23] proposed another adaptive selection method that found out the range of preferences and then searched an appropriate value in the space of preferences to cluster. And in 2012, Su et al. [24] proposed an adaptive AP algorithm for semisupervised hyperspectral band selection and used bisection method to address preferences selection. In 2014, Chen et al. [25] proposed a new approach based on stability, using NMI measurement to calculate the stability of AP. References [22–25] use adaptive methods to detect preferences by gradient descent, searching in the preferences range or bisection method, all of which give feasible preferences to cluster instead of the optimal ones. In fact, people are more satisfied with the optimal clustering result induced by the optimal preferences, which inspires us to build up our model drawn on the experience of [26, 27].
Some papers provided solutions of preferences detection combining AP and optimization algorithms in recent years. Wang et al. [28, 29] applied particle swarm optimization (PSO) algorithm to find the optimal preferences for AP and clustering solution. Zhong et al. [30] also proposed an approach that utilized PSO to detect the optimal preferences and the optimal cluster number in AP. You et al. [31] presented a similar approach to find the preferences. It is obvious that [28–31] have been designed to detect the optimal clustering results, giving inspiration to other researches. So we propose GS/GA-AP to reduce the time complexity at a certain probability and solve the problem on the optimal preference choice.
Proposed by Holland [13] in 1975, genetic algorithm (GA) is a simulation for the survival and evolution process of the creatures in the natural environment. Individuals, who are more appropriately living in the specified environment, have more opportunities to survive, reproduce, and evolve themselves, and others have no choices but are eliminated in several iterative calculation before the algorithm is terminated. Recently GA has been widely used in searching an optimal or feasible solution in NP-hard combinatorial optimization problems, such as dealing with time dependent demand and variable holding cost in a soft computing optimization based on two warehouse inventory models [32], motif discovering in molecular biology research [33], joint tactical air requests [34], describing the linear relationships to bicluster [35], and data clustering [36, 37].
Parallel genetic algorithm (PGA) has been derived from the original GA due to the parallelization property [38] of GA, which demonstrated that GA had possibility to process the large scale data. An effective PGA model was presented in [39], which could automatically parallelize GA as a feasible implementation. Under numerous research for parallelization, PGA combining MapReduce [40] was extensively applied in paralleling computing for big data [41] and automatic generation of test suites [42].
3. Background
3.1. Affinity Propagation
Affinity propagation (AP) [10–12] is a clustering algorithm using max-sum (sum-product) belief propagation in factor graph [43] to identify an appropriate exemplar configuration for the data set. Given a data set

The algorithm aims at identifying the exemplar configuration to maximise the similarity function


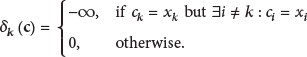
Here,
The function

Max-sum algorithm is applied in the iterative calculating process in order to recognise an appropriate exemplar configuration. There are two kinds of message passing via edges on the factor graph in this algorithm: one is called
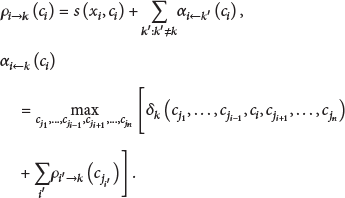
The exemplar configuration and data point assignments are identified when an iterative calculation for


Then
At last, the exemplar labels

The details of AP are described in Algorithm 1.
p: The global shared reference. λ : The damping factor.
(1) AP.Initial( (2) (3) (4) (5) (6) (7) (8) (9) Responsibility (10) Responsibility matrix (11) Availability (12) Availability matrix (13) Iteration number (14) (15) update (16) (17) update (18) (19) (20) (21) (22) (23) Exemplar labels (24) Calculating
Algorithm 1: AP clustering algorithm (AP) [10, 12].
3.2. Golden Section
Golden section, also known as golden ratio, comes from the partition of a line segment. If a line segment is one unit long, the line segment is divided into two unequal parts, where the shorter one is

Since x should not be zero, the equation is converted to the following without the denominator:

The positive root of equation
3.3. Genetic Algorithm
Genetic algorithm (GA) is an intelligent optimization algorithm, the original theoretical foundation of which was proposed by Holland [13] in 1975. GA maintains and reproduces these individuals that are fitter for the environment and eliminates those that are less fit during the whole procedure. Because of the reproduction of superior individuals, these acceptable genes of superior individuals could be inherited by the next generation, which guarantees the whole population to evolve, and are more adaptive to the environment set by GA.
GA algorithm starts by producing initial population of individuals randomly as possible solutions. Each individual should be encoded into a binary string or a real number as a chromosome. A fitness function is specified to calculate the fitness of each individual, and the value of fitness for each individual determines its survival probability: the greater the value of fitness is, the larger the probability is that it can survive and reproduce the next generation. GA uses three phases to search the optimal or satisfactory solution: reproduction, crossover, and mutation. In the reproduction phase, the value of fitness for each individual is calculated, and each individual reproduces the next generation according to its fitness. In the crossover phase, each two individuals surviving exchange their fragments of genes to generate new species. In the mutation phase, each individual has a small probability to alter their genes by changing their preexisting gene to allele one. The reproduction-crossover-mutation cycle is repeated until a stable or satisfactory solution emerges, which is defined as basic steps of a simple GA. The description of GA [13] is shown in Algorithm 2.
F: Fitness function for GA.
(1) GA.Initial(F, (2) (3) (4) Iteration number (5) (6) (7) (8) for all (9) (10) (11) (12) Output the
Algorithm 2: Genetic algorithm (GA) [13].
4. GS/GA-AP Algorithm
We describe GS/GA-AP algorithm in this section. The fitness function for GA is presented in Section 4.1, which is employed to evaluate the fitness and satisfaction of clustering results led by median preference, golden section preference, and the preference from GA. We further give the details and description of GS/GA-AP algorithm in Section 4.2, where how the golden section preference, the preference from GA, and the proper exemplar configuration are generated is explained.
4.1. Fitness Function
Several relative validity indices can be used to evaluate the effectiveness of clustering results, such as variance ratio criterion (VRC), Dais-Bouldin (DB) index, and silhouette coefficient [44]. Silhouette coefficient [45] is a common index which reflects the compactness within a cluster and the separation between clusters simultaneously; it synthetically evaluates the quality of the clustering algorithm by taking the compactness and separation into consideration. Therefore, we select silhouette coefficient as the fitness function for GA in GS/GA-AP.
Suppose a given data set:
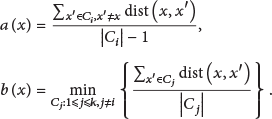

The value of silhouette coefficient is from −1 to 1.
In order to evaluate the quality of clustering, it is necessary to calculate the average of silhouette coefficient of each data points in the given data set, and the average exhibits the quality of the clustering result. According to the property of silhouette coefficient, it is chosen as the fitness function of GA.
4.2. Description of GS/GA-AP Algorithm
GS/GA-AP algorithm is a feasible procedure we propose to detect the proper global shared preference and the exemplar configuration, in order to deal with dissatisfaction caused by the median of similarity as the preference. GS/GA-AP includes two parts, GS-AP and GA-AP. Median of similarity and golden section preference are selected as the original input parameters for the original AP clustering algorithm, and the fitness of clustering results is evaluated under the monitoring of the given fitness function. The algorithm is terminated if the selection of golden section preference has improved the clustering result up to an acceptable evaluation index and the result is a feasible solution, which is named GS-AP procedure. Otherwise the preference and clustering solution are given by a negative feedback learning process that AP takes preference trained in finite GA rounds of reproducing-crossover-mutating cycle, and the evaluation of clustering result determines whether GA is activated to generate a new preference for AP, all of which is named GA-AP procedure.
The algorithm description of GS/GA-AP is in Algorithm 3.
λ : The damping factor. F: The evaluation function and fitness function for GA.
(1) AP.Initial( (2) GA.Initial(F, (3) (4) (5) (6) (7) (8) (9) (10) Output( (11) Algorithm terminated. (12) (13) GA.SearchRange(Min( (14) p (15) (16) (17) (18) (19) (20) p (21) p (22) p (23) (24) (25) Output(p, (26) Algorithm terminated. (27)
Algorithm 3: GS/GA-AP.
5. Explanation for GS/GA-AP Effectiveness
We describe a brief explanation for the effectiveness of GS/GA-AP algorithm detecting the proper preference as a simple proof instead of rigorous one in this section. Section 5.1 restates a perspective association of AP clustering of how a global shared preference governs the cluster number. Section 5.2 gives an interpretation that GS-AP provides a more appropriate preference than median or minimum preference, and GA-AP takes a heuristic advantage of GA to accelerate searching a proper preference for AP.
5.1. Perspective Association between Global Shared Preference and Cluster Numbers
A global shared preference is a control knob in governing cluster numbers, and as a metric of “confidence” representing how each data point becomes a definite exemplar to represent a cluster. A greater preference tends to encourage the candidate exemplars to gather data points for constructing clusters, whereas a smaller preference results in that some candidate exemplars surrender to the clusters and other exemplars dominate. The cluster number is not directly proportional to preference owing to a possibility that the algorithm selects exemplars by the max-sum algorithm in a probabilistic graph model inference, which weakens the numerical precision of messages passing in the model and just focuses on the suitability of each data point being exemplar. A brief illustration has been presented in [12] and we give an intuitive explanation shown in this part. An experiment is designed to verify the possibility which takes a data set downloaded from Frey Lab website [46], and the distribution and meta information of the data set are shown in Figure 2(a) and Table 1.
The meta information of the toy problem data set.


(a) A toy problem data set downloaded from Frey Lab website [46]. (b) The clustering result of toyproblem.
An appropriate clustering result is shown in Figure 2(b) that contains 3 clusters. The exemplars are marked with unique colours and the data points are linked to their exemplars with the same colour. The original data distribution and the appropriate clustering result shown in intuitive Figures 2(a) and 2(b) are treated as a standard benchmark to test the effectiveness of original AP and GS/GA-AP.
AP runs on the standard benchmark data set that takes as input a range of global shared preferences from −100 to −0.1 and minus Euclidean distance as similarity metric, and then a line chart revealing the association between these preferences and cluster numbers is presented in Figure 3, which illustrates that cluster number is not directly proportional to preference as a linear model. It is found out that a wide range of global shared preferences leads to a steady clustering result with the growth of preference, until greater global shared preferences cause the oscillation and rapid rise of the cluster numbers. There exists a long range of preferences leading to the proper clustering configuration shown in Figure 2(b), containing the minimum of similarities, and a clustering configuration is judged as a valid one if the preference for AP falls into this interval. It is an expert experiment that the minimum of similarities is no more commonly taken than the median for AP as it always leads to less clusters, although it seems minimum is a better choice as preference than the median of similarities, which falls into the oscillation range in this experiment.

A line diagram showing the association between global shared preferences and cluster numbers.
5.2. Effectiveness of GS/GA-AP
A novel choice of preference is proposed in this study where the golden section value between the maximum and minimum of similarities is taken as input, for the purpose of avoiding the shortcoming of minimum and median of similarities. Taking golden section preference leads to a more appropriate cluster number than the minimum, which ties up the whole data set and the median that has a possibility to separate a data set into scraps, since the golden section preference falls between the minimum and the median, which is shown in Figure 4.

A line diagram showing the association between global shared preferences and cluster numbers, where the golden section preference is marked.
The cluster number is
Silhouette coefficient affected by the cluster number reflects the quality of clusters, a line chart of which is shown in Figure 5. The line chart exhibits a similar fact that AP with golden section preference obtains a no worse quality of clusters compared to the common minimum or median of similarities, according to the reason that the silhouette coefficient is
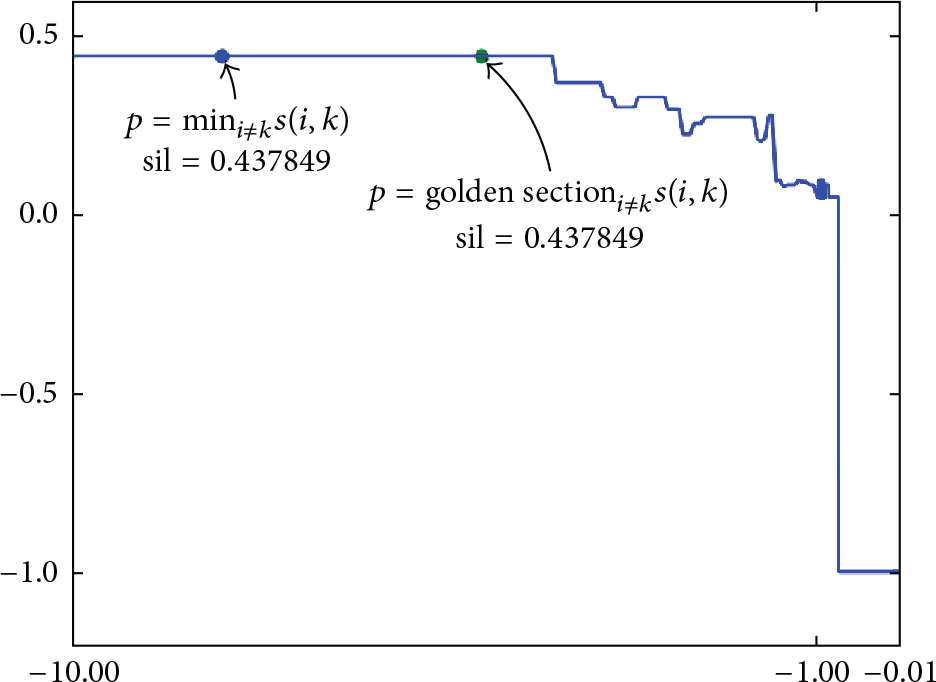
A line diagram showing the association between global shared preferences and silhouette coefficients, where the golden section point is marked using a green point.
GA searches in the interval of minimum and maximum of similarities as the preference space, and it returns a proper preference for the clustering result according to its silhouette coefficient value as fitness, so as to optimise the data point assignments for AP. GA always chooses the proper preference in spite of the negligible local optima, and its heuristic property guarantees the efficiency where the searching process is not too slow to tolerate. Figure 6 shows GA-based preference leads to an appropriate data points assignment, which is another evidence illustrating the effectiveness of GA-AP.
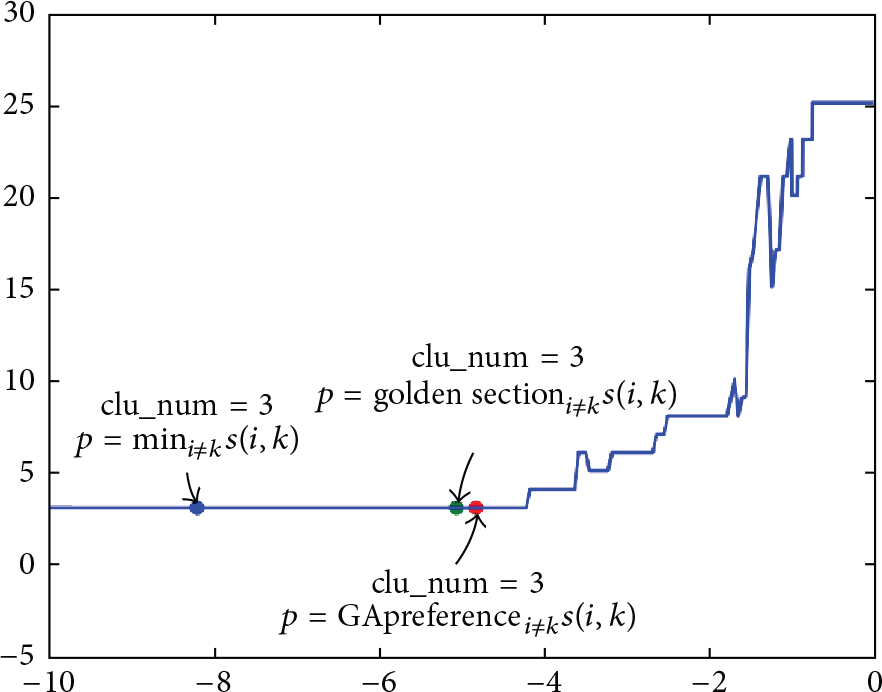
A line diagram showing the association between global shared preferences and cluster numbers, where the golden section preference and GA-based preference are marked using green and red points.
The silhouette coefficient line chart is shown in Figure 7 where the golden section preference and the proper GA-based preference are marked using green and red points. These two silhouette coefficient values are not smaller than the minimum preference, which means taking GA-based preference is capable of obtaining the proper clustering result.

A line diagram showing the association between global shared preferences and silhouette coefficient, where the golden section preference and GA-based preference are marked using green and red points.
An interesting phenomenon seems to be figured out where the proper GA-based preference is much closer to the golden section preference than the minimum of similarities, and a little greater than the golden section one. A speculation for the phenomenon is given in which GA-based preference appears between GS and median of similarities, and it leads to a fitter balance of compactness and separation of the clustering result than the suboptimal one of the GS. The location of GA-based proper preference closing to golden section preference is not a coincidence but it supports that golden section preference is getting close to the proper one, and Figures 6 and 7 give interpretations of the validation of GA-AP, all of which could be treated as evidences for the effectiveness of GS/GA-AP.
6. Experiments and Results
Implemented program instances of GS/GA-AP are created using scikit-learn [47] machine learning toolkit, an open-source machine learning package implemented by Python, and Pyevolve [48], a Python genetic algorithm framework. Comparison experiments validate the effectiveness of GS/GA-AP, in which a testing data set is randomly generated and standard benchmark data sets come from UCI machine learning repository [49]. We replace some cumbersome expressions for brief with their abbreviations and acronyms presented here: the original AP with the median of similarity as default preference is represented by “original AP,” while AP with the golden section preference value and AP optimised by GA are denoted by GS-AP and GA-AP unless mentioned specifically. Some key default parameters for AP and GA are listed here: the similarity measurement in the experiment is the minus squared Euclidean distance, and the assignment of damping factor is
6.1. Randomly Generated Data Set Test
A two-dimensional random data set containing two hundred data points is generated by function make_blobs from scikit-learn [47]. The function make_blobs is assigned with

(a) Test data set. (b) The clustering result of original AP. (c) The clustering result of GS-AP. (d) The clustering result of GA-AP.
The cluster numbers of original AP, GS-AP, and GA-AP are
Table 2 shows the cluster numbers (Cluster_number) and silhouette coefficients (Silhouette_coefficient) which further verify the effectiveness of these two algorithms. Silhouette coefficient reflects the compactness within one cluster and separation among clusters, as an inner index to evaluate the quality of clustering result. The cluster number indicates the exact distribution of data points as an external property. GA-AP exceeds GS-AP and original AP in the average silhouette coefficient that approaches the proper value in theory, the cluster number reaches the actual number of original clusters as well, all of which validate the effectiveness of GS/GA-AP.
The experiment result of AP and GS/GA-AP.

6.2. Standard Benchmark Data Set Test
Another testing experiment is designed to evaluate GS/GA-AP algorithm on eight real-world data sets from UCI machine learning repository [49] as the standard benchmark data sets, which offers evidences to validate the superior proper performance and effectiveness. The data set names (Data sets), instance numbers (#Instances), feature numbers (#Features), and cluster numbers of these data sets (#Clusters) are shown in Table 3 after data preprocessing such as filling missing values, normalizing, and calculating minus squared Euclidean data sets.
Information of standard benchmark dat aset from UCI.

Table 3 shows the meta information of these data sets as standard references. The actual cluster number reflects the inner distribution and connection between data points, as a vital reference to evaluate the original AP and GS/GA-AP algorithm. The time complexity of clustering and similarity calculation influenced by the instance numbers and feature numbers are not involved in the discussion of this study. Noting that the data set “ionosphere” was collected by the system in Goose Bay, Labrador, the experiment conducted on it might reveal the effectiveness in sensor using.
Implemented program instances of GS/GA-AP and original AP are initialized by the default aforementioned parameters. The experiment results of GS-AP, GA-AP, and original AP are shown in Table 4, respectively, including the global shared preferences (p), cluster numbers (#clu), and silhouette coefficients (Sil).
The result of original AP, GS-AP and GA-AP clustering.
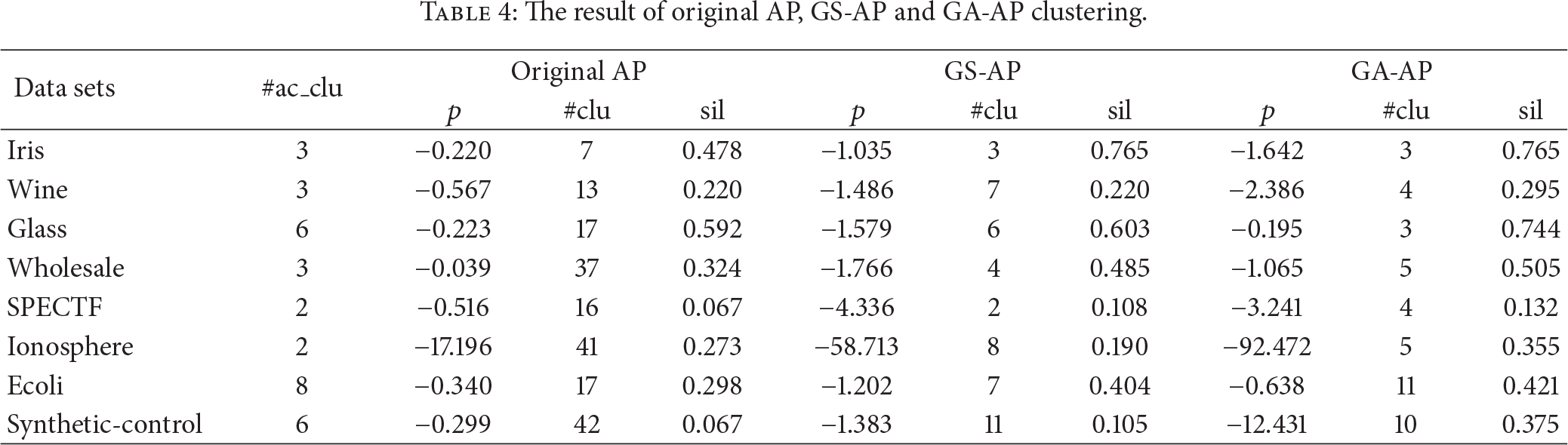
Global shared preferences (p), cluster numbers (#clu), silhouette coefficients (sil) among original AP, GS-AP, and GA-AP, and the actual cluster numbers of all data sets (#ac_clu) are shown in Table 4. It is observed that GS-AP and GA-AP outperform the original AP in each evaluation reference, and the proper global shared preferences appear as the golden section value of the similarity interval or smaller one, which are capable of demonstrating the effectiveness of GS/GA-AP. The chart for cluster numbers and silhouette coefficients is displayed in Figures 9 and 10 by Highcharts [51] to further analyse the clustering phenomenon by original AP and GS/GA-AP.

The cluster number in standard benchmark data sets.

Silhouette coefficient.
The actual cluster numbers can possibly be treated as references representing the real distribution of data points among the original data sets, although some data sets are much fitter for training and classification rather than being clustered. Clustering algorithms may identify different distribution and divide data sets in a distinctive way, and this is why the actual cluster numbers are regarded as references rather than evaluation index in the experiment. The precise mapping relationship between preference and cluster number for original AP has already been presented in Section 5, where we explain why the algorithm author just gave a simple intuition [12] and chose the median as the default choice [10]. Actually the unstable phenomenon of cluster numbers has been found in [12] where a greater preference value may cause the oscillation of cluster number and more scraps of subsets. The preference value from GS-AP is smaller than the median of similarity substantially and helps control the scrap generating in effect. The GA-AP with GA optimization succeeds in finding the proper preference for AP and approaches the most appropriate solution of clustering, which is robust with the default input. GS/GA-AP outperforms the original AP under the evaluation of cluster numbers.
Silhouette coefficient reflects the compactness within a cluster and the separation between different clusters and evaluates the quality of the clustering algorithm by taking the compactness and separation into consideration synthetically according to its definition. GA-AP always tends to discover an appropriate separation for maximising the silhouette coefficient, while GS-AP is not good at it, owing to some lower silhouette coefficients than the original AP. The data sets are associated with the improvement of silhouette coefficient where higher improvement comes from high silhouette coefficient of the original AP as opposed to the lower ones, for all these AP-based algorithms perform well on the same data sets. It is indicated that GS/GA-AP acquires the great improvement compared to the original AP and improves the clustering results. Three results of eight data sets have improved to satisfactory evaluation index and the results are feasible solution via GS-AP, so GS/GA-AP could save time at a certain probability.
7. Conclusion
We propose a new feasible procedure called GS/GA-AP algorithm, which uses the GS value as a replacement of the default median preference and then deploys genetic algorithm to detect a proper preference for the appropriate cluster solution, if the cluster configuration generated by the GS value is not a satisfactory clustering solution. The original AP and GS/GA-AP algorithms are, respectively, executed on a simulation data set and eight standard benchmark data sets in order to evaluate the effectiveness of GS/GA-AP compared with the original AP. The experiment results reveal a notable phenomenon that GS/GA-AP substantially captures more proper and effective cluster configurations compared with the original AP on the nine data sets, which means GS/GA-AP improves the original AP clustering algorithm heuristically.
We devise GS/GA-AP algorithm that concentrates on the offline data processing as it separates the data set into several clusters autonomously, discovers the inner-connection among the data set in which the data points are similar within a cluster while dissimilar between clusters, and characterizes each data point with its exemplar, so the clustering result reflects more knowledge for further processing. AP takes into account the global similarity optimization to identify the exemplar configuration, and the golden section preference is given as a replacement of the default median preference to enhance the clustering result; GA further conducts a heuristic research of preference for AP to cluster properly if the clustering result induced by golden section preference is not satisfactory or promoted evidently, all of which lead to more proper clustering result than the original AP clustering algorithm.
However, a left complicated problem is the runtime of GS/GA-AP which have not been discussed, since the time complexity of the original AP is
Footnotes
Competing Interests
The authors declare that they have no competing interests.
Acknowledgments
This research is sponsored by National Natural Science Foundation of China (nos. 61171014, 61371185, 61401029, 61472044, 61472403, and 61571049), the Fundamental Research Funds for the Central Universities (nos. 2014KJJCB32, 2013NT57), China Postdoctoral Science Foundation (2016M591109), and the BNU Graduate Students' Platform for Innovation & Entrepreneurship Training Program (no. 1601121E1) and by SRF for ROCS, SEM.