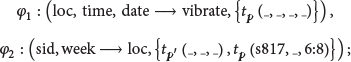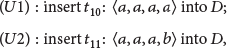Cyberphysical systems (CPSs) have been widely applied in a variety of applications to collect data, while data is often dirty in reality. We pay attention to the way of evaluating data inconsistency which is a major concern for evaluating quality of data and its source. This paper is the first study on data inconsistency evaluation problem for CPS based on conditional functional dependencies. Given a database instance D including n tuples and a CFD set including r CFDs, data inconsistency is defined as the ratio of the size of minimum culprit in D, where a culprit is a set of tuples leading to integrity errors. Firstly, we give a sufficient analysis on the complexity and inapproximability of minimum culprit problem. Then, we provide a practical algorithm that gives a 2-approximation of the data dirtiness in time based on independent residual subgraph. To deal with the large dynamic data, we provide a compact structure based on B-tree for storing independent residual subgraph in order to update inconsistency efficiently. At last, we test our algorithm on both synthetic and real-life datasets; the experiment results show the scalability of our algorithm and the quality of the evaluation result.
1. Introduction
Cyberphysical Systems (CPSs) have been widely applied in a variety of applications to collect data, such as temperature, heart rate, and speed, from the physical world and make decisions based on the analysis of the data, thereby controlling and optimizing the physical objects in the real world, and they have a great influence on the way we observe and change the world [1]. CPS obtains the information of the physical world through many sensors and impacts the environment by actuators. Data sensed and sampled by sensors usually contains valuable information about the physical world, and its volume is growing. For better understanding and changing the physical environment, data collection and analysis are of the essence [2]. The knowledge extracted from the data also guides the behavior of actuators in CPS; for instance, sensors and actuators cooperate with each other to monitor some area [3] and react when a certain event is detected [4, 5]. Data gathered by sensors will not just be thrown away when they have been transmitted to the processors, but they will also be stored for further analysis. Unfortunately, not all the information gathered by different CPSs is reliable due to hardware and communication limits [6]. Many deployment experiences have shown that low data quality is the most serious problem that impacts CPS performance. Tolle et al. pointed out that faulty data can occur in various unexpected ways and less than 69% of their data could be used for meaningful interpretation [7]. Szewczyk et al. also found that about 30% of data are faulty in their deployment [8]. What makes the situation worse is that the quality of data is not easily judged. It is important to find a way to identify the quality of data gathered by CPSs to estimate the availability of data. Meanwhile, the data quality also reflects the reliability of the system. In this paper, we utilized data inconsistency to measure the data quality and we store all the data in a relational database.
Once these systems get pervasive and ubiquitously available, large amounts of data will be collected. They may include faked information. Such case highlights the quality of the data in the decision-making system and other CPSs; it is crucial for the success of the applications. Without high-quality data, no high-quality service based on the right decision could be provided, for instance, aggregation and routing services [9–15].
1.1. Motivation
In CPSs, data is collected mostly from the physical world. However, data availability would be reduced by faulty data which is not reporting the real value of the monitoring objects. The idea in this paper is that the database techniques of data inconsistency can be utilized to model and manage the data quality for CPS, in order to evaluate data source quality, CPS data quality, and so on. Based on this, we propose the new measurement and technique for its efficient computation.
In database technique, data consistency is one of the most important aspects of data quality; it is usually defined based on integrity constraints. They are semantic conditions that a database should satisfy in order to be an appropriate model of external reality. In practice, a database may not satisfy those integrity constraints, and for that reason it is said to be inconsistent or dirty. As a type of integrity constraint, conditional functional dependency (CFD) [16] has been proposed to capture inconsistency in data, which is a generalization of functional dependency (FD) [17] and has more powerful expressibility than FD. Based on CFD, many works on data quality have appeared; for example, [18–20] focus on inconsistency detection problem, while [21–26] focus on the data repairing problem. Besides inconsistency detection and data repairing, an important problem is data inconsistency evaluation which aims to quantify how dirty the data is.
Traditional evaluation methods for data source are mostly based on statistics. Compared with them, the logical method proposed in this paper is more flexible and fundamental. And the proposed method has a higher capability of expression. To the best of our knowledge, there is no existing work on providing a specific formula quantifying the data inconsistency based on CFD. We now give an example for modeling CPS data using CFDs. Consider the example below.
Example 1.
A CPS group maintains a relation of sensing data for its laboratory for several years:
Each climate monitor tuple contains information about a record t (a unique sensor id , location of sensor loc, time information about data reporting (time, week, and date), temperature, and vibrate). A sampled fragment D from all the data is shown in Table 1.
Two CFDs defined over such sampled data are shown as follows:
intuitively, restrains the notion that the vibrate status of each location is the same at the same time, while specifies that the location of each sensor cannot be changed in the same week; however, for the special one “,” its position cannot be changed no matter the time. According to such two CFDs, D is inconsistent, since there exists violation in them as follows:
Tuple pair are violations with respect to , because they reported different “vibrate” status.
Tuple is a violation with respect to , because “s817” at location “6:8” cannot be changed.
Tuple pairs and are violations with respect to , because “s816” reported different “location” at the same week.
It is easy to see that the size of minimum culprit is because any culprit cannot have less than tuples; for example, subset is a minimum culprit. That is to say, the data we sampled is not very reliable, and, to make it clear, at least 33.3% of the data should be cleaned.
Sampled data.
sid
loc
Time
Week
Date
Temp.
Vibrate
s816
6:8.1
14:10
0079
11-04
48
0
s816
6:8.1
14:10
0079
11-05
24
1
s816
7:4.2
14:10
0079
11-06
22
1
s817
6:8.1
14:10
0079
11-04
24
1
s817
6:8
14:10
0080
11-09
24
0
s817
6:8
14:10
0080
11-10
22
0
Motivated by this, we consider how to efficiently compute this inconsistency measurement when the integrity constraint is conditional functional dependency in this paper. Technically, to the best of our knowledge, there is no existing work considering this aspect. There are some detection techniques [18–20, 27] but they are not able to reveal how dirty the data is directly. For confidence computation [28], our problem generalizes the confidence of a single CFD; actually, this measurement is also the confidence of a set of CFDs. For repairing techniques, our problem can be seen as a special case of [29], because the complementary minimum culprit can be seen as C-repair (cardinality repair) of an inconsistent database; however, it is much more expensive using the techniques proposed by [29] directly, especially for dynamic data, and the algorithm given in this paper is more efficient and seems optimal. Briefly, there are three challenges. The first challenge is how to evaluate the inconsistency efficiently. It is proved that the inconsistency evaluation problem we study is NP-complete even if there are only two CFDs in rule set and there are only three attributes in relation schema. Therefore, we should provide an efficient approximation algorithm for evaluating the data inconsistency. Because most existing repair algorithms that could perform repair encounter a huge searching space when data is large and they have to take an expensive cost on performance, the approximation algorithm is also expected to be more efficient than the C-repair algorithms and to be able to guarantee the approximation ratio and evaluate large data more than data in memory. For the dynamic data, an external memory data structure is necessary to make the approximation algorithm able to deal with the update of tuples efficiently rather than recomputing the inconsistency from scratch.
1.2. Contributions
This paper first studies how to compute the data inconsistency for CPS data efficiently with respect to CFDs; the main contributions in this paper are as follows:
We formally define the inconsistency evaluation problem. The inconsistency of a given database instance D is defined based on minimum culprit, the minimum subset of D, whose complementary value in D is consistent with respect to all the given CFDs, and we use the proportion of minimum culprit to quantize the inconsistency of a database. It is proved that it is monotonic and insensitive to a small change on the database. And we prove that the minimum culprit problem is still NP-complete even if Σ has only two variable CFDs; the relation has only attributes; and the number of violations caused by each tuple is not more than .
Based on the conflict graph model, we transform the inconsistency evaluation problem into the minimum vertex cover problem based on conflict graph model. Based on finding the maximal matching of independent residual subgraph, we give a -approximation algorithm with time complexity where r is the number of given CFDs and always a small constant. To deal with large dynamic data, we design a compact structure for indexing all tuples and give the method for its maintenance. Some useful properties of independent residual subgraph prevent storing edges in the compact structure so that the storage cost of the graph is and the update cost is only .
Using TPCH for large-scale data and IMDB and DBLP for real-life data, we conduct experiments on PC. We find that the adjusted counterpart outperforms the evaluation algorithm if several CFDs are of small confidence while the others are not. In addition, our algorithms scale well with both the size of the data and the number of CFDs.
2. Background
An l-ary relation schema can be represented by , where R is the relation name and all 's () are the attributes of R. Let be , and let be the domain of attribute . An instance D of relation R is a set of l-ary tuples, denoted by , where each tuple belongs to the set . Let be the value of on attribute .
Conditional functional dependency, CFD for short, is a class of integrity constraints capturing the consistency of data, whose formal definition can be found in [24]. Next, the syntax and semantic definitions of CFD will be reviewed briefly.
Syntax. A CFD rule φ defined over relation R is a pair , where X and Y are two distinctive attribute lists satisfying , is a standard FD, and is a pattern tableau over attributes . For each tuple and each attribute , the value can be either a constant “a” in or a wild card “_”. For a rule φ, we use to denote X and to denote Y.
Semantic. Given a tuple t and a pattern tuple , t is said to match , denoted by , if either or = “_” is satisfied for each attribute A. Two tuples and satisfy φ, denoted by , if when , there must be ; if but , then tuple pair is a violation. Particularly, a single tuple , if when , we must have . Given a relational instance D and a CFD rule φ, D is said to satisfy φ (i.e., ) iff, (a) for each tuple , and, (b) for any two tuples and in D, . Given a CFD set Σ, D is consistent with respect to Σ, if it satisfies all rules in set Σ; otherwise, it is inconsistent or dirty, denoted by . For example, in Table 1, tuple pair is a violation with respect to shown in Example 1 (i.e., ) due to the fact that “”, but “ ‘0’ ‘1’”; therefore, D is inconsistent or dirty because of the existence of violation.
A CFD is said to be simple if there is only one row in its pattern tableau such as both CFDs shown in Example 1. Additionally, two special fragments of simple CFD can be defined as follows:
A simple CFD is said to be a variable CFD, if, for each , “_”; for example, is a variable CFD.
A simple CFD is said to be a constant CFD, if, for each , “_”; for example, the second pattern of can be changed into a constant CFD.
Intuitively, a constant CFD can capture inconsistencies on single tuple, while a variable CFD can capture inconsistencies between two tuples.
In fact, given any CFD, it can be rewritten by some simple CFDs naïvely by splitting its tableau horizontally, while a simple CFD can be rewritten by at most a constant one and a variable one. Therefore, without loss of generality, only simple CFDs are used in this paper.
3. Problem Definition
This section first formally defines the data inconsistency evaluation problem and then proves that it is NP-complete.
Given a CFD set Σ and a database instance D such that , intuitively, the dirty part is a subset of D such that the deletion of will make the data clean. We can formalize this idea as follows.
Definition 2 (culprit).
Given a database instance D and a set of CFD rules Σ, culprit is a subset of D satisfying .
Obviously, for fixed Σ and D, there may be many culprits. In this paper, to measure the data dirtiness, we only care about the minimum culprit. is the minimum culprit if, for any culprit , .
Definition 3 (data dirtiness evaluation problem).
Given a database instance D and a set of CFD rules Σ, we want to compute the dirtiness of a database instance D, which is .
Property 1 (minimality).
Given any instance D and any CFD set Σ, is the portion of tuples that need to be edited at least in any exact repair algorithm.
Measurement is also monotonic and insensitive to a small change Δ (i.e., set of tuples) on instance D as the following proposition states.
Property 2 (monotonic and insensitive).
Given an instance D, a set of tuples Δ, and CFD set Σ, we have .
This implies .
Remark 4.
That is to say, the inconsistency of data measured by Definition 2 changes gently with small update. Usually, this trend of variation agrees with the reality; this is really because “(1) most of the data is often correct, especially for large data, and (2) a small update has a tiny impact on the dirtiness of the entire dataset.”
Similar to [30], we next have the following theorem on the complexity of minimum culprit problem with more restricted condition on the input. Here, the decision version of minimum culprit problem, k-culprit problem for short, is that, given a database instance D and a CFD set Σ, it is to decide whether there is a culprit C of D with respect to Σ and the size .
Theorem 5.
Given an instance D of relation R and CFD set Σ, k-culprit problem is NP-complete, even if (1) there are only 2 variable CFDs in Σ, (2) R is a 3-ary relation, and (3) for each tuple there are at most 6 violations including t.
Proof.
NP. There is an NP algorithm as follows: guess a subset C of D with size of k; check whether , that is, to check whether each tuple pair in satisfies all CFDs of Σ; output “” when and “” otherwise. For each instantiation, the checking step can be done in polynomial time. Thus, the problem is in NP.
NP-Hardness. The lower bound is established by a reduction from -SAT problem to k-culprit problem. An instance of -SAT problem includes a set U of n variables and a collection S of m clauses , while, in each clause , each is the qth literal of . Given an instance of -SAT problem, it is to decide whether there is a satisfying truth assignment for S. The -SAT problem is NP-complete, and it remains NP-complete even if, for each , there are at most clauses in S that contain either or .
A polynomial reduction from -SAT to k-culprit problem can be constructed as follows. Given an instance of -SAT, we introduce a 3-ary relation and a variable CFD set Σ including and . Build an instance D over R. For each variable , insert two tuples and into D. For each literal in clause , if it is a positive literal of variable , add tuple to D; if it is a positive literal of variable , add tuple to D. (3) At last, let . Note that the instance D can be constructed in ; there are attributes in R and two variable CFDs in Σ; for each tuple t in T the number of violations caused by t is at most , if each variable exhibits at most clauses.
Suppose that the -SAT instance is satisfiable; that is, there is a satisfying truth assignment for S; then, there is a culprit C of D such that its size is at most . Concretely, it can be computed as follows, for each variable ; if , delete tuple from D. Then, for each clause , if is a positive literal of and , delete from D; if , delete tuple from D. Then, for each clause , if is a negative literal of and , , and , delete from D. We have that, for each i, either or is deleted from D, and, for each j, either of is deleted from D for each j. This is because, in each clause, there is at least one literal that is made by assignment ρ . Therefore, there is a set C of the rest of the tuples such that and .
To see the converse, let C be the culprit such that . CFD restricts the notion that either or should be deleted from D, for each , and at least two tuples of should be deleted from D. That is, the size of C is at least . Therefore is exactly . Moreover, CFD restricts the notion that there is only one literal of each variable in . Then, there is a satisfying truth assignment ρ for S such that, for each ,
4. Evaluation Algorithm
For any database instance D, let be the subset of D where each tuple violates at least one constant CFD in Σ; then, we have
this is because any culprit C of D satisfying must be larger than . Therefore, data dirtiness can be computed as
where can be detected by scanning the database once. Without loss of generality, we do not let Σ contain constant CFD from now on.
Given an instance D and a CFD set Σ with r CFDs, the conflict graph is an undirected graph , where V is the vertex set and E is the edge set. In conflict graph , each vertex refers to the tuple and edge , if , .
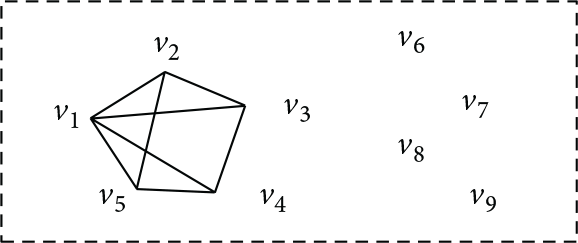
Conflict graphs , , and are shown in Figures 1, 2, and 3. We see that is adjacent to because conflicts with with respect to ; they have the same value on A but different values on B. Obviously, both and are the subgraphs of .
Conflict graph .
, .
, .
There is a naïve -approximate algorithm (Algorithm 1). The minimum culprit can be transformed as the minimum vertex cover on the conflict graph which can be built by the input database and CFDs, and it is easy to see that the size of minimum vertex cover of the conflict graph equals the size of minimum culprit of D. Therefore, a naïve -approximation algorithm (Algorithm 1) will be obtained immediately.
Algorithm 1: Linear algorithm.
Input: Database instance D = , CFD set .
Output: which is the dirtiness of database D w.r.t. .
(1) , ;
(2) for all tuple pair in Ddo
(3) for all such that do
(4) ifthen
(5) add vertices and into V;
(6) add edge into E;
(7) GOTO line (2);
(8) ;
(9) return;
Algorithm 1 works like this: lines (1)–(6): build a conflict graph G for the given database instance D and the CFD set Σ; line (7): compute the minimum vertex cover approximately. One can call the classic approximation algorithm [32] to find maximal matching greedily, where a matching in G is a set of pairwise nonadjacent edges and the matching is maximal if it is not a proper subset of any other matching in G. For any maximal matching M, the amount of vertexes in M (i.e., ) is at most twice as much as the size of minimum vertex cover, a -approximation of .
5. Reduce Quadratic for Large Dynamic Data
We propose another -approximation dirtiness evaluation algorithm DDEva to overcome the shortcomings stated above. Then, an index based on B-tree is designed to enable time and space implementation of DDEva over large data, where r is the number of CFDs given in a general form rather than a simple CFD. It prevents the potential quadratic storage of edges. At last, an update method based on the efficient update of maximal matching and conflict graph is proposed to deal with dynamic data. Generally, the number of general CFDs, r, is a small constant, so that the algorithm we proposed works efficiently as shown in the experiments. We still use simple CFD in order to simplify the description below, but note that our algorithm can process the general CFDs natively.
5.1. Some Notations and Observations
For clarity, we first declare the following notations formally. (A) Given a CFD set Σ, it has r variable CFDs, and the jth CFD is . The conflict graph is denoted by for short. Recall Definition 6; obviously, is a subgraph of . (B) For any matching M, let be the set of all vertices in M. The size of M is denoted by which is the number of edges in it; obviously, . For any graph G, let be the maximal matching of G; (C) given a graph and a matching M, let be a graph , where and is obtained by removing all edges covered by from E; (D) let represent a complete multipartite graph with l vertex equiv-classes, such that any pair of vertices in the same equiv-class ω are nonadjacent while any pair of vertices in different equiv-classes are adjacent. For each equiv-class , let be the number of vertices in it.
Given a CFD set Σ of r variable CFDs, let be the conflict graph . Interestingly, we have the following useful observation of conflict graph with respect to one CFD.
Observation 1.
Each conflict graph is a forest of multipartite graph; that is, it is composed of several nonoverlapping connected components, and each component is a complete multipartite graph.
It is easy to find maximal matching for each complete multipartite connected component in each . However, the sum of each 's maximal matching sizes is not a -approximation of minimum vertex cover due to the overlaps among those matching scenarios. In order to remove these overlaps, we next define a series of independent residual subgraphs for , in which each is a counterpart of the conflict graph .
Definition 8 (independent residual subgraph).
Given a database instance D and CFD set , the independent residual subgraph is a subgraph of , ir-subgraph for short, such that
where .
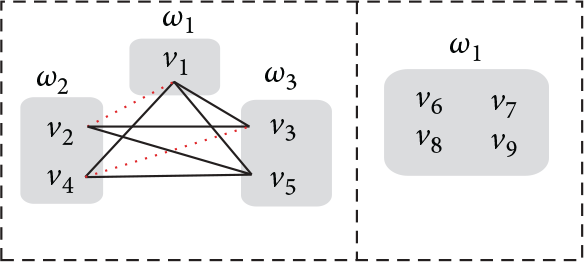
Following Example 7, Figure 4 shows with the dash line, and Figure 5 shows ; is obtained by removing all the vertexes , , , and and their adjacent edges from G since such four vertexes are all in the maximal matching of represented by dash edges.
and .
and .
Observation 2.
Each ir-subgraph is also a forest of complete multipartite graph.
This observation is correct because is still a complete multipartite graph when any vertex v and its adjacent edges are removed from . For example, in Figure 5, is still a forest of complete multipartite graph.
Interestingly, we find that the union of maximal matchings (dash edges in Figure 4) and (dash edges in Figure 5) is exactly a maximal matching of (dash edges in Figure 6). This inspires a proposition for computing the maximal matching of conflict graph as follows.
Maximal matching .
Proposition 9.
is a maximal matching of , and .
5.2. Algorithm for Dirtiness Evaluation
In contrast to the naïve algorithm, we propose Algorithm 2 to compute the data dirtiness in an time rather than the quadratic cost while r is a small constant generally. It works as follows: r ir-subgraphs are built first instead of the conflict graph ; compute maximal matching of each ir-subgraph independently to get the value which is a -approximation of the size of minimum vertex cover. Proposition 9 guarantees the correctness of this algorithm.
Algorithm 2: .
Input: Database instance D, CFD set .
Output: which is the dirtiness of database D with respect to .
(1) ;
(2) for allj such that do
(3) build for D with respect to ;
(4) ;
(5) for alldo
(6) ifthen
(7) remove and its adjacent edges from ;
(8) ;
(9) ;
(10) return;
Briefly, there are two key points to reduce the quadratic cost, respectively; each ir-subgraph can be built within , and the maximal matching of each ir-subgraph can be specified quickly without scanning any edge of it.
5.2.1. Building ir-Subgraphs
Let the jth CFD be ; to get , we will build the conflict graph first and then remove all vertices of and their adjacent edges. Recall Observation 1; each connected component of is a complete multipartite graph which can be built by partitioning without pairwise comparison. Concretely, we can partition all tuples of D according to the attribute values on X and Y; each connected component refers to the tuples with the same attribute value on X, and each equiv-class in the component refers to the tuples with the same attribute value on Y. Because we do not need to store edges in complete multipartite graph, only vertices in need to be removed from . As the size of is always no more than n, it will take at most time cost to check whether a vertex based on a lookup data structure. Therefore, an ir-subgraph can be built within an time.
5.2.2. Finding Maximal Matching Greedily
Due to Observation 2, each connected component of ir-subgraph is also a complete multipartite graph. We can quickly specify an arbitrary maximal matching of each connected component without scanning any edge so that the time cost for computing the maximal matching only depends on the number of vertices rather than edges.
Algorithm 3 is proposed to find a maximal matching quickly. Concretely, the maximal matching of each ir-subgraph can be obtained by the union of the maximal matchings of each component. For each component containing l equiv-classes, namely, , we group the l equiv-classes into two groups . During the scan on , each equiv-class is added to the group with smaller cardinality greedily where cardinality of a group S is , if . Then, for a grouping , we build the maximal matching like this; for each vertex in group L, match it with a vertex of R orderly. The time cost of Algorithm 3 does not depend on the number of edges but only depends on the number of vertexes.
Algorithm 3: .
Input: ir-subgraph Δ .
Output: a maximal matching M (Δ).
(1) ;
(2) for each component do
(3) ;
(4) for alli such that do
(5) ifthen
(6) put into L;
(7) else
(8) put into R;
(9) ;
(10) returnM;
Example 10.
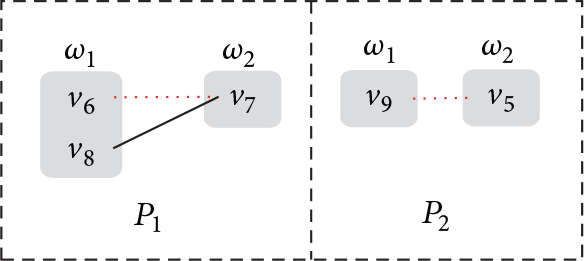
Following Example 7, the grouping of and is shown in Figures 7(a) and 7(b); maximal matchings are represented by dashes. Recall Example 7; there are two components and in the ir-subgraph . In , equiv-class only contains , equiv-class includes and , and equiv-class includes and . Algorithm 3 first adds to group L. Since , then is added to group R by Algorithm 3. At last, is added to group L due to . The maximal matching of is obtained by matching the vertices between L and R one by one. However, in , there is only one equiv-class so that group R is empty; thus, the maximal matching of is an empty set. Therefore, we get a maximal matching for . In a similar way, we find a maximal matching for . Finally, the union of both matchings is exactly a maximal matching of as shown in Figure 6 which is represented by dashes. Obviously, maximal matching finding can be done in an time for each ir-subgraph. Additionally, we have an observation that, in each component , all of the unmatched vertexes belong to one equiv-class () which is called tail class, such as in ; is and is as shown by a dashed rectangle in Figure 7. Obviously, there is at most one tail class in a component.
Computing maximal matching independently.
5.3. Update
According to Definition 8, all the ir-subgraphs are updated based on update of maximal matching. We next show how to maintain the maximal matching, following an efficient ir-subgraph update method.
5.3.1. Update Maximal Matching
Given an ir-subgraph Δ, when a vertex update arises, subroutine will update the grouping of component P that v is involved in. Concretely, suppose that v belongs to some equiv-class ω of P; then, will update grouping upon the following two cases (E1)~(E2):
Vertex Deletion (). Without loss of generality, let . It is obvious that tail class currently; then, grouping needs to be updated, iff (a) and (b) . If (a) and (b) are satisfied, will delete vertex v from ω and switch into R from L; otherwise, it only delete v from ω . And if , the opposite will occur.
Vertex Insertion (). Without loss of generality, let . Grouping needs to be updated, iff (a) and (b) (). If (a) and (b) are satisfied, will insert v into ω and switch ω into R from L; otherwise, it only inserts v from ω . And if , the opposite will occur.
After updating , a new maximal matching can be obtained in greedy order.
Observation 3.
Let M be the maximal matching of component P before grouping update, while is the new maximal matching obtained in greedy order after grouping update. We have that if , there must be one and only one vertex () such that (a) but or (b) but .
5.3.2. Update ir-Subgraph
Algorithm 4 shows how to update the ir-subgraphs. When a tuple update arises, all ir-subgraphs are updated one by one. Specifically, starting from , updates the ir-subgraph according to the parameter “” by calling . For vertex deletion, parameter “” is set as “”; for vertex insertion, it is set as “”; Algorithm 4 ends until r ir-subgraphs have been processed.
Algorithm 4: ().
Input: tuple need to be processed t, operator parameter op.
Output: updated.
(1) for to rdo
(2) , ;
(3) ifandthen
(4) , ;
(5) ifandthen
(6) , ;
This algorithm is correct. Actually, for each , if update v does not result in a change on maximal matching , then there must be v that does not belong to , and it still should be inserted into or deleted from the following ir-subgraphs. If update v results in a change on maximal matching , according to Observation 3, there must be one and only one vertex such that “it was matched but becomes unmatched” or “it was unmatched but becomes matched.” Then, according to the definition of ir-subgraph, should be either inserted into or deleted from the following ir-subgraphs. Therefore, there is also an important observation that each ir-subgraph needs to be processed only once by . In the next section, we organized each ir-subgraph as a compact structure, in which the costs of vertex operations including insertion, deletion, and lookup are . That is, in the processing procedure of each ir-subgraph, (line (2)) and vertex checking (lines (3) and (5)) can be done in . Therefore, at most time cost will be taken to update the r ir-subgraphs.
the grouping updated after each insertion was shown in Figures 8(a) and 8(b).
Example for update processing.
Respectively, we show the procedure of processing and as follows:
In , according to the attribute values on X and Y, vertex belongs to of . In , belongs to L, and vertex does not result in a change on the grouping and is still the tail class since ; however, vertex is not matched any more; intuitively, it is squeezed out from the matching; it should be inserted into . After update on , class has become the tail class of component in .
After insertion of vertex , switches the tail class into R from L since the size of ; however, because has become matched after the switch, then it is deleted from and is matched with in .
5.4. Implementation
In this subsection, a compact structure is given to support the following efficient implementation scenarios: answer the membership query of whether a vertex belongs to the maximal matching in time and update each ir-subgraph and its maximal matching in time once a tuple update arises.
5.4.1. Compact Structure for ir-Subgraph
As shown in Figure 9, we store each ir-subgraph () as the index of database D (with B-tree implementation in this paper). Concretely, given D and variable rule , only indexes those tuples satisfying , ; the index key is of each tuple. In B-tree implementation, (a) each entry in an index node refers to a vertex of ; (b) all the vertices of each equiv-class and all the equiv-classes of each component are, respectively, organized as a double linked list for constant time update once the maximal matching changes. Additionally, two kinds of header entries are settled in the index.
Compact Structure for storing ir-subgraph Δ1.
K-Header. For each component P, a K-header is settled for keeping relative information about the corresponding component as follows:
the attribute value on Y corresponding to the tail class . Actually, each equiv-class in a component will be identified uniquely by the attribute value on Y.
the id of the last matched vertex in . It is exactly less than the ids of all unmatched vertices because all vertices are sorted by id inside each equiv-class. For example, in shown in Figure 7, “3”, while we let “” as there is no vertex matched in component .
it points to the tail of the double linked list of L.
it points to the tail of the double linked list of R.
W-Header. For each equiv-class ω, a W-header is settled for keeping relative information about it as follows:
it points to the tail of the double linked list of ω .
it indicates which group ω belongs to.
5.4.2. Supporting Membership Query
Given a vertex v and ir-subgraph , the membership query of whether it is in the maximal matching will be answered in . Let v refer to the tuple t and find K-header of component P by key value ; then, we have if (a) , which means , and (b) .
5.4.3. Supporting Update on ir-Subgraphs
In the B-tree implementation, it will take only time on average to insert or delete a vertex in an ir-subgraph. Once a tuple update results in a change on a maximal matching, only updates the corresponding K-header and W-header in a constant time after finding both headers in time.
Example 12.
Following Example 10, Figure 9 shows the storage implementation of ir-subgraph for D with respect to . For component , its K-header can be found by key “.” In K-header of , the size of maximal matching of is recorded as with respect to the grouping in Figure 7 where and . The K-header has also recorded “c” for tail class which can be identified uniquely in by value “c” (the attribute value on “B”), while is set as which refers to end vertex . The pointer (resp., ) in K-header points to the W-header of the last class (resp., ) of group L (resp., R). In the index, equiv-classes and (resp., ) in group L (resp., R) are organized as a double linked list by pointers placed in the corresponding W-header. All the vertices inside each class are also organized as a double linked list by pointers placed in the corresponding entry.
Considering the insertion of , will update in the first iteration by implementation as the following three steps.
Step 1 (update the double linked list of vertices in each equiv-class).
Insert as the new tail of the double linked list of ; that is, find the last vertex before insertion of and reset its pointer and then change the last vertex in W-header of as “” which is the id of vertex . Here, the key of the last vertex of can be fetched from W-header of .
Step 2 (update the double linked list of groups L and R).
Because after the insertion of , then need to be switched into R from L. Concretely, delete W-header of from the double linked list of group L (its key is obtained by the value of attributes A and B of , i.e., ). This is implemented by setting the pointer as “” and changing the pointer to point to ; insert a W-header for into the double linked list of group R. This is implemented by setting the pointer to be pointing to and changing the pointer to point to , meanwhile changing as “R.”
Step 3 (update the relative information recorded in K-header).
Since , then remains the tail class of this component, but is updated as because new point matches ; at last, a membership query of whether is matched is necessary to decide how to update the following ir-subgraph in the next iteration of . and can be fetched from the K-header of component ; then, it is checked that and .
It is easy to see that, in each iteration of , such steps can be achieved by querying B-tree index in time and updating the linked list in time. After at most r iterations, the update finishes in time.
6. Optimizations and Extensions
6.1. Key Value Compression
The sort key of each tuple consists of the values on X and Y and tuple id with respect to a CFD (). Reducing the size of the key implies improving the efficiency of finding vertex in the index. However, we can build two prefix-trees, one for X and the other for Y, respectively. Then, we assign each leaf a unique id. Then, each string with arbitrary size will be transformed into an integer; that is, each key value is compressed as a triple of integers. As the size of string of each attribute is not more than a fixed constant, then each prefix-tree has a fixed height; thus, this transformation can be done in a constant time.
6.2. The Number of Indexes
In practice, CFD is always given in a general form and it can be transformed into lots of simple rules. That is, r may be very large and many indexes need to be built; thus, there will be lots of copies of isolated vertexes stored. However, actually, our algorithm can process each CFD with general form natively; this is really because the conflict graph with respect to a general CFD is also a forest of complete multipartite graph. Therefore, only one index needs to be built for one general CFD. In practice, the number of indexes to be built equals the number of the general CFDs.
6.3. Minimum Space Cost
Due to the definition of the ir-subgraph, each ir-subgraph has to store many copies of vertexes which are unmatched in the previous ir-subgraphs. Reducing the size of each index implies the improvement of the efficiency of the index. The size of all the indexes depends on the processing order of r indexes. To reduce the space cost caused by the redundancy, we should choose the best processing order of the CFDs. However, the best order that minimizes the overall space cost cannot be precomputed and it also will change with the update of data. Therefore, we chose the processing order of CFDs as the decreasing order of factor , in which and are the support and confidence of a given CFD ϕ, respectively, and such two values can be obtained by sampling method [28]. Intuitively, in each index, the bigger the ratio is, the more the tuples will be matched as early as possible, so that there may be less tuple copies storing in the indexes of the following ir-subgraphs and the number of queries will be also reduced possibly when building and updating the indexes of all ir-subgraphs.
7. Experiments
We next present an experimental study of data dirtiness evaluation algorithms, measuring elapsed time and the quality of the evaluation result. Using both synthetic data TPC-H and real-life data including DBLP and IMDB, we focus on their scalability by varying the following three parameters: : the size of the original database; : the size of updates; : the number of CFDs.
7.1. Experimental Settings
We used synthetic and real-life data.
7.1.1. Datasets
(a) TPC-H [33]: we built a wider table by joining all the tables. The data ranges from 2 million tuples (i.e., M) to million tuples (i.e., M). Note that the size of M tuples is almost as large as GB. (b) IMDB [34]: we extracted a GB relation from its XML data. The data scales from M tuples to M tuples where the size of M tuples is almost as large as GB. (c) DBLP [35]: we extracted a GB relation from its XML data. The data scales from K tuples to M tuples where the size of M tuples is almost as large as GB.
7.1.2. CFDs
We designed CFDs manually, varied by modifying patterns. (a) TPC-H: the number of variable CFDs ranges from to including FDs with by default. (b) IMDB: scales from to variable CFDs including FDs, with by default. (c) DBLP: scales from to including FDs, with by default.
7.1.3. Updates
Updates contain % insertions and % deletions. The size of updates is up to GB (about M tuples) for TPC-H, up to M tuples for DBLP, and up to M tuples for IMDB.
7.2. Implementation
We denote by DDEva the straightforward implementation of our evaluation algorithms, while adjusted-DDEva refers to the order adjusting method based on sampling. We compare our algorithm with the naïve algorithm. In the implementation of the naïve algorithm, we use the adjacency list to store the conflict graph and build an index for all vertexes based on their ids so that each vertex can be found efficiently. In order to lower the cost of finding all the violations as much as possible, for each CFD , we partition the database into different blocks according to the value of X and check all the tuple pairs for a violation in each block, rather than checking all possible tuple pairs naïvely.
All codes were written in C/C++ and compiled by Visual Studio 2005 and QT4 library. We run our algorithms on Windows 7 platform on Dell PC OptiPlex 790 with 3.10 GHz Intel Core i5 CPU, 4 GB memory, and hard disk of 5400 rpm. In the following, the algorithms are run five times under each setting and the average time is taken. In each run, we use large amount of random data to wipe I/O cache.
7.3. Experimental Results for Evaluation Algorithm
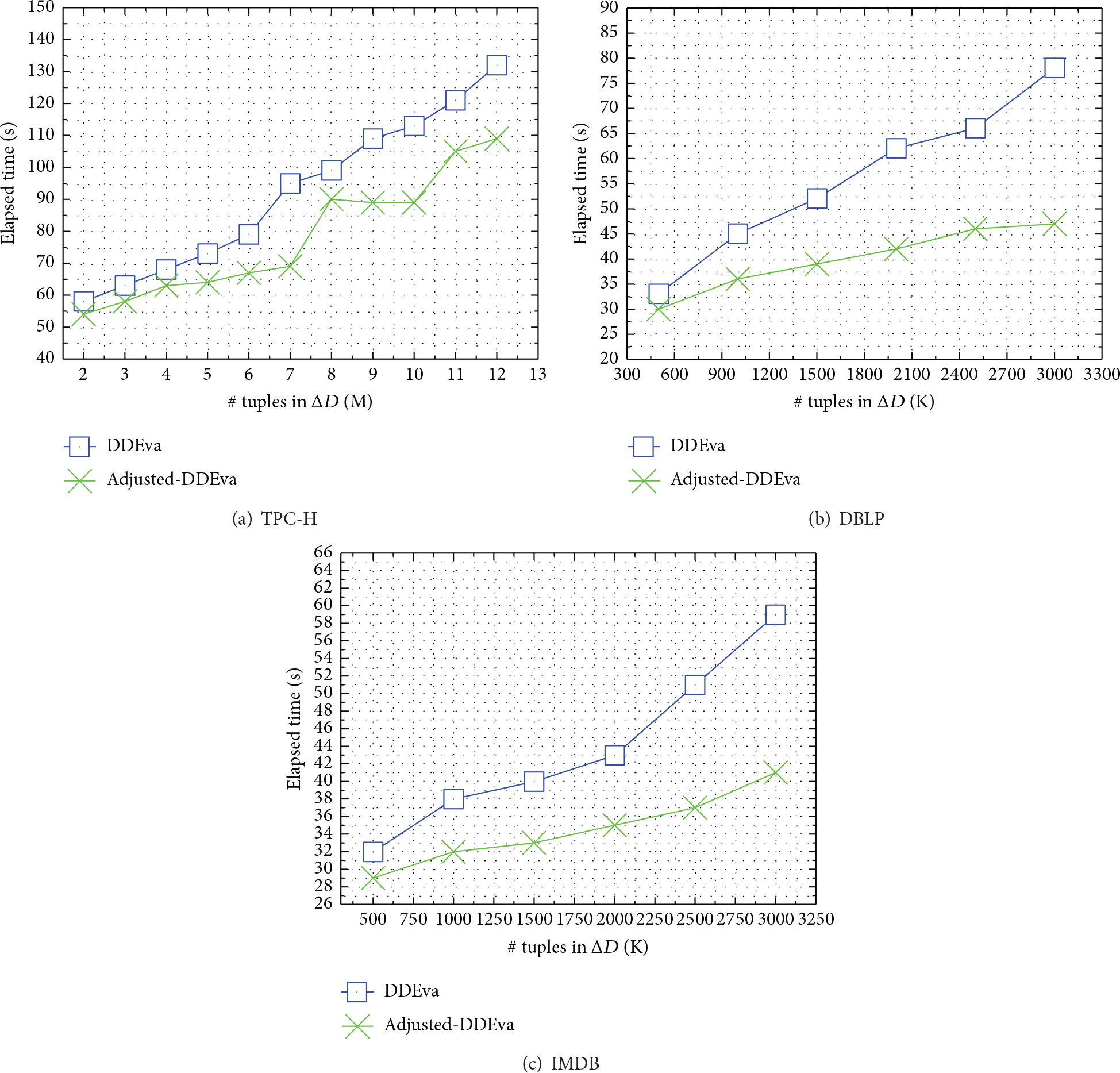
Exp-1: Impact of. In the first set of experiments, we show the impact of the size of the database D on the performance of evaluation algorithm of inconsistencies in static data. Fixing (including 5% FDs), the size of D (i.e., ) is varied from M to M tuples ( GB) for TPC-H. And for IMDB and DBLP, is varied from K to M while fixing (including FDs) for both datasets.
The elapsed time in seconds is shown in Figure 10 when varying . From the results, it is first shown that the naïve algorithm takes too much time to perform computation; we manually terminate the program when the elapsed time exceeds the top boundary. It is also shown that adjusted-DDEva outperforms DDEva for both real-life datasets while sometimes it does not for TPC-H. This is really because both real-life datasets are much less dirty with respect to many CFDs such that most tuples are matched earlier avoiding redundancy in the following indexes and the factor just captures this. Figure 10 also shows that both DDEva and adjusted-DDEva scale well with the size .
Elapsed time of DDEva and adjusted-DDEva.
Our algorithm works well on both synthetic data TPC-H and real-life data DBLP and IMDB demonstrating that algorithm is able to deal with large dataset efficiently.
Exp-2: Impact of. In the second set of experiments, we show how the size of changes to the database affects the performance of inconsistency evaluation algorithm. Fixing and M, the size of is varied from M to M tuples for TPC-H. is varied from K to K tuples for DBLP and IMDB while fixing K and . The elapsed times in seconds when varying for TPC-H (resp., DBLP and IMDB) are shown in Figure 11(a) (resp., Figures 11(b) and 11(c)).
Elapsed time of and adjusted-DDEva.
As shown in Figures 11(a), 11(b), and 11(c), the elapsed times of adjusted-DDEva scale well up with , for example, seconds when is updated from M to M and seconds when is updated from M to M as shown in Figure 11(a).
Also, adjusted-DDEva updates the result much more efficiently than DDEva in both real-life datasets and it has a slower growth in contrast to DDEva. That is, in experiment 2, the results have shown that adjusted-DDEva updates the result much more efficiently than DDEva in both real-life datasets.
Exp-3: Impact of. In this set of experiments, we study the impact of the number of variable CFDs on data dirtiness evaluation. Fixing M and M for TPC-H, we varied the number of CFDs from to including FDs. Moreover, fixing K and K for DBLP and IMDB, we varied from to including FDs. The elapsed times when varying from to for TPC-H (resp., from to for DBLP and IMDB) are shown in Figure 12(a) (resp., Figures 12(b) and 12(c)). Both and - are able to evaluate the data dirtiness with good scalability when varying .
Elapsed time of and adjusted-DDEva.
As the number of indexes will increase with , the elapsed time of DDEva will increase with . However, the elapsed time of adjusted-DDEva performance is better than that of DDEva since the size of indexes with higher rank is very small after adjusting the processing order of CFDs in Σ . The results demonstrate that adjusted-DDEva has good scalability with , and it works well on a larger number of CFDs.
Note that, in Figures 12(b) and 12(c), we can see that the increase of size does not lead to a fast growth of the adjusted-DDEva; that is really because the number of FDs included in the CFD set for DBLP and IMDB is fixed and captures most conflicts so that a large amount of random I/Os in the following indexes is prevented in practice.
Exp-4: Space Cost. In this set of experiments, we study the sizes of indexes that our algorithm needs to build. Fixing the number of general CFDs , each with pattern tuples generated randomly, and setting as M for TPC-H (i.e., GB) and M for DBLP and IMDB (about GB), we record the size of each index for the three datasets. The results are shown in Figure 13.
Space cost of and adjusted-DDEva.
First, for each dataset, the index size decreases with the processing order; this is consistent with the definition of ir-subgraph. Second, the total space our algorithm takes does not depend on the width of the dataset due to key compression. Actually, in practice, a pair of 32-bit or 64-bit integers is enough to partition the dataset according to the values on X and Y without errors. Third, as shown in the results of this experiment, - takes less total space cost than its counterpart, and the first few indexes almost cover most of the matched tuples.
Exp-5: Quality of Evaluation Result. In the last set of experiments, we study the evaluation result quality of our evaluation method based on minimum culprit with respect to CFD set Σ (MC), in contrast with naïve methods based on conflicts counting (CC). Here, we introduce a variable “” representing the difference of data inconsistency between the ith update and the th update; concretely, “” is the difference of minimum culprit size estimated with respect to CFD set Σ; “” is the difference of conflicts detected, respectively. To measure the result quality of two evaluation methods under assumption in , we compute the standard deviation of “” on samples with tuples which lead to inconsistency.
Figure 14 shows the standard deviation of variable “” computed for TPC-H ( M, , and is varied from M to M including only insert operation) and DBLP and IMDB ( K, , and is varied from K to K including only insert operation).
Elapsed time of and adjusted-DDEva.
The figure tells us that, for each dataset, is insensitive to a single update operation, but is very sensitive to each single update operation which will be inconsistent with existing tuples. That is to say, the evaluation method MC studied in this paper will give a very smooth monitoring curve rather than the naïve method CC.
7.4. Summary
We find the following conclusions from the results of the experiments conducted on both synthetic data TPC-H and real-life data DBLP and IMDB. Our evaluation algorithms scale well with respect to the size of database , the size of changes to database , and the number of CFDs for large data (Exp-1 to Exp-3). The modified version of algorithm adjusted-DDEva outperforms its counterpart DDEva much more especially for both real-life datasets and larger because a few CFDs in Σ have small confidence while the others do not. The evaluation method proposed based on minimum culprit with respect to CFD set Σ substantially revealed how dirty the data is under the typical assumption: “ most of the data is often correct, especially for large data, and an update of a tuple with error has a very tiny impact on the dirtiness of the entire dataset” (Exp-5).
8. Related Works
Conditional functional dependency (CFD) was first proposed by the authors of [16] while the SQL techniques they provided have been applied in data cleaning broadly, which can be used to detect the inconsistencies of databases. However, there is no existing work focusing on computing the inconsistency of a database based on CFDs efficiently. The most relevant works to this paper can be categorized into inconsistency detection and resolution.
For inconsistency detection, there exist some detection techniques which are able to detect errors efficiently; SQL techniques for detecting CFD violations were given by [18]; practical algorithms for detecting violations of CFDs in fragmented and distributed relations were provided by [19] and an incremental detection algorithm was proposed by [20]. In contrast to inconsistency detection, inconsistency evaluation needs to compute the quantized dirtiness value of the data, rather than finding all violations.
For data repair, there are two kinds of works which are based on FDs/CFDs; they both aim to directly resolve the inconsistency of database. One kind of method is to repair data based on minimizing the repair cost, for example, [22, 24, 29, 36, 37]. Given the data edit operations (including tuple-level and cell-level), minimum cost repair will output repaired data with minimizing the difference between it and the original one. Our problem can be seen as a special case of [29], because the complementary minimum culprit can be seen as C-repair (cardinality repair) of an inconsistent database; however, it is much more expensive using the techniques of the authors of [27] directly, especially for dynamic data, and the algorithm given in this paper is more efficient and seems optimal. There are some other repair definitions, such as “minimum description length (MDL)” [23] and “relative trust” [21]. To the best of our knowledge, there is almost no polynomial approximation algorithm with a good ratio bound for repairing inconsistent data based on CFDs except for a few approximation algorithms with constant ratio which were provided, such as [25], while the ratio could not reach , although the repair algorithm starts to need an approximate minimum vertex cover in a conflict graph, which is why they do not consider how to compute it efficiently; moreover, they cannot deal with large dynamic data well because it starts by finding all FD violations and a conflict hypergraph with respect to all FDs/CFDs should be built first which may take quadratic time and space. Another kind of method is consistent query answer (CQA) [29, 36, 38–43]; for a fixed boolean query q, is the following problem: given a database D, decide whether q evaluates to true on every repair of D. Such method will not edit the data but will find a query answer among all possible repairs of original database, and, unfortunately, there is no technique in CQA that can be used in this paper directly. Moreover, there are some works considering the theoretical result of CQA under C-repair [38, 44–46], but they do not provide the technique able to solve the problem this paper studied. Additionally, if the minimality assumption fails or there are multiple optimal repairs of the data, output of repair approximation algorithm will be meaningless sometimes even if it has an accuracy guarantee. In contrast to data repair, this paper aims to output the value of dirtiness for data quality evaluation, monitoring, and so on. Therefore, approximation with constant factor is also the lower bound of repairing cost.
9. Conclusions
This paper studied the data consistency evaluation based on CFDs, in order to give a quantized quality value to users. We proved that the complexity of dirtiness evaluation is NP-complete even if the condition is simple enough; moreover, for any , it is hard to give an approximation within in polynomial time. The time complexity of our -approximate algorithm is , and it scales well. To deal with the larger data and its update, the compact structure reduces the storage of conflict graph to and reduces the time of update to . The experiments show that our algorithm scales well with data size and the quality of its evaluation result is good.
Footnotes
Competing Interests
The authors declare that they have no competing interests.
Acknowledgments
This work is supported in part by the National Basic Research Program of China (973 Program) under Grant no. 2012CB316200, the National Natural Science Foundation of China (NSFC) under Grant no. 61190115, 61370217, the Fundamental Research Funds for the Central Universities under Grant no. HIT.KISTP201415, the National Science Foundation (NSF) under Grants nos. CNS-1152001 and CNS-1252292, the Research Fund for the Doctoral Program of Higher Education of China under Grant no. 20132302120045, and the Natural Scientific Research Innovation Foundation in Harbin Institute of Technology under Grant no. HIT.NSRIF.2014070.
References
1.
RajkumarR. R.LeeI.ShaL.StankovicJ.Cyber-physical systems: the next computing revolutionProceedings of the 47th Design Automation Conference (DAC '10)June 2010Anaheim, Calif, USAACM73173610.1145/1837274.18374612-s2.0-77956217277
2.
LiJ.ChengS.GaoH.CaiZ.Approximate physical world reconstruction algorithms in sensor networksIEEE Transactions on Parallel and Distributed Systems201425123099311010.1109/TPDS.2013.22971212-s2.0-84908187999
3.
ChengX.ThaelerA.XueG.ChenD.TPS: a time-based positioning scheme for outdoor wireless sensor networks4Proceedings of the 23rd Annual Joint Conference of the IEEE Computer and Communications Societies (INFOCOM '04)March 20042685269610.1109/infcom.2004.13546872-s2.0-8344222870
4.
DingM.ChenD.XingK.ChengX.Localized fault-tolerant event boundary detection in sensor networks2Proceedings of the 24th IEEE Annual Joint Conference of the IEEE Computer and Communications Societies (INFOCOM '05)March 2005Miami, Fla, USA9029132-s2.0-25844521520
5.
LiH.HuaQ. S.WuC.LauF. C. M.Minimum-latency aggregation scheduling in wireless sensor networks under physical interference modelProceedings of the 13th ACM International Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems (MSWiM '10)October 2010Bodrum, TurkeyACM36036710.1145/1868521.18685812-s2.0-78650222013
6.
ShaK.ZeadallyS.Data quality challenges in cyber-physical systemsJournal of Data and Information Quality201562-3, article 810.1145/27409652-s2.0-84930974854
7.
TolleG.PolastreJ.SzewczykR.CullerD.TurnerN.TuK.BurgessS.DawsonT.BuonadonnaP.GayD.HongW.A macroscope in the redwoodsProceedings of the 3rd ACM International Conference on Embedded Networked Sensor Systems (SenSys '05)November 2005ACM516310.1145/1098918.10989252-s2.0-84905819805
8.
SzewczykR.PolastreJ.MainwaringA.CullerD.Lessons from a sensor network expeditionProceedings of the 1st EuropeanWorkshop (EWSN '04)2004Berlin, Germany307322
9.
CaiZ.ChenZ.-Z.LinG.A -approximation algorithm for the capacitated multicast tree routing problemTheoretical Computer Science2009410525415542410.1016/j.tcs.2009.05.013MR25676422-s2.0-70449123289
10.
CaiZ.ChenZ.-Z.LinG.WangL.An improved approximation algorithm for the capacitated multicast tree routing problemCombinatorial Optimization and Applications: Second International Conference, COCOA 2008, St. John's, NL, Canada, August 21–24, 2008. Proceedings20085165Berlin, GermanySpringer286295Lecture Notes in Computer Science10.1007/978-3-540-85097-7_27MR2733023
11.
CaiZ.GoebelR.LinG.Size-constrained tree partitioning: approximating the multicast k-tree routing problemTheoretical Computer Science2011412324024510.1016/j.tcs.2009.05.031MR27896462-s2.0-78650610629
12.
CaiZ.LinG.XueG.Improved approximation algorithms for the capacitated multicast routing problemComputing and Combinatorics: 11th Annual International Conference, COCOON 2005 Kunming, China, August 16–19, 2005 Proceedings20053595Berlin, GermanySpringer136145Lecture Notes in Computer Science10.1007/11533719_16
13.
GuoL.LiY.CaiZ.Minimum-latency aggregation scheduling in wireless sensor networkJournal of Combinatorial Optimization201631127931010.1007/s10878-014-9748-7MR3440260ZBL1332.901102-s2.0-84953639722
14.
HeZ.CaiZ.ChengS.WangX.Approximate aggregation for tracking quantiles in wireless sensor networksProceedings of the 8th International Conference on Combinatorial Optimization and Applications (COCOA '14)December 2014Maui, Hawaii, USA161172
15.
HeZ.CaiZ.ChengS.WangX.Approximate aggregation for tracking quantiles and range countings in wireless sensor networksTheoretical Computer Science201560738139010.1016/j.tcs.2015.07.056MR34290602-s2.0-84939525641
16.
BohannonP.FanW.GeertsF.JiaX.KementsietsidisA.Conditional functional dependencies for data cleaningProceedings of the 23rd International Conference on Data Engineering (ICDE '07)April 2007Istanbul, Turkey74675510.1109/icde.2007.3679202-s2.0-34548731840
17.
AbiteboulS.HullR.VianuV.Foundations of Databases1995
18.
FanW.GeertsF.JiaX.KementsietsidisA.Conditional functional dependencies for capturing data inconsistenciesACM Transactions on Database Systems2008332136610310.1145/1366102.13661032-s2.0-46649106686
19.
FanW.GeertsF.MaS.MüllerH.Detecting inconsistencies in distributed dataProceedings of the 26th IEEE International Conference on Data Engineering (ICDE '10)March 2010Long Beach, Calif, USA647510.1109/icde.2010.54478552-s2.0-77952749687
20.
FanW.LiJ.TangN.YuW.Incremental detection of inconsistencies in distributed dataProceedings of the IEEE 28th International Conference on Data Engineering (ICDE '12)April 2012Washington, DC, USAIEEE31832910.1109/icde.2012.822-s2.0-84864198280
21.
BeskalesG.IlyasI. F.GolabL.GaliullinA.On the relative trust between inconsistent data and inaccurate constraintsProceedings of the 29th International Conference on Data Engineering (ICDE '13)April 2013Brisbane, Australia54155210.1109/icde.2013.65448542-s2.0-84881320841
22.
BohannonP.FanW.FlasterM.RastogiR.A cost-based model and effective heuristic for repairing constraints by value modificationProceedings of the 2005 ACM SIGMOD international conference on Management of data (SIGMOD '05)June 2005Baltimore, Md, USAACM14315410.1145/1066157.10661752-s2.0-29844436973
23.
ChiangF.MillerR. J.A unified model for data and constraint repairProceedings of the IEEE 27th International Conference on Data Engineering (ICDE '11)April 2011Hannover, GermanyIEEE44645710.1109/icde.2011.57678332-s2.0-79957823829
24.
CongG.FanW.GeertsF.JiaX.MaS.Improving data quality: consistency and accuracyProceedings of the 33rd International Conference on Very Large Data Bases (VLDB '07)2007315326
25.
KolahiS.LakshmananL. V. S.On approximating optimum repairs for functional dependency violationsProceedings of the 12th International Conference on Database Theory (ICDT '09)March 2009Saint-Petersburg, RussiaACM536210.1145/1514894.15149012-s2.0-70349143135
26.
YakoutM.ElmagarmidA. K.NevilleJ.OuzzaniM.IlyasI. F.Guided data repairProceedings of the VLDB Endowment20114527928910.14778/1952376.1952378
27.
MiaoD.LiuX.LiJ.On the complexity of sampling query feedback restricted database repair of functional dependency violationsTheoretical Computer Science2016609359460510.1016/j.tcs.2015.02.010MR34290922-s2.0-84948808360
28.
CormodeG.GolabL.FlipK.McGregorA.SrivastavaD.ZhangX.Estimating the confidence of conditional functional dependenciesProceedings of the 35th ACM SIGMOD International Conference on Management of DataJuly 2009Providence, RI, USA46948210.1145/1559845.15598952-s2.0-70849101505
29.
LopatenkoA.BravoL.Efficient approximation algorithms for repairing inconsistent databasesProceedings of the 23rd International Conference on Data Engineering ICDE 2007April 2007Istanbul, Turkey21622510.1109/icde.2007.3678672-s2.0-34548775857
30.
MiaoD.LiJ.LiuX.GaoH.Vertex cover in conflict graphs: complexity and a near optimal approximationCombinatorial Optimization and Applications: 9th International Conference, COCOA 2015, Houston, TX, USA, December 18–20, 2015, Proceedings20159486Berlin, GermanySpringer395408Lecture Notes in Computer Science10.1007/978-3-319-26626-8_29
31.
ArenasM.BertossiL. E.ChomickiJ.Scalar aggregation in fd-inconsistent databasesProceedings of the 8th International Conference on Database Theory (ICDT '01)2001London, UKSpringer3953
32.
GavrilF.Algorithms for minimum coloring, maximum clique, minimum covering by cliques, and maximum independent set of a chordal graphSIAM Journal on Computing19721218018710.1137/0201013MR0327580
ArenasM.BertossiL.ChomickiJ.Consistent query answers in inconsistent databasesProceedings of the 18th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems (PODS' 99)June 1999ACM68792-s2.0-0032640897
37.
WinklerW. E.Methods for evaluating and creating data qualityInformation Systems200429753155010.1016/j.is.2003.12.0032-s2.0-2942709772
38.
ChomickiJ.MarcinkowskiJ.Minimal-change integrity maintenance using tuple deletionsInformation and Computation20051971-29012110.1016/j.ic.2004.04.007MR21263642-s2.0-14744293228
39.
BertossiL.BravoL.FranconiE.LopatenkoA.Complexity and approximation of fixing numerical attributes in databases under integrity constraintsDatabase Programming Languages2005Berlin, GermanySpringer262278
40.
CalìA.LemboD.RosatiR.On the decidability and complexity of query answering over inconsistent and incomplete databasesProceedings of the 22nd ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems (PODS '03)June 20032602712-s2.0-1142299764
41.
FuxmanA.FazliE.MillerR. J.ConQuer: efficient management of inconsistent databasesProceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD '05)June 2005Baltimore, Md, USA15516610.1145/1066157.10661762-s2.0-29844448776
42.
FuxmanA.MillerR. J.First-order query rewriting for inconsistent databasesJournal of Computer and System Sciences200773461063510.1016/j.jcss.2006.10.013MR2320187ZBL1112.680422-s2.0-33947319488
43.
WijsenJ.Database repairing using updatesACM Transactions on Database Systems200530372276810.1145/1093382.10933852-s2.0-33745206041
44.
ArenasM.BertossiL.ChomickiJ.Answer sets for consistent query answering in inconsistent databasesTheory and Practice of Logic Programming200334-539342410.1017/S1471068403001832MR2014092ZBL1079.680262-s2.0-0345393818
45.
KolahiS.LibkinL.An information-theoretic analysis of worst-case redundancy in database designACM Transactions on Database Systems2010351, article 510.1145/1670243.16702482-s2.0-77249147548
46.
LopatenkoA.BertossiL.Complexity of consistent query answering in databases under cardinality-based and incremental repair semanticsProceedings of the 11th International Conference on Database Theory (ICDT '07)2006Berlin, GermanySpringer179193