
Abstract
The combination of mobile and social media sensors is foreseen to become a crucial course of action so as to comprehensively capture and understand the movement of people in large spatial regions. In that sense, the present work describes a novel personal location predictor that makes use of these two types of sensors. Firstly, it extracts the mobility models of an area capturing aspects related to particular users along with crowd-based features on the basis of geotagged tweets. Unlike previous approaches, the proposed solution mines such models in an online manner so that no previous off-line training is required. Then, on the basis of such models, a predictor able to forecast the next activity and position of a user is developed. Finally, the described approach is tested by using Twitter datasets from two different cities.
1. Introduction
Nowadays, handheld and wearable devices have actually become instrumental tools for most of our daily tasks. Among other features, such devices have been steadily enriched with more precise positioning sensors, like GPS. This has allowed collecting a large amount of high-resolution digital traces which, in turn, have eased the development of the mobility mining discipline which focuses on giving insight into the underlying spatiotemporal trajectories of the gathered traces [1]. As a result, innovative location-based services have been developed like personal advertisement campaigns [2] or pervasive navigation systems [3].
At the same time, social networking has become a very popular activity in most developed and developing societies allowing people to remain socially connected to their friends, relatives, and colleagues in an easy manner. As a matter of fact, the number of active users of social media reached 2000 million in August 2014 (http://wearesocial.net/blog/2014/08/global-social-media-users-pass-2-billion/).
During recent years, many social network and microblogging sites, such as Twitter, Facebook, or Foursquare, have included location-based capabilities into their smartphone's applications. The fact that most of the documents and data belonging to those sites can be geotagged thanks to these capabilities has enabled the advent of what has been called soft sensors combining social media and location data.
From these soft sensors, an unprecedented amount of user-generated data on human movement and activity participation has become easily available. Unlike previous mobility datasets (e.g., GPS-based ones), these new ones not only include spatiotemporal information (e.g., the spatial coordinates of a person at a particular moment) but also include textual data attached to a particular spot which provides more semantic information.
In this scope, a new course of action within the aforementioned mobility mining discipline focuses on giving insight into this new social media data so as to come up with novel human mobility models and patterns [4–6]. Nonetheless, previous studies frequently suffer from some of the following limitations:
They center on extracting general mobility information related to a particular urban area or region without distinguishing between particular users. In that sense, inferring more personal mobility models might be useful to come up with more customized location services. A preprocessing step of the whole available dataset is required before generating the final models or patterns. However, under certain conditions, this requirement is not feasible as the whole dataset is not available in advance. Moreover, most works constrain their processing to the spatiotemporal aspects of the data (check-in posts) without considering other textual details like the content of the document. As a result, these works do not fully take advantage of social media datasets. Lastly, little efforts have been done so far to devise solutions able to anticipate future locations or activities of users, by taking advantage of geotagged social media documents.
In this context, the present work puts forward a novel approach for personal mobility mining based on microblogging content that fully considers the four limitations listed above.
In particular, the proposed system composes personal mobility graphs in an online fashion. A user's personal graph is endlessly generated and updated on the basis of his geotagged documents (“tweets”) gathered on the social network Twitter (https://twitter.com/). Next, such graphs are steadily aggregated to compose a hierarchy representing the mobility flows of a large spatial region.
Unlike previous approaches, these graphs include the important geographical areas of a person or region (“landmarks”), how they are interconnected, and also the frequent topics mentioned in Twitter within each place by considering not only check-in documents.
Figure 1 depicts an illustrative example of the aforementioned mobility graph hierarchy which basically comprises two different levels. The first one is compound of the personal graphs related to particular users, whereas the second level comprises a more general one representing the crowd-based mobility within the spatial region of interest.

Overview of the proposal.
In order to compose each graph, three key mechanisms have been used, a novel density-based clustering for the extraction of meaningful places, whereas the topic mining has been carried out by means of lightweight bag of words solution. In addition to that, due to the event nature of tweets, the orchestration of all the components has been done with the Complex Event Processing (CEP) paradigm [7]. CEP is a well-established technology to extract predefined patterns in event-based environments.
Next, on the basis of the historical data contained in the whole graph hierarchy, a multilevel Markov-model-based predictor has been designed. In brief, it incrementally accesses each graph level until a suitable prediction is generated regarding location and potential activity. In that sense, the prediction is also discretized considering temporal factors.
Last but no least, the adopted solution takes the form of a mobile client and a back-end server. The client runs and deals with personal mobility features whereas the back-end server is in charge of the crowd-sensing features.
To sum up, bearing in mind the four current limitations for mobility mining based on social media previously listed, the salient contributions of the present work can be summarized as follows: (1) a novel mobility model based on Twitter data that considers both personal and crowd-based mobility, (2) an online approach to extract such a model with no need of off-line processing, (3) the usage of different types of geotagged documents and not only check-in ones, and (4) one of the first attempts to anticipate future user's location by only relying on social media information.
The remainder of the paper is structured as follows. An overview of the approach's background is put forward in Section 2. Section 3 is devoted to describing the logic structure of the proposed system. Then, Section 4 shows a study of the proposal. Finally, the main conclusions and the future work are summed up in Section 5.
2. Related Work
An overview of the contribution of our work with respect to related domains is stated in this section.
2.1. Social Media for Human Mobility
During recent years, data from several social network sites has been mainly used to extract information related to different types of human features. Apart from sentiment analysis [8, 9], a foremost line of research in this domain focuses on mining useful information related to how people move and the underlying goals of this movement. In that sense, it is possible to classify these works under three different categories.
Firstly, one group of works aim at automatically extracting spatial regions within an urban area on the basis of their usage (e.g., leisure, home, and work) by processing geotagged tweets [6, 10, 11]. For that goal, either visual analytics [11] clustering algorithms [10] or predefine classifiers from third-party location services [6] are commonly used to process the data coming from social network sites.
Secondly, another course of action intends to automatically extract events of interest (e.g., live shows, exhibitions, and traffic jams) from social media. For instance, [12, 13] come up with smart social agendas that can be updated in real time whereas [14] makes use of tweets so as to timely detect potential earthquakes. In a road-traffic monitoring scenario, several works make use of social media data in order to either detect or semantically enrich traffic anomalies. This is the case of [15], which studies the correlation between tweets and road-traffic incidents. [16] takes social media data as input in order to explain previously detected traffic problems. Similarly, [17] collects documents from official traffic-management institutions' Twitter accounts in order to detect in real time traffic congestions.
Finally, our work is enclosed in a third line of study whose main goal is to include social media as a new data-source for detecting the movement of different kinds of people among different places [4–6, 18]. More in detail, [4] proposes a novel approach to semantically enrich spatiotemporal trajectories given data from different social media sites. This way, a more dynamic labelling is achieved. Moreover, [18] states a worldwide mobility report based geotagged Twitter data. Apart from that, [6] proposes a personal mobility mining approach to detect the frequency in which a user visits different locations on the basis of his underlaying activity. Finally, [5] processes the spatial coordinates of geotagged tweets in order to compose the spatial-temporal trajectories of a set of Twitter users. Such trajectories are defined as simple Origin-Destination matrices and the labelling of each potential origin or destination is done by means of a third-party location service.
Despite some similarities between the aforementioned solutions and our work, some key differences can also be stated. In that sense, either such works rely on previously collected datasets or, even providing real time processing, all this processing is centralized in a back-end server without providing any component running in the clients' mobile devices. In addition to that, works like [4, 6] do not use regular social media documents as incoming data but only check-in documents. These types of documents explicitly indicate when the user has been at a certain venue by appending a URL providing more details of such a venue. A clear example of social site that provides this type of content is Foursquare (https://foursquare.com/).
On the contrary, our proposal defines a proper client-server architecture able to run in smartphones. Furthermore, the solution also avoids a preprocessing step of the dataset by incrementally composing the graphs. Finally, the system has been designed to take as input regular tweets, not only check-in ones.
2.2. Location Prediction
Location prediction is based on the assumption that common people follow daily routines and, thus, have only a set of frequently visited locations [19]. This makes people's regular trips quite predictable due to their high level of repetition [20, 21].
In this scope, it is possible to mainly distinguish two different trends for personal location prediction. The former follows a geometrical approach so as to predict a path in the Euclidean space [22, 23]. In this line of work, future locations are predicted by applying a mathematical function to the current location and velocity of the target person.
The second line of work is based on pattern matching and it profits from the above-mentioned repetition assumption. In brief, solutions within this trend compare the route in progress with a set of mobility models (created on the basis of previously observed routes). If a match fires, the selected (group of) pattern(s) is used to make a prediction [24]. In that sense, Bayesian networks [25, 26], hidden Markov models [27–30], and Markov decision processes [31] have been some of the applied solutions given high-resolution mobility datasets (e.g., those comprising GPS-based traces). Despite the fact that these datasets provide more detailed mobility information, they are not really convenient for full-blown deployments as GPS feed is one of the most battery-draining sensors of a mobile device. On the contrary, our work relies on social media sources that are not so expensive in terms of energy usage as the aforementioned positioning sensors.
Regarding social media datasets, a remarkable solution for location prediction is the probabilistic model W4 described in [32]. By following a Bayesian-network approach, the proposed system is able to forecast the next location and activity of a user by also taking into account temporal factors. Despite the fact that the goal of such a method and our work is the same, a major difference exists. W4 makes up a Bayesian-network for each single user by only using his own tweets. Similarly, our work also composes a set of personal graphs by only using the geotagged tweets of the target user. Nonetheless, it also creates a mobility graph combining the tweets from all users representing the crowd-dynamics within a region. Then, both types of graphs are used to provide a prediction. Therefore, unlike W4, our system makes use of personal and more general mobility information to provide prediction.
Lastly, [33] provides a complete analysis of which mobility features may have an impact on next location prediction given social media diaries. Despite its interesting results, authors focus on check-in documents instead of other types of social media content.
2.3. Complex Event Processing
Complex Event Processing (CEP) is an evolution of the former publish/subscribe model in order to deal with more complex subscription patterns, so it can be regarded as a relatively recent technology [7].
Despite CEP's widespread usage, there exists a scarcity of CEP solutions which deal with spatiotemporality since only a few works actually propose practical CEP applications able to process spatiotemporal data [34]. In that sense, [35] devises a formal framework to timely detect spatiotemporal relationships between moving entities. However, such a solution only focuses on GPS-based high-resolution data discarding other types of spatiotemporal event sources.
Concerning the usage of CEP to process events generated by social network sites, only theoretical solutions to define formal event-based information models and architectures for social media processing have been put forward so far [36]. Therefore, to the best of the authors knowledge, this paper constitutes one of the first efforts to actually process social media data by means of the CEP paradigm.
3. Proposed System
This section is devoted to explain in detail the goal along with the architecture of the proposal.
3.1. Prediction Target
The main goal of the present system is to provide an accurate and early prediction of the next meaningful location, or landmark, visited by a person along with the underlying activity of such a place.
As the bottom of Figure 1 shows, we assume that the spatial and temporal spread of tweets of a user define a set of personal landmarks like his home, office, school, and so forth. In our setting, such landmarks have been defined by means of a spatial approach.
Definition 1.
A landmark for a person
Furthermore, the spatial and temporal distribution of tweets also composes a set of more general landmarks that are not related to a particular individual but, instead, are meaningful for a crowd of people, like the center of a city, business parks, or shopping areas. Such collective landmarks can be defined as follows.
Definition 2.
A collective landmark,
Consequently, from a social media point of view, the mobility of a person is constrained to personal and collective landmarks. In this way, the route of a person can be stated as follows.
Definition 3.
A route of a person
All in all, our approach focuses on predicting the next personal or crowd-based landmark
3.2. Architecture Overview
In order to achieve the prediction features explained before, the present system has been designed to run in handheld devices. Nonetheless, due to the different types of landmarks to be detected, the system architecture has been split into two parts, a client side that runs on the mobile device of each user in charge of detecting personal landmarks and a server side responsible for composing the collective ones.
The system's logic structure is depicted in Figure 2. For its design, the CEP paradigm has been followed. Thus, the system's inner structure basically consists of a palette of interconnected Event Processing Rules (EPRs) along with other modules providing different kinds of computational support.

System architecture. The components that are not EPRs are depicted as dashed boxes.
Each EPR takes as input one or more streams of raw or derived streams. From these streams, it is in charge of detecting a specific pattern. Each time EPR fires, a derived event is composed and asynchronously distributed to other upstream EPRs or an event sink or consumer.
3.3. Event Model
When it comes to develop a CEP system, one of the first tasks to be undertaken is the definition of the events that the system is going to make up during its execution. In this scope, Figure 3 depicts the information model of the system. As we can see from it, the event types have been structured by means of a hierarchical approach.

Information model of the system.
On the one hand, the tweet event represents a raw tweet written by the user. In that sense, the attributes of this event include not only the textual content of the tweet but also other important metadata like the user nick, its timestamp, and its geotagging. Next, the tweet with topic event refines it by including the most probable topics its textual content refers to.
On the other hand, landmark event further enhances the previous tweet events by also indicating if a tweet has been written inside any personal or collective landmark. Finally, the route event represents a completed route as a sequence of personal or collective landmarks as it was put forward in Definition 3.
Most route prediction approaches usually consist of a chained process comprising three stages, route composition, mobility model generation, and eventually location prediction. Therefore, the description of the system is split into these three steps.
3.4. Route Composition
This first step aims at composing the ongoing route
3.4.1. Tweet Filter EPR
First of all, this rule is in charge of filtering out the incoming user's tweets that might not provide useful information to infer his current activity. In that sense, this rule discards those tweets that are just repetitions (“retweets”) of a tweet written by a completely different user. This way, we ensure that the route will be composed of the documents originally written by the user.
Moreover, this event rule also undertakes the cleaning of the text content of the tweet. In that sense, elements that do not provide information about the user's current activity are considered as noise and, hence, removed from the text. Such elements are (1) URL links, (2) mentions to other users, and (3) stop words, including articles and pronouns.
An event-based processing rule generally comprises two different parts, (1) a condition part where the requirements for the rule to fire are listed and (2) an action part that indicates the actions to be done if the condition part is fulfilled. Consequently, the pseudocode of the tweet filter EPR looks as follows:
where the string ''RT: '' is the default prefix indicating a retweeted content and the clean_text function is responsible for the text cleaning process.
3.4.2. Tweet Topic EPR
The next step in the route composition is to detect which is the underling activity that each filtered tweet refers to, if any. For that goal, an approach based on a bag of words has been applied. This involves two different tasks.
To begin with, it is necessary to define a set

Simplified taxonomy of target activities.
Secondly a bag of key unigrams
Next, the tweet topic EPR makes use of the aforementioned bags of words for the activity discovery procedure. To do so, it matches the keywords of each new tweet event t with the bag of words
where the function find_activities represents the activity detection described above. Note that this function could return an empty set indicating that there have not been any match.
3.4.3. Tweet in Landmark EPR
Once the activity discovery has been done, the next step in the route composition stage is to detect the landmark
Regarding the landmark's spatial region, if we consider Definitions 1 and 2, personal and collective landmarks can be regarded as spatial regions with a high density of tweets related to one or more activities. As a result, a density-based clustering has been applied to tweets' locations for landmark detection. This type of clustering has been widely applied to detect meaningful places given sets of spatiotemporal trajectories as in [39].
In short, density-based clustering is based on the concept of local neighbourhood

The density clustering algorithm applied for landmark detection is a slightly modified version of the online landmark discovery algorithm (LDM) described in [40].
In brief, LDA firstly intends to detect the set of centroids
On the basis of the detected centroids, a landmark
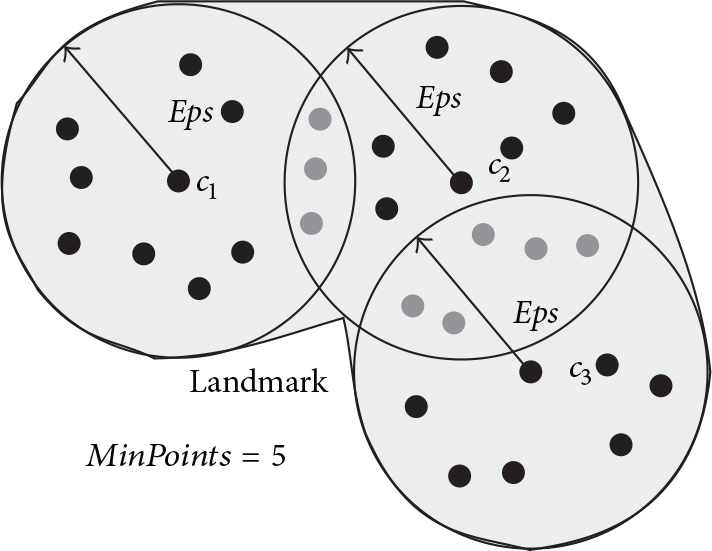
Example of a landmark returned by the LDA.
For the present work, the original algorithm has been adapted to certain characteristics of the present setting such as the spatial distribution of tweets and the fact that the client side is intended to run in handheld contrivances that should be regarded as memory-constrained devices.
Regarding the memory saving improvement, unlike the previous version of LDA, the set of available points

Example of local neighbourhood
Concerning the algorithm itself, it basically comprises two steps. In the first one (lines 4–10 of Algorithm 1), the algorithm tries to detect whether the incoming tweet t is already within the neighbourhood of any existing centroid. This step has been modified in order to avoid the spatial overspread of landmarks in the original approach. This caused the landmarks to cover very large spatial regions. In the present work, very large landmarks are not really convenient. The larger a landmark is, the more varied types of activities might be assigned to it. In our case, it is desirable to keep the types of activities associated with a more concise landmark.
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25)
Consequently, unlike the original LDA, the tweet location p is only considered as part of a landmark

Example of two potential situations between an incoming tweet location p and a landmark with two centroids (
Moreover, in order to avoid the overmerging problem of the original LDA, two different landmarks are now merged only if the distance between its middle points is less than or equal to
The second step (lines 11–21) is executed if the incoming tweet location p is not included in any existing centroid's neighbourhood. In that case, the algorithm first checks if p can be considered a centroid (line 12). If that condition is accomplished, a new landmark is generated (lines 14-15), it is merged with any other surroundings (lines 17–19) and the locations, which are not centroids, in
Finally, the resulting landmark is tagged with the same activities associated with the incoming tweet t (line 24). In that sense, if the algorithm has not been able to detect any landmark, the incoming location p is include in
Computational Complexity. Computing the neighbourhood of a point is
On the whole, two instances of the algorithm are executed (see Figure 2); the personal landmark discovery algorithm (
Due to Definition 2, a spatial region is considered a collective landmark only if it is frequently visited by a group of different people. In order to support this characteristic, the
As Figure 2 the tweet in landmark EPR composes a new landmark event from each tweet with topic event by indicating the detected personal or collective landmarks. Hence, the rule code is shown next:
In that sense, if the original tweet with topic event does not have an associated topic, then this landmark event represents that the user has visited the region for an unspecified purpose.
3.4.4. Route Composer EPRs
At this point, a stream of tweet in landmark events has been generated. On the basis of the landmarks contained in these events, the ongoing route of a user
In order to do that, the different landmarks are appended to
where
Consequently, two different EPRs are devoted to compose
The second rule just mirrors the previous one to detect if the new landmark event does not belong to the current route. If so, the current route is considered as finished and a new one must be started:
Furthermore, if this second rule fires, it also sends the just-completed route to the Local Graph Manager (LGM) (see Figure 2). As it will be put forward in the following section, this module carries out the update and management of the personal mobility graph in the user's device.
3.4.5. Graph Generation
This second stage of the route prediction focuses on generating on the fly the personal and collective mobility graphs,
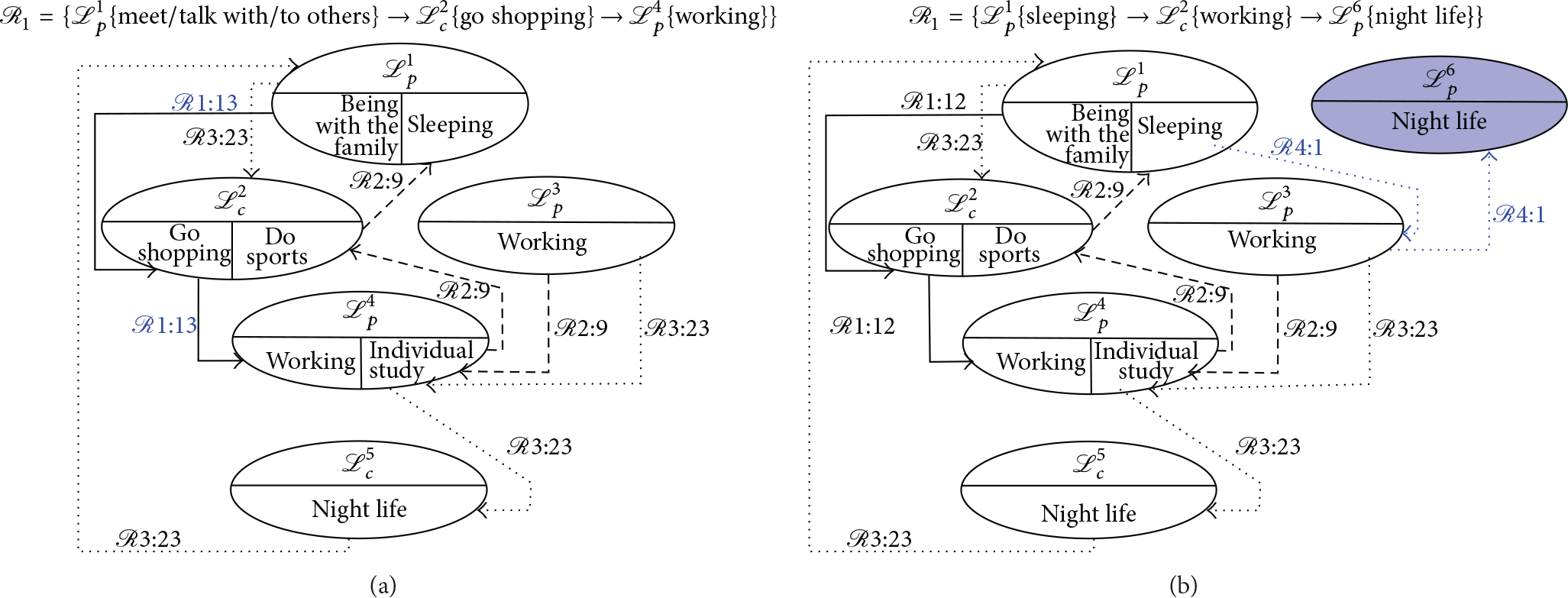
Figure 8 shows an illustrative example of a multigraph comprising 3 different routes,

Example of a multigraph structure. Each edge is labelled with the tuple
Regarding the personal mobility graph, Firstly, LGM checks if Secondly, the frequency attribute of each edge associated with this identifier is incremented. In case of a new identifier, a new set of edges connecting the landmarks are created. During this step, if the incoming route comprises a new landmark, a new vertex representing this new area is also generated.
Figure 9 shows two common cases of
Examples of multigraph updates. (a) A previously covered route updates just the frequency feature of the multigraph's edges. (b) A novel route updates the multigraph by adding a new vertex and set of edges.
At the same time the personal multigraph
As the LGM, the GGM also adapts the incoming
Consequently, while the LGM is responsible for endlessly updating the personal graphs that comprise the frequent routes of a particular user, the GGM performs a similar task but with the collective routes that are gathered by means of a crowd-sensing approach.
Lastly, the generated mobility graphs also take into account the temporal aspects of the route. In this frame, the present work is based on the assumption that people have different routes during working days than during weekends. Hence, in order to reflect such distinction in the mobility model, two personal and collective subgraphs are composed,

Example of system's graph hierarchies
All in all, the update of such a hierarchy is summarized in Algorithm 2. In such code, getFirst function returns the first landmark event of the route (its origin) and
/⋆ (1) (2) (3) (4) (5) (6) (7) (8) /⋆ (9) (10) (11) (12) (13) (14) (15) (16)
3.4.6. Location Prediction
Each time the route composer EPR enlarges or restarts
More in detail, LPM focuses on forecasting the next landmark (in terms of spatial region and associated topic) covered by the ongoing route. In order to provide the prediction with adjustable reliability, the system also considers a domain-dependant parameter minProb that defines the minimum probability of the prediction to be considered a suitable outcome.
In a nutshell, the proposed solution firstly tries to provide a prediction by only using the statistics related to the target user in
To start with, the algorithm removes from the ongoing route
(1) (2) (3) (4) /⋆ (5) (6) (7) Else (8) (9) (10) (11) (12) (13) /⋆ (14) (15) (16) Else (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) (28) (29) i– (30) (31) (32) (33) (34) (35) return (36) (37) (38) (39) (40) (41) (42) (43) (44) (45)
Next,
This function incrementally intersects the outbound edges of all the landmarks in
It may occur that two consecutive landmarks in
The rationale to start the selection of the candidate edges with the last landmark of a route is based on the intuition that the most recent places visited by a person provide more reliable information about his next place compared to the ones at the beginning of the route. Moreover, by doing this search in reverse using the outbound edges instead of the incoming ones, we ensure that the last landmark of
Finally, the function also supports the case in which there are no edges between two consecutive landmarks in
However, the ongoing route could not match any route in the graph. Hence, the aforementioned process will lead to an empty set. In order to cope with this problem and provide an alternative set of candidate edges, we have defined a lightweight heuristic included in the select_edges function as a special case (lines 32–35 of Algorithm 3). In this case, the outbound-edge intersection is restricted to the shortest common path of
For instance, provided an ongoing route
Finally, the function make_prediction (lines 38–44) comprises the second and last step of the prediction method. This step is responsible for actually generating the prediction outcome of the method. This is done by exclusively using the set of edges
More in detail, such a method makes use of the edges' attribute indicating their ending vertices. Thus, the method firstly calculates for each vertex (landmark) l in
Returning to our exemplary scenario, the system would extract the set
Finally, the inferred prediction could be sent to a third-party location-based service that may profit from such anticipated prediction.
3.4.7. Workflow Summary
To sum up, bearing in mind Figure 2, the workflow of the proposed system is as follows. To begin with, the incoming tweets are filtered by the tweet filter EPR to discard those that do not provide insightful mobility information. The resulting tweets are incrementally enriched by the tweet topic and tweet landmark EPRs by appending their associate topic and ROI. Next, a set of route composer EPRs reconstructs the coarse-grained ongoing route
4. Experimental Results
In this section we state the most important results of the proposal's evaluation.
4.1. Experiment Setup
Dataset. To evaluate our proposal we used the Twitter Crawling API (https://dev.twitter.com/) targeting two different Spanish cities, Madrid (MA) and Murcia (MU). While Madrid is the capital of Spain and one of the most important and crowded urban areas in Europe with a very dynamic lifestyle, Murcia is a middle-sized city in the southwest of Spain with a more quiet pace of life. The underlying idea was to test the system in two different urban ecosystems. In that sense, Table 1 shows some details of the generated datasets for both cities. As we can see, we manually removed certain Twitter accounts from the dataset that only posted spam content.
Datasets' details. Numbers in brackets are the percentage with respect to the raw tweets/users.

Figure 11 depicts the resulting digital traces of both datasets. While the MA dataset fits into the square of latitude from 40.20 to 40.62 and longitude from −4.00 to −3.40, the MU dataset fits into the square of latitude from 37.87 to 38.08 and longitude from −1.28 to −0.96. As we can see, a remarkable density of tweets exists in the center of each city whereas the tweets in the suburbs tweets are more spread.

Digital traces of the datasets.
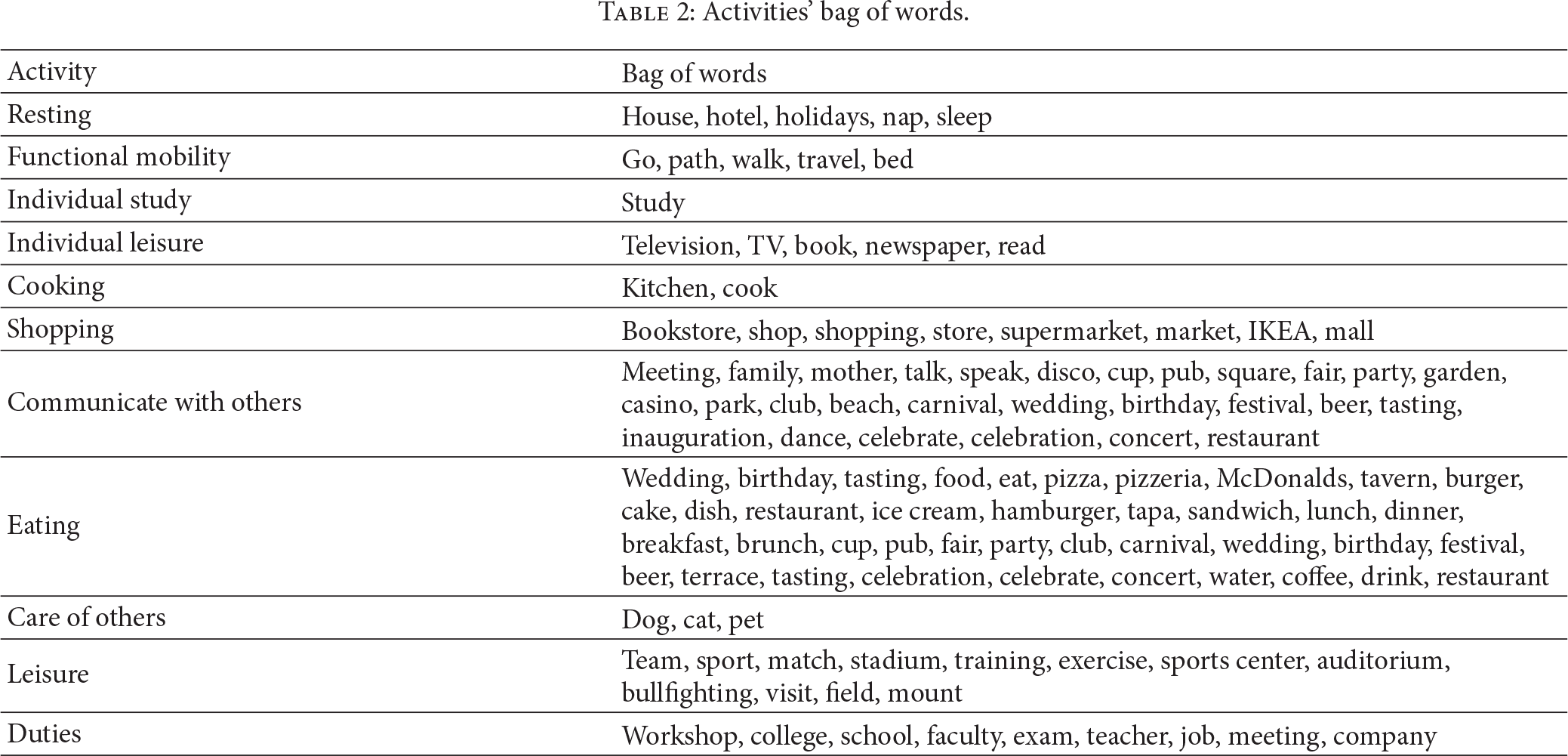
Settings. A paramount aspect in the configuration of the system is the definition of the bag of words associated with each target activity. Table 2 shows a minimized version of such bags translated into English for some elements of the taxonomy. In order to compose these bags, we selected the n most frequent words in the dataset. Then, we manually classify each word into one of the 11 target activities by considering the type of tweets the work belongs to. Lastly, Table 3 shows other system parameters.
Activities' bag of words.
System default configuration.

Measurements. The evaluation of the system has been carried out in the light of two different measurements, the prediction rate (PR) and the prediction error (PE). PR counts the number of routes for which at least one landmark is provided as prediction. By means of this factor, we intend to measure the coverage of the proposal. It should be made clear that detection rate counts the predictions for each version of the route (whenever a new element is appended to its sequence). Therefore PR can be defined by means of the following formula:

PE is the average of all distance deviations across each prediction of all routes. This measure indicates how far the system deviates from the actual next landmark. In order to measure the distance between two landmarks, a representative location for each landmark
Since each landmark may be associated with an activity, the distance between the predicted and the real activity must be also considered. Due to the fact that such activities are organized in a tree structure (see Figure 4), it is possible to assess the similarity between two activities by means of a conceptual distance. For the current scope, we have used the Semantic-Hierarchical Similarity (SHS) [42] that is defined by the formula
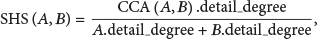
On the whole, PE is calculated by the following formula:

It is important to remark that, by means of this definition, PE ranges from 0 (when the predicted landmark is completely different to the real one in terms of spatial location and associate activity) to 1 (when there is a perfect match between the real and the predicted landmark). Finally, if the system provided more than one
4.2. Dataset Preliminary Analysis
Before getting deep into the evaluation of the proposal, we extracted some interesting features of both datasets. In that sense, Figure 12 shows the probability distribution of spatial distance and time intervals between consecutive tweets of the same user.

Complementary Cumulative Distribution Function (CCDF) of spatial distance and time elapsed between consecutive tweets.
From this figure we can see that, in terms of spatial distance between consecutive tweets (Figures 12(a) and 12(b)), short distances are more likely to appear (50% of the tweets in MU and MA are separated by less than 100 m). Nonetheless, longer distances are still likely. Regarding the distribution of time intervals (Figures 12(c) and 12(d)), very long intervals are less likely than shorter ones (50% of the tweets in MU and MA are separated by more than 24 hours). Therefore, we appreciated certain laziness of the Twitter users as they tend to tweet not very frequently and usually not in very different places.
4.3. Effect of Landmark Size
One of the factors that affects most the system performance is the spatial size of the landmarks. This size is mainly defined by the Eps and MinPoints parameters of the landmark discovery algorithm. Figure 13 depicts the PR and PE of the proposal for different Eps × MinPoints configurations for

PR and PE of the system with different configurations of Eps × MinPoints.
As we can see, the size and density of the landmarks are correlated with the PE and PR in both datasets. Regarding the decrease of PR, it has to do with the minimum density required for the landmarks. As it was put forward in Section 3.4.3, LDA does not return any landmark until it receives at least MinPoints of close tweets locations. Consequently, if we increment this factor, the system will have more locations without any assigned landmark (the ones received before getting MinPoints to conform a landmark) which, as a result, decreases the overall PR of the system.
As far as PE is concerned, its decrement trend is related to the spatial dimension of the landmarks. If we increase Eps, which defines the initial radius of a landmark, then the spatial region covered by each landmark will be larger. Hence, in case the system wrongly predicts the next landmark of a user then the distance of this predicted landmark's middle point and the real one will become larger if both elements cover wide spatial regions.
Consequently, given the stated results, we selected the configuration

Collective and personal landmarks for the selected Eps × MinPoints configuration.
4.4. Memory Saving Evaluation
One of the most improvements of the present work regarding the original LDA is the new mechanism that avoids keeping in memory all the locations collected so far. To give insight into the actual memory saving that we can achieve, Figure 15 shows the overall number of points the system kept in memory to generate the personal landmarks. The number of stored locations is shown with respect to the sheer number of received locations as the system proceeds.
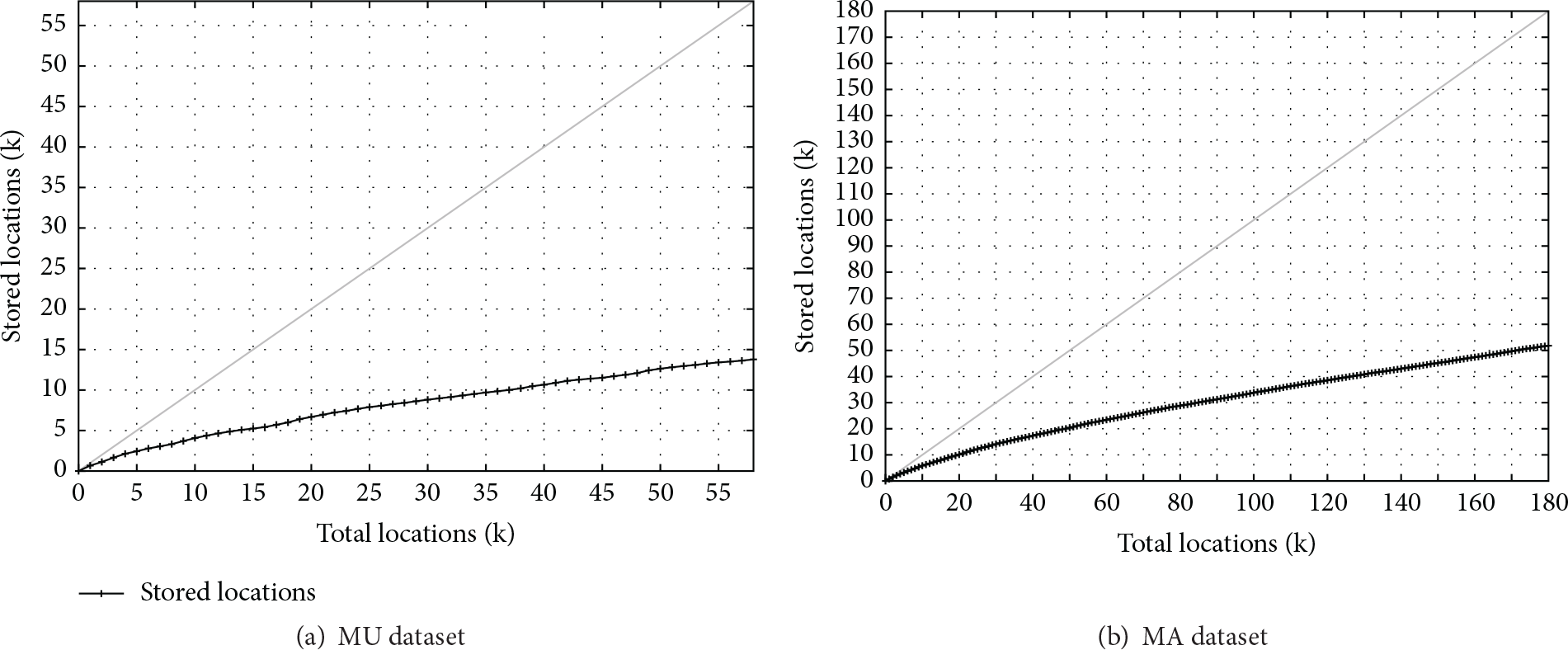
Total number of locations actually stored by the client sides of the proposal. The grey line depicts the imaginary progression of stored locations without the memory saving mechanism.
According to these results, we reduced the number of points in memory up to 75% in both scenarios. Recall that these landmarks are composed in the client side running in the users' contrivances. Thus, this saving is of great utility to enable density-based clustering techniques in memory-constrained scenarios.
4.5. System Performance Evolution
One of the key features of the system is its ability to compose mobility models and make predictions over them on the fly. However, one drawback of this approach is that the system will need a certain convergence period so as to compose a preliminary model rich enough to provide the first predictions. Figure 16 shows the PR and PE as the system processed the dataset. In order to come up with a more reliable test, we have evaluated the system with 5 different subsets each one comprising a slide of the original dataset with 70% of its tweets.

Evolution of the PR and PE of the system.
From this figure, we can appreciate that the PE remained more or less flat with no significant variance throughout all the experiment in both datasets. This way, when only 10% of the dataset was processed our proposal was capable of achieving around 0.85 PE. The reason for this quite high PE even when only a small piece of the dataset has been processed is the spatial distribution of the tweets. As we pointed out in Section 4.2, users tend to post tweets located relatively close among them. This limits the number of total locations that should be considered by the system and, thus, it is more likely to correctly predict the next location of a user. For the sake of clarity, Figure 17 shows the distribution of users with respect to their number of landmarks. In both datasets, the vast majority of users only have one or two different places. This facilitates the achievement of high PE.

Probability distribution of the number of landmarks per user in both datasets.
Concerning the PR, it follows a quite different trend in MA and MU. In the former, the PR remained stable around 13% when the system processed 20% of the dataset. However, in MU, this measurement remarkably varied during the whole experiment. These variations are due to the graph hierarchies generated in the two scenarios. In this frame, MA has much more active users than in MU. Hence, the system is able to generate a complete set of collective landmarks. Since this type of landmark provides support when it is not possible to assign a personal one and, thus, provide a prediction, the generation of a dense network of collective landmarks is a key factor for PR. Figure 18 depicts the evolution of number of collective and personal landmarks along with the sheer number of edges in the personal graphs

Evolution of the number of personal and collective landmarks along with the number of edges in the personal graphs.
4.6. Comparison with Alternative Subapproaches
This section is devoted to comparing the present proposal with some of its slight variations so as to uncover which aspects are actually relevant so as to predict future locations and activities with social media data. For that goal, four potential alternatives of the original (O) approach have been considered; namely,
no-activity (NA) approach stands for a predictor that does not take into account the current activity of the topic. Therefore, the nodes in the personal and collective graphs only comprise spatial information. The hierarchy of graphs remains the same as in the original approach, no-collective (NC) approach does not have any graph hierarchy, so only the personal graph hierarchy no-activity-no-collective (NANC) approach does not take into account the activity to compose the graphs and make predictions. Moreover, only the personal graph hierarchy no-time-hierarchy (NTH) approach differs from the original approach in the graph hierarchy. In this case, there is neither
Table 4 summarizes the key features of each subsolution. While the no-collective versions (NC, NANC) could be suitable for those deployments where the frequent connection between personal mobile devices and a central server is not desired, the no-activity ones (NA, NANC) could be a proper solution for domains where only spatiotemporal knowledge should be mined.
Alternative subapproaches summary.

Figure 19 depicts the prediction accuracy of the present proposal (original) and the aforementioned alternatives. Since some of them do not infer the activity, the PE in this figure only considers the spatial distance factor and not the SHS. Hence, a uniform evaluation is performed.

Comparison between the original approach and different variants.
From the aforementioned figure we can draw interesting conclusions. To start with, the most noticeable one is that we observe similar results in both datasets. Therefore, the temporal and spatial size of the dataset under consideration do not really affect the behaviour of each alternative.
Focusing on each of these alternatives, we can see that relying on a collective graph hierarchy
Secondly, discarding the activity as parameter to provide predictions increases the PR but inevitably also decreases the accuracy of the predictions. In that sense, the extra level of indexation that the activity provides in the mobility model allows one to meaningfully refine the prediction.
Lastly, according to Figure 19, the time-based graphs allows one to slightly increase the accuracy of the system with respect to the subapproach NTH. Like the activity, considering the time factor adds a new level of indexation in order to select the appropriate path within a graph for making a prediction. As a result, such selection is done in a more accurate manner.
4.7. Mobility Graphs Example
In this section, an actual personal mobility graph
4.7.1. User #1
Figure 20 shows

Personal mobility graph of User #1 in MU.
For the sake of completeness, Figure 21 locates each landmark in a map. In that sense,

Map of landmarks of User #1 in MU.
Moreover, four types of routes of the user were uncovered
4.7.2. User #2
This user has been extracted from the MA dataset. The system was able to recognize three different personal landmarks according to his graph in Figure 22. Again, we can intuitively infer that

Personal mobility graph of User #2 in MA.
Finally, Figure 23 shows the location of the three landmarks in Madrid city.

Map of landmarks of User #2 in MA.

Basic activities taxonomy.

Activities within community taxonomy.
All in all, both users have one landmark with higher number of activity tags compared to the others. This landmark can be usually mapped to the user's home. In addition to that, landmarks representing the user's office/school and his favourite/most visited leisure place have been also uncovered. The discovery of these three types of regions makes sense as they are probably the places where a person spends more time and, thus, writes most of his tweets.
4.8. Results Discussion
On the whole, the present evaluation has allowed coming up with several interesting conclusions about the proposal and Twitter itself as mobility data-source:
Firstly, an analysis of datasets of two different cities shows that half of Twitter users tend to write no more than one tweet per day and in very close locations. Therefore, they seem rather reluctant to write several tweets in many different locations. The spatial size configuration for the landmark should be carefully selected beforehand as this parameter meaningfully affects the system performance. According to the results for the two datasets under evaluation, it is more suitable to define small landmarks with low density of points given the aforementioned laziness of users. The modification of the density-based clustering to avoid keeping in memory all the processed locations achieves savings of more than 75% in terms of stored locations. This can be a suitable approach to execute this type of clustering in memory-constrained scenarios. Results confirm that the PR of the system is closely related to the level of detail of the graph hierarchy. In that sense, the generation of collective landmarks has proved to be an interesting approach to keep in acceptable terms the PR. Finally, the devised hierarchy of mobility graphs comprising personal and crowd-sensed knowledge allows combining both types of information in a suitable way. In particular, the collective hierarchy
5. Conclusion
The endless improvement of built-in positioning sensors in personal mobile devices and the pervasiveness of social media data allows capturing an unprecedented amount of location data that is not constrained to the spatiotemporal dimension but also enlarged with semantic meaning.
The present work intends to be one of the first steps towards the full usage of both the spatiotemporal and semantic aspects of the aforementioned type of data. In particular, given the geotagged tweets within an area of interest, the devised solution is able to extract the mobility flows at different levels of detail by means of a crowd-sensing approach. In order to orchestrate the different components of the proposal, the Complex Event Processing (CEP) approach has been applied. Moreover, a complete evaluation of different features of the solution with two real-world datasets has been described.
To conclude, further work will focus on coming up with automatic detection of similarities among groups of users in terms of mobility and activity. This will generate intermediate mobility graphs, related to specific groups of users, allocated between the personal and the collective ones. This would enrich even more the proposed graph hierarchy.
Footnotes
Competing Interests
The authors declare that they have no competing interests.
Acknowledgments
This paper has been also possible partially by the European Commission through the H2020-ENTROPY-649849 and the Spanish National Project CICYT EDISON (TIN2014-52099-R) granted by the Ministry of Economy and Competitiveness of Spain (including ERDF support).