
Abstract
Suppressing the trajectory data to be released can effectively reduce the risk of user privacy leakage. However, the global suppression of the data set to meet the traditional privacy model method reduces the availability of trajectory data. Therefore, we propose a trajectory data differential privacy protection algorithm based on local suppression Trajectory privacy protection based on local suppression (TPLS) to provide the user with the ability and flexibility of protecting data through local suppression. The main contributions of this article include as follows: (1) introducing privacy protection method in trajectory data release, (2) performing effective local suppression judgment on the points in the minimum violation sequence of the trajectory data set, and (3) proposing a differential privacy protection algorithm based on local suppression. In the algorithm, we achieve the purpose Maximal frequent sequence (MFS) sequence loss rate in the trajectory data set by effective local inhibition judgment and updating the minimum violation sequence set, and then establish a classification tree and add noise to the leaf nodes to improve the security of the data to be published. Simulation results show that the proposed algorithm is effective, which can reduce the data loss rate and improve data availability while reducing the risk of user privacy leakage.
Introduction
With the development of positioning technology and the popularization of intelligent devices, a large number of trajectory data of moving objects are produced, and the information contained in these trajectory data makes the in-depth study and analysis of trajectory data becomes a research hot spot in the field of data mining.1–4 Through the analysis and exploration of trajectory data, researchers obtain a large amount of valuable information to study the privacy protection of user information. If the security of the data is not ensured during the analysis and mining of the data, the attacker with background knowledge can infer the user’s privacy information by analyzing the trajectory data,5–7 resulting in the disclosure of the user’s privacy information, and threatening the user’s property security. However, if the processing of the trajectory data set is too strict, the integrity of the data set will be lost, the availability of information will be greatly reduced, and the digging value of the data set will lose, resulting in a waste of information.8,9 So how to ensure that the published trajectory data does not reveal the privacy of users while having high data availability is an important research topic.
At present, some achievements have been made in the research of privacy protection methods in trajectory data release. For example, Mohanmmed et al. 10 propose an LKC-privacy model suitable for radio-frequency identification (RFID) data and used an anonymous algorithm to implement the LKC-privacy model; the algorithm first identifies the minimum violation sequence set in the trajectory data set, and then global suppression of the violation sequence is carried out by the Greedy method to minimize the loss of the maximum frequent sequence. However, the global suppression method needs to remove a large amount of data, which does not effectively improve the data availability. In Ghasemzadeh et al., 11 the authors realize the privacy protection of trajectory data using global suppression after researching the situation of C = 1 in the LKC-privacy model. Chen and others 12 propose the concept of local suppression by (K,C)L-privacy model and algorithm; this algorithm first determines all sequences in the trajectory data set that do not meet the requirements of the (K,C)L-privacy model, and then simplifies the trajectory data set by local suppression under the premise of ensuring the efficient availability of data. However, there is no detailed suppression scheme for the location point in the process of local suppression, so it will produce a new minimum violation sequence and increase the suppression cost. According to the relationship between privacy correlation degree and data utility, Jing et al. 13 proposed to improve the global suppression operation of trajectory data to only suppress part of trajectory data when the trajectory data are processed anonymously. The trajectory sequence with higher frequency is processed first, so as to reduce the number of positions to be suppressed. However, this algorithm will also produce new points to be suppressed in the process, so the time complexity is relatively high.
Through the above analysis, we find that local suppression can effectively solve the problem of reducing data availability caused by global suppression, but it is possible to produce a new minimum violation sequence in the process of suppression, which may lead to the risk of data privacy disclosure again. Therefore, we need effective local suppression so that it does not produce a new minimum violation sequence in the process of data processing, which helps to improve the security and availability of data. So, in this article, we focus on improving the security of user trajectory data release process and reducing the degree of data loss due to global suppression or other ineffective local suppression and proposing a trajectory data differential privacy protection algorithm based on local suppression which satisfies the LKC-privacy model. In the algorithm, we first find out the subsequences that satisfy the effective local suppression in the frequent sequences, and then judge the effective local suppression of the points in the subsequences, avoiding the occurrence of new minimum violation sequences due to invalid inhibition judgment. The analysis results of a large number of trajectory data sets show that compared with other algorithms, the algorithm can effectively reduce data loss while ensuring the security of trajectory data release. The rest of this article is organized as follows. In section “Relevant work,” we describe some related work. In section “The basic idea of the algorithm,” we explain the proposed algorithm in two parts: one is the relevant design ideas and the other is the algorithm description. We also perform some experiment to evaluate our proposed algorithm along with two scenarios for better illustration. Finally, we conclude this article in section “Conclusion.”
Relevant work
This section mainly describes some basic research works and related concepts, including trajectory, violation sequence, frequent sequence, classification tree, and so on.
Trajectory and sequence
Trajectory
Trajectory is a sequence of moving object’s position information sorted in chronological order; generally, it can be expressed as
Definition 1 (trajectory data set)
In Table 1,
A trajectory data set T containing sensitive attributes.
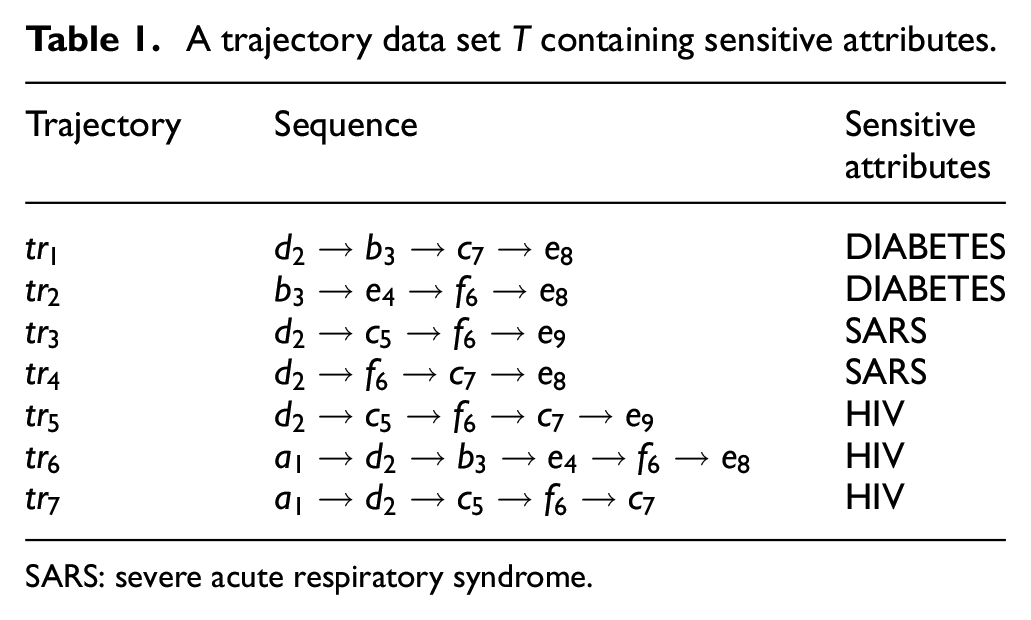
SARS: severe acute respiratory syndrome.
LKC-privacy
Definition 2 (violation sequence)
Suppose the length of the sequence
Definition 3 (minimum violation sequence)
If the sequence
Definition 4 (frequent sequences)
Given a threshold
Definition 5 (maximum frequent sequences)
If a sequence
Classification tree
Classification trees
For a given trajectory data set, sensitive information items in the data set are used as leaf nodes of the classification tree, and generalized leaf nodes become nodes of the classification tree, and the root nodes of the classification tree are the sets of all leaf nodes. 16 Figure 1 shows a simple classification tree about garbage classification.

Garbage classification tree.
Differential privacy
Differential privacy protection is a privacy technology based on data distortion, using noise technology to make sensitive data distortion, but at the same time keep some data or data properties unchanged. Differential privacy protection can guarantee that adding or deleting a piece of data in a data set will not affect the query output result, so even in the worst case, all sensitive data known to the attacker except a record can still guarantee that the sensitive information of this record will not be leaked.
Differential privacy
There is at most one different record between the given two data sets:

In the inequality,
Definition 6 (global sensitivity)
For any function

where
Theorem 1 (Laplace mechanism)
For any function

In the inequality,
Definition 7 (count queries)
For the given trajectory data set T and sequence q, the count of count query R to data set T is
Definition 8 (average relative error)
Average relative error is used to measure the utilization of trajectory data set

where
The basic idea of the algorithm
In order to ensure the security of user privacy information in trajectory data set while ensuring the availability of data to be published, this article proposes a trajectory data differential privacy protection algorithm based on local suppression. In the algorithm, we use the method of effective local suppression judgment to avoid the trajectory sequence to produce a new minimum violation sequence, at the same time, we constantly update the original minimum violation sequence set in the trajectory sequence so that all trajectory sequences satisfy the LKC-privacy model, this processing effectively avoids the over-repression of information brought by global suppression and improves data availability. Second, the classification tree is based on trajectory data information and noise is added to leaf nodes to improve the security of user privacy information.
The algorithm flowchart is shown in Figure 2.
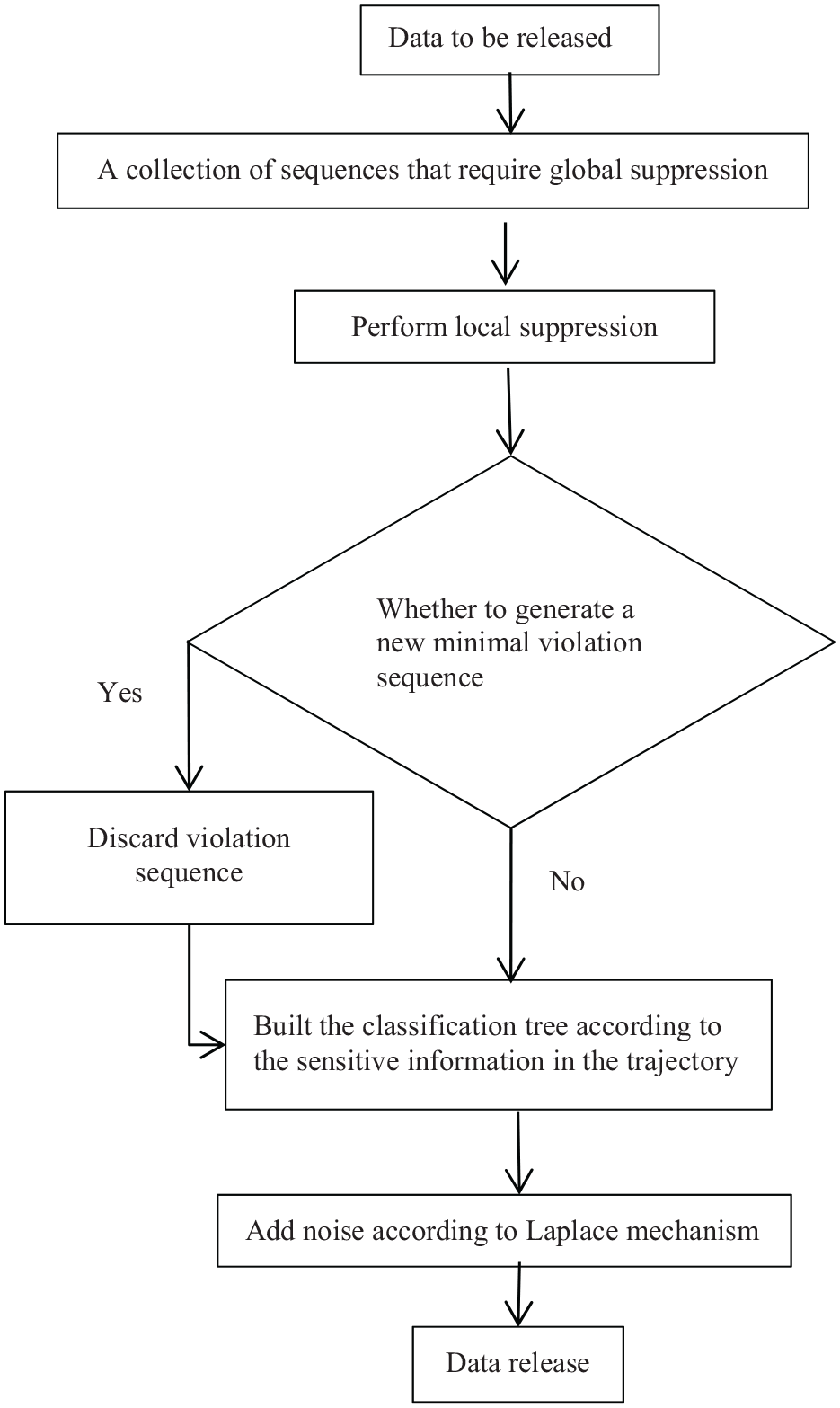
Computational flowchart.
The algorithm first calculates the updated minimum violation sequence

where

In the second part, the classification tree is constructed using the data iteratively processed by the LKC-privacy model of the trajectory data set, and the sensitive information is protected by the Laplace noise mechanism.
19
First, initialize the data set

Algorithm analysis
The first part of the algorithm Trajectory local suppression (TLS, Steps 1–18 in the above algorithm) first identifies the minimum violation sequence (MVS) in the original trajectory data set T, then constructs the MFS tree according to the maximum frequent sequence set, and then determines the suppression by the suppression priority score
The second part of the algorithm Trajectory classification tree node (TCN, Steps 19–43 in the above algorithm) first initializes the original trajectory data set T and establishes iteratively the classification tree
Results of the experiment
Experiment environment and data set
This experiment runs in Python environment and is implemented by MyEclipse integrated development software. The experiment hardware environment: processor is Intel® Core™ i7-5500U CPU 2.40 GHz, RAM is 8.0 GB, and Linux operating system is adopted in this article. The open-source data set provided by the Geolife project of the Institute of Continental Studies,20,21 which contains 18,670 real user traces, is widely used in trace data–related research experiments.
Measurement criteria
Data loss is an important reference to measure the influence of an algorithm on the availability of trajectory data. This article measures from three aspects: frequent sequence (MFS), trajectory sequence, and average relative error: 22
1. MFS data loss (MFSLoss) depends on the number of MFSs in the original trajectory data set and the number of MFSs remaining in the data set after local suppression processing
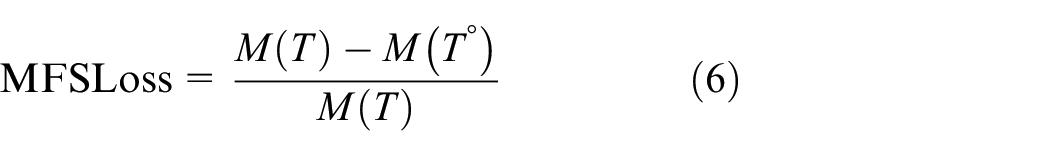
where
2. The trajectory sequence loss (TLoss) depends on the number of sequences in the original trajectory data set and the number of sequences processed

where
3. The algorithm calculates the average relative error of data by counting query; the results will be regarded as the standards of measuring data loss. 17 The error formula is shown in Definition 12.
Results of the experiment
In order to verify the validity of this algorithm, the TLS algorithm in this article is compared with the Trajectory Privacy-preserving based on Non-Sensitive information Analysis (TPNSA) algorithm in Jinsong et al. 23 The anonymous number K and the confidence threshold C in the algorithm have different effects on the experimental results, so the experimental results of the two algorithms are compared under different values of K and C:
1. Effect of different K values on data loss.
From the experimental results in Figures 3 and 4, as the K value increases, the MFS loss and the sequence loss also increase, since an increase in the K value leads to an increase in the MVS, that will lead to an increase in the sequence which needs to be suppressed, so the loss of data increases. Although TP-NSA algorithm has certain utility to reduce data loss, it does not optimize the MVS in the trajectory data set and does not effectively utilize the advantage of local suppression, so the TLS algorithm in this article causes less loss to the data.
2. Effect of different C values on data loss.

Effect of different K values on MFS loss rate.

Effect of different K values on sequence loss rate.
It can be seen from the experimental results in Figures 5 and 6 that the MFS loss and the sequence loss decrease with the increase in the C value, and the MFS loss and the sequence loss are both due to the decrease in the number of MVSs to be suppressed due to the increase in the C value step-by-step reduction. The experimental results can be seen that whether the increasing value is K or C, the data processing results of this TLS algorithm are always superior to those of the TP-NSA algorithm in the literature, 23 because the TLS algorithm is based on the suppression point score priority to determine the suppression order, and reasonably update the MVS, which can better reduce the loss caused by data suppression.

Effect of different C values on MFS loss rate.

Effect of different C values on sequence loss rate.
For average relative error, the experimental results of Hierarchical data fusion publishing mechanism (HDFPM) in Li et al. 19 are compared with those of TCN algorithm in this article. The experimental results show that the average relative error of the data increases with the increase in the length of the trajectory data set, but the average relative error of the data decreases with the increase in the privacy budget. The experimental results show that compared with HDFPM algorithm, the TLS algorithm used in this article can reduce the average relative error and effectively protect the user’s trajectory privacy while improving the availability of data, because the trajectory data classification tree of this algorithm is established on the basis of the processed data through local suppression, which avoids the data distortion caused by adding too much Laplace noise. The results are shown in Figure 7 and Figure 8.

Effect of data set length on average relative error when
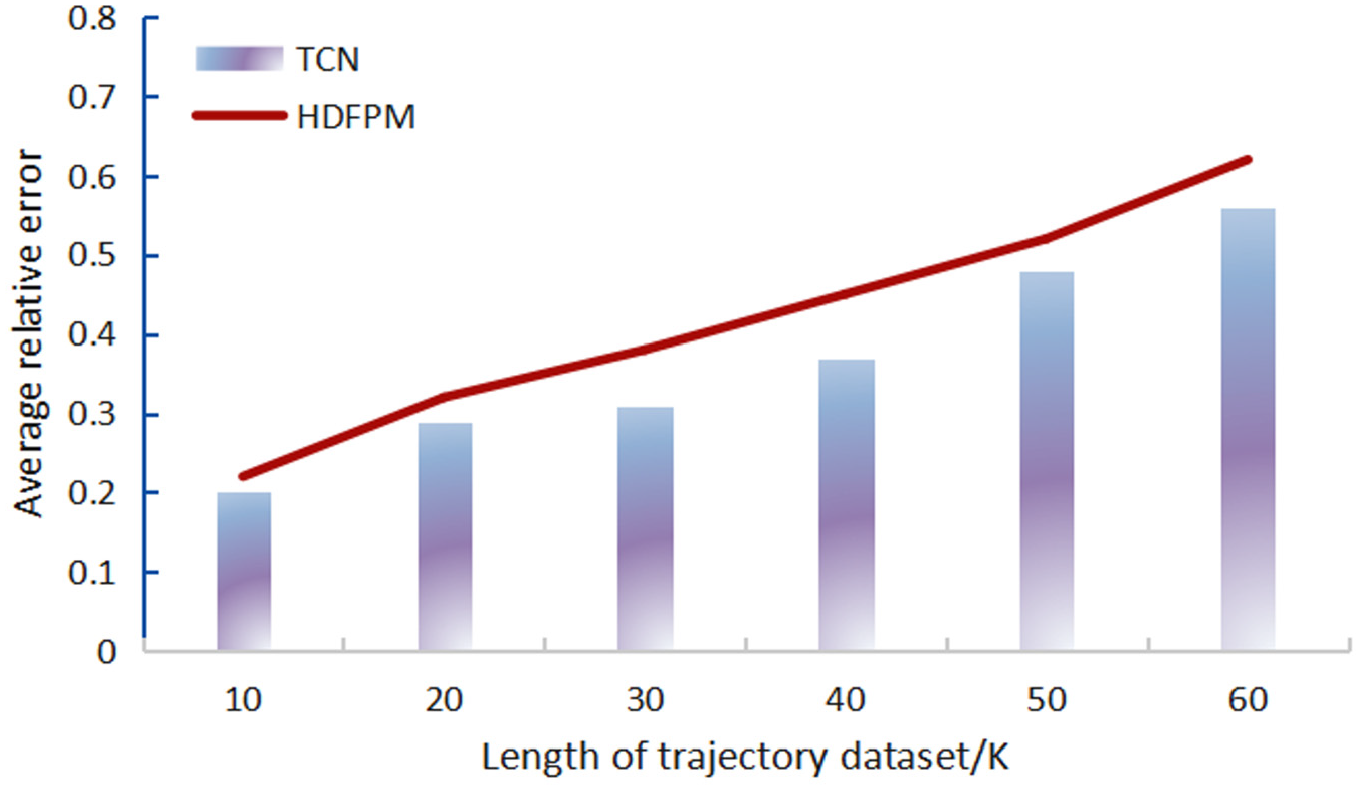
Effect of data set length on average relative error when
Conclusion
A trajectory data differential privacy protection algorithm based on local suppression is proposed by this article. In the process of data release processing, local suppression is used instead of global suppression, which effectively solves a large amount of data waste caused by global suppression and improves the availability of published data. According to the Laplace mechanism, differential privacy protection processing of classification trees based on trajectory data information ensures the security of user privacy information. Compared with other algorithms, the proposed algorithm reduces the data loss rate to a certain extent, and in the data security aspect, the average relative error is smaller under the same noise addition state, and the data privacy is not increased at the same time with significant data distortion. Further research and analysis on data release will continue in the future.
Footnotes
Handling Editor: Yanjiao Chen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported, in part, by the National Natural Science Foundation of China (no. 61802161), the Department of Education of Liaoning Province (no. JZL202015402), and the Natural Science Foundation of Liaoning Province (nos 2020-MS-291 and 2020-MS-292).