
Abstract
Aiming at the problems existing in existing steganalysis algorithms, this article proposes Motion Vector Coding Cost Change video steganalysis features based on Improved Motion Vector Reversion-Based features and Subtractive Probability of Coding Cost Optimal Matching features based on Subtractive Probability of Optimal Matching features from the perspective of the change of coding cost. Motion Vector Coding Cost Change features can be well consistent with the coding cost before recoding by analyzing the sub-pixel coding cost of recoding. By counting the sub-pixel coding costs of motion vectors before and after video recoding, the Sum of Absolute Difference values of motion vectors instead of predicted residuals are applied to steganalysis and detection, and the steganographic algorithm based on motion vectors is effectively detected. Experiments show that Motion Vector Coding Cost Change features have higher detection accuracy than Add-or-Subtract-One, Improved Motion Vector Reversion-Based, and other typical features in various steganography methods, and Subtractive Probability of Coding Cost Optimal Matching features have higher detection effect and better robustness than Subtractive Probability of Optimal Matching features.
Keywords
Introduction
Traditional steganography and steganalysis techniques are mostly targeted at image carriers, and the technology is becoming more mature. As one of the most popular media in the Internet, video is composed of a series of spatially and temporally related images. It has a larger amount of data than a single frame image and can accommodate more secret messages. To this end, more researchers have turned their attention to steganography and steganalysis of video carriers.
Video steganography in compressed domain is the main research direction, which can be divided into special type and general type. The special video steganalysis techniques in compressed domain can be divided into four types: steganalysis method based on intra prediction mode, steganalysis method based on transformation coefficient, steganalysis method based on inter prediction mode, and steganalysis method based on MV (Motion Vector).
For steganalysis method based on intra prediction model, Zhao et al. 1 proposed that the intra prediction mode reverted to the original mode after the video was recompressed. Therefore, designing 13-dimensional IPMC (Intra Prediction Mode Calibration) features by calculating the coding cost change of macroblocks in the intra prediction mode could have better detection results for the steganography method based on the intra prediction mode. For steganalysis method based on transformation coefficient, Wang et al. 2 applied the DCTR (Discrete Cosine Transform Residual) 3 features for image steganalysis to the video, constructed the features of 1440 dimensions from the perspective of the temporal and spatial correlation change of the video, and had a good detection accuracy rate for steganography based on DCT (Discrete Cosine Transform) coefficient. For steganalysis method based on inter prediction model, in Zhang et al., 4 the phenomenon that the intra prediction mode reverts to the original model after recoding is also used. By calculating the changes of the intra prediction mode before and after recoding, the 40-dimensional features were designed, which had a good detection effect.
Research on video steganalysis based on MV is relatively mature, which can be divided into four types. The first method is to take advantage of the statistical properties of MV. Su et al. 5 constructed a 12-dimensional feature, which comprehensively utilized the central moment of MV histogram from both time domain and space domain. In Zhang and XiJian, 6 the method of temporal and spatial correlation based on pixels is applied to steganographic method detection based on MV. Ye et al. 7 used four-phase scanning to construct the symbiosis matrix to capture the abnormal changes in the space-time correlation of MVs caused by steganography. Tasdemir et al. 8 transferred the SRM (Spatio Rich Model) applied in the field of image steganalysis into the video field, and detected the temporal and spatial characteristic changes of MVs in three dimensions, which has a good effect. However, this method can extract higher characteristic dimensions, and the calculation is more complex and time-consuming. The second is to use the MV calibration method. Cao et al. 9 found through experiments that MV tended to recover to the original when video was re-encoded. A 15-dimensional Motion Vector Reversion-Based (MVRB) feature was designed by utilizing the distance offset of MV before and after video recompression and the change of predicted residual size. On this basis, Wang et al. 10 proposed the IMVRB (Improved Motion Vector Reversion-Based) steganalysis features of video. This method first decoded the video to obtain the available parameters, and then selected the motion prediction method to re-encode the video through the distance offset of MV. This method obtained the available parameters and simulated the unavailable parameters, which had better detection effect than MVRB features. The third method uses the local optimality of MV to determine whether steganography exists. Wang et al. 11 proposed an 18-dimensional steganalysis feature of Add-or-Subtract-One (AoSO) video by taking advantage of the locally optimal property of MV after coding, namely, SAD (Sum of Absolute Difference) minimization. The AoSO feature constructs features by adding or subtracting the SAD value within a range of the MV neighborhood. AoSO is the most effective feature of MV steganography. The fourth method is based on adaptive method to determine whether steganography exists. Wang et al. 12 divided video subsequence by computing the dynamic attitude (Frame Dynamic Degree) of video frames, and carried out feature extraction for subsequence with high dynamic attitude, which is helpful to improve detection accuracy.
The general video steganalysis techniques in compressed domain are still in research stage. In Liu and Li, 13 the convolutional neural network for image steganalysis was improved. The SRM 14 algorithm was used to input the neural network to distinguish the original video frame and the encrypted video frame, which could detect the steganography method based on MV and the steganography method based on intra prediction mode.
In this article, a video steganalysis method based on coding cost change is proposed, which improved the IMVRB feature based on the coding cost change of MV before and after recoding and the SPOM (Subtractive Probability of Optimal Matching) feature based on the coding cost change of local optimal probability, so as to improve detection performance and robustness. This method could also effectively detect the video steganography method which better maintains the local optimalness of the MV’s SAD (Sum of Absolute Difference) value.
Analysis of the variation of recompressed coding cost value
Most of the motion-based steganalysis methods use the characteristics of the MV’s SAD value. Due to the existence of quantization errors, although the MV offset of the video is small after recompression, the SAD value of the MV has changed greatly before and after re-encoding, even in the same prediction mode. This section mainly analyzes the coding cost change of the MV before and after re-encoding.
Let


where
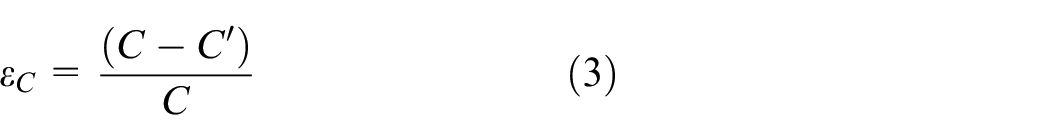
In the case that coastguard_cif.yuv sequence is selected from the standard video library website, and the macroblock size is set to 16. JM coding software was used for compression coding, and the

Variation of the motion vector coding cost value of the first 60 frames of the coastguard_cif.yuv sequence.
Through the analysis in Figure 1, it can be found that in the case of recoding with the same prediction pattern, despite the quantization error, the coding cost value of the video MV will not change greatly before and after the recoding. Even if it changes, the change is modest. Compared with the change of SAD value, the distribution is relatively concentrated, especially the high proportion that the coding cost value of MV can keep consistent. Although there are quantization errors, the key feature of the improved steganalysis method based on MVs is the consistent proportion of MVs before and after recoding.
Analysis of the selection of coding cost’s variation features
Selection of coding cost’s variation features
In the process of video recoding, although due to the existence of quantization error, the coding cost value of video MV generally will not change greatly before and after recoding, especially the consistent proportion is very high. Further analysis will be carried out in the following.
First, decode the original video and the re-encoded video, then record the decoded MV of the original video and the prediction residual matrix to calculate the coding cost value, and finally, use the same method to calculate the coding cost value of the re-encoded video for the sub-pixel coding cost calculation. For macroblock

Let
Three classic video sequences are selected from the standard video library website: bus_cif.yuv, mobile_cif.yuv, and coastguard_cif.yuv. By compressing the three video sequences separately, the respective carrier video, the MV larger component least significant bit (LSB)+1 steganographic video, and the larger component LSB of the MV match embedding steganographic video are obtained. The experimental statistics have the following rules after decoding and re-encoding: the proportion that the same macroblock’s coding cost of the carrier video without steganographic techniques after the decoding and recompression remains consistent is high, that is, the ratio that the value is 0 is very high. Steganography reduces this ratio and the value changes greatly after recompression compared with decoding. The specific experimental results are shown in Table 1.
Carrier video’s, LSB+1 steganographic video’s, and LSB matching steganographic video’s

LSB: least significant bit.
It can be seen from Table 1 that the probability value of the carrier video
The MV and coding cost information of the video macroblock is used for feature calculation. Through the foregoing analysis, the probability value
The feature set 1

This feature set is consistent with the feature set of the IMVRB, reflecting the change of the MV before and after the video recompression.
The feature set 2

where

The feature set 2 counts the variation of the sub-pixel coding cost of the MV with an offset distance k, where
The feature set 3

where

The feature set 3 counts the comprehensive variation of the sub-pixel coding cost of the MV with an offset distance k and offset distance.
The MVCCC video steganalysis feature proposed in this article uses the above three feature sets and the probability value
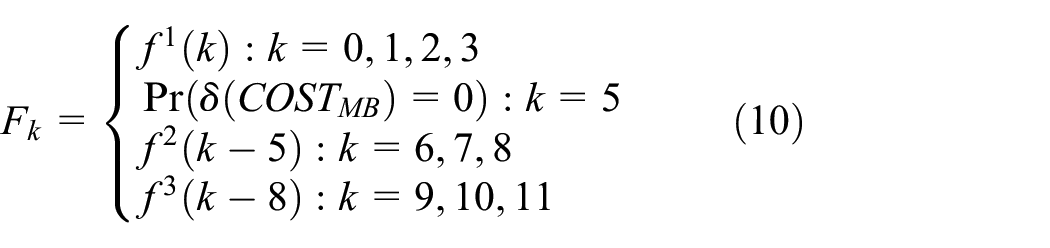
In order to visually observe the discrimination of the above features, a sample carrier video and steganographic video are selected to extract the above 11-dimensional features, as shown in Figure 2.
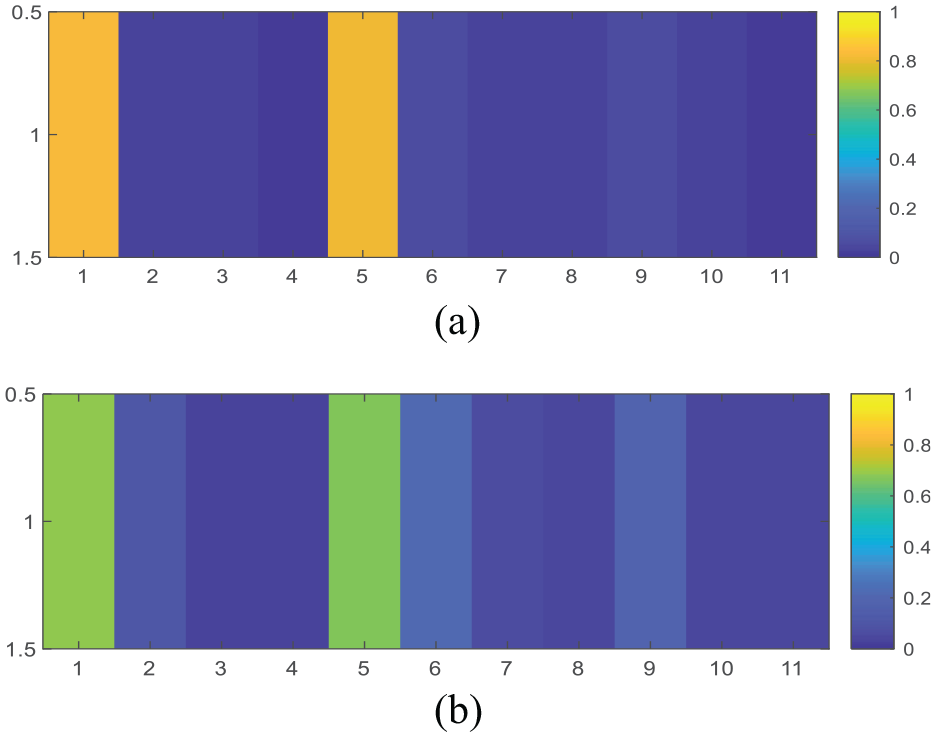
Extracting sample features for (a) carrier video and (b) steganographic video.
It can be observed that the probability that the MV offset distance of the first-dimensional feature is 0 is consistent with the sub-pixel coding cost before and after the re-encoding of the fifth-dimensional feature of the carrier video is significantly larger than the steganographic video, but the change in the sub-pixel coding cost of the 6th–11th dimensions and the comprehensive variation of the MV and sub-pixel coding cost of the carrier video are smaller than the steganographic video.
Finally, the support-vector machine (SVM) is used for classification, and the Gaussian kernel function is selected
15
. The penalty factor used includes
Selection of the variation features of the probability of coding cost optimal matching
Through the introduction above, when the video is re-encoded, although the video MV SAD value and the coding cost value may change before and after the re-encoding due to the existence of the quantization error, the variation of the SAD value and the probability value of coding cost optimal matching need further analysis. Given a video segment

Similarly, for a macroblock MB, the MV has the least cost
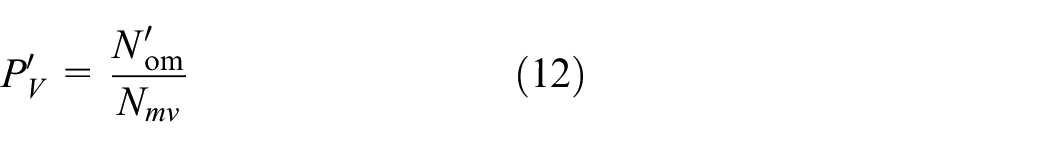
The recompressed video is defined as

Similarly, the variation of probability of coding cost optimal matching before and after the video re-encoding is defined as

First, the impact of steganography on video CCPOM is analyzed. Three classic video sequences are selected in the standard video library website which are bus_cif.yuv, soccer_cif.yuv, and coastguard_cif.yuv, respectively. The respective carrier video and MV larger component LSB+1 steganographic video are obtained by compressing the first 150 frames of the three video sequences, respectively. The experimental steganography operation has the effect on the video CCPOM is as follows: the probability of carrier video’s coding cost optimal matching CCPOM without steganography operation is higher, and the CCPOM value of the steganographic video is lower. The specific experimental results are shown in Table 2.
CCPOM% of carrier video and LSB+1 steganographic video.

CCPOM: Coding Cost Optimal Matching; LSB: least significant bit.
It can be seen from Table 2 that the CCPOM value of the original carrier video is high, and the steganographic video will reduce the probability of local optimization of the coding cost, that is, the CCPOM value will be much lower.
Then, the effect of the steganographic operation on the variation of the probability

LSB: least significant bit.
It can be seen from Table 3 that the probability
Referring to the design idea of SPOM video steganalysis features, SCCPOM (Subtractive Probability of Coding Cost Optimal Matching) feature design is divided into the following two feature sets:
The feature set 1

The feature set reflects the change of the probability of SAD which is locally optimal before and after video recompression, and k is 0, 1, 2, 3, and 4, respectively, represent the calculated values
The feature set 2

The feature set reflects the variation of probability of coding cost optimal matching before and after video recompression, and
The SPCCOM (Subtractive Probability of Coding Cost Optimal Matching) video steganalysis feature proposed in this article uses the above two feature sets, the original position SAD and the design of the probability of coding cost optimal matching,
The SPCCOM feature has a total of 12 dimensions. The specific formula is as follows

The feature includes the SAD value of the video MV at its original position, the position where the vertical component is incremented by one, the position where the horizontal component is decremented by one, the position where the vertical component is decremented by one, and the position where the horizontal component is incremented by one and the variation value of probability of coding cost optimal matching before and after the recompression which enhances robustness compared to SPOM. This feature also includes the SAD of the video MV and the probability values of coding cost optimal matching, namely, POM and CCPOM. Because the two values of different videos are different in size, and the situation which the original MV is close to the local optimum is not the same. Therefore, some videos with low values will be misjudged as steganographic videos. If these videos are not steganized, the SAD values before and after re-encoding and the variation of the probability of coding cost optimal matching will be low. A proposal to combine the two is proposed and classification method is the same as the previous section.
Design of the steganalysis method
Design of the steganalysis method based on the variation of coding cost value
Through the analysis of the selection of coding cost features in the above section 2.1, it can be found that the proportion of the MV’s coding cost of the carrier video which is consistent before and after re-encoding is high, while the corresponding proportion of the steganographic is low, which has a good distinguishing effect. So this phenomenon can be used to design one-dimensional features. In addition, the IMVRB video steganalysis feature based on the method of restoring MV proposed in the previous section uses the variation of the prediction error SAD before and after re-encoding to design features, but the prediction error is not a key component of video coding motion estimation calculation. So, the change of prediction error is used to design features, although the change after video steganography can be reflected to some extent, it is still not an accurate solution. It can provide better detection results for simple steganographic methods such as Xu et al. 17 and Aly, 18 while reduce the embedding rate and the distortion of the video after the steganographic operation for the method proposed by Cao et al. 19 for STC (syndrome-tellis codes) coding technology 20 to a large extent. Therefore, using prediction error to analyze steganographic operations is no longer sufficient. Although this cannot be met, this idea can be used to design features that change the coding cost by reflecting the changes in the coding cost before and after re-encoding.
The SATD (Sum of Absolute Transformed Difference) value of the H.264 video sub-pixel coding cost reflects the size of code stream to a certain extent, so the scheme uses the sub-pixel coding cost. The overall scheme flow is as follows:
Prepare the carrier and the original video set.
Recode video by the motion search method selected and counted using the similarity.
Decode the video and the re-encoded video, record MV and predict residual information, and calculate the coding cost.
Calculate feature using MV and coding cost of decoding and re-encoding.
Train SVM for classification.
The specific process of MVCCC feature extraction in this article is shown in Figure 3.

Flowchart of video steganalysis feature extraction based on the variation of coding cost.
First, the video is decompressed, the effective compression parameters are collected, and the MV and prediction error (PE) are recorded. When the video is decoded, the video is compressed to obtain residuals and MVs by entropy decoding, inverse quantization, and iDCT transform, and the current macroblock is obtained by macroblock decoding in the reference frame by motion compensation. The available compression parameters can be collected for recompression after the decoding process.
Important available parameters can be broadly classified into three categories according to their role. The first category is related to the basic characteristics of the video, including resolution, frame number, and frame rate. The second category is related to video quality, such as compression parameters and bit rate. The last category determines the location of macroblocks, such as image groups and macroblock partitioning. In order to ensure the consistency of the above important parameters in the recompression process, the above video compression parameters are collected in this step.
Then, the video is recompressed, matching the most similar motion prediction methods and recording MVs and the information about prediction error. The process of video recompression is to predict the motion for each macroblock of the current frame, find the reference block in the reference frame, and obtain error and MV. The error is subjected to DCT transform, quantization, and entropy coding processing, and the MV is subjected to entropy coding processing to obtain a compressed video for transmission. Since the current block is still possible as a reference block after encoding, the current block is decoded (inverse quantization and iDCT transform) to obtain a reconstructed macroblock during the compression process.
In recompressed motion prediction, full search, hex search, and small diamond search are traversed. The MV obtained by the above method is used as a candidate for matching. In the matching process, the video offset distance is used to measure whether the MV is similar to that obtained by decoding. The MV which is the most similar to the decoded MV will be used as the MV in recompression. Then, the MV and the information about prediction error of each macroblock are recorded. Finally, the MV and the information about prediction error are obtained before and after the recompression to calculate the sub-pixel coding cost using the H.264 video sub-pixel coding cost formula.
Design of the steganalysis method based on the variation of probability of coding cost optimal matching
Through the analysis of the selection of coding cost features in the above section 2.2, we can find that the probability of MV’s coding cost optimal matching of carrier video is very high, and the variation of the probability value before and after re-encoding is very relatively low. And the corresponding proportion of steganographic video will increase, which has a good distinction. So this phenomenon can be used to design features. In addition, the SPOM feature, which also uses the prediction error SAD variation, is less effective in dealing with the steganographic method of Cao et al., 19 and because it has only one-dimensional features, it is less robust and needs to be improved. The scheme first uses the motion estimation matching method in the re-encoding process as in the MVCCC feature in section “Selection of coding cost’s variation features,” 10 and then needs to record the value of the MV in the range of its addition and subtraction and the prediction error SAD value in the decoding process. Then, after recompression, the same operation is performed to calculate the original MV’s SAD and the probability value of coding cost optimal matching in the range of its addition and subtraction. Finally, calculate the change of the SAD and the probability value of coding cost optimal matching after decoding and re-encoding and decoding. The procedure of the scheme is as follows:
Prepare the carrier and the original video set.
Decode the video and the re-encoded video, record MV and predict residual information, and calculate the coding cost.
Recode video by the motion search method selected and counted using the similarity, decode the re-encoded video, record MV information, and calculate the probability of coding cost optimal matching.
Calculate feature using SAD and the probability of coding cost optimal matching.
Train SVM for classification.
Experimental results and analysis
Introduction to the experimental environment
Test sequence: 30 CIF (352*288) video frames form a video library with a pixel format of YUV4:2:0. These videos are downloaded from the standard video library website on the Internet. Since the length of the video is different from 100 to 2000 frames, each video is not cross-cut into 60 frames, and a total of 200 sub-video sets are used for experiments. The video is compressed using the JM10.2 open-source video encoder. The motion estimation fast search algorithm is DIA, HEX, and so on.
Steganographic method: in order to ensure the comprehensiveness of the selected steganographic algorithm, the first one we selected is the method based on MV magnitude of Xu et al., 17 and the second is the method based on prediction residual of Aly, 18 and the third is the method based on STC and wet paper coding which could better maintain the local optimality of MVs of Cao et al. 19 The corrupted motion vector ratio (CMVR) is used to represent the steganographic embedding rate, and the CMVR of the carrier video is set to 0, considering the case where the CMVR is 0.2, 0.4, and 0.6.
Steganalysis method: in addition to the features we proposed, the IMVRB video steganalysis feature of Wang et al., 10 the SPOM steganalysis feature of Ren et al., 16 and the AoSO video steganalysis feature of Wang et al. 11 were used as a comparison object; these three features are quite effective steganalysis methods for MV domains.
Training and detection: in each set of steganalysis experiments, 70% of the carrier video and corresponding steganographic video are randomly selected for training support-vector machines, and the remaining 30% of the sample pairs are used for steganographic classification decisions.
Analysis of results
First, verify the validity of the MVCCC features, and perform experiments according to the above experimental configuration. Figures 4–6 show the detection accuracy of the IMVRB video steganalysis feature of Wang et al. 10 and the AoSO video steganalysis feature of Wang et al., 11 and the MVCCC feature based on the coding cost change proposed in this article for the Xu et al. 17 video steganography method, the Aly 18 video steganography method, and the Cao et al. 19 video steganography method, respectively, and the comparison of the three MV steganalysis features can be observed in the figures.

Detection accuracy % based on the steganalysis method of the Xu.

Detection accuracy % based on the steganalysis method of the Aly.

Detection accuracy % based on the steganalysis method of the Cao.
The experimental results show that the MVCCC features proposed in this article are better and more effective than the IMVRB video steganalysis feature and the AoSO video steganalysis feature in the Xu steganography method, the Aly steganography method, and the Cao steganography method. For the Aly steganography method, the detection result of the IMVRB video steganalysis feature is quite close to the detection result of the proposed method, but the detection result of the AoSO video steganalysis feature is slightly lower. For the Cao steganography method, the accuracy of the proposed scheme is much higher than the IMVRB video steganalysis feature and the AoSO video steganalysis feature. The feature of this article first uses the motion prediction matching method to effectively restore the video compression process, avoiding the increase of detection error rate due to the uncertainty of motion estimation mode. Then, considering the estimated coding cost value of the sub-pixel MV motion in re-encoding, the value before re-encoding can be well maintained, and the MV is usually optimized in the sense of distortion rate. The AoSO video steganalysis feature only uses the size of the distortion as the basis for judgment which is not an accurate criterion for the encoding process. The IMVRB video steganalysis feature also uses SAD as a feature, so the effect is not particularly good when it copes with the steganographic algorithm such as the Cao method to maintain the distortion of local optimal features. Therefore, the features of this article have a more effective detection rate than the IMVRB video steganalysis feature and the AoSO video steganalysis feature.
Next, the validity of the SCCPOM feature is verified. The comparison feature is the SPOM feature extracted by Ren 18 and the steganography method is the Cao 19 video steganography, which is performed at different embedding rates, as shown in Figure 7.

Detection accuracy % based on the steganalysis method of the Cao.
It can be seen from Figure 7 that the SPOM feature is not effective in the steganographic algorithm which maintains the local optimality of SAD such as Cao et al. 19 But the SCCPOM feature proposed in this article increases the variation of probability of coding cost optimal matching before and after video re-encoding based on SPOM features, and it performs better when detecting the method of keeping SAD local optimality. The SPOM feature has only one-dimensional features, so the robustness is poor. The SCCPOM feature combines the variation of the local optimal characteristics of the video and the local optimal probability before and after re-encoding, which has better detection effect and robustness.
Conclusion
In this article, two video MV steganalysis methods based on coding cost changes are proposed. Experiments show that MVCCC features have higher detection accuracy than typical features such as AoSO and IMVRB in various steganography methods, and SPCCOM features have higher detection effect and better robustness than SPOM features. This article verifies the validity of the coding cost feature and provides a favorable reference for further research on video steganalysis.
Footnotes
Handling Editor: Svalastog, J
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported, in part, by the National Key R&D Program of China (2019YFB1406504) and the National Natural Science Foundation of China (U1836108, U1936216, 62002197, and 62001038).