
Abstract
Vehicle re-identification, which aims to retrieve information regarding a vehicle from different cameras with non-overlapping views, has recently attracted extensive attention in the field of computer vision owing to the development of smart cities. This task can be regarded as a type of retrieval problem, where re-ranking is important for performance enhancement. In the vehicle re-identification ranking list, images whose orientations are dissimilar to that of the query image must preferably be optimized on priority. However, traditional methods are incompatible with such samples, resulting in unsatisfactory vehicle re-identification performances. Therefore, in this study, we propose a vehicle re-identification re-ranking method with orientation-guide query expansion to optimize the initial ranking list obtained by a re-identification model. In the proposed method, we first find the nearest neighbor image whose orientation is dissimilar to the queried image and then fuse the features of the query and neighbor images to obtain new features for information retrieval. Experiments are performed on two public data sets, VeRi-776 and VehicleID, and the effectiveness of the proposed method is confirmed.
Introduction
Owing to the increasing development of video surveillance and public security methods and systems, there is a growing need for vehicle re-identification (re-ID) from images. However, this is a challenging task in computer vision and can be regarded as an information retrieval problem. Given a query vehicle image, a vehicle re-ID method attempts to find all images containing that vehicle across multiple non-overlapping cameras. It can be seen from the initial sensor-based methods1–3 for re-ID, hand-crafted-feature-based methods,4–9 and deep-feature-based methods10–15 that the ability to express the acquired features from images is rapidly improving. However, owing to the range of camera capture angles, the orientations of the vehicle images may differ, and these vehicle images often have differences in visual effects. As shown in Figure 1, images whose orientations are different from that of the query images may rank lower than those whose orientations are similar to that of the query image. To address this problem of orientation variation, in certain previous studies, components were primarily added in the training phase to learn the embedded features robustly, thereby increasing the training complexity. Thus, in this study, we propose a simple but effective method to tackle the issue in the post-processing stage.

Partial ranking list obtained from the vehicle re-ID model, where images with blue, red, and green borders are the query, incorrectly retrieved, and correctly retrieved images, respectively. The first three rows are from the VeRi-776 dataset, and the last three rows are from the VehicleID dataset.
In the post-processing stage, re-ranking is used as an effective method to optimize the retrieval ranking. Average query expansion (AQE) 16 is a type of re-ranking method based on the k-nearest neighbor principle, where the new query features are constructed by averaging the old features and the top-k features in the returned list are ranked in order before retrieval is performed again to obtain the final result. Jegou et al. 17 used the corresponding neighborhood and proposed the contextual dissimilarity measure (CDM) to improve the re-ID performance. Leng et al. 18 first proposed the relative information of the nearest neighborhood of each image to improve re-ranking. Sparse contextual activation (SCA) 19 simply completed re-ranking tasks through vectors comparison under the generalized Jaccard metric. Zhong et al. 20 used the original distance and Jaccard distance to complete re-ranking. Jiang et al. 21 used spatial–temporal relationship among vehicles to re-rank the initial ranking list. However, in the vehicle re-ID task, vehicle images with orientations similar to that of the query image often occupy a considerable portion of the top-k returns in the ranking list. Therefore, use of the top-k results to enhance the features directly may not contribute substantially to optimizing the retrieval rankings of vehicle images with orientations dissimilar to that of the query image. Hence, we propose an orientation-guide query expansion method to optimize the rankings of images whose orientations are dissimilar to that of the query image by adding vehicle orientation information to the re-ranking process, thereby improving the retrieval performance.
The proposed orientation-guide query expansion approach consists of three steps. First, we extract image features using a feature extractor and select appropriate similarity measures to calculate the similarity matrix. Here, the vehicle orientation information can be obtained based on methods such as manual annotation and classifier prediction. Then, based on the similarity matrix and vehicle orientation information, we calculate the nearest neighbor image with the highest similarity and dissimilar orientation to the query image. Finally, the new features are obtained by fusing the feature of the query and nearest neighbor image obtained in the previous step, and image retrieval is performed again for the fused data. In the feature fusion process, we weight the original and nearest neighbor features based on their similarities. The contributions of this study are summarized as follows:
An orientation-guide query expansion method is proposed to optimize the rankings of images that are dissimilar to the query image by including vehicle orientation information in the query expansion process.
A feature fusion method based on similarity is used to reduce the influences of unexpected samples on the features, and the weights of the original features are increased to reduce the impacts on the retrieval of images whose orientations are similar to that of the query image.
Extensive experiments are conducted using two public datasets to show that the proposed method can achieve a relative performance improvement.
Related work
Orientation-aware vehicle Re-ID
The vehicle re-ID task has garnered increasing attention in the field of computer vision. VehicleID 22 and VeRi-776 23 are two widely used datasets for vehicle re-ID tasks. In these datasets, any two images of the same vehicle may have different orientations, thereby affecting vehicle recognition. Therefore, Wang et al. 24 used an orientation invariant feature embedding scheme to extract the features of the vehicle from different orientations based on 20 key-point locations. Chu et al. 25 proposed a viewpoint-aware network that learns two kinds of metrics in two feature spaces for similar and different orientations. Meng et al. 26 proposed a parsing-based view-aware embedding network to achieve view-aware feature alignment and enhancement for vehicle re-ID. Sun et al. 27 used orientation information to learn two different metrics according to whether there is common field of view of two vehicle images to deal with large intra-class difference.
Re-ranking for re-ID
Re-ranking is a method used to optimize the ranking of the images, which can effectively improve retrieval performance. Re-ID can be regarded as a retrieval problem; some methods of image retrieval re-ranking can also be used in the re-ID task. In particular, Jegou et al. 17 proposed the CDM that considers the neighborhood of a point. Arandjelović and Zisserman 28 proposed the discriminative query expansion (DQE) method where a richer model for the query is learnt discriminatively in a form suited to immediate retrieval via use of the inverted index. Bai and Bai 19 proposed a SCA scheme to encode the neighbor set into a vector and indicate sample similarities based on the generalized Jaccard distance.
Recently, some re-ranking methods have been proposed for the person re-ID tasks. For instance, Zhong et al. 20 proposed a re-ranking method with k-reciprocal encoding, which encodes the k-reciprocal features into a single vector to obtain the k-reciprocal features of an image. Li et al. 29 developed a re-ranking model by analyzing the relative information and direct information of the nearest neighbors of each pair of images. Garcia et al. 30 refined a given initial ranking by removing the visual ambiguities common to the first ranks by analyzing their content and contextual information. Chen et al. 31 incorporated graph models into feature subsets resorting to the initial ranking in the graph convolution network by integration of the attention mechanism. In addition, in the vehicle re-ID task, some studies21,24 have used spatial–temporal information to re-rank the initial list obtained with visual features. Shi et al. 32 Perform hash learning by calculating the semantic similarity among seen classes. However, owing to the extreme orientation variations in vehicle images, objects that need to be primarily optimized are the vehicle images whose orientations are dissimilar to that of the query image. Inspired by this idea, in this study, we designed a simple but effective re-ranking method based on query expansion and orientation information.
Method
This proposed orientation-guide query expansion approach consists of three steps. As illustrated in Figure 2, given a query image of a vehicle, first, we extract image features from the Reid Model, and select the appropriate similarity measure to calculate the similarity matrix, and obtain an initial ranking list. Wherein, the vehicle orientation information can be obtained based on some methods, such as manual annotation and classifier prediction. Then, according to the similarity matrix and vehicle orientation information, we calculate the nearest neighbor image with the highest similarity and dissimilar orientations to the query image. Finally, the new feature is obtained by fusing the feature of the query image and the nearest neighbor image obtained in the previous step, which is used to retrieve again for the final result. In the process of feature fusion, we weight the original feature and the nearest neighbor feature based on similarity.

Schematic of the proposed orientation-guide query expansion approach.
Problem statement
We first extract the embedded features of the vehicle images in the database through the feature extractor, and then adopt the feature representation to get the initial similarity matrix and the ranking list according to the similarity measure. We define the query set
For a query vehicle
Orientation-guide nearest neighbor search
Our approach is based on vehicle orientation information. These orientation information are already existed in some datasets, such as the dataset VeRi-776. In VeRi-776, all vehicle images (including the training set and the test set) are manually labeled as eight types of orientations (“front,”“rear,”“left,”“left-front,”“left-rear,”“right,”“right-front,” and “right-rear”) by Wang et al. 24 We directly use the label on the test set and add orientation information to the re-ranking operation. We develop a rule to determine whether two vehicle images have the similar orientation as shown in Table 1. The formulation of this rule is mainly based on whether there are common fields of view in two orientations, such as two pictures with the orientation of front and rear, we think their orientation is dissimilar because there are very few common fields of view. Conversely, for orientations of left and left-front, we consider their orientations are similar because there exists more common fields of view.
The rule to determine whether two vehicle images have similar orientation according to the orientation label in the VeRi-776 data set. Where

For some datasets that are lack of orientation information for all samples, such as the dataset VehicleID, which has only labeled the orientation information of the training set, we use ResNet50 as the backbone to train an orientation classifier to predict the orientation label of the test set. There are two orientations in VehicleID dataset, containing front and rear. When the orientation labels of two pictures are the same, the orientation is similar, otherwise, the orientation is dissimilar.
We get the similarity matrix of all images in the test set by cosine similarity. The similarity
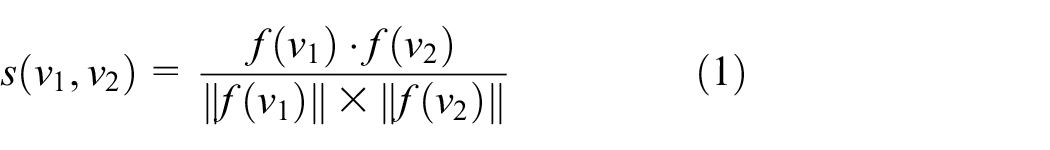
where

We will use features of
Feature fusion
In the previous section, we described the orientation-guide nearest neighbor,
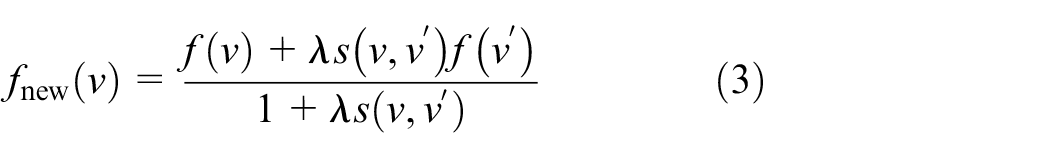

where
Experiment
In this section, we first introduce the experimental settings including two public benchmark sets used for vehicle re-ID and the evaluation metrics. Then, we compare our proposed method with several existing re-ranking methods based on the multiple feature extractor.
Experimental settings
In the experiments, we adopted two public datasets VeRi-776 23 and VehicleID 22 to vehicle re-ID, which are composed of vehicle images from the real-world surveillance video.
VeRi-776 contains over 50,000 images of 776 vehicles captured using 20 surveillance cameras in unconstrained traffic scenes. Among them, about 37,778 images of 576 vehicles are used for training, while the remaining 11,579 images of 200 vehicles are used for testing. VehicleID contains 221,763 images of 26,267 vehicles, which were captured during daytime by multiple real-world surveillance cameras distributed across a small city in China. VehicleID provides three test subsets with different sizes, namely, small, medium, and large, including 800, 1600, and 2400 vehicles, respectively.
We evaluated the proposed method based on two evaluation metrics, the mean average precision (mAP) and cumulative match characteristic (CMC) score. The former one is a widely used evaluation metric in retrieval tasks, which is considered as the mean value of the average precision (AP) for all the query images in this study. The latter one shows the probability of a query identity appearing in candidate lists with different sizes. In VeRi-776, we used mAP and CMC scores (rank-1 denoted as CMC@1 and rank-5 denoted as CMC@5) as evaluation index. In VehicleID, we only used CMC@1 and CMC@5 as evaluation metric.
Experimental results and analyses
We use a strong baseline (https://github.com/heshuting555/AICITY2020_DMT_VehicleReID)33–35 for the vehicle re-ID as the feature extractor. Based on the features, we applied our method and two frequently used re-ranking methods for re-ID, namely, AQE and k-reciprocal encoding. For our method, we set
Results (%) on VeRi-776 dataset, and the best results are shown in bold.
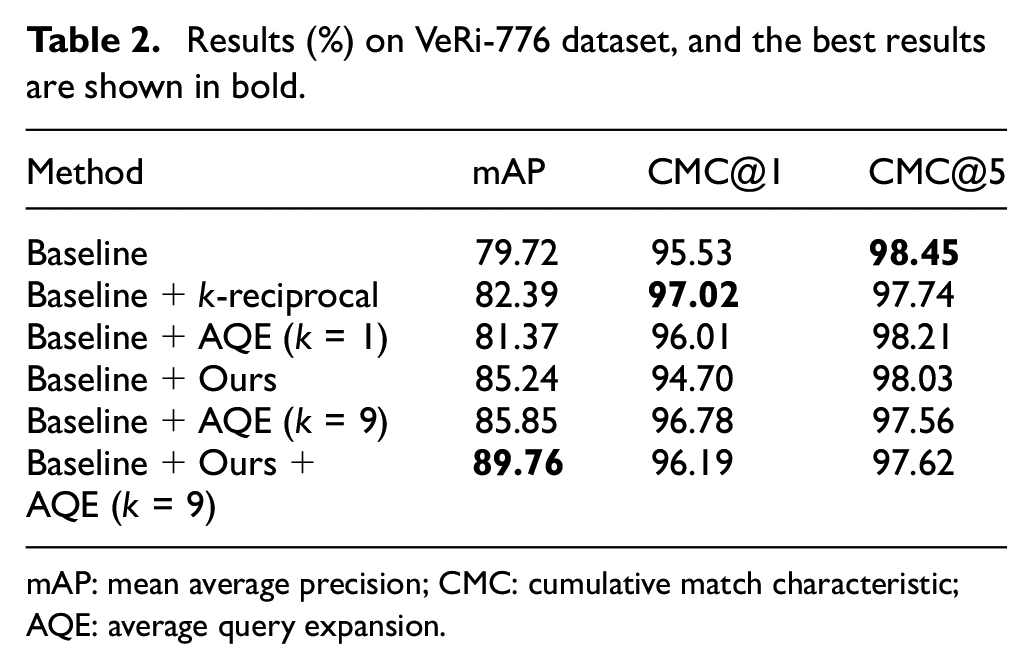
mAP: mean average precision; CMC: cumulative match characteristic; AQE: average query expansion.
Results (%) on VehicleID dataset, and the best results are shown in bold.

CMC: cumulative match characteristic; AQE: average query expansion.
As seen in Table 2, the mAP of our method outperforms the k-reciprocal and AQE
To verify the universality of the vehicle re-ID method, in addition to a strong baseline, we added this method to several commonly used model architectures for re-ID, including the part-based convolutional baseline (PCB), 36 multiple granularity network (MGN), 37 and batch dropblock network (BDBNet). 38 These results are shown in Tables 4 and 5.
Results (%) of other models on VehicleID dataset, and the best results are shown in bold.

CMC: cumulative match characteristic; BDBNet: batch dropblock network; AQE: average query expansion; PCB: part-based convolutional baseline; MGN: multiple granularity network.
Results (%) of other models on VeRi-776 dataset, and the best results are shown in bold.

mAP: mean average precision; CMC: cumulative match characteristic; PCB: part-based convolutional baseline; MGN: multiple granularity network; AQE: average query expansion; BDBNet: batch dropblock network.
As shown in Tables 4 and 5, we see that our method achieves reliable results for both databases and three models. It is noted that the CMC scores are a bit lower than some existing methods in some cases. However, the proposed method can well handle the vehicle images that are with different orientations with the query image, while the existing methods always focuses on the correctly retrieved sample whose orientations are similar to that of the query image. Therefore, the whole performance (mAP score) of the proposed method is better than existing re-ranking methods, especially for the cases that are not similar with the query image in orientations.
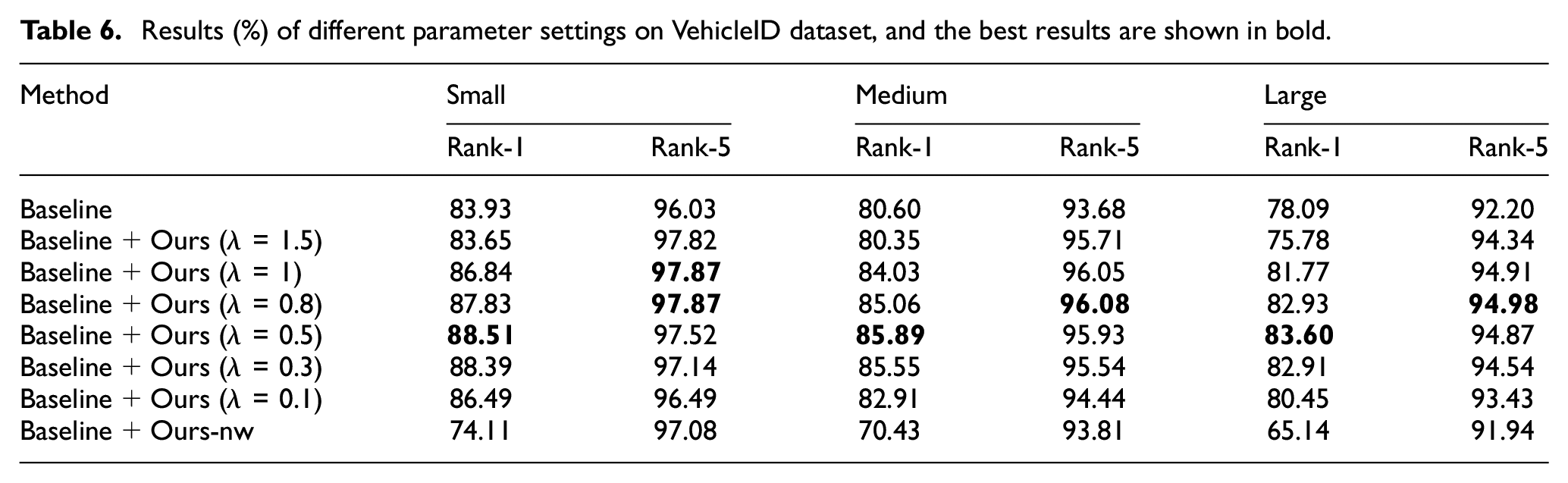
As shown in Tables 6 and 7, Baseline + Ours-nw represents no weight and it is not equivalent to λ = 0, which means that there is no addition to the part based on similarity weight. Without weighting, performance will degrade a lot. Generally, large
Results (%) of different parameter settings on VehicleID dataset, and the best results are shown in bold.
Results (%) of different parameter settings on VeRi-776 dataset, and the best results are shown in bold.

mAP: mean average precision.
The visualizations of the experimental results for the two data sets are shown in Figures 3 and 4. For each query image, the first line represents a part of the initial ranking list from the baseline model, and the second line depicts the results of re-ranking by our proposed method. It can be seen that our method optimizes the rankings of images whose orientations are dissimilar to that of the query image.

The visualization of re-ranking results on VehicleID dataset.

The visualization of re-ranking results on VeRi-776 dataset.
Conclusion
In this study, we aim to solve the problem of extreme orientation variation of vehicle image in the post-processing stage. By adding orientation information to the re-ranking operation, the proposed method can optimize the ranking of images whose orientation is dissimilar to query.
Footnotes
Handling Editor: Yanjiao Chen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported in part by the National Natural Science Foundation of China (62176141), Shandong Provincial Natural Science Foundation for Distinguished Young Scholars(ZR2021JQ26), Taishan Scholar Project of Shandong Province (tsqn202103088) and special funds for distinguished professors of Shandong Jianzhu University.