
Abstract
Policy gradient methods are effective means to solve the problems of mobile multimedia data transmission in Content Centric Networks. Current policy gradient algorithms impose high computational cost in processing high-dimensional data. Meanwhile, the issue of privacy disclosure has not been taken into account. However, privacy protection is important in data training. Therefore, we propose a randomized block policy gradient algorithm with differential privacy. In order to reduce computational complexity when processing high-dimensional data, we randomly select a block coordinate to update the gradients at each round. To solve the privacy protection problem, we add a differential privacy protection mechanism to the algorithm, and we prove that it preserves the
Introduction
Content Centric Network (CCN) shows great potential in the future Internet development; many multimedia applications in CCN are policy decision problems in essence, for example, traffic prediction and resource allocation. Reinforcement learning1–3 is an effective means to deal with optimization decision problems; it is applied in many network fields, such as congestion control, 4 traffic scheduling, 5 network security, 6 and load balancing. 7 The principle of reinforcement learning is an iteration decision process in which an agent constantly interacts with the environment to strengthen its decision-making ability, which mainly solves the sequence decision problem. At each iteration, an agent changes the state of the environment by performing an action, and the environment feeds it back a reward based on a reward function. The objective of reinforcement learning is to obtain a policy that maximizes cumulative reward. Therefore, how to design a better policy to achieve this goal is very important.
As an important branch of reinforcement learning, policy gradient methods are widely used in many fields, such as video game,
8
AlphaGo,
9
news recommendation,
10
and network resource.11,12 Policy gradient methods have a better performance in continuous action space (or higher dimensional space), and they can implement a randomized strategy. Policy gradient methods directly parameterize the policy and learn based on the strategy, which defines a policy
In order to reduce the variance in gradient estimation, Stochastic Variance Reduced Gradient Descent (SVRG)
16
uses a batch sample to estimate and calculate the gradient of all the samples every once in a while; although SVRG is very successful in supervised learning, it is difficult to apply it to policy gradient. To address the problem, Stochastic Variance Reduced Policy Gradient (SVRPG)
17
is a random variance reduction algorithm of the policy gradient used to solve the Markov Decision Process (MDP). SVRPG uses the importance sampling weight to retain the unbiased gradient estimation, which can ensure convergence under the standard assumption of MDP. But the above algorithms have a high sample complexity and large training batches; then important-sampling momentum-based policy gradient (IS-MBPG) and Hessian-Aided Momentum-based Policy Gradient (HA-MBPG)
18
combine momentum methods19–21 with the important sampling and Hessian-aided methods, which achieves a faster convergence rate with an adaptive learning rate, and IS-MBPG reduces the sample complexity of
However, the algorithms mentioned above calculate the full gradient for all dimensions of data in each iteration, which causes a large amount of calculation. And these algorithms use centralized processing methods in the data training, which upload data to the central node, reducing communication resources. In addition, the data training may involve sensitive data, which causes the privacy breach.
In order to solve the above problems, we propose a randomized block policy gradient algorithm with differential privacy (DP-RBPG) in CCN, which combines the random block-coordinate methods and differential privacy to meet the demand of high-dimensional data processing and privacy protection. At each iteration, we randomly select one block coordinate to update the gradients, which decreases the variance of gradient estimator and accelerates the convergence rate. And if we use all block coordinates in gradient updating, our algorithm will reduce to IS-MBPG. DP-RBPG can also reduce the sample complexity of
The comparison on sample complexity to attain

DP-RBPG: randomized block policy gradient algorithm with differential privacy; GPOMDP: gradient of a partially observable markov decision process; HA-MBPG: Hessian-aided momentum-based policy gradient; HAPG: Hessian aided golicy gradient; IS-MBPG: important-sampling momentum-based policy gradient; PGT: Policy Gradient Theorem; SVRPG: Stochastic Variance Reduced Policy Gradient.
Meanwhile, we achieve the differential privacy protection with increasing a Laplace distribution noise perturbation in the process of gradient updating, which increases the security of the training process and solves the differential privacy leakage problem in the process of data transmission.
The main contributions are listed as follows.
We propose a DP-RBPG based on momentum and important sampling methods. DP-RBPG accelerates gradient descent and decreases the variance of gradient estimator without sacrificing the performance, and we introduce a differential privacy protection mechanism during data processing.
We add the noise interference into updating gradient, which follows the Laplace distribution. Based on the property of Laplace distribution, we prove that it can preserve the
We implement DP-RBPG in MuJoCo environment, which contains CartPole, Walker, Hopper, and HalfCheetah. The experimental results show that DP-RBPG improves the convergence rate, and as the data dimension goes up, the algorithm has a better performance. Meanwhile, as the level of
The article is organized as follows. We review the related works in the “Related work” section. The preliminaries of policy gradient and reinforcement learning are described in the “Preliminaries” section. Our algorithm is proposed in the “Differential privacy randomized block policy gradient” section. Environment deployment and results of the contrast experiments are described in the “Experiments” section. Finally, we give a conclusion about the article in the “Conclusion” section.
Related work
Policy gradient
Recently, decreasing the variance of gradient estimator is the main way to study policy gradient. Le Roux et al.
23
proposed stochastic average gradient (SAG) algorithm, which used two gradients: one is the gradient of the previous iteration and the other is the new gradient—both of these gradients selected a sample randomly to calculate. The convergence rate of SAG was faster than the stochastic gradient descent (SGD) of the gradient estimated from a single sample. Defazio et al.
24
proposed stochastic average gradient descent (SAGA), an accelerated version of the SAG algorithm, which used an unbiased estimator to update gradient and reduced the impact of noise. However, the problems of SAG and SAGA were that they required memory to maintain every old gradient. Xu et al. proposed SVRG, which used a batch sample to estimate the gradient and estimated gradient with the batch samples over a period of time; after then, it reselected a batch sample to estimate the gradient. SVRG attained a faster convergence rate than SAG, but it could not guarantee the unbiased estimation of gradient. Allen-Zhu
25
proposed a new algorithm named for nonconvex stochastic optimization problems, which divided the internal cycle of SVRG into
More recently, Papini et al.
17
came up with a new reinforcement learning algorithm named SVRPG, which was applied to policy gradient. This method decreased the sample complexity and converged faster. Xu et al. proposed a better convergence analysis method than SVRPG; the sample complexity of
Randomized block coordinate
Randomized block methods selected one coordinate to update the gradient in each iteration, which could reduce iteration costs and memory requirements and speed up convergence rate. 29 In order to handle large training tasks, Diakonikolas and Orecchia 30 proposed an algorithm named accelerated alternating randomized block coordinate descent (AAR-BCD), which optimized the method of random block selection. Zhao et al. 31 proposed a mini-batch randomized block coordinate descent (MRBCD) algorithm, which updated the gradient with mini-batch samples in each round, and the variance of gradient estimator in MRBCD was reduced and the convergence rate was accelerated. Lacoste-Julien et al. 32 proposed a randomized block algorithm to solve the problem of block-separable constraints, which was mainly used in support vector machines (SVMs). Singh et al. 33 improved the Nesterov method with gradient projection methods, which accelerated the convergence rate. Lin et al. 34 put forward a new method to analyzing the problem of asynchronous distributed optimization. Based on the above observation, we select randomized block-coordinate method to update the gradients, which can decrease the variance of gradient estimator and accelerate the convergence rate.
Differential privacy
Differential privacy methods resist differential attacks by adding a random mechanism to achieve the purpose of privacy protection.35,36 Gao and Ma 37 proposed an algorithm which combines reinforcement with differential privacy in processing dynamic data. Ding et al. 38 put forward a alternating direction method based on differential privacy and reinforcement. Cheng et al. 39 proposed a novel stochastic gradient descent algorithm with deep learning and differential privacy. Dai et al. 40 utilized reinforcement learning to solve the problem of network security. Whereas in processing high-dimensional data, these algorithms are lacking.
Preliminaries
In this section, we will introduce some preliminary knowledge about reinforcement learning and policy gradient methods.
Reinforcement learning
The most basic model of reinforcement learning is MDP, which consists of a set of environmental states

The MDP can be described as follows: an agent whose initial state is

The goal of the MDP is to find an optimal policy
Policy gradient
Different from the value-based methods, policy gradient methods are based on a policy to learn, which outputs the action or the probability of the action directly based on the state. Comparing with the parameterized representation in the value function, the policy parameterization is simpler and has better convergence. Analyzing from the perspective of importance sampling, the objective of policy gradient is maximizing cumulative return.

During the training, the objective of policy gradient is to find optimal parameter

Based on formula (4), we turn the policy search approach into an optimization problem. The methods solving this problem include the policy gradient, Newton’s method and Quasi-Newton Methods, and Interior Point Method. The policy gradient is the simplest and most commonly used, which uses

When calculating the policy gradient, the data used are sampled under the new strategy, which requires that all the samples should be resampled according to the new strategy after each gradient updation. The data utilization of this approach is very low, which makes the lower speed of convergence. Therefore, we bring in the concept of importance sampling, using the old parameter
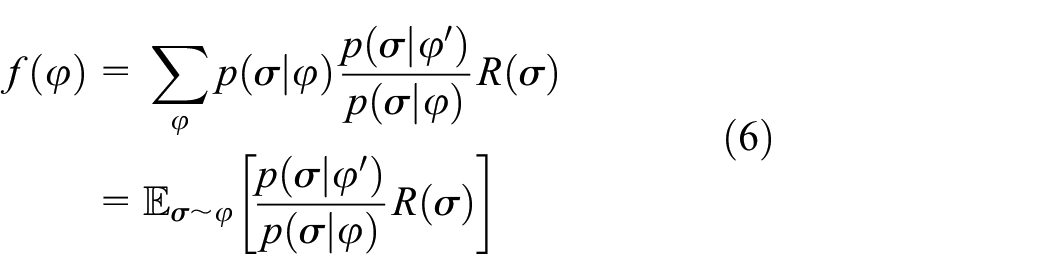
Taking the derivative of this formula, we can get the same result as equation (5). But the trajectory probability

Based on equation (7), we add the learning rate

where the learning rate is greater than zero and
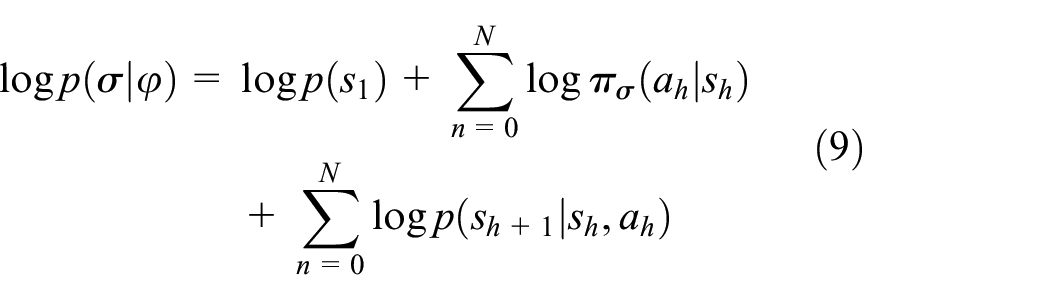
so that

However, there are some problems with equation (9); the lager cumulative return value will make the larger parameter update, so that the model will fluctuate greatly, which may affect the final model effect. Although the policy is an unbiased estimator of expectation, the variance is very large due to over-dependence on each sampling trajectory, so we bring in the baseline

We can prove that
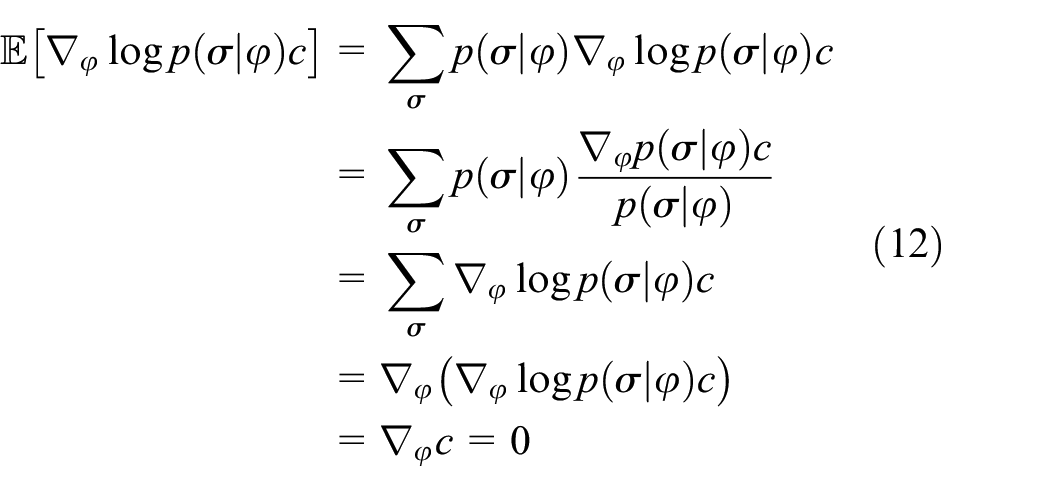
So that the baseline
The current strategy gradient algorithm has high computational cost when processing high-dimensional data, and privacy leakage has not been considered, but privacy protection is very important in data training. Therefore, we propose the differential privacy randomized block policy gradient algorithm. In order to reduce the computational complexity of processing high-dimensional data, a random block coordinate is selected randomly to update the gradient of each round. In terms of privacy protection, a differential privacy protection mechanism is added to the algorithm, and it is proved that it maintains
Differential privacy randomized block policy gradient
In this part, we combine the randomized coordinate method and differential privacy with important sampling momentum-based policy gradient method (DP-RBPG). The randomized coordinate way does well in dealing with optimization problems, especially in higher dimensions. The implementation of the method is shown in Algorithm 1. Due to the trajectory probability,

DP-RBPG: randomized block policy gradient algorithm with differential privacy.
Definition 1
We first define the concept of adjacent relation, we introduce the adjacent data sets
Definition 2
Then we bring in the definition of differential privacy. For a randomized algorithm

where
Definition 3
We introduce the definition of the randomized algorithm

where
Formally, for

where

where we select
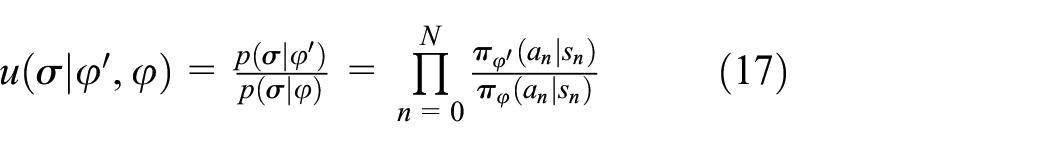
By equation (16), we can achieve that
According to the proof method in IS-MBPG, we can also get the similar conclusion that the
Then we will prove that DP-RBPG preserves the

For the

Next, we will analyze the privacy property of our algorithm.
Theorem 1
Based on Algorithm 1,
Proof

The first inequality above uses the triangle inequality, and the second inequality uses equation (19) to prove; when the parameter
Experiments
In this part, considering about the multimedia data transmission mechanism in CCN, we train our algorithm offline in a lot of epochs. Meanwhile, we mainly introduce the experimental results with our algorithm in four simulation environments, which are CartPole, Walker2D, HalfCheetah, and Hopper. We compare our algorithm with IS-MBPG, REINFORCE, 14 and HA-MBPG 18 in these simulation environments. The detailed environmental setup and the analysis of experimental results are shown below.
Experimental setup
The experiments are implemented on VMware Workstation 15 Pro 15.5.0 with a Linux environment with Ubuntu-18.04.3 (Linux kernel 4.8.4); the whole process is in a computer with Intel® Xeon® Sliver 4114 CPU and 64 GB RAM. To ensure the fairness of the experiments, we implement these algorithms in the same environment, which is based on PyTorch 1.6.0, 41 MuJoCo 1.50.1.68, 42 Garage 2019.10.0, 43 TensorFlow 1.15.3, 44 and Gym 0.12.4. 45 In the process, we set the same initial value for all algorithms, aiming at the problem of data randomness that may exist in the experiment; we repeated the experiment many times and selected the average result as the final result.
In particular, different from REINFORCE, we rewrite CartPole using categorical policies to calculate, which is always used in discrete action space, and other environments use Gaussian policies, which are always used in continuous action space. The parameters of the experiment are set as follows: the Neural Network expects that CartPole is 8 × 8, others are 64 × 64. In an experiment, the training horizon of CartPole is 100, Walker2D and HalfCheetah are 500, and Hopper is 1000. To be fair, the learning rate of these algorithms is set to 0.01. The number of timesteps of CartPole is set to 5 × 105, and others are 1 × 107. The batch size of CartPole and Hopper is 50, and the ones in Walker2D and HalfCheetah are 100. Some other hyperparameters such as
Summary of experimental parameters.

Specially, similar to HA-MBPG and IS-MBPG, we use the system probes to represent the complexity of samples, which is a better measurement standard for training. The system probes avoid the problem of returning failure caused by different sample lengths in the training process. In the experiments, we achieve a faster convergence rate than the other three algorithms by comparing running time for the same system probes; meanwhile, the average episode return is close to the latest algorithm IS-MBPG. In addition, during data training, considering about preserving data privacy, we add differential privacy protections when calculating average episode returns, which increases security during data training. We add a stochastic Laplace distribution factor
Experimental results
As shown in Figure 1, we deploy four algorithms, which are DP-RBPG, IS-MBPG, HA-MBPG, and REINFORCE, in the same environment. In CartPole environment, we can see that our algorithm is close to IS-MBPG, which is obviously better than HA-MBPG and REINFORCE; to be more precise, the training results of the average training episode reward of IS-MBPG and DP-RBPG are close to 90, and HA-MBPG and REINFORCE are close to 85 and 78. As shown in Figure 2, because there is little difference in low-dimensional data of training, we record the training time of 500 epochs; the time of these algorithms is similar, and the fastest one is REINFORCE, followed by DP-RBPG. Because the algorithm has a certain degree of randomness, we choose the best training result of each algorithm as the final result, and the running time of DP-RBPG is 99% and 96% of IS-MBPG and HA-MBPG, respectively, in CartPole; though the convergence rate of DP-RBPG is 1% slower than REINFORCE, the average episode return is much better than it.
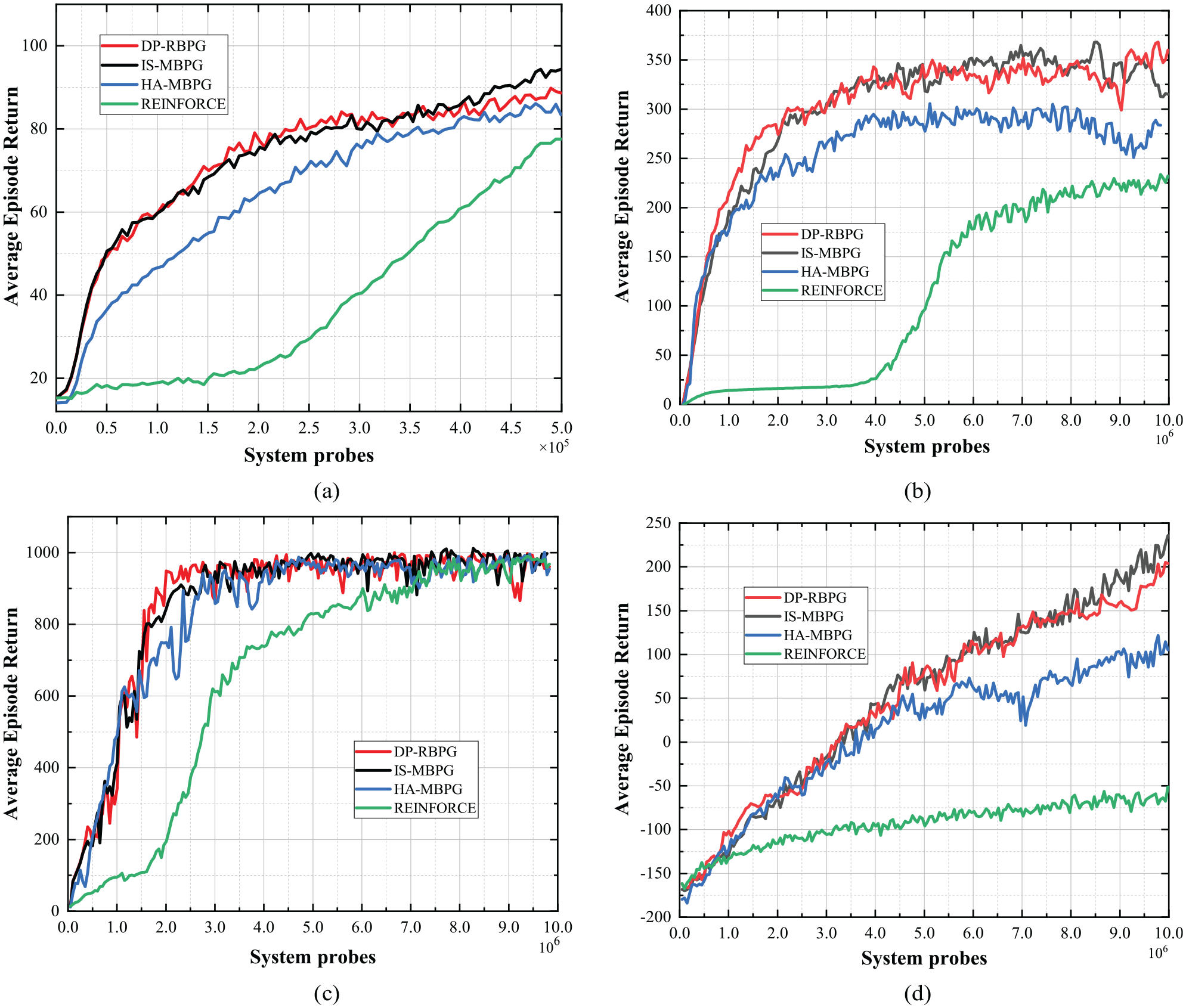
A performance comparison of our algorithm and IS-MBPG, HA-MBPG, REINFORCE in (a) CartPole, (b) Walker, (c) Hopper, and (d) HalfCheetah. The x-axis is the number of state transitions, and the y-axis is the average training episode reward.
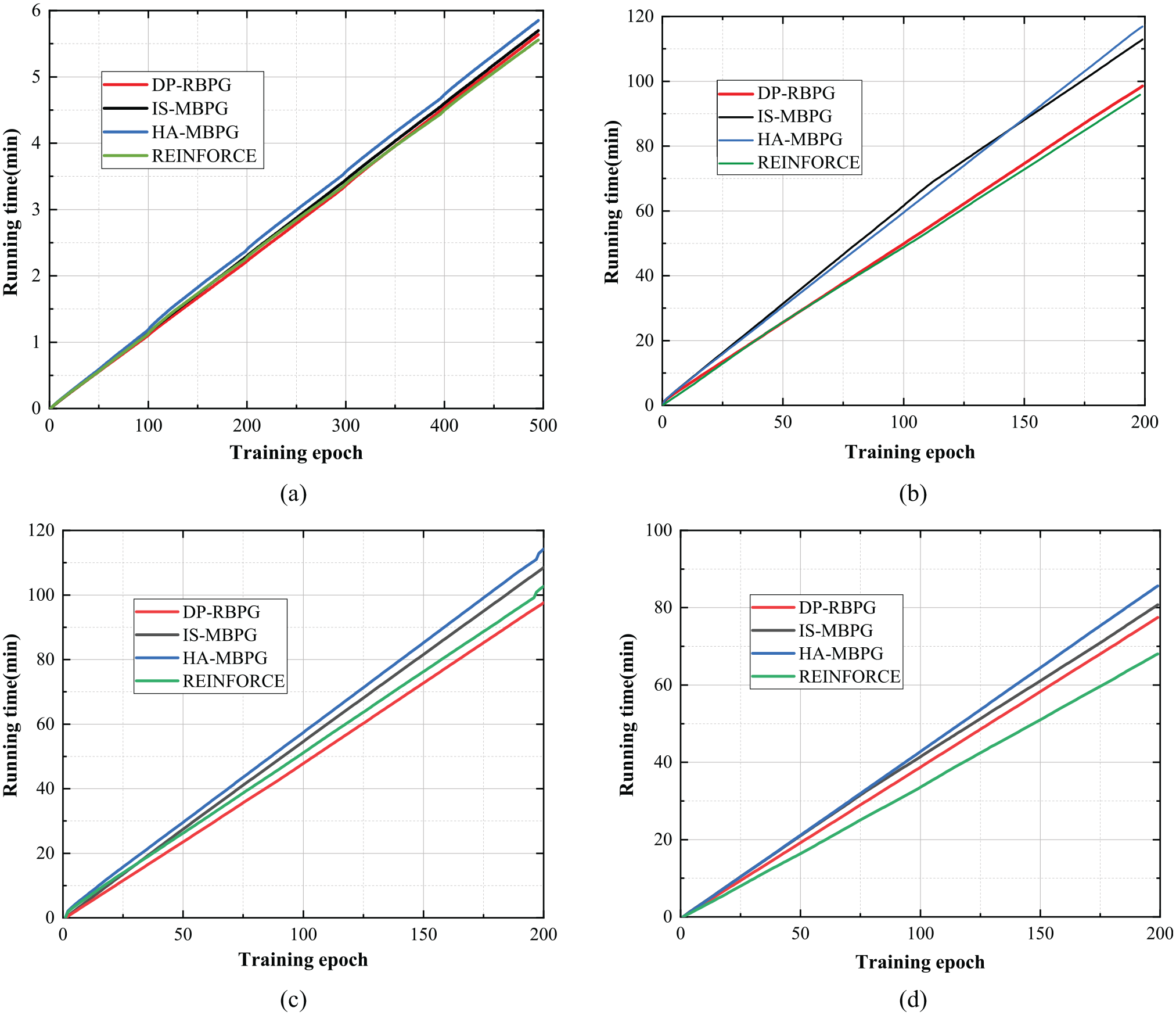
The running time comparison of our algorithm and IS-MBPG, HA-MBPG, REINFORCE in (a) CartPole, (b) Walker, (c) Hopper, and (d) HalfCheetah. The x-axis is the number of training epochs, the y-axis is the total training time.
In Walker environment, as shown in Figure 1, we can see that the average episode return of our algorithm is close to IS-MBPG, which is obviously better than HA-MBPG and REINFORCE. In particular, the training results of IS-MBPG and DP-RBPG are close to 350, and HA-MBPG and REINFORCE are close to 290 and 230. Meanwhile, different from training low-dimensional data in CartPole, as the data dimension goes up, we can see that DP-RBPG reaches a state of convergence more quickly than IS-MBPG and HA-MBPG. In Figure 2, we record the training time of 200 epochs; although REINFORCE is also the fastest one, the performance is poor. The running time of DP-RBPG is 87% and 82% of IS-MBPG and HA-MBPG, respectively, in Walker environment.
In Hopper environment, as shown in Figure 1, all of these algorithms are convergent to 1000. However, we can plainly find that our algorithm DP-RBPG converges faster than IS-MBPG, HA-MBPG, and REINFORCE from the beginning to the maximum. Due to the fluctuation of data training greatly, the training result is the average episode return, the batch size is 50,000, and we divide it into five rounds. The results show that our algorithm can effectively converge. In Figure 2, we can see that the running time of DP-RBPG is lower than IS-MBPG, HA-MBPG, and REINFORCE in 200 training epochs. The running time of DP-RBPG is 89%, 85%, and 95% of IS-MBPG, HA-MBPG, and REINFORCE, respectively, in Hopper environment.
In HalfCheetah environment, as shown in Figure 1, IS-MBPG is the best one in average episode return, which is close to 240. The average episode return of our algorithm DP-RBPG is close to 200, and the growth trend is roughly the same with IS-MBPG. The training results of HA-MBPG and REINFORCE are close to 120 and −50. In Figure 2, we can find that HA-MBPG costs the most time in 200 epochs; although REINFORCE is also the fastest one, the performance is poor in Figure 1. The running time of DP-RBPG is 91% and 85% of IS-MBPG and HA-MBPG, respectively, in HalfCheetah environment.
In summary, from the above experimental results, the running time of our algorithm is lower than IS-MBPG and HA-MBPG in the same environment. Although the running time of REINFORCE is lower than our algorithm, the performance is poor. The reason is that REINFORCE is an update of the turn-based system, which has a big variance in gradient estimation. We can get a conclusion that our algorithm iterates more times than others in the same time period, which accelerates gradient descent. Moreover, we can see that the average episode return is close to IS-MBPG in all environments. And we can see that the experimental results in CartPole are unconspicuous; as the dimensions go up, we can get the difference between the running time in these algorithms.
In addition, we bring in the differential privacy protection mechanism, which adds a stochastic Laplace distribution factor

The average episode return of our algorithm with different Laplace distribution factor: (a) CartPole and (b) Walker.
Conclusion
In this article, we proposed a DP-RBPG in CCN, which can solve the problems of mobile multimedia data transmission in CCN. In the process of data packet transmission in CCN, traffic optimization and congestion control problems can be formulated into policy decision problem based on the current network delay, packet loss rate, and maximum throughput. DP-RBPG can generate a policy to adjust network state through constantly interacting with the environment. DP-RBPG selects one randomized block coordinate in gradient updating at every round; we compared it with other algorithms. The experiments prove that the training time of DP-RBPG is lower than others in the same training epochs. Moreover, we bring in a differential privacy protection mechanism, which adds a Laplace distribution factor in gradient updating, and we prove that it preserves the
Footnotes
Handling Editor: Yanjiao Chen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China (NSFC; Grant No. 61871430), the Scientific and Technological Innovation Team of Colleges and Universities in Henan Province (Grant No. 20IRTSTHN018), the basic research projects in the University of Henan Province (Grant No. 19zx010), and the Key Scientific and Technological Projects Henan Province (Grant No. 202102210169), Key Scientific Research Projects of Colleges and Universities in Henan Province (Grant No.22A520005).