
Abstract
Deep neural networks have achieved a great success in a variety of applications, such as self-driving cars and intelligent robotics. Meanwhile, knowledge distillation has received increasing attention as an effective model compression technique for training very efficient deep models. The performance of the student network obtained through knowledge distillation heavily depends on whether the transfer of the teacher’s knowledge can effectively guide the student training. However, most existing knowledge distillation schemes require a large teacher network pre-trained on large-scale data sets, which can increase the difficulty of knowledge distillation in different applications. In this article, we propose a feature fusion-based collaborative learning for knowledge distillation. Specifically, during knowledge distillation, it enables networks to learn from each other using the feature/response-based knowledge in different network layers. We concatenate the features learned by the teacher and the student networks to obtain a more representative feature map for knowledge transfer. In addition, we also introduce a network regularization method to further improve the model performance by providing a positive knowledge during training. Experiments and ablation studies on two widely used data sets demonstrate that the proposed method, feature fusion-based collaborative learning, significantly outperforms recent state-of-the-art knowledge distillation methods.
Introduction
Recently, since deep neural networks (DNNs) have shown breakthrough results in the visual recognition tasks, the number of deep learning applications in real-world scenarios has exploded.1–3 These deep learning-based methods have been widely used in self-driving cars, cancer detection, and intelligent robotics. However, the high performance of DNNs mainly comes at the cost of the high computational complexity. Therefore, it is usually very difficult to deploy large-scale DNNs on mobile and embedded devices due to their limited computational power. To overcome those issues, several model compression methods have been developed to improve the model efficiency without significantly sacrificing the model accuracy, such as network pruning,4,5 low-rank decomposition,6,7 and knowledge distillation (KD).8,9 Among different model compression schemes, KD has received a lot of attention because of its great flexibility in teacher–student network architectures. Specifically, KD is first formally introduced by Hinton et al., 8 where the teacher network transfers the knowledge in the output layer to the student network. Furthermore, Romero et al. 9 develop the idea of FitNets, that is, the middle layer of DNNs also contains rich knowledge.
Traditional offline KD usually requires a large pre-trained neural network as the teacher network, and then exacts knowledge from the teacher network and transfers it to the student network during the distillation process.8–12 However, it takes a lot of time to pre-train a large teacher network, and how to choose a proper teacher network for a given student network is also an intractable problem. In contrast, the online KD scheme does not require the participation of a large teacher network, and thus avoids the problem caused by the large-scale pre-trained teacher network.13–17 Specifically, Zhang et al. 13 proposed a distillation method without indicating the teacher network, that is, two peer student networks learn from each other. Guo et al. 14 utilizes the collaborative learning to ensemble the output of all student networks to improve the performance of student networks. However, the above two methods only consider the knowledge of the output layer of the student network, making it possible for further improvement using feature knowledge. For example, Hou et al. 15 fuse the features of the middle layer in two parallel student networks using the fusion module formed by a simple “SUM” operation, while two parallel student networks must share the same network structure. Kim et al. 16 proposed a feature fusion learning method to fuse the features of the student network and devise an ensemble classifier to work together to improve the model performance.
To further improve the performance of the student network with a more effective KD scheme, we propose a feature fusion-based collaborative learning (FFCL) for KD in this article. Specifically, in the process of distillation, two parallel peer (or student) networks improve their performance in a collaborative manner. Since the parameters in the network are randomly initialized and different student networks may have different abilities to learn knowledge, there will be a gap between the performance of two parallel student networks with the same architecture during training. In this case, two networks learn from each other, while the network with a poor performance may affect the network with a good performance, which then affects the final results. Therefore, before the distillation process, we first pre-train the network that will participate in the training process. During the distillation process, the pre-trained network will guide the corresponding network. We refer to this step as the network regularization, which can enable the student network to obtain the correct knowledge from the pre-trained network, reduce the negative impact of the wrong knowledge among the peer networks, and further avoid the issue caused by training a large-scale teacher network. Moreover, to further utilize more feature knowledge from the middle layers during collaborative learning, we fuse the features from peer networks to obtain more representative features, which can then be used to further improve network performance. Consequently, through the collaborative learning between peer networks, network regularization for each network and feature fusion between peer networks, the distilled knowledge could be more informative for training each peer network. The main contributions of this article can be summarized as follows:
A novel collaborative learning framework for KD: not only can it improve the performance of parallel student networks, but also improve the performance of the fusion module in an end-to-end trainable manner.
The network architecture of parallel student networks can be different, and in order to reduce the impact of incorrect knowledge between networks on performance, a regularization process is introduced.
Related work
KD
Due to the excellent performance of DNNs in computer vision, speech recognition, and natural language processing, a variety of KD schemes have been proposed to train small networks with high performances. Existing KD schemes can usually be divided into three types: 18 (1) offline distillation,8–12 (2) online distillation,13–17 and (3) self-distillation.19–23 As a classic KD scheme, offline distillation can effectively improve the performance of the student network. However, it takes a lot of time to pre-train a large-scale teacher network. Therefore, how to choose a proper teacher network is also a difficult problem. Compared with the offline KD, online distillation does not require a pre-trained teacher network. All peer networks in online distillation are trained from scratch by transferring the knowledge from each other, but a poor-performance network may affect the performance of other networks during collaborative learning. Self-distillation indicates that the network improves its performance in a self-learning way, where one network is trained again using its pre-trained network as the regularization during learning. For instance, Yuan et al. 19 proposed a teacher-free knowledge distillation (Tf-KD) method, which is a special self-learning framework. Therefore, an effective distillation method should not only improve the performance of the student network but also save training time and storage space. To overcome the weakness existed in each distillation strategy, we explore a new distillation scheme, where multiple different schemes can work together to further improve the performance of the model.
Collaborative learning
Recently, many KD schemes based on collaborative learning have been proposed.14,15,24 Specifically, Zhang et al. 13 proposed a deep mutual learning (DML) strategy, where a group of student networks learn from each other and guide each other throughout the training process, instead of using a pre-defined one-way conversion path between teacher and student networks. Guo et al. 14 proposed knowledge distillation via collaborative learning (KDCL), which ensembles the output of different networks and then use the ensemble results to teach each individual network through collaborative learning. Lan et al. 25 constructed a multi-branch structure through the network hierarchy. The authors regard each branch as a student network, and merge these branches to generate a better-performing teacher network. Then, through the joint online learning of the teacher–student network, a single-branch model or a multi-branch fusion model with superior performance can be obtained. Chen et al. 26 proposed a two-level scheme for the online KD with a group leader and multiple auxiliary peers. Hou et al. 15 extracted and fused the features of two student networks to obtain more meaningful feature maps, and then input the fused features into the fused module. Although the final classifier can achieve better performance, two student networks must share the same network structure, because the authors adopt a simple “SUM” operation in the process of feature fusion. Kim et al. 16 made a further improvement on this basis of using feature fusion learning (FFL) to improve the performance of the fusion classifier. This scheme is also suitable for two student networks with different network structures. Different from the above methods, our proposed FFCL scheme learns different knowledge among the peer networks in the distillation process of collaborative learning, and uses a network regularization for each peer model to improve the performance.
The proposed method
In this section, we introduce our FFCL framework in detail. We first describe how to perform collaborative learning between peer student networks, and then introduce how to use regularization to improve the network performance during the learning process.
During the collaborative learning, different networks learn from each other using the feature knowledge in the middle layer and the response knowledge in the output layer. We extract features from the middle layers of two networks, and fuse these features to get more meaningful feature maps. 16 We then input the feature maps into the fusion module, and the output from the fused classifier will be used to guide each peer network to improve the performance. In this way, the network can learn the feature knowledge in the middle layer of other networks. At the same time, the networks also learn the response knowledge in the output layer from each other. 13 All networks are trained from scratch during the distillation process of collaborative learning. Furthermore, to make each peer network to be learned with more positive knowledge from its other networks, a model regularization process is introduced during collaborative learning. 19 Before the training process of the peer student networks, the model regularization is first carried out by pre-training all peer networks that can participate in the training process. During the training process, the knowledge is extracted from the pre-trained network and transferred to the corresponding network. The overview framework of FFCL is illustrated in Figure 1.

The framework of feature fusion-based collaborative learning (FFCL) for knowledge distillation. We extract features from the middle layers of two peer networks and input the feature maps into the fusion module after fusing these features. Besides, peer networks learn from each other in parallel with their own pre-trained teacher.
Notations
Given
Fused feature-based collaborative distillation
In the process of collaborative learning, the network learns two parts of knowledge from each other, namely, fused feature knowledge from the middle layers of the peer networks and response knowledge of their output layers. First, we introduce the feature knowledge during collaborative distillation. The features extracted from the middle layers of the given peer student network

where
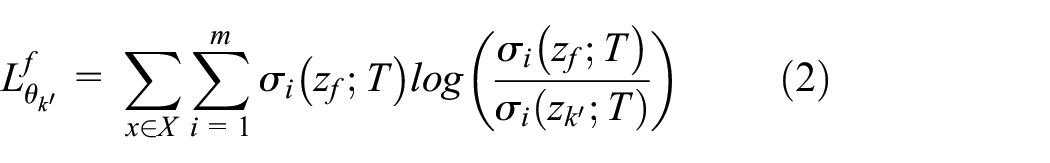
In the distillation process with fusing features, the fused model is always very small network and its used structure is chosen as in Figure 2. In the proposed FFCL, the used network structure of fused module
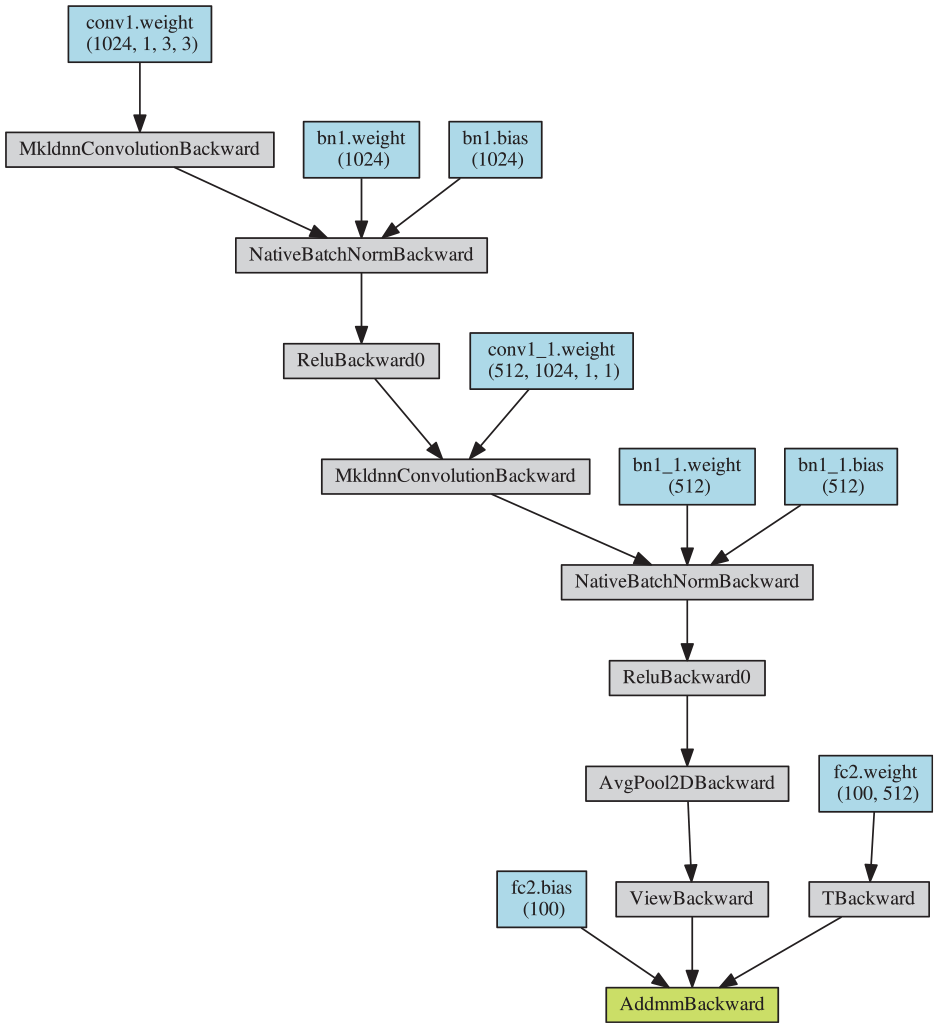
The structure diagram of the used fusion module
Next, we introduce the response knowledge during collaborative distillation. That is, one peer student network learns the knowledge from the output layer of the other peer student network during the training process. The distillation loss function of transferring response knowledge from the network

where the value 1 means the temperature parameter

Therefore, the distillation loss function for the network

where

Through the collaborative learning, the knowledge between the peer student networks is distilled from each other for learning the optimal peer student networks and obtaining the optimal fusion module.
Network regularization-based distillation
During the collaborative distillation, all student peer networks collaboratively train each other from scratch. However, the performance of the peer networks can be degraded by the negative knowledge from each other. In the process of peer model training, to provide the correct knowledge for each network as a guidance, we introduce network regularization. First, for the peer student networks to participate in the training process, we first pre-train them using the one-hot labels. Then, in the training process, the knowledge from the pre-trained network is transferred to learn its current same network. The logit output of the pre-trained network

Similarly, the distillation loss function as a network regularization for the peer network

In the ablation experiment, it is obviously that Case G, which only represents regularization-based distillation, is the most effective method among all the cases (Cases E–G). From this, we affirm the validity of network regularization and ensure the effectiveness of those pre-trained networks.
FFCL loss
In the distillation process, each step has its own favorable effect, and they work together to improve the network performance. In the framework of collaborative learning between two peer networks

where
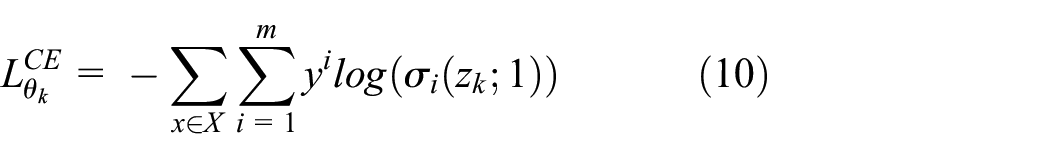

Similarly, for training network

where
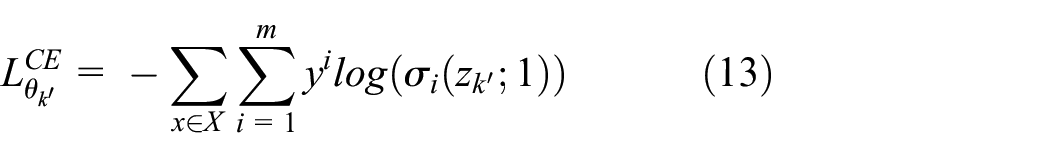
In summary, using the overall distillation loss function above, the collaborative learning of the two peer networks is performed by KD, and the proposed FFCL is shown in Algorithm 1. As a result, the proposed collaborative KD between two peer student networks can further improve the performance, which is verified in the experimental section.

FFCL extension
The formulation of the proposed FFCL above is based on two peer networks and can be a standard FFCL framework. In fact, it can be extended more than two peer networks. Given
Give the features extracted from the middle layers of all the networks (i.e.

During the collaborative learning among the multiple peer student networks, each network learns from the other

where
Finally, the overall distillation loss function of the general FFCL for learning the network
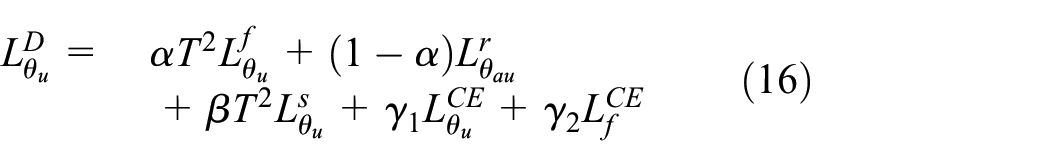
where
To intuitively understand the proposed FFCL, we provide the overview diagrams of the standard FFCL between two peer student networks and the general FFCL among three peer student networks, shown in Figures 3 and 4. In the figures, the green arrow represents the process of network regularization, and the yellow arrow represents the process of feature fusion.
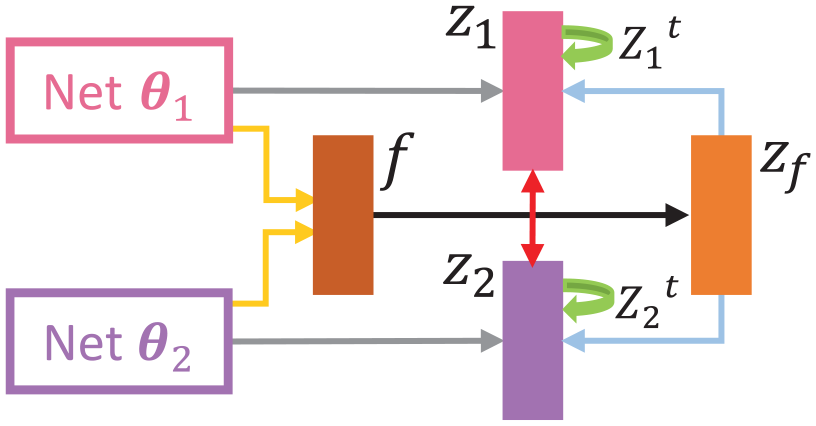
The standard FFCL based on two peer networks. In the figure,

The general FFCL based on three peer networks. In the figure,
Experiments
We conducted favorable experiments to verify the effectiveness of FFCL on CIFAR-10 and CIFAR-100 data set, 27 while comparing our FFCL framework with some classic and recent state-of-the-art methods including KD, 8 DML, 13 KDCL, 14 FFL, 16 and Tf-KD. 19 The architecture of each peer network was chosen from ResNet, 28 WideResNet (WRN), 29 and ShuffleNet. 17
Data sets and settings
CIFAR-10 contains a total of 60,000 samples, including 50,000 training samples and 10,000 testing samples. Those samples are divided into 10 classes. CIFAR-100 is similar to CIFAR-10, but contains 100 classes. And each class has the same numbers of training and testing samples.
In the experiments, we used stochastic gradient descent (SGD) optimizer with momentum 0.9 and weight decay 5e−4. For the hyper-parameters
All the reported accuracies were averaged over three runs that are randomly initialized. It is noteworthy that the compared Tf-KD method was trained with the network architecture
Baselines
To highlight the improvements of the competitors, we provide the baselines of the used networks without KD. On CIFAR-10 and CIFAR-100, we used baseline models including ShuffleNet, ResNet18 and ResNet34. Besides, WRN-28-10 was also used for CIFAR-100. The baselines were trained for 200 epochs with batch size 128. The initial learning rate is 0.1 and then divided at the 60th, 120th, and 160th epochs. We used SGD optimizer with momentum of 0.9, and weight decay was set as 5e−4. The average top-1 accuracy (%) of baselines for different networks is reported in Table 1.
The average top-1 accuracy (%) of baselines for different network architectures on CIFAR data.

WRN: WideResNet.
Results on CIFAR-10
We first compare our proposed FFCL based on two peer networks on CIFAR-10 data set with DML, 13 KDCL, 14 FFL, 16 and Tf-KD. 19 We considered five pairs of peer networks, selected from ResNet and ShuffleNet. The top-1 accuracies over three individual runs with the corresponding standard deviations derived by each model with different architecture settings are reported in Table 2.
The top-1 accuracy (%) over three individual runs with the corresponding standard deviations on CIFAR-10 data set.
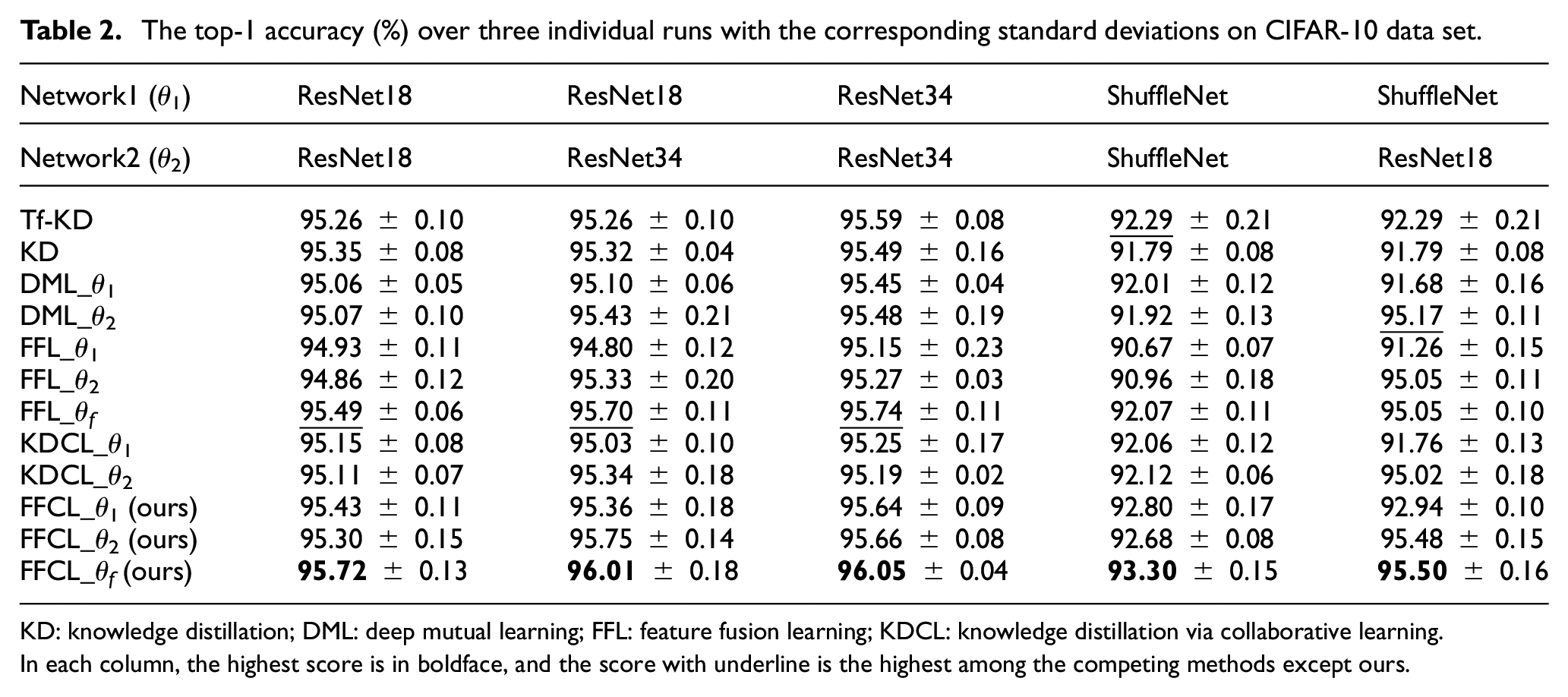
KD: knowledge distillation; DML: deep mutual learning; FFL: feature fusion learning; KDCL: knowledge distillation via collaborative learning.
In each column, the highest score is in boldface, and the score with underline is the highest among the competing methods except ours.
Equipped with the feature fusion mechanism during collaborative learning, our FFCL_θf achieved the highest top-1 accuracies across the five architecture settings, gaining improvement on the runner up by 0.24%–0.8%. Comparing the two peer networks (i.e.
Results on CIFAR-100
We further compared FFCL based on two peer networks using CIFAR-100 with KD, 8 DML, 13 KDCL, 14 FFL, 16 and Tf-KD. 19 Similarly, we considered six pairs of peer networks that were selected from ResNet, WRN, and ShuffleNet.
Table 3 shows the performance of all the models over the six architecture settings. Similar to what we observed on CIFAR-10, FFCL outperformed all the other state-of-the-art methods with a notable margin, which further demonstrates the effectiveness of FFCL in fusing features. Specifically, with network
The average top-1 accuracy (%) over three individual runs with the corresponding standard deviations on CIFAR-100 data set.

WRN: WideResNet; KD: knowledge distillation; DML: deep mutual learning; FFL: feature fusion learning; KDCL: knowledge distillation via collaborative learning.
In each column, the highest score is in boldface, and the score with underline is the highest among the competing methods except ours.
Further experiments
To further investigate the classification performance of the proposed FFCL, we conducted the comparative experiments on CIFAR-100 among the collaborative learning methods using multiple peer networks (i.e. more than two peer networks) including DML, 13 KDCL, 14 FFL, 16 and our FFCL. For easy implementation in the experiments, the collaborative learning was carried out on three different peer architectures composed of three peer networks.
The top-1 accuracies over three individual runs with the corresponding standard deviations derived by each peer model with different architecture settings are reported in Table 4. It can be seen that FFCL_θi significantly outperforms their counterparts with FFL and DML, and our FFCL_θf performs very better than FFL_θf. Moreover, through the experimental results in Tables 3 and 4, our FFCL_θf with three peer networks obtains the counterpart with two peer networks. Thus, the comparative experiments on the peer architectures of two and three student networks show that our proposed feature fusion-based collaborative distillation is very effective.
The average top-1 accuracy (%) of FFL, DML, and our FFCL using three peer student networks over three individual runs with the corresponding standard deviations on CIFAR-100 data set.
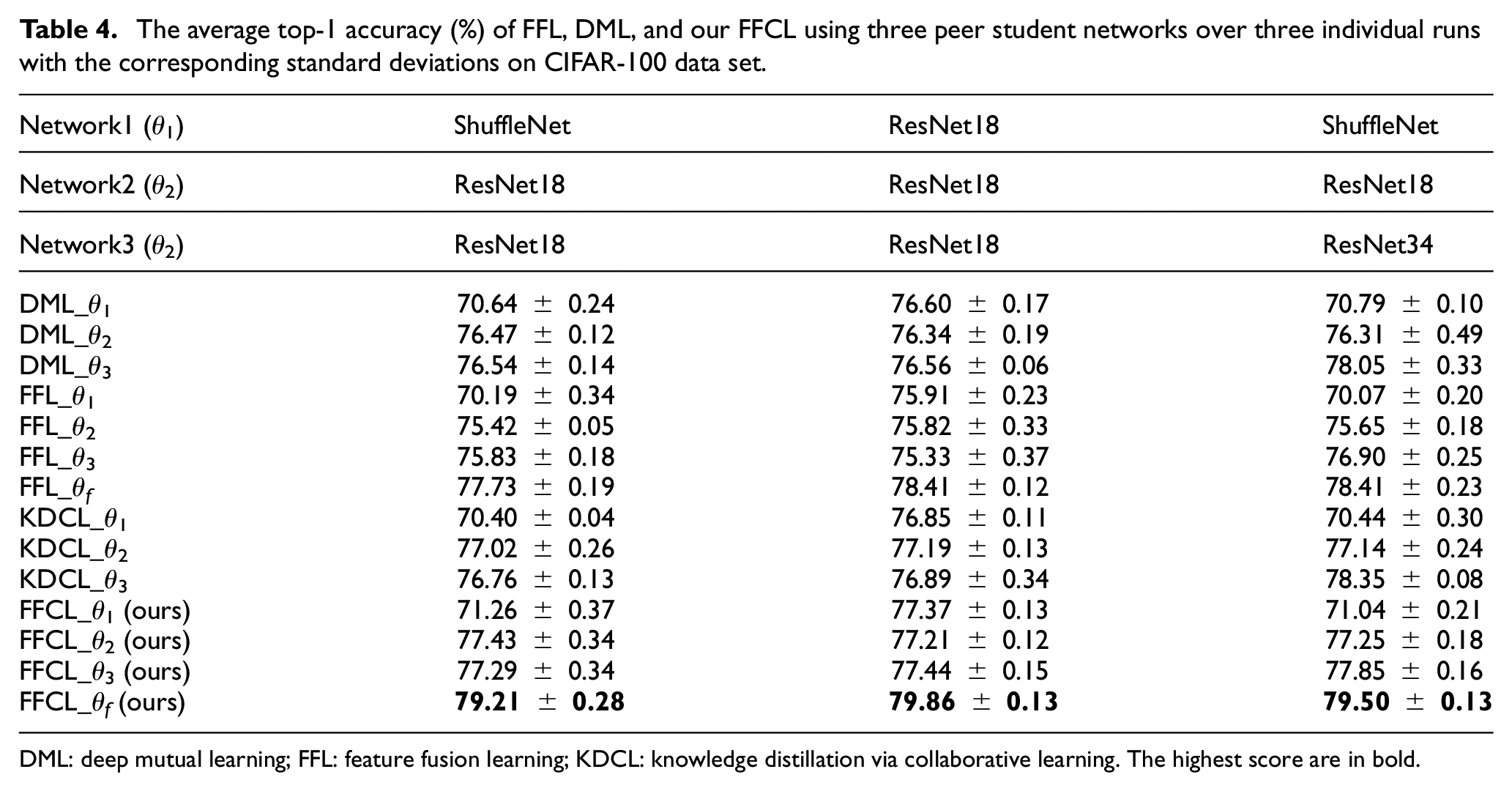
DML: deep mutual learning; FFL: feature fusion learning; KDCL: knowledge distillation via collaborative learning. The highest score are in bold.
Ablation study
Our FFCL framework transfers variety kinds of knowledge while training the peer networks through collaborative learning. We verify the importance of each kind of knowledge with a set of ablation studies in this section. As shown in Table 5, we carried out experiments under seven settings. The two peer networks were set to ResNet18. RK means the response knowledge, namely, the knowledge of the output layer transferred between networks, it corresponds to
Case A represents our proposed FFCL scheme with the objective function
Case B only retains the feature knowledge and the network regularization knowledge, where the objective function for the peer network
Case C keeps the response knowledge and the network regularization knowledge, where the objective function for the peer network
Case D excludes the network regularization knowledge where the objective function for the peer network
Case E only includes the response knowledge where the objective function for the peer network
Case F only includes the feature knowledge where the objective function for the peer network
Case G only includes the network regularization knowledge where the objective function for the peer network
Ablation study of FFCL in terms of the average top-1 accuracy over three individual runs with the corresponding standard deviations on CIFAR-100. ResNet18-ResNet18 was selected as the peer architecture.
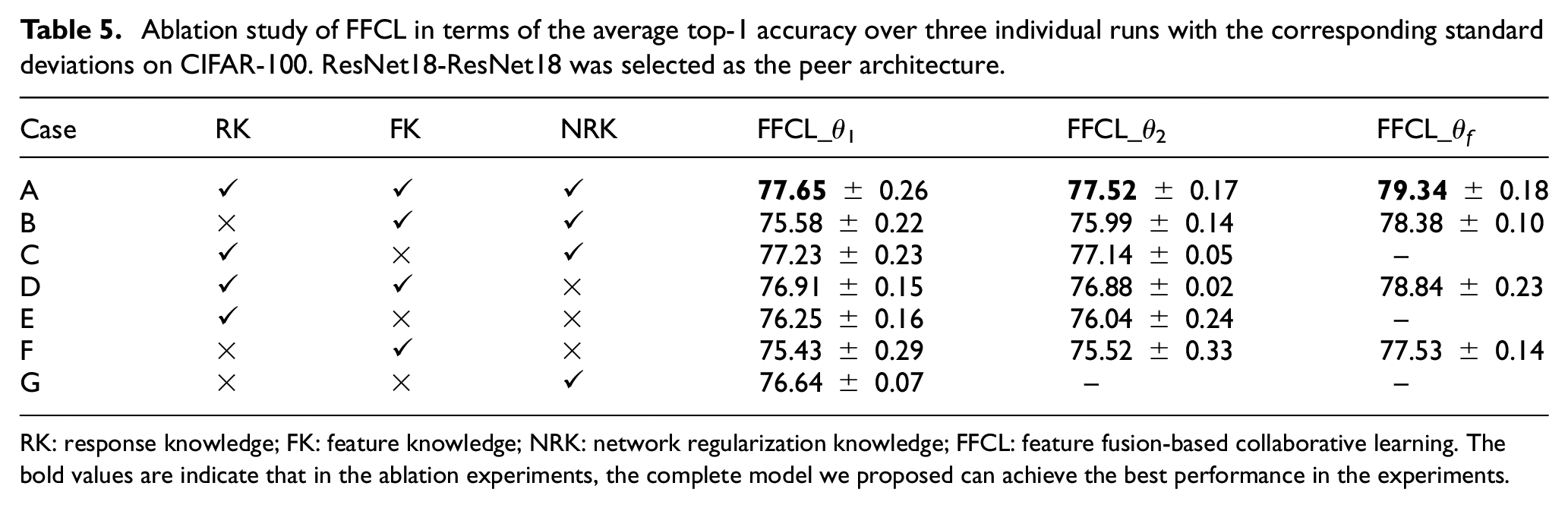
RK: response knowledge; FK: feature knowledge; NRK: network regularization knowledge; FFCL: feature fusion-based collaborative learning. The bold values are indicate that in the ablation experiments, the complete model we proposed can achieve the best performance in the experiments.
It should be noted that
According to the ablation results in Table 5, the removal of any knowledge will cause performance degradation. More importantly, the FFCL_θf via the fused feature knowledge transfer performs better than FFCL_θ1 and FFCL_θ2 with and without using fused feature. Thus, these ablation results verify the effectiveness of our proposed FFCL method via collaborative learning, network regularization, and feature fusion.
Conclusion
In this article, we have proposed a novel KD framework called FFCL. Through collaborative learning, the proposed FFCL method effectively concatenates the features of peer networks to generate a more expressive feature map for transferring feature knowledge between peer networks. Meanwhile, it also transfers the response knowledge in the output layers between the peer networks during the distillation process. We have also introduced a regularization process, which eliminates the trouble of training for a large teacher network and provides a positive knowledge for the student peer network, leading to a further improved performance. The insights of collaborative KD given by FFCL can potentially facilitate the future works.
Footnotes
Handling Editor: Yanjiao Chen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was, in part, supported by the National Natural Science Foundation of China (grant nos 61976107 and 61502208) and the Postgraduate Research and Practice Innovation Program of Jiangsu Province (grant no. KYCX20_3085).