
Abstract
In the Internet of Things-Edge cloud, service provision presents a challenge to operators to satisfy user service-level agreements while meeting service-specific quality-of-service requirements. This is because of inherent limitations in the Internet of Things-Edge in terms of resource infrastructure as well as the complexity of user requirements in terms of resource management in a heterogeneous environment like edge. An efficient solution to this problem is service orchestration and placement of service functions to meet user-specific requirements. This work aims to satisfy user quality of service through optimizing the user response time and cost by factoring in the workload variation on the edge infrastructure. We formulate the service function placement at the edge problem. We employ user service request patterns in terms of user preference and service selection probability to model service placement. Our framework proposal relies on mixed-integer linear programming and heuristic solutions. The main objective is to realize a reduced user response time at minimal overall cost while satisfying the user service requirements. For this, several parameters, and factors such as capacity, latency, workload, and cost constraints, are considered. The proposed solutions are evaluated based on different metrics and the obtained results show the gap between the heuristic user preference placement algorithm and the optimal solution to be minimal.
Introduction
Edge computing is an architectural development of computing with access to a shared pool of configurable, ubiquitous, and decentralized computing resources and services in close proximity to users. The Internet of Things-Edge (IoT-Edge) cloud is a distributed hierarchical network with partitioned layers of IoT/sensor devices, intermediate layer of processing servers, and a more centrally located core cloud for data processing and storage. 1 To support the IoT and critical applications, edge computing needs to ensure reliability, availability, efficiency, high performance, self-healing, and cost-effective deployment. In IoT-Edge cloud computing, service provision presents a challenge to operators to meet the service-specific quality-of-service (QoS) requirements and satisfy service-level agreements (SLAs) with the users. Challenges such as limited resources, network congestion, large network latencies, and large amounts of generated data traffic contribute to lowering the user QoS, which can be mitigated by the optimal placement of service functions (SFs) at the edge network. Different virtual SF components are aggregated together to realize a service or a service function chain (SFC). IoT application components can also be implemented as SFs within the IoT-Edge environment with the structured graphs also forming SFCs. The relative placement of SFs affects the end-to-end latency leading to increased network delays, and in extreme cases may lead to a traffic loop as packets for a network service request traverse the same virtual machines (VMs) repeatedly consuming more bandwidth. 2 While the problem of SF placement in core data centers (DCs) 3 has been widely researched, a gap still exists in the IoT-Edge computing domain. This work addresses the service function placement at the edge (SFPE) problem, whereby less consideration has been made toward the user QoS with most solutions focused on service provider’s deployment perspective.
A key metric for IoT-Edge performance evaluation is latency. While most studies’ approach is optimizing resource allocation strategies or through proactive dynamic resource provisioning,4,5 our work takes a user centric approach with user response time and cost as the main parameters under investigation. The IoT is heterogeneous and highly dynamic with multiple events which need edge systems to be able to dynamically adjust to network parameters (data traffic) and be able to deploy more resources on-demand for a timely response. A user-centric approach allows to anticipate user interests in different services 4 which vary and may have different characteristics. Identifying a usage pattern with the objective of optimizing the QoS ought to inform how allocation decisions influence overall system performance when subsets of SFs are shared by multiple services. Typical characteristics and some representative use cases facilitated by the IoT-Edge include the following: low latency communication for real-time IoT applications (mobile gaming, intelligent transportation); geographical distribution for localized data processing; and effective bandwidth management by offloading to the edge cloud. 6 Some issues to consider include, among others, the host compute capabilities, total latency, inter-host latencies, as well as the SF response times. Other issues include energy consumption and efficiency of IoT-Edge systems.7,8 In Agarwal et al., 4 a placement heuristic is evaluated, with latency the main optimization goal. The study in Fei et al. 5 focuses on proactive dynamic resource provisioning for overloaded SFs. While the approach in Fei et al. 5 is similar to ours in terms of splitting the SF requests into categories based on their latency tolerance, the difference is that we employ user request patterns and their similarity to select and schedule a set of candidate requests for priority placement with QoS consideration factored. The studies in Yala et al. 9 and Cziva et al. 10 also optimize access latency for uRLLC traffic through a genetic algorithm and Tabu search metaheuristics, but these studies did not consider chaining constraints and user response time.
The complexity of user requirements creates a challenge in terms of resource management in a heterogeneous infrastructure like the IoT-Edge cloud, where each SF selects the best matching resource from the available resource pool. Most placement strategies assume a static cluster of resources, 9 and this becomes a bottleneck in terms of resource management and service heterogeneity 11 and regardless of how optimal the initial service task arrangement is, it will degrade as the resource utilization and workload change over time. 12 Some services require both shareable and non-shareable 13 which means that multiple demands compete for limited edge resources impacting the workload capacity. Our approach to address this involves splitting the workload into priority classes, which facilitates grouping requests by SF characteristics, resource availability, and user patterns.
Prediction and pre-allocation of resources also depend on users’ behavior and future probability of using the resources. 14 Estimating resources beforehand creates efficiency and fairness in resource management. In Zhou et al., 15 the selection of an SF for each service request is performed with the goal of optimizing the overall QoS criteria of the composite service. QoS correlation between services may have significant impact on the overall QoS values of composite services. These correlations occur when some QoS attributes of a service are not only dependent on the service itself but correlated to some other service. We present an approach to the SFPE problem 16 with the objectives of optimizing user response time, resource workload, and cost for enhanced user QoS. An analysis of the resource workload for service requests is necessary in providing an optimal QoS guarantee for the user satisfaction. This work addresses SF placement in the IoT-Edge cloud environment and our approach models the multiple user requests in terms of user preference and service selection probability to determine placement. We also adopt a network hyper-exponential queuing approach to model the allocation of resources based on demand for specific service types and formulate a heuristic solution for optimized placement of different service requests. By utilizing the user patterns, we develop a framework that allows to prioritize placement and ensure reliable service provisioning. Our approach targets a lower cost of resources and user latency to improve the user QoS. Minimizing the total cost releases additional resources that can potentially be used to allocated additional SFs and improves the acceptance rate of requests for service chains. Specifically, this article makes the following contributions:
We define and formulate the SFPE problem and prove that this mixed-integer linear programming (MILP) optimization problem is an NP-hard problem.
We model user preference and service request patterns; we adopt the cosine similarity index value to highlight similarities in user requests and determine an optimal policy for categorizing them.
We design a heuristic user preference placement algorithm (HUPPA) and compare our approach with Greedy, Baseline, and Optimal algorithms. The experimental results show that our approach is superior to Greedy on resource cost minimization.
The rest of this study is organized as follows. We formulate and model the SFPE optimization problem in section “Problem formulation.” Section “HUPPA algorithm design” presents our meta-heuristic HUPPA algorithm. Section “Simulation and numerical experiments” gives results evaluation, followed by a discussion. Finally, section “Conclusion” concludes the article.
Problem formulation
We consider an IoT-Edge computing cloud consisting of a set of n edge nodes,
Notations.

User request–similarity model
In practice, multiple users have varying degrees of interest for various services. This influx of request demands can overwhelm the provider infrastructure and affect the user QoS, thus the system is best served if it is prepared to handle such workloads. This problem can be likened to the resource matching problem,17,18 where the user and service request requirements are estimated a-priori and a match is made based mainly on the user preference data. Multiple-attribute decision-making methods are necessary to comparison and to set up the preference or similar relations among QoS attributes of user requests and available resources. Our model introduces preference modeling and considers it an indispensable step in the decision-making process. The request probability for different services correspondingly varies and can be characterized in terms of user preference. Given a set of SFs

To efficiently classify the request, we adopt a similarity computation approach for active users that are active around a given edge. A similarity measure or similarity function is a real-valued function that quantifies the similarity between two objects. We assume that there is no prior history data on user requests made for services hosted on these specific edge nodes made by users. The cosine similarity index method 19 involves feature vectors which represent requests from users U for SFs F. In our model, we assume multiple users make multiple requests for a specific service composed of various SFs. Figure 1 shows an example of this scenario whereby multiple user request queues with correlated SFs show in dashed circles. The arcs between SFs show the correlation in similarity. Afterwards, a candidate set is created based on similarity of these functions. A repository is created that is updated when a new service request is added into the repository or when an existing service is updated or removed from the repository. Based on a QoS criteria a new subset is implemented where similar requests are then aggregated, ranked, and finally placed on appropriate nodes.

Similarity matching framework.
One motivation for this is to reduce the cost on resources required to instantiate the constituent VMs hosting them by allocating collective resources to requests with similar demands, subsequently reducing the request processing time. The user requests follow a uniform distribution 15 whereby requests are generated and a realistic representation of our scenario. The mathematical representation of the method is shown in equation (2), where the left-hand side is the degree of proximity with a range of [0,1] between users’u and w requests. Afterwards, the requests are aggregated based on QoS requirements that will later form placement policy. To ensure objectivity, we conduct a similarity weighting 19 to reduce matching time and improve matching efficiency. We use the enhanced Top-K algorithms in Wang et al. 20 to rank the users based on the Pearson coefficient similarities and select the Top-K most similar users for making QoS value predictions. The Pearson correlation coefficient (PCC) mirrors the level of direct relationship between two factors, that is, the degree to which the factors are connected, and extends from +1 to −1. 21 A connection of +1 implies that there is a great positive direct relationship between factors or in different words two clients have fundamentally the same tastes, while a negative connection shows that the clients have divergent tastes. Pearson’s connection coefficients are utilized to determine whether the level of the relationship is dynamic. Different from traditional Top-K algorithms, we adopt the approach in Wang et al. 20 where users with PCC similarities less than or equal to 0 are excluded, that is, removing the negative similarity. This creates a top subset of similar users’ functions, where K represents the subset of similar user requests. The modified user request top set can be found with the following equation


Service latency
Service operators aim to derive suitable placements for SFs on physical nodes or VMs can be launched subject to the demand. One objective of SFPE is to find an appropriate placement for

We explore the notion of multiple requests arriving at the edge in the Poisson distribution for packets with a certain frequency which we refer to as service request arrival rate
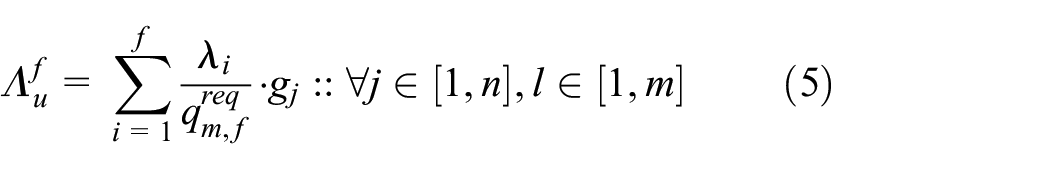
In our model, we assume that different users make a single request for a specific service at a given time and these similar requests are then aggregated together and instantiated. The motivation for this is to reduce the cost on resources required to instantiate the VMs hosting them by allocating collective resources to requests with similar demands. Before we proceed, we would like to stress the significance of transmission time as a dominant factor in large networks9,18 but in our work we do not consider it. This is because the SFs are deployed at the same physical location.
Propagation latency
The propagation delay involves the flow of packets that travel to the edge cloud which in turn experience a certain delay value determined by the physical path and the respective link congestion that occurs between the user source device and destination node where the SF instantiated. We assume the nodes are all located in a cluster and therefore we do not take into consideration the latency between edge nodes in our model, as the bandwidth consumption rate is negligible. Furthermore, we also assume a uniform propagation delay value

Processing latency
Processing delay generally includes a queuing delay that is determined by the number of user service requests in addition to the traffic. In the first processing phase we consider the edge network an open network and assume the total incoming request arrival rate

where

Workload
In most existing cluster management systems, for example, Alibaba, two main categories of workloads are defined: batch jobs and long running services. 25 Batch jobs are characterized as delay tolerant with a limited lifetime, while the latter requires high availability and low latency, for example, web-based applications. Zhong and Buyya 12 investigated four representative workloads: (a) a stable workload pattern represents situations where the workload density does not have any obvious fluctuations; (b) a growing workload pattern may emulate a scenario where an application suddenly becomes popular and attracts a considerable number of visits, holding a high accelerating rate; (c) a cycle/bursting workload could simulate online shopping websites where the network traffic experiences periodical changes and reaches a peak during certain time ranges; and (d) an on-and-off workload pattern depicts applications periodically having a short active stage, such as map-reduce jobs executed on a daily or weekly basis.
Our work focuses on a growing pattern that emulates a scenario where an application suddenly becomes popular and attracts a large visit rate. The expected number of visits (requests) to a node hosting an SF is a ratio which shows the frequency of instantiation of different functions. Its value supplements the user preference model and is given as

Cost
In our previous work,
27
we treat cost as a function of the associated VM workload and it was observed that when SF workload pressure is large among VMs, the execution time will be affected. We look at cost from a SF processing capacity perspective and consider inter-host traffic as a higher rate of inter-host traffic might lead to congestion given constraints on the bandwidth demand. Inspired by Raumer et al.
28
and Ramaswamy et al.,
29
we formulate the total costs

Optimization analysis
System delay is a critical metric to ensure QoS is maintained and in our work, the objective is to minimize the user response time and cost while optimizing the workload. The SFPE problem can thus be formulated into two parts: to realize the joint objectives of minimizing the response time, we solve the sub-modular optimization problems P1 and P2



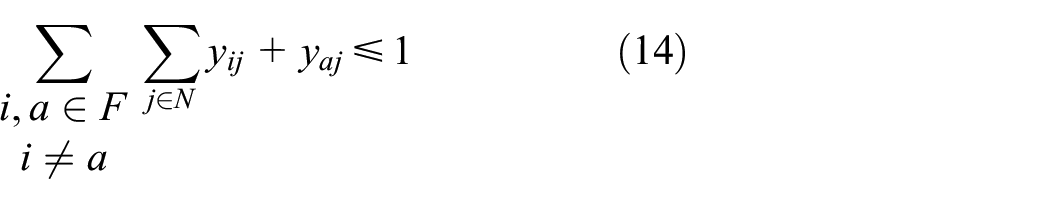



Constraint in equation (12) ensures that the SF processing capacity does not exceed the available capacity. Constraint in equation (13) affirms that at least an SF instance has to be instantiated for any active request. Anti-affinity (cases whereby the other correlated SFs can be instantiated separately but still preserve their functionality in a chain) is preserved in equation (14) for SFs that are dissimilar in characteristics and QoS requirements but form part of the same chain. Equation (16) ensures that no requests will be dropped. Congestion control is guaranteed in equation (17).
HUPPA algorithm design
To conduct multi-objective optimization, often huge computational effort is required. 30 In most of the cases, multi-objective optimization problem is designed to meet a particular scenario reducing their adaptability and makes them less scalable. Besides, solutions to a multi-objective optimization problem have a large time complexity, therefore placing such an approach is at a disadvantage in a real-time IoT-Edge environment characterized by resource constrained nodes. It can be easily seen that P1 and P2 are NP-hard and an analytical solution will be computationally expensive. Therefore, we design a priority-driven algorithm HUPPA that places SF requests with lowest latency priority and to find a near-optimal cost-effective placement solution for the user. An SF repository is created and is updated when a new service request is added into the repository or when an existing service is updated or removed from the repository (Figure 2). We use a set Activlist to save the active compute nodes, that is, nodes in service and a set Vaclist to save the spare compute nodes with residual capacity. A set Servlist holds the initial set of SFs that are to be instantiated. Another set Holdlist holds the remaining SFs that are yet to be placed after instantiation. HUPPA first checks the availability of resources (lines 2 and 3) after which the Servlist which contains the already categorized requests as results from Algorithm 1. This is facilitated by the visit rate. Lines 6 and 7 then select the first request and sorts its component SFs based on decreasing latency values. The results are then placed into the Holdlist SF where similar instances are aggregated (line 8). The active compute nodes are then sorted from those with least to highest processing capacity. The reason for this is that we aim to place those SFs with least resource-demand to proportional nodes to prevent oversubscription of resources, as the scenario we are investigating is for a growing pattern that emulates a scenario where an application suddenly becomes popular and attracts a large visit rate, holding a high accelerating rate workload. To ensure system stability and maintain a high admission rate (line 11) affirms constraint in equation (17). At this point, the algorithm checks that the end-to-end latency requirement for multiple SF requests is not compromised (line 12) and the node capacity of active nodes can host another instance (line 13). For placement of multiple SFs, the algorithm chooses the node with maximum processing capacity to facilitate re-usability of the node for future placements (line 15). If the minimum QoS requirements cannot be guaranteed, then no placement can occur, and the lack of a feasible solution forces the system to terminate and loop back to line 2. This process continues in a loop fashion until all SFs are successfully placed (line 16), otherwise the placement is complete, and a new service is selected, until all SFs have been successfully placed.

HUPPA placement framework.


Simulation and numerical experiments
In this section, we conduct simulations to evaluate our approach. We choose response time and executive cost to examine the efficiency of HUPPA algorithm. We investigate six commonly requested different SFs:28,31 NAT, FW, TM, WOC, VOC, and IDS. Each SF represents a different profile in terms of requests arrival distribution, delay tolerance and processing capacity.
We model a scenario similar to Cziva et al., 10 Mouradian et al., 16 and Mutichiro et al. 27 with an edge cloud of 3–10 nodes. The number of requests range from 30–1000, with all instances featuring SFCs of varying lengths from 3 to 6 SFs/IoT applications generated uniformly. The packet size of the data transmitted in the chains is selected randomly in the range of 64–1518 bytes. The number of users is set at between 10 and 100. We assume the arrival time of requests follows a Poisson distribution with an arrival rate ranging from 500 to 800 requests/second. The service rate for SF instances varies between 600 and 1200 units. Optimal solutions for selected instances were obtained using general linear integer programming implemented in CPLEX solver. The performance of the proposed algorithm is compared with Greedy and Optimal algorithms. We investigate the parameters of delay, workload and cost and observe how they meet the user QoS demand requirements. We briefly describe the sequence of the Greedy algorithm for comparison:
Greedy approach
For each service request, this algorithm will sort a list of candidate nodes and first place an SF into one of the best nodes in terms of available resources. If the first one is fails due to constraint violation, the next one will be selected. This loop is continued until placement of all the SFs into the physical nodes occurs.
Baseline approach
The algorithm performs similar to the approach used in hybrid clouds. 32 It considers first SFs that have a high priority level and then selects a node to place an instance of the SF with adequate processing resources.
The reason we selected this approach is to compare our own approach with an algorithm that seeks to benefit as much as possible from the IoT-Edge infrastructure.
In Figure 3, we compare our heuristic with the Optimal and Baseline
32
approach in a typical scenario over a period of 1 hour. Optimal adopts the MILP model and as expected provides the lowest response time. It can then be observed that for the Greedy, the delay increases exponentially from 600 requests/hour. Greedy algorithm does not categorize the requests according to QoS requirements and tries to allocate them to instances/consolidate them on the same node thereby increasing the response time for

Comparison of delay versus arrival rate.

Average delay versus arrival rate.
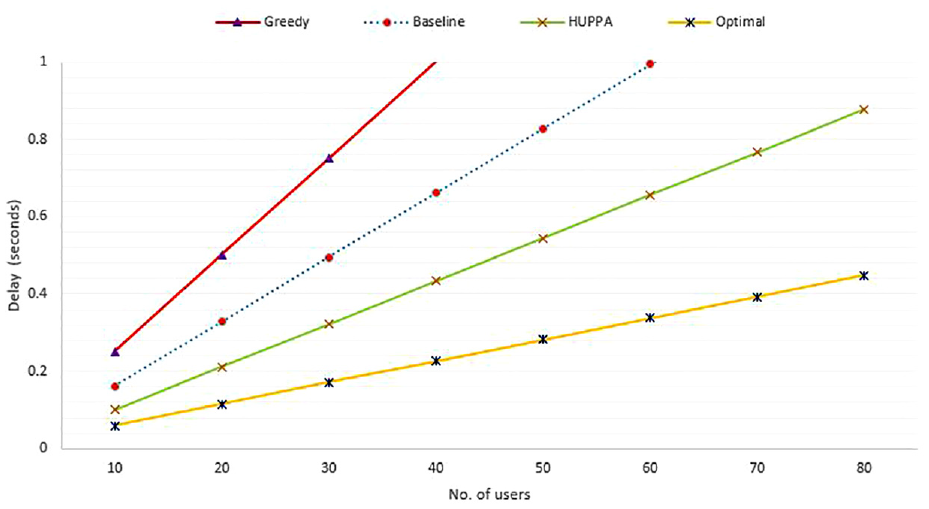
We also observed that the huge impact on the performance in average delay is significantly lower than for Greedy and the solution values are comparable for the other three algorithms with the exception of Baseline. In detail, when
Figure 5 shows the processing delay values for four algorithms, in which Greedy has a higher delay proportional to number of users. However, HUPPA exhibits a lower response time as the user numbers increase. This is due to the steady-state policy nature of the
Delay versus number of users.
Workload–delay tradeoff
We evaluate workload for a growing workload scenario as shown in Figure 6. For Greedy, most requests remain in pending status with poor QoS performance as it does not take into consideration how overloading the compute nodes can exponentially increase the overall queuing and processing delays. This leads to higher response time, as resource consumption from all active instances keeps accumulating simultaneously and there is under-utilization of resources. However, HUPPA supports an on-demand workload scaling strategy which together with the selection strategy allows it to avoid over-utilization of resources ensuring load balancing to optimize the workload. This can be explained with the increase in generated traffic, whereby the resources are stretched, and some SFs may need to be duplicated to meet demand as more SF instances are provisioned. Therefore, being able to instantiate multiple similar requests for the same SF instances allows HUPPA to better utilize resources increasing the CPU utilization efficiency and lowering the response time. Another observation is Baseline utilizes a higher number of resources as it instantiates a higher number of SFs and seeks to place them on only the best nodes. This limits its efficiency as the incoming traffic’s granular characteristics are not taken into account during placement resulting in increased delays. We observe from Figure 7 that with variance in workload processed by the nodes against incoming user requests. HUPPA is able to balance the workload relative to the processing capacities of the different nodes where the SFs are instantiated along the objectives reducing response time and cost. Baseline and Greedy only consider resource usage as an evaluation measure, as both algorithms try to exhaust the resources of each node to minimize resource idleness. While this is good for cost minimization, it increases delay overhead leading to increased response times.

CPU usage versus arrival rate.

Workload variance versus arrival rate.
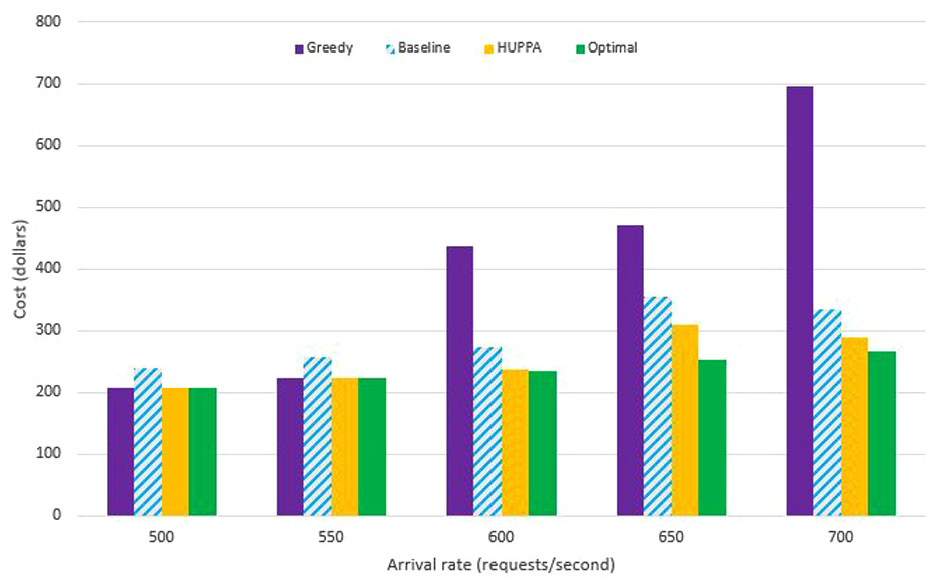
Cost–delay tradeoff
To analyze the cost for transmitting, receiving, and processing packets, we set
Experimental values.

Cost versus arrival rate.
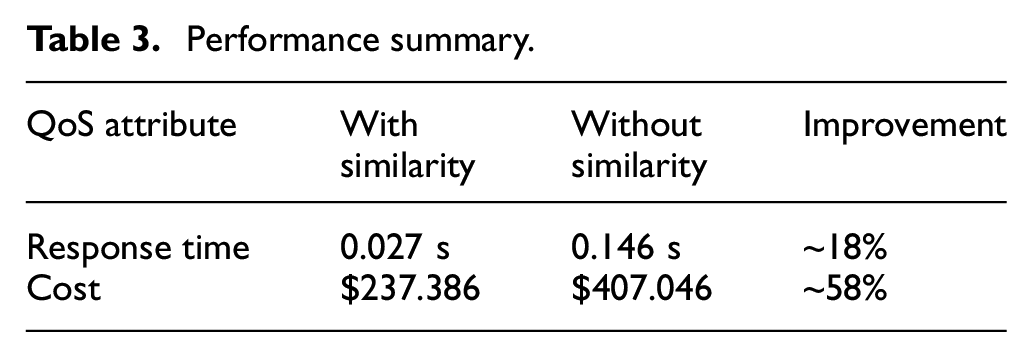
Performance summary.
State-of-the-art
The estimation of resources beforehand creates efficiency and fairness in resource management in the edge environment. Considering the rapid growth of 5G and enablers such as IoT and cloud computing technology, service providers have realized that service QoS and user satisfaction are fast becoming benchmarks in ensuring quality service provision. The current state-of-the-art has adopted users’ behavior as a tool to predict and pre-allocate resources as well as determine future probability of using the resources. 14 Wang et al. 20 have addressed the challenge of QoS prediction for service recommendation in edge computing by modeling user mobility and data volatility to adapt to mobile edge computing environments. They calculate user or edge server similarity depending on users’ changing locations. However, they also identify shortcomings in their approach specifically, a decreased prediction accuracy when the edge server distribution is sparse. Li et al. 17 also proposed a method of resource prediction based on QoS values. Their approach uses QoS attribute values like response time, availability, and price that are requested by users to calculate the similarity between the user requirements and edge resources. They adopt similarity matching algorithm and regression-Markov chain prediction method. However, their work does not go beyond just matching resources as other areas like resource scheduling and allocation are not considered. Our work builds upon the state-of-the-art by combining similarity matching with the resource allocation aspect. We propose and implement a model that adopts service request patterns to realize a user preference and to highlight similarities in user requests. Using different QoS attributes, we are able to further filter and rank similar requests after which we implement an optimal policy for allocating resources to instances that are matched to those top requests. The benefit here is three-fold: our heuristic approach achieves a lower response time and due to its scalable nature, it ensures a better cost-delay tradeoff. It also prevents resource wasting and overprovisioning while minimizing QoS degradation. Also, another area we address is the characteristic of the incoming traffic, whereby we model for a growing workload with increasing intensity overtime. This is important as it imitates a typical edge environment that may need to scale periodically on-demand but still maintain a high resource utilization numbers while meeting the QoS requirements.
Conclusion
In this work, we investigated the SF placement in edge computing problem in a scenario with rapidly increasing workload within a short period in a resource-constrained environment. The method consists of a comparison of batch user requests in a similarity-based manner and categorizing them according to QoS requirements. The placement then aims to optimize user response time and cost. For this, we proposed a framework that utilizes the user patterns to derive similarity in user requests and subjected to policy engine rules, it then determines and prioritizes which requests to instantiate at the IoT-Edge cloud and how many replicas are needed to meet the user service requirements. The key parameters we considered were latency and cost, whereby consideration was given to the dynamic and bursty nature of IoT data traffic as well as consideration for the heterogeneous edge environment. We propose two algorithms: the first is similarity matching heuristic that creates a set of similar requests and ranks them; the second is heuristic that ensures placement occurs and user QoS requirements are not violated, while achieving the objective goal. The results of our experimental evaluation have further confirmed that a use case based on our similarity framework can not only mitigate delay without data loss but also improve the user QoS for the IoT-Edge cloud. Results show that our approach offers better performance with near-optimal results compared to current state-of-the-art. Future directions include enhancing our framework to consider different forms of dynamic workloads with a focus on user mobility.
Footnotes
Handling Editor: Yanjiao Chen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Institute for Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT, No. 2020-0-00946, Development of Fast and Automatic Service Recovery and Transition Software in Hybrid Cloud Environment) and the ITRC (Information Technology Research Center) support program (IITP-2021-2017-0-01633) supervised by the IITP.