
Abstract
Time series have broad usage in the wireless Internet of Things. This article proposes a nonlinear time series prediction algorithm based on the Small-World Scale-Free Network after the AIC-Optimized Subtractive Clustering Algorithm (AIC-DSCA-SSNET, AD-SSNET) to predict the nonlinear and unstable time series, which improves the prediction accuracy. The AD-SSNET is introduced as a reservoir based on the echo state network to improve the predictive capability of nonlinear time series, and combined with artificial intelligence method to construct the prediction model training samples. First, the optimal clustering scheme of randomly distributed neurons in the network is adaptively obtained by the AIC-DSCA, then the AD-SSNET is constructed according to the intra-cluster priority connection algorithm. Finally, the reservoir synaptic matrix is calculated according to the synaptic information. Experimental results show that the proposed nonlinear time series prediction algorithm extends the feasible range of spectral radii of the reservoir, improves the prediction accuracy of nonlinear time series, and has great significance to time series analysis in the era of wireless Internet of Things.
Introduction
Numerous data spark in many known or unknown fields with the advent of 5G and the Internet of Things era; these data submerge the world that human beings depend. The analysis of these data has brought great challenges to scholars and has become a hot spot of artificial intelligence research.1–3 Time series data refer to a consistent stream of datasets over the course of a period of time. The time series analysis by machine learning method mainly includes clustering, classification, anomaly detection, and prediction, which will bring significant benefits to all kinds of people in various vertical fields.4,5 Therefore, this article researches the time series prediction method to provide more possibilities for analyzing a large number of time series in the wireless Internet of Things.
Time series prediction is widely used in the fields of industry, 6 economy, 7 environment, 8 and so on. However, most of the time series show strong nonlinear characteristics in the real world. Therefore, it is necessary to construct a prediction model by using a nonlinear prediction method to improve the model’s fitting ability to the nonlinear time series data. At present, nonlinear prediction methods are mainly divided into two categories. One is the regression method,9–13 which is suitable for time series prediction with slower change, and the nonlinear characteristics of the time series are easily eliminated by its linearization process. The other is to predict by the neural network in machine learning,14–16 especially represented by echo state network (ESN).17,18 It has a large, sparsely connected reservoir, and its learning method is efficient.19,20 The approximation capability of nonlinear time series is mainly ensured through its reservoir. However, the random connection of internal neurons in the reservoir of traditional ESN leads to the randomness of the network structure, making the model training purposeless and poorly adaptable, and unable to meet the requirements of effective prediction to nonlinear time series.21,22 Therefore, it is necessary to analyze and improve the network structure of the reservoir.
To improve the performance of the reservoir, some scholars proposed the small-world networks to replace the random network.23–26 The small-world network is a kind of network structure that can reflect the real world. It has both a short average characteristic path length (ACPL) and a high average clustering coefficient (ACC) and has the advantage of random network and regular network. The literature27–30 proposed a small-world echo state network (SWESN). It used a small-world network to improve the structure of the reservoir and improve prediction accuracy and adaptability.31–33 Kawai et al. 34 studied the performance of the reservoir under three different topologies: regular network, small-world network, and random network, which proved the superiority of the small-world network. However, the real-world social network nodes are randomly distributed at birth and gradually form a life circle. Therefore, some scholars applied this idea to improve ESN through clustering methods. The internal neurons of the reservoir are clustered to construct the synaptic matrix according to the clustering information. Furthermore, the predictive model is constructed to improve the nonlinear prediction capability. 35 Deng and Zhang 36 proposed a scale-free highly clustered echo state network (SHESN), whose reservoir is uniformly clustered with both small-world and scale-free characteristics. It was successfully applied to Mackey–Glass (MG) and laser time series prediction and obtained higher prediction accuracy than ESN. The Xue te al. 37 applied SHESN in the financial time series prediction and achieved better prediction performance. It proved that the high clustered scale-free network has strong computing power. Lei et al. 38 proposed a complex ESN based on prior clusters. The results of power spectrum analysis are used as prior knowledge to construct subclusters for the prediction problem of traffic flow time series with multi-period characteristics. Najibi and Rostami 39 used the k-means algorithm to optimize the clustering effect of the reservoir in SHESN. However, the number of cluster heads in the reservoir must be pre-set according to prior knowledge.
This article is absorbed in the problem that the above method relies too much on prior knowledge when clustering. In order to improve the clustering performance, the nonlinear time series prediction algorithm based on the Small-World Scale-Free Network after the AIC-Optimized Subtractive Clustering Algorithm (AIC-DSCA-SSNET, AD-SSNET) is proposed. It can adaptively obtain optimal clustering scheme and construct a complex clustering network with small-world scale-free characteristics. The clustering network is used as a reservoir to improve the prediction accuracy of nonlinear time series. Moreover, it has great significance to time series analysis in the era of wireless Internet of Things.
Nonlinear time series prediction algorithm based on AD-SSNET
AD-SSESN architecture
On the basis of ESN architecture, the AD-SSESN model is constructed by using the AD-SSNET as the reservoir to improve the nonlinear approximation capability. The AD-SSESN architecture is shown in Figure 1.

AD-SSESN architecture.
The AD-SSESN architecture has three layers, and the reservoir is AD-SSNET. Its state updated equation and output equation are as follows:
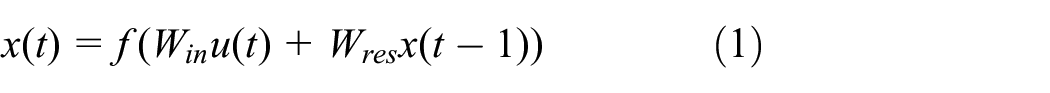

where
AD-SSNET generation method
How to build a reservoir synaptic matrix

Flow diagram of AD-SSNET model generation.
First, the AIC-DSCA optimal clustering algorithm is studied to cluster randomly distributed neurons. Then, the small-world scale-free network is built by the clustering result. Finally, the synaptic information between two neurons is extracted, and the reservoir synaptic matrix
Determination of optimal clustering scheme by AIC-DSCA
The AIC-DSCA is used to obtain the optimal clustering scheme adaptively for randomly distributed neurons. First, the dynamic subtractive clustering algorithm (DSCA) is studied. The maximum intra-cluster distance variance as the evaluation index is proposed to find the optimal clustering scheme under different cluster head numbers. Second, the Akaike information criterion (AIC) of DSCA is introduced to determine the optimal clustering scheme by calculating the optimal cluster heads. The specific steps are as follows:
1. DSCA
The parameter combinations
First, the cluster head numbers

where

where
If
Finally, it is necessary to choose the optimal clustering scheme with an evaluation index if there are more than one candidate scheme under the same cluster head numbers. For each candidate scheme, each neuron is assigned to the nearest cluster head by the nearest distance principle. According to the distance from each neuron of the ith cluster to the cluster head under
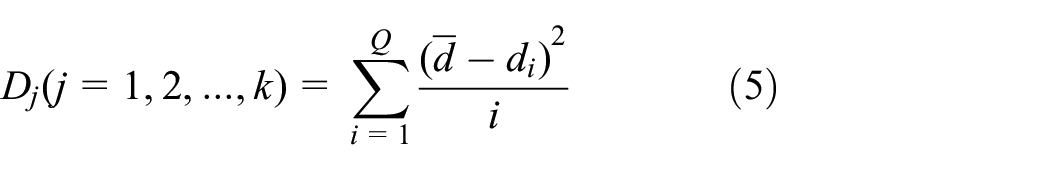
where
The maximum distance variance
2. The AIC criterion of DSCA
It is necessary to select the optimal cluster heads after obtaining the optimal clustering scheme under different cluster heads. The AIC is used as an evaluation index proposed by H. Akaike in the study of time series ordering problems. Its distinctive feature is the “principle of parsimony,” and its definition is as follows:

where
The AIC criterion of DSCA is as follows. Setting the number of neurons to
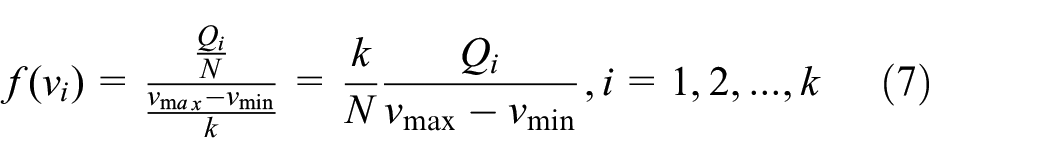
Therefore, according to the log maximum likelihood estimation function, the intra-cluster distance variance likelihood estimation function

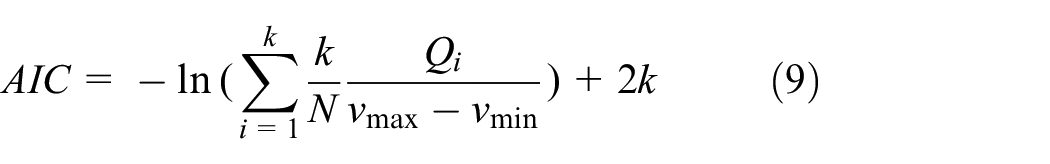
According to equation (9), the cluster head numbers with the smallest


Flow diagram of the AIC-DSCA.
Construction of SSNET
According to the clustering result of neurons, the small-world scale-free network is constructed by intra-cluster connections and inter-cluster connections. Inter-cluster connections will be fully connected for all cluster heads, and the way of intra-cluster connections is as follows.
First, the neurons are defined as two types. One is the cluster head neurons as backbone neurons; the other is the neurons close to their backbone neuron as local neurons. The candidate neighbors of a new local neuron are the set of neurons to which this new local neuron is allowed to be connected. Assuming that there is a circle whose center is the location of backbone neurons in the current cluster and radius is the Euclidean distance from the new local neuron to the location of its backbone neuron. Other existing local neurons in the circle are defined as candidate neighbors of newly added local neurons. Of course, the backbone neuron of the current cluster is always one of the candidate neighbors.
Then, local neurons within the cluster are chosen according to the distance from the backbone neurons and the connections are established with the existing candidate neighbor neurons.
if
if

The number of connections of a neuron is called degree. Here,
The flow diagram of the SSNET construction is shown in Figure 4 and its specific steps are as follows:
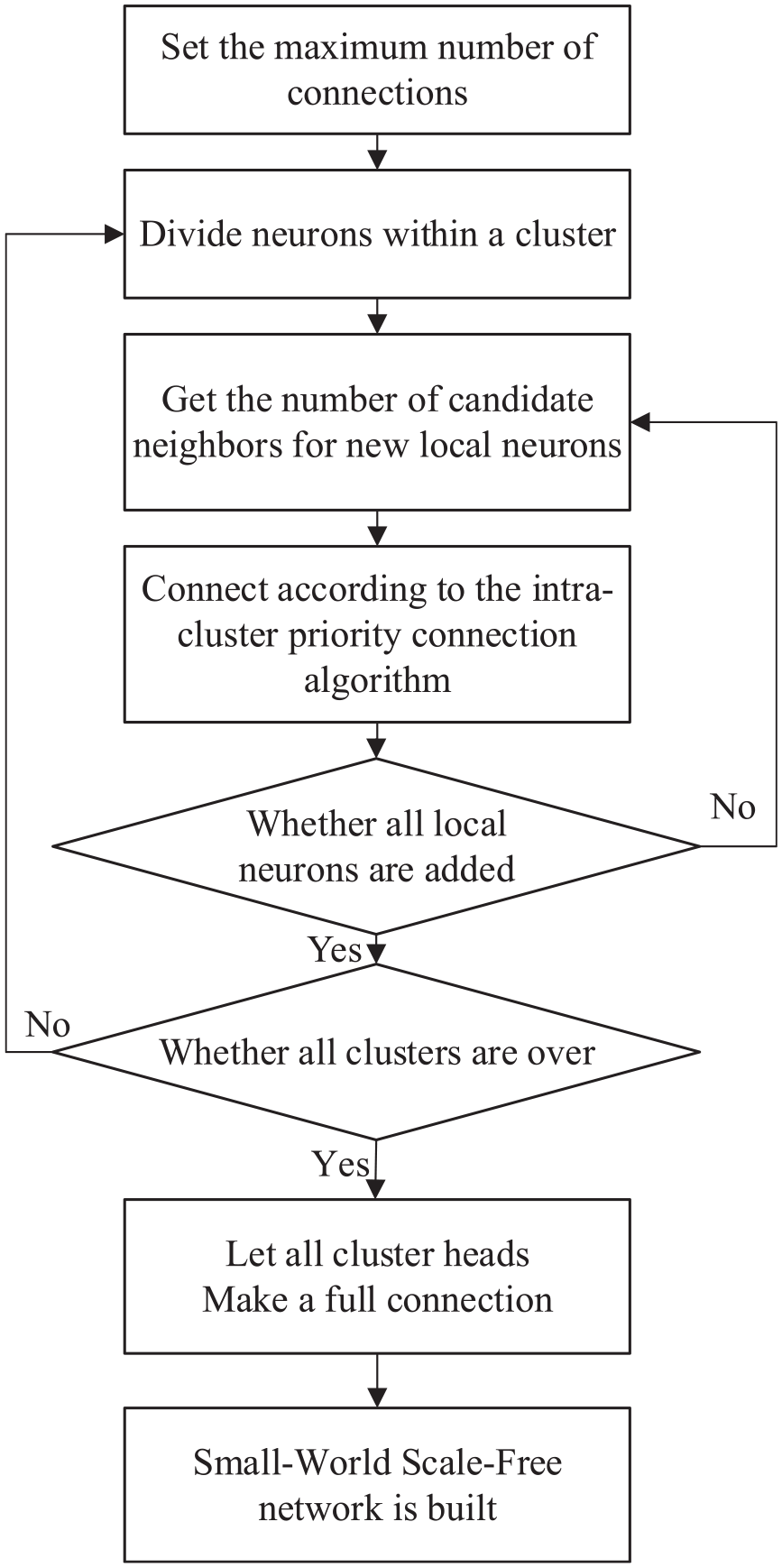
Flow diagram of network construction.

Therefore, the AD-SSESN prediction model construction and training process of the prediction algorithm in this article are as follows:
Analysis of simulation
Analysis of cluster
In total, 1000 neurons were randomly distributed on the plane of
Clustering results under different cluster head numbers.

Table 1 lists the clustering information under the number of cluster heads from 7 to 12. It can be seen that the clustering scheme is diverse under the same cluster head number. Therefore, the optimal clustering scheme under each cluster head number is selected by an indicator (the smallest “intra-cluster maximum distance variance”).
After obtaining the optimal clustering scheme under each cluster head number, the final optimal cluster head number and its optimal clustering scheme could be selected by the AIC of the DSCA. The

The number of cluster heads with the minimum

Optimal clustering result based on AIC-DSCA.
Analysis of network characteristics
After the optimal clustering scheme is obtained, the AD network is constructed by the method explained in section “Construction of SSNET.” The small-world characteristics and the scale-free characteristics of the AD network are analyzed.
Analysis of small-world characteristics
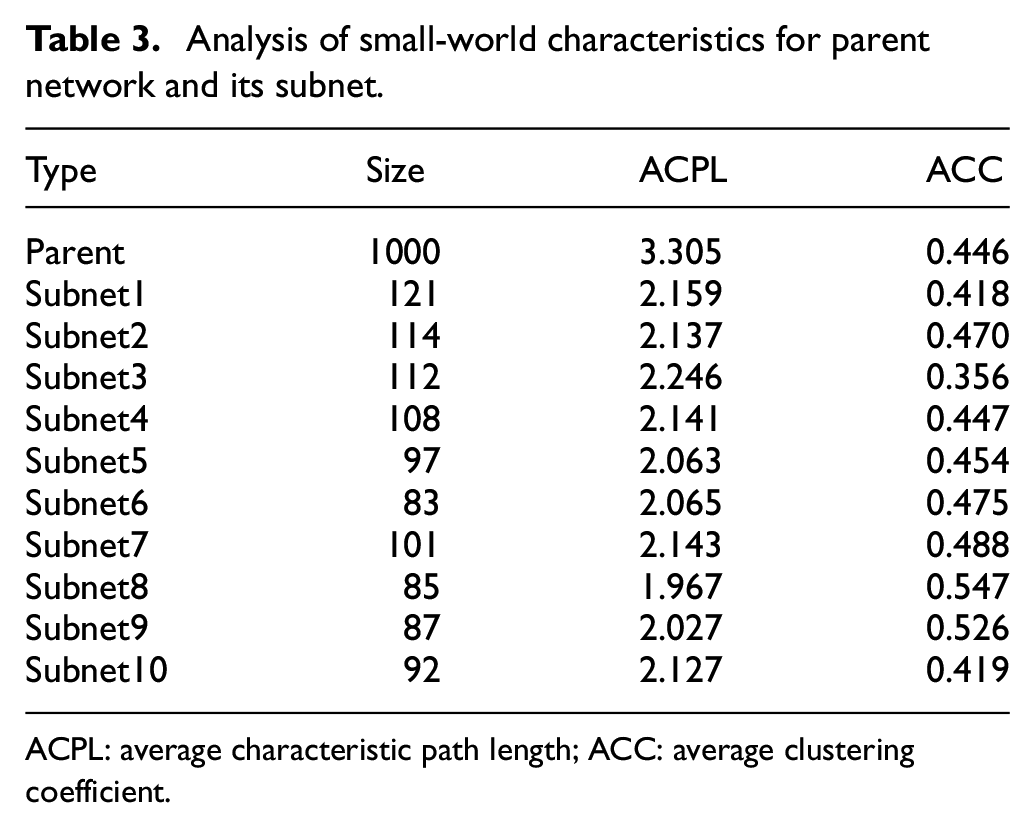
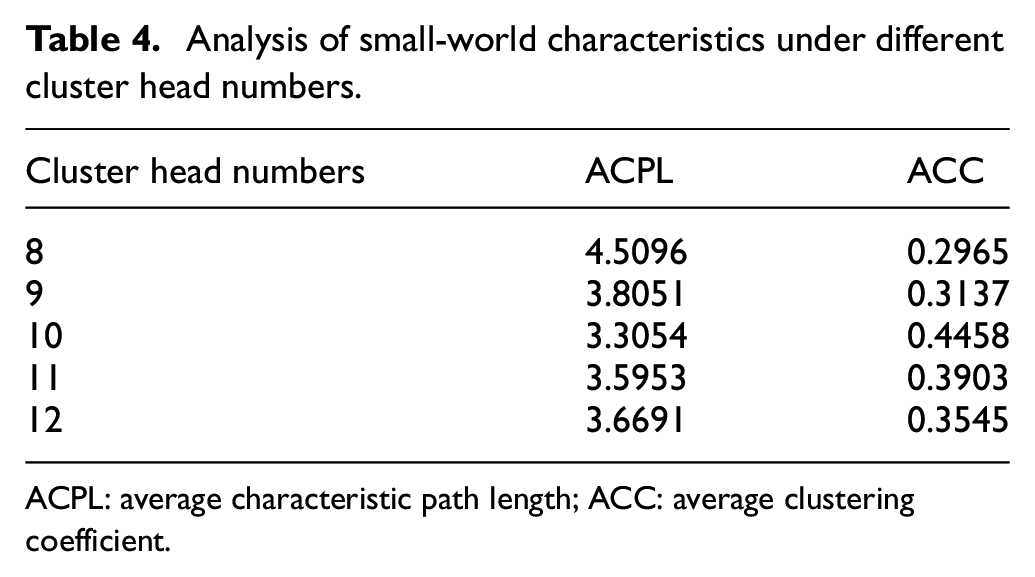
The small-world characteristics in the complex network can be characterized by its ACPL and ACC. When the ACPL is small and the ACC is large, the small-world characteristics of network are better. 41 The ACPL and ACC of the parent network and each subnet based on the AD network are shown in Table 3. The ACPL and ACC of clustering schemes under different cluster head numbers are shown in Table 4. The ACPL and ACC of random-network, small-world network, and high-clustering scale-free network under the same scale are shown in Table 5.
Analysis of small-world characteristics for parent network and its subnet.
ACPL: average characteristic path length; ACC: average clustering coefficient.
Analysis of small-world characteristics under different cluster head numbers.
ACPL: average characteristic path length; ACC: average clustering coefficient.
Analysis of small-world characteristics under different networks.

ACPL: average characteristic path length; ACC: average clustering coefficient.
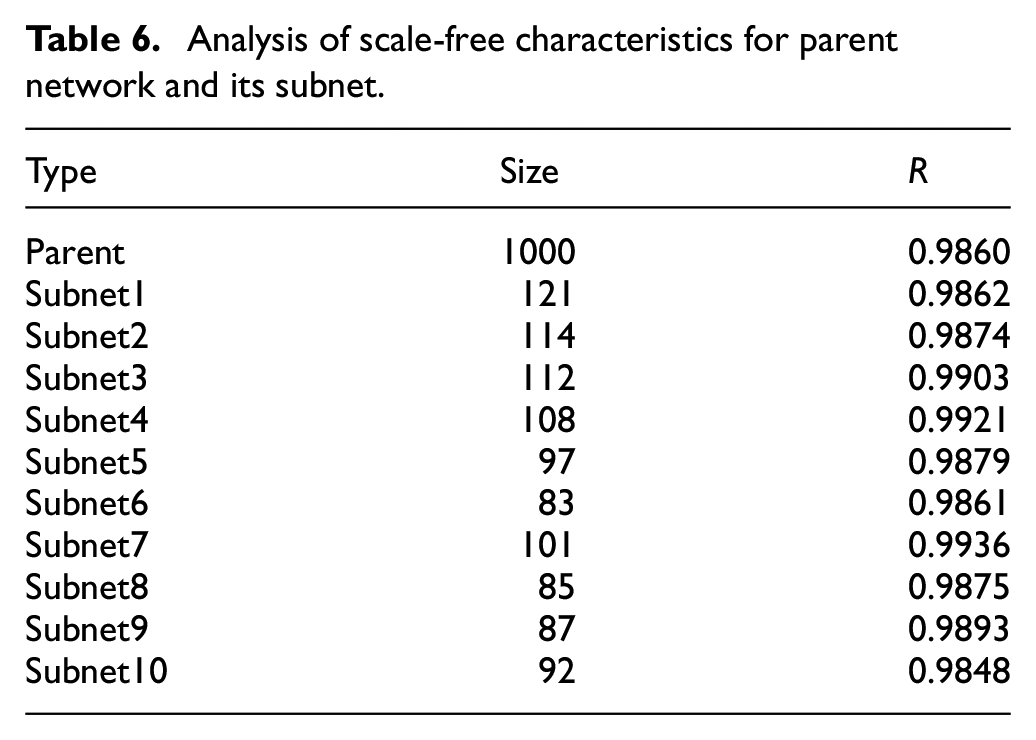
It can be seen from Table 3 that the ACPL of the parent network and its subnets are small, and the ACC is large, so this indicates all have small-world characteristics. The number of members and the small-world characteristics is similar in each subnet, so this indicates that the structures of the AD network are hierarchical and uniform-clustering in terms of small-world characteristics. It can be seen from Table 4 that the ACPL reaches a minimum when the cluster head numbers are 10, and the ACC reaches a maximum when the number of the cluster heads is 10. Therefore, when the number of the cluster heads is 10, the small-world characteristic of the AD network is the best. It can be seen from Table 5 that the ACPL of the AD network is smaller than the small-world network and the highly clustered scale-free network, and the ACC is larger than the random network, the small-world network, and the highly clustered scale-free network. Consequently, the small-world characteristic of the AD network is more significant.
Analysis of scale-free characteristics
The scale-free characteristics in complex networks can be characterized by whether the degree of neurons satisfies the power-law distribution.
42
In the AD network, the degree of each neuron is calculated, and the number of neurons with different degrees is got accounted for; its distribution is shown in Figure 6. It is processed logarithmically and fitted linearly, and then the correlation coefficient

Plot of the number of neurons versus degree.
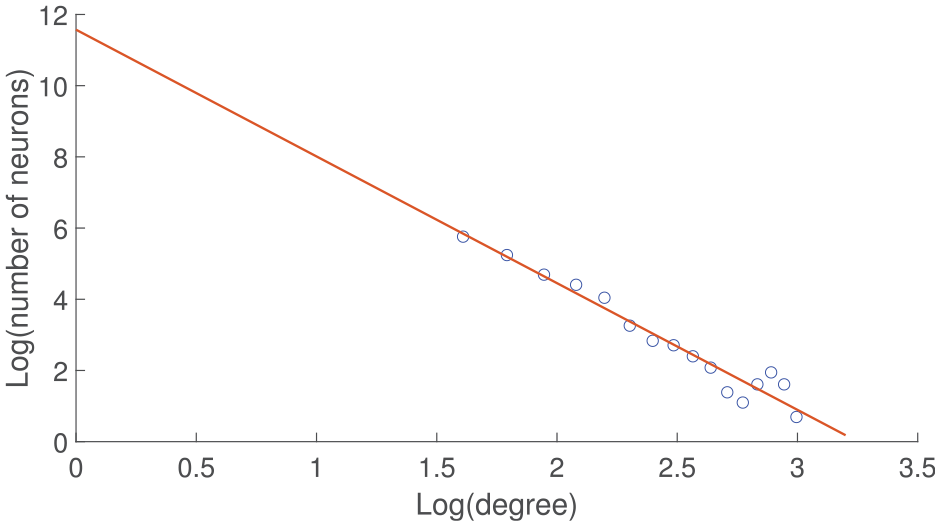
Log-log plot of the number of neurons versus degree.
In addition, the correlation coefficient
Analysis of scale-free characteristics for parent network and its subnet.
Analysis of prediction
Dataset preparation and testing criterion
The MG time series and Lorenz time series were used as the dataset of nonlinear time series for prediction, which is generated as follows:
1. The chaotic dynamic formula of the MG system is as follows:

where
2. The chaotic dynamic formula of the Lorenz system is as follows:

The Lorenz system is solved by the fourth-order Runge–Kutta algorithm, and the time series of 2500 points are calculated, then the first 2300 points of dataset as the training set and the last 200 points as the test set are obtained.
The normalized root mean square error (NRMSE) is the performance indicator for all simulation predictions:
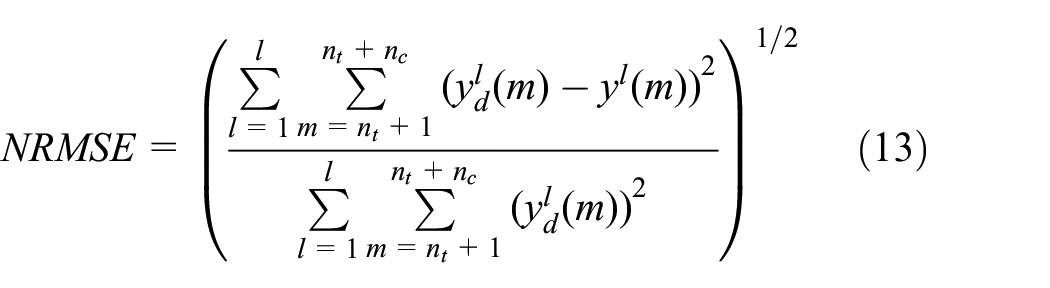
where
Analysis of echo state property
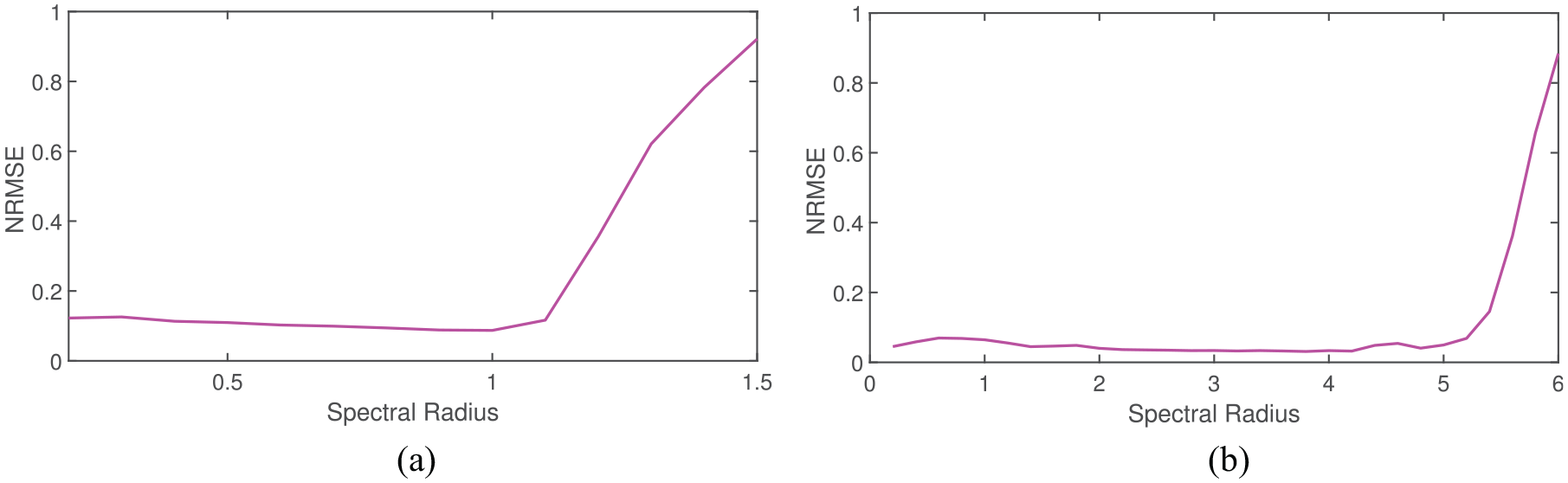
Generally, the prediction model can be trained and predicted normally and stably only when the reservoir has “the echo state.” After normalizing the synaptic matrix, the spectral radius of synaptic matrix

NRMSE error versus spectral radius on MG dataset: (a) testing ESN and (b) testing AD-SSESN.
NRMSE error versus spectral radius on Lorenz dataset: (a) testing ESN and (b) testing AD-SSESN.
It can be seen from Figures 8 and 9 that the spectral radius of the AD-SSESN is significantly larger than the ESN when NRMSE error increases significantly in the MG dataset and Lorenz data. Therefore, the “echo state” of the AD-SSESN is significantly enhanced, the stability of the prediction time series of the AD-SSESN is maintained over a wider range of spectral radius, and the predictive power is enhanced.
Approximating nonlinear capability
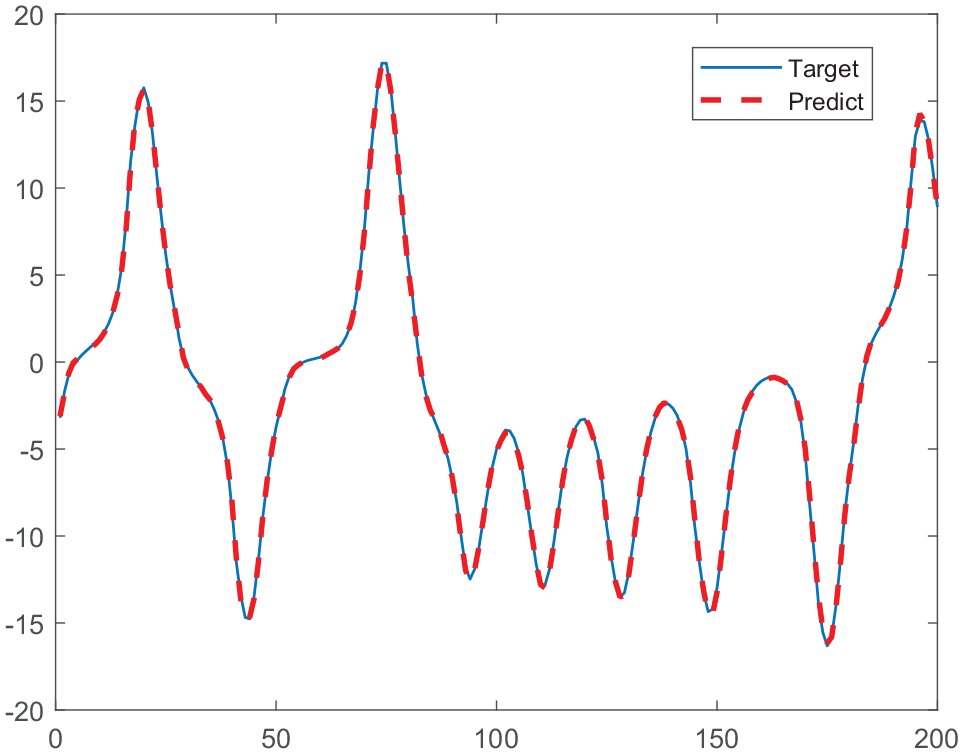
The MG dataset and Lorenz dataset are preprocessed through normalization and phase space reconstruction, and the prediction results are de-normalized. The prediction results of AD-SSESN for MG dataset and Lorenz dataset are shown in Figures 10 and 11.

Prediction results of AD-SSESN for MG (
Prediction results of AD-SSESN for Lorenz dataset.
It can be seen from Figures 10 and 11 that the predicted curves of the AD-SSESN for MG datasets and Lorenz datasets are consistent with the actual curve trend, which indicates that the AD-SSESN has a high fitting ability.
In order to further analyze the error, the small-world scale-free prediction models (X-SSESN) are constructed according to different clustering schemes in Table 4, and 15 MG datasets and Lorenz datasets are predicted respectively. The results are shown in Figure 12 and Table 7.
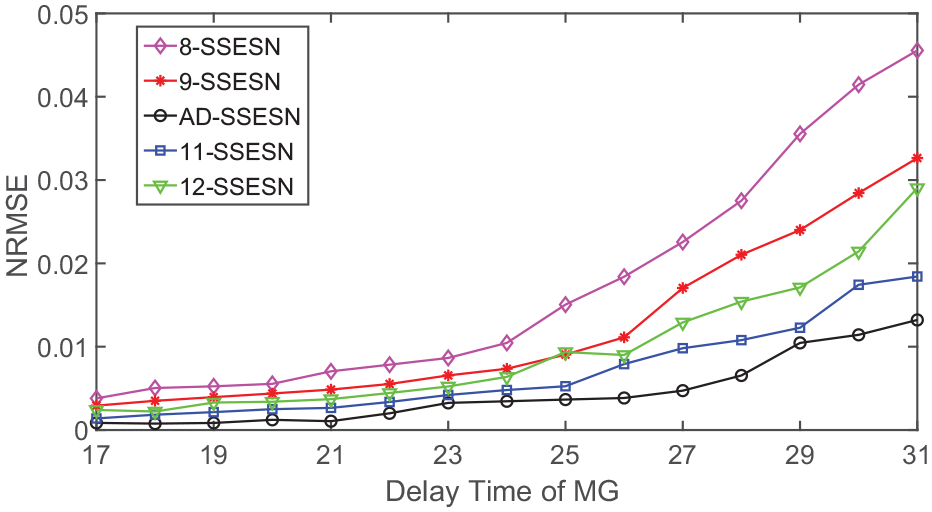
Prediction results of different cluster head numbers in the MG dataset.
Prediction results of different cluster head numbers in the Lorenz dataset.

NRMSE: normalized root mean square error.
It can be seen from Figure 12 and Table 7 that the NRMSE errors of AD-SSESN for 15 MG datasets and Lorenz datasets are the minimum. Furthermore, in the prediction of MG datasets, the prediction accuracy can still be maintained with the increase in MG delay time.
Finally, four prediction models of AD-SSESN, ESN, SWESN, and SHESN with the same reservoir size, sparse connectivity, and appropriate spectral radius are constructed respectively according to the different reservoirs in Table 5. And 15 MG datasets and Lorenz datasets are predicted by the above models, and the results are shown in Figure 13 and Table 8.

Prediction results of different networks in the MG dataset.
Prediction results of different networks in the Lorenz dataset.

NRMSE: normalized root mean square error; ESN: echo state network; SWESN: small-world echo state network; SHESN: scale-free highly clustered echo state network.
It can be seen from Figure 13 and Table 8 that AD-SSESN has better prediction results for MG datasets with different time delays and Lorenz datasets compared with the other models. In the MG datasets, the AD-SSESN can maintain good prediction performance when
Conclusion
This article proposes a nonlinear time series prediction algorithm based on the AD-SSNET, which improves the prediction accuracy of the prediction model to nonlinear time series data and brings more possibilities for the analysis of a large number of time series in the wireless Internet of Things. The number of the optimal cluster heads is obtained adaptively and its clustering schemes are optimized by the AIC-DSCA, then the AD-SSNET with small-world scale-free characteristics is constructed by the intra-cluster priority connection algorithm. This network is used as a reservoir to construct the AD-SSESN prediction model. Finally, the AD-SSESN prediction model is used to predict MG datasets and Lorenz datasets, respectively. Experimental results show that the NRMSE error of AD-SSESN is the minimum compared with other small-world scale-free network prediction models with different clustering schemes; the NRMSE error of AD-SSESN is also the minimum compared with the other three prediction models with different reservoir networks. The above results show that the highly complex nonlinear dynamic system is more accurately approximated. The prediction accuracy is steadily improved due to the optimized clustering performance of the reservoir, the ACC of the network is improved, and the “echo state” is enhanced significantly in the AD-SSESN.
Footnotes
Handling Editor: Peio Lopez Iturri
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Public Welfare Technology Research Projects of Zhejiang Province of China (Grant Nos LGG20F010009 and GF21F010018), the Zhejiang Shuren University Basic Scientific Research Special Funds (No. 2020XZ009), and the Project Intelligentization and Digitization for Airline Revolution (No. 2018R02008).