
Abstract
Spectral dimensionality reduction is a crucial step for hyperspectral image classification in practical applications. Dimensionality reduction has a strong influence on image classification performance with the problems of strong coupling features and high band correlation. To solve these issues, we propose the Mahalanobis distance–based kernel supervised machine learning framework for spectral dimensionality reduction. With Mahalanobis distance matrix–based dimensional reduction, the coupling relationship between features and the elimination of the scale effect are removed in low-dimensional feature space, which benefits the image classification. The experimental results show that compared with other methods, the proposed algorithm demonstrates the best accuracy and efficiency. The Mahalanobis distance–based multiples kernel learning achieves higher classification accuracy than the Euclidean distance kernel function. Accordingly, the proposed Mahalanobis distance–based kernel supervised machine learning method performs well with respect to the spectral dimensionality reduction in hyperspectral imaging remote sensing.
Introduction
Hyperspectral sensing remote systems are widely used in energy exploration, social safety, military monitoring, and other areas. Hyperspectral remote sensing provides accurate representations of the different materials with high spectral resolution on airborne and satellite platforms. Machine learning is a promising method for hyperspectral data analysis. Since the relationship between spectral curves is nonlinear and complex, spectral classification is a classic complex and nonlinear problem. Among these machine learning methods, a feasible and effective nonlinear method utilizes a kernel technique. As the spectral resolution increases, the coupling between the spectral bands becomes stronger, and the correlation becomes greater. The different spectral bands have different weights on the particular classification problem. Some bands affect the classification results. In feature space, each sample corresponds to a point in space, and the distance between the points reflects the degree of similarity between the sample points. Many classification algorithms do not use sample features directly but use the distance between features, that is, the degree of similarity of the samples as the object of analysis. Previous machine learning methods have often used the Euclidean distance to measure this degree of similarity. However, the character of Euclid space assumes that each feature of the sample is equally important and independent of each other, which often does not correspond to the actual spectral characteristics, resulting in a Euclidean distance that does not produce satisfactory results. However, a suitable similarity measure should be related to a specific problem and not be absolutely constant. Generally, for the different classification tasks, the methods used to measure similarity should be different. Metric learning extracts the similarity between different samples with a similarity function. Therefore, the procedural parameters are computed according to the training sample data. We can improve the classification performance by optimizing the matrix learning function in dimensionality reduction.
Depending on the sample used in the study, the metric learning algorithm can be divided into two categories: unsupervised and supervised. The unsupervised learning algorithm does not require class label information during the training stage. Alternatively, an implicit manifold structure is obtained that can maintain the geometric relationship between the sample points in the space. Typical unsupervised metric learning includes multidimensional scaling, nonnegative matrix factorization (NMF), independent component analysis (ICA), neighborhood preserving embedding, locality preserving projection (LPP), 1 and other computing methods.2,3 In previous works, many researchers have developed dimensionality reduction methods for different application fields, such as generalized discriminant analysis, 4 uncorrelated discriminant vector analysis (a criterion for optimizing kernel parameters), 5 and kernel machine–based one-parameter regularized Fisher discriminant6,7 methods. In addition, other recognition algorithms have been applied in other application areas, such as vehicle estimation.8,9 As another feature extraction method, this article proposes an improved kernel function supervised kernel–based LPP method, a local structure supervised feature extraction, 10 kernel subspace linear discriminant analysis (LDA) method, 11 a kernel minimum squared error (MSE) algorithm, 12 and quasiconformal mapping–based kernel machine method. 13 Kernel optimization learning is based on feature extraction to improve kernel-based learning.14–16 Regarding the kernel model selection problem, in previous works, many kernel learning algorithms—for example, sparse multiple kernel learning (MKL), 17 large-scale MKL, 18 and Lp-norm MKL 19 —have been proposed to improve the performance accuracy of practical learning systems. Moreover, hyperspectral data classification is the classical problem of high-dimensional data classification, and it is difficult to classify the original data space with the classifier, that is, the so-called “curse of dimensionality,” so dimensionality reduction is the crucial preprocessing step of the classification. The performance of dimensionality reduction directly affects the final classification performance, so dimensionality reduction is a necessary and important step for high-dimensional data classification. Therefore, this topic focuses on dimensionality reduction but for the purposes of classification. Learning-based dimensionality reduction is an effective algorithm for classification. On the dimensionality reduction and classification of hyperspectral, some advanced machine learning methods are presented for hyperspectral data to solve the classification problem, for example, the extreme learning machines. 20 Moreover, the optimization learning methods are applied to hyperspectral image classification, for example, particle swarm optimization–based learning method. 21 Compared with unsupervised metric learning, supervised metric learning makes full use of the label information of the sample so that a better performance metric function can be obtained. On the measure of the “closeness” of samples via the information-theoretic metric learning technique, it is effective to solve such problems directly. In previous studies,22–24 the authors presented information-theoretic metric learning algorithms and an improved version, and excellent performance was achieved. At the same time, different annotation information can be set to meet different evaluation criteria. Supervised metric learning is roughly divided into a metric learning algorithm based on pairwise constraints and a metric learning algorithm based on unpaired constraints in the literature. The pairwise constraint information refers to a priori information, and the class labels are easy to obtain and widely used in machine learning. According to the different criteria followed by the optimization process, the metric learning algorithm based on pairwise constraints can be divided into four categories: sample-pair distance sum, information theory, probability theory, and cosine similarity. Unpaired constraints generally refer to priori information other than pairwise constraints, often using ternary constraint information that represents the relative relationship between samples. In addition, machine learning methods are divided into global or local metric learning methods. According to different sample input methods, these methods can also be divided into offline learning and online learning.
In this article, we present the proposed Mahalanobis distance–based MKL-based algorithm, with the advantage of the nonlinear relationship of the spectral bands under hyperspectral imaging conditions, such as the lighting, atmospheric environment, geographical environment, temperature, and humidity. In low-dimensional nonlinear feature space, we use the Mahalanobis distance–based metric to learn the feature similarity representation. The previous kernel learning represents feature similarity with the Euclidean distance, but the Euclidean distance–based representation performs well on the global differences of two vectors because of the mean square deviation of the two feature vectors. However, the method does not distinguish between some single spectral bands because the difference in the single spectral band can be ignored with mean square deviation computing. In contrast, in this article, the Mahalanobis distance–based similarity method is more effective for individual element differences because the difference in the single spectral band is weighted with the Mahalanobis weight matrix, that is, if some spectral elements in the spectral vectors are meaningful for hyperspectral image classification, then the Mahalanobis weight is large. It is important for hyperspectral image classification. Therefore, the Mahalanobis distance–based similarity measurement is more effective for hyperspectral data classification than the Euclidean distance. The Mahalanobis distance–based feature metric describes the nonlinear relations of spectral bands under hyperspectral imaging conditions such as lighting, atmospheric environment, geographical environment, temperature, and humidity. Therefore, compared with the other methods, the proposed dimensionality reduction method performs better with respect to extracting the nonlinear features of hyperspectral images for classification.
Proposed Mahalanobis distance–based kernel supervised machine learning
Framework
A single Mahalanobis distance–based kernel function cannot sufficiently process multidimensional and heterogeneous data. Therefore, we propose multikernel learning with the Mahalanobis distance kernel function so that a better performing Mahalanobis distance multikernel function can be obtained. In particular, the expression for the Mahalanobis Gaussian kernel function is
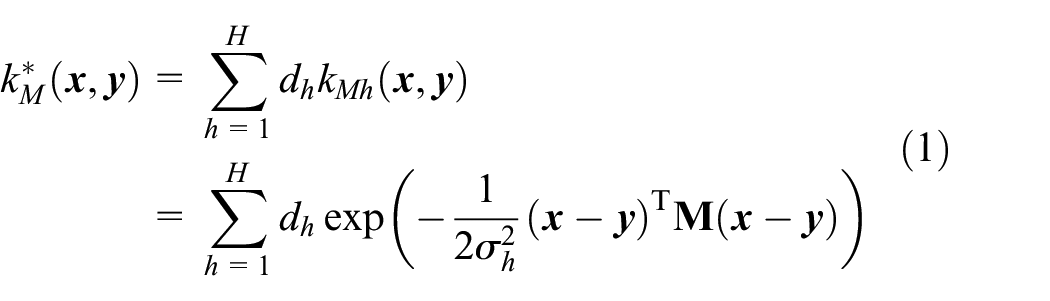
where
Considering metric learning, especially Mahalanobis distance metric learning for mining the potential structure inside the data, reducing the coupling relationship between features, and adjusting the weight of the features according to the correlation, researchers began to study how to integrate metric learning with existing classification algorithms to improve classification performance. In the previous work Abe, 25 the Mahalanobis distance instead of the Euclidean distance was used in the radial basis function (RBF) kernel function to construct the Mahalanobis distance kernel function; this function was used to support vector machine (SVM) classification and obtained a better classification effect. The kernel function was used to construct the Mahalanobis distance kernel function to SVM classification and to obtain a better classification effect. In Wang et al., 26 the researchers theoretically analyzed how the Mahalanobis distance kernel function improves the classification performance of SVMs. When using a SVM for classification, the kernel function based on Euclidean distance uses the information contained in the support vector. For the whole sample space, this approach is equivalent to using the local information of the sample, and it is easy to produce a situation where the actual distribution of the sample does not match the hyperplane, resulting in a certain risk of misjudgment. When using the Mahalanobis distance kernel function, the Mahalanobis matrix can introduce the global information of the sample to obtain a more reasonable classification hyperplane.
The Mahalanobis distance–based kernel function is constructed by extending the existing Euclidean distance–based kernel function. For a specific metric learning algorithm, if the mapping of matrix
According to the different ways of using sample features, the existing common kernel functions can be roughly divided into two types: kernel functions based on feature similarity and kernel functions based on the feature inner product. Since the expressions of these two types of kernel functions are different, the method to construct the Mahalanobis distance kernel function is also different.
Learning criteria
We proposed a large margin nearest neighbor criterion based on similar/dissimilar–based learning. The metric learning algorithm utilizes ternary constraint information. Better consistency is achieved with the perspective of the feature space. The sample located at the category boundary has a great influence on the classification. If a metric can enlarge the distance between heterogeneous samples located at the category boundary, then the feature space after the metric mapping is beneficial for the subsequent classification operation.
The closest sample in the same samples. Then, the target loss function is

where the training set

where
Discussion on metric learning
Information theoretic–based metric learning is widely used in designing optimization goals. As a general method, the information entropy, Kullbacle–Leibler (KL) divergence, is used to measure the difference between two probability distributions. For two probability distributions P and Q in continuous space X, p(

However, for a metric matrix
The distance from the same class labels is not greater than the threshold u and is not less than a certain threshold l as a constraint. After determining the objective function and constraints, the metric learning problem based on the relative entropy can be expressed as

where

where
Algorithm procedure
The Mahalanobis distance matrix and the combination parameters are solved through the actual solution process. It is difficult to convert the equation into an optimization problem. Therefore, we propose a two-stage optimization method to solve the matrix

Proposed algorithm procedure.
Experiments and discussion
Experimental setting
We implement some experiments to test the feasibility of the proposed algorithm and compare the performance with that of the other algorithms. The experiments are implemented on two hyperspectral sensing data sets: the Indian Pine data set and the Pavia University data set. The accuracy of the spectrum classification is an important index for evaluating the performance of the spectrum classification. The Indian Pine data set is based on an airborne platform at various spectral and spatial resolutions. The data include 224 0.4–2.5 μm bands. Nine kinds of 145 × 145 pixel images are realized in the experiment. The data collection at the University of Pavia is based on a reflective optical system imaging spectrometer (ROSIS). The data include 115 bands. In the experiment, the performance of nine kinds of 610 × 340 images is verified. Except for the feature dimensions of the participating categories, the two experiments were identical. Regarding the use of classification features, considering the computational efficiency and stability of the Mahalanobis matrix, the dimensions of the original spectral features are reduced by principal component analysis (PCA). After dimension reduction, the features are normalized to eliminate the deviation caused by the sampling method. For the first experiment, the top 30 principal components are selected to participate in the classification, that is, the feature dimension is 30. For experiment 2, the first 40 principal components are selected to participate in the classification, that is, the feature dimension is 40. Regarding the classifier settings, the preset parameter values are selected by cross-validation by a standard multiclass SVM. In the kernel function setting, the Gaussian kernel function and the Mahalanobis Gaussian kernel function are used as the basis kernel functions. The scale parameter σ is set between [0.01, 2], and the number of basis kernels is 10. The overall classification accuracy (OA) and Kappa coefficient (KC) are used to evaluate the classification accuracy and to evaluate the computation efficiency with the classifier training time and test time. In the comparison method, the average multiple kernel matrix and different MKL methods are used. The Gaussian kernel and polynomial kernel are used with the Mahalanobis and Euclidean distances. In the following experiments, we implement some experiments on the Indian Pine data set and Pavia University data set to test the feasibility of the proposed algorithm and compare its performance results with that of the other algorithms.
Performance regarding the difference dimensionality
In these experiments, we implement four algorithms as follows. Euclidean-MKL1: 27 the Euclidean distance kernel function. Each kernel function is combined according to the same weight, that is, the combination coefficient of each kernel function is the reciprocal of the number of kernel functions. See the description of Gonen and Alpaydin 27 for details. Mahalanobis-MKL1: the Mahalanobis distance kernel function is used for kernel learning. Euclidean-MKL2: 30 the Euclidean distance kernel function is used, which describes the combination coefficient and is described in Gu et al. 30 Mahalanobis-MKL2: the Mahalanobis distance kernel function is used, and the kernel learning is the same as Euclidean-MKL2. During the experiment, a certain number of samples are randomly selected from the sample data as training samples, and the remaining samples were used as test samples. The number of training samples is 10, 20, 30, 40, and 50. For each parameter setting, 10 experiments are repeated and averaged, while the variance values are calculated.
Performance of the Indian Pine data set
Figure 2 shows the classification OA results for the four methods with respect to the Indian Pine data set. Combined with the KC results shown in Figure 3, it can be seen that the classification accuracy and KC of the corresponding algorithm are improved after using the Mahalanobis distance kernel function. Figures 2 and 3 describe the recognition accuracy under the same feature dimension, for the dimension of feature, 10, 20, 30, 40, and 50. The highest recognition accuracy is 77.12%, under the 50 dimensional feature. And the Mahalanobis-MKL2 method has the highest recognition accuracy Indian Pine data set. And with the similar results, the performance with KC of different methods on the Indian Pine data set is described in Figure 3, and the Mahalanobis-MKL2 method has the highest recognition accuracy compared with other results. In terms of the extent of OA improvement, Mahalanobis-MKL1 has a 3% increase in the Euclidean-MKL1 algorithm, and the amplitude of the increase does not change as the number of training samples increases. The experimental results show that the Mahalanobis distance kernel combined with metric learning can make full use of the sample information when the number of training samples is small, thus improving the separability of the sample. Similarly, Mahalanobis-MKL2 also improves the Euclidean-MKL2 algorithm, but the increase is relatively low, and its amplitude does not increase as the number of training samples increases.

OA (%) of the different methods on the Indian Pine data set.

Kappa coefficient of different methods on the Indian Pine data set.
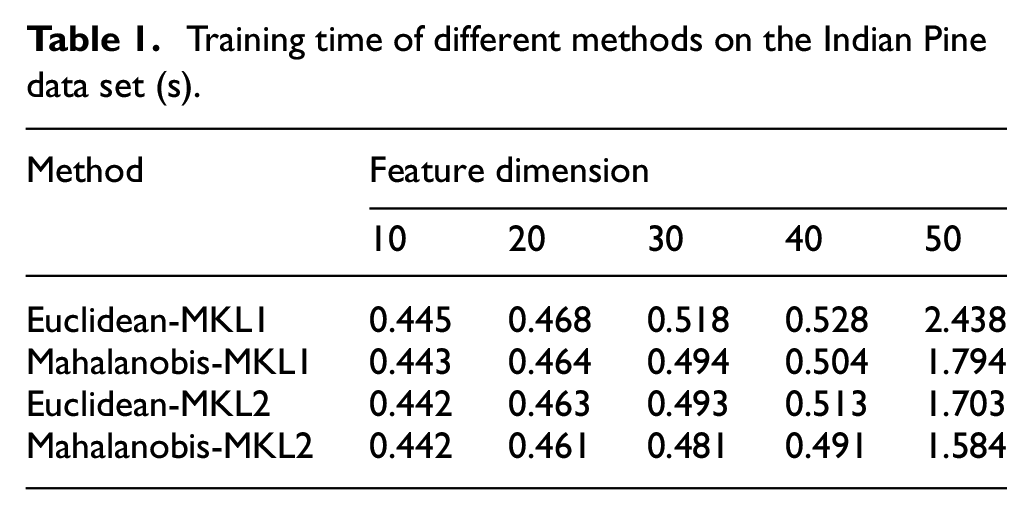
As shown in Table 1, the classifier using the Mahalanobis distance kernel function has the lowest computation time for classifier training and testing. Under the mapping of the Mahalanobis distance matrix, the distance between samples of different categories is larger, but the distance between similar samples is smaller. As shown in Table 2, the test times are computed as a function of the number of support vectors. For the training time of the classifier, although the difference is not very obvious, the trend is the same as the test time of the classifier. As the number of samples increases, the difference in time is more obvious. Table 3 shows the actual mapping effect of the four methods when the number of training samples is 50.
Training time of different methods on the Indian Pine data set (s).
Testing time of different methods on the Indian Pine data set (s).

Number of support vectors of different methods on the Indian Pine data set.

Performance using university of Pavia data set
Regarding the classification accuracy in the different dimensions, Figure 4 shows the classification OA for the four methods with the University of Pavia data set, and Figure 5 shows the corresponding KCs. As shown in Figure 4, the recognition accuracy under the same feature dimension is denoted, for the dimension of feature, 10, 20, 30, 40, and 50. The highest recognition accuracy is 79.86%, under the 50 dimensional feature on the Pavia University data set. And the Mahalanobis-MKL2 method has the highest recognition accuracy, which has the same conclusion to the Indian Pine data set. And with the similar results, the performance with KC of different methods on the Pavia University data set is described in Figure 5. Compared with the Indian Pine data set, the Mahalanobis distance kernel function is lower with respect to the OA, only by approximately 1%–2%, but the overall trend is the same as that of the Indian Pine data set.
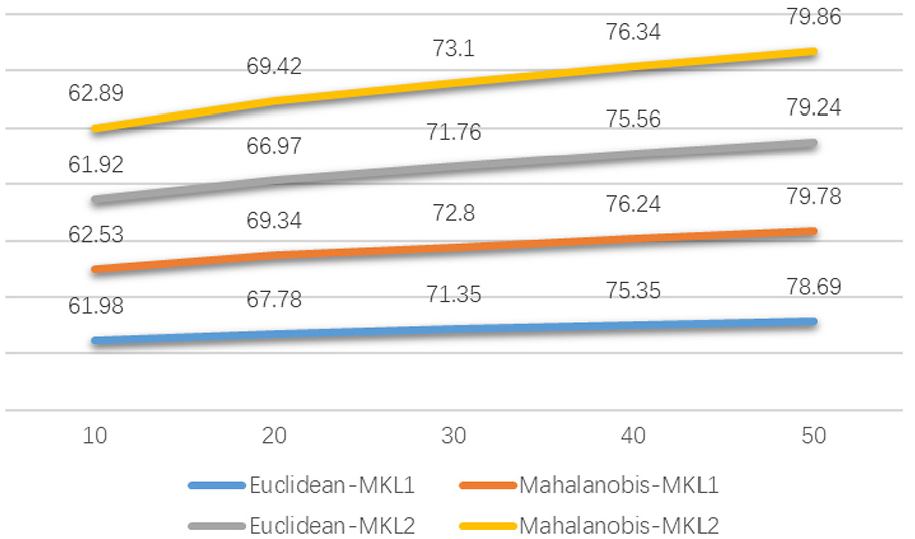
OA (%) of different methods for the Pavia University data set.

Kappa coefficient of different methods for the Pavia University data set.
By analyzing the classifier training and test times given in Tables 4 and 5 and accordingly the number of support vectors given in Table 6, we can see the role of the Mahalanobis distance kernel in reducing the classifier runtime. In the case of the fixed training samples, because the number of samples in each category of the University of Pavia data set is larger, the corresponding number of test samples is larger, and the Mahalanobis distance kernel is more effective in shortening the test time of the classifier.
Training time of different methods for the Pavia University data set (s).

Testing time of different methods for the Pavia University data set (s).

Number of support vectors of different methods for the Pavia University data set.

Comparing the computational time, Tables 1, 2, 4, and 5 show the computational times for the two data sets with the different vector dimensions. The computational cost was recorded via a PC with a 2.6 GHz i5-3320 processor and 4 GB RAM. All the results are averages of 10 repeated experiments. As shown in the tables, different computational costs are achieved with the different features. The proposed algorithms omit the parameter optimization process under the same dimension of the feature vector, so that high computation efficiency is achieved. Both Euclidean-MKL1 and Mahalanobis-MKL1 adopt NMF to optimize the kernel weights, and higher dimensional features require more time because they need more memory to save the kernel matrix and have more dimensions to compute. Therefore, Mahalanobis-MKL1 has a higher computational efficiency than Euclidean-MKL1 with the same feature dimensions.
Performance comparisons
For the comparisons, we have some experiments to compare the performance of the proposed algorithm, and the following 12 methods are implemented as the comparison. The experimental results are shown in Table 7. They are as follows:
RBF: RBF Euclidean kernel as the kernel function in the SVM. 26
POLY: polynomial Euclidean kernel as the kernel function in the SVM. 26
Mahal-RBF: Mahalanobis distance–based RBF kernel as the kernel function in the SVM. 31
Mahal-Poly: Mahalanobis distance–based polynomial kernel as the kernel function in the SVM. 31
SK-CV (RBF): an SVM with a single kernel and adopting the RBF kernel as the kernel function in the SVM. 32
SK-POLY: standard SVM with a single kernel and adopting a polynomial kernel as the kernel function in the SVM. 32
NMF-MKL: the NMF-MKL proposed by Gu et al., 33 which combines multiple kernels with NMF.
KNMF-MKL: the kernel-based nonnegative matrix factorization (KNMF)-MKL method, also proposed by Gu et al., 33 which combines multiple kernels with the KNMF method.
Euclidean-MKL1: 27 the Euclidean distance kernel function. Each kernel function is combined according to the same weight, that is, the combination coefficient of each kernel function is the reciprocal of the number of kernel functions. See the description in Gonen and Alpaydin 27 for details.
Euclidean-MKL2: 30 the Euclidean distance kernel function is used, which describes the combination coefficient, as described in Gu et al. 30
Mahalanobis-MKL2: proposed the Mahalanobis distance–based multiple kernel function, and the learning criterion is the same as that of Euclidean-MKL1.
Mahalanobis-MKL2: the Mahalanobis distance kernel function is used, and the learning criterion is the same as that of Euclidean-MKL2.
Performance comparisons of two databases.

OA: overall accuracy; KC: Kappa coefficient; NMF: nonnegative matrix factorization; KNMF: kernel-based nonnegative matrix factorization.
Bold value signifies the proposed algorithm.
In Table 7, the experiments show that the proposed algorithms perform better than the other algorithms. The data sets are constructed with the images under different conditions, including lighting, atmospheric environment, geographical environment, temperature, and humidity. Therefore, from the experimental results, the proposed Mahalanobis distance–based MKL-based algorithm has the advantage of the nonlinear relationships of the spectral bands under hyperspectral imaging conditions. In low-dimensional nonlinear feature space, we use the Mahalanobis distance–based metric to learn the feature similarity representation. The Mahalanobis distance–based similarity method is more effective for individual element differences because the difference in the single spectral band is weighted with the Mahalanobis weight matrix, that is, if some spectral elements in the spectral vectors are meaningful for hyperspectral image classification, then the Mahalanobis weight is large. The experimental results show that the proposed algorithm performs better than the other kernel matrix learning methods. Compared with the Euclidean distance kernel function, the Mahalanobis distance kernel learning achieves higher classification accuracy. The number of support vectors is reduced by reducing the boundary of similar samples, and accordingly, the algorithm performs more efficiently.
Discussion
The experimental results show that the addition of metric learning can effectively improve the sample features and the classification performance of the classifier. Under the Indian Pine data set, while the classification accuracy increased by 3%, the classifier training time was reduced by 23%, and the test time was reduced by 31%. Under the University of Pavia data set, while the classification accuracy increased by 1.5%, the classifier training time was reduced by 25%, and the test time was reduced by 33%. Compared with the multikernel learning method using the Euclidean distance kernel function, the Mahalanobis multikernel learning algorithm has higher classification accuracy, reduces the number of support vectors, and shortens the training time and test time of the classifier by the cohesion of similar samples.
Conclusion
Hyperspectral features have a different importance for each band, strong coupling between features, and challenge the classification method with the Euclidean distance as a measure. This article optimizes sample features from the perspective of improving the sample metrics. First, we introduce the basic concepts of metric learning, as well as some typical Mahalanobis distance metrics. By mining the distribution information and discriminative information contained in the sample data, the Mahalanobis distance matrix can remove the dimensional influence and coupling relationship in the spectral features. In addition, this matrix can also map the features to a feature space with a smaller distance within the class, and a larger space between classes is distanced, making subsequent classification operations easier. On this basis, from the perspective of kernel function design, the Mahalanobis distance kernel function is constructed, and a Mahalanobis distance multikernel learning method is proposed.
Footnotes
Handling Editor: Feng-Jang Hwang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Science Foundation of China under grant no. 61871142.