
Abstract
In order to guarantee the tag identification accuracy and efficiency in mobile radio frequency identification system, it is necessary to estimate the tags’ arrival rate before performing identification. This research aims to develop a novel estimation method based on improved grey model(1,1) and sliding window mechanism. By establishing tags’ dynamic arrival model, this article emphasizes the importance of tags’ arrival rate estimation in mobile radio frequency identification system. Using sliding window mechanism and weighted coefficients method, weighted grey model(1,1) with sliding window (WGMSW(1,1)) is proposed based on traditional grey model(1,1). For experimental verification, three kinds of data are used as original data in WGMSW(1,1). The experimental results show that the proposed method has lower estimation error rate, lower computation complexity, and high system stability.
Keywords
Introduction
With the rapid development of Internet of things (IOT), 1 radio frequency identification (RFID) technology becomes popular to users who want to track something. If the objects with RFID tags are stable, the system is called stable RFID system. Otherwise, if the objects with tags are moving during identification, this kind of system is called mobile RFID system. 2 No matter stable RFID system or mobile RFID system, there is an unavoidable phenomenon which is called confliction. After receiving the request from reader, tags will rely with their own information. When more than two tags reply the request simultaneously, the confliction will occur.3,4 In this circumstance, the reader usually cannot identify any of conflicted tags, and the time will be consumed. In stable RFID system, the unidentified tags can attend next identification process, and finally all the tags can be successfully identified. But, in mobile RFID system, if tags cannot be identified before moving out of the identification region, this phenomenon is called tag loss. 5 And the efficiency of mobile RFID system will decrease. Therefore, tag loss is a more serious problem than that in stable RFID system.
In order to solve this kind of confliction, many researchers proposed some efficient anti-collision algorithms. All algorithms are mainly classified two categories: one is based on ALOHA (which is called ALOHA-based algorithm), the other is based on tree-algorithm (which is called tree-based algorithm). 6 Dynamic frame slotted ALOHA (DFSA) is the most important method in ALOHA-based algorithms. 7 Q-algorithm, which uses DFSA method, is applied to some applications. 8 So far, most of ALOHA anti-collision algorithms focus on how to identify tags as fast and accurately as possible. Tree-based algorithms, such as binary splitting tree (BST) 9 and query tree (QT), 10 will traverse the entire search space to identify a certain tag. When the tag number increases, the time required to identify one tag will increase dramatically.
In mobile RFID system, new tags may move into or move out of identification area, and the time used for identifying tags is very limited. If tags move very fast, they cannot be identified before they move out of the identification area. So, the tag loss phenomenon is very serious. So, the requirements of mobile RFID system are not only the high speed and accuracy of identification but also the lower tag loss. The original algorithms mentioned above do not take the mobile requirement into consideration, so they cannot be directly applied to mobile RFID system.
With the rapid development of IOT, 11 more and more mobile RFID systems are applied in intelligent logistics, intelligent airport, and other supply-chain applications. So many researchers focus on how to improve existing algorithms and apply them to mobile RFID systems.
In mobile RFID system, the number of tags in identification area will change over time. If the tags leave the identification area without being identified, the information of the tags will be lost. Such situation is intolerable in some applications such as intelligent logistics and intelligent airport. In order to reduce the tag loss rate, the most important things for the reader is to know how many tags are in identification area at that time. The reader can adjust the parameter to identify tags. Because of tags’ movement, the number of tags is unknown in advance and how many tags enter the recognition area is also uncertain. So, it is difficult for reader to set parameter according the number of tags. Therefore, the prediction of tag arrival rate is the key point for reader.
At present, there are many ways to achieve prediction such as time-series method, 12 neural network (NN) prediction method, 13 and statistical prediction method. 14 In RFID system, due to the limitation of memory capacity, the RFID reader cannot record too much previous data, so the chosen algorithm must meet the requirements of small amount of data. Restricted by the reader’s processing ability, the selected prediction algorithm should have lower computational complexity. If the algorithm will be used in mobile RFID system, it should have real-time specificity. For traditional forecasting methods, such as time-series method and NN method, the number of samples will seriously affect the accuracy of forecasting. So, these methods are not suitable for mobile RFID systems without improvement.
Grey system theory was first put forward by Chinese scholar Professor D Julong 15 in March 1982. The grey prediction is a method for predicting the system which has uncertain feature. The grey prediction method 16 identifies the degree of difference between the development factors of the system, performs correlation analysis, and then processes the original data to find the law of system variation. According to the law of system variation, the system can perform prediction. This model uses a small number of samples (at least four samples) to predict the value in future. At present, grey forecasting model has been widely used in various small samples forecasting, such as electricity consumption forecasting in the power industry 17 and water quality in rivers and lakes of the hydrological industry. 18 In this article, the tag arrival rate is also a small sample, so the grey prediction can be used in this kind of prediction.
In the grey model(1,1) (also known as GM(1,1)), the first parameter in parentheses means that grey process can be described by a first-order differential equation. The second one means that the system contains only one variable. In GM(1,1), the minimum number of samples required is 4, that is, the fewest modeling length is 4. In mobile RFID system, if the tag arrival rate is as a variable, it meets the requirements of GM(1,1) for variables. However, when the tag arrival rate suddenly changes, the accuracy of GM(1,1) model prediction will decrease. In this article, the author proposed an improved GM(1,1) prediction method based on sliding window mechanism. Traditional GM is used to predict the future data using a set of static data. Using the method in this article, prediction becomes a dynamic process because of a set of dynamic data. This method can be used in many environments such as intelligent logistics, luggage identification in smart Airport, and intelligent animal breeding.
This article is organized as follows. In section “Mobile RFID systems,” this article describes the tag arrival model in mobile RFID system. The improved prediction method is proposed in section “Our method weighted grey model(1,1) with sliding window (WGMSW(1,1)).” Then, we simulate the proposed method and compare the results with existing method to get the results in section “Simulation and analysis.” This article is concluded in section “Conclusion.”
Mobile RFID systems
In order to describe the tag identification model, this article uses the following symbols and definitions:
R (round): in static RFID system, the duration, from the beginning of reader’s broadcasting of instruction to all tags are identified, is called a round (denoted by R).
Fi: the ith frame in an identification process.
tij: the jth timeslots in the ith frame.
Ui: the number of tags which move from the ith frame to the (i + 1)th frame.
xi: the tags’ arrival rate in Fi.
Li: the timeslots number in Fi.
In static RFID system, the R consists of multiple frames Fi (i ≥ 1), so R = {Fi|i ∈ N}, in which N represents the natural numbers. Each frame Fi is divided into several timeslots tij, so Fi = {tij|j = 1,2,…,Li}. Tags in identification area randomly select one timeslot in Fi to wait for being identified. When the tag is successfully identified in this timeslot, this one is called successfully timeslot. If two or more tags select this timeslot, tags cannot be identified because of collision, so this timeslot is called collision timeslot. If no tags select a certain timeslot, this kind of timeslot is called empty timeslot. After a frame, the reader will count three kinds of timeslots. According to the statistical results, the reader sets new parameters and then initialize next frame. In static RFID system, there are no new tags entering the identification area during identification process. The definition of R in static RFID system cannot be used in mobile RFID system. The definition frame Fi in mobile RFID system is the same as that in static RFID system. But during the identification process in mobile RFID system, new tags may come into the identification area. We use the following assumptions that the new tags arrived in Fi will not participate in the identification of current frame, but in the next frame Fi+1. Because the tag arrival rate xi in the frame Fi is unknown, the number of tags arrived in frame Fi cannot be known, and then the number of tags to be identified in the next frame is unknown, and the frame length of the next frame cannot be determined. To solve these problems, we must first predict the tag arrival rate xi in a frame Fi. The xi is a dynamic value, and there is no way to know its value accurately in advance. Therefore, online accurate prediction of tag arrival rate has become one of the key issues to be solved for mobile RFID systems. Tags’ arrival model in mobile RFID system is shown in Figure 1.

Tags’ arrival model in mobile RFID systems.
The notations used in Figure 1 are the same to ones in static RFID system. Ui is the number of unidentified tags which should be identified in Fi+1. w is the total number of frames in identification area. d is the distance of identification area. F0 is the initial frame. In F0, the reader does not identify any tags, so all tags in F0 will attend identification process in F1. According to DFSA algorithm, 19 Ui(i ≥ 1) consists of two parts, one part is the number of unidentified tags Ni in the ith frame due to confliction, the other one is the number of new tags arrived in the ith frame xi × Li

In equation (1),
In Alcaraz et al., 21 based on frame slotted aloha (FSA) algorithm and dynamic system theory, the author proposes a model to calculate tag loss rate and then obtains the optimal frame length setting method. YH Chen et al. 22 put forward the method which dynamically changes the modeling length of GM to improve the accuracy of prediction.
Our method WGMSW(1,1)
The theory of GM(1,1) in mobile RFID system
In mobile RFID system, the tag arrival rate should be predicted in advance. Many methods are proposed for predicting data, but not all methods are suitable for mobile RFID system. GM has the characteristics of needing fewer samples and less computation complexity, so it is suitable for the requirement of mobile RFID system.
GM forecasting is to identify the development trend of the system and to generate data series with strong regularity, then to establish corresponding differential equations, and finally achieve the purpose of forecasting the future state.
The first-order single-variable grey differential equation model is called GM(1,1). GM(1,1) performs accumulated generating operation (1-AGO) to generate data which follows approximate exponential laws and then describe these data using first-order differential equations.
For an original nonnegative time-series

The GM(1,1) can describe the trend of data using equation (3)

Using equation (3), we can predict the next data. The parameter a represents the development index, and the parameter b represents the grey actuating quality. It can be seen from the results that the value of
Our method WGMSW(1,1)
In mobile RFID system, the latest tag arrival rate has a great impact on predicting future tag arrival rates. Tag arrival rate has local correlation. For this reason, we make improvement to GM(1,1) as follows.
Sliding window mechanism
After a prediction process, the RFID reader gets a new tag arrival rate. Using this estimation value, the reader sets frame length and performs next reading cycle. To keep local correlation, this estimation value should be appended to the raw data as a latest value, and the oldest value in raw data should be deleted. The model length m will not change. This mechanism is just like a window which slides with the identification process. The window size is the number of raw data. After a reading cycle, the window will slide foreword, as shown in Figure 2.

Sliding window mechanism.
Using weighting method to update x1(0)
From section “The theory of GM(1,1) in mobile RFID system,” we know that traditional GM(1,1) uses

In equation (4),

So the implementation schematic of WGMSW(1,1) is shown in Figure 3.

The implementation scheme of WGMSM(1,1).
The reader side performs prediction and reading, as shown in Figure 3. The tags are passive tags, which only receive the signal of reader and reply information at certain time. The interaction between reader and tag is shown in Figure 4.

Interaction between reader and tags.
Evaluation of WGMSW(1,1)
In order to evaluate the accuracy of WGMSW(1,1), we use following definition.
Residual sequence ε0

where
Mean relative error (
)

where
Mean variance ratio



Small error probability (p)
In order to evaluate the performance of GM, many research works15,16 put forward equation (10), in this article, we adopt this as a method

Many researchers believe that the model performance is determined by
Performance evaluation of GM model.
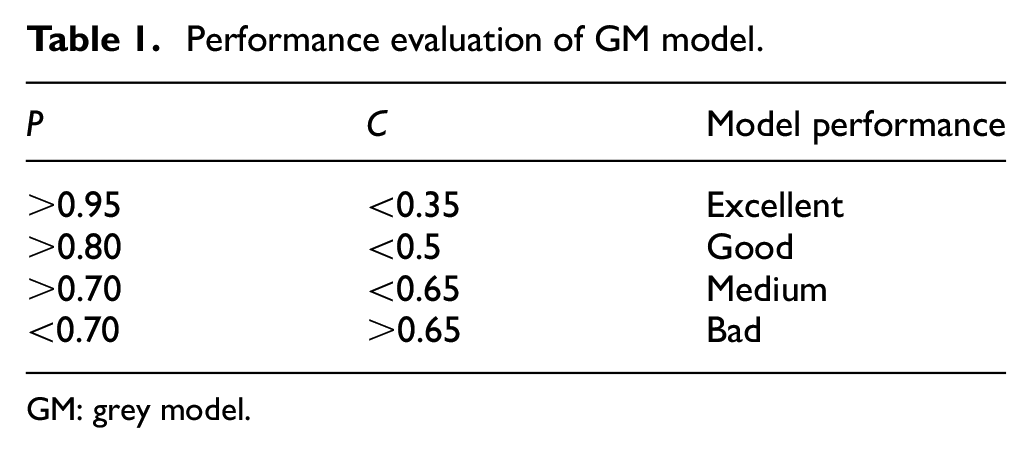
GM: grey model.
In this algorithm, the model length is always 4, so the system is stable. During forecasting process, the reader needs to calculate the parameter a and b by least square method. The calculation amount of this method is less. The time complexity of WGMSW(1,1) is the same as traditional GM(1,1) which is O(m2).
Simulation and analysis
Preparation of the original data
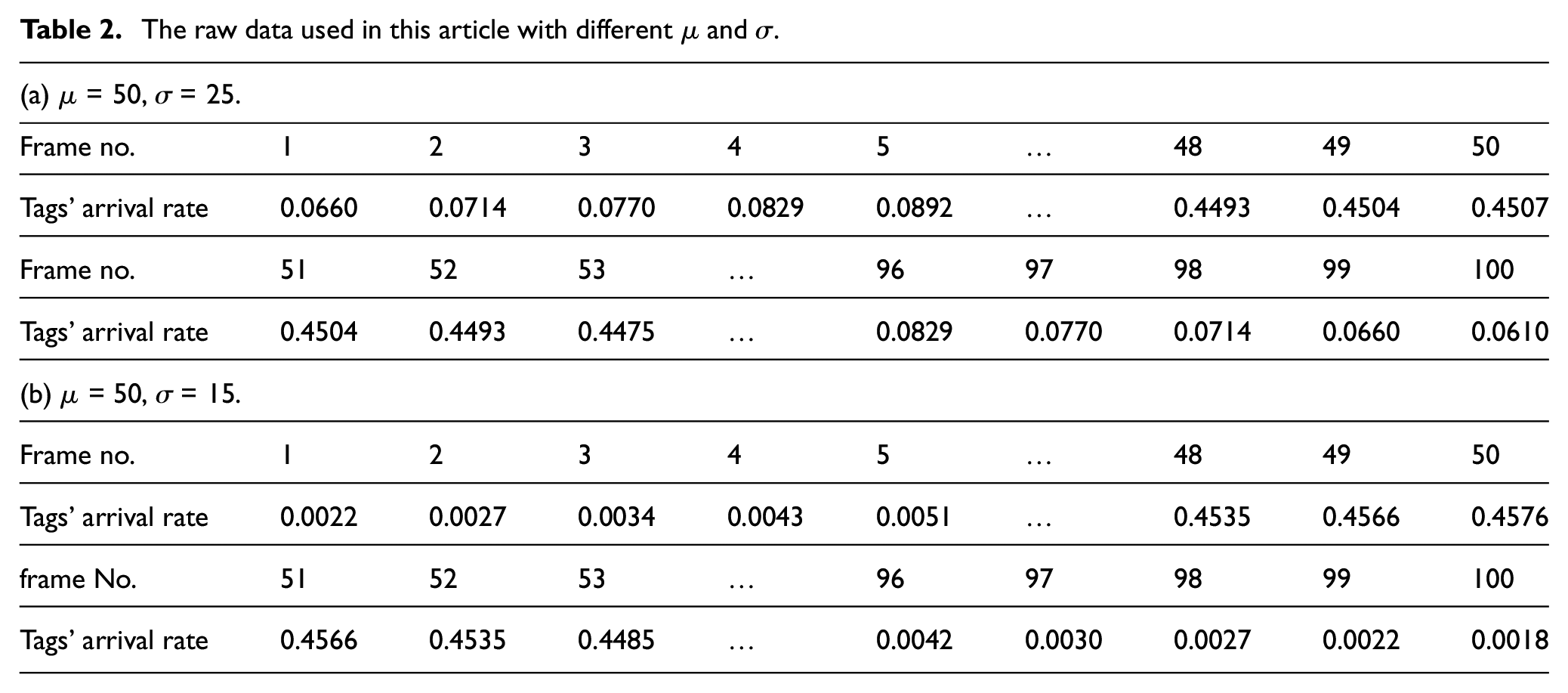
Many researchers regard tag arrival as a stationary Poisson process in which the tag arrival rate is constant. In fact, the arrival rate may change over time, and in generally, the arrival rate takes the single-peak or multiple-peaks’ shapes. In this article, Gaussian distribution is proposed to simulate the arrival rate of tags, which makes the procedure more objective.
The reading efficiency of DFSA algorithm is generally 0.368. 23 After optimization, the efficiency can reach 0.46. 24 Tags can be considered as customers in queuing systems, and the reader is the server. According to queuing theory, the arrival rate of tags should not exceed 0.46.
This article uses normal distribution
Before prediction, the series ratio of original data should be calculated first to insure the data can be predicted by WGMSW(1,1). The series ration can be defined as

According to GM(1,1) application conditions,
The raw data used in this article with different μ and σ.
Simulation and comparison
The pseudo code of WGMSW(1,1) is shown as follows:

In mobile RFID system, using the pseudo code above, the reader can predict one future tag arrival rate which will be used for setting frame length in the next reading process. Looping of this pseudo can get more arrival rate using sliding window.
The hardware platform used to simulation is CPU: Intel(R) Core(TM) i5-4590 CPU at 3.3 GHz; RAM: 8 GB. The operation system of PC is windows 7, and the simulation software is MATLAB 2015b.
To evaluate the performance of WGMSW(1,1), we choose different
In Figure 5(a), at the 52nd frame, the original data is 0.4535, but the estimation result is 0.5, so the estimation error is bigger than others using traditional GM(1,1) for normal arrival model with

Estimation results with different original data: (a) GM(1,1) with
In order to compare the estimation error rate between GM(1,1) and WGMSW(1,1), we calculate the average estimation error rate, as shown in Table 3.
Average estimation error rate with different

WGMSW(1,1): weighted grey model(1,1) with sliding window; GM(1,1): grey model(1,1).
Comparing with traditional GM(1,1) and WGMSW(1,1) in Table 3, WGMSW(1,1) is superior to traditional GM(1,1) in average estimation error rate. When
using our proposed method. When
To compare data used by other researchers, we quoted data in Chen et al. 22
The average estimation error rate is got by 41st data to 47th one, so these values may different from the results in Chen et al., 22 but it does not affect the conclusions. From the results we can conclude that WGMSW(1,1) has lower average estimation error rate than the algorithm proposed by Chen et al. 22 In Chen et al., 22 the model length is 4 or 8, and it will change according to the raw data. But using WGMSW(1,1), model length is a constant 4, so the system is steady (Table 4).
Estimation results using data in Chen et al. 22

The WGMSW(1,1) only optimizes the initial value and the calculation is very simple. The complexity of this algorithm has not increased compared with traditional GM(1,1).
Evaluation of WGMSW(1,1)
Using MRE, C, and p, we can evaluate the WGMSW(1,1).
According to Tables 1 and 5, we can conclude that the WGMSW(1,1) is superior than GM(1,1) in MER, C, and p.
Evaluation of WGMSW(1,1) and GM(1,1).

WGMSW(1,1): weighted grey model(1,1) with sliding window; GM(1,1): grey model(1,1).
Conclusion
In this article, we proposed a tag arrival rate prediction method WGMSW(1,1) based on traditional GM(1,1) in RFID systems. Using sliding window mechanism and weighted GM(1,1) method, Our WGMSW(1,1) method produces lower estimation error rate and computational complexity when tag arrival rate is a normally distribution. In the reader’s hardware system, the algorithm program proposed in this article is built in. When the reader recognizes the tag, it automatically runs the program to complete the continuous prediction of the number of tags and the arrival rate. In the reader’s hardware system, the algorithm program proposed in this article is built in. When the reader recognizes the tag, it automatically runs the program to complete the continuous prediction of the number of tags and the arrival rate. There are some limitations in proposed method. First, the method use isometric GM(1,1) as the basic method, while further research works may use non-isometric GM(1,1) to perform prediction. Second, for getting background value, this article adopts an intermediate value. Further research works should take other method to get much more accurate background value.
Footnotes
Handling Editor: Yanjiao Chen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Nature Science Foundation of China under Grant No. 61962047, the Project of Scientific Research Foundation of Department of Education of Inner Mongolia Antonymous Region under Grant No. NJZY17057, and the Nature Science Foundation of Inner Mongolia Antonymous Region under Grant No. 2019MS06015. The authors are with the College of Computer and Information Engineering, Inner Mongolia Agriculture University, Hohhot 010010, China.