
Abstract
In the past few decades, the whole world has been badly affected by terrorism and other law-and-order situations. The newspapers have been covering terrorism and other law-and-order issues with relevant details. However, to the best of our knowledge, there is no existing information system that is capable of accumulating and analyzing these events to help in devising strategies to avoid and minimize such incidents in future. This research aims to provide a generic architectural framework to semi-automatically accumulate law-and-order-related news through different news portals and classify them using machine learning approaches. The proposed architectural framework discusses all the important components that include data ingestion, preprocessor, reporting and visualization, and pattern recognition. The information extractor and news classifier have been implemented, whereby the classification sub-component employs widely used text classifiers for a news data set comprising almost 5000 news manually compiled for this purpose. The results reveal that both support vector machine and multinomial Naïve Bayes classifiers exhibit almost 90% accuracy. Finally, a generic method for calculating security profile of a city or a region has been developed, which is augmented by visualization and reporting components that maps this information onto maps using geographical information system.
Introduction
Maintenance of law-and-order is an important issue for every country. There are several different forms of such issues including crime, terrorism, and accidents. 1 Furthermore, natural disasters also result into human loss. Apart from this, counter terrorism operations also affect the security situation of a place. Different strategies are being devised and applied globally to counter these different types of menace. One important mechanism to curb this issue is to keep a record of all such incidents, possibly with the help of news reports and devise pro-active strategies 2 and perform security profiling of different locations. The news reports related to the law-and-order situation or the ones involving human loss, that is, involving injury or death of people, are very crucial source to serve this purpose. The statistics gathered from such news can be used for pre-emptive measures to avoid such incidents; similarly, the data collected from these news can be used in computing security factor of a city, country, or a region. Likewise, timely reporting and analysis for different patterns of such events and then forwarding this information to take decisions is very crucial to the concerned field formations so that they can take appropriate measures to avoid such incidents in future. In order to make all these effective, this information must be regularly updated and made readily available to the involved stakeholders. 3
Motivation
The motivation behind this work is to come up with a system to collect human loss news from authentic resources, build a repository, and use it for several purposes including extraction of useful information from each news, identifying the patterns in the occurrence of events, maintenance of security profiles for different cities and regions, and so on. In order to understand the idea, an sample layered map of Pakistan, a country enormously hit by terrorism, shows the districts affected by law-and-order situation, as shown in Figure 1. In the figure, the darker color reflects higher number of incidents in a given area, while the lighter color shows lesser number of incidents. The figure shows that mostly the western region of the country which is near Afghanistan border has been affected by incidents involving human loss.

A sample heat-map for terrorism and other human loss incidents in Pakistan.
To the best of our knowledge, no such architectural framework exists that can help. The proposed framework involves a module for data acquisition using a web crawler, other components perform preprocessing on the collected news, which are then passed to a classifier module that classifies these news into predefined news categories. Each news along with its meta-information is saved into a news repository. Finally, separate components are used for security profiling using statistical analysis, data visualization, and pattern recognition from the news stored in the repository. Three important components of the proposed architectural framework have been discussed in detail. The first one is about data acquisition that discusses the news crawler to collect the relevant news. The challenges and process of developing such news crawler have been discussed, which are followed by the statistics of the news repository accumulated by implementing this crawler. The second component is the one that automatically categorizes the news in the repository using widely used text classifiers. While another perspective of security profiling, reporting, and data visualization has also been presented.
Contribution
This research work provides the following contributions:
Defines an architectural framework for human loss news data integration that involves collection, processing, analyzing, and visualization of human loss news involving terrorism and law-and-order situations.
Provides detailed design and implementation issues and solution for its three major components, namely, information extractor, news classifier, and visualization and reporting.
Presents a data set of human loss new gathered and classified manually for the evaluation of classification component.
Empirically identifies a suitable news classifier for the categorization of human loss news.
Proposes a mechanism for security profiling of a city based on the statistics gathered from the proposed data integration framework.
The rest of the article is structured in the following manner. The relevant literature is discussed in section “Related work.” While, the proposed architectural framework and some details of its components are discussed in section “Architectural framework,” which is followed by the section “News repository” that explains the process and relevant details of building human loss news repository. Section “Classification methodology” presents an empirical comparison of widely used text classifiers to automatically categorize obtained news into appropriate human loss news category. Section “Experiments and results” presents experimental setup, evaluation measures, and result and discussion. Finally, security profiling and reporting and visualization of news is discussed in section “Security profiling and data visualization.” The conclusion and future directions is presented in section “Conclusion.”
Related work
There exist several data services and systems which capitalize on acquisition and processing of data from these services. 4 Web crawler is the best tool for news extraction. Guo et al. 5 provide an effective and easy way, Extract COtent from web News (ECON), to extract content from any news web page written in any language automatically. It exploits document object model (DOM) tree structure of news web page and uses features of DOM tree to do its job.
Organization and management of large volumes of electronic text information are a great challenge. 6 Text classification could be used as an essential technique to handle this issue. Categorization of textual data to predefined categories is known as text classification. Several text classification applications, such as prediction of user preferences, news filtering, email filtering, and many more, exist7–9 and are used for different purposes. A number of machine learning techniques have been used to classify texts including rule induction, Naïve Bayes (NB), 10 decision tree induction, K-nearest neighbors (KNN), random forest (RF),11,12 and support vector machine (SVM).9,13
Yang and Liu 7 studied five classifiers with statistical significance and show that SVM, KNN, and linear least square fit (LLSF) perform significantly better than NNet and NB against categories having less than ten instances and all the classifiers perform equally well when instances per category are more than 300. Lewis and Ringuette 14 present a study regarding performance of an NB and a decision tree classifier on two textual data sets. They show that both classifiers performed reasonably. They also demonstrate the effects of temporal nature of definitions of categories.
Moral et al. 15 and Hull and Grefenstette 16 discussed pros and cons of stemming. They show that benefits of stemming are specific to context. Nature of language also influences the performance of a stemmer. Furthermore, effects of stemming are not always positive, a warning note on the exercise of stemming words, which can have mixed effects on classification performance in information retrieval.
Ting et al. 17 aim at highlighting NB classifier’s performance for document classification. It shows that NB is accurate and computationally efficient classifier for document classification due to its simplicity. Rish 10 discusses assumptions made by NB classifier about features such as class independence. It shows that NB is accurate because of independent features and functionally dependent features. Kibriya et al. 18 demonstrate that performance of multinomial NB classifier can be improved using term frequency–inverse document frequency (TF–IDF) conversion and normalization of document length. Frank and Bouckaert 19 identified a deficiency of multinomial Naïve Bayes (MNB) when data set is unbalanced and shows that this deficiency can be removed by employing classwise word vector normalization.
Dumais 8 shows that using linear SVMs against training examples, an accurate text classifiers can be learned. It reports that SVMs are robust for preprocessing, and sequential minimal optimization (SMO) method is quite efficient for learning SVMs even for large textual data sets. Joachims 9 explores usage of SVMs for classification from text examples. It analyzes properties of textual data and identifies applicability of SVMs for this kind of task. It shows that there is no need for manual tuning of parameters for SVMs. Hsu et al. 13 provide a guide for SVM classification technique. They propose a simple procedure which usually gives reasonable results. It discusses usage of appropriate kernels in different situations.
Breiman 11 proposed RFs. In an RF, each node is split using the best among a subset of predictors randomly chosen at that node. These predictors are chosen with replacement. Results of RFs are comparable to other classifiers like SVM and NNet. Amaratunga et al. 20 elaborate that when number of features in a data set are huge and truly informative features is small, then performance of RF degrades significantly. In such situations, results can be improved by decreasing the number of trees generated for non-informative features. Xu et al. 21 developed an improved version of RF classifier for classification of textual data. It is designed for high dimensional data with multiple classes. A feature weighting procedure and tree selection procedure are implemented for creating RF suited to text documents’ classification. Biau 12 offers an improvement to RFs suggested by Breiman. This procedure is consistent and adapts to sparsity. Xu et al. 22 propose a model selection method which aims to optimize the tree selection process so that only good trees are included in an RF.
Recently, some work has been published related to visualization and reporting of news. For instance, in Watanabe, 23 the authors present a semi-supervised approach to geographical news classification. Similarly, some other work has been accomplished on classification of UN news. 24 Another work related to adding semantics to news data has been reported in Rodosthenous and Michael. 25 The work done in this research presents a complete architectural framework for maintaining security profiles of cities while compiling data from news reports. It also implements and presents the results of its three important components.
Architectural framework
The proposed system intends to collect the news from famous news websites and stores this information to generate different useful reports for relevant agencies. It further intends to identify different crime pockets, the patterns, and possible connections between different events. The overall architecture of the proposed system is shown in Figure 2.

Overall architecture of the proposed system.
News crawler
The news will be automatically collected through a crawler that will extract crime- and terrorism-related news from different famous news portals. This component is responsible for browsing the news portals efficiently so as to collect news stories.
Preprocessor
The collection of news invites certain preprocessing of the collected news. The preprocess in turn comprises three main sub-components, namely, duplicate detector, information extractor, and the news classifier.
Duplicate detector
This extraction of information from multiple sources involves two types of concerns: first, system may encounter same news from different news portals on the same day. Second, there are follow-up news for major incidents for many days which generally involve updates in statistics, condemnation of events by different people, and so on. This sets up another important requirement of detecting follow-up news stories. The duplicate and follow-up news, if not identified properly, may result into adding the same incident multiple times, hence affecting the credibility of the gathered statistics. Therefore, it requires the design and development of a separate component to process input news so as to detect duplicate and follow-up news.
Information extractor
Apart from the categorization of the news story, useful information shall be extracted from the news story including date and time of the event, location of the event, number of injured people, and number of casualties in the incident. Part of this information shall be used to build the context of news, which can be useful in analyzing the news.
News classifier
This news will be further classified based on the text in the news story. To this end, appropriate text classification algorithm shall be used to automatically classify the news report.
News input manager
The news input manager is responsible for manipulating the gathered news so as to store a single news and its variants along with the source of information in an efficient storage system. Similarly, it also manages the linking of follow-up news with the principal news already present in the system.
Furthermore, this news classification and extraction of certain useful information can lead to an interface that would help semi-automatic news input system. Where, most of the information is furnished by the news preprocessing system and is then reviewed and endorsed by a human. This semi-automatic system will help maintaining the credibility of the news repository. Figure 3 shows the steps involved in preprocessing and news classification. While, a sample input screen is shown in Figure 4.

Algorithm for news processing.

Semi-automatic data entry screen.
Reports and graphs
The collection of such news will help us creating different useful reports showing the type and number of incidents in different time intervals in specific locations. A sample heat-map report showing frequency of incidents in different districts in Pakistan is shown in Figure 1.
Pattern recognition
Once the system will have sufficient news, it would set the platform to analyze the stored information so as to identify crime pockets and crime patterns using the stored information.
News repository
This research requires a repository data set comprising human loss news reports. Such work cannot be accomplished in an effective manner in the absence of real and correct data. Thus, a real news repository has been created from scratch by taking advantage of the World Wide Web. News reports are gathered and processed from the websites of famous and top-ranked newspapers of Pakistan to generate this repository.
News categories: A specialized set of news categories are defined on the recommendations of a group of experts from private security agencies of Pakistan (https://hesecurity.com.pk/). A brief description for the news of each category is presented in Table 1.
Categories of human loss news.

Automatic news repository generation
The general process for the creation of this purposeful news repository is presented in Figure 5. It comprises a news crawler that extracts the news from the websites of news agencies. It preprocesses each news page to extract the main story from it and then checks for its conformance to human loss news. If a news falls under the category of human loss news, then it is added to the repository and is discarded otherwise.

Process for generating human loss news repository.
News extractor
A crawler is developed that collects human loss–related news stories from the news websites and saves them into a database. It consists of two modules, first one visits home page of the newspaper’s website and extracts all URLs present on it along with their text. These URLs are actually the links to the individual news reports. Then, it checks these URLs against a predefined list of words called keywords. If any of the keywords is present in the text or source of URL, it is saved otherwise dropped. Whereas, the second module visits web page of each link of these saved URLs in the list and extracts story presented on it. It stores both story and URL into database for future reference. Thus, the crawler application explores the web sites using breadth first graph traversal algorithm.
The extraction of actual news story from the web page is not trivial. As the issue with the extracted story data is that apart from the actual content of news story, it also constrains some advertisements, links to related and recent news stories, menu bars, headers and footers of web page, and other irrelevant data. Figure 6 shows a sample of a news story web page. Actual content of story is in rectangle and ellipses show noisy areas. Almost 70% data of every news story web page are occupied with irrelevant material. In order to separate and extract actual content of story from a news story web page, the technique used in Guo et al. 5 has been employed. Thus, the crawler application uses breadth first search to explore all the news while ignoring the noisy data.

A news story web page showing news story and noisy data.
News report preprocessing
More than 60,000 news reports are collected by this web crawler application for the period between 1 January 2010 and 31 March 2017. These news reports are passed through different filters, as shown in Figure 7, as all of these reports are not true reports in perspective of human loss. Certain keywords used in human loss–related news have been used to apply an initial filter so as to collect the human loss news. All the news collected are then processed manually and the reports which are extracted but are not required are discarded from the repository manually.

Preprocessing steps for a news.
Since news reports have been collected from five different sources, therefore, a lot of duplicated reports have been found in the repository, as same incident is reported by all these news agencies. Similarly, some high-impact news are continuously reported for several days, and thus need to be identified as another type of duplicate news, which we refer to as follow-up news. This requires the detection and removal of duplicate reports. Thus, only one instance of a news story is retained in the final repository. It is pertinent to mention that duplicate news detection is itself a complete research problem; therefore, in this research, duplicate news have been manually detected, and only a single copy of each duplicate news has been used for visualization and security profiling to avoid any over statement of facts. However, we intend to address this problem as one of the promising future directions. After the initial scrutiny, nearly 5000 unique reports are left. All these news are already manually categorized into the relevant classes.
Statistics of the repository
The news repository is composed of nearly 5000 news stories related to human loss (dead and/or injured subjects). Out of these, the most frequent news stories belong to the category
Categories of human loss news.

Classification methodology
An important objective of this research is to build a classifier to automatically categorize the news stories into appropriate class tag. To this end, a conventional process has been adopted, as shown in Figure 8. The whole news repository is divided into two different sets, one for training the classifiers and second for testing purpose. It is pertinent to mention that a large number of text classifiers have been used for many different purposes. Therefore, it is not trivial to take any of them as suitable classifier for the categorization of human loss news. Most prominent and effective classification techniques for text data are NB, SVM, and RFs. Therefore, this research involves all these classifiers to choose the best one for the categorization of human loss news.
Process for categorization of news reports.
Multinomial naive bayes
This is a feature independent and probabilistic model based on Bayes’ theorem that assumes strong independence. It makes use of prior and posterior probabilities. NB classifier calculates the probability with which a news report may fall in a given category and assigns it the category that has the highest probability. The strength of this approach is that it is simple, efficient as it consumes less computational time and does not require large memory for execution. Every news story consists of English language text, and every distinct word in text represents a feature. MNB uses these features to calculate probabilities of words or terms for all classes using the training data set. These probabilities are in turn used to compute the probability scores for a newly encountered news story.
Support vector machine
SVM is a discriminative classifier that makes use of separating hyperplane. By providing labeled trained news reports as input to the algorithm, it outputs an optimal hyperplane that is used to categorize future or test news reports. News reports may or may not be linearly separable. If news reports are not separable, then algorithms transforms it to higher dimension and try to find hyperplane in that dimension. Different kernels are used for transformation. This research employs linear kernel and radial basis function (RBF) kernel for transformation. Linear kernel is used if data are linearly separable among classes, whereas RBF (Gaussian) kernel is used if data are not linearly separable. SVM is computationally complex method as compared to NB, but is considered to be more accurate classification method.
Random forest
RF has been reported as successful method for text classification in recent literature. It is an ensemble learning method for text and other kind of classification, which compiles its decision based on involved several individual decision trees. From training set, more than one decision trees are constructed and then class is output as mode of the classes. These decision trees are constructed based upon randomly selected features (terms/words) from news reports. These features are selected with replacement. For a given news story, the class which is most frequently resulted by the trees in the forest is considered to be the most appropriate class.
Variants of selected classifiers
In general, the text classification problems are of empirical nature and most of the text classifiers apply certain preprocessing techniques on the data set before actually applying the classifiers on the considered data elements. Therefore, this research also involves commonly used natural language processing (NLP) techniques, namely, stemming 15 and TF–IDF weighting. 26 Stemming reduces a word to its base word, whereas TF–IDF associates a weight to a given word based on its frequency of occurrence in a given document and in the whole corpus of data. Thus, for each approach, four different variants are considered, that is, simple version, stemmed words are represented by superscripted S, TF–IDF weighted words are represented by superscripted T, and both stemming and TF–IDF weighted words are represented by superscripted TS.
Experiments and results
The principal objective of this research is to find the most accurate text classifier for human loss new reports. In order to find the best classifier among 16 variants of three classification techniques, rigorous experiments have been conducted and evaluated using appropriate evaluation measures.
Experimental setup
Tenfold cross-validation has been employed to conduct experiments. That is, every experiment involves a training set consisting of 90% of instances in the data set, whereas, the test set consists of the rest of the 10% of instances in the data set. It is ensured that this division is stratified, that is, the percentage of instances for each category in the training and test sets remains the same. This whole process is repeated 10 times. Average results of these 10 iterations have been reported. In the end, a discussion on the obtained results provides a synthesis of all the experiments.
Evaluation measures
The evaluation measures used to evaluate this work are presented in Table 3. They include the accuracy, time to train and classify the instances, receiver operating curve, and area under receiver operating curve.
Evaluation measures.

Accuracy
Accuracy is a measure to evaluate how correctly a classifier is classifying the news reports. It is the percentage of number of reports correctly predicted over the total number of reports in the news repository. It is a simple measure but reflects the overall correctness of the proposed method. In this article, accuracy is denoted by
Time
Time is another measure to judge the performance of a classifying algorithm. It is measured in seconds. In this work, the reported time consists of the time taken by each classifier to train a model and to make all the predictions in aforementioned settings. Time taken is denoted by
Receiver operating characteristic (ROC) curve
ROC curve is a good way to judge performance of two competitive classifiers. In an ROC curve, true positive rate (sensitivity) is plotted as a function of false positive rate (specificity). The curve that is closer to the ideal is considered to be the better that the other.
Area under ROC
Area under ROC tells how close a classifier is to perfection. It ranges from 0 to 1. An area of 1 represents perfection and an area of 0.5 or below is considered to be worse than even a random classifier.
Results and discussion
Variants of multinomial NB
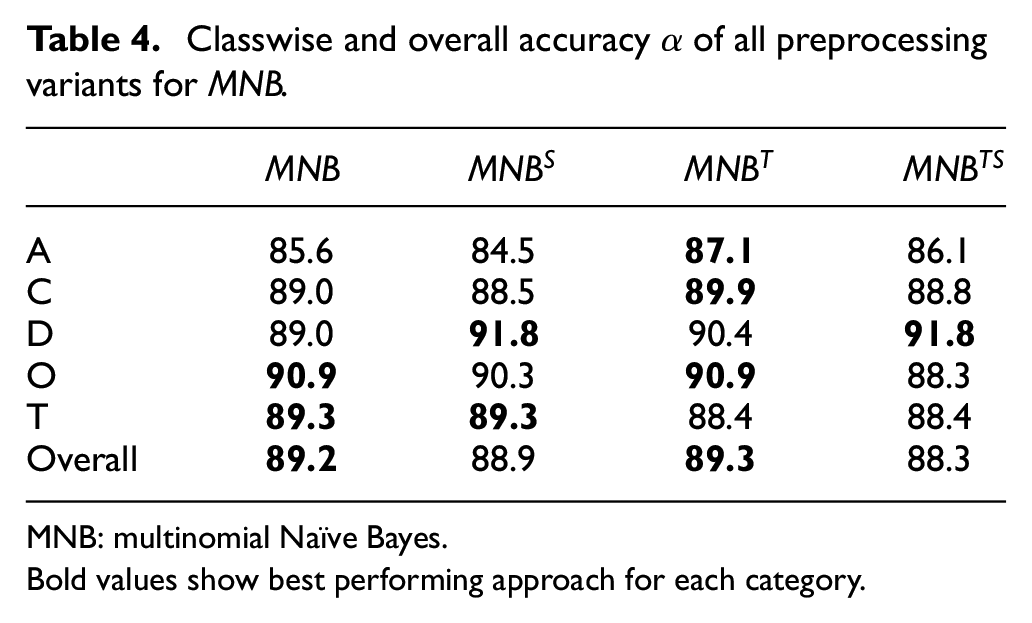
Overall and classwise accuracies of all four variants of MNB are presented in Table 4. It is clear from Table 4 that all these variants performed equally well against news reports in the considered repository. Overall accuracy of all four is almost 90% and equal at 1% level of statistical significance. Classwise accuracies are almost same at 3% level of statistical significance for each class for all variants. Also accuracies of all classes within each variant are not differing more than 5%, which shows that
Classwise and overall accuracy
MNB: multinomial Naïve Bayes.
Bold values show best performing approach for each category.
Variants of SVM
Overall and classwise accuracies of all eight variants of SVM are shown in Table 5. It is clear from overall accuracy that all variants of SVM performed equally well. Accuracy of all eight is almost 90% and equal at 2% level of statistical significance. Classwise accuracies of four variants of RBF kernel are significantly lesser than four variants of linear kernel for classes A and D. For rest of the classes, they are almost similar at 5% level of statistical significance. Difference between accuracies of all classes within each variant is significant and more than 5%, which shows that SVM is biased toward those classes that have greater number of news reports in the repository.
Classwise and overall accuracy

SVM: support vector machine.
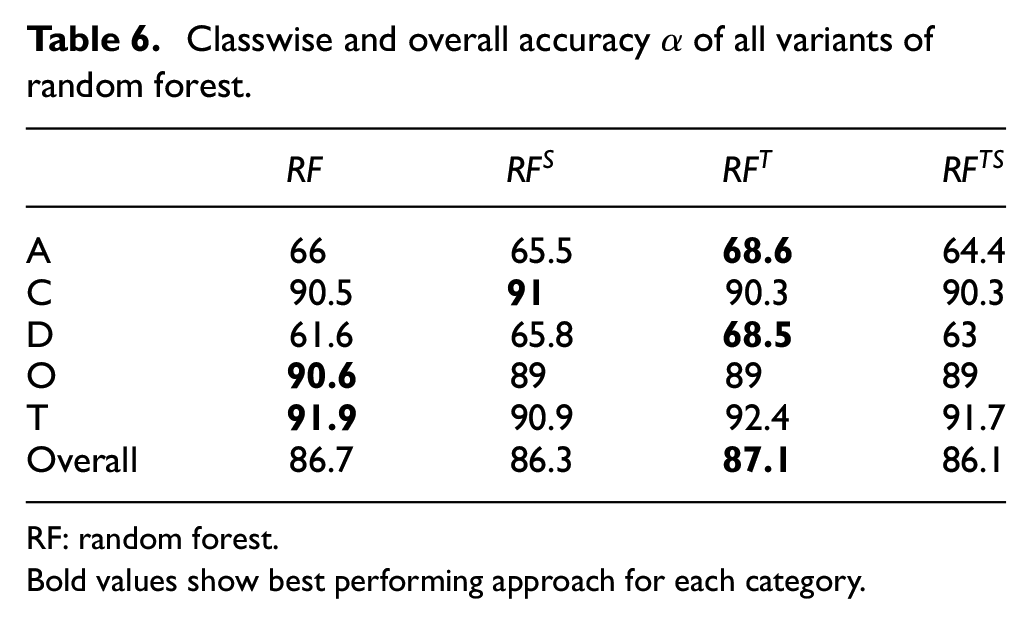
Variants of RF
The experimental results for the experiments conducted with the variants of
Classwise and overall accuracy
RF: random forest.
Bold values show best performing approach for each category.
Comparison for best variant
Results of all variants of each approach have shown that simple
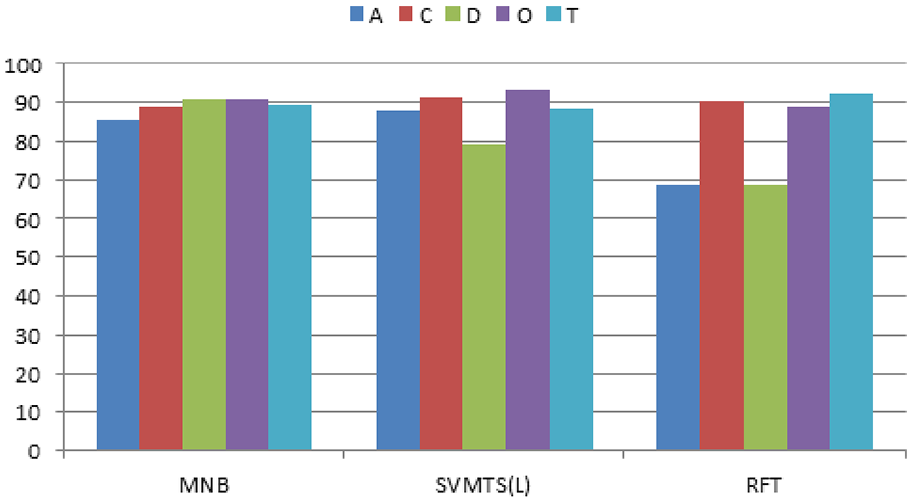
Figure 9 shows classwise accuracy of all three best variants. It is very clear that these three variants perform equally well at less than 5% level of statistical significance against C, O, and T classes. But performance of
Comparison of classwise accuracy of all best variants.
Table 7 shows the comparison of all best variants in terms of accuracy, time, and area under the ROC curve. It shows that the accuracy of all three selected variants
Comparison of

AUROC: area under receiver operating characteristic; MNB: multinomial Naïve Bayes; SVM: support vector machine; RF: random forest.
Similarly, in terms of time taken to train and predict news reports, the statistics show that
Table 7 shows the AUROC comparison for the selected variants. It is evident that all three best variants are performing equally well. The value of 0.9 or above is considered a very good result, and it is clear that all the selected variants have higher values than 0.9.
Table 8 shows classwise area under ROC of all three variants. Whereas Figure 10 shows ROC curves of all three best variants classwise. Performance of all three best is close to perfection as per statistics listed in Table 8. All are above 0.9 which is considered excellent and close to perfection. ROC curves shown in Figure 10 also testify this as all curves are away from diagonal line (random classifier line) and toward and near to top left corner (0, 1) of the chart and that corner belongs to perfection.
Classwise comparison of all best variants.

MNB: multinomial Nave Bayes; SVM: support vector machine; RF: random forest.

Comparison of ROC curves for best variants.
After analyzing accuracy, time, areas under ROC, and ROC curves, it can be claimed that
Security profiling and data visualization
The input data compile a useful repository for the further analysis. The analyzers can then generate expedient reports from this repository reflecting security situation in a given geographical or political unit (city, district, division, province, and so on) in a given period of time.
News classifier in data ingestion
In the proposed system, the news crawler gets news stories, and among these stories, the human loss news are retained, while the others are discarded. These news are passed to the news classifier module discussed in this section which assigns it a category automatically. Figure 11 shows how this classifier is integrated with the data ingestion system. It can also be observed that the data ingestion system also records other meta-information related to the extracted news including date, Islamic month and date, source of data, and location of data. It also extracts statistics with the help of preprocessor and fills the fields showing number of casualties and injured people during an incident. All this information is shown to a data entry operator, whose job is to just quickly vet the extracted information, thus resulting into a semi-automatic data acquisition system. The data entry operator may further enrich or correct the extracted information where required. For instance, he may add some missing information, for instance, responsibility claim, target, and so on. The data entry operator may also correct the outcome of the classifier whenever required.

Sample heat-map for incidents in Pakistan.
Security profiling based on gathered statistics
Based on the raw data, security profiles can be created for different geographical regions. The data shown in Table 9 are a comparison report showing the number of different types of incidents happened in the provinces of Pakistan during 2013 and 2014. The number of different types of incidents is a significant parameter for security profiling. While at the same time, the meta-information extracted from the news, including number of deaths, injuries, type of event, and so on, helps enriching these parameters further. The whole information is subsequently graded based on the number and types of the incidents and the number of injuries and deaths in those incidents in a given period, thus generating a security profile score of each city in a specific period.
Statistics of events took place in different provinces.
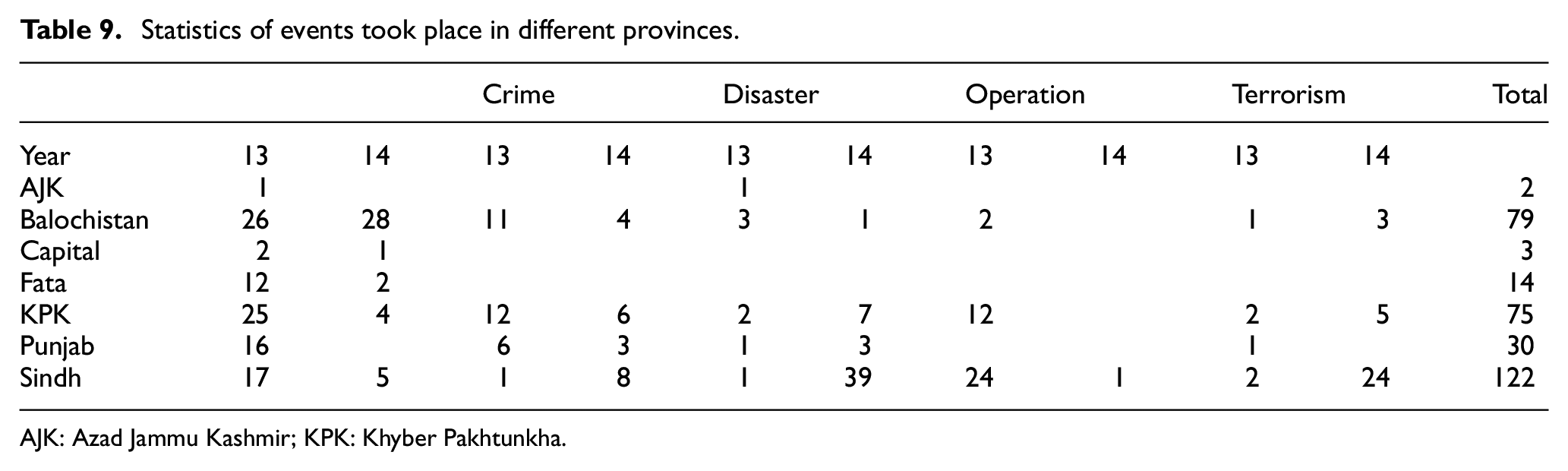
AJK: Azad Jammu Kashmir; KPK: Khyber Pakhtunkha.
Thus, the user can create a report that shows events of a specific type, in a given period of time, having more than 10 casualties, in a given region by applying different filters. These reports can be materialized and archived in different suitable and useful file formats.
This involves assigning weightage to each category and number of dead and injured persons. This score can be used to draw a layered map showing peaceful areas and the crime and terrorism pockets in the country

where
Visualization and reporting
The visualization and reporting module represents the data in tabular and graphical formats. It is supported by some customized reports that are frequently required. Furthermore, a flexible data extractor is also part of this module that allows the users to apply filters on any type of attributes shown in visualization of number of incidents and the injured and dead people in those incidents in a given period of time in the whole country. Similarly, Figure 12 shows another graphs presenting the percentage of people who got injured in accidents happened in different provinces. It shows that nearly 82% of injuries happened in Sindh province which is second largest province in the country in terms of populations, while nearly 6% people got injured in Punjab, the largest province in terms of population. Similarly, the visualization component helps generating the graphical form of many useful reports. For instance, Figure 13 shows different types of events occurred during a specified period; while Figure 14 shows the heat-map of incidents took place, where the radius of the circle reflects the human loss in the form of deaths and injuries took place in the incident, it also shows the details of the incident pointed to by the mouse.
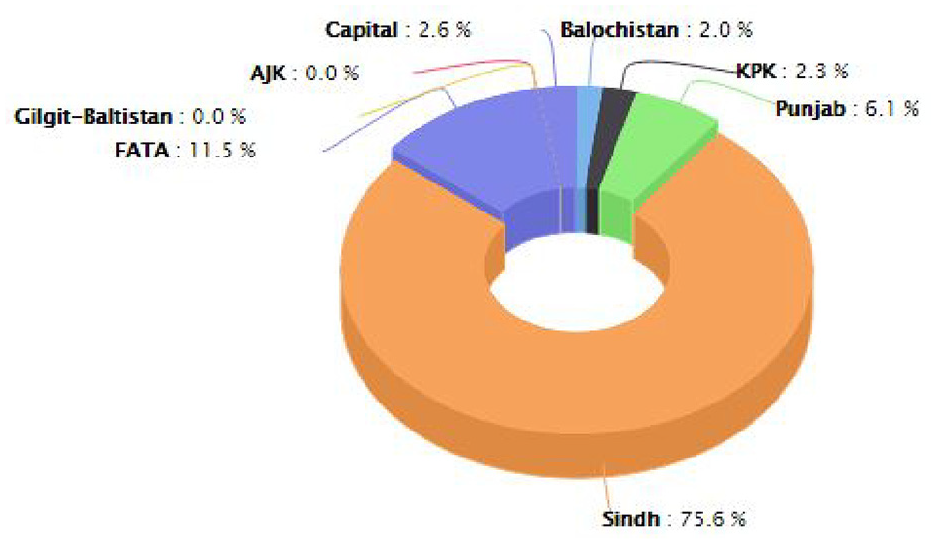
Pie-chart showing percentage injured persons per province for accident category.

Different types of incidents occurred during a specific period.
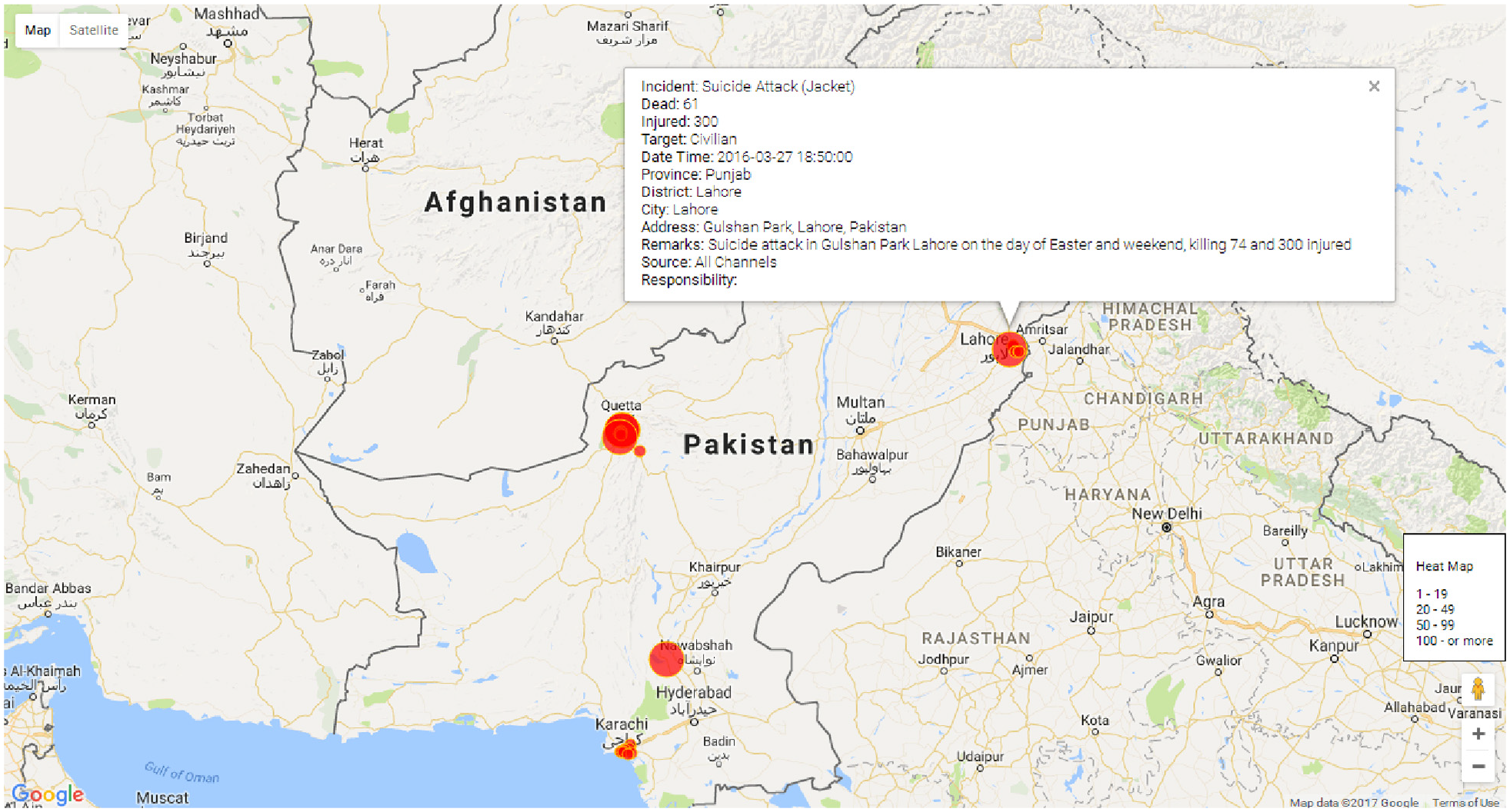
Heat-map of different incidents.
Conclusion
This research has proposed an architectural framework for accumulating human loss news from news portals, so as to process them and build security index for different cities and regions. To this end, all the components have been discussed, while data accumulation, classification, and data visualization components have been developed. In order to implement the classification component widely used, text classifiers have been used to categorize human loss news. A repository of such news has been generated by designing and developing a customized web crawler that crawled five top news websites of Pakistan. All the collected news are manually checked and categorized into appropriate classes that include accident, crime, disaster, operation, and terrorism. These classes have been provided by the domain experts. This repository served as a gold standard to empirically evaluate some widely used text classifiers including MNB, SVM, and RF. Based on certain preprocessing techniques, 16 variants of these classifiers have been tested and evaluated using appropriate evaluation measures. The study concludes that MNB is best of them as it achieved 89% overall accuracy and more than 85% accuracy against all classes. Similarly, in terms of time taken, it is the most efficient classification approach among the considered classifiers. Its overall area under ROC was greater than 0.9 that is considered excellent. Classwise area under ROC for all classes was also greater than 0.9.
Although the number of news reports in the repository was enough for this study, yet in near future, more reports will be collected to extend size of this set to verify the results on bigger set. In this research, news reports were categorized to only one category but there is a need to classify some news reports to more than one category. Multiclass labeling of such reports is a possible extension to this work. In this study, the duplicate news reports were detected manually. There is a need to devise some automated mechanism for duplicate detection of news reports, which demands an automatic duplicate detector for human loss news. Similarly, another possible extension to this work involves the summarization of these news reports and the extraction of useful statistical and contextual information from the news report.
Footnotes
Handling Editor: Yanjiao Chen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research work was supported by Abu Dhabi Faculty Research grant.