
Abstract
This article addresses the problem of outlier detection for wireless sensor networks. As increasing amounts of observational data are tending to be high-dimensional and large scale, it is becoming increasingly difficult for existing techniques to perform outlier detection accurately and efficiently. Although dimensionality reduction tools (such as deep belief network) have been utilized to compress the high-dimensional data to support outlier detection, these methods may not achieve the desired performance due to the special distribution of the compressed data. Furthermore, because most existed classification methods must solve a quadratic optimization problem in their training stage, they cannot perform well in large-scale datasets. In this article, we developed a new form of classification model called “deep belief network online quarter-sphere support vector machine,” which combines deep belief network with online quarter-sphere one-class support vector machine. Based on this model, we first propose a model training method that learns the radius of the quarter sphere by a sorting method. Then, an online testing method is proposed to perform online outlier detection without supervision. Finally, we compare the proposed method with the state of the arts using extensive experiments. The experimental results show that our method not only reduces the computational cost by three orders of magnitude but also improves the detection accuracy by 3%–5%.
Keywords
Introduction
With the rapid development of human society, the Internet of Things (IoT) has penetrated every aspect of our culture. It enables a large number of physical objects and environments to be monitored efficiently and effectively. 1 The wireless sensor network (WSN) is an important infrastructure allowing the IoT to collect data. Nowadays, the information collected is characterized by large amounts of data, often with high dimensions. Due to the complex environmental factors and limited resources of the sensors (i.e. energy, CPU, and memory), WSNs are susceptible to different types of misbehavior and harsh environments. 2 We define an outlier in WSNs as a measurement that seriously deviates from the normal pattern of the sensed data. 3 It is critical to identify outliers in the sensed data to ensure the data quality for making reliable decisions. Therefore, the purpose of outlier detection is to monitor the abnormal behavior caused by the fault equipment or concerning events in the monitoring environment, which is of great significance in the application of the IoT.
The environment of sensor networks and characteristics of the sensed data present several challenges for the design of a proper outlier detection technique. First, due to the limited computational power and memory of each node, outlier detection algorithms must have low computational complexity and occupy restricted memory space. Second, as sensed data are typically unlabeled, outlier detection for WSNs is required to operate in an unsupervised manner. Finally, collected datasets have high dimensionality and large scalability for certain cases, presenting issues for data processing. In the past several years, numerous methods have been proposed to perform outlier detection for WSNs4–19 (reviewed in section “Related work”). However, the majority of these can only address the first two challenges, and most of them cannot be directly applied to high-dimensional and large-scalability data because of the following issues: 15 (1) time-consuming—as the dimension of the input data vector increases, the number of feature subspaces increases exponentially, which results in an exponential search space; (2) low detection rate—the high proportion of irrelevant features in high-dimensional datasets unavoidably include noises, which makes the true outliers inconspicuous; and (3) high false alarm rate—in high-dimensional space, we can always determine at least one feature subspace for each point of a dataset that defines such a point as an outlier, that is, every data instance can be considered as an outlier under a particular circumstance. Erfani et al. 15 proposed a method that combines an unsupervised deep belief network (DBN) with a one-class support vector machine (OCSVM) to be applied to a large-scale and high-dimensional dataset. It utilizes DBN to compress a high-dimensional dataset to a low-dimensional dataset, before learning a sphere to partition the outliers from the normal data using OCSVM. However, two problems prevent the use of this method in practical applications. First, outliers compressed by DBN always present a one-sided distribution (refer to section “Characteristics of data vectors reduced by DBN”), which is not suitable for a general OCSVM to learn an appropriate sphere. Second, to obtain the sphere, the OCSVM must solve a quadratic optimization problem, which requires high computational complexity.
Alternatively, we found in our experiments that another form of OCSVM model, the quarter-sphere SVM (QSSVM), 16 is particularly suitable for the one-side distributed outlier. The QSSVM learns a quarter sphere near the origin to partition the outliers from the normal data. Furthermore, the QSSVM obtains the quarter sphere by solving a linear optimization problem, which has relatively less computational complexity. However, the QSSVM can only be performed in an offline mode, and because the linear optimization problem in QSSVM refers to a high-dimensional kernel, it continues to require a high space and time complexity for large-scale datasets.
To address the above problems, we propose a new form of online outlier detection method DBN-OQSSVM, which can accurately and efficiently perform outlier detection for large-scale and high-dimensional datasets of WSNs. To summarize, this article makes the following contributions to the field of outlier detection for WSNs:
We design a new hybrid model DBN-OQSSVM based on DBN and QSSVM, that can process high-dimensional and large-scale data in an unsupervised manner. Utilizing the characteristics of compressed data, the new model can greatly improve the detection accuracy than the models of DBN-OCSVM. 15
We propose an online outlier detection method based on the hybrid model. To avoid the calculation of the highly complex kernel function in the feature space, we fix the center of the compressed data to the origin in the input space and propose a theorem to learn the radius of the QSSVM through a sorting method instead of solving an optimization problem. Moreover, a decision function is proposed afterward to detect the newly arriving data in an online manner.
We compare the performance of our method with those of the three competitors through extensive experiments. The results show that compared with DBN-QSSVM, DBN-OCSVM, and iForest, the DBN-OQSSVM method can reduce the computing time by three orders of magnitude on average and improve the accuracy by 3%–5%.
The remainder of this article is organized as follows. First, the related works are reviewed in section “Related work.” The details of the four models referred to in our method, as well as their characteristics, are described in section “Background and problem formulation.” We present our proposed outlier detection method, with an evaluation using experiments on four real datasets, in sections “Fast outlier detection algorithm for high-dimensional sensor data” and “Evaluation,” respectively. Finally, the main conclusions are stated in section “Conclusion.”
Related work
It is important to detect the outliers efficiently and accurately to improve the reliability of WSN data. The general outlier detection methods can be classified into four classes: statistical-based methods,4–6 nearest neighbor–based methods,7,9 clustering-based methods,10–12 and classification-based methods.13–17 Statistical-based methods capture the distribution of the data and evaluate how well the data instance matches the model. If the prediction probability of the data instance generated by the model is overly low, the data instance is defined as an outlier. Zhang et al. 4 proposed an outlier detection method that can find the observations that do not conform to the expected behavior of the data, based on time-series analysis and geostatistics. Ghorbel et al. 5 proposed an outlier detection method that utilizes Mahalanobis distance to calculate the mapping of the data points in the feature space to separate outliers from the normal patterns of data distribution. However, as most statistical-based outlier detection techniques have a quadratic time complexity, they cannot be applied to large-scale WSNs. For nearest neighbor–based methods, the sensors are required to collect all the neighbors’ data for a comparison with their data. Huang et al. 9 proposed an outlier detection method for WSNs, where sensors adaptively send probes to their neighbors to test their availability. Branch et al. 7 proposed an unsupervised outlier detection method for WSNs based on neighborhood collaboration, which can also accommodate dynamic updates to data. However, due to the significant number of communications among neighbors, the nearest neighbor–based methods consume excessive energy at each sensor to perform the outlier detection, which may reduce the lifetime of WSNs. Clustering-based methods group data instances that have similar behaviors into the same cluster and define an instance that cannot be grouped into any cluster as an outlier. Yu et al. 10 proposed a cluster-based data analysis framework using recursive principal component analysis. The framework aggregates the sensor data by extracting the principal components and determines the outliers by abnormal squared prediction error scores. Because cluster-based methods can only perform clustering when they collect the whole dataset, they only perform outlier detection in an offline manner. Classification-based methods use historical data to train the classification model and use the trained model to test the new collections in an online manner. One-class SVM is one of the most common classification models for outlier detection. Huan et al. 13 proposed an outlier detection algorithm using a model selection-based support vector data description. The method can select a relatively optimal decision model for the support vector data description and avoid both underfitting and overfitting. Deng et al. 14 proposed a one-class support Tucker machine based on tensor Tucker factorization to detect the outliers hidden by the destroyed structural information. However, as SVM-based methods require to solve a quadratic program problem, they have relatively high computational complexities. Furthermore, most outlier detection methods cannot achieve their desired performances when they process high-dimensional datasets due to the reasons provided in the above section.
As far as we know, there exists limited work on outlier detection particularly for high-dimensional data. Pang et al. 20 proposed a feature selection-based outlier detection method that selects the feature value interactions which are positively related to outlier detection and determines the outliers by the outlierness of the selected features. As the feature selection-based method has quadratic time complexity with respect to the number of dimensions, it may become inefficient when the data have especially high dimensions. Erfani et al. 15 proposed a high-dimensional outlier detection method that first reduces the dimension of data by DBN and then determines the outliers by OCSVM. However, this approach only performs well when the compressed outliers are distributed uniformly around the normal instances; otherwise, it suffers a low accuracy. Liu et al. 18 proposed an isolation-based method iForest that randomly partitions all instances recursively to generate a binary tree. Outliers are expected to be isolated closer to the root. iForest can be applied to both large-scale and high-dimensional datasets as it avoids computing the distance between instances. However, as the binary trees are generated randomly, in some cases, it requires a large number of iterations to converge the result.
In the following sections, we propose a new form and considerably more efficient outlier detection method that can reduce the computational cost as well as improve the detection accuracy.
Background and problem formulation
Deep belief networks
DBN is a neural network composed of a multi-layer restricted Boltzmann machine (RBM). 21 It can efficiently extract invariant features for complex and high-dimensional datasets by non-linear processing, which is proved to be more powerful than the model that uses linear processing method when the dataset presents non-linear pattern. 15 The architectures of one RBM and a DBN stacked by two RBMs are shown in Figure 1.

RBM and DBN architectures: (a) model architecture of one RBM; (b) model architecture of DBN.
An RBM is a bipartite graph (as indicated in Figure 1(a)).
The training process of DBN is a greedy layer-by-layer technique. After training an RBM, another RBM can be stacked on its top. Meanwhile, the hidden layer of the first RBM is used as the input layer of the second RBM.
Traditional one-class SVM
Tax and Duin 22 proposed a hypersphere-based OCSVM that determines the minimum hypersphere, encompassing as many data points as possible in the feature space. The geometry of the scheme is displayed in Figure 2.
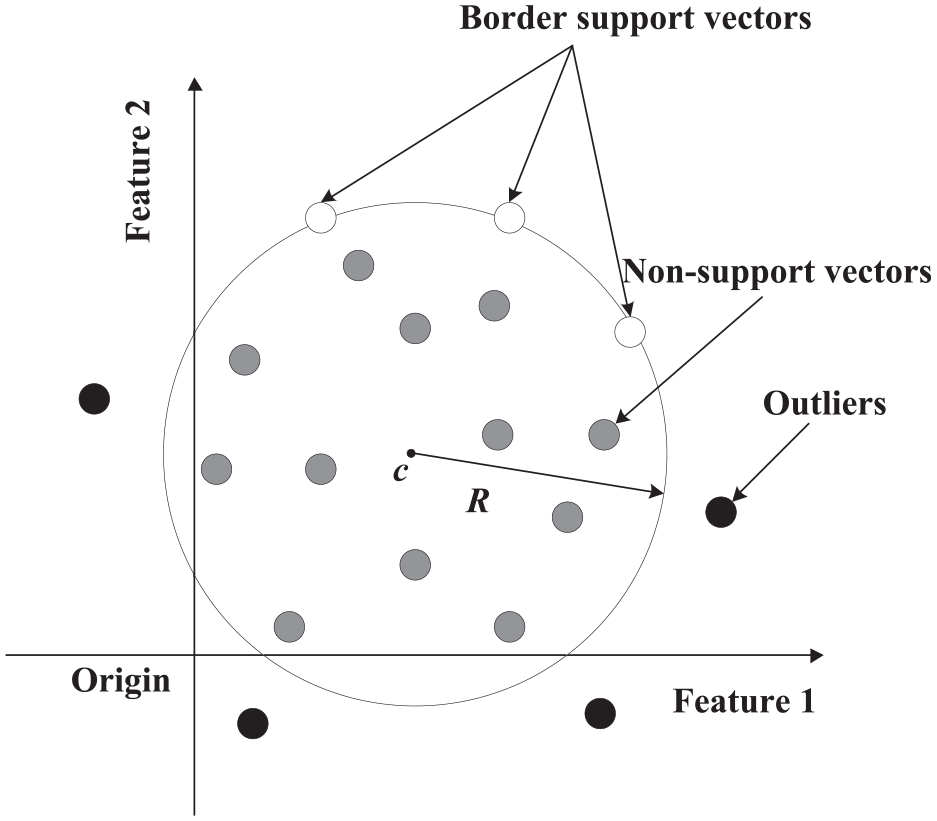
Geometry of hypersphere-based OCSVM.
As indicated in Figure 2,

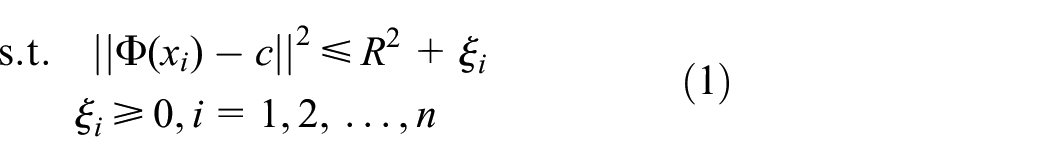
here,
By introducing the Lagrange multipliers, the programming problem displayed in equation (1) can be transformed into the following dual problem


here,

where radius R is the distance between the border support vector and the center of the sphere. When the distance between a data point x and the center of the sphere is greater than
Quarter-sphere one-class SVM
The QSSVM 16 first centers the dataset at the origin in their feature space before modeling a quarter sphere to encompass as many data points as possible. By doing this, it can convert the quadratic optimization problem of equation (2) to a linear optimization problem. The geometry of the QSSVM is displayed in Figure 3.

Geometry of the hypersphere-based QSSVM.
In Figure 3, R is the radius of the modeled quarter-sphere surface, which encompasses the majority of the data points in the feature space. Thus, the optimization problem of a QSSVM classifier is formalized as follows


We also employ the Lagrange multiplier method to solve the formulation of equation (4). Then, the dual problem of equation (4) can be formulated as


If a distance-based kernel is used when solving equation (5), such as the radial basis function (RBF) kernel, the inner products of the mapped data vectors (i.e.

Then, the centered kernel matrix

where
After centering the kernel matrix in the feature space, the norms of the kernel are no longer equal and
After solving equation (5), data instances can be classified by their corresponding Lagrange multipliers:
Characteristics of data vectors reduced by DBN
The data collected by sensors is becoming increasingly high-dimensional, making outlier detection a challenge. We downloaded four real datasets from the UCI datasets. 23 The four datasets include gas sensor array drift (GAS) with 128 dimensions, human activity recognition (HAR) using the smartphone with 561 dimensions, daily and sports activities (DSA) with 315 dimensions, and forest cover type (FCT) with 54 dimensions. We randomly mixed 5% stochastic anomalies with these four datasets (the detailed method is described in section “Datasets”) and compressed them by DBN. The compressed data vectors of the four datasets are plotted in Figure 4. For convenience, we only plot the distributions of two dimensions.

Distributions of features extracted by DBN: (a) GAS, (b) HAR, (c) DSA, and (d) FCT.
After the dimensionality reduction, two phenomena emerge as follows:
Outliers are typically asymmetrically distributed, that is, all outliers in the four datasets are distributed on one side of the normal data. As the center of the sphere modeled by the OCSVM is calculated from all of the input data, the one-sided distributed outliers may lead to a biased center. However, the QSSVM fixes the center to the origin and maps the data to the quarter-sphere space. As the QSSVM considers the data instances that are close to the origin as normal, it performs effectively on the datasets with one-sided outliers.
After the dimensionality reduction by DBN, a clearer separation appears between the normal records and outliers, especially for the GAS and FCT datasets, which has also been demonstrated by Erfani et al. 15 As a result, the new method online QSSVM (OQSSVM) can be modeled in the input space after a dimensionality reduction of the data, to avoid the calculation of a highly complex kernel function in the feature space.
In summary, it is appropriate to model the QSSVM in the input space to perform outlier detection on the datasets that have been compressed by DBN. In the following sections, we will combine DBN with an online QSSVM model, which can accurately and efficiently detect large-scale and high-dimensional outliers in an online manner.
Fast outlier detection algorithm forhigh-dimensional sensor data
In this section, we first introduce an overview of our DBN-OQSSVM method. Then, we specifically introduce the OQSSVM model, including an efficient model training strategy to learn the optimal radius of the model and an online model testing strategy to detect outliers.
Method overview
Combining the functional characteristics of the DBN model and OQSSVM, we propose a new hybrid model DBN-OQSSVM for outlier detection. The DBN part consists of several RBMs, as indicated in Figure 5. The raw data are input into DBN, and the output of the DBN is used as an input for the OQSSVM. In the hybrid model, DBN is used as a dimensionality reduction tool to transform the data from high- to low-dimensional space, and OQSSVM is utilized as an outlier detection tool to identify outliers in large-scale datasets using a sorting method instead of solving an optimization problem.

DBN-OQSSVM hybrid model.
There are two main advantages of using the DBN to preprocess the raw data: (1) the DBN can increase the disparity between the outliers and normal records 15 (also verified by our experimental results); and (2) the computational complexity can be significantly reduced when the dimensions of the input data are reduced.
The model training and testing processes are shown in Figure 6. For the training stage, we first use the training dataset to train the DBN model, and then we obtain the trained DBN model as well as the compressed vectors of the training set. We use the compressed vectors to train the OQSSVM model, and finally, we obtain the radius of the quarter sphere by a sorting method. For the testing stage, we first reduce the dimensions of the testing dataset using the trained DBN model, and then we identify the outliers through a decision function.

Model training and testing for DBN-OQSSVM.
Online quarter-sphere one-class SVM
In this section, we introduce our OQSSVM method that can efficiently and accurately perform outlier detection after the dataset has been compressed by DBN. The OQSSVM model improves the original QSSVM model by much efficient model training as well as online model testing.
Efficient model training in input space
To reduce the computational time and space, we first introduce Theorem 1, 24 and then propose Theorem 2 to efficiently obtain the radius of the quarter sphere.
We use

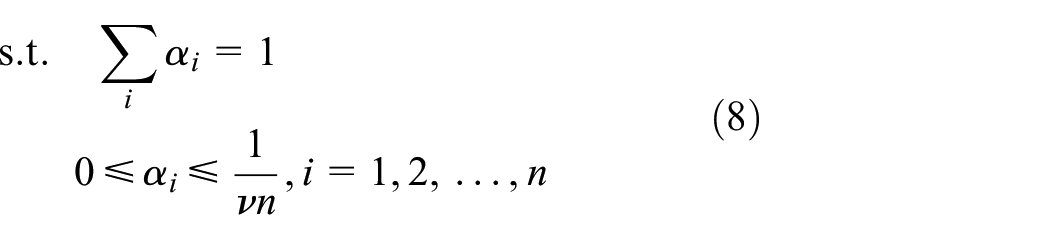
Theorem 1
The square of the radius R for the quarter sphere obtained by solving equation (8) equals

Proof
Refer to the proof in the literature. 24 □
As the DBN can separate most outliers from the normals in the input space, we model the quarter sphere in the input space, avoiding the computation of a large-scale kernel function. First, definitions for the model are provided and a theorem to rapidly train the model is then proposed.
Definitions
Let
Theorem 2
For the training set

Proof
As the OQSSVM fixes the center of the data on the origin, all training data will be centralized around the center,


Thus, the dual problem for equation (11) can be formulated by

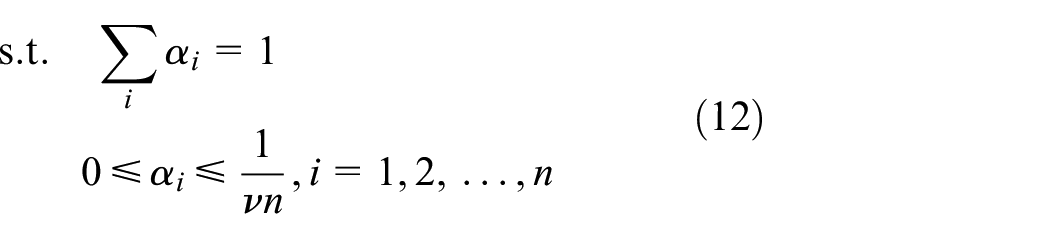
After sorting
Based on Theorem 2, the training process for the DBN-OQSSVM can be dramatically simplified. The pseudo-code of the model training is presented in Algorithm 1. It inputs a historic dataset

Online model testing
To efficiently perform the outlier detection in an online manner, a decision function is designed to determine whether the newly arriving data,

and then determine the state of

where
Algorithm 2 presents the pseudo-code for the online detection algorithm DBN-OQSSVM. It inputs the new arriving data

The complete algorithm details
The pseudo-code of the complete outlier detection algorithm is presented in Algorithm 3. It inputs a training dataset

Evaluation
In this section, we compare the performance of our method DBN-OQSSVM with DBN-OCSVM, 15 DBN-QSSVM, and iForest 18 through extensive experiments.
Competitors
DBN-OCSVM
DBN-OCSVM 15 first compresses the raw data by DBN and then models the surface of a minimum hypersphere which can encompass as many instances as possible in the feature space. Instances outside the border are identified as outliers.
DBN-QSSVM
DBN-QSSVM first compresses the raw data by DBN as well. Then, the compressed data are centered at the origin in their feature space. Finally, the surface of a minimum quarter hypersphere is modeled, which can encompass the majority of the centered instances.
IForest
iForest 18 is an isolation-based outlier detection method. It randomly partitions all instances recursively to generate a binary tree. Outliers are expected to be isolated closer to the root. As the isolation does not require any distance or density measures, it avoids the optimization problem with high computational complexity. However, since each partition is randomly generated, individual trees are generated with different sets of partitions. It generally needs to generate abundant trees to converge the path lengths of each instance.
Datasets
In our experiments, We used four different types of real datasets from the UCI Machine Learning Repository 23 to verify the performance of the four methods, including a GAS with 128 dimensions, HAR using smartphones with 561 dimensions, DSA with 315 dimensions, and FCT with 54 dimensions. The GAS dataset is collected by 16 chemical sensors, each of which records 8 features, including steady-state feature, the exponential moving average, and transformation of feature sets. The data records in HAR are obtained from accelerometer and gyroscope three-axial raw signals. For each signal, the HAR database records its characteristics such as the mean value, standard deviation, signal magnitude area, and signal entropy. The DSA dataset records the motion sensor data of 19 DSA, including sitting, standing, lying on the back and on the right side, ascending and descending stairs, and standing in an elevator still. The FCT dataset records the environmental features of forests, including elevation, aspect, slope, and horizontal. For all of the datasets, we selected 5000–50,000 consecutive records; 80% for the training data and the remaining 20% for the testing data.
By referring to the experimental settings in Erfani et al., 15 we normalized all datasets in the range [0,1], and then randomly select 5% and 10% records in training and testing sets, respectively. For each selected record, we replaced it with a random value drawn from the uniform distribution function U(0,1) to simulate an outlier.
Metrics
The four methods are evaluated using two metrics:
Area under the curve (AUC): AUC is the area under the receiver operating characteristic (ROC) curve, indicating the overall accuracy of a classification method.
Computational time: the training time is the period starting from an algorithm inputting the training dataset and the necessary parameters until the trained model is output. The testing time is the period starting from an algorithm inputting the testing dataset until the testing results are output. QSSVM is an offline method whose training and testing processes can only be implemented simultaneously. We only record the overall time of QSSVM. Because algorithms for DBN-OCSVM, DBN-QSSVM, and DBN-OQSSVM cost the same amount of time on the DBN training and testing, we only record the time required for the SVM training and testing.
Model settings
When comparing the three methods of DBN-OQSSVM, DBN-QSSVM, and DBN-OCSVM, the structure of DBN (including the number of epochs, units on the hidden layers, and learning rate) was set based on the best performance of the three methods.
25
For the FCT and GAS datasets, the OCSVM and QSSVM have a similar accuracy under the linear kernel and RBF kernel. As the linear kernel is much more efficient compared to the RBF,
24
we apply a linear kernel to the OCSVM and QSSVM for the FCT and GAS datasets. However, for HAR and DSA, the accuracy of OCSVM and QSSVM can be notably improved by RBF kernel. Therefore, we use RBF kernel in the OCSVM and QSSVM on HAR and DSA. Because the predefined outlier ratio,
For the iForest method, we set the subsample size to 256 and the number of trees to 100 based on its best performance in terms of efficiency and accuracy. The results presented in the following sections were averaged over 100 executions. All methods were implemented with MATLAB 2017a, running on a server with a quad-core CPU at 1.90 GHz and 32GB RAM.
Results
Overall performance
Table 1 displays the AUC, training, and testing times for the four methods on different datasets. In the table,
Overall performance results.

DBN: deep belief network; SVM: support vector machine; GAS: gas sensor array drift; HAR: human activity recognition; DSA: daily and sports activities; FCT: forest cover type; AUC: area under the curve; QSSVM: quarter-sphere SVM; OCSVM: one-class support vector machine.
The bold values highlight the comparison on method accuracy.
Sensitivity test on DBN structure
To verify the performance of our method under different DBN structures, we vary the number of hidden-layer units as well as the output-layer units (i.e. the dimension for the compressed data) in our experiments. The hidden layer varies from 20 to 38 and the output layer varies from 2 to 10. From Figure 7, the structure of DBN seems not to influence the accuracy of our method much. More specifically, as the number of hidden-layer units changes, the change in the AUC is no more than 0.32%; as the number of output-layer units changes, the change in the AUC is no more than 0.46%.

AUC for DBN-OQSSVM over different DBN structures: (a) GAS, (b) HAR, (c) DSA, and (d) FCT.
Sensitivity test on
The AUCs of the three algorithms under different

AUC for three algorithms over different
Scalability test
Figure 9 compares the overall computing time (averaged over the four datasets) of the four methods on different scales of datasets. From the figure, the time of the DBN-OQSSVM is considerably less than those of the DBN-OCSVM, DBN-QSSVM, and iForest by up to three orders of magnitude. Even for the dataset with 50,000 records, DBN-OQSSVM only requires less than 10−3 second to output the outliers, while DBN-OCSVM and DBN-QSSVM require close to 10 s and iForest requires about 3 s. This is because, during the training phase, the radius of the OQSSVM is obtained by sorting, whereas both the OCSVM and QSSVM compute the radius by solving an optimization problem. In the testing phase, the decision function of equation (14) in our method only requires the inner product, whereas the decision function of equation (3) in DBN-OCSVM method requires the computation of the high-dimensional kernels. iForest needs to construct 100 binary trees to obtain the average length of paths for each instance. The testing data needs to traverse each of the trees as well to obtain its average height. The results in Figure 9 also demonstrate that compared to the competitors, our method is more appropriate for large-scale datasets.
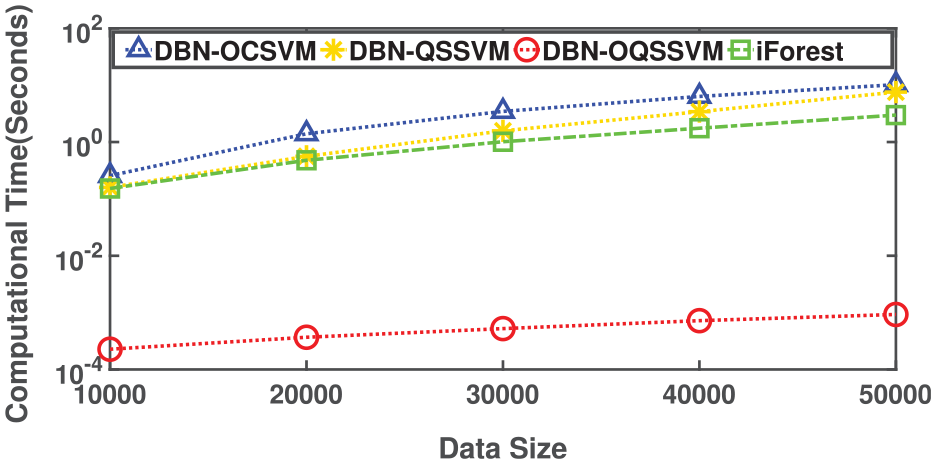
Computational time of the four methods under different dataset scales.
Conclusion
In this article, we proposed a fast outlier detection method DBN-OQSSVM for high-dimensional and large-scale data collected by WSNs. The method DBN-OQSSVM first reduces the dimension of the observations by the DBN. It then fixes the center of the datasets to the origin in the input space and calculates the radius of the quarter sphere using a sorting method. Finally, based on the learned radius, outlier detection is performed in an online fashion. We compared our method with three competitors through extensive experiments on four real WSN datasets. The experimental results strongly confirm the satisfactory performance of our method.
Footnotes
Handling Editor: Olivier Berder
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Natural Science Foundation of China (Nos 61402013 and 31671589), Anhui Provincial Natural Science Foundation (No. 2008 085MF203), and the Open Foundation of State Key Laboratory of Networking and Switching Technology (No. SKLNST-2018-1-10).