
Abstract
In video surveillance, person tracking is considered as challenging task. Numerous computer vision, machine and deep learning–based techniques have been developed in recent years. Majority of these techniques are based on frontal view images/video sequences. The advancement of convolutional neural network reforms the way of object tracking. The network layers of convolutional neural network models trained on a number of images or video sequences improve speed and accuracy of object tracking. In this work, the generalization performance of existing pre-trained deep learning models have investigated for overhead view person detection and tracking, under different experimental conditions. The object tracking method Generic Object Tracking Using Regression Networks (GOTURN) which has been yielding outstanding tracking results in recent years is explored for person tracking using overhead views. This work mainly focused on overhead view person tracking using Faster region convolutional neural network (Faster-RCNN) in combination with GOTURN architecture. In this way, the person is first identified in overhead view video sequences and then tracked using a GOTURN tracking algorithm. Faster-RCNN detection model achieved the true detection rate ranging from 90% to 93% with a minimum false detection rate up to 0.5%. The GOTURN tracking algorithm achieved similar results with the success rate ranging from 90% to 94%. Finally, the discussion is made on output results along with future direction.
Keywords
Introduction
Nowadays, convolutional neural network (CNN)-based models achieve remarkable success, particularly in the area of pattern recognition, image processing, remote sensing, data classification, computer vision, and smart surveillance analysis (specifically in object detection, tracking, and recognition). Person tracking is used for analysis of the target trajectory of person in video sequences. It is considered important because of its wide applications in numerous research areas, covering unusual event detection, fall detection in elderly humans, congestion or crowd locality evaluation, human–computer interaction, robot navigation, and so on.
Person tracking is a challenging task, as the person is a deformable object and has variation in appearance, pose, scale, and size. Various person tracking methods have been developed by researchers, 1 which have shown good tracking results for normal frontal view images and video sequences. There are a number of factors which may affect the accuracy of different tracking algorithms, including variations in illumination conditions, complex backgrounds, cluttered scenes, abrupt motion, shadows, deformable nature of the person (scale and size variations), close interaction of peoples, camera perspective view, and occlusion as in Figure 1. As per first row sample images, the person shape and size are varied with respect to camera distance. The person visibility is also affected because of other person or object (occlusion), and close interaction between two persons may cause hurdles during tracking.

To overcome the problem of occlusion and better scene visibility, some researchers4,7–9 suggested and considered overhead/top view for person tracking and detection. The change in scene visualization due to camera perspective is highlighted in Figure 1. In case of overhead view as shown in sample images (d), (e), and (f) of Figure 1, the object appearance, visibility, and pose are significantly different from the frontal view as shown in Figure 1(a)–(c). The appearance of a person is considerably affected depending upon the location of the person with respect to the camera position. Moreover, overhead view camera covers a wide field of view and provides better visibility of scenes. Using single overhead camera may provide an efficient solution for saving energy consumption, human resource, and installation costs. 10
In this work, overhead view person tracking is performed using CNN-based detection and tracking models. For overhead person tracking, Generic Object Tracking Using Regression Networks (GOTURN) algorithm 11 is used which takes advantage of the CNN architecture to track the object in a video sequence with high accuracy and speed. To detect or identify the object (person), Faster region convolutional neural network (Faster-RCNN) 12 is combined with a GOTURN tracking algorithm. In this way, the object (person) is first detected using Faster-RCNN and tracked using the GOTURN algorithm in overhead view video sequences. The GOTURN and Faster-RCNN models were pre-trained using normal frontal view data set, while for testing purpose, the overhead view person data set is used. The present article mainly focuses on the following:
Performing overhead view person tracking using GOTURN tracking algorithm combined with the Faster-RCNN detection model.
For testing purpose, overhead view person data set is used, containing video sequences having variation in person appearance (including a variety of poses, shapes, and scales of person) and different camera resolutions with indoor and outdoor backgrounds.
To show the generalization performance of GOTURN and Faster-RCNN (pre-trained using normal or frontal view data set), testing is performed on a completely different data set, that is overhead view person data set.
Importance of the CNN-based overhead view person tracking model is explored in contrast with conventional frontal view, particularly in the field of video surveillance. Insight discussion is made to understand the importance of CNN-based overhead view person tracking with future guidelines.
A brief review of different tracking methods, including traditional and deep learning–based techniques, is provided in the “Literature review” section. The overhead view data set is briefly discussed in the “Data set” section. The overhead view person tracking model using GOTURN along Faster-RCNN is elaborated in the successive section. Detailed explanation of output results and performance evaluation is provided in the “Experimental results” section, and finally, the “Conclusion” section concludes the discussed work.
Literature review
This section provides a brief summary of different tracking algorithms used in literature. The section is categorized into traditional generic, machine learning, features, and deep learning–based methods. A comprehensive survey of different tracking methods can be found in previous studies.1,13,14
The key purpose of tracking techniques are to detect objects in a video sequence and sustain the tracking information in the successive frames to find trajectories of each detected object. Conventional techniques are usually based on motion- and observation-based models. The motion model involves the detection and prediction of object position in successive frames,15,16 while the observational model focused on tracked object appearance and its position across the frame. 17 Some researchers 18 used the template-based method for object tracking. Numerous researchers utilized machine learning–based methods for object tracking, which classifies 19 the tracked object such as boosting, 20 random forest, 21 Hough forest, 22 structural learning, 20 and support vector machine (SVM). 7 Some proposed feature-based tracking methods such as Haar-like features, 23 local binary pattern (LBP), 24 histogram of oriented gradient (HoG),25,26 scale-invariant feature transform (SFIT), 27 discrete cosine transform (DCT),28,29 and shape features. 30 Other techniques employed Kalman filters or Hungarian algorithm. 31
To improve the performance of tracking methods, different researchers 32 combined multiple cues information and presented methods for object tracking which combines feature-based detector with the probabilistic segmentation method. Majority of these methods are mainly developed for frontal view data set which may suffer from occlusion problems. To overcome the occlusion problem, Ahmad et al. 33 considered overhead view scene for person detection using the background subtraction method. Ahmed et al. 8 proposed a feature-based solution for person tracking in the top view industrial environment. Ullah et al. 34 provided a comparison of different traditional tracking algorithms using the overhead view data set. A rotation invariant solution 9 is also presented for top view person tracking.
Because of recent advancement in deep learning methods such as object detection5,12,35–37 and image classification,38–41 deep learning models are now also being used in object tracking tasks. Specifically, a popular paradigm tracking by detection is used to solve the tracking problem.42–44 Such type of models generally used a detector to first detect the object and then subsequently a tracker is initialized to track the detected object.
Some approaches used for object tracking by detection are based on a calculation of bounding boxes in successive frames via Intersection over Union (IoU). 45 Various methods are based on recurrent neural networks (RNNs)46,47 or Siamese convolutional networks architectures. 48 Most of the developed methods mainly used frontal view data set. Some of the researchers developed object tracking method,49–52 but they use aerial or remote sensing images. Few used deep learning for detection and counting of person in the overhead view.53–55 In this work, the CNN-based model is used for overhead view person tracking in different indoor and outdoor environments. Using the overhead view, different problems faced during frontal view data set as discussed in the “Introduction” section may be overcome.
Data set
In this work, overhead view person data set is used, containing video sequences of person against completely different backgrounds and illumination conditions. The setup consists of a single overhead view camera which captures/records video sequences at 20 frames per second, during different day timings in different scenes. The recorded data set covers wide variety in person appearance, pose, scale, size, and orientation with respect to the camera position as depicted in Figures 5–7. From the sample frames, it can be observed that from the overhead perspective, the person appearance is totally different than frontal. The recording of the data set has been made using different camera devices and camera resolutions elaborated in Table 1. As a person is an important object in video surveillance, the data set contains person video sequences. Table 1 provides the detailed description of the data set used in this work.
Overhead view person data set.

Overhead view person detection and tracking framework
In this section, overhead view person tracking framework shown in Figure 2 is discussed. The overall framework consists of person detection and person tracking modules. In person detection module, the video sequences are converted into video frames, given to the Faster-RCNN 12 model, which detects and identifies the person in overhead view video frames. In recent years, Faster-RCNN has shown excellent performance in various applications. It uses the same conventional network for object detection and region proposal generation which make it faster as compared to other region proposal network (RPN) models such as RCNN 56 and Faster-RCNN. 35 Therefore, for overhead view person detection, Faster-RCNN is chosen with Resnet-101 as depicted in Figure 2. The detection model output comprises a bounding box (containing detected person, label, and a confidence score).

General framework of overhead view person tracking using Faster-RCNN detection model combined with GOTURN tracking architecture.
The Faster-RCNN model is further combined with GOTURN 11 tracking architecture, which is also based on convolutions neural network layers. The detected information (containing bounding box, label, and a confidence score) is given to person tracking module. The tracking module takes the detected information and creates a list for person tracking. If the frames contain the person, the tracker starts tracking with continuously updating the tracker list information and displays person with tracking ID, otherwise it stops tracking. The following subsection explains the detection and tracking modules shown in Figure 2.
Person detection
With advancement in CNN, object detection is also gaining attention of researchers by providing an efficient solution for many object classification and detection problems in terms of speed and computation. In this work, Faster-RCNN 12 is employed for person detection using overhead view video frames as shown in Figure 3. Faster-RCNN mainly has two stages, first stage produces region anchors (regions having high probability about occurrence of the object (person)) via RPN. The next stage classifies object (person) using detected regions and extracts bounding box information. The process shown in Figure 3 is further divided into the following three steps:
Using convolution layers, feature extraction is performed and convolution feature map is generated at the end.
In the second step, anchor boxes are generated using the sliding window approach, which are further refined to specify the presence of an object (person).
In the last step, using a small network, anchors are refined and the loss function is calculated which selects best anchor regions in overhead view images containing object (person).

Complete framework diagram for overhead view person detection using Faster-RCNN. 12
In Figure 3, it can be seen that overhead person frames are fed into the conventional layers, which generates feature maps that is the pre-requisite step for RPN. For feature extraction in overhead view images, Resnet-101 57 based model is used as backbone which contains 30 CNN layers. It has special residual connections in-between layers which helps to learn intermediate, local, and global features, making it effective in comparison with other CNN-based models.
There are different types of Resnet connections (for details, readers are referred to He et al.
57
). In the next step, sliding window approach is used for generation of region proposal. To produce region anchors, window size
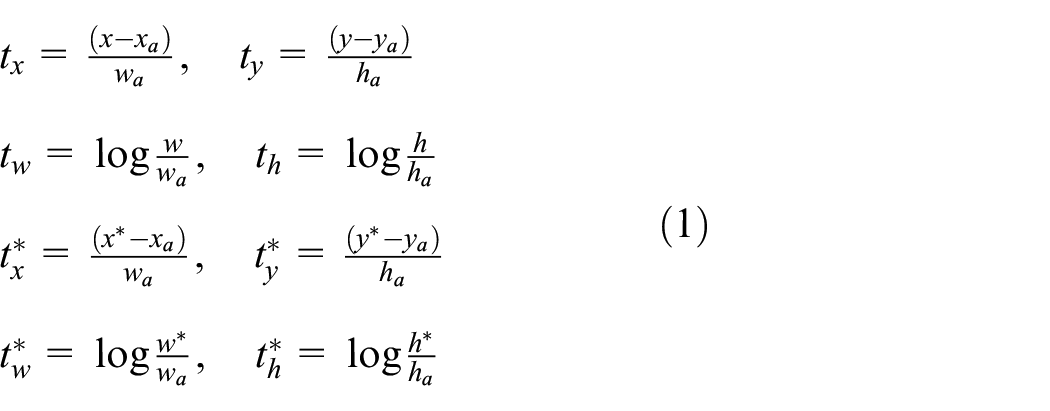
In equation 1, bounding box central coordinates are denoted by

After selection of anchor regions, loss function is used for fine tuning at the end of RPN. A network is used for binary classification to classify the detected object as no person (simply background) or person. The regression function is applied to determine the positions of the predicted bounding box using four coordinates
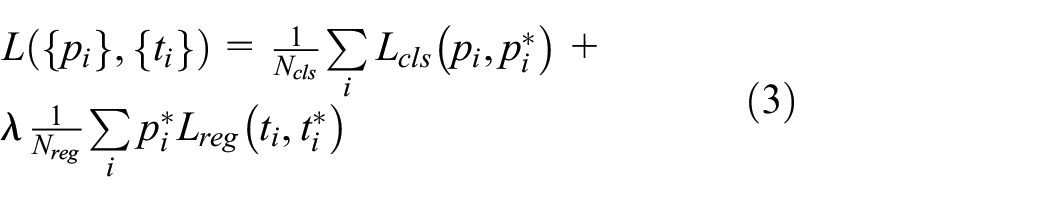
The above equation is used for calculation of classification and regression loss of detected bounding box.
Now, the same size feature maps or ROIs are extracted from the ROI pooling layer. The feature maps are once again used for classification and regression. It involves two steps: in the first step, the calculation of bounding box classification and regression is made, for optimization of the loss function. At the second stage, classification shows the results of detected person class score and regression shows the resized bounding box with values
Person tracking
In this section, overhead view person tracking module is briefly discussed. For tracking purpose, GOTURN 11 is used which is based on CNN layer architecture. The GOTURN architecture is fundamentally trained on thousands of cropped frames (mainly frontal view video sequences). 11 In the first frame, the location of the known ROI (person) is cropped. The cropped ROI is two times the detected bounding box, and location of the each detected ROI in the next frame is predicted as seen in Figure 4. The same information of bounding box is used to crop the person or ROI in the second frame. In the second frame, to predict bounding box location, CNN is used. The main architecture is similar to that of the Siamese CNN model 48 (trained using frontal view data set), which is used for object tracking at high speeds. The flow diagram of GOTURN architecture used for overhead view person tracking is explained using Figure 4. The GOTURN tracker takes the detected bounding box information from the first frame, and pass it through the set of convolution layers. The convolution layers are further concatenated with fully connected layers. In the next successive frame, the same detected bounding box or ROI information is used to initialize the tracker. The output of the Figure 4 is the tracked person from the overhead view. The general architecture of GOTURN model is explained in the following steps:
The original network was entirely trained on frontal view video sequences/images. It learns the genetic relationship of the object appearance and motion.
48
At each training iteration, this relationship was learned by convolution network using the contextual information of the object, and it takes two inputs from the frame: crop bounding box of the previous frame at time
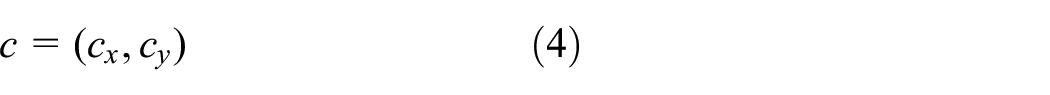
In the second frame, the same object bounding box information which needs to be searched and tracked and called target object is used by next successive frames. The bounding box width and height are automatically adjusted by the tracking algorithm according to the detecting person bounding box information as shown in Figure 4. In original algorithm, it is usually centered at the same point
The input of the detection model passes through a set of convolutional layers of tracking algorithm, and the first five layers are based on CaffeNet architecture, 59 whereas the output convolutional layers (i.e. the pool5 features) are concatenated in one vector form with length of 4096 nodes. 11 These layers are further input to three fully connected layers. Finally, the fully convolution layer is associated with the output layer, includes four nodes representing the bottom and top coordinates of the tracking bounding box (see Figure 4).
A condition is defined for tracking the person in the overhead view input frames: If the target person does not move too rapidly, then the target will be scaled in the present search area. Therefore, the network estimates four coordinates of bounding box directly containing tracked person in search area for the next frame. To initialize and preserve the tracker, the following rules are needed: The tracker is initialized for first detection information received from the person detection module. This detection information is fed into the tracker and target person is defined as shown in Figure 4 If the detection information in the object list is greater than zero, the tracker is initialized. For next input, the previous frame (at time To ensure that tracker does not lose the target, in successive frames, the detection information is checked for at least 10 frames. Furthermore, the results are compared using The predicted track bounding box is then swapped with the predicted detecting bounding box to improve the accuracy. When an object is detected in the field of view, it is tracked by the tracker, however, not be tracked whenever it leaves the field of view. The algorithms stop tracking an object when they do not receive any detection in the successive frames.
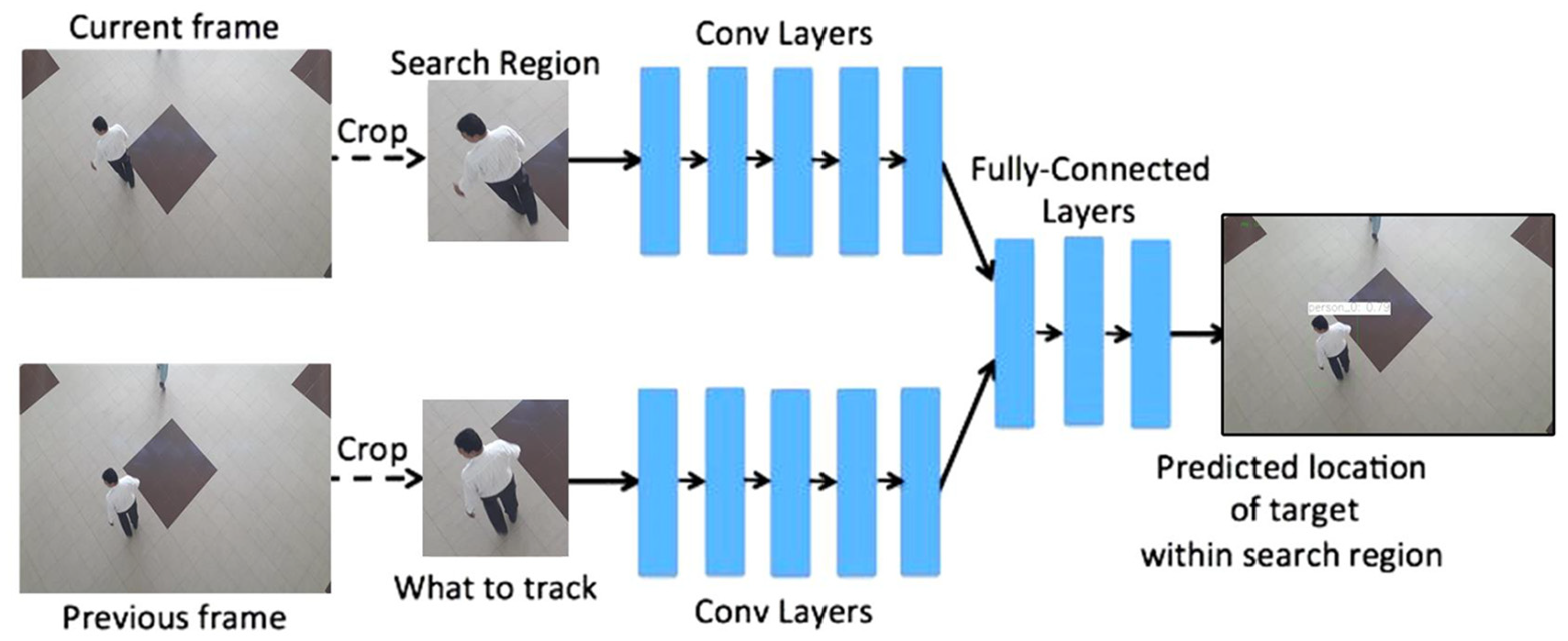
General architecture of GOTURN tracker. 11
Experimental results
This section provides a detailed summary of experimental results using Faster-RCNN and the GOTURN model for overhead view person detection and tracking. Both models are implemented using OpenCV. The experimental results of person detection and tracking from the overhead view using different scenes with variation in background, illumination condition, person appearance (height, pose, angles, scale, and size), camera resolution, and aspect ratio are visualized in Figures 5–7. The first two scenes shown in Figures 5 and 6 mainly contain frames of the person captured from the complete overhead view (symmetric) where the person is considered below the camera in indoor and outdoor environments. As in video surveillance, the main focus is to track the person, so in almost all scenes, our focused ROI is a person. In Figure 5, the tracking and detection results of GOTURN and Faster-RCNN for overhead view person sample frames for indoor environment are depicted. In the sample images, the camera perspective is completely different than the frontal view, but still, the models perform well and give a good detection and tracking results. The green bounding box in the sample frames represents the detected bounding box along with its class label (person) and confidence score which is almost 80% in most of the time. The tracking ID can also be seen, as there is only one person in the video sequence, so ID 0 is assigned to the target person. Furthermore, during the sequence, if the same object is detected, the tracking algorithms continue tracking the object with the same tracking ID (Figure 5). Figure 6 demonstrates the overhead view person tracking and detection results for outdoor environment. The sample frames contain the results of person detection and tracking at different locations of the outdoor scene. It can be seen that the appearance of the person is significantly different in each sample frame with reference to the camera position. The person’s lower body is occluded below the camera, but still, the model detects the person, classifies it to its label class, and gives good tracking results.

Testing results of person detection and tracking using Faster-RCNN and GOTURN, in an indoor environment covering the symmetric overhead view.

Testing results of person detection and tracking using Faster-RCNN and GOTURN, in an outdoor environment covering symmetric overhead view.

Testing results of person detection and tracking using Faster-RCNN and GOTURN, in an outdoor environment covering both symmetric and asymmetric overhead view.
Similarly, the models are also tested for sample frames of person against different backgrounds covering both symmetric and asymmetric overhead view in indoor and outdoor environments as shown in Figure 7. The tracking ID for multiple persons can also be seen, as there are multiple persons in scene; therefore, unique IDs are assigned, which are further used for tracking the person in successive frames. In Figure 7, the sample frames used for testing are completely different from trained models, but still, the above discussed models achieve good results while detecting and tracking person from symmetric and asymmetric overhead views for variety of backgrounds. In Figure 7, the first row indicated the results for the symmetric overhead view, although the persons are too close, but still, the tracking and a detection model achieves good results. Along with good detection results, some false detection and not-detected results are also reported. As in Figure 7, the red detected box indicates not-detected results. The reason might be the complete change in appearance (size, shape, and scale variation) of the person from the overhead view. The overhead view results of person detection and tracking models for outdoor and indoor asymmetric environment are visualized in the second row of Figure 7.
The performance of detection and tracking models are assessed using the true detection rate (TDR) and false detection rate (FDR). For tracking purposes, the accuracy and success rate has been calculated. Table 2 demonstrates the detection results for overhead view person sample frames. The detection model achieves good results without any additional training. For person sample frames, the Faster-RCNN achieves TDR of 93%. For multiple person images, the TDR is ranging from 91% to 90% depending on illumination, background conditions, and the number of persons within the scene.
Overhead view person detection results.

TDR: true detection rate; FDR: false detection rate.
The tracking accuracy of the GOTURN tracker for overhead view person can be seen in Figure 8. The accuracy has been plotted for different numbers of persons against different outdoor and indoor conditions.
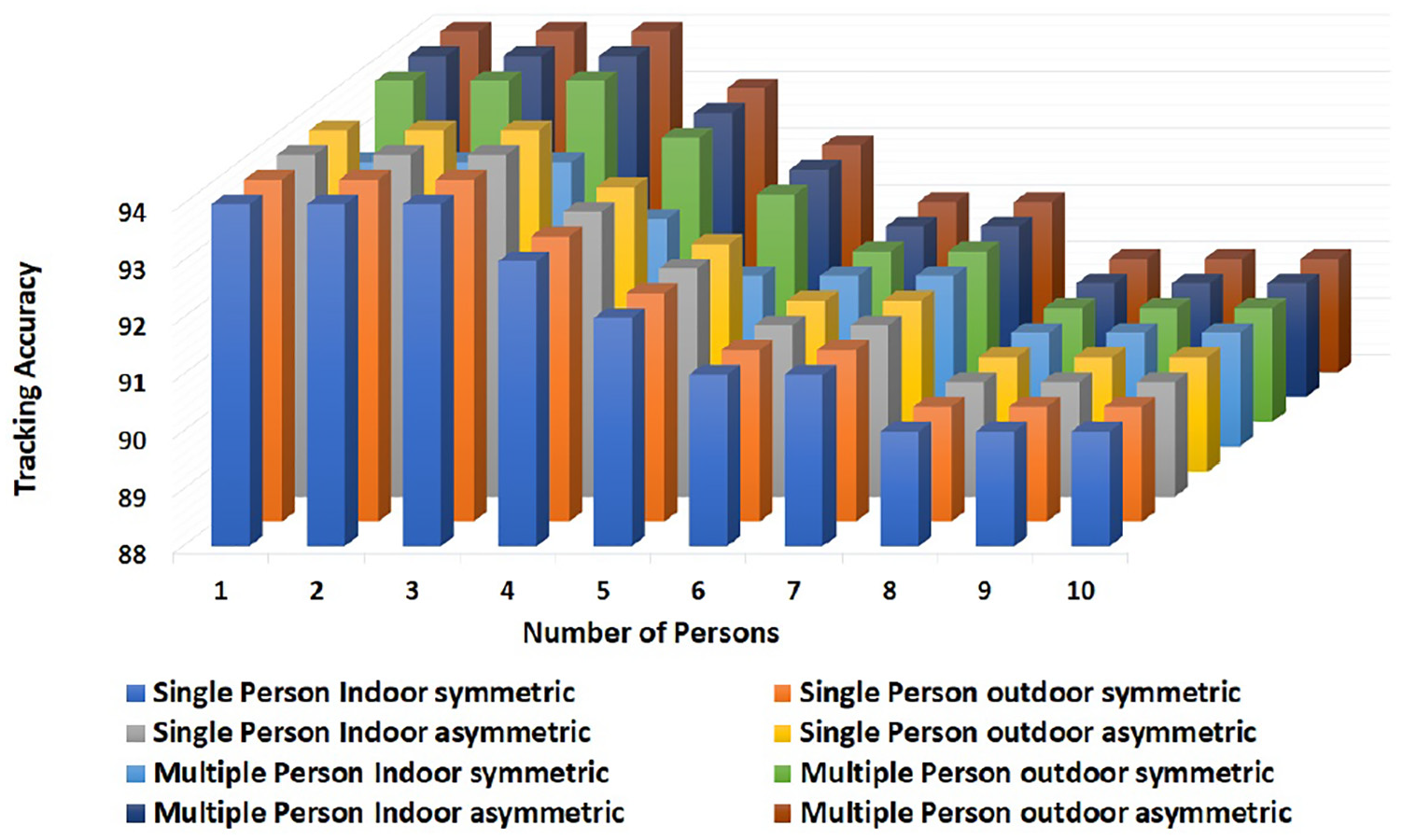
GOTURN tracking accuracy results for overhead view person tracking in different indoor and outdoor environments.
It can be seen that overall performance of the tracking algorithm is good. The accuracy is also computed for multiple persons from the overhead view. Figure 8 illustrates that the algorithm accuracy is slightly effected which depends upon the number of people in the scene. As seen from Figure 7, in case of where the persons are too close to each other, the tracking algorithm is not able to detect and track the person accurately. The GOTURN tracking algorithm results are also compared with those of other conventional tracking algorithms as shown in Figure 9. Multiple instance learning (MIL) tracker is better in accuracy but suffers during reporting failure. Similarly, Kernelized Correlation Filter (KCF) algorithm is faster but does not handle occlusion well. On the other hand, GOTURN algorithm gives good results and better handle changes during tracking (e.g. view point changes, deformation and lighting changes).

Tracking success rate of GOTURN as compared to other traditional tracking algorithms for overhead view multiple person tracking.
Conclusion
In this work, overhead view person tracking is performed using CNN-based object detection model and tracking algorithm. For person detection, Faster-RCNN is used which achieves good detection results for overhead view images. Furthermore, for person tracking, the Faster-RCNN detection model is combined with GOTURN tracking algorithm. The models used in this work were pre-trained on normal frontal view images, while tested on completely different (overhead view person) data set, containing multiple persons against different backgrounds. This work is attempt to combine and used CNN-based models for person tracking and detection using the overhead view. The experimental results demonstrate the robustness and efficiency of CNN-based detection model and tracking algorithm, although there is significant variation in the data set in terms of appearance, visibility, shape, and size of the person in contrast with the normal frontal view. The results prove the performance of tracking algorithm with a success rate of 94% and detection model by achieving a TDR of 90% to 93% with an FDR of 0.5%. In future, this work might be extended by training the models on a suitable overhead view data set.
Footnotes
Acknowledgements
The authors would like to thank the Institute of Management Sciences (IMSciences), Hayatabad, Peshawar, Pakistan, for supporting the technical aspects of this research.
Handling Editor: Manuel Mazzara
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the Deanship of Scientific Research at Princess Nourah Bint Abdulrahman University (PNU), Riyadh, Saudi Arabia, through the Fast-track Research Funding Program.