
Abstract
For the successful operation of smart home environments, it is important to know the state or activity of an occupant. A large number of sensors can be deployed and embedded in places or things. All sensor nodes measure the physical world and send data to the base station for processing. However, the processing of all collected data from every sensor node can consume significant energy and time. In order to enhance the sensor network in smart home applications, we propose the irrelevant data elimination based on k-means clustering algorithm to enhance data aggregation. This approach embeds the cluster head–based algorithm into cluster heads to omit irrelevant data from the base station. The pattern of measured data in each room can be clustered as an active pattern when human activity happens in that room and a stable pattern when human activity does not happen in the room. The irrelevant data elimination based on k-means clustering algorithm approach can reduce 55.94% of the original data with similar results in human activity classification. This study proves that the proposed approach can eliminate meaningless data and intelligently aggregate data by delivering only data from rooms in which human activity likely occurs.
Introduction
The smart home has been of interest to many studies and for many applications, such as automatic controlling appliances and elderly assistance. Smart homes can improve the lives of occupants and the elderly by utilizing ambient sensors to capture the presence and behavior of occupants for active and assisted living (AAL) purposes. A smart home communication system can be divided into an external network, a base station network, and an internal network. 1 This network can be wired or wireless, and the Internet is used to interconnect devices in the home; thus, the smart home is one of the applications of the Internet of things (IoT). Sensors or devices can be placed everywhere, measure the physical world, and then transmit data to the base station by communicating through a network based on the IoT. 2 Gathering huge data in sensor networks can be found in a wide area, such as a smart hospital and smart building. Also, data in smart home have been getting big as a consequence of the increase in intelligent appliances.
The large number of sensors produces a significant amount of data, which leads to concerns about energy consumption for data processing and the transmission of sensors. In addition, a well-designed sensor network must consider various challenges in a smart home, such as privacy and security, 3 data handling and compression, learning, and assessment of an occupant’s behavioral patterns, as well as their home environment. 4 Therefore, an efficient technique is needed to improve the lives of sensors in smart homes to guarantee the sustainable operation of sensor networks. One way to reduce power consumption in a sensor network is to optimize in-network data aggregation in the internal network, which mainly combines with the sensor node and base station. Multiple sensors produce data fusion, including useful and useless data, and a clustering algorithm can be used for efficient data aggregation processing in the sensor network.
An internal communication network comprised a sensor node and a base station. The base station stores data from all sensor nodes and performs management and configuration in the network. Different methods are used to operate the internal communication network between the sensor nodes and a base station to help aggregate data that can improve the lifetime of the network.
Maraiya et al. 5 categorized data aggregation into four approaches based on different methodologies. These approaches include the tree-based approach, cluster-based approach, multipath-based approach, and hybrid-based approach. A similar categorized data aggregation approach, Sirsikar and Anavatti 6 described four strategies consisting of a centralized approach, an in-network approach, a tree-based approach, and a cluster-based approach. The differences of these approaches are as follows: (1) the centralized approach is a simple data aggregation approach, as all sensor nodes send the data to a central node called a header node, and then the header node sends the data packet to a destination node; (2) the in-network aggregation approach gathers data through a multi-hop network and data processing at intermediate nodes in order to reduce power consumption; (3) the tree-based approach considers a sensor network as a tree that consists of sink node as a root and source nodes as leaf nodes, where each node has a parent node to forward its data to the sink node; and (4) the cluster-based approach has several cluster heads that gather data from numerous source nodes under its control and transmit the result to a sink node or the destination.
A cluster-based approach can reduce the bandwidth overhead because of its fewer transmitted data packets. A popular cluster-based approach is the low energy adaptive clustering hierarchy (LEACH). 7 LEACH has inspired other LEACH-based protocols that have attempted to improve the method of cluster head selection, such as EM-LEACH, 8 ESO-LEACH, 9 and LEACH-VA. 10 The fundamental goal of LEACH is to equally distribute energy consumption among the sensors in the network that utilize the randomized rotation of cluster heads. In data transmission, LEACH incorporates data fusion into the routing protocol to reduce the amount of information before transmitting data to the base station. Another cluster-based algorithm is the COUGAR algorithm. COUGAR selects the cluster head based on signal strength and performs in-network aggregation with duplicate sensitive aggregators since it consists of a node synchronization engine, which ensures that data are aggregated correctly. 11 More recent cluster-based algorithms used swarm algorithms for developing cluster selection method. PSO-ECHS is an energy efficient cluster head selection algorithm based on particle swarm optimization (PSO). PSO-based algorithm randomly selects a suitable subset of nodes as CH candidates. PSO-ECHS considers parameters such as intra-cluster distance, sink distance, and residual energy of all the CHs in the fitness function. 12 The grey wolf optimizer (GWO) is a swarm algorithm, which is used to select CHs based on the predicted energy consumption and current residual energy of each node. However, this proposed method may not be suitable for application where the first node dies has a significant effect on performance of the network. 13 A cluster-based approach can be implemented by increasing local data processing to contribute efficient data aggregation to sensor networks.
As the local processor processes data locally, some algorithms can be used to enhance data aggregation before transmitting data to the base station, such as a clustering algorithm. A clustering algorithm can cluster different data patterns from a complete dataset then, unwanted data can be purged to reduce the effect of irrelevant data. Not all measured data can be trusted because data can be false and not all the measured data correlate with the current circumstances due to irrelevant data; eventually, these data can produce false negatives or false positives. In a smart home environment while the occupant is performing an activity in a room, and sensors in other rooms may have active values for many reasons (e.g. the occupant may leave a TV on and go to another room or false data may be transmitted from the sensor).
One of the simplest clustering algorithms is the k-means algorithm, which considers the means of features into k groups based on Euclidean distance. Harb et al. 14 used k-means clustering algorithm to group similar data sets into generated clusters using the KPFF technique. This technique enhanced the prefix frequency filtering (PFF) technique using a k-means-based clustering approach for data aggregation in periodic sensor networks. The same researchers enhanced their previous model based on a one-way analysis of variance (ANOVA) model to identify nodes generated with identical data sets and to aggregate these sets before sending them to the sink, 15 to eliminate redundancy from the sensor node members that generate redundant data sets; Harb and Jaoude 16 presented a similar method of using the k-means algorithm in sensor networks for data compression to handle big data collection.
Idrees et al. 17 proposed a Distributed Data Aggregation–based Modified k-means (DiDAMoK) technique, which uses a modified k-means technique to remove data redundancy in data aggregation and improve the lifetime of a sensor network. Using this technique, a sensor node measures and collects the data. Then, the modified k-means algorithm is employed on the collected data to convert the data into clusters and transmit the collected data for each cluster to the sink.
Rida et al. 18 presented a clustering approach called EK-means for dataset classification in sensor networks with the objective of reducing the amount of transmitted data over a network while preserving their properties. This approach consists of two steps. The first step is to eliminate similar data generated at the sensor level using Euclidean distance based on the data aggregation technique. The second step is to group similar datasets and reduce the amount of data sent to the sink using the EK-means enhanced from the k-means clustering algorithm.
Most researchers used the k-means algorithm to eliminate redundant data in sensor networks because these data provide the ability to group redundant data. However, these approaches cannot remove irrelevant data that has no correlation with the current scenario. In this work, we consider the correlation between the collected data and the current scenario to remove irrelevant data. We aim to enhance efficient data aggregation in a smart home for human activity classification over the lifetime of the network. We focus on data reduction via data fusion among cluster heads in a smart home to reduce the size and members of the data passing through the transmission process in order to apply human activity classification to smart home applications. Based on the challenges above, this article presents a novel approach that uses an algorithm for clustering and decision-making in multi-sensor network system communication.
Here, we propose the irrelevant data elimination based on k-means clustering algorithm (IDEK) for local data processing in cluster heads. These cluster heads are pre-defined and divided based on rooms and could obtain meaningful data from the sensor nodes in the room by utilizing the data and enhanced k-means algorithm to decide whether to transmit the data to a base station as shown in Figure 1(b). The presented approach enables cluster heads to make an intelligent decision about whether to transmit stored data to a base station using an embedded cluster head–based algorithm. The cluster-based sensor network architecture is illustrated in Figure 1(a), where the cluster heads aggregate data from the sensor nodes and transmit those data to a base station by intelligently making a decision based on the patterns of source nodes.
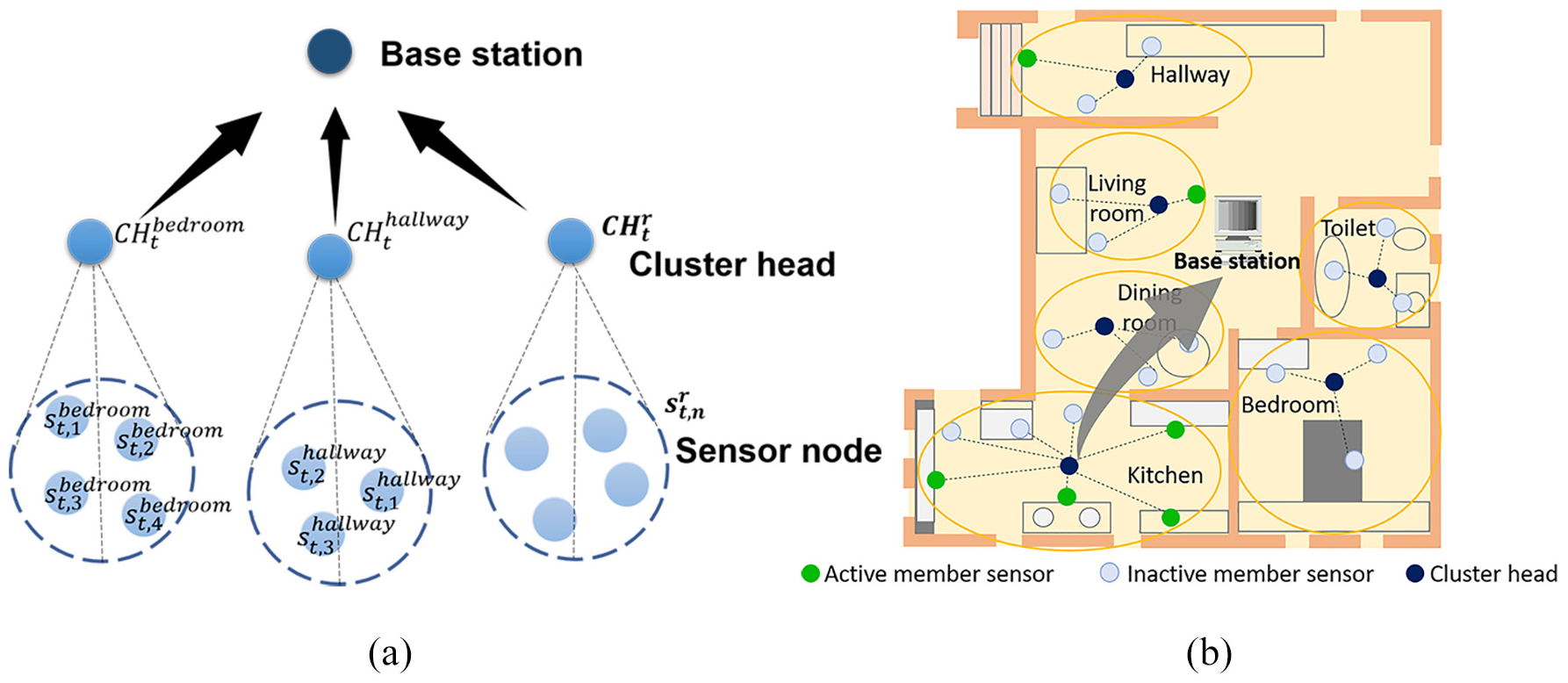
Illustration of cluster-based sensor network: (a) communication architecture and (b) sensor deployment scheme.
The contributions of this work are as follows: (1) efficient data aggregation to reduce energy consumption; (2) IDEK; and (3) human activity classification via ambient sensors in a smart home.
IDEK
This section exhibits the IDEK, which exploits the correlation between measured data from sensors and human activity to reduce the amount of data and save the energy of data transmission to a base station. IDEK is proposed to eliminate irrelevant data aggregation for the objective of human activity classification in a smart home with a hierarchical network structure comprised three levels, as shown in Figure 2. The architecture is designed to suitably embed a cluster head–based algorithm at the cluster head level. Figure 2 explains the IDEK hierarchy, which works alongside the hierarchical network. A cluster head intelligently transmits the measured data from sensor nodes in certain rooms using the IDEK approach. This approach utilizes an embedded cluster head–based algorithm based on the k-means algorithm to cluster data in each CH to decide whether to transmit data during human activities. The transmitted data will be classified according to human activity at the base station level, and then smart home applications can possibly provide a given service to the occupant or elderly. Figure 3 summarizes the procedure of IDEK approach, and we will explain in the detail as below.

Irrelevant data elimination based on k-means algorithm (IDEK) hierarchy.

The procedure of IDEK approach.
Sensor node level
The physical environment and human activities are measured through all embedded sensor nodes in the smart home. The sensor nodes update data at given time intervals as
Cluster head level
We assume that a certain spatial monitoring area, such as a room, is covered by a sensor cluster, and each cluster consists of a single cluster head and several members of sensors. Every cluster head plays the role of aggregator and receives measured data from their descendants placed in the same room.
The cluster head election is based on the highest residual energy and the smallest distance from base station. For long lifetime of sensor networks, sensor node which has the highest residual energy among members will be selected as cluster head and in case all members have the same residual energy, cluster head will be selected based on the smallest distance from base station. There are communications between sensor node and its own cluster head and between cluster head and base station in order to be aware in case any cluster heads die during the processing. The sensor nodes will get a response from its own cluster head in the limit of time if the cluster head completely received the data packets, if not new cluster head will be selected and announce to others. Likewise, the case of base station cannot receive data packets from the cluster head.
These data are aggregated as a

The example of some measured data in the kitchen cluster head.
In order to enhance the ability of a cluster head, the cluster head needs to undergo offline learning from previous datasets before embedding the cluster head–based algorithm in the cluster heads. The clustering algorithm, called CorrKmeans++algorithm 1, is used to cluster the collected data in each cluster head, so the cluster head can decide to transmit aggregated data to the base station when it possibly contains data on the occurrence of an activity. The proposed clustering algorithm utilizes the k-means++algorithm.
19
This algorithm utilizes the complete data of the cluster head

The results of the sensor pattern, which are grouped together and shown as examples in Figure 5, will also be considered for use as a time schedule for data transmission in the cluster head. For long-term usage, the model needs to be retrained when the model detects a change in human behavior, such as activity time duration or activity pattern.

Examples of sensor data in the cluster head in the (a) bedroom and (b) kitchen are grouped with
The problem of clustering the sensor data in the cluster heads is how many

On account of the offline learning, as explained above, we obtain optimal

Base station level
At this level, a base station receives the measured data from every cluster head transmitting data that passes; then, the process of human activity classification is performed on a perceptron classifier using one versus all (OVA) for a multi-class problem via the Scikit-learn framework.
20
The measured data, that were eliminated of irrelevant data at cluster head level, are fed as the input of classifier as shown in Figure 6. Each training point belongs to one of k different classes, and a predicted activity is a maximum output from k different output. The classifier was made using the default parameters, except that


where
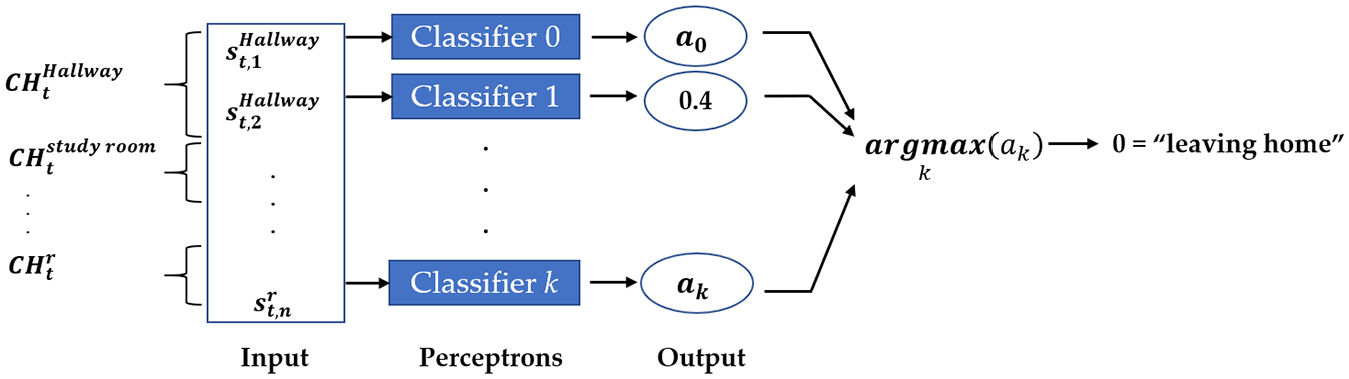
One versus all perceptron classifier.
At this level, the algorithm is able to add a behavioral change detection model to detect when the inhabitant has changed behaviors since this situation will affect the CorrKmeans++algorithm. Our network can undergo offline learning to acquire new information and retrain its human activity classification model.
Simulation set-up
The simulation study was performed to validate our proposed method in a rich-sensor smart home scenario dataset. We designed the simulation in three steps. In this work, we implemented the human activity classifier on a Google Colab environment as shown in Table 1 and simulated with Python. The first step in the simulation is to locally divide the sensor following room functioning and define the fixed cluster head of each as shown in Table 2. Then, enhance the ability of a cluster head through CorrKmeans++algorithm 1 in offline learning. The second step, every cluster head is embedded algorithm 2 to determine the measured data while the activity is happening in the room and while nothing is happening in the room. The last step is to compare the performance of IDEK approach and other approaches described in the “Results” section. The occupants activity classification is used to measure the performance metrics, including the size of the data being communicated and the quality of the data aggregated for human activity classification using the metrics described in the “Results” section.
The simulation set-up.

The choice of options.
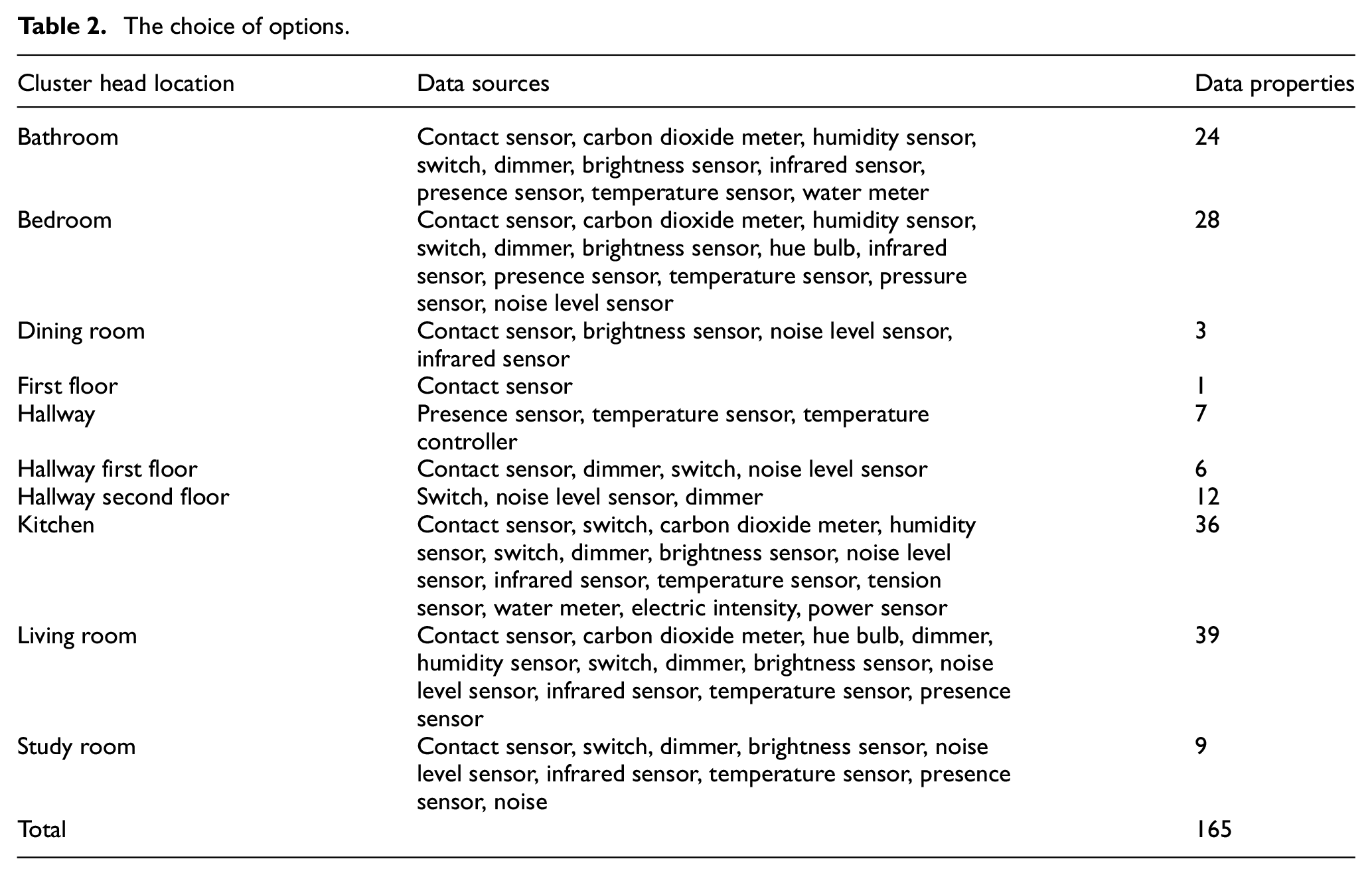
The simulation was processed on the ContextAct@A4H Real-Life dataset from Amiqual4Home 21 which focuses on AAL in a smart home. This dataset describes daily living activities during July 2016 (1 week) and November 2016 (3 weeks) in an apartment equipped with various types of sensors and actuators. All sensors are ambient sensors deployed in a bedroom, bathroom, kitchen, study room, and around hallways. We used the November dataset with 165 data properties from different sensors. We placed 10 cluster heads based on the room, namely the bathroom, bedroom, dining room, first floor, hallway, hallway first floor, hallway second floor, kitchen, living room, and study room. Each cluster head gathers the data properties from sensor nodes.
The dataset is a log dataset of 1,108,617 tuples with 444 tuples of activity annotation (start time and stop time). However, the occupant reported missing some activity annotations. Thus, we only utilized the data that have a labeled stop time for the activity and measured properties for which we could identify the placement of the sensor or the relative room from the dataset description file with 452,245 tuples. We modified the loc dataset with the time series dataset using a 1-min interval, since we set all sensor nodes to transmit data to the cluster head every minute. The modified dataset contains data for 27,339 timestamps, with activity label data for 17,230 timestamps based on the stop time of the activity annotation in the loc dataset. Our model assumes that we are able to perform algorithm 2 processing on the cluster heads. In a practical and simplified way, we can simulate this model on a virtual machine that emulates a Raspberry Pi.
Results
We compared the quality of data aggregation and the size of the dataset being transmitted between the full data transmission approach, the EK-means approach,
18
and our cluster-based data transmission approach. The performance results of the data reduction with the existing aggregation approach, called the EK-means aggregation algorithm at the sensor level, show results with different values for the required parameters, which include the period size of the data represented by point
In the simulation, we can eliminate the irrelevant data by transmitting the measured data following the schedule as shown in Figure 7. The schedule was made from the matching result of the activity and the chosen cluster head transmission. The highest matching scores (

A summary of the sensor patterns grouped and selected for cluster head transmission compared to relevant activity labels (hallway (k = 8, group = 4)—leaving home; study room (k = 2, group = 1)—working; kitchen (k = 2, group = 1)—cooking; kitchen (k = 9, group = 6)—eating; bathroom (k = 6, group = 0)—using the toilet; bathroom (k = 3, group = 0)—washing dishes; bedroom (k = 3, group = 1)—sleeping; and bathroom (k = 2, group = 1)—taking a shower).
We used 17,230 samples, with activity labels available from the time series dataset, to train and test the activity classifier because the dataset cannot be used as it is missing some activity labels. We evaluated the performance using stratified fivefold cross-validation with 90% of training and 10% of testing. Folds were made by preserving the percentage of samples for each class. The result of activity classification was performed on a real-life sensor-rich environmental dataset, which includes a large variety of sensors to avoid the potential reuse of data. This means that our proposed approach can be used in a wide area, such as a smart hospital or smart building.
In the resulting session, we used performance metrics consisting of balanced accuracy (BA),
22
training time (s), and testing time (s) to compare the performances between the collected data from the proposed approach and the EK-means approach. Vaizman et al.
23
used BA as a fair (balanced) version of accuracy for an imbalanced dataset such as human activity dataset. BA incorporates both true positive rate (sensitivity) and true negative rate (specificity):
The quality of data aggregation
The dataset labels eight activities with an imbalanced sample, including leaving home (9143), working (139), cooking (677), using the toilet (69), eating (336), washing a dish (197), sleeping (6330), and taking a shower (339). In Tables 3 and 4 and Figure 8, we show the results of comparing the activity classification between utilizing data from fully transmitted data (original), IDEK approach, and EK-means approach with
Balanced accuracy.
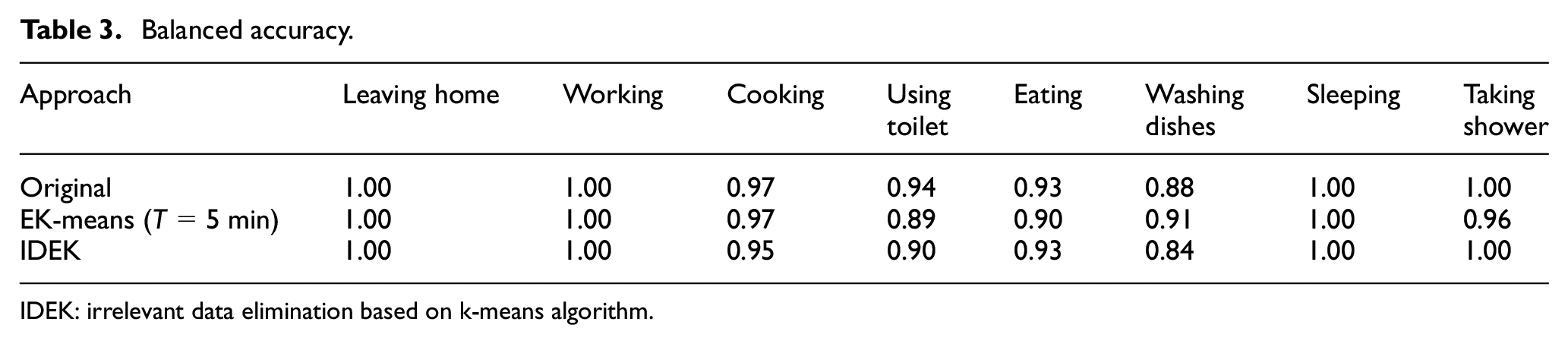
IDEK: irrelevant data elimination based on k-means algorithm.
Training time and testing time.

IDEK: irrelevant data elimination based on k-means algorithm.

Confusion matrix and normalized confusion matrix: (a, b) fully transmitting approach (original); (c, d) EK-means approach; and (e, f) IDEK approach.
The size of data passing transmission
The original loc dataset of 452,245 tuples from different scheduled times was changed into minute-long intervals by assuming that all sensor nodes sample data every minute. The modified dataset used 17,230 timestamped samples. Our model can reduce the data transmitted from the cluster heads to the base stations by 51.84% as shown in Table 5. In addition, our work also reduces the energy in the sensor node level when the sensor node measures the same physical value as the previous value; under this condition, the sensor node will not send the current value to the cluster head, thereby reducing energy consumption.
Size of the data reduction.

IDEK: irrelevant data elimination based on k-means algorithm.
We used the model discussed in Heinzelman et al.
7
to analyze the energy consumption needed to transmit data messages to the base station. For simplicity, we assume that all cluster heads are placed far from the base station at the same distance

According to equation (4), if the size of the data passing transmission is decreased, the energy consumption needed to transmit the collected data to the base station will be also reduced. Figure 9 shows that the use of IDEK approach can reduce the size of the data passing transmission and provide almost the same BA when transmitting all measured data. For EK-means algorithm, Table 5 shows that the greater the

The comparison of the overall balanced accuracy and size of the data passing transmission.
Semi-supervise activity classification
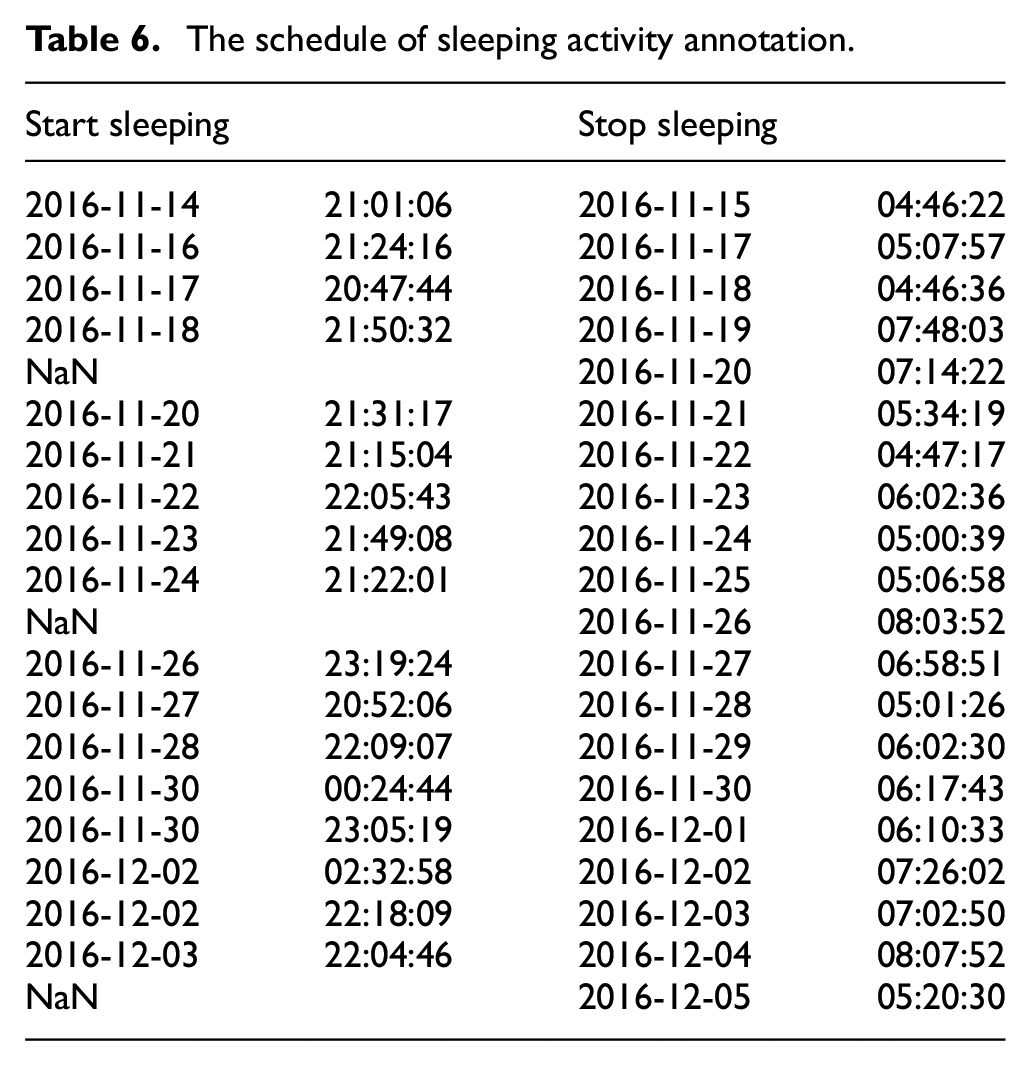
In semi-supervised learning, we can use unlabeled data to improve the training model because the model can learn more data. We used our model to prediction activity of unknown data (unlabeled data). The results of fully transmitting (original) and IDEK approach are shown in Figure 10(b) and (c) (shorter vertical line) comparing to ground truth in Figure 10(a) (higher vertical line). The results show that our model can predict sleeping activity that the subject did not annotation shown in Table 6.

The results of missing annotated activity prediction (shorter vertical line): (b) fully transmitting approach (original) and (c) IDEK approach comparing to (a) ground truth (higher vertical line).
The schedule of sleeping activity annotation.
This model can especially increase performance on a small sample. For example, Figure 11 illustrates a large difference in the performance classifications of eating and dishwashing activities.

A confusion matrix and normalized confusion matrix: (a and b) IDEK approach in semi-supervised learning.
Discussion and conclusion
The results show that the IDEK approach, which includes embedded cluster-based algorithm in the cluster heads, can enhance data aggregation of a sensor network by eliminating irrelevant data, because cluster heads act as local processors that perform data pre-processing and eliminate irrelative data. In addition, the IDEK approach can reduce the size of the data being communicated, which effects energy consumption. The performance of this approach was compared to the existing approach, which utilizes the EK-means algorithm at the sensor level to reduce redundant data.
The EK-means algorithm needs to define two parameters: the period size of the data, represented by point
However, our approach seems unsuitable to classify activities that are poorly captured by an ambient sensor (such as eating). These actions also include small sample or short-duration activities, such as using the toilet, and multifunctional appliance-using activities, such as using a sink for handwashing, vegetable preparation, dishwashing, and so on.
We developed this approach to intelligently collect and measure only the data that activate the cluster head if the relevant data are captured to reduce the size of the data transmission, reduce energy consumption, and ensure security/privacy data aggregation, as all collected data are not sent to others. On the contrary, most of the other works on data aggregation based on k-means algorithm enhancement focus on the similarities between the amount of data generated without considering present circumstances.
In the future, if we embed more powerful artificial intelligence (AI) technologies into the cluster heads, the sensors could determine complex situations, such as when a user overuses an appliance. For example, if the user leaves a living room with the television on and cooks in the kitchen, then the sensors are active in two places. The cluster heads should be able to learn from the patterns of each room and send data only from the kitchen room to the base station, where the occupant is located. Furthermore, human behaviors can alter these scenarios and environmental effects. Therefore, we may apply online learning to continuously test and update this model over time to reduce errors when the pertinent elements change.
Footnotes
Handling Editor: Zhong Shen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is result of studies with the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (NRF-2018R1C1B5045953).