
Abstract
In relational databases, embedding watermarks in integer data using traditional histogram shifting method has the problem of large data distortion. To solve this problem, a reversible database watermarking method without redundant shifting distortion is proposed, taking advantage of a large number of gaps in the integer histogram. This method embeds the watermark bit by bit on the basis of grouping. First, an integer data histogram is constructed with the absolute value of the prediction error of the data as a variable. Second, the positional relationship between each column and the gap in the histogram is analyzed to find out all the columns adjacent to the gap. Third, the highest column is selected as the embedded point. Finally, a watermark bit is embedded on the group by the histogram non-redundant shifting method. Experimental results show that compared with existing reversible database watermarking methods, such as genetic algorithm and histogram shift watermarking and histogram gap–based watermarking, the proposed method has no data distortion caused by the shifting redundant histogram columns after embedding watermarks on forest cover type data set and effectively reduces the data distortion rate after embedding watermarks.
Keywords
Introduction
In the era of big data, how to protect data security in the database is an important issue. Therefore, researchers introduced digital watermarking technology1–4 into the database as an effective means and then the database watermarking technology5,6 came into being. The technology protects the rights of the database owner by modifying the data in the database and embedding the watermark containing the copyright information. In 2002, IBM Almaden research center introduced digital watermarking technology in the relational database for the first time. 7 Thereafter, a variety of database watermarking technologies successively appeared, such as watermark technology based on special marker tuples, 8 fingerprint technology based on block idea, 9 and optimization technology based on verification. 10
In order to further protect the authenticity and integrity of data, reversible database watermarking technology emerges as the times require.11,12 This technique can not only hide the watermark information in the original carrier data but also recover the original carrier data without loss after extracting the watermark. In 2006, a reversible database watermarking method histogram shifting watermarking (HSW) based on histogram shifting was first proposed by Zhang et al. 13 Since then, researchers have successively proposed different types of reversible watermarking technologies, such as the difference expansion–based watermarking (DEW), 14 the differential expansion watermark technology combined with genetic algorithm (GADEW), 15 the differential expansion watermark technology combined with firefly algorithm (FFADEW), 16 and the predictive error extended watermarking (PEEW). 17 Although these techniques have solved the problems of copyright protection and data recovery in different degrees, they have some shortcomings in data distortion rate (DDR) and watermark robustness.
In 2018, DH Hu et al. 18 proposed a reversible database watermarking method called genetic algorithm and histogram shift watermarking (GAHSW) based on numerical relational data distortion control. This method uses a genetic algorithm to group tuples and then uses the HSW method to embed watermarks. This method improves the robustness of reversible database watermarking while reducing data distortion. Li et al. 19 proposed a low-distortion reversible database watermarking method called histogram gap–based watermarking (HGW). Compared with GAHSW, this method reduces data distortion without weakening the robustness of watermark.
However, through the analysis, we found that the HGW is unnecessary to modify part of the data when embedding watermarks, which is caused by the shifting of redundant columns. Therefore, we propose a reversible database watermarking method without redundant shifting distortion, which is abbreviated as NSHGW (non-shifting histogram gaps based on watermarking). The traditional histogram shifting method is improved using the characteristics of a large number of gaps in the database histogram, the positional relationship between each column and gap in the histogram is analyzed, and all adjacent columns are found; then choose the highest one of these columns as the embedding point to embed watermark information, so as to reduce the amount of modification to the carrier database data, reduce the redundant shifting of histogram columns, so as to reduce data distortion.
The structure of the article is as follows: Section “Related work” describes the related work in the early stage of the paper; section “The proposed method” elaborates the basic ideas and main contents of the proposed method; experimental verification and result analysis were carried out in section “Results and analysis”; and section “Conclusion” gives conclusions.
Related work
In this section, histogram shifting method and HGW reversible database watermarking method will be introduced in detail.
Histogram shifting method
The histogram shifting method (HS, histogram shifting) is mainly used in the early stage to process the reversible watermarking of digital images, which hides the watermarking information with the vertex value of the histogram. In Zhang et al.’s study,
13
the histogram shifting method was introduced into the database. This method obtains non-zero prediction errors from two adjacent local raw values in the database, uses these error values as the horizontal axis, and uses the frequency of each value of prediction error as the vertical axis to construct a histogram. The prediction errors are calculated by equation (1.1), where

A non-zero frequency peak bit is found in the histogram, and the corresponding prediction error is marked as

After



For example,
HGW reversible database watermarking method
Li et al. 19 propose a low-distortion reversible database watermarking method which is HGW. This method improves the traditional histogram shifting method. It uses histogram gaps to reduce the number of columns shifted when embedding a watermark to reduce data distortion.
HGW first divides the database tuples into
Step 1. Determine the relevant parameters: for the first
Step 2. Determining the shifting direction: this method judges the sizes of
if
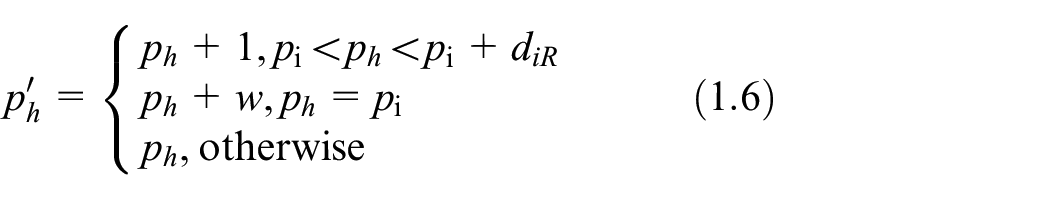
if


Histogram gap diagram.
According to the reference, when
The proposed method
The proposed NSHGW mainly consists of three sections: preprocessing, watermark embedding, and watermark extraction. This method is applicable to the integer numerical data of relational database. The algorithm principle is shown in Figure 2. Among them,

The algorithm principle of the method.
Preprocessing
In the preprocessing stage, the step should be completed before watermark embedding and watermark extraction. The specific pretreatment process is as follows:
Step 1.1 Determining candidate attribute columns: selecting multiple integer columns from the database that can identify the features of things as Candidate attribute columns for embedding watermarks. The data in the candidate attribute column usually indicate the characteristics of things (such as hair color). When watermarks are embedded in these data, the data distortion caused by the data has less impact on the data quality.
Step 1.2. Sorting candidate attribute columns: This method sorts the column names of the candidate attribute columns in ascending order, in order to enhance the robustness of the algorithm when it is attacked by the attribute columns.
Step 1.3. Determining the range of semantic distortion and calculating tolerance: the value range of the candidate attribute column is usually the semantic distortion range of the attribute column. In the watermark embedding process, in order to ensure that the modification of the data does not exceed the range of semantic distortion defined by each attribute column, the method uses the minimum and maximum values in the data of each column as the lower and upper bounds of the value range, respectively. This method defines the range of semantic distortion of the jth attribute column in

In equation (2.1),
Step 1.4 Grouping tuples: in the method, Ks, a secret grouping key, is set by a random method, and the tuples in the relational database are divided into Several non-overlapping groups

In equation (2.2),
Watermark embedding
The method requires embedding a watermark 1 bit in each grouping. Therefore, the process of embedding a watermark is an iterative process of performing steps 2.1–2.4 for each grouping. For the convenience of expression, group

Histogram analysis and embedding watermark flowchart.
Step 2.1. Construct a histogram of group


In equation (2.3),
Step 2.2. Selecting eligible columns in group
If
Step 2.3. Determining the position of the watermark embedding: the method selects the highest column from all eligible
Step 2.4. Embedding watermark bit.
It performs the watermark embedding operation based on the value of
if

if

It can be concluded from equation (2.4) that when
if

if

if

if

In summary, the histogram shifting and watermark embedding performed by this method can be finally processed according to the formulas (3.7)–formula (3.10). In addition, in order to extract the watermark and recover data from the database, an array needs to be used here to store the
Watermark extracting
Detailed algorithm for watermark extraction and data recovery is reported below. The following steps can be used to extract the watermarks and restore the database after the database is attacked by insertion, deletion, and alteration. Before the extraction watermarking, it is necessary to preprocess the database according to the pretreatment Steps 1.1–1.4, and then perform the procedure of Step 3.1–3.3.
Step 3.1. Constructing histogram: equation (2.11) was used to calculate all
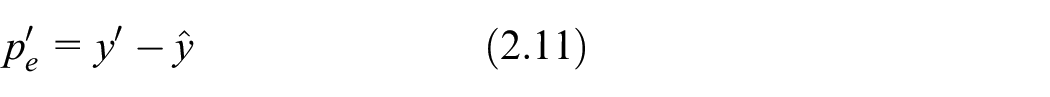

Among them,
Step 3.2. Extracting watermark: extracting watermark with the
The specific test operation method is as follows: when
After repeated experiments, the watermark extracted by the majority voting mechanism can be used to prove the copyright owner. If the extracted watermark is the same as the current one, it means that the database is real and that the extraction process does not modify it.
Step 3.3. Recovering data: Figure 1 shows watermark extraction and data recovery. According to the positive and negative values of
if

if

if

if
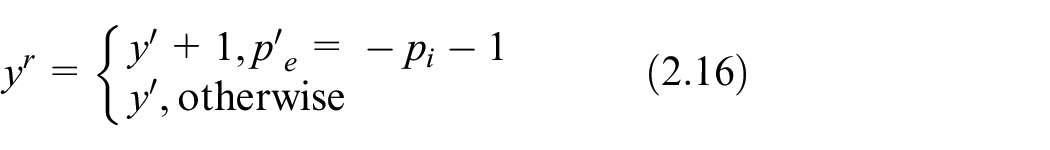
Among them,
Notations used in the article.

Experimental results and analysis
In this article, in order to evaluate the performance of the watermark and validation method, we conduct experiments in an Intel Core i5 environment with a 2.40 GHz CPU and 8GB RAM. The selected database was the forest cover type dataset provided by the University of California as the database for testing the watermark. This data set contains 581,012 tuples and 54 attributes. According to the experimental requirements, we selected 10 integer numeric attributes for the experiment and compared them with the existing HGW reversible watermarking method.
The experiment was set up in three parts. The first part is DDR analysis, which compares this method with similar methods reported by Hu et al. 18 and Li et al. 19 The second part is the quantitative analysis of histogram distortion, which shows the influence of this parameter on the performance of the algorithm. The third part is the robustness analysis, which shows the performance of the method under some well-known attacks in the database to test the effectiveness of the watermark. The method used is set as the HGW experiment by Li et al., 19 which generates a composite column as the primary key, and the length (number of packets) of the watermark is 48. For the convenience of comparison, all the following experiments are embedded with watermarks under the same conditions.
DDR analysis
The loss and harm caused by data distortion are huge, so data distortion must be strictly prevented. In this experimental study, in order to better understand the effect of DDR on data quality, we not only evaluated and calculated the watermark length of 48-bit but also selected the watermark length of 24-bit and 72-bit to compare the distortion rate of NSHGW and HGW watermarking methods.
We use the DDR to assess NSHGW and HGW embedded watermark after the distortion of the effects on the database. The larger the DDR, the greater the distortion of the data will be and vice versa. The calculation formula of DDR is as follows
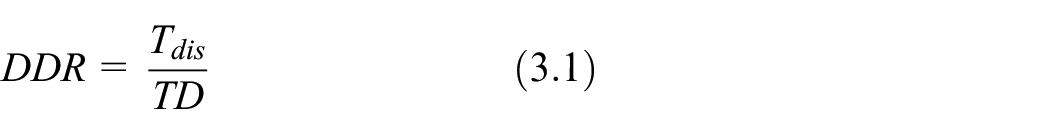
In the formula above
In the experiment, the distortion rates of NSHGW and HGW were verified when the total tuples were 1000, 1200, 1400, 1600, 1800, and 2000, respectively. We use different lengths of watermarks (the number of packets) and get different results. Figure 4 shows the DDRs of the two methods when the watermark length is 24, 48, and 72, respectively.

The comparison of data distortion rates caused by watermark of different bits: (a) 24-bit watermark, (b) 48-bit watermark, and (c) 72-bit watermark.
The horizontal axis represents the number of different tuples in the database, while the vertical axis is DDR, representing the rate of distortion. When DDR is 0, the data in the database is not distorted. Because both NSHGW and HGW rely on stochastic optimization, the distortion rate is the average of the 10 runs of the two methods, respectively.
As can be seen from Figure 4, while embedding the same watermark information into the same database in the experiment, the DDR generated by NSHGW method is much lower than that of HGW, both less than 0.42%.
Quantitative analysis of histogram distortion
In the experiment, in order to identify redundancy shifting brought about by the distortion effect more clearly, we not only for 48 to evaluate watermark length calculation, but also with the above DDR analysis experiments, selected the additional 24 and 72—bit watermark value, the length of the two watermarking methods and NSHGW HGW distortion of histograms multi-faceted contrast. It is important to note that it is necessary to evaluate the distortion effect of NSHGW- and HGW-embedded watermarks on the database by the amount of distorted data caused by shifting (excluding the distortion caused by embedding watermark bits).
In the experiment, we compare the two methods of NSHGW and HGW each time, and verifying the total amount of distorted data caused by the shifting of the two methods of NSHGW and HGW when the total number of tuples is 1000, 1200, 1400, 1600, 1800, and 2000, respectively, under the condition of the same embedded watermark. We use different lengths of watermarks (the number of packets) and get different results. Figure 5 shows the total amount of distorted data caused by the shifting of the two methods when the watermark length is 24, 48, and 72, respectively.

The comparison of the total amount of the data distortion caused by shift with watermark of different bits: (a) 24-bit watermark, (b) 48-bit watermark, and (c) 72-bit watermark.
In the figure, the horizontal axis represents the number of different tuples in the database, while the vertical axis represents the total amount of distorted data and represents the number of distorted data. When the total amount of shifting distortion data is 0, it means that the data of the database is not distorted. Since both NSHGW and HGW depend on random optimization, the total amount of distortion data is the average of the results of 10 runs of the two methods. As can be seen from the above figure, when the same watermark information is embedded in the same database, the total amount of redundant translation distortion data generated by NSHGW method is close to 0 and far lower than that of HGW, with a minimum of 12 and a maximum of 29, almost overlapping with the horizontal axis.
Robustness analysis
In this experiment, we mainly study the robustness of NSHGW watermarking method under malicious attack of well-known database. The watermarked data in the experiment will be attacked by different types, such as insertion attack, altered attack, and deleted attack. In order to facilitate the comparison with other methods, NSHGW watermarking method is consistent with the experiments of HGW, GAHSW, and other watermarking methods by Gupta and Pieprzyk, 14 Jawad and Khan, 15 Farfoura et al., 17 Hu et al., 18 and Li et al., 19 and the length of the same watermark is set to 48 for this experimental test. The value of bit error rate (BER) is used to evaluate the robustness of the watermarking method. From the following equation, we can easily see that the lower the BER value is, the higher the watermark robustness will be. BER is the ratio of the number of error-extracted bits to the number of embedded watermark bits. The calculation equation, of BER is as follows

where
We present the results as a graph, with the horizontal axis representing the percentage (%) of attacks based on the size of the database. This means we need to change the specific rate of tuples which exist in the data set. Zero (0)% attack means no detection of any attack on the data set. We simulate the attacker trying to insert, delete, and modify 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, and 90% of the data in the data set. If the data set contains 1000 tuples, changing 10% means 100 tuples will be attacked. In the figure, the vertical axis is BER, indicating the rate of unsuccessful detection of watermark. When BER approaches 0, the watermark is correctly detected from the database. Because NSHGW relies on random optimization, the BER extracted from the watermark is the average of the 10 runs of the method. The results of the deletion and alteration are drawn as shown in Figures 6 and 7, respectively.

Deleted attack BER comparison.

Alteration attack BER comparison.
Insertion attack is an attack by inserting a new tuple to affect the watermark detection process. In the database, the attacker adds new tuples to increase the number of false positives and affect the process of detecting data. But the experimental results show that the BER value is 0 before insertion attack. After the insertion attack, BER remains 0 even if 60% of the new tuples are added to the watermarked data set. It is verified that insertion attack will not cause the problem of watermark robustness because our technology only involves tuples with watermark, and tuples without watermark or newly added tuples will not affect the process of watermark detection. Therefore, the three watermarking methods of NSHGW, HGW, and GAHSW are robust for insertion attack. No matter how many tuples are inserted, the BER under the insertion attack is always 0, so the comparison diagram of insertion attack will not be drawn here.
Deletion attack is a process in which an attacker destroys the watermark by deleting tuples randomly. Attackers randomly remove some tuples from the watermarked data set in the hope that some of the watermarked tuples will also be deleted, resulting in the loss of watermark bits. Deleted attack is a process in which an attacker destroys the watermark by deleting tuples randomly. Attackers randomly remove some tuples from the watermarked data set in the hope that some of the watermarked tuples will also be deleted; resulting in the loss of watermark bits. Deleted attack is more damaging than other attack because there is a chance that watermark bits will not be detected correctly when removing a tuple with a watermark. As the percentage of delete attack increases, the rate of correct detection plummets and is more damaging than other attacks because there is a chance that watermark bits will not be detected correctly when removing a tuple with a watermark. As the percentage of delete attack increases, the rate of correct detection plummets. Figure 6 shows the BER of the watermark extracted by NSHGW, HGW, GAHSW, PEEW, DEW, and GADEW methods after removing the attack. GAHSW, DEW, GADEW, and PEEW extracted watermarks with BER values of 0.477, 0.814, 0.9550, and 0.915, respectively, when the number of deleted tuples in the database increased by 90% when the database was severely attacked by deletion. However, the BER extracted from NSHGW watermark is 0.388 and that from HGW watermark is 0.472. NSHGW can also recover at least half of the watermark. If most of the watermarks contained in the terra-tuple are removed from the database, the watermark cannot be recovered. The harm of deleting attack to database watermark is obvious.
Alteration attack is a process in which an attacker randomly altered the tuples of a database to destroy the watermark. Attackers randomly or permanently change some tuple values from a watermarked data set in the hope that some watermarked attributes will be changed altogether, never increasing the difficulty of detecting watermark bits. As the percentage of alteration attack increases, the rate of correct detection plummets. Figure 7 shows the BER of the watermark extracted by NSHGW, HGW, GAHSW, PEEW, DEW, and GADEW methods after alteration attack. The BER of extracted watermarks will increase with the increase of data altered. amount, and the number of altered attributes in the database reaches 90%. GAHSW, DEW, GADEW and PEEW extracted watermarks with BER values of 0.411, 0.434, 0.584 and 0.526, respectively. The BER of NSHGW watermark extraction is 0.356, and that of HGW watermark extraction is 0.383. We can see that NSHGW can recover at least half of the watermark at this point. However, if a large number of watermark attributes are altered, it is difficult to extract the watermark tuples affected by this attack from the remaining unaffected data.
In general, in the deletion attack and altered attack, Figures 6 and 7 show that the robustness of NSHGW, HGW, and GAHSW methods is roughly the same. With the increase of attack intensity, the BER of extracting watermark by these three methods also increases. But compared with other methods, NSHGW has better watermark detection rate under this attack. Experiments also show that the NSHGW method produces a lower BER when embedding the same watermark into the same database.
Conclusions
We propose a new method of reversible database watermarking with low distortion and the originality of the method lies in the grate reduction of the distortion rate of the carrier data. NSHGW method is to use the characteristics of database histogram gap to improve the histogram shifting method, find the best embedding point in the gap, and realize watermark embedding. While embedding watermark, the quantity of redundant shifting of histogram column is avoided, the data quality is guaranteed (the amount of changed data is greatly reduced), and the data distortion caused by watermark embedding is effectively reduced. Experiments show that NSHGW method is better than the existing HGW method in distortion rate analysis and histogram shifting quantitative analysis. The robustness analysis of NSHGW method is similar to that of HGW and GAHSW. Based on the current histogram embedding method and on the basis of reducing data distortion, the future work is to find better and smaller data distortion methods, which is also my research direction.
Footnotes
Handling Editor: Hongxin Hu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.