
Abstract
In this article, versatile video coding, the next-generation video coding standard, is combined with a deep convolutional neural network to achieve state-of-the-art image compression efficiency. The proposed hierarchical grouped residual dense network exhaustively exploits hierarchical features in each architectural level to maximize the image quality enhancement capability. The basic building block employed for hierarchical grouped residual dense network is residual dense block which exploits hierarchical features from internal convolutional layers. Residual dense blocks are then combined into a grouped residual dense block exploiting hierarchical features from residual dense blocks. Finally, grouped residual dense blocks are connected to comprise a hierarchical grouped residual dense block so that hierarchical features from grouped residual dense blocks can also be exploited for quality enhancement of versatile video coding intra-coded images. Various non-architectural and architectural aspects affecting the training efficiency and performance of hierarchical grouped residual dense network are explored. The proposed hierarchical grouped residual dense network respectively obtained 10.72% and 14.3% of Bjøntegaard-delta-rate gains against versatile video coding in the experiments conducted on two public image datasets with different characteristics to verify the image compression efficiency.
Introduction
Image compression is a crucial technology for rich multimedia services over the Internet; it allows viewing high-quality natural and synthetic images created by an expert photographer on a web browser; it allows sharing tremendous number of photos taken by users through a social network service; in addition, an intuitive user interface based on compressed images allows users to explore other multimedia services. Highly efficient image compression can increase user satisfaction with multimedia services on the Internet by reducing image loading time or enabling higher quality image viewing. Also, it can provide a seamless multimedia service even in severe network environment. Therefore, even though image compression such as JPEG, WebP, 1 and BPG 2 already exists, higher image compression efficiency is still required.
Image compression using deep neural network (DNN) has become one of the emerging research fields due to its potential for significant improvement of compression efficiency over handcrafted algorithms. Joint Photographic Experts Group (JPEG) of ISO/IEC JTC1/SC29/WG1 and ITU-T SG16 is exploring DNN-based image compression technology for JPEG-AI.3,4 To improve image compression efficiency using a dedicated DNN, it can be end-to-end trained to efficiently code latent variables using a probability distribution model.5–9 Recent works8,9 in this type of approach show superior performance than BPG which is compatible with high-efficiency video coding (HEVC) intra coding, for both peak signal-to-noise (PSNR) and multi-scale structural similarity (MS-SSIM). 10 As another type of approach to improve image compression efficiency, a DNN can be used to improve the quality of an image that has already been reconstructed after compression. Joint Video Experts Team (JVET), jointly formed by ISO/IEC Moving Picture Experts Group (MPEG) and ITU-T Video Coding Experts Group (VCEG), is currently standardizing the next-generation video compression technology, versatile video coding (VVC). 11 VVC has a requirement to improve the compression efficiency of existing HEVC 12 by more than 30% and 50% for the same perceptual quality depending on use-cases. 13 This work focuses on quality enhancement of VVC intra-coded images to maximize the image compression efficiency. There are three main contributions of this work:
VVC intra coding is combined with the proposed DNN-based compression artifact removal method to obtain a state-of-the-art image compression efficiency. Experimental results show that substantial quality enhancement is achieved with the proposed method for a wide bitrate range.
Hierarchical grouped residual dense network (HGRDN) architecture is proposed to efficiently remove artifacts from VVC intra coding. Combinations of feature fusion in different architectural levels are explored to determine the overall HGRDN architecture.
Non-architectural aspects affecting the training efficiency and the performance of HGRDN, such as size of the training image patch and number of the convolutional filters, are investigated. An effective learning rate decaying strategy is also introduced to adaptively adjust the learning rate throughout the training period of HGRDN.
The remainder of this article is organized as follows. Section “Related works” provides brief introductions to VVC intra coding and DNN-based image quality enhancement. Section “Proposed method” presents the details of our proposed HGRDN in each architectural level. Section “Results and discussions” provides experimental results and discussions. Finally, we conclude our work in section “Conclusion.”
Related works
VVC intra coding
VVC supports a 128 × 128 Coding Tree Unit (CTU) size that is extended from the maximum CTU size of HEVC, 64 × 64. A more sophisticated block partitioning scheme, which extends HEVC’s quadtree to quadtree plus binary tree and ternary tree (QTBTTT), is adopted for VVC. Figure 1(a) depicts an example of QTBTTT block partitioning of VVC. VVC also extends the maximum transform size from 32 × 32 to 64 × 64. Furthermore, mode-dependent non-separable secondary transforms and explicit multiple core transforms are adopted for VVC intra-frame coding. Although these changes are not directly related to intra prediction, they give VVC intra-frame coding a substantial coding gain compared to HEVC. Following are the coding tools adopted for VVC to improve intra-prediction accuracy: 14
Sixty-seven intra-prediction modes (refer to Figure 1(b));
Wide-angle intra prediction for non-square blocks;
Block size and mode-dependent four-tap interpolation filter;
Position-dependent intra-prediction combination;
Cross-component linear model intra prediction;
Multi-reference line intra prediction;
Intra sub-partition.
It is reported that VVC has achieved 23.14% of Y-PSNR Bjøntegaard delta (BD)-rate gain on average when the VVC test model (VTM) 15 is compared with the HEVC test model (HM) 16 in all intra-coding conditions. 17

(a) An example of QTBTTT block partitioning of VVC; (b) 67 intra-prediction modes of VVC. Both (a) and (b) are copied from Chen et al. 14
DNN-based image quality enhancement
DNNs are being actively studied for recent years achieving great success on image restoration tasks such as image super resolution (SR), denoising, inpainting, and dehazing. The DNNs for such tasks have similar design considerations, thus they are affecting each other’s design and rapidly improving the performance for overall image restoration tasks. Enhancing the quality of compressed images and videos is a task to remove compression artifacts, which essentially falls into the same category with denoising, and DNN-based approaches are driving the performance improvement for this research field. Dong et al. 18 introduced a DNN named artifact reduction convolutional neural network (AR-CNN) that is inspired by well-known super-resolution CNN (SRCNN) 19 for image SR and successfully reduced JPEG artifacts. After that, following works20–22 introduced DNNs with improved performance for JPEG artifact reduction.
The efforts were not limited to the traditional JPEG image codec; DNNs combined with a recent video codec HEVC for compression artifact reduction were also introduced. Dai et al. 23 achieved a 4.6% average BD-rate gain by post-filtering HEVC intra-coded frames with variable-filter-size residue-learning CNN (VRCNN) which uses multiple convolutional filer sizes. Soh et al. 24 introduced a DNN with temporal branches where the network extracts features from neighboring frames for artifact removal of the image patch in the current frame. This work achieved a 0.23-dB average PSNR gain by post-filtering HEVC frames encoded in random access (RA) condition; however, the gain was limited only for low bitrates. Yang et al. 25 proposed quality-enhanced CNN (QE-CNN) which mainly consists of two sub-networks, QE-CNN-I and QE-CNN-P, dedicated for HEVC intra-mode and inter-mode distortions, respectively. This one achieved an 11.06% average BD-rate gain when HEVC I and P frames are post-filtered with the dedicated sub-networks.
Several DNNs applied for VVC artifact reduction were introduced more recently. Lu et al. 26 proposed a DNN based on residual blocks in multiple spatial scales, and Cho et al. 27 applied grouped residual dense network (GRDN) that showed an excellent image denoising performance in Kim et al. 28 Both Lu et al.’s 26 and Cho et al.’s 27 models work as post-filters of VVC intra coding to obtain improved image compression efficiency. Cho et al. 27 achieved a superior performance over Lu et al. 26 in terms of PSNR and mean opinion score (MOS). 29 This work exploits the previous work 27 as a base model and extends it in different architectural levels to find out a better architecture for compression artifact reduction of VVC intra-coded frames.
Proposed method
In this section, the architecture of HGRDN is introduced in detail. HGRDN has top, middle, and bottom architectural levels each of which respectively determines the hierarchical grouped residual dense block (HGRDB), grouped residual dense block (GRDB), and residual dense block (RDB) sub-architectures. We introduce the HGRDN architectural levels in top-to-bottom order.
Top-level HGRDN architecture with HGRDB sub-architectures
HGRDN consists of six parts in top-level: input feature extraction, down-sampling, an HGRDB which consists of GRDBs, up-sampling, a convolutional block attention module (CBAM), and global residual restoration. Figure 2 illustrates the top-level HGRDN architecture with three HGRDB sub-architectures—Serial, Merged, and Dense—that differ from each other depending on how GRDBs in an HGRDB are connected to each other. Figure 2(a) shows the top-level HGRDN architecture with Serial HGRDB sub-architecture. It should be noted that Serial herein means the HGRDB has a number of serialized GRDBs in it, as shown in the gray box in Figure 2(a). The first convolutional layer of HGRDN depicted as Conv in Figure 2 extracts a feature map

where

Top-level HGRDN architecture with different HGRDBs: (a) Serial HGRDB and (b) Merged and Dense HGRDBs. In (b), Merged HGRDB only includes solid arrows, while Dense HGRDB includes both solid and dashed arrows.
Figure 2(b) shows the top-level HGRDN architecture with Merged and Dense HGRDB sub-architectures. The difference between Serial and the other two HGRDB sub-architectures is the connectivity between GRDBs that can be noted by comparing the gray boxes in Figure 2(a) and (b). The output of dth GRDB
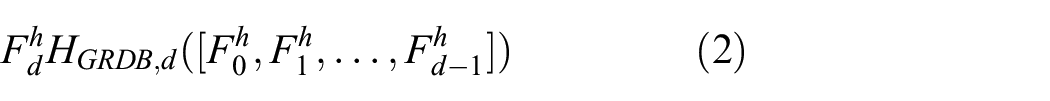
where

where
Middle-level HGRDN architecture with GRDB sub-architectures
GRDB consists of three parts: an input convolutional layer, RDBs, and local residual restoration. Figure 3 illustrates the middle-level HGRDN architecture with two GRDB sub-architectures, Merged and Dense, that differ from each other depending on how RDBs in a GRDB are connected to each other. The input convolutional layer of dth GRDB that is depicted as Conv-in in Figure 3 adjusts the depth of input

where
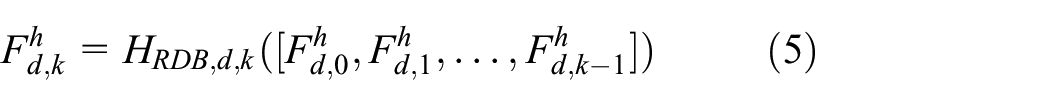
where

where

Middle-level HGRDN architectures with Merged and Dense GRDBs; Merged GRDB only includes solid arrows, while Dense GRDB includes both solid and dashed arrows; the Conv-in is only valid for GRDBs in a Dense HGRDB.
Bottom-level HGRDN architecture with RDB sub-architecture
Figure 4 illustrates the bottom-level HGRDN architecture with RDB sub-architecture. In this work, the RDB introduced by Zhang et al.
32
is used with a minor modification. RDB in this work consists of three parts: an input convolutional layer, convolutional layers with rectified linear unit (ReLU) activation function, and local residual restoration. The input convolutional layer of kth RDB in dth GRDB that is depicted as Conv-in in Figure 4 adjusts the depth of input

where
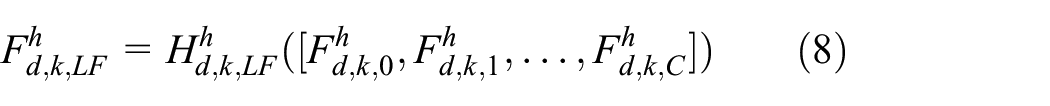
where

Bottom-level HGRDN architecture with RDBs; the Conv-in is only valid for RDBs in a Dense GRDB.
Results and discussions
Implementation details and training HGRDNs
HGRDBs are implemented with PyTorch-1.0.1, and NVIDIA TITAN Xp is used for training and testing the HGRDBs. Five HGRDNs, each of which has different overall architecture, are tested to find out the best top- and middle-level HGRDN architectures. The test results on these architectural variations will be discussed in section “Architectural exploration.” Same numbers of building blocks are used to implement the HGRDNs; four GRDBs to consist an HGRDN; four RDBs to consist a GRDB; and eight convolutional layers with the ReLU activation function to consist an RDB. The input to HGRDN,
We collected 1633 CLIC (Challenge on Learned Image Compression) training images
29
and 30,000 images randomly selected from Microsoft COCO training dataset.
33
Those images over 1024 in width or height were cropped into non-overlapping 256 × 256 image patches. An N × N image patch is randomly cropped from each of the collected images and the 256 × 256 image patches to train an HGRDN with batch size equal to 16. We investigated the impact of the training image patch size on the HGRDN’s performance by testing different N values; the test results will be discussed in section “Non-architectural exploration.” The CLIC validation dataset
29
that consists of 102 images was used for validation at the end of each epoch while training an HGRDN. We used L2 loss between
Non-architectural exploration
Before the exploration to determine the overall HGRDN architecture, we conducted several experiments to investigate non-architectural aspects. The HGRDB and GRDB sub-architectures used in the non-architectural exploration are Serial and Merged, respectively, which are the same as in the base model. 27 Quantization parameter (QP) equal to 37 is used for VVC intra coding, and aggregated PSNR for the validation dataset is measured at the end of each training epoch in the non-architectural and architectural explorations.
First, Figure 5 shows the experimental results of the learning rate decaying strategies. The number of filters for all convolutional layers inside an HGRDN is set to 48 for this experiment, and 64 × 64 image patches randomly cropped from the training set are used. In this experiment, the learning rate is decayed by half for every 10 epochs in the fixed decaying method, while it is decayed only when there is no PSNR improvements evaluated on the validation set for four epochs in the adaptive decaying method. Figure 5(a) compares the PSNR convergence of the fixed and adaptive learning rate decaying methods observed for 80 training epochs. It can be noted in Figure 5(a) that the resulting PSNR of the adaptive decaying converges with less fluctuations and quickly reaches to a higher value, compared to the resulting PSNR of the fixed decaying. Figure 5(b) compares the learning rate changes in both methods during the experiment. With the knowledge obtained from the experiment, we used the adaptive learning rate decaying strategy in the following experiments of this work.

Comparison of fixed and adaptive learning rate decaying strategies: (a) PSNR convergence and (b) learning rate changes.
Second, Figure 6 shows the experimental results on different numbers of filters. In this experiment, HGRDNs using 48, 64, and 80 filters are tested in the experiment while training the HGRDNs using 64 × 64 training image patches. In this experiment, the HGRDN with 64 filters achieved the best PSNR performance as shown in Figure 6. We conducted this experiment twice to confirm the result shown in Figure 6, and notable differences between the first and the second experimental results were not found. More filters in an HGRDN provide higher performance; however, the performance improvement is saturated at some point and too many filters may cause a performance loss. This is because the deeper the HGRDN, the harder it becomes to train the HGRDN efficiently. From this experiment, we decided to use 64 filters to implement the HGRDNs for the performance evaluation of which results will be discussed in section “Experimental results.”

PSNR convergence comparison for different numbers of filters.
Third, Figure 7 shows the experimental results on different training image patch sizes. HGRDNs are trained using 64 × 64, 96 × 96, and 128 × 128 training image patches in this experiment, while the number of filters is fixed to 48 × 48. In this experiment, the HGRDN trained with 96 × 96 image patches achieved much better PSNR performance than the HGRDN trained with 64 × 64 image patches, as shown in Figure 7. However, the HGRDN trained with 128 × 128 patches only achieved similar PSNR results with the HGRDN trained with 96 × 96 patches. Although the former converged within less training epochs than the later, they ended up with being saturated at a similar PSNR. We decided to use 96 × 96 patches to train the HGRDNs for performance evaluation of which results will be discussed in section “Experimental results,” because 128 × 128 patches require much training time than 96 × 96 patches.

PSNR convergence comparison for different training image patch sizes.
Architectural exploration
We conducted an experiment to find out the best overall HGRDN architecture, for which five combinations of HGRDB and GRDB sub-architectures are tested. In this experiment, the number of filters for all convolutional layers inside an HGRDN is set to 48 and 64 × 64 training image patches are used. Figure 8 shows the experimental result comparing PSNR convergences of the tested combinations. An overall HGRDN architecture can be identified in Figure 8 with a combined word that consists of the names of HGRDB and GRDB sub-architecture, for example, Serial–Merged denotes the combination of Serial HGRDB and Merged GRDB. As shown in Figure 8, an HGRDN configured with Dense GRDBs achieved superior PSNR performance compared to HGRDNs configured with Merged GRDBs. The HGRDN with a Dense HGRDB achieved the best PSNR performance, the one with a Merged HGRDB achieved the second best PSNR performance, and the one with a Serial HGRDB achieved the worst PSNR performance among the HGRDNs configured with Dense GRDBs. From these observations, we found that exploiting hierarchical features works not only in the bottom-level HGRDN architecture but also in the middle- and top-level HGRDN architectures. We also found that the Dense sub-architecture, in which hierarchical features are further exploited as addressed in section “Top-level HGRDN architecture with HGRDB sub-architectures,” is more effective than the Merged sub-architecture. We chose the Dense–Dense as our overall HGRDN architecture and used it for the experiments to evaluate the performance of the HGRDN with test datasets; the test results will be discussed in section “Experimental results.”

PSNR convergence comparisons for various combinations of HGRDB and GRDB sub-architectures.
Experimental results
In this section, the experimental results for the performance evaluation of our Dense–Dense HGRDN are provided. In the experiment, we respectively used 24 KODAK PhotoCD images 34 and 330 images of CLIC 2019 test dataset 29 to see whether the HGRDN works robustly for images with different characteristics. Also, the experiments are conducted for VVC QPs equal to 22, 27, 32, and 37 to see whether the HGRDN effectively improves the quality of VVC intra-coded images with various degrees of compression artifacts. To clarify the impact of the HGRDN on image compression efficiency, WebP, 1 HEVC test model HM-16.20, 16 and VVC test model VTM-5.0 15 are compared with our HGRDN combined with VTM-5.0. 15 The rate-distortion (RD) performance measured with aggregated PSNR and bits per pixel (bpp) is used for the comparison.
Figure 9(a) and (b) compares RD curves of the WebP, HM, VTM, and HGRDN combined with the VTM for the two test datasets, respectively. The BD-rate gain of our method against the VTM is measured as 10.72% for the KODAK test dataset and 14.3% for the CLIC 2019 test dataset. As can be noted from Figure 9(a) and (b), the HGRDN works well not only in low bitrates but also in high bitrates. Unlike Yang et al., 25 the HGRDN provides better performance at higher bitrates than low bitrates. Detailed experimental results for the performance evaluation of the HGRDN on the KODAK test dataset and the CLIC 2019 test dataset are shown in Tables 1 and 2, respectively. Figure 10 compares the subjective quality of images encoded at similar bitrates using the WebP, HM, VTM, and our HGRDN combined with the VTM. For all the images in Figure 10, our method provides a significantly improved image quality compared to the VTM and the other methods. Looking at the images in the first row in Figure 10, VVC blocking artifacts are substantially reduced in our method. Looking at the images in the second and third rows in Figure 10, blurred edges in the VTM image are effectively restored. Looking at the images in the last row in Figure 10, ringing artifacts in the VTM image are considerably removed.
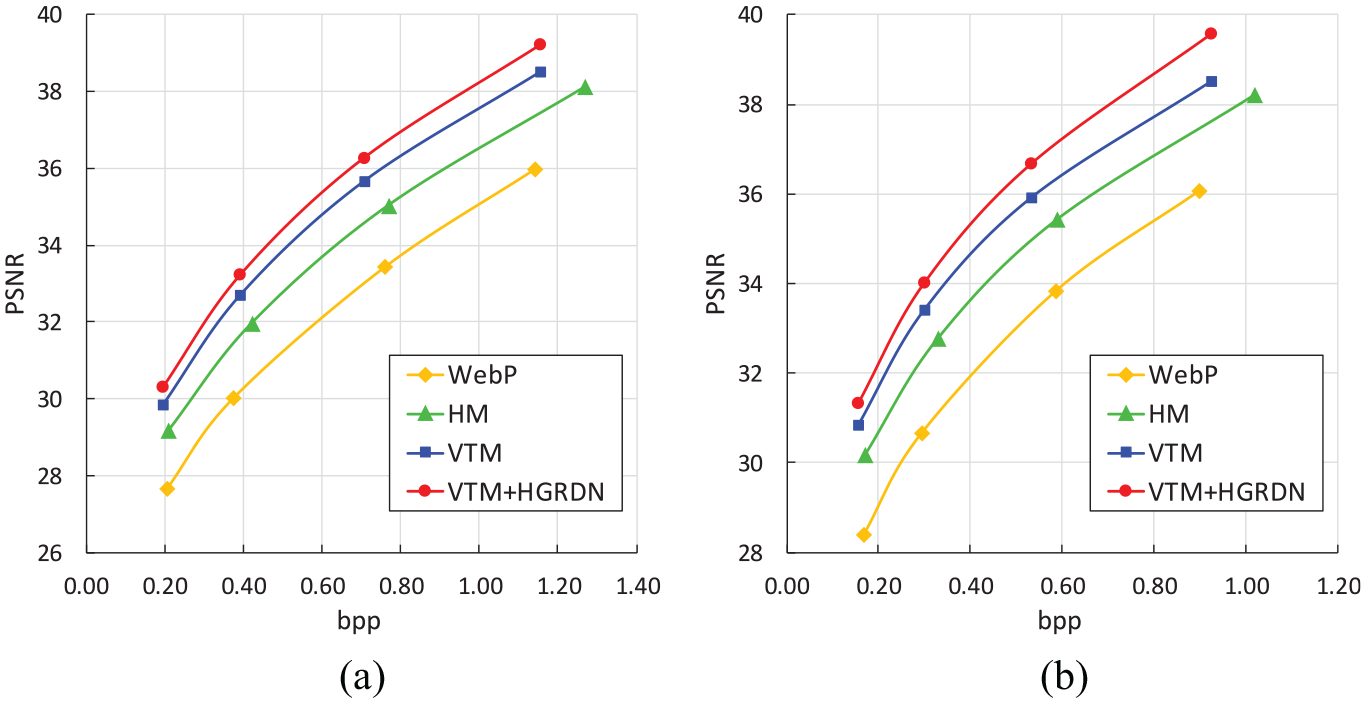
Comparisons of RD curves of the WebP, HM, VTM, and HGRDN combined with the VTM for the test datasets: (a) KODAK PhotoCD and (b) CLIC 2019 test dataset.
Detailed experimental results for performance evaluation of the HGRDN on the KODAK PhotoCD.
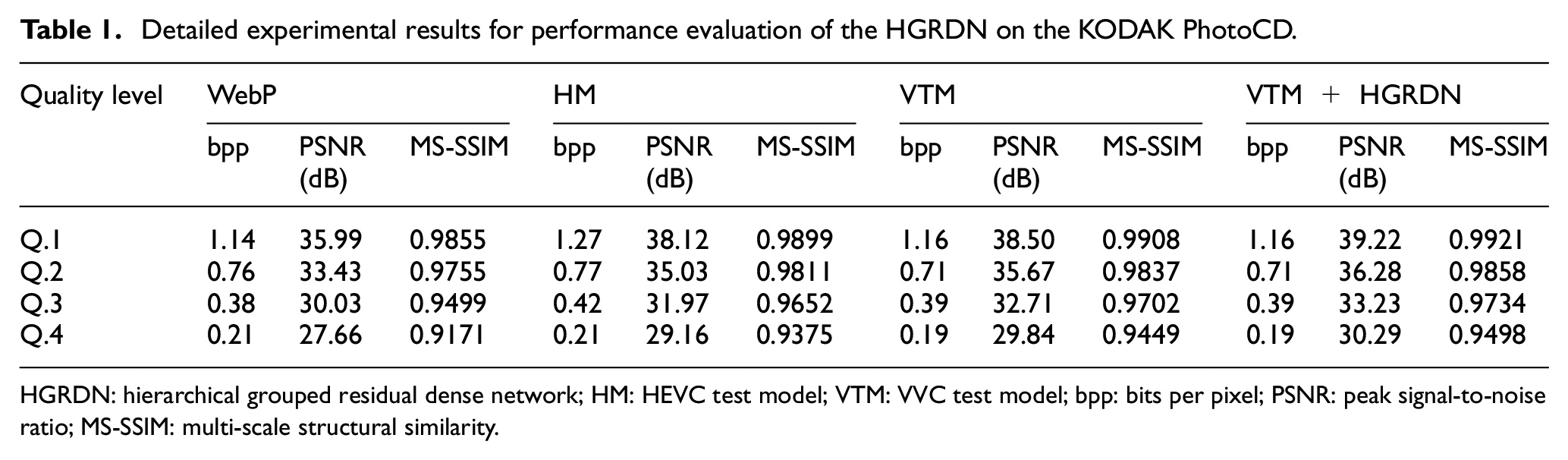
HGRDN: hierarchical grouped residual dense network; HM: HEVC test model; VTM: VVC test model; bpp: bits per pixel; PSNR: peak signal-to-noise ratio; MS-SSIM: multi-scale structural similarity.
Detailed experimental results for performance evaluation of the HGRDN on the CLIC 2019 test dataset.

HGRDN: hierarchical grouped residual dense network; CLIC: Challenge on Learned Image Compression; HM: HEVC test model; VTM: VVC test model; bpp: bits per pixel; PSNR: peak signal-to-noise ratio; MS-SSIM: multi-scale structural similarity.

Subjective image quality of the KODAK images encoded with (a) WebP, (b) HM, (c) VTM, and (d) VTM + HGRDN.
Conclusion
In this article, HGRDN is introduced to effectively remove the compression artifacts of the VVC intra-coded images. Non-architectural aspects, which considerably affect HGRDN’s training efficiency and performance, are explored through a number of experiments. To find out an efficient HGRDN architecture, possible top-, middle-, and bottom-level HGRDN architectures are designed and they are tested in various combinations. The determined HGRDN architecture thoroughly utilizes hierarchical features in every architectural level to maximize the performance of VVC artifact reduction. From the result of the experiments to verify the RD performance, it is proved that the proposed HGRDN effectively removes the VVC artifacts over a wide bitrate range. Subsequent research of this work can be video in-loop filtering using DNN such as HGRDN. For example, one or more of the in-loop filters in VVC, deblock, sample adaptive offset (SAO), and adaptive loop filter (ALF) may be replaced with a DNN. Alternatively, a DNN can be applied as an additional in-loop filter to the existing ones. In both cases, the effect of pixel blocks restored by the DNN on inter-frame prediction should be carefully studied and harmonization with other tools should be considered.
Footnotes
Handling Editor: Partha Roy
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Institute for Information and Communications Technology Promotion (IITP) grant funded by the Korea government (MSIP; 2017-0-00072, Development of Audio/Video Coding and Light Field Media Fundamental Technologies for Ultra Realistic Tera-media).