
Abstract
In recent years, Internet of things (IoT) devices are playing an important role in business, education, medical as well as in other fields. Devices connected to the Internet is much more than the number of world population. However, it may face all kinds of attacks from the Internet easily for its accessibility. As we all know, most attacks against IoT devices are based on Web applications. So protecting the security of Web services can effectively improve the situation of IoT ecosystem. Conventional Web attack detection methods highly rely on samples, and artificial intelligence detection results are uninterpretable. Hence, this article introduced a supervised detection algorithm based on benign samples. Seq2Seq algorithm is been chosen and applied to detect malicious web requests. Meanwhile, the attention mechanism is introduced to label the attack payload and highlight labeling abnormal characters. The results of experiments show that on the premise of training a benign sample, the precision of proposed model is 97.02%, and the recall is 97.60%. It explains that the model can detect Web attack requests effectively. Simultaneously, the model can label attack payload visually and make the model “interpretable.”
Introduction
Today portable devices are playing an important role in business, education, and medicine as well as in other fields. IoT devices can provide convenience for human life in auxiliary medical treatment, 1 sleep detection, 2 and activity analysis. 3 Meanwhile, IoT devices may also be used by attackers, leading to privacy disclosure. 4 The IoT devices, which is of easy deployment and scalability, offer a choice instead of traditional desktop programs and greatly facilitate people’s daily life and work. IoT devices usually use Web application to provide services to users, so Web attack is also an effective method to attack IoT devices. Therefore, attacks against IoT devices can be launched from the Web application. For its accessibility, it may receive all kinds of attacks from the Internet easily. Meanwhile, its vulnerability is exacerbated due to its distribution and the complexity of its configuration. These factors are relevant to the fact that Web attacks are happening with increasing frequency, through which attackers retrieve or change sensitive data or even execute arbitrary code in remote systems.
Most attacks against IoT devices are based on Web applications. To deal with the various attack methods, it has been a trend for security researchers to apply machine-learning and deep-learning to web applications attack detection technique.
A trust-aware probability marking traceback scheme is proposed to locate malicious source quickly. 5 The nodes are marked with different marking probabilities according to its trust which is deduced by trust evaluation. The high marking probability for low trust node can locate malicious source quickly, and the low marking probability for high trust node can reduce the number of marking to improve the network lifetime, so the security and the network lifetime can be improved in this scheme. Wu et.al. 6 proposed a safety detection mechanism based on the analysis of big data. Fuzzy cluster analytical method, game theory, and reinforcement learning are integrated seamlessly to perform the safety detection. The simulation and experimental results show the advantages of this scheme in terms of high efficiency and low error rate.
Adeva and Atxa
7
proposed another attack identify method. This method helps extract metadata from the Weblog, including date, source address, size, type, and so on. Besides, it allows selecting the best feature through the feature assessment, classifying log samples or identifying attacks with Naive Bayes algorithm,
8
The above detection methods affect well since data sets have been given. However, there are still some problems that need resolving:
The lack of label data: There are numerous normal request samples while there are few variegated attack samples in real environment, which causes obstacles to the model’s learning and training.
The lack of sample classes: In the stage of training, if there are only SQL injection and XSS attacks in the sample data sets it is hard to identify command executions or new Payload attacks in real environment. Besides, Web applications run by different users vary greatly. Even SQL injection has numerous forms. Obviously, we cannot be sure to use a data collected in the past to train a model that can detect unknown attacks. It is easy to understand that the results will be deadly different in the experimental environment from the real environment.
The interpretability of the results: If the model identifies SQL injection, security researchers can find out the exact location of the attack payload so that they can maintain the Web applications consciously. But common Web maintainers may not understand the significance of the alarm. Even though they constrain the attacks at that very moment, they still cannot repair the Web applications. Because of that, the security risk still exists.
As services provided by IoT devices are often subject to Web attacks, to improve the security of IoT devices, an attack detection model based on Seq2Seq 23 to implement the shortage of current Web attack detection technologies is proposed in this article. This model helps acquire a great many of normal samples, identify kinds of Web attacks efficiently, and locate attack payload timely. We summarize the major contributions as following:
We propose a visual payload labeling model to detect network attack. Under the premise of using only benign training samples, our model has good precision and recall.
As our model relies on comparing predicted values and thresholds to classify benign and malicious Web requests, it can identify whether a Web request is malicious, rather than defend against a specific type of Web attacks.
Our model not only distinguishes normal requests from attack requests but also interprets the detection results by visually labeling the attack payloads. In the stage of encoding, we encode request samples from HTTP through the Bi-LSTM algorithm and maintain the context semantics in the request. In the decoding stage, we introduce the attention mechanism, calculate the probability distribution of each character in the sequence vector, and mark the exact location of the attack payload. The detect results of our model are interpretable. Website maintainers are able to locate the attack payload swiftly, repair security risks in time, and protect the data security of enterprises or organizations.
Web attack detection model based on Seq2Seq
Detection model framework
Figure 1 presents the whole framework of the Web attack detection model based on Seq2Seq. The model is mainly divided into three modules: data preparation module, attack detection module, and attack payload visualization module. In the data preparation module, pretreating original HTTP request samples, establishing vocabulary, generating sequence vectors that meet the model’s input requirements happend in sequence. In the attack detection module, the main task is to construct and train the attack detection model as well as testify and classify the test sample sets. In the attack payload visualization module, the attack payload is visually labeled, and normal elements (characters) are labeled as white but abnormal elements (characters) are labeled as red.

Diagram of detection model framework.
Data preparation module
Sample labeling
Sample cleansing and labeling play a key role in machine learning, as samples’ quality determines the quality of model training and the accuracy of subsequent detections. Through the observation of the data sets, we could conclude that the data of benign samples accords with expectations while mislabeled many malicious samples, and we found that the length of most wrongly labeled data requests is less than 20 bits. So, the first step is to delete all the POST and GET request data which is less than 20 bits, and then label the samples manually to ensure all our training samples are labeled correctly. Though we would delete some data wrongly, the sample data labeling is more accurate, guaranteeing the accuracy of the experiments. After cleansing, we store rest of the samples, labeling abnormal HTTP requests as “malicious” and normal HTTP requests as “benign.”
Establish vocabulary based on ASCII
Paper 20 applied the Webshell traffic detection technology which is based on deep-learning. Similar to the method introduced in that paper, the model in this article constructs sequence vectors by embedding characters. The first step is to establish vocabulary with the following steps:
We store the visible characters in the vocabulary, and the index number of each character is its corresponding ASCII code.
Per the autoencoder model introduced in section “Experiment and assessment,” we input <GO> first at the decoding sequence, index number 0, and output <EOS> last at the sequence, index number 2.
Setting the characters as <UNK> which are not in the vocabulary or we cannot identify, index number “4.”
The length of ordered column vectors needs to be filled into the same length to meet the requirements of Bi-LSTM. <PAD> is the filler word, index number “0.”
Link break “/r,” tab “t” is added to the vocabulary. Figure 2 shows the final vocabulary. Figure 3 elaborates sequence vectors after we encoding samples in one batch in training.

Normal request character embedded vocabulary.

Sample encode example.
Attack detection module based on Seq2Seq
Seq2Seq model framework
Figure 4 refers to Seq2Seq (we choose the Seq2Seq framework because its output length is uncertain, which we do not need modify the input vector) framework. As the figure shows, X = [X1, X2, X3, X4] refers to input sequences, and Y = [Y1, Y2, Y3] refers to output sequences. Encoder and decoder can be various neural network models or their combinations. We believe that the payload of a Web attack has a context, and Bi-LSTM can better capture the bidirectional semantic dependency, so after encoding with Bi-LSTM, this context can be expressed in the vector. Semantic Coding C refers to the encoding value of sequence X.
Encoder
At the stage of encoding, for the Encoder is Bi-LSTM, its hidden layer output is the splicing of farward and reverse LSTM hidden layer ouput. Shown as follows



f is the encoding function of Bi-LSTM,

A common simple method is to use the hidden layer output of the last moment as the semantic vector C, that is

2. Decoder
The decoding stage can be regarded as the inverse process of encoding. For the output

it can be abbreviated as

For the model that decoder is Bi-LSTM,


Basic framework of Seq2Seq model.
Attack detection algorithm based on measuring the loss of model
The last section introduced the basic framework of Seq2Seq. Seq2Seq needs modifying before it is applied to detect attacks. In Figure 5, we take training samples as input and output of the model at the same time, and this model is also called autoencoder. This model is almost the same as the Seq2Seq model diagram in Figure 3. The main difference is that the output layer also uses the same data as the input layer. It should be noted that in the decoding stage, the first input of the sequence is replaced by “<GO>,” and the last output of the sequence is replaced by “<EOS>.”

Basic framework of Seq2Seq model (Autoencoder).
To train only with positive samples and process attack detection, this article designed an attack detection algorithm based on measuring the loss of a model. The procedures are as follows:
To gain a model with slight loss by training a great many of benign sample sets.
To predict benign samples in test sets. Under normal circumstance, every sequence has one predictive value with rather low loss. The loss of all the sequences is counted and recorded as

Calculate the mean and standard deviation of

In the above formula, mean refers to calculate mean value, and std refers to calculate the standard deviation. C is a constant, and we need to adjust it in experiments, so that threshold can gradually approach the optimal threshold. Generally speaking, C should ensure that the threshold value is greater than the maximum value of
4. The model predicted benign samples and malicious samples at the same time. If the
Attack payload visualization module based on attention mechanism
Seq2Seq model with attention mechanism
To solve the problem that cannot explain the results of the conventional detection model, this section will optimize the Seq2Seq model using the attention mechanism and mark the specific location of attack payload using the characteristics of this mechanism, to realize the visualization function of attack payload. The optimized model is shown in Figure 6.
Encoder
After leading into the attention mechanism, the semantic vector C is obtained by weighted averaging the output H of encoder’s hidden layer, as follows


Seq2Seq model with attention mechanism.


For the score function, Luong et al. 24 defines the following three definitions, which can be selected according to the different problems

2. Decoder
The decoding stage is determined by the current time semantic vector

Finally, the predicted output

We should note that the output
Attack payload labeling principle based on attention mechanism
Formula (15) shows that the output
Assuming that the input of

Attention layer and output layer diagram.
Based on this conclusion, the following steps can be taken to optimize the model:
The test samples are predicted by the trained model, receive the output probabilistic sequence

In the formula,
2. Count all outputs of samples, set as

Calculate the mean value and standard deviation of

3. By adjusting the constant C, make sure the threshold value is guaranteed to be less than the minimum weight of benign samples in the test set, and greater than the maximum weight of malicious samples, such as Formula (20). Meanwhile, it is necessary to observe whether the sample labeling conforms to objective facts. If it does, the threshold value should be selected; otherwise, it will continue to adjust
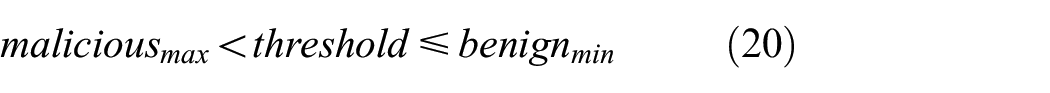
4. If a sequence in the test set is checked by the model, the model predicts the No.j element
Experiment and assessment
Data set
This article applied HTTP DATASET CSIC 2010 data set to to do experiments and make analysis. 25 After processing, we stored 20,331 pieces of benign samples and 16,243 malicious samples. According to the detection method introduced in this article, we divide data sets into three parts: training samples, testing samples, and detection samples. Among them, we take 30% benign samples randomly to do threshold test training, and 1001 benign samples and 1001 malicious samples randomly to do abnormal element threshold test. Away from that, this model only adopts benign samples in training, but in comparative experiments, it adopts benign samples and malicious samples simultaneously. The specific allocation of data sets is shown in Table 1.
Data set.

Environment for experiment
The model introduced in this article is mainly developed under Windows system. The code involved in the experiment is mainly based on Python’s tensorflow framework.
26
Function
Hardware and software configuration of experimental environment.

Experiment process
Classification threshold parameter optimization
In sections “Attack detection module based on Seq2Seq” and “Attack payload visualization module based on attention mechanism,” the calculation methods of threshold value of model classification and threshold value of exceptional determination have been introduced in detail, but the formula cannot directly calculate the final threshold value. Further experimental tests are necessary to get the optimal threshold value. Formula (10) shows that constant C needs to be adjusted to obtain a reasonable threshold value to achieve the goal of sample classification. We tested the accuracy change with a constant C from 1 to 7 in steps of 2, and specifically tested the accuracy with a constant 0. The relationship between threshold value and accuracy is shown in Table 3.
Threshold test results.

It is understandable that the higher the threshold is, the higher the accuracy of benign samples is, but the model also needs to detect malicious samples, so while ensuring the accuracy, the smaller the threshold, the more consistent with the classification standard of the model. As shown in the table above, when the constant C is 5 and 7, the accuracy no longer increases significantly, and the threshold value is 0.772084.
Threshold parameter optimization of abnormal elements
Because we cannot quantify the threshold value of the classification of abnormal elements accuracy, we only calculate an estimated value by Formula (19):
Initial value C = 0, step size = 0.1 and maximum value = 1.5;
Calculate threshold value by formula (19);
Ten malicious samples and 10 normal samples were printed randomly to observe whether to label the labels of attack payload;
If it does not meet the expectation, repeat (1) to (3) until it meets the expectation, and store the current threshold value.
After many rounds of experiments, we set the threshold value to 0.076589 (constant C = 1.3), when the output meets the target of labeling attack payload. Figure 8 is an example of labeling attack payloads.

An example of labeling attack payloads.
Experiment indicators
To get better evaluation of the attack detection model based on attention mechanism and Bi-LSTM algorithm, the experimental results will be evaluated using Confusion Matrix. The obfuscation matrix, also known as Error Matrix, can be used to visually evaluate the performance of classification model algorithms, as shown in Table 4.
Confusion Matrix.

TP: true positive; FP: false positive; FN: false negative; TN: true negative.
The matrix has the following four categories of indicators:
True positive (TP): An attack request and the result of model judgment is also a sample of the attack request.
False positive (FP): Samples which are real normal requests but whose model judgment results are attack requests.
True negative (TN): Samples that are real normal requests and the results of model judgment are also normal requests.
False negative (FN): Samples that are attacking requests but the model judges the results as normal requests.
Based on the above definition and the detection of attack behaviors in this article, we can consider it as a binary classification, which can deduce the performance indicators of this model



The precision reflects the proportion of real malicious requests in the sample in which the results of model judgment are malicious requests; the recall reflects the proportion of malicious requests correctly identified by the model, and the F1 score is the harmonic mean of the precision rate and recall rate.
Results
To make the experiment’s objective, we compare results from the model introduced in this article with the other four attack detection models:
SVM: Characteristic construction feature vectors are extracted artificially, and then the samples are classified by SVM algorithm.
TF-IDF_RF: Word frequency vectors are extracted from samples by TF-IDF, and then the samples are classified by Random Forest.
Word2vec_MLP: The samples are segmented artificially, and then word vectors with semantics are constructed by Word2vec. At last, the samples are classified by MLP algorithm.
Character_CNN: Sequence vectors are constructed by character embedding. Finally, samples are classified by CNN algorithm.
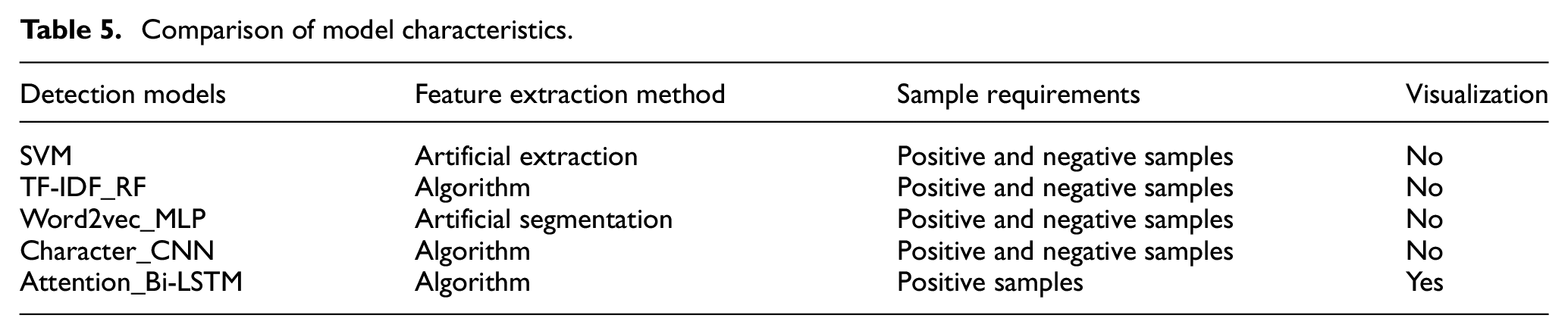
Table 5 shows that they use different methods to extract features: SVM extracts features artificially, Word2vec_MLP needs semantic model constructed artificially, and the rest three models extract features with the help of algorithms. As for the requirements toward samples, the Attention_Bi-LSTM model in this article only needs to train positive samples, but the rest four models all need samples with positive and negative labels. For the interpretability of results, only the model introduced in this article achieves attack visualization.
Comparison of model characteristics.
The comparative results of experimental performance indexes are shown in Table 6. Character_CNN has a precision rate of 99.48%, but the recall rate is only 94.66%, indicating that the model has a lower false positive rate (FPR) but a higher false negative rate. Our model does not have the precision accuracy, but the recall rate is 97.60%, and the F1 value is 97.31%, means that our model has better comprehensive ability. The attention_Bi-LSTM model performs better in the aspect of precision, recall, F1 value than SVM, TF-IDF_R, and Word2vec_MLP. Although Attention_Bi-LSTM has lower precision than Character_CNN, it does better in recalling, and it has a higher F1 value. In summary, on the premise of only positive training samples, Attention_Bi-LSTM performs best in classification. Character_CNN and Word2vec_MLP are good. The performance of TF-IDF_RF and SVM is worse.
Model performance indicators.

Figure 9 shows a comparison of the receiver operating characteristic (ROC) curve of five models. The Attention_Bi-LSTM model achieved the best true positive rate (TPR) at smaller FPR, proving that our model has better accuracy than other models. In terms of the degree of automation of the model, our model has higher accuracy using only benign samples for training, and do not need extract features artificially. Although Character_CNN has higher precision than Attention_Bi-LSTM, our model is better than the other four models in terms of construction, training, and accuracy.

Comparison of ROC curves of different models.
Conclusion
Based on experimental data sets, tests on Attention_Bi-LSTM, SVM, TF-IDF_RF, Word2vec_MLP, Character_CNN are processed. The results indicate that SVM and TF-IDF_RF have relatively low detection rate; their precision is 92.07% and 93.81%, respectively; their recall is 94.95% and 89.12%, respectively. The detection and recall of Word2vec_MLP are of average, 96.28% and 96.29%, respectively.
That means extracting word vectors by Word2vec can maintain samples’ semantics and make classification as well. The precision of Character_CNN reaches 99.48%, but the recall is 94.66%. It shows that Character_CNN has a high false alarm rate. The precision, recall, and F1 values of Attention_Bi-LSTM are as high as 97.02%, 97.60%, and 97.31%, respectively. Also, Attention_Bi-LSTM has the largest AUC (the area under the ROC curve). It shows that on the premise of benign training samples alone, this model can detect attack requests effectively and has rather high precision and recall. Besides, its exclusive function of labeling attack payload helps to achieve attack visualization.
However, the model has some shortcomings. The model constructs sequence vectors by using character embedding. Although it shortcuts the steps of artificial word segmentation and feature extraction, it enlarges calculation. There are only around 20,000 data sets, but the training time is more than 10 h. We will consider adopting the embedding method of N-gram to process experiments or improve hardware resources of experiments.
Footnotes
Acknowledgements
The authors thank anonymous reviewers and editors for providing helpful comments on earlier drafts of the manuscript.
Handling Editor: Kien Nguyen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by National Key Research and Development Program (2016YFE0206700 and 2018YFB0804503) and the Fundamental Research Funds for the Central Universities.