
Abstract
Tensor compression algorithms play an important role in the processing of multidimensional signals. In previous work, tensor data structures are usually destroyed by vectorization operations, resulting in information loss and new noise. To this end, this article proposes a tensor compression algorithm using Tucker decomposition and dictionary dimensionality reduction, which mainly includes three parts: tensor dictionary representation, dictionary preprocessing, and dictionary update. Specifically, the tensor is respectively performed by the sparse representation and Tucker decomposition, from which one can obtain the dictionary, sparse coefficient, and core tensor. Furthermore, the sparse representation can be obtained through the relationship between sparse coefficient and core tensor. In addition, the dimensionality of the input tensor is reduced by using the concentrated dictionary learning. Finally, some experiments show that, compared with other algorithms, the proposed algorithm has obvious advantages in preserving the original data information and denoising ability.
Keywords
Introduction
To meet the great burden in the process of transmission and storage brought by multidimensional (MD) signal processing and complete efficient extraction of signal features, more and more researchers are focusing on the tensor representation of MD signals. The study of tensor compression algorithms has become a hot research topic today.
In tensor processing, the most basic methods are canonical polyadic (CP) decomposition and Tucker decomposition. The CP decomposition serves the tensor as a sum of finite rank-one tensors. 1 Tucker decomposition decomposes a tensor into a core tensor and matrix product on each modulo. 2 Due to the practical requirement, many tensor processing algorithms, such as non-negative tensor decomposition, 3 non-negative Tucker decomposition, 4 and high-order singular value decomposition (HOSVD) decomposition,5,6 have been derived by adding different constraints. To extract and fuse data features effectively, so as to realize the effective recognition and transmission of data, the researchers proposed two types of compression algorithms based on the abovementioned tensor processing methods. The one is based on the tensor decomposition, and the other is based on the sparse representation of the tensor. The following two aspects of research work will be described in detail.
On one hand, Kuang et al.
7
proposed a tensor-based big data scalar dimensionality reduction method, in which the new data are projected into the tensor modulus expansion matrix space to achieve dimensionality reduction. In addition, the kernel-based tensor sparse dictionary learning algorithm (K-PCD) based on CP decomposition was proposed. It is an extension of the
On the other hand, the sparse representation of the tensor was applied to the processing of MD signals. Due to the equivalence of the tensor Tucker model and the Kronecker representation, the tensor can be defined as a representation of a given Kronecker dictionary with certain sparsity, such as multidirectional sparsity and block sparsity. 12 The corresponding Kroneker orthogonal matching pursuit (Kroneker-OMP) and N-way block OMP (N-BOMP) algorithms were also used to recover MD signals with fixed dictionaries. In addition, a dictionary learning method based on tensor factorization was proposed, 13 and some approximate tensor algorithms were proposed based on tensor decomposition14,15 or tensor low rank approximation.16,17 However, in the process of tensor dictionary learning, new noise will be generated, affecting the accuracy of data,18,19 and the determination of sparsity will bring some difficulties to tensor compression.
To solve the abovementioned problems, this article utilizes two dimensionality reduction ideas of the multilinear principal component analysis (MPCA) and the concentrated dictionary learning (CDL) to realize the tensor compression. First, the tensor is sparsely represented and Tucker decomposed to obtain the dictionary, sparse coefficient, and core tensor. Next, the results of the first step are fused to obtain a new sparse representation through the relationship between the sparse coefficient and core tensor. Furthermore, the dictionary of the second step is dimensionally reduced by the CDL algorithm to complete the dimensionality reduction of the input tensor. Finally, experimental results reveal that the proposed algorithm has significant advantages in retaining information of original data and denoising ability compared with other algorithms.
The rest of this article is organized as follows. Section “The proposed algorithm” introduces the proposed algorithm in detail. In the “Experiments” section, some experiments are examined to verify the proposed algorithm. Finally, the “Conclusion” section concludes this work.
The proposed algorithm
As depicted in Figure 1, the process of the proposed algorithm is divided into three parts. The first step is the sparse representation and Tucker decomposition of tensors. A new sparse representation is constructed in the second step. The dictionary dimensionality is reduced by using CDL algorithm in the third step. Finally, tensor compression is completed.

The flow chart of the proposed algorithm.
Before describing the algorithm in detail, let us introduce the sparse representation and Tucker decomposition of the tensor, which will be useful in the sequel.
Given a tensor signal

Note that Caiafa and Cichocki
21
pointed out the relationship between the Kronecker model and Tucker representation. Given the

by stacking all the one-mode vectors.22,23 After the above analysis, the sparse representation of the tensor
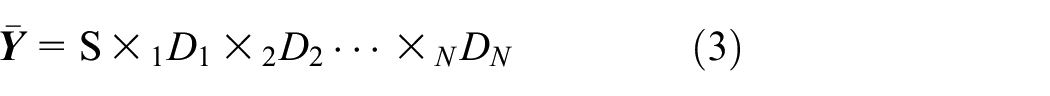
where
Given a tensor signal

where

Tucker decomposition of a three-order tensor.
More generally, for the

Tensor dictionary representation
From the above analysis, it can be found that equations (3) and (5) are similar for the same tensor. Furthermore, the sparse coefficient tensor in equation (3) is approximately equal to the core tensor in equation (5), that is,

Substituting equation (6) into equation (3), we get

The properties of the tensor operations mentioned in Zeyde et al. 26 show that
When

When

Therefore, from equations (8) and (9), the objective function can be obtained
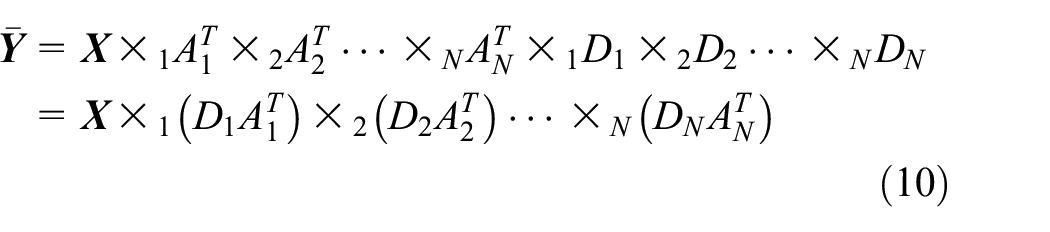
Let

Substituting equation (11) into equation (10), we get
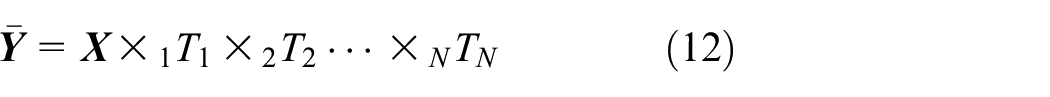
where

where
Dictionary preprocessing
In the dimensionality reduction process of
The main idea of the CDL algorithm is based on the conclusions drawn in previous literature.28–30 For the original signal

where
To make

where

Then, the singular value is updated as
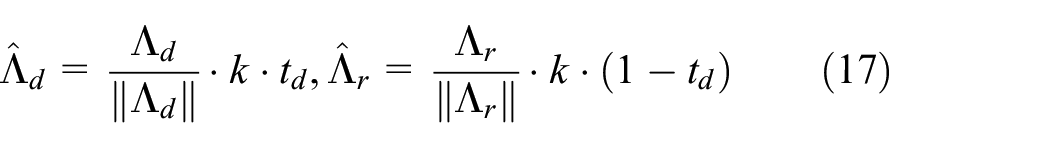
where

Finally, gain a new dictionary

where
Dictionary update
In the CDL algorithm, the two-dimensional signal is used, and the dictionary can be updated by the K-SVD algorithm. However, in the high-dimensional tensor, the K-SVD algorithm cannot be used for dictionary update of high-dimensional signals. Here, the tensor-based multidimensional dictionary learning algorithm (TKSVD) 31 is utilized to complete the dictionary update process for high-dimensional tensor signals. There are two points to be noticed in the TKSVD algorithm: (1) different from other two-dimensional signal learning methods, according to the definition of the tensor norm, the MD dictionary learning method is got

where

where † represents a pseudo inverse matrix, that is,

The
The detailed algorithm flow of tensor compression is depicted in Algorithm 1. It can be seen from the algorithm flow that the proposed algorithm only contains one loop iterative process. In other words, when the dictionary is updated, only steps 5–9 are performed. Assume that there are

Experiments
In this section, the RE is used to test the information retention ability of the proposed algorithm. In this regard, it will be compared with the principal component analysis (PCA), maximum noise fraction (MNF) algorithm, and MPCA. In addition, signal-to-noise ratio (SNR), peak signal-to-noise ratio (PSNR), and structural similarity index measurement (SSIM) are applied to test the denoising ability of the proposed algorithm. Here, it will be compared with PCA, the binary wavelet threshold shrinkage (PCA-Bish), and MPCA.
Reconstruction performance analysis
The dataset of the hyperspectral image library published by the Computer Vision Laboratory of the Department of Computer Science of Columbia University is applied to test the ability of retaining the original data information. The RE is used to describe the closeness of the reconstructed tensor to the original tensor, that is

Obviously, the reconstructed tensor is closer to the original tensor with a smaller
Here, the spatial size of each hyperspectral image is

The original image: (a) feather, (b) painting, (c) hair, and (d) statue.
To test the performance of algorithm reconstruction, the hyperspectral image is compressed by the proposed algorithm according to the compression rate (CR) of 0.04, 0.08, 0.14, 0.21, and 0.27, respectively. Under the same CR, a comparison of PCA, MNF, and MPCA, RE in the 31st spectral channel is given (see Figure 4).
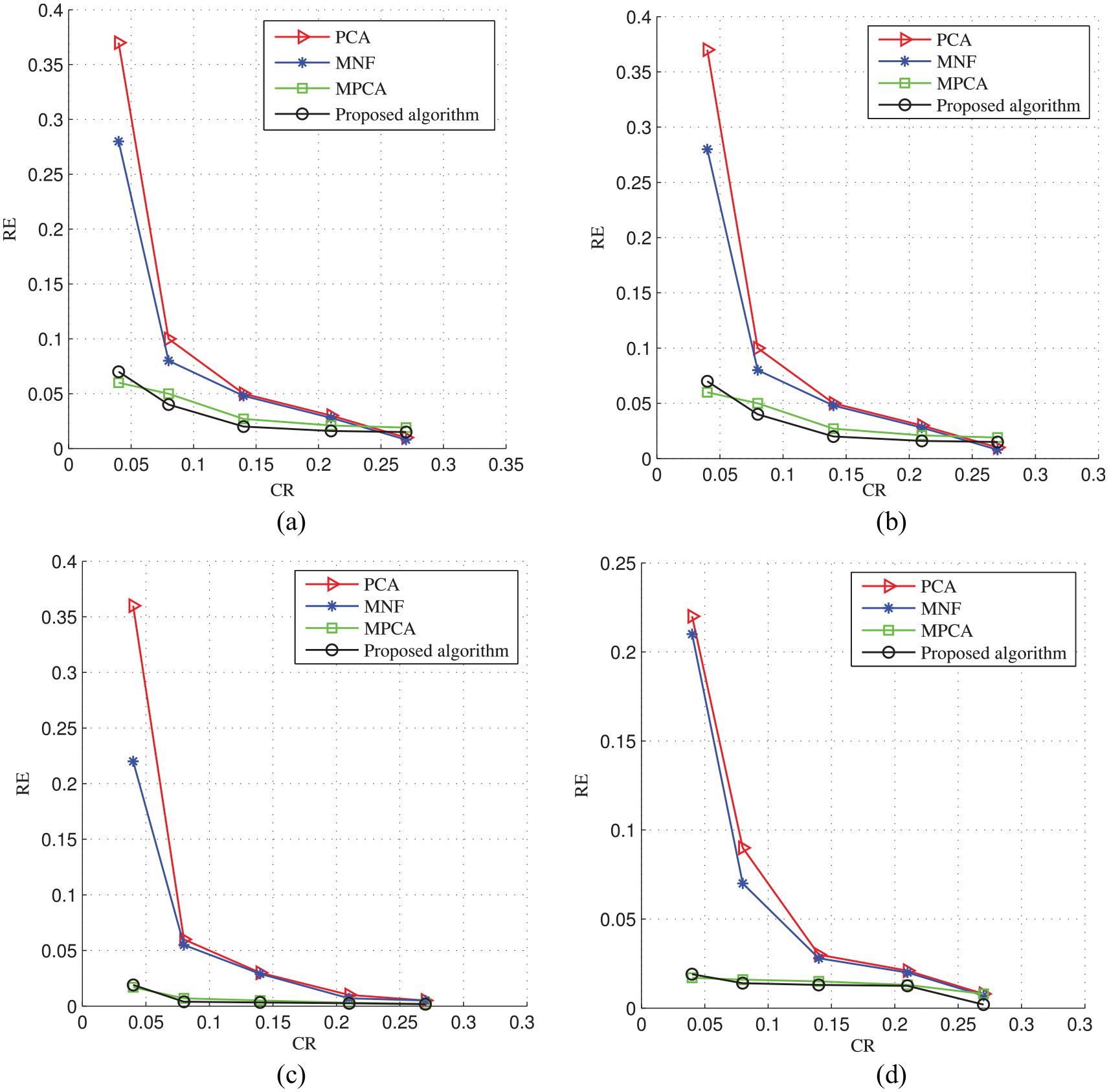
RE of hyperspectral images reconstruction under different CR: (a) feather, (b) painting, (c) hair, and (d) statue.
In the curves of Figure 4(a)–(d), the closer to the lower left of the figure, the better the performance of all algorithms. It can be seen that in the compression and reconstruction experiments of hyperspectral images, the RE of the proposed algorithm is lower than PCA and MNF under the same CR. Especially when the CR is extremely low, the RE of the proposed algorithm is slightly higher than that of the MPCA algorithm. But when the CR increases, the RE of the proposed algorithm is higher than that of the MPCA algorithm, so the overall reconstruction performance is better than the MPCA algorithm.
To verify the practicability, the CR is set to 0.01, and the original image of the 31st spectral channel and the reconstructed image of the proposed algorithm are shown in Figures 5 and 6, respectively. The RE of the reconstruction of the four groups of hyperspectral images are 0.0251, 0.0239, 0.0211, and 0.0195, respectively. Obviously, for the image hair and the statue with simple texture, the RE of reconstruction can be controlled within 0.03. Therefore, the proposed algorithm has a good practical value.

Original images (spectral channel 31): (a) feather, (b) painting, (c) hair, and (d) statue.

Reconstructed images (spectral channel 31): (a) feather, (b) painting, (c) hair, and (d) statue.
Robust analysis
The spectral data “splib06a” collected by the American Bureau of Geological Survey’s Digital Spectrum Laboratory using the AVIRIS (airborne visible/infrared imaging spectrometer) sensor Indian Pines 32 are utilized as a dataset to test the denoising ability of the proposed algorithm.
Here, the noise is the white Gaussian noise. To verify the effectiveness of the proposed algorithm in denoising, it is compared with the following two denoising algorithms: (1) PCA denoising algorithm (abbreviated as PCA algorithm) 33 and (2) denoising algorithm combined with PCA and 2D PCA-Bish algorithm. 34
Figures 7 and 8 show two bands of randomly selected data from the simulated data Indian Pines with noise (

Compression performance of different algorithms (spectral channel 25): (a) original image, (b) noisy image, (c) PCA, (d) PCA-Bish, and (e) proposed algorithm.

Compression performance of different algorithms (spectral channel 35): (a) original image, (b) noisy image, (c) PCA, (d) PCA-Bish, and (e) proposed algorithm.
It can be seen that although the data amount of the image is greatly compressed, from the visual effect, the difference between the reconstructed image and the original image is not obvious. Thus, in addition to visual effects, SNR, PSNR, and SSIM are used to compare the performance of different methods, and they are defined as
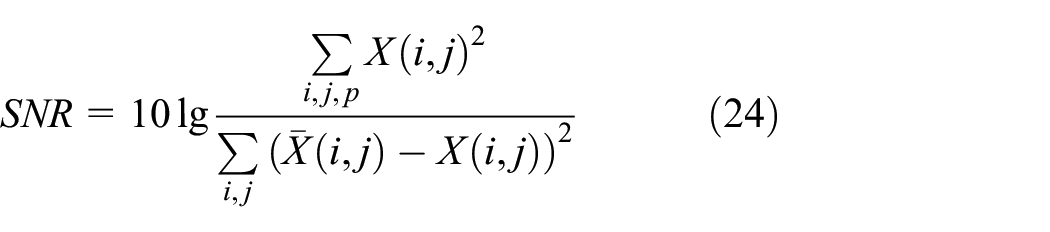
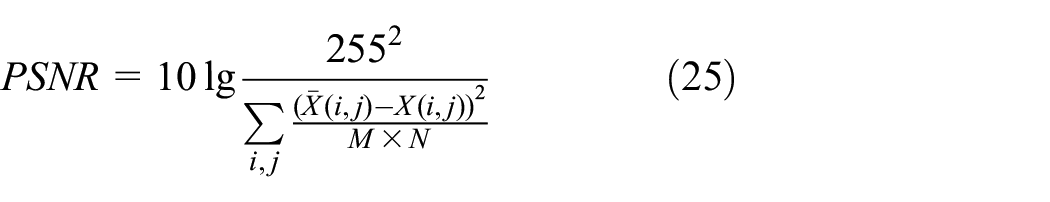

where
The Indian Pines is processed by PCA, PCA-Bish, and the proposed algorithm, respectively. And SNR, PSNR, and SSIM are used to judge the robustness of the proposed algorithm.
It can be seen from the mean and Std in Table 1 that under the three kinds of noise standard deviation, the proposed algorithm has less noise than the other two algorithms, and the effect is more obvious under the condition of higher noise.
Comparison of denoising performance of three denoising methods (SNR/dB).
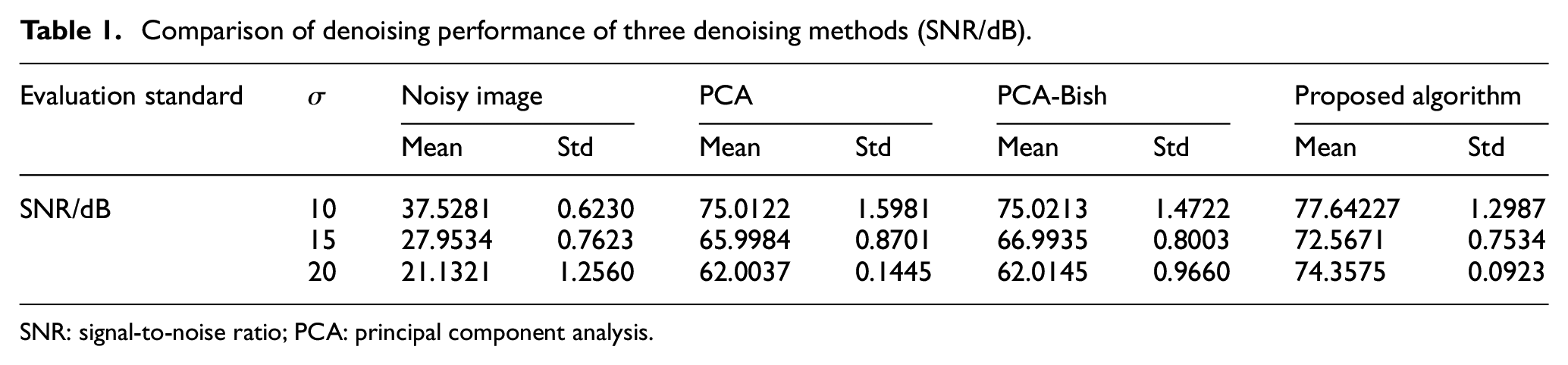
SNR: signal-to-noise ratio; PCA: principal component analysis.
Table 2 displays that under the three kinds of noise standard deviation conditions, PCA and PCA-Bish compression reconstructed image quality are similar, but the image quality processed by PCA is higher than PCA-Bish image quality when the noise is larger. Compared with the proposed algorithm, PCA has lower reconstructed image quality. Therefore, under noise conditions, the performance of the proposed algorithm is better than PCA and PCA-Bish.
Comparison of denoising performance of three denoising methods (PSNR/dB).

PSNR: peak signal-to-noise ratio; PCA: principal component analysis.
Table 3 illustrates the compression performance by using SSIM. It can be seen that the SSIM values of the three algorithms are different in three cases. But considering SSIM and Std, the proposed algorithm is obviously higher than other two algorithms, and the reconstructed image is more similar to the original image. In general, due to the large number of hyperspectral image bands, the visual effect evaluation of a certain band image is insufficient to illustrate the effectiveness of the proposed algorithm. For this purpose, data analysis of all bands is required.
Comparison of denoising performance of three denoising methods (SSIM).
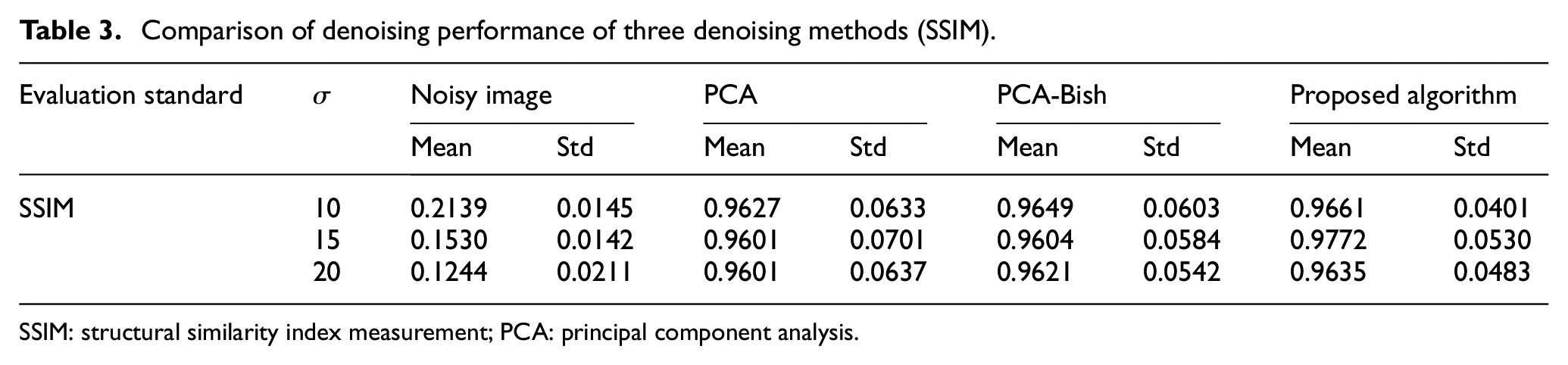
SSIM: structural similarity index measurement; PCA: principal component analysis.
By observing the data in Tables 1–3, it can be seen that the trends of SNR, PSNR, and SSIM are basically the same. The denoising effects of the three methods are also analyzed: (1) they have no obvious advantage when the noise standard deviation is very low. This is mainly because the noisy image group generated by PCA conversion retains most of the image information when the noise is very small. The three methods except PCA will cause the loss of image detail information in denoising, and the PCA method directly uses the principal component image, so there is no such problem. (2) When the standard deviation of noise gradually increases, the advantage of the proposed algorithm becomes more obvious.
Conclusion
In this article, to solve the problems of information loss and new noise in previous work, a tensor compression algorithm using Tucker decomposition and dictionary dimensionality reduction has been proposed. The sparse coefficient and core tensor have been used to relate the sparse representation of the tensor with the Tucker decomposition. In the new sparse representation, the dimensionality reduction of the dictionary has been applied to the dimensionality reduction of the mapping matrix, and the tensor compression has been implemented. Finally, some experiments show that compared with other algorithms, the proposed algorithm can better preserve the original data information, and in the noise environment, the denoising ability of the proposed algorithm is stronger and the system is more stable.
In addition, it has to be mentioned that the approximate relationship between the sparse coefficients and core tensors plays an important role in the proposed algorithm. In the approximation process, there must be a certain approximation error. Therefore, how to reduce the error in the process is a problem worthy of study in the next research work. Meanwhile, deep learning has been widely used in many fields such as sentiment analysis35,36 and automatic modulation classification; 37 thus, how to effectively apply deep learning to the field of tensor signal compression may give rise to a research field of interest.
Footnotes
Acknowledgements
The authors are grateful to the anonymous reviewers and the editor for their valuable comments and suggestions.
Handling Editor: Hongxiang Li
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the Natural Science Foundation of China (Grant Nos. 61702066 and 61903056), Major Project of Science and Technology Research Program of Chongqing Education Commission of China (Grant No. KJZD-M201900601), Chongqing Research Program of Basic Research and Frontier Technology (Grant Nos. cstc2017jcyjAX0256, cstc2019jcyj-msxmX0681, and cstc2018jcyjAX0154), and Project Supported by Chongqing Municipal Key Laboratory of Institutions of Higher Education (Grant No. cqupt-mct-201901).