
Abstract
Nodes in a wireless sensor network are normally constrained by hardware and environmental conditions and face challenges of reduced computing capabilities and system security vulnerabilities. This fact calls for special requirements for network protocol design, security assessment models, and energy-efficient algorithms. Data aggregation is an effective energy conservation technique, which removes redundant information from the data aggregated from neighbor sensor nodes. How to further improve the effectiveness of data aggregation plays an important role in improving data collection accuracy and reducing the overall network energy consumption. Unfortunately, sensor nodes are normally deployed in an open environment and thus are subject to various attacks conducted by adversaries. Consequently, data aggregation brings new challenges to wireless sensor network security. In this article, we propose a novel secure data aggregation solution based on autoregressive integrated moving average model, a time series analysis technique, to prevent private data from being learned by adversaries. We leverage the autoregressive integrated moving average model to predict the data volume in sensor nodes, and update and synchronize the model as needed. The experimental results demonstrate that our model provides accurate predictions and that, compared with competing methods, our solution achieves better security, lower computation and communication costs, and better flexibility.
Keywords
Introduction
As a distributed sensor network, wireless sensor networks (WSNs) have been widely used in many different domains, such as environmental monitoring, intelligent transportation, medical care, and military affairs. As shown in Figure 1, a WSN combines the information world with the real world to realize the convenient Internet of Things (IoT) project. In the harsh wild, people cannot stay for a long time, and there are no fixed network facilities for communication. In contrast, due to their self-adaptive and self-organizing properties, ad hoc WSNs are particularly suitable for applications in such situations. A massive number of sensor nodes can be deployed to collect and process monitoring data and send it to a remote control terminal by wireless communication. Since WSNs are normally deployed in unattended open environments with limited resources and are of a large network scale, there are many security challenges in data sensing, collection, transmission, and processing. Among them, data aggregation and network security are two important hot research topics. Due to a large number of nodes and a large amount of data generated in WSN, end-to-end security is difficult to achieve. Nodes in WSN have a limited communication range and noise or collision may cause transmission failure or error. Considering the aggregated data, privacy protection is necessary. Attackers will attempt to obtain or tamper with private data using link eavesdropping and nodes compromising. For private data protection, methods such as data perturbation, anonymity, or encryption can generally be used to accomplish data aggregation or query with no leakage of private data.

An illustration of a wireless sensor network system.
Data aggregation can internally aggregate raw data collected from sensor nodes and eliminate redundant data. It reduces the number of transmissions and communication costs and thus extends a network’s overall lifecycle. In the literature, there are two ways of realizing data aggregation in WSNs. The first way is to improve raw data integrity and security. WSN nodes are often affected by some environmental factors, and the data collected by sensor nodes may be imprecise, noisy, and sometimes even fake. This requires data authentication to ensure integrity and security. Although the authentication method improves data validity, it leads to a longer aggregation time and increased energy consumption and reduces a network’s aggregation capability. Some communication protocols have better data aggregation capability, but lack considerations on system security. The second is to utilize secure aggregation algorithms. Due to the similarity of the data sampled from neighbor nodes, the impact of some individual malicious data can be reduced by an aggregation processing on raw data. This line of research also has some limitations. The aggregation nodes cannot always obtain multiple non-redundant valuable data points, and the effect may be different in various industrial applications. Data aggregation can obtain better results in time-driven applications, for example, air pollution index monitoring. In contrast, it is less effective for event-driven applications, such as fire alarm monitoring and positioning, and might even mishandle some important information.
In terms of network security, asymmetric encryption is not suitable for WSNs, and symmetric encryption cannot solve all security problems as well. There is a plethora of factors that can affect the security of WSNs. When designing a network system model, how to evaluate its overall security and how to avoid data damage or loss and system crashes are of practical importance.
WSN nodes are usually composed of low-power sensors equipped with antennas and small computing units, which are used to monitor the surrounding environment and transfer data to the base station. For a battery-powered sensor node, the biggest challenge is how to reduce energy consumption as much as possible and extend the lifecycle of the network because computation and communication consume the most energy.
Rault et al. 1 listed energy-saving measures in WSNs from different perspectives, including energy collection and transmission. Among all the approaches, data aggregation was considered to be an effective energy-saving method. Data aggregation integrates the data of sensor nodes and returns the required or valuable data to users. The key of data aggregation is to remove redundant data transmitted in WSNs, which reduces the energy cost by cutting down the amount of data transmitted.
Networks might suffer from internal and external attacks in the data aggregation process. 2 Researchers have proposed several effective encryption schemes for WSNs, which can effectively resist external attacks, but need to consider the problem of energy consumption. Since attackers will try to compromise sensor nodes, internal attacks are generally more harmful. They may lead to the leakage of private data and keys. Furthermore, attackers can tamper with sensor nodes’ private data, leading users to wrong aggregation nodes, and in turn directly mislead users’ decision making in the corresponding scenario. Traditional data aggregation algorithms include Bayesian probability theory, 3 Dempster–Shafer algorithm, 4 Markov random field theory, weighted average method, and Kalman filter algorithm. Some of the recent research results focus on improving the limitations of these traditional algorithms. With the development of relevant technologies, some researchers introduced new theories, such as information entropy, 5 fuzzy theory, 6 and neural network, 7 to data aggregation in order to improve aggregation accuracy.
Madden et al. 8 presented the tree structure–based tiny aggregation (TAG) protocol for aggregation in low-power distributed wireless environments. In this protocol, a WSN is considered as a connected graph whose nodes are the sensor nodes. At the beginning of data aggregation, each child node transfers data to the base station along the layers in the aggregation tree. Avokh and Mirjalily 9 proposed a dynamic balanced spanning tree (DBST) for data aggregation, which considers several criteria to balance the energy consumption among sensor nodes. DBST not only minimizes the maximum energy consumption among the sensor nodes, but also balances the traffic load in the network by a dynamic design of the routing tree. Based on locality sensitive hashing (LSH) algorithm, Patil and Kulkarni 10 introduced support vector machine (SVM) to reduce data redundancy and eliminate the abnormal sensor nodes sending wrong data. Mantri et al. 11 presented a solution for effective data gathering with in-network aggregation using the bandwidth efficient heterogeneity aware cluster based data aggregation (BHCDA) algorithm. It considers a network with heterogeneous nodes in terms of energy and mobile sink to aggregate data packets. A novel cluster-based strategy for eliminating redundancy in the data dissemination process was proposed by Ramachandran et al. 12 Obviously, for multi-node prediction, the overall computation cost in the network significantly increases, but the amount and frequency of communication are largely reduced.
Tulone and Madden 13 proposed a method to approximate the values of sensors in a WSN based on autoregressive (AR) models. When the prediction error exceeds the threshold value of 13, a node synchronizes data with the base station and transmits new data. This scheme does not take into account the time slot of data collection and transmission. Frequently updating the model will lead to degraded network service quality and high delay. Moreover, updating the model of a node requires interactions with the base station. When the node is far away from the base station, it will cause high communication overhead.
Lu et al. 14 proposed a distributed data aggregation scheme based on an autoregressive moving average (ARMA) model. It sets an observation window and measures the prediction error according to the size of the observation window. Similarly, autoregressive integrated moving average (ARIMA) is also used to model historical data.15,16 For data produced in WSNs, ARMA proposed for stationary time series can reach high accuracy, but the complexity of ARIMA brings additional computation overhead to the sensor nodes. Based on the AR model, Ghaddar et al. 17 adjusted the coefficients of the model using predicted residuals to avoid the process of multiple modeling processes. Unfortunately, all the above prediction-based data aggregation schemes do not consider data privacy, and thus are vulnerable to privacy attacks.
In the context of data aggregation, security requirements are mainly reflected in terms of data confidentiality, integrity, and immediacy. Most of the early secure data aggregation schemes made use of hop-by-hop encryption, 18 where each packet must experience a decryption–aggregation–encryption process at the next hop. If an intermediate node is compromised, the private data in itself and its children may leak. Moreover, the nodes execute encryption and decryption operations when sending data packets to the base station, which brings computation overhead and network delay. The end-to-end secure data aggregation scheme well solves the above problems. 19 In this scheme, once data are encrypted, any intermediate node cannot decrypt it. Only after the base station receives an aggregated data packet, it can decrypt the data to extract the plaintext information. However, it cannot prevent attackers from actively tampering with data or injecting fake packets into the network.
Privacy homomorphism was proposed by Rivest et al., 20 which directly performs calculations on encrypted data. It well fits WSNs’ end-to-end confidentiality protection requirements. Castelluccia et al. 21 proposed a simple and provably secure additively homomorphic stream cipher (CMT) that allows efficient aggregation of encrypted data. The key is produced using a pseudorandom number generator, making the scheme more feasible for WSNs. Based on CMT, Papadopoulos et al. 22 devised the secure in-network processing of exact SUM (SIES) queries method. It leverages the idea of secret sharing to protect the integrity of a data aggregation process and adds the aggregation cycle count to protect data instantaneity. Li and Gong 23 proposed a network coding scheme based on the homomorphic message authentication code (MAC) for integrity protection. It requires each leaf node to share a key with the base station. However, if a leaf node is compromised, its key information will be unveiled, which further jeopardizes the entire network’s security. Homomorphic encryption–based data aggregation schemes have drawbacks such as malleability, unauthorized aggregation, and limited aggregation functions. To solve these problems, Zhong et al. 24 proposed a secure data aggregation scheme by combining homomorphic encryption technology with a signature scheme. Gopikrishnan and Priakanth 25 proposed a hybrid secure data aggregation (HSDA) to provide high secure data aggregation in an energy-efficient way, which implements an end-to-end symmetric key cryptography for secure authentication using shared public key and uses hop-by-hop asymmetric key cryptography with the private keys of each node for data integrity and confidentiality.
Being the continuation of prediction-based secure data aggregation, the exponential smoothing data aggregation (ESDA) 26 introduced the exponential smoothing method to time series processing, which has the advantages of less transmission and higher security. He et al. 27 presented a cluster-based private data aggregation (CPDA) scheme by introducing the secure multi-party computation (SMC) to data aggregation in WSNs. First, the sensor nodes are formed randomly into clusters. Then, after encrypting and cross-summing, the data collected by the sensor nodes are transmitted to the corresponding cluster heads. Finally, data aggregation in cluster heads and among the clusters will be executed, and the final results are sent to the base station. The CPDA scheme can effectively preserve data privacy, but lead to the increasing computation and communication overhead. In order to reduce the communication overhead, Zhang et al. 28 proposed a privacy-preserving data aggregation protocol called rotation-based privacy-preserving data aggregation (RPDA), which is suitable for additive aggregation. The protocol protects the actual data from other nodes based on a rotation scheme and achieves accurate aggregation results. Considering IoT-enabled applications, Yu et al. 29 proposed a cluster-based data analysis framework using recursive principal component analysis, which can aggregate the redundant data and detect the outliers in the meantime. Vinodha and Anita 30 presented a comprehensive survey on existing privacy preserved data aggregation techniques for WSN, which explored the various mechanisms for data aggregation for preserving energy of sensor nodes by eliminating the redundant data transmission. It was indicated that the topology of nodes had a significant impact on the performance of the data aggregation schemes. By comparing and analyzing on artificial intelligence (AI)–based data aggregation techniques in WSNs, Kumar et al. 31 designed a modified protocol, which is better in terms of network lifetime and throughput of the networks.
To sum up, data aggregation is an important means to reduce the amount of data transmission, which can indirectly improve network lifecycle and bandwidth utilization. In the process of data aggregation, privacy protection is the core, which requires us to reduce data traffic, computation cost, and energy consumption while preserving data privacy.
In this article, we introduce the ARIMA model, a technique for time series analysis, to data aggregation, and propose an improved data aggregation scheme, which offers high security, low computational and communication costs, high accuracy, and better flexibility. The experimental results confirm the desirable performance of our ARIMA model–based solution.
The rest of the article is organized as follows. In section “System model,” we introduce the network model, security model, and attack model. In section “Proposed method,” we describe the aggregation method and privacy protection strategy based on the ARIMA model. The experimental results are presented in section “Experimental results and analysis.” Finally, we conclude the article in section “Summary and outlook.”
System model
Network model
Sensor nodes in a network can be divided into three categories, namely the base station, intermediate nodes, and leaf nodes. The base station is located on the top of a WSN, which is responsible for connecting terminal devices and sending aggregated (query) results to users. An intermediate node, also called a cluster head, is in charge of processing data within the cluster. A leaf node collects and sends raw data.
Different from a tree structure, the intracluster relationship in this scheme is a planar data link, and we mainly consider the sum calculation in this article. With slight modifications, the model is also suitable for more complicated aggregation operations, for example, computing the mean and the variance.
A query operation is defined as
The network model has the following characteristics:
The
Each node has the same communication range
Each node has the same initial energy sufficient to support the proposed scheme.
The communication energy cost of each node is different.
The base station knows the exact location of each node.
The proposed model is based on a topology of TAG tree aggregation, and the aggregation process can be divided into three steps. First, non-cluster head nodes use the ARMA model to model historical data and transmit the model parameters and historical data to the cluster head. Then, the cluster head calculates the data of each node at the next time and waits for messages from these nodes. Finally, the cluster head performs data aggregation processing as needed.
Security model
This scheme is based on the semi-honest model, that is, the participating nodes follow the protocol completely, but they will attempt to obtain the private data of other participating nodes. Meanwhile, an attacker will try to eavesdrop the original data and compromise some nodes to tamper with the aggregated data.
In this article, we use the key distribution mechanism, which includes key pre-distribution, shared key discovery, and key pair establishment. In the key pre-distribution stage, a key pool with
Attack model
An attacker may monitor the wireless channel to obtain a node’s private data or compromise an internal sensor node to tamper with uploaded data. To this end, the purpose of our proposed method is to protect data privacy and determine whether an internal node has been tampered with according to a threshold. Moreover, the energy cost also needs to be considered.
Proposed method
Data collection is to transmit sensory data from multiple sensor nodes to the base station for further processing. Due to limited energy, sensor nodes usually do not send data directly to the base station, and the sensing data of each sensor node have a certain extent of redundancy and correlation.
In Figure 2(a), if all the nodes upload collected data directly to their parent nodes without any processing, the closer a node is to the base station, the more packets it needs to transmit. In contrast, if an intermediate node is allowed to aggregate the data sent from its child nodes, as illustrated in Figure 2(b), the number of packets required to be sent by upper nodes can be greatly reduced.
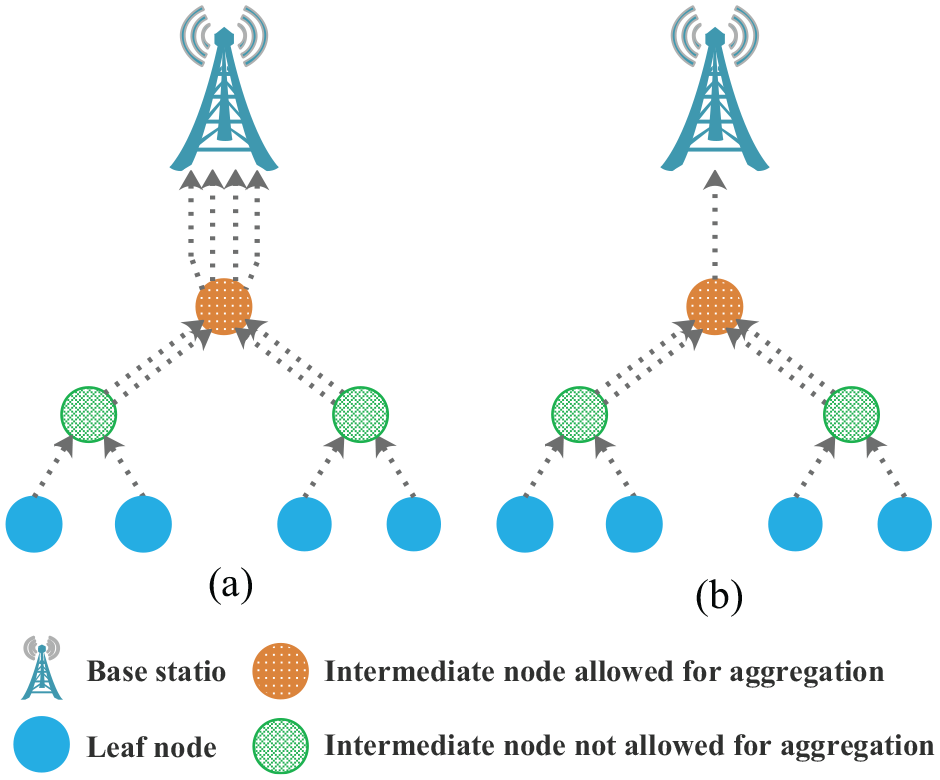
A sketch map of data aggregation.
Data aggregation is to eliminate redundant data packets and utilize data correlation to reduce the total amount of data transmission in a WSN, and then reduce the probability of data collision and congestion in the network, and finally achieve the goal of saving resource consumption and extending the lifecycle of the entire network.
ARIMA model
The functional expression of the model is described by
As an important method to study time series, the ARIMA model is a typical method to model the rational spectrum of a stationary stochastic process, which can be used to solve many practical problems. Compared with the AR and MA model, ARIMA has more accurate spectral estimation and better spectral resolution performance, but its parameter estimation is relatively complex. Therefore, in engineering practice, AR and MA parameters are usually estimated separately to obtain a suboptimal scheme. Although AR and MA parameters cannot be estimated at the same time to identify the optimal parameter setting, the computation cost can be considerably reduced.
The most important assumption of the ARIMA model is the stationarity of time series data. The stationarity requires that the fitting curve obtained from the sample time series can continue along with the existing form inertia in the near future, that is, the mean and variance of the data should not change too much in theory. The stationarity can be divided into two categories: strict stationary and weak stationary. Strict stationary means that the distribution of data does not change over time; weak stationary means that the mean value and correlation coefficient of data will not change. In the process of data aggregation, strict stationary is too idealized and theorized, and weak stationary applies to most cases. For unstable data, we need to first stabilize it. The difference method is the most commonly used technology, which calculates the difference between time
AR model
The AR model specifies that the output variable linearly depends on its own previous values and on a stochastic term. When analyzing the states of network nodes, it describes the relationship between current and historical values and leverages a variable’s historical events to predict the variable’s future events. The model is in the form of a stochastic difference equation, which is given as follows

Here,
There are four limitations when using AR models:
The model uses its own data for prediction, that is, the data used for training and predictions are the same.
The data used must be stationary.
The data used must be partial autocorrelative. If the partial autocorrelation coefficient is less than 0.5, the AR model is not suitable.
The AR model can only be used to predict the phenomenon related to its earlier states.
MA model
In time series analysis, the MA model is a common approach for modeling univariate time series, which specifies that the output variable depends linearly on the current and various past values of a stochastic (imperfectly predictable) term. Contrary to the AR model, the finite MA model is always stationary. The MA model focuses on the accumulation of error terms in the AR model and can effectively eliminate the random fluctuations in the prediction. It can be formulated as follows

Here,
ARMA model
In the statistical analysis of time series, ARMA models provide a parsimonious description of a (weakly) stationary stochastic process in terms of two polynomials, one for the AR and the other for the MA. The ARMA model can be given by

Here,
Differencing
Differencing in statistics is a transformation applied to time series data in order to make it stationary. The difference between consecutive observations is computed as follows
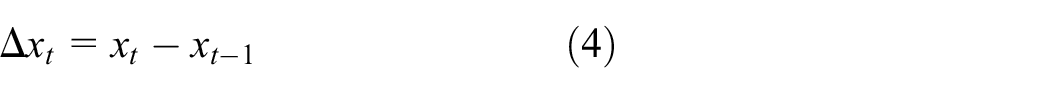
where

In general, we can define the dth order difference in a similar way. If a random process contains
After the dth order difference, we need to determine whether the random state of the network is stationary at this time. For a suitable
In addition, the autocorrelation between the states of network nodes is to compare the ordered random state sequence with itself, and it reflects the correlation between the values of the same sequence in different timestamps. The partial autocorrelation function (PACF) calculates the partial correlation between two variables, which eliminates the interference of other intermediate variables.
For a stationary AR(
Aggregation process based on ARIMA model
Sensor nodes continuously monitor data continuously and update the ARIMA model when the prediction error is greater than the predetermined threshold. It has a few advantages. First, nodes can detect outliers exceeding the predetermined error range, which may be caused by nodes’ wrong observations or the change of the distribution of observations. Second, it does not need communication during the modeling step, and in the prediction stage, communication between a sensor node and the cluster head is needed only when the prediction error is too large. Third, the cluster heads utilize the model to calculate the predicted value at the next timestamp iteratively after receiving the data and model parameters from each sensor node. The model is updated only when the error exceeds the predetermined threshold, and the updated model is used for future predictions. The detailed aggregation process is illustrated in Figure 3.

The aggregation process based on the ARIMA model.
To select a proper error threshold, we define the parameters in Table 1. According to the threshold for the upper limit of error, when
ARIMA model parameters.

ARIMA: autoregressive integrated moving average.
At any time

Here, we can choose an appropriate
We divide error calculations into two categories based on the time interval between two data observations. A cluster head needs to wait for a period of time to receive new data and model parameters to update the model. If the time gap

Considering the limited storage in sensor nodes, each node only stores the latest
Experimental results and analysis
In the experiments, an Ubuntu server with the Hadoop platform is used to simulate a distributed WSN. The simulation analysis of the proposed framework is conducted on the PAMAP2 Physical Activity Monitoring dataset 32 in the UCI machine learning repository. The dataset contains data of 18 different physical activities, performed by nine subjects wearing three inertial measurement units and a heart rate monitor. It is multivariate and collected from real sensor nodes. There are 3,850,505 instances in the dataset, each of which contains 52 attributes. To evaluate the performance of the method proposed in this article, we compare it with ESDA, TAG, CPDA, and RPDA. The RPDA was the first to propose a chain aggregation scheme in clusters.
Privacy
In the experiments, we propose a key agreement scheme for the ARIMA model. First,

Then we set a random node to receive the corresponding encrypted message, whose probability is

We assume that there are 10,000 keys in the key pool. In the stage of key distribution, 200 nodes are selected from the key pool. Hence,
ARIMA controls the maximum allowable error within a small range by adjusting the parameter
Computation cost
Since ARIMA is a strongly dynamic system, we assume that a node performed
The cluster head makes a prediction at each timestamp. It involves a polynomial operation and an extra addition operation to update the model. The computational cost

where
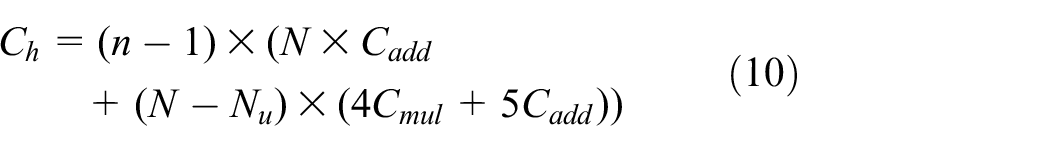
where
It can be seen that the computation cost of both cluster head nodes and non-cluster head nodes completely depends on the order of the ARMA model and the number of model updates. The higher the order of the model, the higher the precision and the fewer the model updates, but a model of a higher order implies more multiplication operations. On the contrary, the lower the order of the model, the lower the precision and the less multiplication operations, but the more model updates. Therefore, in practice, we should choose a reasonable order and error range according to the specific environment and experience.
Communication cost
Figure 4 describes how the communication cost varies under different numbers of queries. With the increasing number of queries, the communication costs of all data aggregation schemes except the ARIMA scheme proposed in this article are relatively stable. Since frequent information interactions within clusters are indispensable in the CPDA method, its communication cost is the highest. In contrast, the communication cost of TAG is much less than CPDA, RPDA, and ESDA. The communication cost of ESDA, in which the number of packets transmitted in the network is substantially smaller, is less than that of RPDA.

Communication cost under different query numbers.
For ARIMA, in the first few queries, since there is less historical data, the predictions are less accurate. Thus, nodes in the cluster need to update the ARIMA model more frequently and send the new model and recent historical data to the cluster head, leading to a higher communication cost. After that, the model becomes stable. If the model needs to be updated, the node sends a message; otherwise, no communication is necessary. As a result, the communication cost of subsequent queries becomes stable, which is close to that of TAG.
Accuracy
Accuracy is an important metric to evaluate the performance of a data aggregation algorithm. Generally, in the course of data transmission, the accuracy of data aggregation cannot reach 100% due to the impact of channel noise, data transmission delay, and data collision. The experimental results show that the accuracy increases with the increase of the query time intervals. In theory, if there is no data loss, the accuracy of each method could reach 100% theoretically. However, in practice, data collisions in wireless channel cause packet losses. As a result, the aggregation accuracy will be affected.
It can be observed from Figure 5 that the larger the query time interval, the better accuracy. This is because the chance of having data collisions is lower with a longer query time interval. ARIMA has the highest overall accuracy. In contrast, CPDA has the lowest because nodes in a cluster need frequent information exchanges, resulting in a high delay. The accuracy of TAG is next to ARIMA, slightly higher than ESDA. It is worth noting that ESDA has a smaller traffic volume. Although ESDA is a prediction-based model, the prediction error will not affect data aggregation because the cluster head will generate the complete original observation value by adding the data sent from each node in the cluster.
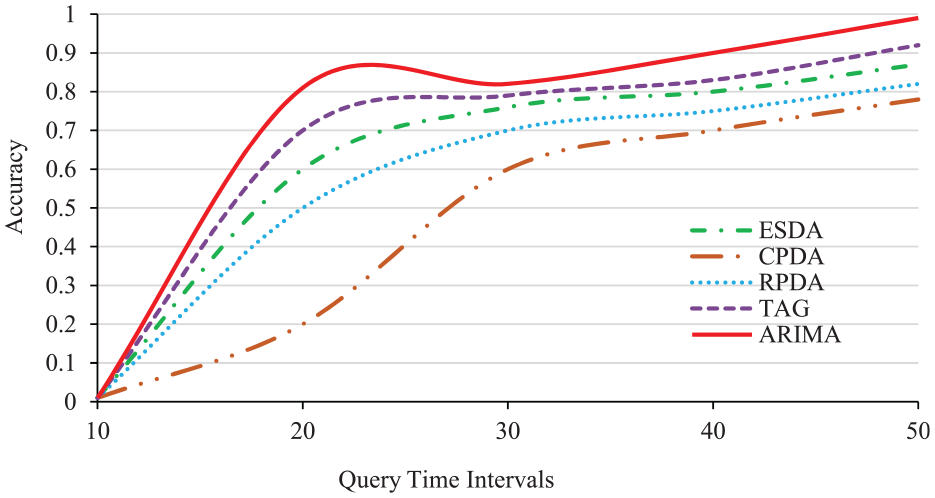
Accuracy under different query time intervals.
Figure 6 gives the relationship between accuracy and the aggregation time of the proposed scheme under 60, 80 and 100 nodes. It indicates that aggregation accuracy decreases with the increasing node density.

Accuracy of ARIMA under different numbers of nodes.
Flexibility
The current schemes for data aggregation usually support only a single data type and are not suitable for multi-application scenarios. Due to the unlimited number of applications theoretically supported by ARIMA, it is more flexible, where the length of ciphertext is related to the number of applications

Relationship between the number of nodes and the maximum number of applications supported.
Summary and outlook
In this article, we proposed a secure data aggregation scheme for wireless sensor data based on the ARIMA model. The scheme requires a cluster head to store the prediction model of all nodes in the cluster and all nodes to make predictions synchronously during data aggregation. If the prediction error is less than the predetermined threshold, the prediction value is taken as the aggregated value. When a node needs to update the model, new data and a new ARIMA model will be sent to the cluster head in the form of the prediction error plus a private random number.
This scheme aims to improve prediction accuracy, reduce the number of communications among nodes in a cluster, and ensure data privacy. Based on the Hadoop framework, the proposed secure data aggregation method can effectively analyze and integrate a variety of data generated by a WSN while preserving data privacy. The experimental results show that the ARIMA model outperforms a few competing methods in terms of accuracy, computation cost, and communication cost. Our method also achieves desirable data privacy, which is not provided by any of the competing methods.
While data privacy is important in the process of data aggregation, data integrity is equally important. This article does not consider the protection of data integrity. In future work, we will study how to integrate data integrity into a prediction-based model.
Footnotes
Handling Editor: Xiaojiang Du
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China under grant nos 61370084 and 61872105 and the Fundamental Research Funds for the Central Universities under grant no. 3072019CF0603 and the Project for Innovative Talents of Science and Technology of Harbin under grant no. 2016RAXXJ013.