
Abstract
Developing the technology of reversible data hiding based on video compression standard, such as H.264/advanced video coding, has attracted increasing attention from researchers. Because it can be applied in some applications, such as error concealment and privacy protection. This has motivated us to propose a novel two-dimensional reversible data hiding method with high embedding capacity in this article. In this method, all selected quantized discrete cosine transform coefficients are first paired two by two. And then, each zero coefficient-pair can embed 3 information bits and the coefficient-pairs only containing one zero coefficient can embed 1 information bit. In addition, only one coefficient of each one of the rest coefficient-pairs needs to be changed for reversibility. Therefore, the proposed two-dimensional reversible data hiding method can obtain high embedding capacity when compared with the related work. Moreover, the proposed method leads to less degradation in terms of peak-signal-to-noise ratio, structural similarity index, and less impact on bit-rate increase.
Keywords
Introduction
With the introduction of sensor networks, many smart devices are used to collect a large amount of data, including images, videos, speeches, and texts, for smart homes, health monitoring, traffic control, and so on. This indeed makes people’s life more convenient. However, this may lead to the leakage of personal information at the same time. For example, the face information and fingerprint information in public videos are abused. Therefore, it is important to guarantee the key content of video but not make the personal information leakage. Nowadays, distributing digital videos to the global has become easier because of the rapid development of high-speed broadband Internet and video encoding standard. For instance, in practice, many social applications, such as Skype, Facebook, WhatsAPP, WeChat, Blog, and QQ, can be used to spread digital videos. This has brought many concerns and maybe lead to many problems, even criminal activities, such as the illegal distribution of a digital movies and the leakage of personal privacy information in public videos. Therefore, researching and finding out effective ways to solve these problems or prevent them happening has become necessary.
Currently, encryption and digital watermarking are two commonly used techniques in digital multimedia, such as images and videos, to these problems. When applying encryption technique in images or videos (also referred to as motion images), the computational complexity may be high. In addition, it is possible for a video codec to produce format incompatibility. At the same time, encryption usually makes the content of images or videos unavailable. However, in some cases, like copyright protection, the content should be available. Hence, there have been many researchers to start to research digital watermarking in videos not only for solving these problem but also for other purposes, such as broadcast monitoring, copy or playback control, online location, and content filtering. 1 Digital watermarking is a part of data hiding (DH),1,2 and it is classified into irreversible and reversible watermarking corresponding to the technologies of irreversible DH and reversible data hiding (RDH), respectively. Compared with irreversible data embedding, RDH has attracted much more attention from many researchers because it can embed additional information into digital media, such as images and videos, and recover the original media content after extracting the embedded information from the marked digital media.3,4
In the past two decades, RDH in images has been rapidly developed that leads to make many achievements. 5 For instance, Wu et al. 6 designed an RDH scheme in encrypted palette images since palette images are widely utilized in real life. In their RDH scheme, a color partitioning method is proposed to make use of the palette colors to construct a certain number of embeddable color triples for embedding the secret data. By doing this, their scheme can provide a relatively high data-embedding payload and have a low computational complexity. Recently, Yang et al. 7 propose an adaptive real-time RDH for JPEG images. This RDH scheme is realized by using successive zero coefficients in zig-zag order of discrete cosine transform (DCT) blocks. Their experimental results have verified that their proposed scheme can enhance embedding capacity meanwhile maintaining the image quality. Moreover, Chen and Wang 8 proposed a RDH method with high embedding payload for JPEG images. For this method, each quantized discrete cosine transform (QDCT) coefficients is changed for carrying 1 information bit, thus leading to high embedding payloads.
In videos, there exist many kinds of coding parameters that can be changed for RDH, even DH. Therefore, compared with images, videos have much more research room to develop the techniques of RDH and DH. Recently, as the development of video compression standard, such as H.264/advanced video coding (AVC) 9 and high-efficiency video coding (HEVC), 10 some video DH methods2,11–16 and video RDH methods17–23 are reported. For these DH methods, they are proposed for improving embedding capacity,12,14 stopping intra-frame drift,11,13,16 and reducing bit-rate increase. 24 For these RDH methods, they are proposed for improving error concealments performance, 18 making embedding capacity larger, 17 protecting privacy,20,23 and preventing inter-frame distortion drift. 19 However, compared with the development of RDH technique in images, it is not enough. Thus, this has motivated us to continue to research RDH technique in video. Recently, Xu and Wang 18 proposed a two-dimensional (2D) RDH method, as shown in Figure 1, for error concealment of intra-frame in videos. Compared with one-dimensional RDH method, 2D RDH can keep better performance in terms of peak-signal-to-noise ratio (PSNR) and structural similarity index (SSIM). Thus, Xu et al.’s scheme is better than Chung et al.’s scheme. 25 However, Xu et al. did not make full use of (0,0) and only a part of coefficient-pairs containing 1 zero coefficients are used to map for DH. Based on this, this has motivated us to propose a novel 2D RDH method in this article for improving the embedding capacity. In our experiments, we exploit the method of block selecting in Chen et al.’ method 11 and apply the 2D RDH of Xu and Wang’s method 18 and our proposed 2D RDH method in H.264/AVC reference software JM12.0. 26 In other words, we compare them in identical cases. Experimental results have verified that our proposed method outperforms Xu and Wang’s method in terms of embedding capacity. Furthermore, our proposed 2D RDH method causes little degradation in visual quality and little impact on coding efficiency in terms of bit-rate increase.

Illustration of Xu et al.’s two-dimensional histogram modification.
The remainder of this article is organized as follows. In section “proposed method,” we present the proposed 2D RDH method. Some experimental results and analysis are given in section “Experimental results and analysis.” Finally, we draw some conclusions in section “Conclusion”.
Proposed method
In common RDH methods, zero QDCT coefficients are not considered and exploited to embed information in compressed images and videos. Therefore, Chen et al. present a video RDH scheme by combining with zero QDCT coefficient-pairs from high-frequency areas. 17 Based on Chen et al.’s 17 work, we propose a novel 2D RDH method in H.264/AVC videos in the following. The histogram modification is shown in Figure 2.

Illustration of the proposed two-dimensional histogram modification.
Data embedding
During the procedure of data embedding, our proposed 2D RDH method is based on paired QDCT coefficients and thus all coefficients should first be paired two by two. In the following, all coefficient-pairs, each of which is also called as a point, that is,
Shifting
1. If

2. If

3. If

Data embedding
1. If

2. If

3. If

Exploiting equations (1)–(6), information can be embedded into the videos reversibly.
Data extraction and video recovery
Corresponding to the procedure of data embedding, the data extraction and the video recovery are addressed as follows.
Data extraction
1. For one point

2. If

3. For one point

Video recovery
1. For one point

2. For one point

3. For one point

4. For one point

5. If

6. If

By using equations (10)–(15), the original compressed videos can be restored.
Analysis of embedding capacity and distortion
To analyze the embedding capacity and distortion of our proposed method, we first define three sets as follows

where

where

where

In our experiments, we count

It is very close to the result shown in Table 1, that is, 7343 bits. Moreover, embedding distortion can be defined by
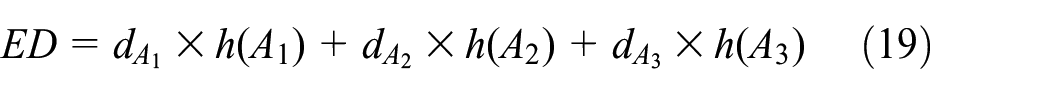
where

Maximum embedding capacity (bits) on video sequences.

QP: quantization parameter.
Furthermore

In fact, the embedding distortion cannot be measured by equation (19) since H.264/AVC has intra-frame and inter-frame predictions. Equation (19) can stand for total number of modification on QDCT coefficients but not embedding distortion. Finding a good way to reasonably calculate the embedding distortion is a big challenge and it is also a research direction for us in the future. In this article, we will not address more details about how to find a good way to reasonably calculate embedding distortion.
Experimental results and analysis
This section contains four subsections, that is, setup, embedding capacity, visual quality, and bit-rate variation.
Setup
To evaluate the performance of the proposed 2D RDH method, we applied the proposed 2D RDH method in the H.264/AVC reference software JM12.0.
26
Twelve standard video sequences, that is, Akiyo, Claire, Coastguard, Container, Foreman, Miss America, Mobile, Mother–Daughter, News, and Suzie (as shown in Figure 3) downloaded from websites,
27
which are with the resolution of

Test video sequences: (a) Akiyo, (b) Carphone, (c) Clair, (d) Coastguard, (e) Container, (f) Foreman, (g) Hall Monitor, (h) Miss America, (i) Mobile, (j) Mother–Daughter, (k) News, and (l) Suzie.
Configuration parameters of the JM12.0 software.

CAVLC: context-adaptive variable length coding.
In addition, we exploit embedding capacity, visual quality, and bit-rate variation to measure the performance of our proposed 2D RDH method. PSNR and SSIM 28 are used for objectively evaluating visual quality of marked videos. Bit-rate comparisons show the impact of our proposed 2D RDH method on H.264/AVC encoder in terms of coding efficiency. In the following several subsections, the “Original” of PSNR, SSIM, and bit-rate is computed by the original H.264/AVC encoder. Otherwise, they are computed by H.264/AVC encoder with the corresponding DH methods. More analyses are given as follows.
Embedding capacity
Table 1 shows the maximum embedding capacities on these 12 video sequences mentioned in section “Setup” by using Xu and Wang’s method 18 and our proposed method. In Table 1, QP has three values, that is, 24, 26, and 28 and it determines the quantization step of H.264/AVC encoder. 9 According to Table 1, obviously, our proposed method has larger maximum embedding capacities on these 12 video sequences when compared with Xu and Wang’s method. 18 For example, on Miss America in Table 1, our proposed method obtains 3204, 2628, and 2543 bits corresponding to QP = 24, 26, and 28, respectively. However, Xu and Wang’s method 18 obtains 2086, 1720, and 1664 bits correspondingly. Moreover, our proposed method obtains average maximum embedding capacities of 6803, 6450, and 3598 bits, which are greater than that Xu and Wang’s method 18 obtains, that is, 4339, 4126, and 2348 bits. These have verified that our proposed 2D RDH method has indeed an advantage in embedding capacity when compared with Xu and Wang’s method. 18
Visual quality
In this subsection, we will measure the visual quality of marked videos by our proposed method in two sides. On one hand, we give Figures 4 and 5 to subjectively evaluate the visual quality of marked videos. Herein, Figures 4 and 5 represent videos with more smooth areas and more rich areas, respectively. At the same time, Figures 4 and 5 are the 31st frame of Hall Monitor and Mobile, respectively. Figures 4(a)–(c) and 5(a)–(c) are obtained by using the original H.264/AVC encoder. Figures 4(d)–(f) and 5(d)–(f) are generated by H.264/AVC encoder with Xu and Wang’s method 18 and similarly Figures 4(g)–(i) and 5(g)–(i) are generated by H.264/AVC encoder with our proposed method. According to Figures 4 and 5, we do not observe any distortion of video frame caused by Xu and Wang’s method 18 and our proposed method when compared with the original video frames. Under this case, our proposed method outperforms Xu and Wang’s method 18 in terms of embedding capacity.

The 31st frame of Hall Monitor (with more smooth areas): (a)–(c) original frames, (d)–(f) marked frames by Xu and Wang’s method,
18
and (g)–(i) marked frames by the proposed two-dimensional reversible data hiding method. For (a), (d), and (g),

The 31st frame of Mobile (with more rich areas): (a)–(c) original frames, (d)–(f) marked frames by Xu and Wang’s method,
18
and (g)–(i) marked frames by the proposed two-dimensional reversible data hiding method. For (a), (d), and (g),
However, we make use of PSNR and SSIM to objectively evaluate visual quality of marked videos and they are shown in Tables 3 and 4. In Table 3, when

where

Peak-signal-to-noise-ratio variation comparisons
Comparisons of PSNR (dB) between Original, Xu and Wang’s method, 18 and the proposed method.

PSNR: peak-signal-to-noise ratio; QP: quantization parameter.
Comparisons of SSIM between Original, Xu and Wang’s method, 18 and the proposed method.

SSIM: Structural similarity index; QP: quantization parameter.
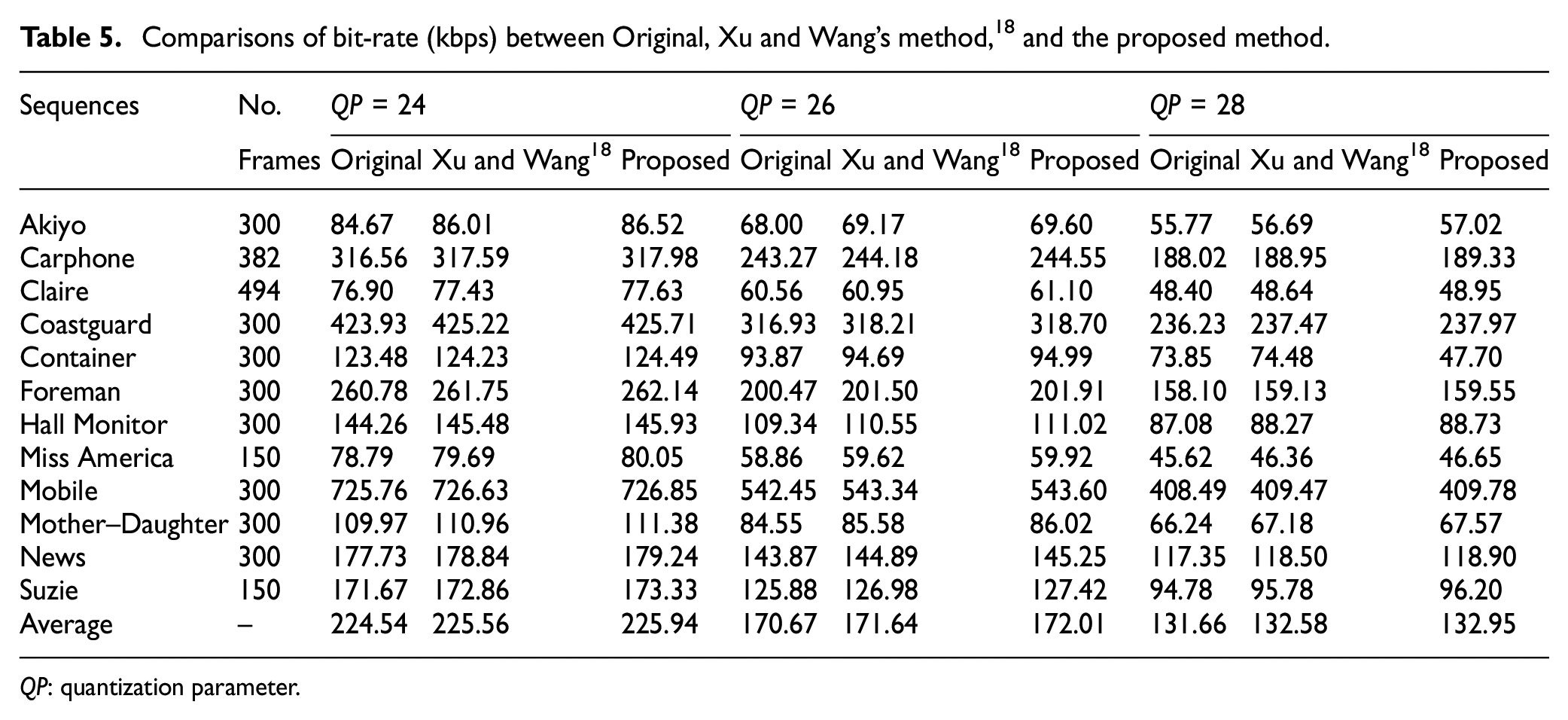
Comparisons of bit-rate (kbps) between Original, Xu and Wang’s method, 18 and the proposed method.
QP: quantization parameter.
In Table 4, for “Original,” Xu and Wang’s method, 18 and our proposed method, the SSIM values are decreasing with the increase in the QP value. Although our proposed method provides least SSIM value of 0.9404 on Coastguard when QP = 28, the difference between them are little. When considering the embedding capacity (shown in Table 1), the performance of our proposed method is accepted. Totally, our proposed method provides larger embedding capacity and leads to close embedding distortion when compared with the related work.
Bit-rate variation
Bit-rate after and before embedding data into video sequences is often used to evaluate the coding efficiency of H.264/AVC codec. In this subsection, we give Table 5 to show bit-rate variation without and with DH method. Likewise, Table 5 also corresponds to Table 1.
According to Table 5, our proposed method leads to close coding efficiency of H.264/AVC encoder with Xu and Wang’s method. 18 Compared with “Original,” our proposed method has a little impact on coding efficiency. In addition, to better compare our proposed method with Xu and Wang’s method, 18 we define bit-rate variation by

where
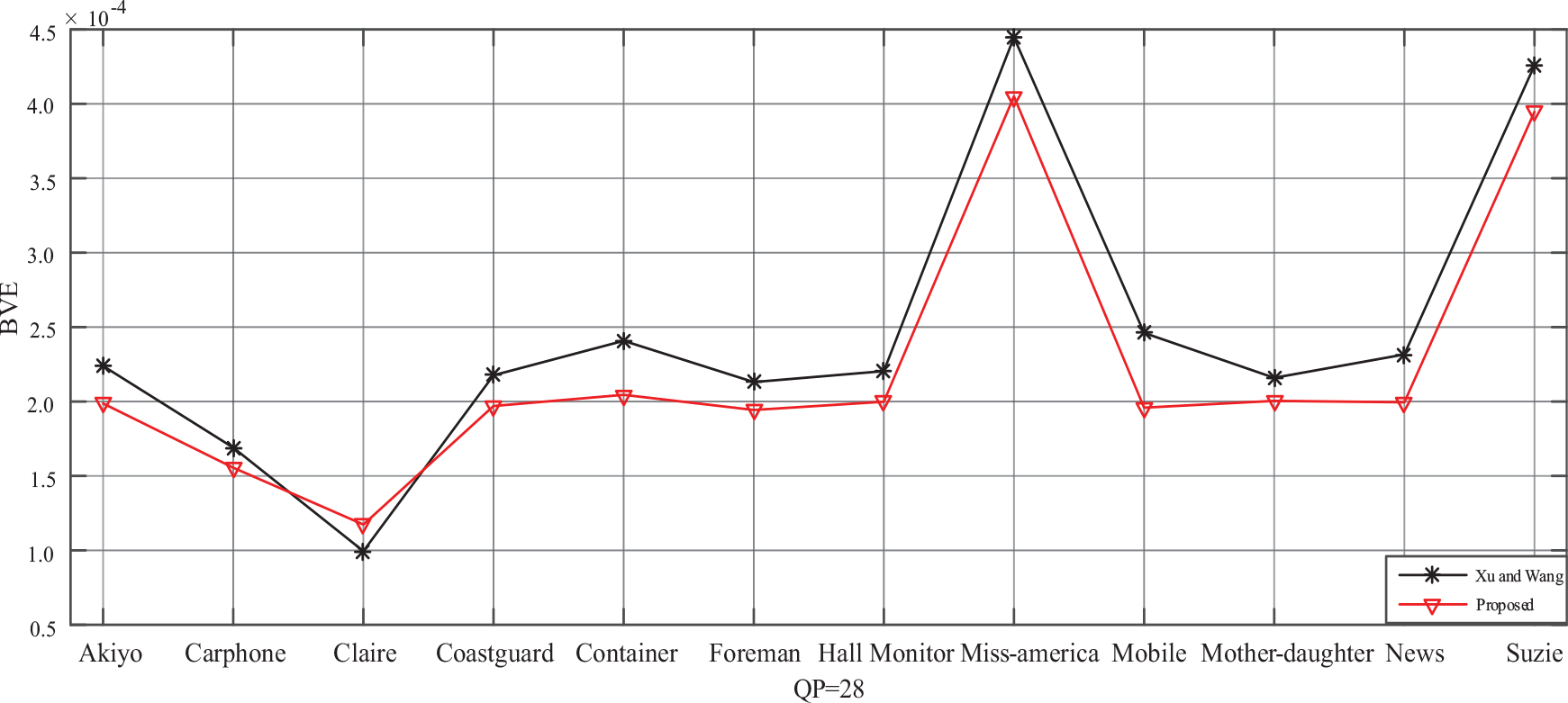
BVE comparisons
Conclusion
This article presents a novel 2D RDH method, which is based on H.264/AVC compression standard, with high embedding capacity. In the proposed 2D RDH method, almost all points, referred to as coefficient-pair in this article, containing coefficient with a value of 0 are used for data embedding. In addition, only one coefficient in other points is changed to vacate room for reversibility. Therefore, the proposed method provides higher embedding capacity compared with the related method. When compared the variation of PSNR and SSIM caused by each embedding information bit, the proposed method keeps better visual quality. Moreover, the increase in bit-rate caused by the proposed method is less.
Footnotes
Handling Editor: Yulei Wu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (NSFC) under Grant No. 61972269, the Fundamental Research Funds for the Central Universities under Grant No. YJ201881, and Doctoral Innovation Fund Program of Southwest Jiaotong University under Grant No. DCX201824.