
Abstract
In recent years, fifth-generation communication technology has begun to experiment successfully. As an indoor positioning technology of the Internet of things, it changes with each passing day and shows great vitality in the development of smart cities. Aiming at the problem that existing radio frequency identification indoor positioning algorithm is prone to environmental interference and poor positioning accuracy, a LANDMARC indoor positioning algorithm based on density-based spatial clustering of applications with noise–genetic algorithm–radial basis function neural network is proposed. In this article, the signal intensity value is processed by Gaussian filter, and the noise points and boundary points are removed by density-based clustering algorithm. The threshold and weight of radial basis function neural network were optimized by genetic algorithm. With less data information, the relationship between the value of label signal strength and position coordinate could be established to improve the positioning accuracy of LANDMARC positioning algorithm. Experimental research shows that the average positioning error of the proposed LANDMARC algorithm based on density-based spatial clustering of applications with noise–genetic algorithm–radial basis function neural network is about 0.9 m, which is 64% lower than the average positioning error of the traditional LANDMARC algorithm and improves the indoor positioning accuracy.
Keywords
Introduction
With the rapid development of indoor positioning technology, the demand for indoor positioning information service is increasing gradually, and location services are a growing concern. Although, in outdoor positioning, people mostly use Global Positioning System (GPS) for positioning, the signal is difficult to be received in the complex indoor environment and is easy to be shielded by building walls, and it is also difficult to achieve the positioning accuracy in indoor environment. In recent years, fifth-generation (5G) communication technology has begun to experiment successfully, and as Internet technology changes with each passing day and a variety of handheld devices, tablet computers and other mobile terminals appear in the public’s field of vision, the indoor positioning technology has been applied in many places.1–3 As a research hotspot, smart city has been applied in many intelligent management scenarios. Indoor positioning technology can connect things with things and people with things. As the Internet of things technology, it plays a huge role in the development of smart cities.4,5 What is more, location-based services are increasingly convenient for people and show great vitality. 6 At present, the main indoor positioning technologies include Bluetooth, geomagnetic positioning, Zigbee, ultrasonic, infrared, ultra wide band, radio frequency identification (RFID), and WiFi.7–11 Bluetooth devices are mainly used in small range positioning. Due to its small size, most devices are integrated into mobile phones, and it has advantages in power consumption control. The signal is not affected by the line-of-sight during transmission. Some small devices have access points (APs), and users can use Bluetooth to determine their location by collecting data from these AP nodes. In the indoor positioning method, the geomagnetic positioning is more secure, and the price is relatively low. The geomagnetic information of the mobile carrier is collected and compared with the geomagnetic reference map, and the best matching results are obtained by the corresponding criteria to achieve the positioning function. 12 Zigbee positioning technology is also a widely used indoor positioning method. The localization algorithm is designed for localization through received signal strength indication (RSSI) of the reference node obtained from the localization node. Without any additional hardware equipment, Zigbee network is used to provide indoor positioning services. 13 Ultrasonic positioning technology calculates the distance according to the measured ultrasonic signal, converts the distance into coordinates, and obtains the final positioning result. 14 Ultra wide bandwidth (UWB) is a wireless carrier technology based on narrow pulse, which has superior obstacle crossing ability and has been widely applied due to its advantages of high efficiency, high accuracy, low power consumption, and low price. 15 RFID system can receive data without direct contact with objects. It uses the radio frequency electromagnetic field to transmit data from the RFID tag to the reader, tracking and collecting specific digital information, so as to automatically identify the target. Compared with other identification methods, RFID technology has the advantages of high accuracy, wide transmission range, and low cost.16,17 WiFi location technology is completely built on the existing wireless local area network (WLAN) infrastructure and mobile devices. Only APs are required to regularly send information containing the received signal strength (RSS), and no additional device technical support is required. Due to the advantages of simple implementation method and low cost, indoor fingerprint positioning method has been widely applied in urban construction and has been highly valued by people.18–20
However, the RSS-based method is sensitive to fading and multipath effects, and its accuracy is not high. In order to improve the accuracy of indoor positioning, a pseudo-absolute positioning algorithm based on RFID was proposed in Ying et al. 21 and the nearest neighbor algorithm of LANDMARC was improved. In the selection of adjacent tags, although a lot of unnecessary calculations are discarded, the influence of other reference tags is ignored. A positioning method based on differential hologram is proposed in Huang et al. 22 Based on the original hologram, a differential hologram is calculated to locate the target. Both the pure holographic method and the differential holographic method are better than the method based on the enhanced phase arrival difference, and it also shows that the difference holographic method has higher accuracy, but the method using the difference technology to solve the internal error factors of the system is more complex. In Narzullaev and Mohd, 23 a new fingerprint database construction method is proposed, which combines the signal and the path loss prediction algorithm in the sampling process. Although it can be read directly from a commercial WiFi access point at a distance and does not require manual signal collection, multiple WiFi and RFID tags need to be installed at the target location to continuously monitor the signal strength level and send the scanned data to the server. In Murofushi et al., 24 a one-dimensional indoor positioning system based on RSSI power transmission of backscatter signal coupled by RFID tag to the position of mobile vehicle is introduced and compared with the distance measured by ultrasonic sensor; though it has higher positioning accuracy, the antennas are incompatible and need to have a fixed position. In Lohan et al., 25 the RFID and WLAN channel positioning models are compared, and the path loss channel models of WLAN and RFID signals are analyzed. It can be clearly concluded from the comparison that WLAN and RFID path loss channels are very similar. RFID positioning is not applicable in the indoor environment as the communication range between the transmitter and receiver is small, and positioning accuracy is low. In Seyyedi et al., 26 a new method is proposed, which does not need to add redundant reference tags but calculates the position of the tag to be tested based on the virtual reference tag, with low cost, but still cannot completely eliminate the influence of multipath propagation and signal interference. In Zou et al., 27 a low-cost RFID indoor positioning system is developed by using cheaper active RFID tags, sensors, and readers. An extreme learning machine (ELM) combining weighted path loss (WPL) rapid estimation and ELM high positioning accuracy is proposed. According to this algorithm, indoor environment is divided. In the online phase, the WPL method determines the region of the target and then deploys the ELM model to estimate the final location of the target. Based on the experimental results, this algorithm has higher positioning efficiency and higher positioning accuracy. However, the algorithm needs to detect the existence of tags and find their location. In Savochkin et al., 28 a method for spatial search and identification of objects with passive RFID tags is proposed. It does not need to detect the existence of tags and find their positions, but the algorithm requires more computing time, so as to improve the positioning accuracy. In Wang and Xu, 29 in order to improve the positioning performance, a Kalman Filter indoor positioning algorithm (KILA) based on singular value judgment is proposed. KILA algorithm is adopted to determine the maximum singular value of WiFi signal waveform, so as to achieve the purpose of optimization and effective data fusion of WiFi and RFID signals. This algorithm has low cost, can simulate the location blind area even in the case of dynamic change of indoor noise, and can also maintain good positioning performance. However, the extra computing from RFID adds a bit of computational complexity. In Lai and Ho, 30 a real-time indoor positioning system was developed, in which heron-bilateration based on external RFID-based heron bilateration and Inertial Measurement Unit (IMU) angular driven navigation estimation methods were used. The two methods can further improve the accuracy and reliability of indoor positioning system. In Qing and Ben, 31 in order to process the spatial data information in the RFID positioning system, the positioning of the target tag is realized. Aiming at the problem that a single clustering algorithm cannot meet the accuracy requirement when dealing with the actual positioning problem, a method integrating density peak clustering and grid clustering algorithm is proposed, which can not only deal with large-scale spatial data sets but also improve the operation efficiency of the algorithm. However, this method needs to grid the data set. In Yuan et al., 32 an improved LANDMARC method was proposed, and the volume Kalman filter was used to filter the estimated value of the target to be measured obtained by LANDMARC algorithm to improve the localization robustness. However, incorrect selection of some adjustable parameters in Cubature Kalman Filter (CKF) algorithm will also lead to errors in the algorithm. In Zhe and Ji, 33 a method is proposed to locate QR code landmarks by using Kinect sensor-assisted RGB camera, but this method is also vulnerable to environmental interference. In Yong, 34 an RFID indoor positioning method based on particle swarm optimization (PSO) and integrating K-means algorithm and declustering algorithm is proposed. The K-means algorithm is used to preprocess the generated particle swarm values. After that, the depolymerization algorithm is adopted to reduce the influence of external factors. The optimized radial basis function (RBF) neural network model is used for training, and the final optimized positioning result is obtained. In Shan et al., 35 in order to optimize the parameter values of the neural network, the PSO algorithm was first adopted, and then the training model was obtained from the filtered training data to predict the target position, which effectively improved the positioning accuracy and shortened the prediction time. Artificial neural network (ANN) has disadvantages such as slow convergence speed and sensitivity to initial weight. Back-propagation neural network LANDMARC (BPNN-LANDMARC) algorithm is proposed in Zhang and Li, 36 which obviously reduces the complexity of the algorithm. In Huang et al., 37 a method based on K-means and weighted K nearest neighbor (WKNN) algorithm is proposed. The K-means algorithm is used to analyze the collected signal strength and improve the search speed. In Zhang et al., 38 a joint clustering algorithm of Gaussian mixture model and K-means is proposed, and Kalman filtering is adopted. This algorithm has better positioning effect and faster operation. In Yuan et al., 39 back-propagation (BP) neural network is used to preprocess the collected signals, and the cultural dual quantum particle swarm algorithm is adopted to improve the operation speed, enhance the global search ability, and effectively improve the positioning efficiency and accuracy of indoor LANDMARC positioning. However, the learning rate of BP algorithm is still very slow. In Yong et al., 40 a density-based clustering method was adopted to eliminate noise points and boundary points, and generalized regression neural network was used to construct the mapping function of RSS of heterogeneous terminals. The location of test points was located by the least square support vector regression machine (LSSVR) model, so as to better solve the problem of excessive positioning deviation caused by heterogeneous terminals.
Based on the above considerations, in order to improve the operation speed of indoor positioning system and the search ability of the algorithm, the optimal target position can be estimated with less data information. In this article, a LANDMARC location method which combines Gaussian filtering algorithm with density-based spatial clustering of applications with noise (DBSCAN) algorithm and optimizes RBF neural network by genetic algorithm (GA) is proposed. DBSCAN algorithm is a clustering method, which can cluster a certain kind of signal. In addition, values in each class are assigned and noise points unrelated to the data are excluded. 41 After the outliers of signal intensity were processed by Gaussian filtering and DBSCAN algorithm, the optimal value in LANDMARC was selected. Because crossover and mutation are the main contents of GA, it can greatly improve the search ability of the algorithm. 42 The RBF neural network optimized by GA is used to train a small number of sample values, which can well meet the requirements of indoor positioning and reduce indoor positioning errors.
Methodology
In order to reduce the error of indoor positioning, improve the operation speed, and improve the global search ability of the algorithm, this article adopts a LANDMARC indoor positioning algorithm based on density-based spatial clustering of applications with noise–genetic algorithm–radial basis function (DBSCAN-GA-RBF) neural network. First, Gaussian filter and DBSCAN algorithm are used to process the signal strength sample set of reference tag and tag to be tested, and the boundary points and noise points in the sample set are removed. Then, by using LANDMARC positioning algorithm to predetermine the measured position, the signal strength sample set with the strongest correlation between the actual position and the target to be positioned was found. The RBF neural network optimized by GA is used to construct the training model and obtain the target position to be determined. The block diagram of the LANDMARC positioning system of DBSCAN-GA-RBF neural network in this article is shown in Figure 1.

The block diagram of the positioning system.
Density-based clustering algorithm
DBSCAN is one of the most commonly used clustering methods. Different from other algorithms, this algorithm uses density space to process data so as to aggregate data into a specific category. This method takes the region with sufficient density as the distance center and expands the clustering boundary continuously. Any core data can generate a cluster, and after a threshold is set, the number of data within a certain range should be greater than the set value. Therefore, it is possible to connect the areas within the range of a certain density value nearby and eliminate the irrelevant noise points. 41
DBSCAN algorithm needs to first determine several parameters:
Epsilon-neighborhood: it can be understood as the density space, which means the radius is e and contains several points, and the density is equal to the number of points/space size.
Epsilon neighborhood: specify the neighborhood within the data radius of epsilon.
Minpts: the minimum number of points within the range of the adjacent region.
Core point: if the epsilon neighborhood just determines the minimum number of minpts data that exists, then this object is the core object.
Edge point: a boundary point is a point in the neighborhood other than the core point.
Outlier point: a point other than the boundary point and the core point.
The general steps for DBSCAN are: (given epsilon and minpts) if a point is arbitrarily selected (neither specified to a class nor specified as a peripheral point), the number of objects in its neighborhood is calculated to determine whether it is a core point. If so, create a class around the point; otherwise, set it as a peripheral point. Iterate through the other points until you create a class. Join the directly reachable point to the class, then the density reachable is also added. If a point marked as peripheral is added, change the state to edge point. Repeat the above steps until all the points are satisfied in the class (core or edge points) or are peripheral points.
Arrange the number of reference tags M, the number of pending positioning tags N, the number of readers k, and write down the position coordinates of all tags. After all the data information is collected, the signal strength vector collected by the ith reference tag is

where

and the sample set of the test point is

where
LANDMARC algorithm
LANDMARC system is composed of a large number of reference tags and RFID readers, and the tag position of the reader of this system has been determined. 43 First, obtain the positioning of the reference label in the indoor environment. Second, the RSSI value of the reference tag is compared with the RSSI value of the tag to be measured. Finally, the reference tag closest to the RSSI of the positioning tag was found and the location of the positioning tag was estimated. 44
Arrange the number of reference tags M, the number of pending positioning tags N, the number of readers k, and write down the position coordinates of all tags. The signal strength vector observed in the ith reference tag is

where

where
Therefore, the Euclidean distance between the ith reference tag and the jth pending positioning tag can be obtained

Therefore, the vector of the pending positioning tag

LANDMARC algorithm that if the value

where l is the nearest reference tag to the pending positioning tag.

The position estimation error is

where
After Gaussian filtering and DBSCAN filtering, the sample set of signal intensity observed by the ith reference tag in group q was obtained,

where
Genetic algorithm
GA is an efficient algorithm that can realize global search and is a biological method with natural laws, which can automatically obtain the contents related to search space. After mutation, crossover, and other methods, all chromosomes in the population were used as objects to obtain a new generation of population and achieve the final desired results. 46
Coding: there are some parameters in the neural network that need to be improved. Binary coding is carried out on these data in the RBF neural network, after which it is called chromosome.
Fitness: fitness function is used to evaluate whether the method is good or bad. Thus, to construct a map, you can use the fitness of the solution from the genome to it. The process of solving the optimal value in the multivariate function is actually the process of GA.
Selection: the probability of selecting some individuals from the population is a fixed value, and the selection process is also a measure of fitness.
Crossover and mutation: both crossover and mutation operations can improve the search ability of the algorithm in search. Random selection of crossover bits ensures the convergence of the algorithm according to crossover probability, so crossover is an important operation in GA. Variation can also maintain the diversity of the GA population, and ensure that the population can produce new traits and continuously evolve to get the optimal population after variation.
In GA, each individual represents a population of variables that need to be optimized. In this article, GA is used to optimize some parameters in the RBF neural network, such as output weight, width, and center of Gaussian function. Therefore, chromosomes are composed of the width and center of chromosomes. 47
RBF radial basis neural network principle
The RBF is also a real valued function, and its value depends on the distance from the origin, which can be expressed as

where
The RBF neural network can be composed of three parts: input layer, output layer, and hidden layer. The flow chart is shown in Figure 2.
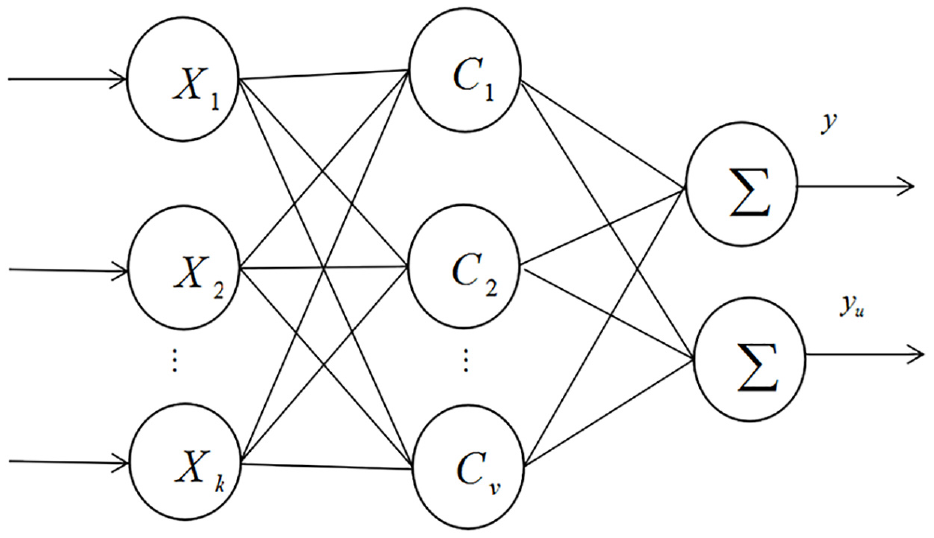
The radial basis function neural network structure.
The basis of the hidden element is composed of the RBF and constitutes the hidden layer space. Therefore, the center point of the RBF reflects the mapping situation. Moreover, the hidden layer space to the output space also constitutes a linear mapping, where the weight can also be adjusted. The important thing about the kernel is that if the vector is linearly indivisible in the lower dimensions, then it is linearly separable in the higher dimensions, and the mapping of a vector is from a low dimensional k to a high dimensional v. Therefore, the nonlinear mapping constituted by the neural network from input to output is a linear output compared with the adjustable parameters. In this way, the weight can be obtained in the system of linear equations, which improves the learning rate and avoids the problem of local minimum. The K-means algorithm can be used to obtain the RBF center C, and the extension constant of RBF is

where the number of training samples can be expressed as U,
Experiments and analysis
Four readers were placed in four corners of the 10 × 10 m laboratory, a total of 121 reference tags. The distance between each adjacent reference tag was 1 m, and 20 pending positioning tags were randomly selected. In the experiment, LANDMARC positioning algorithm was used for positioning. In the process of positioning, the number of adjacent reference tags was selected as 4. The experimental system deployment diagram is shown in Figure 3.

The experimental system deployment diagram.
DBSCAN algorithm parameters are commonly used values: minpts is set to 3, eps is set to 2. Figure 4 is the scatter plot of the sample set of the collected reference label signal strength, and Figure 5 is the scatter plot processed by DBSCAN algorithm. DBSCAN algorithm can effectively filter noise points in scatter diagram. When the GA is adopted for optimization, the population size parameter is set as 50. After the population is initialized, the genetic algebra is selected as 100. The change of fitness function is shown in Figure 6.

The scatter plot of the collected signal strength.

The scatter plot processed by DBSCAN algorithm.
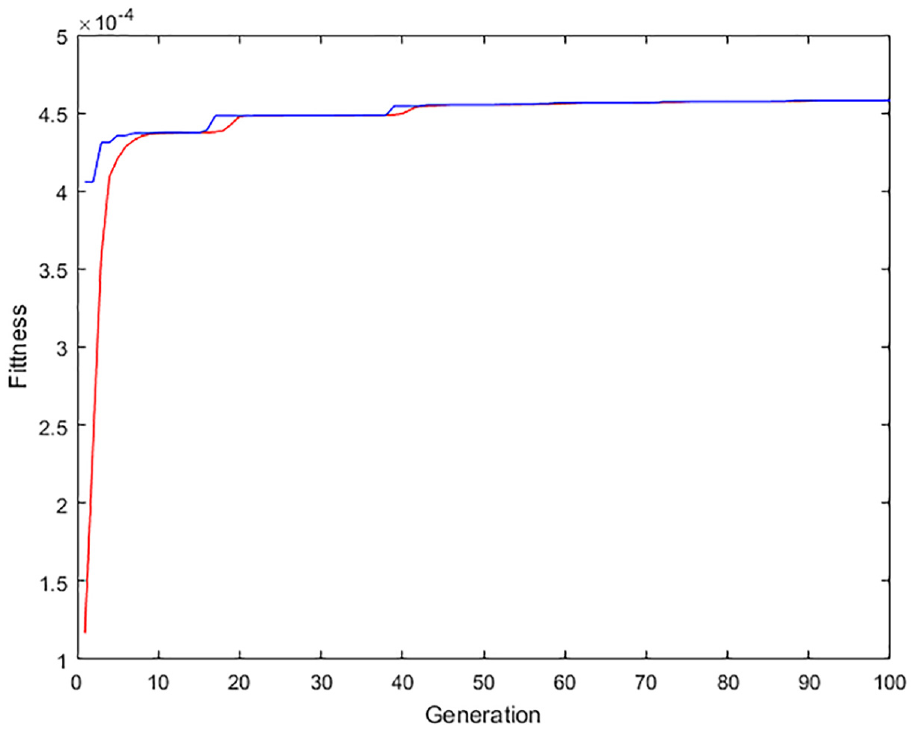
The fitness function of genetic algorithm changes.
In this article, signal strength data are collected from four readers, and then the system uses above algorithm to calculate the positioning error of each tag to be tested. Figure 7 shows the positioning error of the four algorithms. It can be seen that, compared with the improved algorithm in this article, LANDMARC algorithm, RBF-LANDMARC algorithm, and DBSCAN-RBF-LANDMARC algorithm have large positioning errors, and the positioning accuracy of data processed by DBSCAN algorithm is higher than the existing algorithm. Table 1 shows the maximum, minimum, and average errors of the four algorithms. Figure 8 shows the system running time of the four algorithms. RBF neural network is an efficient feed-forward network with fast training speed. Although the training time of DBSCAN-GA-RBF-LANDMARC algorithm is close to that of DBSCAN-RBF-LANDMARC algorithm and RBF-LANDMARC algorithm, it is obviously better than LANDMARC algorithm. According to the final results of the experiment, it can be shown that the average positioning error of the LANDMARC algorithm proposed in this article based on DBSCAN-GA-RBF neural network is about 0.9 m, which is 64% less than that of the LANDMARC algorithm, 56% less than that of the RBF-LANDMARC algorithm, and 18% less than that of the DBSCAN-RBF-LANDMARC algorithm. The positioning error of the algorithm proposed in this article fluctuates between 0.09 and 3.45 m, with a small fluctuation range. The improved algorithm proposed in this article runs faster than the traditional LANDMARC algorithm, and its positioning accuracy is better than the other three algorithms.
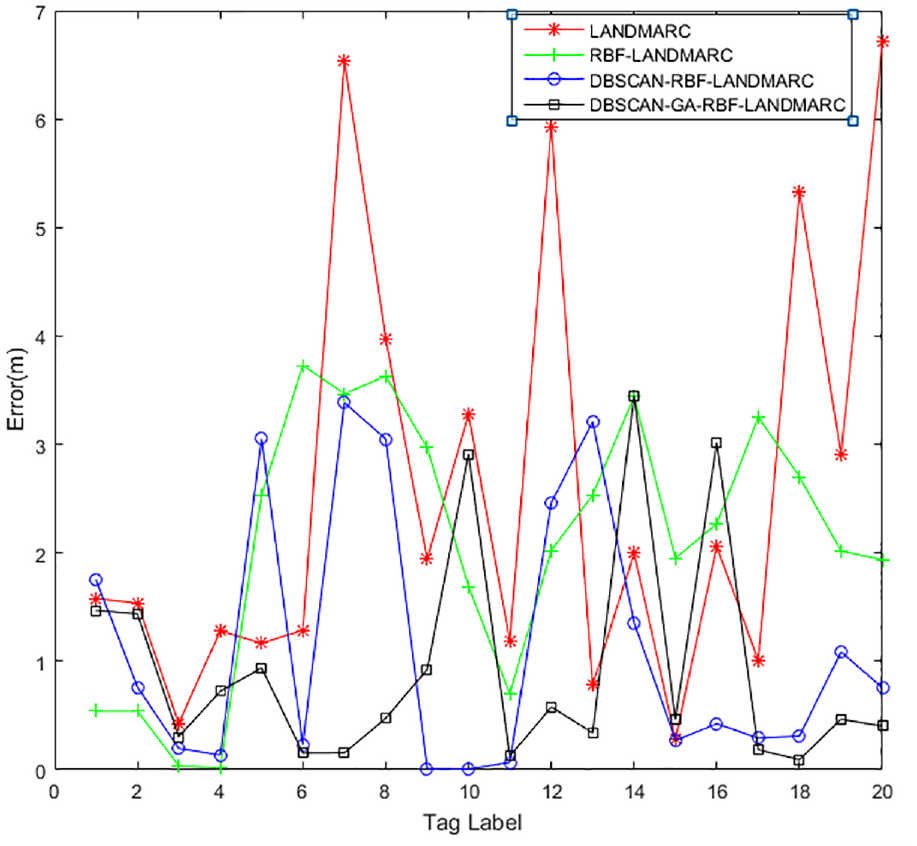
Positioning error comparison of the four algorithms.
Positioning errors of the four algorithms.

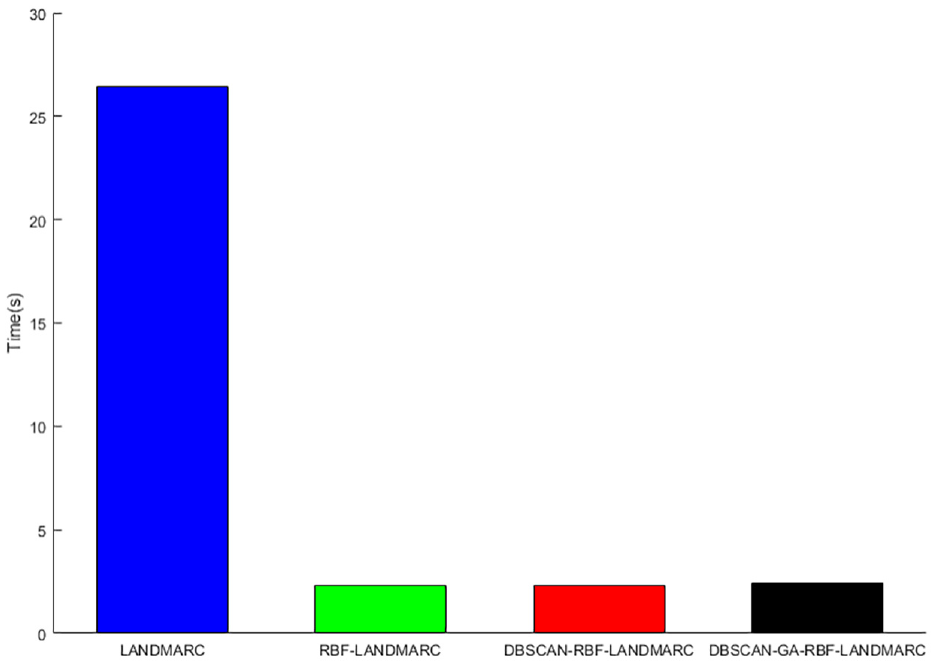
The running time of the four different algorithms.
The distance error cumulative distribution function of the improved algorithm and LANDMARC algorithm, RBF-LANDMARC algorithm, and DBSCAN-RBF-LANDMARC algorithm in this article is shown in Figure 9. In this article, the positioning accuracy of the algorithm within 1 m is 80%, the LANDMARC algorithm is 15%, the RBF-LANDMARC algorithm is 25%, and the DBSCAN-RBF-LANDMARC algorithm is 60%. In this article, the positioning accuracy of the positioning algorithm within 2 m is 85%, and that of LANDMARC algorithm, RBF-LANDMARC algorithm, and DBSCAN-RBF-LANDMARC algorithm are respectively 60%, 40%, and 75%. It can be seen that the improved positioning algorithm in this article has better positioning effect. Figure 10 shows the cumulative distribution function of distance error of K-means-weighted K nearest neighbor (K-means-WKNN) algorithm, Gaussian mixture model and K-means joint clustering algorithm, back-propagation LANDMARC (BP-LANDMARC) algorithm, and DBSCAN-GA-RBF-LANDMARC algorithm. In this article, the positioning accuracy of the algorithm within 1 m is 80%, the K-means-WKNN algorithm is 30%, the joint clustering algorithm is 25%, and the BP-LANDMARC algorithm is 20%. Compared with BP-LANDMARC algorithm and joint clustering algorithm, the algorithm in this article has a higher learning rate, better positioning stability, and better positioning effect than K-means-WKNN algorithm.

Comparison of distance error cumulative distribution functions between different algorithms based on LANDMARC.

Comparison of distance error cumulative distribution function between the proposed algorithm and other algorithms.
Conclusion
To solve the problem of large indoor positioning errors in traditional LANDMARC, this article proposes a LANDMARC algorithm based on DBSCAN-GA-RBF neural network. After collecting the signal strength value of the tag, the scatter diagram was established. Gaussian filter and DBSCAN algorithm were used to process the signal strength sample set of the reference tag and the tag to be tested, and the boundary points and noise points in the sample set were removed. By using LANDMARC positioning algorithm, the correlation between the actual position and the target to be positioned was calculated, and the strongest signal strength sample set was obtained. The RBF neural network optimized by GA was used to construct the training model, and the adjacent reference labels were selected accurately through the model, so as to improve the global search ability and finally obtain the target position to be determined. Through comparative experiments, it can be seen that the DBSCAN-GA-RBF neural network-LANDMARC algorithm proposed in this article can effectively improve the problem of excessive positioning deviation, which is better than LANDMARC algorithm, RBF-LANDMARC algorithm, DBSCAN-RBF-LANDMARC algorithm, and improves the positioning accuracy.
Footnotes
Acknowledgements
The authors would like to acknowledge all the members who participated in the exhaustive field measurement campaign for their valuable effort. Thanks also to the anonymous reviewers for their perspicacious comments.
Handling Editor: Michel Kadoch
Declaration of conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China under Grant 61871348 and open foundation of laboratory (2018JYWXTX02).