
Abstract
In this article, we consider a directional data forwarding problem to multiple destinations under distinct deadline constraints in vehicular ad hoc networks. We present a simple yet effective data forwarding algorithm based on only vehicle-to-vehicle communications in infrastructure-less and map-less environments. Our algorithm consists of two phases: relay selection and proliferation. We design a relay selection algorithm that encourages a shared ride for data delivery toward a certain common intermediate point from time to time for forwarding efficiency. It chooses a strong next relay candidate among nearby connected vehicles by considering their current position, velocity, and also the current progress toward the destination. In case that one of the progress lagging indicators becomes signaled, the number of vehicle relays increases under control depending on the degree of deterioration during a packet replication procedure called proliferation. Embedding two essential parts in designing a timely data forwarding scheme validates its accurate on-time data delivery performance and forwarding efficiency in network overhead based on real-world data-driven experiments.
Introduction
With the emergence and rapid proliferation of autonomous driving and intelligent vehicles, the distributed usage of vehicle-to-vehicle (V2V) communication is known to be a fundamental way of exchanging information in vehicular ad hoc networks (VANETs). In particular, vehicle safety technology aims to ensure the safety of vehicles, passengers, pedestrians, and other vehicular facilities based on V2V networking. Also, developing an intelligent transportation system (ITS) that can reflect on-site road status or traffic information directly from vehicles or from a network of vehicles is a crucial part of building a smart traffic congestion control system.
To provide on-site road, traffic, and accident information to local police stations, emergency centers, fire stations or highway interchange/entrance/exit for timely emergency response, or on-the-road services such as drive-through cafe/restaurant, designing a viable V2V data forwarding mechanism to be responsive to ever-changing road situations is a requirement. At the same time, meeting timely delivery within a designated deadline with low network overhead is another challenge toward a well-balanced trade-off between time and efficiency.
There exist many real-world situations where locally detected road information or on-the-road services such as traffic density or preceding service request needs to be delivered to multiple destinations with distinct deadlines. Sometimes, even a single same event may need to be treated with different priorities depending on the type of multiple recipients: for example, in real-time or within a few seconds toward nearby vehicles or highway entrances and within some more relaxed time of a few minutes or several hours toward state-level traffic control centers. The time-sensitive data delivery to multiple destinations with each distinct deadline has been one of the challenging problems in VANET. It is because the delivery mechanism should be designed to neither over-waste nor under-waste network resources for achieving reliable timely delivery performance.
The problem of data delivery in VANET has been investigated mostly in infrastructure-assisted, map-based, and non-delay-tolerant environments.1,2 Using pre-installed infrastructure nodes such as road-side units (RSUs) or access points as temporary stationary relays, routing paths can be established on top of a relatively stable underlying network.3,4 Furthermore, explicit identification of junctions or anchors extracted from pre-loaded maps allows geographic routing approaches to overcome the local maximum problem due to its locality and traffic-aware street topology information.5–8 However, infrastructure-less and map-less approaches with specific delivery time requirement have not been well studied, and thus need to be investigated for their even more practical applications.
To design an efficient data delivery mechanism toward multiple destinations without using any infrastructure or map information, it is desirable to effectively leverage an allowed delivery time for each destination. Furthermore, encouraging a shared ride for data toward a certain common intermediate point from time to time would be preferred for data forwarding efficiency. For instance, a courier company conveys numerous packages together with similar delivery due to a certain common hub and then distributes them respectively to each different destination from there. By effectively arranging shared and separate delivery methods depending on given delivery times, it is possible to devise a more efficient feasible delivery mechanism.
To handle the deadline-aware delivery progress, some lagging indicators considering the remaining deadline, the relative distance from the current vehicle to each destination, and so on should be defined. If a vehicle checks if one of the lagging indicators turns active, some more aggressive delivery action (e.g. through packet replication) needs to be performed. Otherwise, it can keep the current delivery method or revert back to the original frugal delivery method.
In this article, we propose an agile yet efficient directional data forwarding scheme with neither infrastructure nor digital map in VANET. Our data forwarding algorithm consists of two phases: (1) relay selection and (2) packet replication. In the relay selection phase, a single-vehicle relay finds out a strong next relay candidate among nearby connected vehicles, considering not only their current position, but also its derivatives (i.e. velocity), and also the current progress relative to a given delivery due in a greedy manner. In case that one of lagging indicators becomes signaled, the current vehicle relay decides to increase the number of next relays from one to a suitable pre-selected number. The number of relays to use is selected based on the degree of deterioration during a packet replication procedure called proliferation.
The advantages of our approach are twofold: lightweight yet effective relay selection criteria are selectively applied to designing a data forwarding scheme and validated in real-world datasets, and by adapting a data forwarding based on real-time network and delivery progress situation through controlling the increase of relay population, designing a compact yet timely reliable data forwarding is achieved.
Related work
The problem of directional data delivery in VANET has been investigated with three different perspectives: (1) infrastructure-assisted or infrastructure-less data delivery, (2) map-based or map-less data delivery, and (3) non-delay-tolerant or delay-tolerant data delivery.
First, data delivery schemes can be classified into two categories depending on whether to rely on static infrastructure nodes such as RSUs or access points. By embracing infrastructure devices as stationary nodes with different roles of source, relay, or destination, the underlying volatile data delivery problem in VANET due to highly dynamic topology of vehicles can be mitigated using both forms of communications, which are V2V and vehicle-to-infrastructure (V2I).1,2 The optimal paths are obtained by estimating the delay of message delivery between static nodes,9,10 by a series of sector-to-sector message delivery where a sector is governed by an RSU, 3 or by predicting a sequence of valid junctions to fixed infrastructure. 4 A recent study further considers the quality-of-service (QoS) metric based on considering connectivity, delivery ratio, and delay. 11
As a new trend in the category of infrastructure-assisted data delivery in VANET, the software-defined network (SDN) concept has been integrated with the VANET context. Basically, SDN separates the control plane and the data plane to offer flexible network services. RSUs can gather the nodes’ connectivity information to schedule data dissemination, 12 elect cluster heads,11,13 or predict the mobility with the help of machine learning techniques. 14
Second, most of the vehicular routing protocols in infrastructure-less environments have been developed under the name of geographic routing. Without using prior map information, greedy perimeter stateless routing (GPSR) 15 basically operates in a greedy-based routing and changes the mode to perimeter routing to recover from a local maximum, working in a well-distributed node environment. GPSR+AGF (advanced greedy forwarding) 16 improves its neighbor table considering the velocity, speed, and direction of vehicles, while spatially aware routing (SAR) 17 tries to overcome the local maximum by finding an alternative path with surrounding spatial awareness. This class of geographic routing usually has a limitation of working poorly in a relatively sparse vehicle environment. Instead of leaning on the geographic property, some research work has focused on handling collisions or hidden terminal problems by adapting the handshake mechanism or enhancing the medium access control (MAC).18,19
Under explicit identification of junctions or anchors from pre-loaded digital maps, this class of geographic routing protocol is applied. A classic geographic source routing (GSR) protocol 20 utilizes the locality of all the junctions from the source to its destination to apply the Dijkstra shortest path algorithm. Spatial and traffic-aware routing (STAR), 6 grid-based predictive geographical routing (GPGR), 5 and greedy traffic-aware routing (GyTAR) 7 do both locality and traffic-aware street topology information, to overcome the local maximum problem. However, for regions where their prior map information is not given or outdated, these advanced routing protocols may work poorly in practice.
Third, most of the aforementioned routing protocols work for non-delay-tolerant networks (DTNs) where data packets are transmitted to the destination as soon as possible at their own best effort. These non-delay-tolerant routing protocols do not utilize any margin time to find better connectivity at preceding times. On the other hand, there exist many classic delay-tolerant routing protocols such as epidemic routing 21 and Spray-and-Wait algorithm 22 known for their simple yet effective delivery performance. Recently, various research works such as adaptive carry-store forward (ACSF), 23 distance-aware routing with copy control (DARCC), 24 and geographic delay-tolerant network routing (GeoDTN+) 25 are conducted in the category of vehicular delay-tolerant networks (VDTNs). In VDTN, the main difference from the original DTN is that vehicles show some more characteristic patterns in daily traffic or so. It is more likely possible to track vehicles’ frequently visited active areas and calculate the traffic-aware shortest path. 26
More related to our work, delay-tolerant routing protocols such as scalable knowledge-based vehicular routing (SKVR), 27 vehicle-assisted data delivery (VADD, 10 and GeOpps 28 use the carry-and-forward technique that stores and carries data packets if proper vehicles cannot be found due to link volatility or highly dynamic topology change in VADD.
Although these prior works have contributed to the VANET routing research, devising some more practically feasible research work with infrastructure-less, map-less, and specific delay-sensitive data delivery requirements is necessary as an essential underlying vehicular communication method in the era of autonomous driving. This article presents a novel compact vehicular routing protocol complying with a delivery deadline constraint without using any infrastructure and map information.
System overview
In a scenario that road-side information including traffic situations or on-the-road services needs to be delivered to multiple different destinations such as nearby highway interchanges, road service centers, or emergency call centers, each respective delivery deadline should be considered upon deciding a forwarding path, depending on destination type, physical distance, and severity degree.
We consider the problem of data delivery to multiple destinations within time constraints in VANET. We seek a lightweight networking approach based on directional packet delivery, not relying on any given map or additional hardware tweak such as directional antenna installation. We use only V2V communication in a distributed VANET. The objective of this article is to design a best-effort data delivery mechanism that effectively delivers multiple destinations based on salient vehicle selection as intermediate relays by their distinct time deadlines while incurring low routing overhead.
We assume that each vehicle is equipped with a GPS device to locate itself and collects its past location trajectory in a buffer to calculate the average velocity of the vehicle itself during a past time window. It is also assumed that a vehicle communicates with another vehicle using a single forwarding packet with a wireless interface (e.g. 802.11p). Although the maximum frame body size for 802.11p within a packet is known to be 2304 bytes, many studies limit the packet size to 1000 bytes, concerning throughput and other issues.29,30 We also assume that the data size for one forwarding packet is less than 1000 bytes where the required information can be contained in a single data packet.
To perform on-time data delivery from a source to multiple destinations in a distributed VANET environment, finding a series of reliable vehicle relay selection is necessary. Since the movement of nearby vehicles as relay candidates tends to be very dynamic, the selection of whom the current vehicle should deliver data toward each destination very challenging. On a regular basis, the selection decision should be made among multiple relay candidates based on a contribution level related to where and how long a vehicle candidate will successfully be carrying data toward a designated destination. Our proposed scheme consists of two main phases: (1) relay selection and (2) proliferation, as shown in Figure 1.

System overview with two phases of vehicle relay selection and proliferation depending on the overall timely delivery progress.
During the relay selection phase, in order to make on-road vehicle resource minimally engaged for efficient delivery, it would be necessary to cover with a single-vehicle relay to deliver data toward many destinations in a similar direction. When data get much closer toward those destinations and need to be split toward each different destination at some point, multiple vehicle relays need to be in charge of separate delivery to each destination. The relay selection procedure is described in section “Relay selection.”
In the proliferation phase, we want to proliferate data through packet replication to make aggressive progress for being behind the delivery schedule. If the current vehicle relay finds out that its next data relay to one single-vehicle is not enough to reach its planned destinations on time, it chooses multiple vehicle relays and forwards the data to them. The packet replication procedure is described in section “Proliferation.”
Relay selection
In this section, we present a relay selection algorithm that finds out an effective vehicle relay node that can contribute to carrying data for a while until a next relay takes over. Upon selecting one out of multiple vehicle candidates as the next relay node, we have to prioritize them by quantifying how much each candidate can contribute to carrying the data closer toward a given destination.
To quantify how a vehicle can be used as a message ferry by moving closer toward a given destination, we use the average velocity of recent movements of a vehicle relay candidate during the latest few minutes (e.g. last 5 min). We decompose the vector of velocity into the direction to the destination. As illustrated in Figure 2, the magnitude of the average velocity vector

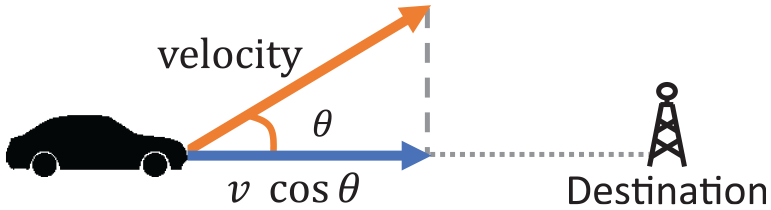
Evaluating nearby relay candidates by calculating the effective travel distance with the average velocity toward the direction of a given destination.
We define a contribution level

where
We calculate each contribution level for all possible nearby vehicle relay candidates from the current relay on a regular basis (e.g. every 3 min) and use the measure as information deliverability. We prioritize them based on the order of measure for selecting its next relay vehicle.
Single destination
In the case of data delivery to a single destination, the current vehicle that holds the packet needs to select a single next relay vehicle that can move it closer toward the destination, compared to itself. On a regular basis, the current relay node considers all of the nearby vehicles as relay candidates for the next round and then chooses one of them as the next relay node. To find adjacent vehicle nodes, the current relay pings surrounding vehicles near its vicinity by sending a HELLO packet. Any nearby vehicle that has received the ping message replies with its vehicle ID and past location trajectory information.
When the current relay vehicle receives all the information from its neighboring vehicles at that time, it calculates the contribution level measure
Multiple destinations
If the initial vehicle or the current relay vehicle is in charge of delivering information toward multiple destinations, we want to make fewer relay vehicles engaged with the relaying task. We aim to save radio energy consumption for transmission and reception in each vehicle side and also reduce network traffic and overhead in the entire network side. If one relay vehicle moves toward several destinations similarly aligned with a certain direction range, it can carry the information up to some point as a shared relay. After that point, the original single data path may need to be split, and the data are relayed from the current vehicle to multiple distinct vehicles. These vehicles are responsible for their respective data delivery to each different destination, as illustrated in Figure 3.

Example of relay selection on multiple destinations.
Based on the received information of adjacent vehicles and their trajectory information, the current relay vehicle calculates the contribution value for each vehicle candidate and each destination as shown in Table 1. Using the table of contribution values calculated across vehicles and destinations, we find a set of vehicles that can effectively cover all the destinations while having higher contribution values across them relative to the number of selected vehicles. In case that the number of selected vehicle relays for the next round is larger than 1, it is time to replicate the currently carrying packet and relay it to the selected multiple vehicles.
Example of contribution values table.

For example, assuming that vehicle A is the current relay node and it finds the adjacent vehicles B, C, and D, vehicle A traverses all possible vehicle set combinations that can cover all the given destinations by satisfying their contribution values larger than or equal to
In case we cannot find a complete set of vehicles that can cover all the destinations, we choose every single vehicle that can cover each destination with the highest contribution value. After solving the set cover problem with the highest efficiency, the current relay vehicle relays the information to the selected next relay vehicles, which are dedicated to data delivery to certain destinations. The detailed relay selection procedure is described in Algorithm 1.

Proliferation
Even if any advanced design of relay selection is embedded in on-time data delivery mechanisms, it is still very challenging to ensure its timely data delivery using only a single relay dedicated to one destination. Since real-world vehicle traces usually include erratic mobility patterns, even carefully selected relays do not often meet the original expectation, for example, arriving at the destination beyond the given deadline or wandering around somewhere else.
To tackle the problem, we borrow the concept of proliferation from biology in designing a packet replication scheme in the VANET context. If the current progress status expects to be pessimistic for on-time data delivery to a certain destination, we want to make rapid reproduction of information by outnumbering the relay vehicles. Through the proliferation process, we anticipate a high probability of delivering information at its intended destination within its given deadline.
However, if the proliferation process performs too aggressively, the overall network should experience an unnecessarily large amount of packet overhead, while wasting too much energy consumption for packet transmission and reception at all the involved vehicles. To effectively control the degree of packet replication, it is important to set a proper criterion of when to turn on the proliferation mode and how aggressively it should perform.
To derive the criterion, we quantify the overall vehicle relaying progress toward each destination. If the current single relay vehicle cannot afford to perform its original mission expected by its previous relay vehicle, the relay should determine how many relay vehicles are necessary to take over the mission by quickly recovering the lagging delivery situation.
As illustrated in Figure 4, we use the original distance d and the remaining delivery due

Estimating the number of replication by comparing original expectation and current progress.
In this situation, we launch the proliferation phase by calculating the necessary number of replication packets and then choosing suitable relay vehicles. We apply the concept of acceleration to catch up the progress lagging, that is,

where
In case that the required number of relays is larger than the total available relay vehicles that satisfies the contribution value threshold (i.e.
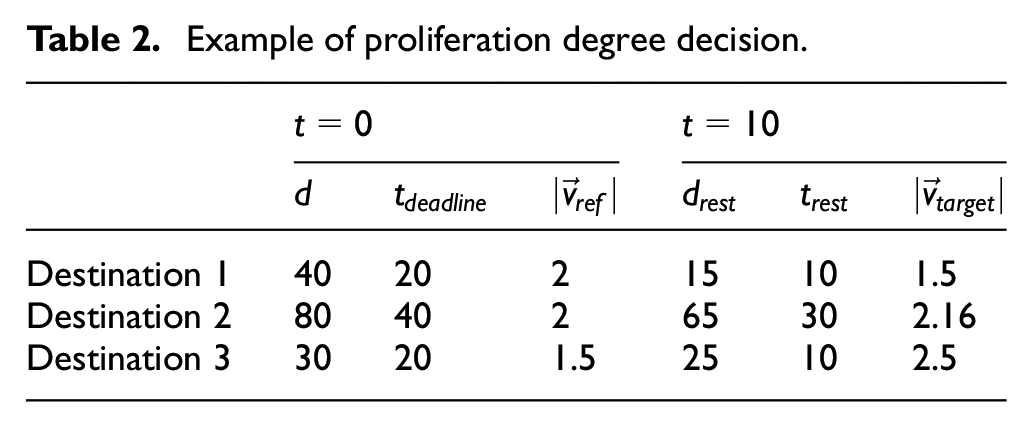
For instance, we consider an example case as shown in Figure 5 and Table 2. The current relay vehicle checks the progress of the current data forwarding for all destinations at

Data forwarding progress example for proliferation: (a) t = 0 and (b) t = 10.
Example of proliferation degree decision.
The detailed proliferation procedure is described in Algorithm 2.

Evaluation
We evaluate our proposed directional data forwarding algorithm based on real-world data-driven simulations. A taxi trace dataset, Shanghai urban vehicular network (SUVnet) 33 that was collected in Shanghai, China is used. Since this dataset does not have any V2V communication history, we simulate the direct packet communication among vehicles on top of vehicles’ moving traces.
The simulated area is

Real trace-driven simulation experiments over
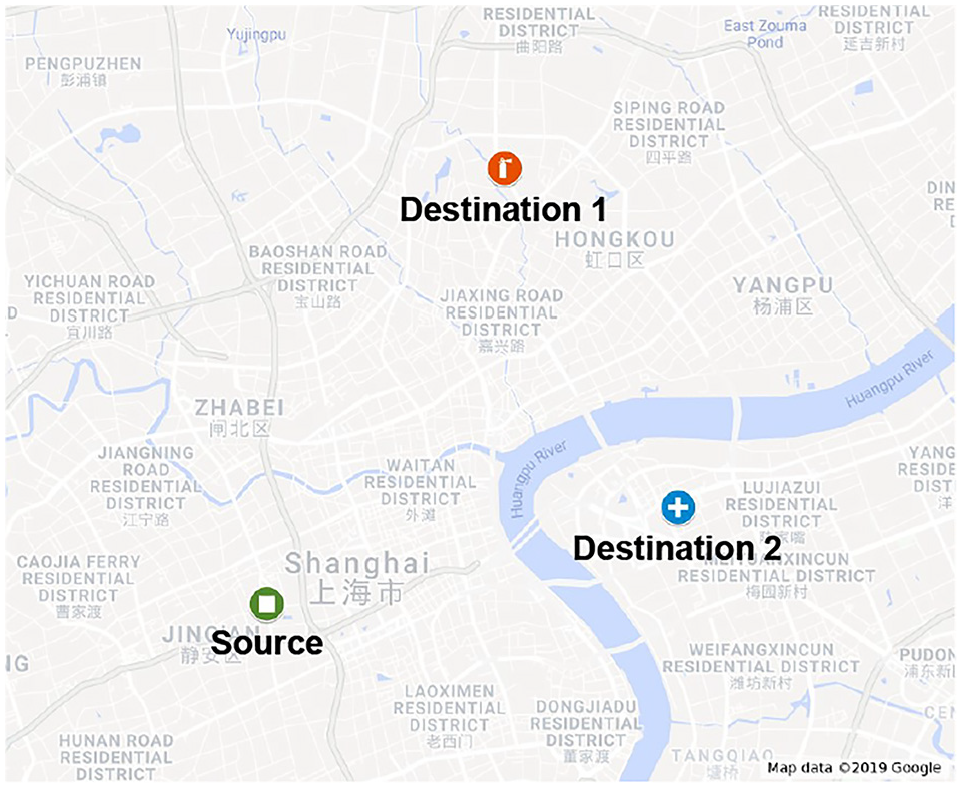
Data delivery scenario from one source to two different destinations in our experiments.
Since the original real-trace dataset includes numerous noisy records such as duplication, unrealistic movements, and unnecessary short trips (less than 180 s), we have pre-processed and refined it. We have removed duplicated and erroneous trace records or filling out some missing records between consecutive records by linear interpolation for our experiments.
For our evaluation, 10-day data out of the whole 30-day dataset are used, that is, from 10 February 2007 to 19 February 2007. We have chosen the most crowded time periods at 11 a.m., 12 p.m., and 1 p.m. where each packet delivery launches. We run data forwarding algorithms including ours under the 30 different experiments and report the averaged measures. For simulating direct vehicular wireless links, the transmission range of
Our relay selection and proliferation algorithm runs every 3 min. The parameters of the contribution level threshold
Simulation environment and parameters.

Relay selection validation
We compare our relay selection algorithm against two other counterpart algorithms: a random relay selection and a greedy data forwarding scheme. The random relay selection algorithm does not consider any vehicle information such as its location, velocity, and deadline constraints and simply selects a single vehicle as to the next round relay among adjacent connected vehicles in a random fashion. The comparison between it and our algorithm may provide some interesting insight into how some essential information can improve timely data delivery in VANET. As another baseline, we let a relay selection algorithm prioritize nearby connected vehicles based on only their location. It chooses a vehicle relay that has the closest to the destination in a greedy manner, which can be considered as a simplified version of GPSR algorithm. 15
First, we examine network performance of each algorithm for two single destination cases, that is, toward destination 1 for test case 1 and toward destination 2 for test case 2, respectively, as shown in Figure 7. In these test cases, two destinations are located within a similar distance from the source, whereas destination 2 is located across the river, making packets only reachable to the end through bridges. We quantify a successful data delivery rate for delivery reliability and the number of unique relay vehicles used for delivery efficiency. We also measure transmission cost consisting of control overhead as the number of HELLO packets used in each case and data overhead as the number of data packet transmissions. We vary the packet delivery deadline from 30 min to 3 h, as shown in Figure 8.
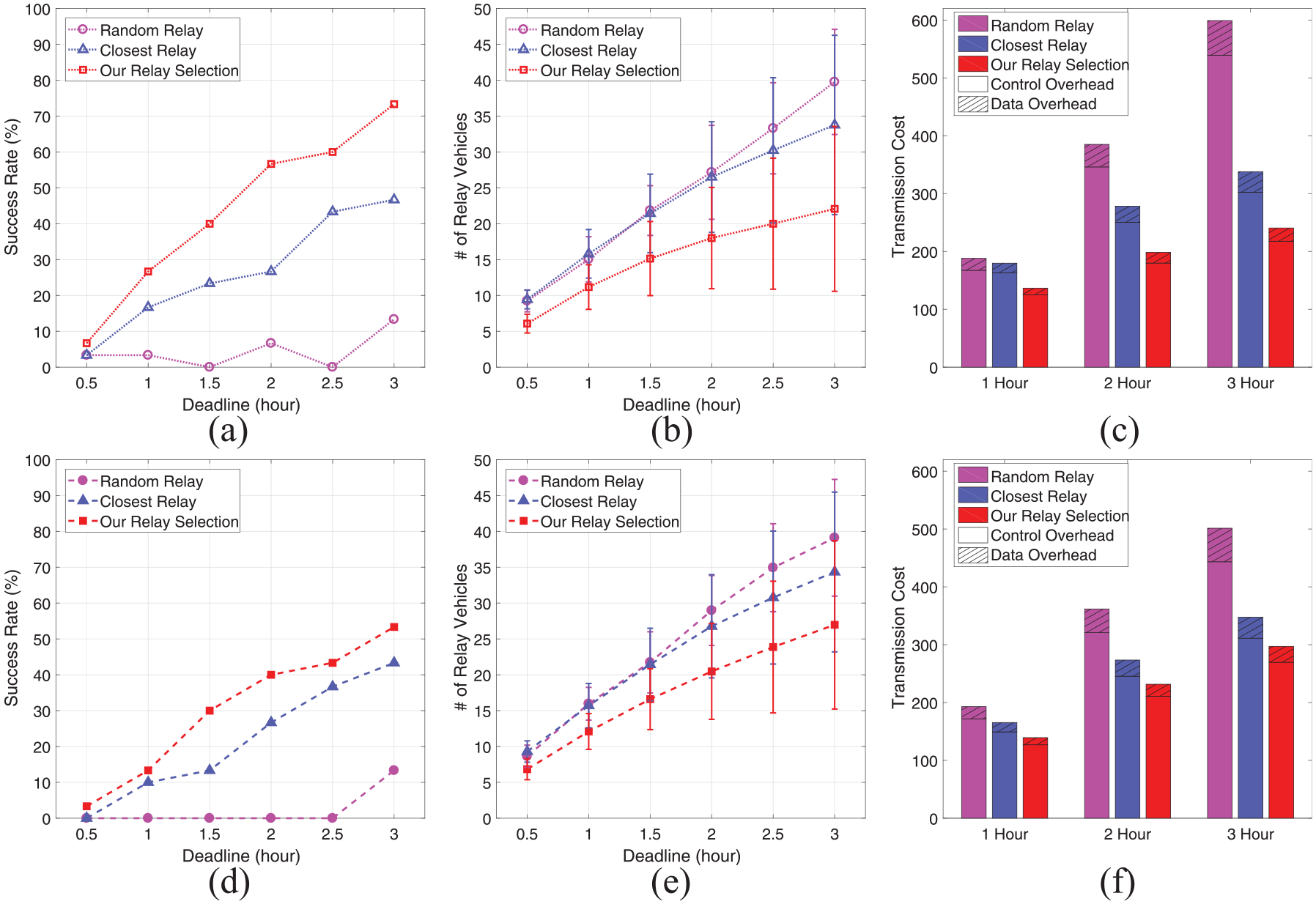
Network performance for single destination experiments toward destination 1 for test case 1 and destination 2 for test case 2. The standard deviation of the number of relay vehicles is shown for test cases 1 and 2: (a) on-time delivery rate on test case 1, (b) number of relay vehicles used on test case 1, (c) transmission cost on test case 1, (d) on-time delivery rate on test case 2, (e) number of relay vehicles used on test case 2, and (f) transmission cost on test case 2.
As shown in Figure 8(a) and (d), all of the algorithms almost fail to deliver one packet to its destination within the deadline of 30 min since there may exist insufficient vehicles for data delivery from the source to each destination for both test cases 1 and 2. By relaxing the deadline constraint up to 3 h, our relay selection algorithm finds an effective way to improve on-time data delivery rate up to 73% for test case 1 and 53% for test case 2, respectively, by continuously finding one effective single relay vehicle at each time. The 20% performance gap between test cases 1 and 2 results from the fact that under the situation of using only one relay vehicle over time, the opportunity for the current relay vehicle to encounter a suitable vehicle toward the other end of the bridge toward destination 2 becomes practically too low.
The random relay selection scheme works very poorly over almost all experiments, while the closet relay selection scheme reaches up to 47% for test case 1 and 43% for test case 2, respectively. The gap between our algorithm and the closest relay selection algorithm means that using not only location information, but also its first derivative and a progress indicator, for example, the remaining delivery time, helps to enhance on-time data delivery rate.
Regarding the number of relay vehicles and transmission cost, all of the algorithms spend more relay and communication resource due to more chances to relay as the deadline gets relaxed. Our relay selection algorithm incurs the lowest relay and communication resource thanks to a salient selection of representative effective relay vehicles, compared to others.
This result implies that although our relay selection algorithm fairly achieves both reliability and efficiency at the same time, using only one relay vehicle at a time is not sufficient for achieving practically high on-time delivery rate in practice. It requires an additional phase of make-up.
Second, we validate delivery performance on a concurrent data delivery scenario that initiates data forwarding from one source to multiple destinations under the same deadline constraints of 1, 2, and 3 h, respectively, as shown in Figure 9. As shown in Figure 9(a), our relay selection algorithm outperforms others while keeping almost similar on-time delivery performance compared to each respective delivery case in Figure 8(a) and (d).

Concurrent data delivery performance under multiple destinations at the same time: (a) on-time delivery rate and (b) transmission cost for each separate delivery scenario versus concurrent delivery scenario.
We check how much our algorithm can share some common relay vehicle to different destinations. We quantify transmission cost of the concurrent data delivery to two destinations compared to the cumulative cost over each respective delivery case. The concurrent data forwarding based on our relay selection algorithm achieves up to 23% less transmission cost. This means that our algorithm selectively uses some effective shared rides that can cover multiple destinations as far as possible for efficient resource usage.
Proliferation validation
Now we evaluate our approach equipped with the proliferation algorithm that can compensate on-time delivery rate without wasting too much network overhead. We first focus on experiments on test case 2 where our proliferation-free relay selection algorithm only achieves up to 53%.
We validate on-time delivery rate and transmission cost with various proliferation parameter setting together with the original (proliferation-free) relay selection algorithm by varying the delivery deadline from 30 min up to 3 h in Figure 10.

Single destination performance with proliferation with respect to deadline: (a) on-time delivery rate on test case 2 with proliferation and (b) transmission cost on test case 2 with proliferation.
As shown in Figure 10(a), the additional proliferation algorithm makes our relay selection algorithm significantly improve on-time delivery rate over up to 90% in the same environment. In particular, a certain parameter setting of
To see how each parameter affects the performance, if the replication scaling factor
Also, we take a closer look at performance dynamics between relay selection and proliferation in terms of distance to destination from the current relay and the number of relay vehicles used over time till the deadline as shown in Figure 11. A certain set of three representative test experiments are chosen under the deadline of 1.5 h: (1) both-success case in Figure 11(a) and (d), (2) only proliferation-success case in Figure 11(b) and (e), and (3) both-fail case in Figure 11(c) and (f).

Relay selection and proliferation result comparison on test case 2 under the deadline of 1.5 h with
In the both-success case, both algorithms successfully reach the destination within the deadline, showing the blue vertical line at that time as shown in Figure 11(a). The number of relay vehicles used in proliferation increases over time as shown in Figure 11(d). This can be considered as an optimistic case.
However, as a more general case, there exist more experiment cases where the single relay selection fails, but the one with proliferation succeeds. By leveraging more relay vehicles by turning on the proliferation mode as shown in Figure 11(e), successful on-time delivery is achieved through some moderate population increase in Figure 11(b). An interesting observation is that once a proliferation mode is enabled, and more relay vehicles become involved, the distance toward the destination becomes decreased. This means that selecting more competitive relay vehicles helps to contribute to its delivery success.
As a pessimistic case where both algorithms fail to deliver within the deadline, we observe that the distance continuously gets decreased as shown in Figure 11(c). This is because more relay vehicles are used over time in Figure 11(f), although its first arrival at destination is out of the deadline.
Finally, we validate network performance in the previous concurrent data delivery scenario where a packet leaves for two destinations at the same time. We compare our proliferation algorithm with a high population setting of (

Concurrent data delivery performance to multiple destinations with proliferation (under
Our proliferation algorithm achieves a high stable on-time delivery rate above 80% for both destinations when the deadline is 1 h and beyond as shown in Figure 12(a). Although the K closest relay selection holds the highest on-time delivery rate, it incurs a much higher transmission cost than ours with a factor of 10 as shown in Figure 12(b) and (c). Furthermore, the epidemic routing spends incomparably high transmission costs, whereas reaching 100% timely delivery. It is demonstrated that without delicate packet replication control, a delivery algorithm can waste a tremendous amount of transmission cost. This implies that our proliferation performs on-time data delivery toward multiple destinations at a practical balance between reliability and efficiency.
Conclusion
We have addressed the problem of directional data delivery to multiple destinations within distinct deadline based on relay selection and proliferation. We have presented a simple yet effective relay selection that encourages a shared ride for data delivery in parts on the way to each destination. By considering only essential vehicle information of position, velocity, and remaining packet delivery time, it continues to find an effective relay vehicle in a periodic manner and makes its best effort to arrive at destinations.
Since only a single relay vehicle is not sufficient for achieving practically stable on-time delivery performance in real-world situations, our approach turns on a proliferation mode that increases the number of relay vehicles. We dynamically control the population of relay vehicles depending on data delivery progress. By doing so, our data forwarding algorithm has validated its practically high performance in terms of both reliability and efficiency in on-time packet delivery in real-world data-driven simulation experiments.
Although our proposed algorithm shows its accuracy and efficiency in timely delivery, it still spends some significant network overhead in urgent situations. This limitation is mainly caused by the fact that even if some relay vehicles have already arrived at the destination, some other relay vehicles have no way to be aware of the delivery results while keeping replicating. As a future extension, we may consider a new design dimension such that each relay vehicle can self-control packet replication in a probabilistic way as the delivery deadline comes closer.
For other future works, we may devise a hybrid data forwarding approach that can use not only unconstrained vehicles but also some constrained vehicles such as buses that move along pre-determined routes. It may improve both packet delivery reliability and efficiency by arranging two different types of vehicles at each suitable time depending on the deadline budget.
Footnotes
Acknowledgements
The authors would like to thank the Wireless and Sensor Networks Lab (WnSN) at Shanghai Jiao Tong University for sharing valuable data on Shanghai taxi GPS traces.
Handling Editor: Stephan Reiff-Marganiec
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (no. NRF-2018R1A2B6004006).