
Abstract
The massive use of cars in cities brings several problems such as traffic congestion and air pollution. Carpooling is an effective way to reduce the use of cars on the premise of meeting passenger transport needs. However, route planning will influence the efficiency of carpooling. By now, most researches on the route planning of carpooling mainly pay attention to minimizing the total driving distance of cars, but for passengers, the most crucial thing is to get to the destination as soon as possible. And in most cases, the minimum total driving distance of cars does not mean the minimal average arriving distance of all passengers. To address this issue, in this article, we formulate a novel carpooling route calculation problem with the objective of minimizing the average arriving distance of all passengers in carpooling. Then, we prove that this problem is NP-hard. To solve this problem, for the situation that the vehicle capacity is sufficient to deliver all passengers, we propose a heuristic algorithm named SimilarDirection with
Introduction
Vehicles have become an indispensable part of human life in modern society. Among all the vehicles, cars play a critically salient role in current urban traffic. It gradually becomes one of the most common tools for people to travel for convenience and comfort. According toNational Statistics, 1 there were about 31.3 million cars used on the roads in Great Britain at the end of March 2018. However, substantial use of cars in cities engenders egregious impacts on many aspects, such as traffic congestion, air contamination, massive gas consumption, and so on.2–4 Therefore, it is urgent to make reasonable use of limited resources to effectively alleviate these urban pressures. A phenomenon frequently happens in our daily life that numerous cars run with empty seats, which wastes the transportation resources. As a result, we should efficiently use the empty seats of the urban traffic systems to improve its efficiency.5,6 To this end, in recent years, there has been an increasing interest in carpooling for the purpose of optimizing the use of cars. That is to say, we should try our best to make cars as fully loaded as possible. Carpooling is a relatively environmentally friendly way of traveling, in which drivers assign empty seats to passengers with similar travel routes.7,8 Since the 1970s, carpooling was on the rise in some developed countries. For instance, in Germany, carpooling is considered as an environmental event, and the government takes administrative measures to encourage carpooling. 9 Recently, in many cities of China, such as Beijing, Shanghai, and Guangzhou, more and more people choose carpooling as their way of traveling. Carpooling brings passengers, who have the same destination, or similar directions into one car, which can reduce fuel consumption, travel costs, and transportation costs, and significantly increase the occupancy rates.
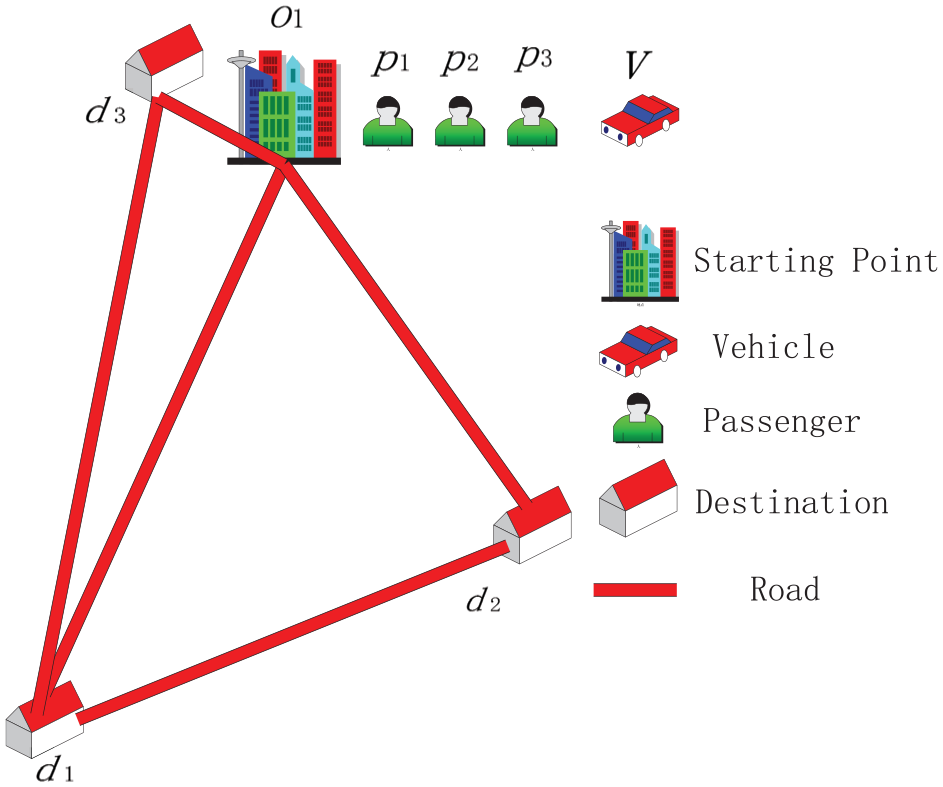
There have been a number of studies that concentrate on carpooling on several aspects, such as route planning, carpooling applications, and social network in carpooling. However, most studies in terms of route planning mainly focus on minimizing the total driving distance of cars on the premise of delivering passengers to their destinations,10–12 but it may give some passengers a bad user experience. For example, in Figure 1, there are three people

Three passengers
Proposing an algorithm for minimizing the average arriving distance in carpooling is the motivation for us to write this article, while few studies take note of this kind of problem at present. We mathematically formulate a carpooling route calculation problem which focuses on minimizing the average arriving distance of all passengers. Then, we prove that this problem is NP-hard. A heuristic algorithm named SimilarDirection is provided to solve this problem for the situation that the total capacity of all vehicles is not less than the number of passengers. The main idea of the algorithm is to assign people whose destinations are located near a specific straight line to the same vehicle, including three phases: actual passenger number determination phase that determines the passenger volume of each vehicle, passenger assignment phase that decides which people will be assigned to the same car, and delivery order determination phase that determines the delivery order of passengers in the same vehicle. When the vehicle capacity is insufficient, we provide three algorithms called DelFar, Unchanged, and DelRan to solve this problem. We use BaiduMap API to obtain a dataset including the location of 400 hotels and the road length between each pair of hotels. This dataset is used for our real-world dataset experiments, and a synthetic dataset is used for our synthetic dataset experiments. The experimental results show that our algorithm has better performance than the other contrast algorithms in producing average arriving distance. In brief, we have made the following contributions:
Due to the fact that far too little attention has been paid to the minimization of the average arriving distance, we formulate a novel carpooling route calculation problem aiming at minimizing the average arriving distance of all people. To the best of our knowledge, it is the first work concentrating on minimizing the average arriving distance of all passengers in carpooling where drivers don’t have their own predetermined routes, and they serve passengers exclusively.
We prove the NP-hardness of the carpooling problem and propose a heuristic algorithm named SimilarDirection to solve this problem. The SimilarDirection algorithm has
A real-world dataset obtained from BaiduMap API is tested in our real-world dataset experiments, and a synthetic dataset in which the latitude and longitude of each vertex is randomly generated is tested in our synthetic dataset experiments. In both real-world dataset experiments and synthetic dataset experiments, SimilarDirection produces the least average arriving distance among different algorithms in sufficient vehicle capacity situation, and DelFar has the best performance in producing less average arriving distance on condition that the vehicle capacity is not sufficient.
The rest of the article is organized as follows. We introduce the related work in the “Related work” section. Basic concepts are listed in the “Network model” section and the carpooling route calculation problem formulation is presented in the section “Problem formulation.” In “SimilarDirection: a heuristic algorithm” section, we provide our heuristic algorithm for solving the carpooling route calculation problem. Then, we do several experiments to evaluate the performance of our algorithm and show the results in “Evaluation” section. Finally, we conclude this article in the “Conclusion” section.
Related work
Existing problems of urban traffic
Massive vehicles in the cities not only bring convenience to people but also bring some challenging problems, such as traffic accidents, air pollution, and traffic congestion. With regard to traffic accidents, the increase of vehicles has led to an increase in traffic accidents. In China, from 2015 to 2016, the number of traffic accidents increased by 13%, and the number of deaths due to traffic accidents increased by 8.7%.13,14 It is foreseeable that the number of traffic accidents and the number of deaths due to traffic accidents will continue to rise in the future. Although this trend is inevitable, it is necessary to reduce the use of vehicles on the premise of meeting passenger transport needs. Meanwhile, the average car occupancy rate, which represents average number of persons carried by a car, is very low nowadays. In America, about 80 million commuters drive with no one else in their cars when commuting according to American Community Survey Reports. 5 In the United Kingdom, a car carries an average of 1.5 passengers. 6 It means that numerous cars are running with empty seats, which can be utilized to reduce the number of cars in use. Carpooling thus became a hot research field, because it helps to solve these problems, and allows the passengers to get a financial discount on the ride.
Researches about carpooling
Classical carpooling researches7,15 mainly focus on the problem where the passengers are regular with fixed routes, so the problem is different from our work. Similar to previous works,7,15 in He et al., 16 the authors obtained “frequent route” of passengers by mining users’ GPS trajectories, then they merged several frequent routes to generate a shared route for carpooling. In today’s carpooling researches, a person’s carpooling partners and carpooling routes are usually dynamically changing, which is closer to reality. There are several researches focusing on carpooling, a main concern is developing carpooling applications. Blerim Cici et al. 10 developed a carpooling system named SORS, where drivers and passengers send their requests for a ride beforehand, to deal with dynamic carpooling requests. Desheng Zhang et al. 11 designed and implemented a carpooling system with both hardware and software design installed on taxis called coRide to deliver passengers with the object of reducing the total driving distance as possible. Many works explored the research of carpooling such as combining carpooling and social network. Maria Luísa Matos et al. 12 developed a system called GO! that allows passengers to build a network of friends when carpooling with others in. Ahmed Elbery et al. 17 designed a carpooling recommendation system to recommend people join the trip of their friends for carpooling, and other papers focused on the social effects of carpooling such as. 18 Obviously, among all the research directions, a common concern is routing planning. However, to the best of our knowledge, almost all work about carpooling mainly focus on minimizing the total driving distance of cars10–12 instead of the average arriving distance of all passengers, which will probably cause bad user experiences for passengers. Shih-Chia Huang et al. 19 put forward a concept called “average travel distance of passengers,” and one of their seven objectives is to minimize the “average travel distance of passengers” in carpooling, but a constraint in their study 19 is that drivers have their own routes, which means that drivers are not dedicated to serving passengers, they only provide free ride service to passengers on the basis of completing their own driving routes; this constraint makes the problem different from ours. In fact, the route planning problem in carpooling is a well-known problem called vehicle routing problem (VRP).
VRP
VRP is a classical NP-hard problem which is combinational optimization and integer programming and appeared first in Dantzig and Ramser. 20 The purpose is to find the optimal routes that minimize the total routing cost for candidate cars to deliver a given group of passengers. It has many variations such as Vehicle Routing Problem with Pickup and Delivery (VRPPD), 21 Vehicle Routing Problem with Time Windows (VRPTW), 22 Capacitated Vehicle Routing Problem (CVRP), 23 Open Vehicle Routing Problem (OVRP), 24 and so on. Among all variations and specializations, OVRP is the most related to our problem because the setting is that vehicles do not need to return to the start point. There are many researches using different algorithms to solve this problem, such as in previous works.25–32 But like most problems about route planning of vehicles, the objective of OVRP is also minimizing the total driving distance of all vehicles, instead of the total driving distance of all passengers.
Network model
In our problem, there are
Definition 1 (road length)
Given a traffic network
Definition 2 (actual driving distance)
Given a specific driving plan
Definition 3 (delivery request)
A delivery request
Definition 4 (actual passenger number)
The actual passenger number of a car is the number of passengers that the car will deliver according to a given delivery request
Definition 5 (driving plan)
Given a delivery request
Definition 6 (arriving distance)
Given a specific driving plan
Problem formulation
Based on the network model and above definitions, we can formulate the carpooling route calculation problem as follows:
In a traffic network
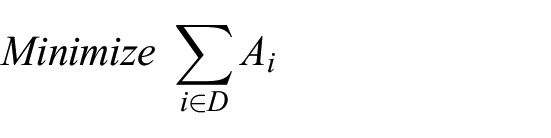
Subject to:
A passenger can only be delivered by one vehicle from the origin to his or her destination;
All passengers will be delivered to their destination at final;
Each vertex in
Each vehicle can only pick up the passengers at the starting point
The total capacity of all vehicles is not less than the number of passengers, that is,
Theorem 1
The carpooling route calculation problem is NP-hard.
Proof
By imposing a bound on the value to be optimized, we can usually transform a given optimization problem into a related decision problem. In order to prove the NP-hardness of a given optimization problem, we can prove that the related decision problem of this optimization problem is NP-Complete.
33
It is obvious that the carpooling route calculation problem is an optimization problem. Therefore, if the related decision problem of the carpooling route calculation problem is a NP-complete problem, then the carpooling route calculation problem is NP-hard. The related decision problem of the carpooling route calculation problem is, in a traffic network
It is easy to prove that the decision carpooling problem is NP, because when a specific driving plan is given, we can consequently calculate the arriving distance of all people in polynomial time and determine whether it is greater than
Next, we have to prove that the decision carpooling problem is NP-hard. Apparently, if a special case of the decision carpooling problem is NP-hard, then the decision carpooling problem is NP-hard. We consider a special case of the decision carpooling problem: (1) for any two vertexes
If a problem is proved to be the reduction from a known NP-hard problem, then this problem is NP-Hard.
33
We will prove the NP-hardness of the special decision carpooling problem by proving hamiltonian path problem, a well-known NP-hard problem, is reducible to the special decision carpooling problem. Let

We will prove that “the graph
Hamiltonian path problem is reduced to the special decision carpooling problem, so the special decision carpooling problem is proved to be NP-hard, thus the decision carpooling problem is NP-hard. Since the decision carpooling problem is NP, the decision carpooling problem is both NP and NP-hard, in other words, it is NP-complete. As the decision carpooling problem is NP-complete, the carpooling route calculation problem is NP-hard. ■
Since the carpooling route calculation problem is NP-hard, the time required for solving the carpooling route calculation problem grows rapidly along with the increase of the number of destinations in the delivery request. Hence, it is impossible to find an optimal algorithm to solve this problem. Therefore, a heuristic algorithm is proposed in this article.
SimilarDirection: a heuristic algorithm
In this section, we propose a heuristic algorithm called SimilarDirection including three phases: actual passenger number determination, passenger assignment, and delivery order determination. First, we give a brief description and the pseudo-code of the three phases of our heuristic algorithm, then give the pseudo-code of SimilarDirection.
Actual passenger number determination
In order to minimize the average arriving distance of all people, we will utilize all available vehicles as possible, so the key is how to determine the actual passenger number of each vehicle. It is forbidden to use the method that aims to simply fill up the vehicles because it will cause idle vehicles. For example, there are eight passengers and three vehicles; each vehicle has four seats. If we use the method we mentioned above, the first two vehicles will be full and the remaining vehicle will be empty. We need to find an effective algorithm to improve the utilization rate of all available vehicles.
The main idea of our actual passenger number determination algorithm is as follows: given a delivery request

Passenger assignment
In most cases, for a vehicle driver, when his or her vehicle is already loaded with passengers, he or she prefers to pick up a passenger that meets the following conditions: (1) on the direction that is the most similar to existing passengers in his or her vehicle among all candidate passengers and (2) causing least “extra distance” for existing people to arrive at their destinations among all candidate passengers. If condition (1) contradicts condition (2), the driver will choose the people that satisfies condition (2).
For example, in Figure 2, an empty vehicle

How will a driver choose passengers to deliver in reality: An empty vehicle
The position of
Inspired by the passenger selection rules used frequently in reality, we provide a passenger assignment algorithm aiming at assigning passengers with similar directions to their destinations in a vehicle. This algorithm will formulate the driving route of each vehicle as a straight line as much as possible. The main idea of the passenger assignment algorithm is as follows: First, we find a passenger
To describe the passenger assignment algorithm more graphically, we use Figure 4 to illustrate the algorithm. In Figure 4, there are two vehicles

An example of our passenger assignment algorithm.
Delivery order calculation
In delivery order calculation phase, we use a simple algorithm based on minimum spanning tree to determine the delivery order of passengers in the same vehicle, called VariantMST. The main idea is as follows: to calculate the delivery order of passengers in a given vehicle, we first define a completed directed graph
We use Figure 5 to illustrate the branches elimination algorithm in Zhang et al.
11
The left tree
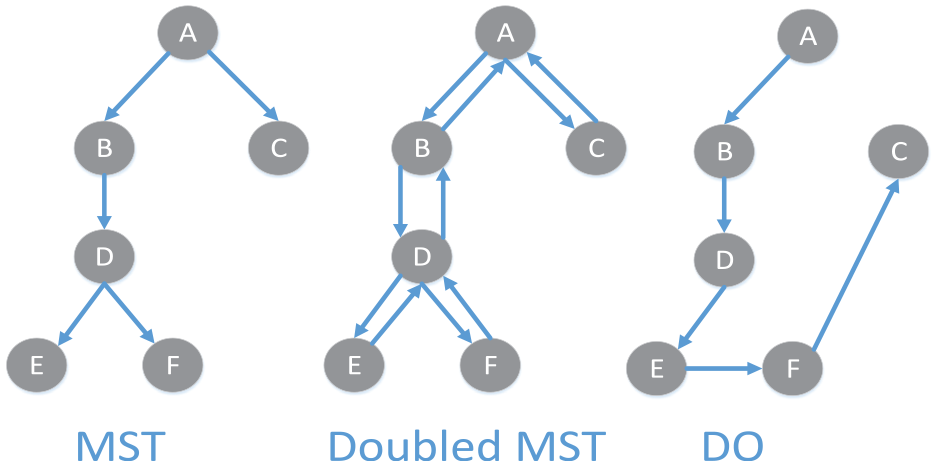
An example to show the branches elimination algorithm provided in Zhang et al. 11
Theorem 2
The VariantMST algorithm has an approximation ratio of
Proof
We will prove that, for any vehicle, the arriving distance of passengers in this vehicle obtained by our VariantMST algorithm is at most
When
Based on the above three algorithms, we give the pseudo-code of our algorithm SimilarDirection in Algorithm 4. And we will show the time complexity of the algorithm SimilarDirection.
Theorem 3
The time complexity of the algorithm SimilarDirection is
Proof
The SimilarDirection algorithm includes three phases: actual passenger number determination, passenger assignment and delivery order determination. So the time complexity of the SimilarDirection algorithm is the sum of the time complexity of the three phases.
In the first phase, we determine the actual passenger number of each vehicle with the number of remained passengers decreased by
In the second phase, for a particular vehicle, the time complexity of the step “Find a vertex

The third phase aims to determine the delivery order of passengers in the same vehicle by using Algorithm 3. Algorithm 3 includes two processes for each vehicle: calculate the minimum spanning tree, eliminate branches of the minimum spanning tree to get the delivery order by depth-first search. For each vehicle, in the first process, we use either Prim’s algorithm or Kruskal’s algorithm to calculate the minimum spanning tree of a complete graph with at most


In conclusion, the time complexity of the SimilarDirection algorithm is
Another situation: insufficient vehicle capacity
So far, what we have considered is a special situation that the total capacity of all vehicles is not less than the number of passengers. It is worth noting that there is another common situation in real life, that is, the vehicle capacity is insufficient, and it is impossible to deliver all passengers by using existing vehicles. Therefore, we can only select part of the passengers to deliver. In this article, there are three candidate algorithms to solve this problem.
DelFar: In this algorithm, first, we will select passengers in accordance with the distance from the starting point to their destination from small to large, so
Unchanged: In this algorithm, we use the SimilarDirection algorithm directly. In this way, when all vehicles are fully loaded, the Passenger Assignment algorithm is terminated.
DelRan: In this algorithm, we will randomly select
Evaluation
To compare the performance of different algorithms, we give two definitions as follows:
Definition 7 (average arriving distance performance ratio)
The average arriving distance performance result of an algorithm is that, for a given case, the average of average arriving distance in each experiment. The average arriving distance performance ratio (AADPR) of an algorithm in a given case is the average arriving distance performance result of SimilarDirection algorithm divided by the average arriving distance performance result of this algorithm when using the same data and running the same time experiments. AADPR is greater than 1 means that this algorithm produces less average arriving distance of all passengers than our algorithm, and the larger the value of AADPR, the better the performance of this algorithm in producing less average arriving distance.
Definition 8 (total driving distance performance ratio)
Similarly, the total driving distance performance result of an algorithm is the average of total driving distance for a given case in each experiment. The total driving distance performance ratio (TDDPR) of an algorithm in a given case is the total driving distance performance result of SimilarDirection algorithm divided by the total driving distance performance result of this algorithm when using the same data and running the same time experiments.
We have done several experiments to test the performance of our algorithm in producing the two kinds of distances. Next, we will introduce other algorithms we used to compare with our algorithm, and we will also introduce the synthetic dataset and the real-world dataset with their experiment settings and the experimental results.
We have also done several experiments to test the performance of the three algorithms for solving the problem when the vehicle capacity is insufficient, and we will show the experiment settings and results.
Algorithms used for comparing with our algorithm
We design two algorithms called Random and NearestFirst. We also implement the passenger assignment phase and delivery order calculation phase of coRide in Zhang et al., 11 then we combine the two algorithms as a new algorithm for solving the carpooling route calculation problem. For ease of understanding, we also call this new algorithm coRide. We use the three algorithms to compare with our algorithm. Random and NearestFirst have three phases named actual passenger number determination, passenger assignment, and delivery order determination. In Random and NearestFirst, the algorithms used in the first phase and the third phase are the same as those used in the first and third phases of our algorithm. The brief descriptions of the three algorithms are as follows.
Random: In the second phase, the passengers assigned to each vehicle are randomly selected.
NearestFirst: In the second phase, the rule to assign passengers is as follows: find the passenger
coRide: Different from our algorithm, coRide only has two phases: passenger assignment and delivery order calculation. In passenger assignment phase, according to the delivery request
Synthetic dataset
In the synthetic dataset experiments, the latitude and longitude of each vertex are randomly generated in given ranges, longitudes range from 125.1 to 125.5 and latitudes range from 43.8 to 44 to ensure that the randomly generated vertexes are located in Changchun city. For simplicity, in each time experiment, the vertexes in the delivery request, including the origin vertex and the destination vertexes, are the same as the vertexes in the traffic network.
Real-world dataset
To do the real-world dataset experiments, we get the latitude and longitude of 400 hotels in Changchun as vertexes and calculate the road length between all points as our traffic network by using BaiduMap Web API. We will concretely introduce how we use BaiduMap Web API to get these data.
Step 1. Get the location of 400 hotels
In the real-world dataset experiments, we should make sure that each vertex in the dataset corresponds to a real POI (Point of Interest) in Changchun. So we use place API, which is used to find a specific kind of POI in a given region, to find 400 hotels in Changchun. We randomly select the detailed information of two hotels in Changchun, the information will be used later. The detailed information of one of the two hotels is as follows:

The location information of each hotel will be used at the next step: get the road length between each pair of hotels.
Step 2. Get the road length between each pair of hotels
To get the road length between each pair of hotels, we use Direction API that can search for qualified driving route plan based on starting point and end point coordinates. The message returned contains an attribute named “distance,” which represents the driving distance in this plan. We regard the attribute “distance” as the road length between two hotels. To use this API, we need to input the latitude and longitude of starting point
It is worth noting that if we set

At first, hotel 1 is the starting point and hotel 2 is the end point. After exchanging the roles of the starting point and the end point, the driving route is different from the previous driving route.
In every experiment where the number of vehicles, the number of passengers, and the capacity of each vehicle are given, we randomly select some vertexes to establish a delivery request with such attributes.
Experiment settings
Settings for testing our SimilarDirection algorithm: In both the real-world dataset experiments and the synthetic dataset experiments, we use four situations to test the performances of our algorithm. In the first three situations, the number of passengers is equal to the product of the number of vehicles and the capacity of each vehicles. The first situation is that the number of passengers is fixed as 180; the number of vehicles and the capacity of each vehicle is variable in different cases. The second situation is that the capacity of each vehicle is fixed as 4; the number of passengers and the number of vehicles are variable in different cases. And in the third situation, the number of vehicles is fixed as 20 in the real-world dataset experiments and is fixed as 45 in the synthetic dataset experiments; the capacity of each vehicle and the number of passengers are variable in different cases. In the fourth situation, the number of passengers is not equal to the product of the number of vehicles and the capacity of each vehicles. The number of vehicles in the fourth situation is 90; the capacity of each vehicle in the fourth situation is 4; and the number of passengers increases from 100 to 360 with 20 passengers’ increasing each time in the fourth situation.
It is unnecessary to use the situation that the total capacity of all vehicles is less than the number of passengers, because for any “insufficient capacity” situation, there is a corresponding equivalent situation apparently where the number of passengers is equal to the product of the number of vehicles and the capacity of each vehicles.
A situation includes several cases, for example, in the first situation we mentioned above, there are cases such as 60 vehicles, each with a capacity of 3, and 45 vehicles, each with a capacity of 4, and so on. In each case, we use different data and run 100,000 times experiment, then we calculate the average of the average arriving distance and the average of the total driving distance of each time.
Settings for testing the performance of the three algorithms: In both the real-world dataset experiments and the synthetic dataset experiments, we use four cases to test the performances of the three algorithms which are used for solving the carpooling problem when the vehicle capacity is insufficient: DelFar, Unchanged, and DelRan. In all the four cases, the number of vehicles is fixed as 45; the capacity of each vehicle is fixed as 4; and the number of passengers in the four cases is 200, 220, 240, and 260, respectively. In other words, compared with the capacity of 180, there are a range of 20 to 80 extra passengers in the four cases. In each case, we also use different data and run 100,000 times experiment, then we calculate the average of the average arriving distance and the average of the total driving distance of each time.
Results
Results about the performance of our SimilarDirection algorithm: We show the experimental results of the real-world dataset experiments about the performance of our SimilarDirection algorithm in Figure 7(a)–(d) and Figure 9(a)–(d), and the synthetic dataset experiments about the performance of our SimilarDirection algorithm in Figure 8(a)–(d) and Figure 10(a)–(d) as follows. The “SD,”“R,”“NF,” and “CR” in Figures 7–10 represent the abbreviation of “SimilarDirection,”“Random,”“NearestFirst,” and “coRide,” respectively. The error bars in Figures 7–10 represent the value of standard deviation

AADPR comparisons in the real-world dataset experiments with four situations: (a) The number of passengers is fixed as 180, (b) the capacity of each vehicle is fixed as 4, (c) the number of vehicles is fixed as 20, and (d) the number of vehicles is 90, the capacity of each vehicle is 4.

AADPR comparisons in the synthetic dataset experiments with four situations: (a) The number of passengers is fixed as 180, (b) the capacity of each vehicle is fixed as 4, (c) the number of vehicles is fixed as 45, and (d) the number of vehicles is 90, the capacity of each vehicle is 4.
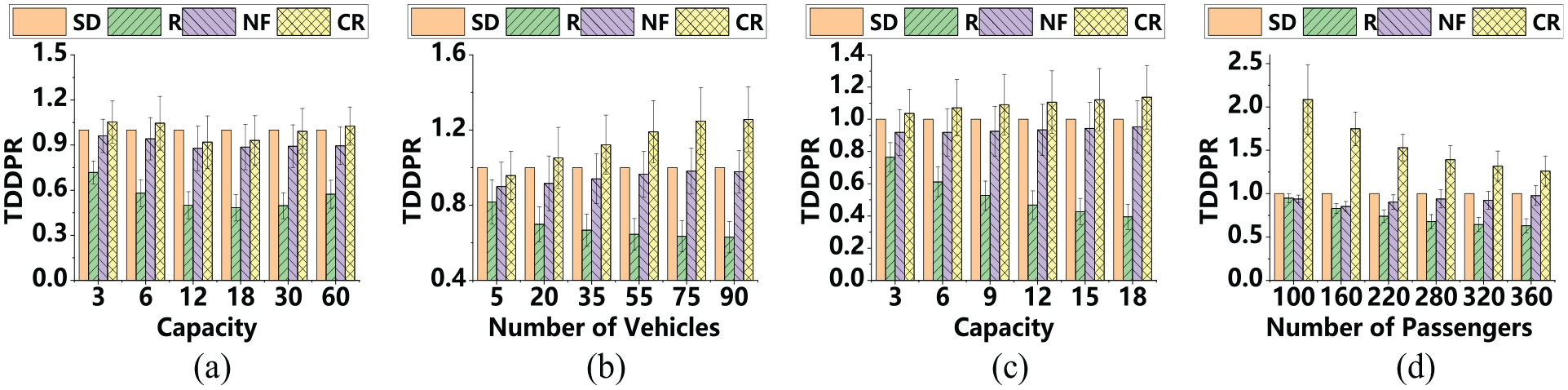
TDDPR comparisons in the real-world dataset experiments with four situations: (a) The number of passengers is fixed as 180, (b) the capacity of each vehicle is fixed as 4, (c) the number of vehicles is fixed as 20, and (d) the number of vehicles is 90, the capacity of each vehicle is 4.

TDDPR comparisons in the synthetic dataset experiments with four situations: (a) The number of passengers is fixed as 180, (b) the capacity of each vehicle is fixed as 4, (c) the number of vehicles is fixed as 45, and (d) the number of vehicles is 90, the capacity of each vehicle is 4.
As we can see, our algorithm can produce the least average arriving distance of all passengers among the four algorithms in all the eight situations we mentioned before in both the real-world dataset experiments and the synthetic dataset experiments. coRide has the second best AADPR in Figure 7(a)–(c) and Figure 8(a)–(c). In Figure 7(a) and (b), and Figure 8(a) and (b), the AADPR of Random and NearestFirst decreases at first, then increases in Figure 7(a) and (b), and Figure 8(a) and decreases in Figure 8(b). The AADPR of algorithms except ours are almost monotone decreasing in Figures 7(c) and 8(c).
In Figures 7(d) and 8(d), the AADPR of coRide is almost monotone increasing. In Figures 9(d) and 10(d), the TDDPR of coRide is almost monotone decreasing. The reason for the two phenomena is the algorithms except coRide aim to utilize all available vehicles as possible. When the number of passengers is small compared with the total capacity of all vehicles, the number of vehicles used by coRide will be smaller than the number of vehicles used by the other three algorithms.
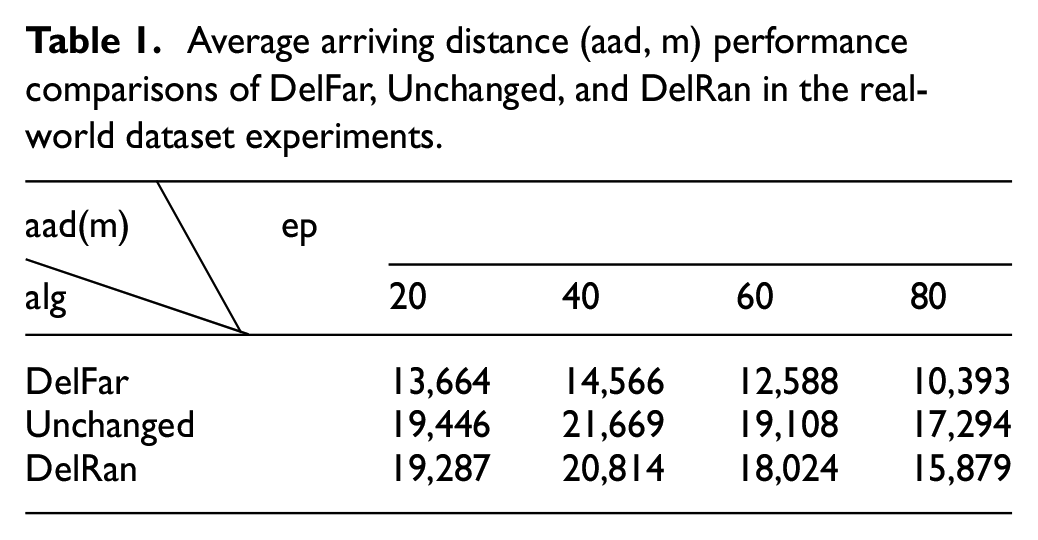
Results about the performance of DelFar, Unchanged, and DelRan: We show the experimental results about the performance of the three algorithms used for solving the carpooling problem when the vehicle capacity is insufficient (Tables 1–4). Tables 1 and 2 show the performance of the three algorithms in producing average arriving distance, Tables 3 and 4 show the performance of the three algorithms in producing total driving distance. The “aad” in Tables 1 and 2 represents the average of the average arriving distance of each time. The “tdd” in Tables 3 and 4 represents the average of the total driving distance of each time. The “ep” in Tables 1–4 represents the number of extra passengers when total capacity of all vehicles is 180. The “alg” in Tables 1–4 represents the abbreviation of “algorithm.” In Tables 1–4, we can see that of all the three algorithms, in both the real-world dataset experiments and the synthetic dataset experiments, DelFar has the best performance in producing less average arriving distance and less total driving distance of all passengers and DelRan has the second best performance, while algorithm Unchanged produces the most average arriving distance and total driving distance of all passengers.
Average arriving distance (aad, m) performance comparisons of DelFar, Unchanged, and DelRan in the real-world dataset experiments.
Average arriving distance (aad, m) performance comparisons of DelFar, Unchanged, and DelRan in the synthetic dataset experiments.

Total driving distance (tdd, km) performance comparisons of DelFar, Unchanged, and DelRan in the real-world dataset experiments.

Total driving distance (tdd, km) performance comparisons of DelFar, Unchanged, and DelRan in the synthetic dataset experiments.

Conclusion
There are many researches nowadays focusing on carpooling to optimize the use of cars. However, most researches mainly concentrate on minimizing the total driving distance of cars in carpooling. It probably takes some passengers a bad user experience. Compared with the total driving distance of cars, the average arriving distance of all passengers is what passengers are more concerned about. In this article, we formulate a problem aiming at minimizing the average arriving distance of all passengers in carpooling where drivers do not have their own routes. Then we prove its NP-hardness. Finally, for the situation that the vehicle capacity is sufficient to deliver all passengers, we propose a heuristic algorithm called SimilarDirection including three phases: actual passenger number determination, passenger assignment, and delivery order determination in order to solve this problem. In delivery order calculation phase, we prove that the arriving distance of all passengers obtained by the VariantMST algorithm is at most
Footnotes
Handling Editor: Paolo Bellavista
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Natural Science Foundations of China under Grant No. 61772230 and No. 61972450, Natural Science Foundation of China for Young Scholars No. 61702215, China Postdoctoral Science Foundation No. 2017M611322 and No. 2018T110247, and Changchun Science and Technology Development Project No.18DY005.